#USAIC20 Dr. Hal Barron, Chief Scientific Officer and President R&D, GlaxoSmithKline GWAS not easy to find which gene drives the association Functional Genomics gene by gene with phenotypes using machine learning significant help
Posted in Artificial Intelligence - Breakthroughs in Theories and Technologies, Artificial Intelligence - General, Artificial Intelligence Applications in Health Care, Artificial Intelligence in Medicine - Application for Diagnosis, Artificial Intelligence in Medicine - Applications in Therapeutics, BioTechnology - Venture Creation, BioTechnology - Venture Creation, Venture Capital, Disease Biology, Small Molecules in Development of Therapeutic Drugs, Drug Delivery Platform Technology, Drug Development Process, Drug Discovery Chemistry, drug repurposing, Genetics & Pharmaceutical, Global Market of Medical Devices Technology, Global Partnering & Biotech Investment, HealthCare IT, Personalized and Precision Medicine & Genomic Research, Pharmaceutical Discovery, Pharmaceutical Drug Discovery, Pharmaceutical Industry Competitive Intelligence, Pharmaceutical R&D Investment, Pharmacogenomics, Precision Cancer Medicine, Rapid automation of plasma protein pools on June 15, 2026|
Posted in Acute Myocardial Infarction, Adaptive Immune Response to Biomaterials and Tissue Repair, Advanced Drug Manufacturing Technology, Amino acids, Apoptosis, Apoptosis, Artificial intelligence applications for cardiology, Artificial Intelligence in Medicine - Application for Diagnosis, Artificial Intelligence in Medicine - Applications in Therapeutics, Atherogenic Processes & Pathology, Autoimmune Inflammatory DIseases, Autologous Cell Therapy, Automated Cell Processing, Autophagosome, Autophagy, Autophagy-Modulating Proteins, “Antibody–enzyme conjugates”, Bio Instrumentation in Experimental Life Sciences Research, Biochemical pathways, Bioengineering & reverse engineering design, Biological Engineering, Biomarkers & Medical Diagnostics, Biomedical Measurement Science, Ca2+ triggered activation, Calcium Signaling, Calmodulin, Calmodulin Kinase and Contraction, Cancer - General, Cardiac muscle regeneration, Cardiovascular Pharmacogenomics, Cell Biology, Signaling & Cell Circuits, Cell death pathways, Cell Processing System in Cell Therapy Process Development, Cerebrovascular and Neurodegenerative Diseases, Chemical Biology and its relations to Metabolic Disease, children, Clinical & Translational, Clinical Genomics, Computational Histopathology, congestive heart failure, Cytokine Receptor Structure, Cytokines, Deep Learning in Pathology, Dehydrogenase, Developmental biology, Diabetes Mellitus, Diagnostic Immunology, Disease Biology, Disease Biology, Small Molecules in Development of Therapeutic Drugs, Drug Carrier Design, Drug Delivery Platform Technology, Drug Discovery Chemistry, drug repurposing, Endocrine Diseases, Endoplasmic reticulum, Enzyme Induction, Enzymes and isoenzymes, Epigenetics and Cardiovascular Risks, Epigenetics and Environmental Factors, Evolution of Biology Through Culture, Fatty acids, Frontiers in Cardiology and Cardiovascular Disorders, Gastroenterology, Gene Regulation, Genome Biology, Genomic Analysis of EKG Electrophysiology Genomics, Genomic Endocrinology, Genomics Pharmacy, Glycobiology: Biopharmaceutical Production, Glycobiology: Biopharmaceutical Production, Pharmacodynamics and Pharmacokinetics, Gut Microbiome and Obesity, HTN, HTN in Youth, Human Antibody Response, Human Circulating Antibody Repertoire, Human Immune System in Health and in Disease, Human Sensation and Cellular Transduction: Physiology and Therapeutics, Immuno-Oncology & Genomics, Immunodiagnostics, Immunology, Immunotherapy, Indigent Nutrition, inflammation independent of lipid levels, Inflammatory Pathophysiology, Innovation in Immunology Diagnostics, Inosine nucleotides, Intellectual Property, Innovations, Commercialization, Investment in technological breakthrough, Interviews with Scientific Leaders, Investment in Technological Breakthrough, ion-transporting enzyme, IP Development by LPBI Group Team, Kinase, Lipid metabolism, Lipidomics, Lipids, Liposome, Liver & Digestive Diseases Research, Machine learning in predicting type 2 diabetes, Materials Science & Engineering, Medical and Population Genetics, Meta-analysis of transcriptome data, Metabolism, Metabolomics, Methylation, Microbiologial genetics, microbiome, Microfuidics, Micronutrients, Microvesicle, Molecular Genetics & Pharmaceutical, Mutant Gene Expression, Myocardial adenine nucleotide metabolism, Myocardial Ischemia, Myocardial Metabolism, Myocardial metabolism, Myocardial ischemia, myocardial perfusion, Myocardial adenine nucleotide metabolism, Na-K transport, Na-K-ATPase, Nanotechnology for Drug Delivery, Neurodegenerative Diseases, Neurohumoral Transmission, Neurological Diseases, Nitric Oxide in Health and Disease, Nutrigenomics, Nutrition, Nutrition and Phytochemistry, Nutrition Disorders, Nutritional Supplements: Atherogenesis, Nutritional Supplements: Atherogenesis, lipid metabolism, Obesity, Organic BioElectronics, Origins of Cardiovascular Disease, Pancreatic adenocarcinoma classifier, Patient-centered Medicine, Perioperative Statins at Noncardiac Surgery, Personalized and Precision Medicine & Genomic Research, Phagophore, Pharmaceutical Analytics, Pharmaceutical Drug Discovery, Pharmacodynamics and Pharmacokinetics, Pharmacogenomics, Pharmacotherapy and Cell Activity, Pharmacotherapy of Cardiovascular Disease, Phosphatase, Phosphorylase, Phosphorylation, Population Health Management, Population Health Management, Genetics & Pharmaceutical, Population Health Management, Nutrition and Phytochemistry, Precision Cancer Medicine, Protection Against Autoimmune Disease, Protein-energy malnutrition, Proteins, Proteomics, Rare heart rhythm disorders and Long QT syndrome (LQTS), Regenerative Biology and Medicine, RNA Biology, S-nitrosylation, Sensors & Analytics, Signaling, Signaling & Cell Circuits, single cell sequencing, Skeletal muscle regeneration, Small Molecules in Development of Therapeutic Drugs, Statistical Methods for Research Evaluation, Stress Disorders, Stroke, Stroke, Systemic Inflammatory Diseases as CVD Risk, Systemic Inflammatory Response Related Disorders, Technology Transfer: Biotech and Pharmaceutical, therapeutics, Tissue Engineering and Regenerative Medicine, Tissue Microenvironment, Tolerance-inducing Autoimmune Disease Therapeutics, Transcriptomics, Transformative Technologies in Healthcare, Translational Research, tyrosine decarboxylases, Ubiquitin, Ubiquitinylation, Unfolded Protein Response (UPR), Universal Immune Cell Therapies (uICT), Variation in human protein-coding regions, Vascular Diseases, Water Transporters on August 19, 2023| Leave a Comment »
Curators:
In this curation we wish to present two breaking through goals:
Goal 1:
Exposition of a new direction of research leading to a more comprehensive understanding of Metabolic Dysfunctional Diseases that are implicated in effecting the emergence of the two leading causes of human mortality in the World in 2023: (a) Cardiovascular Diseases, and (b) Cancer
Goal 2:
Development of Methods for Mapping Bioelectronic Adjustable Measurements as potential new Therapeutics for these eight subcellular causes of chronic metabolic diseases. It is anticipated that it will have a potential impact on the future of Pharmaceuticals to be used, a change from the present time current treatment protocols for Metabolic Dysfunctional Diseases.
According to Dr. Robert Lustig, M.D, an American pediatric endocrinologist. He is Professor emeritus of Pediatrics in the Division of Endocrinology at the University of California, San Francisco, where he specialized in neuroendocrinology and childhood obesity, there are eight subcellular pathologies that drive chronic metabolic diseases.
These eight subcellular pathologies can’t be measured at present time.
In this curation we will attempt to explore methods of measurement for each of these eight pathologies by harnessing the promise of the emerging field known as Bioelectronics.

Image source
Robert Lustig, M.D. on the Subcellular Processes That Belie Chronic Disease
https://www.youtube.com/watch?v=Ee_uoxuQo0I

Image source
Robert Lustig, M.D. on the Subcellular Processes That Belie Chronic Disease
https://www.youtube.com/watch?v=Ee_uoxuQo0I
These eight Subcellular Pathologies driving Chronic Metabolic Diseases are becoming our focus for exploration of the promise of Bioelectronics for two pursuits:
Ten TakeAway Points of Dr. Lustig’s talk on role of diet on the incidence of Type II Diabetes
Posted in Antibiotic resistance, Artificial Intelligence in Health Care - Tools & Innovations, Artificial Intelligence in Medicine - Applications in Therapeutics, Drug Development Process, drug repurposing, Evidence-based decision-making, Infectious Disease & New Antibiotic Targets, Inflammatory Pathophysiology, Pharmaceutical Drug Discovery, Transformative Technologies in Healthcare, tagged Acinetobacter baumanni, AI, Antibiotic resistance, Artificial intelligence, Artificial Intelligence ( AI), artificial intelligence in drug design, drug screens, in silico, rational drug design, superbug, WHO on May 26, 2023| Leave a Comment »
Reporter: Stephen J. Williams, Ph.D.
The World Health Organization has identified 3 superbugs, or infective micororganisms displaying resistance to common antibiotics and multidrug resistance, as threats to humanity:
Three bacteria were listed as critical:
It has been designated critical need for development of antibiotics to these pathogens. Now researchers at Mcmaster University and others in the US had used artificial intelligence (AI) to screen libraries of over 7,000 chemicals to find a drug that could be repurposed to kill off the pathogen.
Liu et. Al. (1) published their results of an AI screen to narrow down potential chemicals that could work against Acinetobacter baumanii in Nature Chemical Biology recently.
Abstract
Acinetobacter baumannii is a nosocomial Gram-negative pathogen that often displays multidrug resistance. Discovering new antibiotics against A. baumannii has proven challenging through conventional screening approaches. Fortunately, machine learning methods allow for the rapid exploration of chemical space, increasing the probability of discovering new antibacterial molecules. Here we screened ~7,500 molecules for those that inhibited the growth of A. baumannii in vitro. We trained a neural network with this growth inhibition dataset and performed in silico predictions for structurally new molecules with activity against A. baumannii. Through this approach, we discovered abaucin, an antibacterial compound with narrow-spectrum activity against A. baumannii. Further investigations revealed that abaucin perturbs lipoprotein trafficking through a mechanism involving LolE. Moreover, abaucin could control an A. baumannii infection in a mouse wound model. This work highlights the utility of machine learning in antibiotic discovery and describes a promising lead with targeted activity against a challenging Gram-negative pathogen.

Schematic workflow for incorporation of AI for antibiotic drug discovery for A. baumannii from 1. Liu, G., Catacutan, D.B., Rathod, K. et al. Deep learning-guided discovery of an antibiotic targeting Acinetobacter baumannii. Nat Chem Biol (2023). https://doi.org/10.1038/s41589-023-01349-8
Figure source: https://www.nature.com/articles/s41589-023-01349-8
Article Source: https://www.nature.com/articles/s41589-023-01349-8
For reference to WHO and lists of most pathogenic superbugs see https://www.scientificamerican.com/article/who-releases-list-of-worlds-most-dangerous-superbugs/
The finding was first reported by the BBC.
Source: https://www.bbc.com/news/health-65709834
By James Gallagher
Health and science correspondent
Scientists have used artificial intelligence (AI) to discover a new antibiotic that can kill a deadly species of superbug.
The AI helped narrow down thousands of potential chemicals to a handful that could be tested in the laboratory.
The result was a potent, experimental antibiotic called abaucin, which will need further tests before being used.
The researchers in Canada and the US say AI has the power to massively accelerate the discovery of new drugs.
It is the latest example of how the tools of artificial intelligence can be a revolutionary force in science and medicine.
Stopping the superbugs
Antibiotics kill bacteria. However, there has been a lack of new drugs for decades and bacteria are becoming harder to treat, as they evolve resistance to the ones we have.
More than a million people a year are estimated to die from infections that resist treatment with antibiotics.The researchers focused on one of the most problematic species of bacteria – Acinetobacter baumannii, which can infect wounds and cause pneumonia.
You may not have heard of it, but it is one of the three superbugs the World Health Organization has identified as a “critical” threat.
It is often able to shrug off multiple antibiotics and is a problem in hospitals and care homes, where it can survive on surfaces and medical equipment.
Dr Jonathan Stokes, from McMaster University, describes the bug as “public enemy number one” as it’s “really common” to find cases where it is “resistant to nearly every antibiotic”.
Artificial intelligence
To find a new antibiotic, the researchers first had to train the AI. They took thousands of drugs where the precise chemical structure was known, and manually tested them on Acinetobacter baumannii to see which could slow it down or kill it.
This information was fed into the AI so it could learn the chemical features of drugs that could attack the problematic bacterium.
The AI was then unleashed on a list of 6,680 compounds whose effectiveness was unknown. The results – published in Nature Chemical Biology – showed it took the AI an hour and a half to produce a shortlist.
The researchers tested 240 in the laboratory, and found nine potential antibiotics. One of them was the incredibly potent antibiotic abaucin.
Laboratory experiments showed it could treat infected wounds in mice and was able to kill A. baumannii samples from patients.
However, Dr Stokes told me: “This is when the work starts.”
The next step is to perfect the drug in the laboratory and then perform clinical trials. He expects the first AI antibiotics could take until 2030 until they are available to be prescribed.
Curiously, this experimental antibiotic had no effect on other species of bacteria, and works only on A. baumannii.
Many antibiotics kill bacteria indiscriminately. The researchers believe the precision of abaucin will make it harder for drug-resistance to emerge, and could lead to fewer side-effects.
In principle, the AI could screen tens of millions of potential compounds – something that would be impractical to do manually.
“AI enhances the rate, and in a perfect world decreases the cost, with which we can discover these new classes of antibiotic that we desperately need,” Dr Stokes told me.
The researchers tested the principles of AI-aided antibiotic discovery in E. coli in 2020, but have now used that knowledge to focus on the big nasties. They plan to look at Staphylococcus aureus and Pseudomonas aeruginosa next.
“This finding further supports the premise that AI can significantly accelerate and expand our search for novel antibiotics,” said Prof James Collins, from the Massachusetts Institute of Technology.
He added: “I’m excited that this work shows that we can use AI to help combat problematic pathogens such as A. baumannii.”
Prof Dame Sally Davies, the former chief medical officer for England and government envoy on anti-microbial resistance, told Radio 4’s The World Tonight: “We’re onto a winner.”
She said the idea of using AI was “a big game-changer, I’m thrilled to see the work he (Dr Stokes) is doing, it will save lives”.
(3 book series: Volume 1, 2&3, 4)
https://www.amazon.com/gp/product/B08VVWTNR4?ref_=dbs_p_pwh_rwt_anx_b_lnk&storeType=ebooks

Infectious Diseases and Therapeutics
and
The Immune System and Therapeutics
(Series D: BioMedicine & Immunology) Kindle Edition.
On Amazon.com since September 4, 2017
(English Edition) Kindle Edition – as one Book
https://www.amazon.com/dp/B075CXHY1B $115
Posted in Drug Development Process, drug repurposing, Pharmaceutical Discovery, Pharmaceutical Drug Discovery, Pharmaceutical Industry Competitive Intelligence, Pharmaceutical R&D Investment, Pharmacogenomics, Scientist: Career considerations on October 15, 2020| Leave a Comment »
Reporter: Aviva Lev-Ari, PhD, RN
Experience
Partner
Company Name
Syncona Limited Full-time
Dates EmployedApr 2020 – Present
Employment Duration7 mos
LocationLondon, England, United Kingdom
Company NameNovartis
Total Duration6 yrs 9 mos
TitleGlobal Head, Clinical Development & Analytics
Dates EmployedMay 2019 – Apr 2020
Employment Duration1 yr
LocationBasel Area, Switzerland
TitleGlobal Head, Neuroscience Development
Dates EmployedMar 2017 – Sep 2019
Employment Duration2 yrs 7 mos
LocationBasel Area, Switzerland
Show 2 more rolesCompany NameTeva Pharmaceuticals
Total Duration6 yrs
TitleHead of CNS & Pain Therapeutic Area, Global Branded Products
Dates EmployedOct 2010 – Dec 2012
Employment Duration2 yrs 3 mos
LocationIsrael
TitleGlobal Medical Director, Multiple Sclerosis
Dates EmployedOct 2009 – Nov 2010
Employment Duration1 yr 2 mos
TitleAssociate Director, Global Clinical Program Leader, MS Products
Dates Employed2006 – Oct 2009
Employment Duration3 yrs
Responsible for the clinical development of the innovative MS franchise in Teva Pharmaceutical Industries
Show fewer rolesSearch and Rescue Airborne Surgeon
Company Name
Israeli Air Force
Dates Employed 2004 – Dec 2009
Employment Duration5 yrs
Education
Tel Aviv University
Degree Name Doctor of Medicine (M.D.)
Grade Graduated with honors
Dates attended or expected graduation –
Tel Aviv University
Degree Name Bachelor of Science (B.Sc.)
Field Of Study Medicine
Dates attended or expected graduation –
Graduated with Honors
SOURCE
https://www.linkedin.com/in/danny-bar-zohar-513904a/
John Carroll
Editor & Founder
After a brief stint as a biotech investor at Syncona, Novartis vet Danny Bar-Zohar is back in R&D, and he’s taking the lead position at Merck KGaA’s drug division.
Bar-Zohar had led late-stage clinical development across a variety of areas — neuroscience, immunology, oncology and ophthalmology, among others — before joining the migration of talent out of the Basel-based multinational. He had been at Novartis for 7 years, which followed an earlier chapter in research at Teva.
Luciano Rossetti
The scientist is taking the lead on development at Merck KGaA, in place of Luciano Rossetti, who had a mixed record in R&D that nevertheless marked a big improvement over the dismal run the company had endured earlier. Joern-Peter Halle will continue on as global head of research. Rossetti is retiring after 6 years of running the research group, which has extensive operations in Germany as well as Massachusetts.Their PD-L1 Bavencio — allied with Pfizer — has had a few successes, and a whole slate of failures. Sprifermin was touted as a big potential advance in osteoarthritis, but Merck KGaA is now auctioning off that part of the portfolio. One of the few late-stage bright spots has been their MET inhibitor tepotinib, which won breakthrough status and now is under priority review. That drug faces a rival at Novartis — capmatinib — that won an accelerated OK at the FDA in May.
advertisement
advertisement
There’s also a BTK inhibitor, evobrutinib, that’s being developed for MS. But that’s a very crowded field, and Sanofi has been bullish about its prospects in the same research niche after buying out Principia.Moving back into mid-stage development, there’s a major program underway for bintrafusp alfa, a bifunctional fusion protein targeting TGF-β and PD-L1, which Merck KGaA has high hopes for.
That all marks some bright, though limited, prospects for Merck KGaA, highlighting the need to find something new to beef up the pipeline. Bar-Zohar will get a say in that.
AUTHOR
John Carroll
SOURCE
Posted in Big Data, BioSimilars, BioTechnology - Venture Creation, BioTechnology - Venture Creation, Venture Capital, Conference Coverage with Social Media, drug repurposing, Pharmaceutical Analytics, Pharmaceutical Discovery, Pharmaceutical Drug Discovery, Pharmaceutical Industry Competitive Intelligence, Pharmaceutical R&D Informatics, Pharmaceutical R&D Investment on September 4, 2020| Leave a Comment »
Reporter: Aviva Lev-Ari, PhD, RN
Real Time Press Coverage: Aviva Lev-Ari, PhD, RN
e-Proceedings 14th Annual BioPharma & Healthcare Summit, Friday, September 4, 2020, 8 AM EST to 3-30 PM EST – Virtual Edition
Real Time Press Coverage: Aviva Lev-Ari, PhD, RN
Founder & Director, LPBI Group
#USAIC20 Dr. Hal Barron, Chief Scientific Officer and President R&D, GlaxoSmithKline GWAS not easy to find which gene drives the association Functional Genomics gene by gene with phenotypes using machine learning significant help
#USAIC20 Dr. Hal Barron, Chief Scientific Officer and President R&D, GSK GWAS not easy to find which gene drives the association Functional Genomics gene by gene with phenotypes using machine learning significant help

Enjoyed hearing enthusiasm for Neuroscience R&D by Roy Vagelos at #USAIC20. Wonderful interview by Mathai Mammen
#USAIC20 Nina Kjellson, General Partner, Canaan Data science is a winner in Healthcare Women – Data Science is an excellent match
#USAIC20 Arpa Garay, President, Global Pharmaceuticals, Commercial Analytics, Merck & Co. Data on Patients and identification who will benefit fro which therapy cultural bias risk aversion
#USAIC20 Dr. Najat Khan, Chief Operating Officer, Janssen R&D Data Sciences, Johnson & Johnson Data Validation Deployment of algorithms embed data by type early on in the crisis to understand the disease
#USAIC20 Sastry Chilukuri, President, Acorn AI- Medidata Opportunities in Data Science in Paharma COVID-19 and Data Science
#USAIC20 Dr. Maya Said, Chief Executive Officer, Outcomes4Me Cancer patients taking change of their care Digital Health – consumerization of Health, patient demand to be part of the decision, part the information FDA launched a Program Project Patient Voice

#USAIC20 Dr. Roy Vagelos, Chairman of the Board, Regeneron HIV-AIDS: reverse transcriptase converted a lethal disease to a chronic disease, tried hard to make vaccine – the science was not there
#USAIC20 Dr. Roy Vagelos, Chairman of the Board, Regeneron Pharmaceuticals Congratulates Big Pharma for taking the challenge on COVID-19 Vaccine, Antibody and anti-viral Government funding Merck was independent from Government – to be able to set the price

#USAIC20 Daphne Zohar, Founder & CEO, PureTech Health Disease focus, best science is the decision factors
#USAIC20 Christopher Viehbacher, Managing Partner, Gurnet Point Capital Dream of every Biotech – get Big Pharma coming to acquire and pay a lot Morph and adapt
of
talks about various philosophies and key reasons why certain projects/molecules are killed early. My counter questions- What are chances of losing hope little early? Do small #biopharma publish negative results to aid to the knowledge pool? #USAIC20
#USAIC20 Rehan Verjee, President, EMD Serono Antibody cytoxic avoidance with precision
#USAIC20 Dr. Laurie Glimcher, President & CEO, Dana-Farber Cancer Institute DNA repair and epignetics are the future of medicine
#USAIC20 Dr. Laurie Glimcher, President & CEO, Dana-Farber Cancer Institute COlonorectal cancer is increasing immuno therapy 5 drugs marketed 30% cancer patients are treated early detection key vs metastatic 10% of cancer are inherited treatment early
#USAIC20 Rehan Verjee, President, EMD Serono Charities funding cancer research – were impacted and resources will come later and in decreased amount New opportunities support access to Medicine improve investment across the board
#USAIC20 Dr. Philip Larsen, Global Head of Research, Bayer AG Repurposing drugs as antiviral from drug screening innovating methods Cytokine storm in OCVID-19 – kinase inhibitors may be antiviral data of tested positive allows research of pathway in new ways
#USAIC20 Dr. Laurie Glimcher, President & CEO, Dana-Farber 3,000 Telemedicine session in the first week of the Pandemic vs 300 before – patient come back visits patient happy with Telemedicine team virtually need be reimbursed same rate working remotely
#USAIC20 Dr. Raju Kucherlapati, Professor of Genetics, Harvard Medical School New normal as a result of the pandemic role of personalized medicine
#USAIC20 Rehan Verjee, President, EMD Serono entire volume of clinical trials at Roche went down same at EMD delay of 6 month, some were to be initiated but was put on hold Charities funding cancer research were impacted and resources will come later smaller
#USAIC20 Dr. Laurie Glimcher, President & CEO, Dana-Farber Cancer Institute Dana Farber saw impact of COVID-19 on immunosuppressed patients coming in for Cancer Tx – switch from IV Tx to Oral 96% decrease in screenings due to Pandemic – increase with Cancer
#USAIC20 Kenneth Frazier, Chairman of the Board and Chief Executive Officer, Merck & Co. Pharma’s obligation for next generations requires investment in R&D vs Politicians running for 4 years Patients must come first vs shareholders vs R&D investment in 2011
#USAIC20 Kenneth Frazier, Chairman of the Board and Chief Executive Officer, Merck & Co. Antibiotic research at Merck – no market incentives on pricing for Merck to invest in antibiotics people will die from bacterial resistance next pandemic be bacterial
#USAIC20 Kenneth Frazier, Chairman of the Board and Chief Executive Officer, Merck & Co. Strategies of Merck = “Medicine is for the People not for Profit” – Ketruda in India is not reembureable in India and million are in need it Partnership are encouraged
Chairman Stelios Papadopoulos asks #KennethFrazier if wealthy nations will try to secure large proportion of #COVID19 drugs/vaccines. #KennethFrazie rightly mentions: pharma industry’s responsibility to balance the access to diff countries during pandemic. #USAIC20
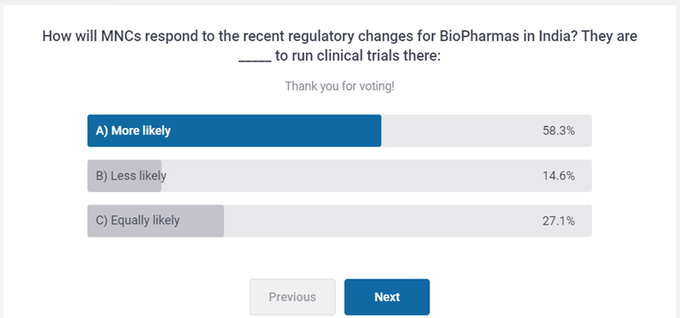
Almost 60% participants at #USAIC20 feel that MNCs are more likely to run their #clinicalTrials in #INDIA seeing changing environment here, reveals the poll. Exciting time ahead for scientific fraternity as this can substantially increase the speed of #DrugDevelopment globally

#USAIC20 Dr. Barry Bloom, Professor & former Dean, Harvard School of Public Health Vaccine in clinical trials, public need to return for 2nd shot, hesitancy Who will get the Vaccine first in the US most vulnerable of those causing transmission Pharma’s risk
#USAIC20 Dr. Barry Bloom, Professor & former Dean, Harvard School of Public Health Testing – PCR expensive does not enable quick testing is expensive result come transmission occurred Antibody testing CRISPR test based Vaccine in clinical trials
#USAIC20 Dr Andrew Plump, President of R&D, Takeda Pharmaceuticals COllaboration effort around the Globe in the Pandemic therapy solutions including Vaccines
Posted in Coronavirus Gene Expression, COVID-19, Drug Development Process, Drug Discovery Chemistry, drug repurposing, Personal Health Applications: Tech Innovations serves HealhCare, Personalized and Precision Medicine & Genomic Research, Pharmaceutical Discovery, Pharmaceutical Drug Discovery, Pharmaceutical Industry Competitive Intelligence, Pharmaceutical R&D Informatics, Pharmaceutical R&D Investment, Pharmacogenomics, Pharmacovigilance, Population Health Management, Population Health Management, Genetics & Pharmaceutical, SARS-CoV-2, Serology tests for coronavirus antibodies, Vaccinology, Virus Infective Acute Respiratory Syndrome: SARS-CoV on May 18, 2020| Leave a Comment »
Reporter: Aviva Lev-Ari, PhD, RN
Posted in BioTechnology - Venture Creation, BioTechnology - Venture Creation, Venture Capital, Conference Coverage with Social Media, Drug Development Process, drug repurposing, Pharmaceutical Discovery, Pharmaceutical Drug Discovery, Pharmaceutical Industry Competitive Intelligence, Pharmaceutical R&D Informatics, Pharmaceutical R&D Investment, Pharmacodynamics and Pharmacokinetics, Pharmacogenomics, Pharmacovigilance, Value-based Drug Pricing on April 30, 2019| Leave a Comment »
Reporter: Aviva Lev-Ari, PhD, RN
| 8:40 AM – 9:10 AM | Registration and Networking |
| 9:10 AM – 9:20 AM | Welcome address: Karun Rishi, President, USAIC
Opening comments: Dr Andrew Plump, President R&D and Director, Takeda Pharmaceuticals |
| 9:20 AM – 9:40 AM | Fireside Chat
Moderator: Sanat Chattopadhyay, President, Merck Manufacturing Division; Merck & Co. |
| 9:40 AM – 10:00 AM | Presentation on CAR (chimeric antigen receptor) T-cell Therapies Dr. Carl June, Director of Translational Research, Abramson Cancer Center University of Pennsylvania Moderator: Dr. Raju Kucherlapati, Professor of Genetics, Harvard Medical School |
| 10:00 AM – 10:50 AM | Panel Discussion: Oncology – The Emperor of BioPharma Development
Panelists:
Moderator: Dr. Christiana Bardon, Managing Director, MPM Capital |
| 10:50 AM – 11:20 AM | Networking Break |
| 11:20 AM – 12:10 PM | Panel Discussion: Future of Clinical Trials and Drug Development
Panelists:
Moderator: Dr. William Chin, Professor of Medicine, Emeritus, Harvard Medical School |
| 12:10 PM – 1:00 PM | Panel Discussion: Manufacturing in the Future
Panelists:
Moderator: Professor N. Venkat Venkatraman, Boston University Questrom School of Business |
| 1:00 PM – 1:50 PM | Lunch |
| 1:50 PM – 1:55 PM | Video message from Suresh Prabhu, Hon’ble Minister of Commerce & Industry, Gov. of India |
| 1:55 PM – 2:45 PM | Panel Discussion: One in a million – Emerging trends in Rare Diseases
Panelists:
Moderator: Dr. Samarth Kulkarni, Chief Executive Officer, CRISPR Therapeutics |
| 2:45 PM – 3:20 PM | Networking & Tea Break |
| 3:20 PM – 3:50 PM | Fireside Chat: Value and Access – The ongoing debate
Moderator: Dr Andrew Plump, President R&D, Takeda Pharmaceuticals |
| 3:50 PM – 4:10 PM | India update on Clinical Trial Regulations
|
| 4:10 PM – 5:00 PM | Panel Discussion: Research and Development Strategies and Trends
Panelists:
Moderator: Dr. Martin Mackay, Co-Founde, Rallybio |
| 5:00 PM – 5:05 PM | Closing Remarks |
| 5:05 PM – 6:15 PM | Cocktails & Networking Reception |









9:10 AM – 9:20 AM
Welcome address: Karun Rishi, President, USAIC
Opening comments: Dr Andrew Plump, President R&D and Director, Takeda Pharmaceuticals
9:20 AM – 9:40 AM
Fireside Chat
Moderator: Sanat Chattopadhyay, President, Merck Manufacturing Division; Merck & Co.
9:40 AM – 10:00 AM Presentation on CAR (chimeric antigen receptor) T-cell Therapies
Dr. Carl June, Director of Translational Research, Abramson Cancer Center University of Pennsylvania Moderator: Dr. Raju Kucherlapati, Professor of Genetics, Harvard Medical School
10:00 AM – 10:50 AM
Panel Discussion: Oncology – The Emperor of BioPharma Development
Panelists:
Moderator: Dr. Christiana Bardon, Managing Director, MPM Capital
10:50 AM – 11:20 AM Networking Break11:20 AM – 12:10 PM
Panel Discussion: Future of Clinical Trials and Drug Development
Panelists:
Moderator: Dr. William Chin, Professor of Medicine, Emeritus, Harvard Medical School
12:10 PM – 1:00 PM
Panel Discussion: Manufacturing in the Future
Panelists:
Moderator: Professor N. Venkat Venkatraman, Boston University Questrom School of Business
1:00 PM – 1:50 PMLunch1:50 PM – 1:55 PM Video message from Suresh Prabhu, Hon’ble Minister of Commerce & Industry, Gov. of India1:55 PM – 2:45 PM
Panel Discussion: One in a million – Emerging trends in Rare Diseases
Panelists:
Moderator: Dr. Samarth Kulkarni, Chief Executive Officer, CRISPR Therapeutics
2:45 PM – 3:20 PMNetworking & Tea Break3:20 PM – 3:50 PM
Fireside Chat: Value and Access – The ongoing debate
Moderator: Dr Andrew Plump, President R&D, Takeda Pharmaceuticals
3:50 PM – 4:10 PM
India update on Clinical Trial Regulations
4:10 PM – 5:00 PM
Panel Discussion: Research and Development Strategies and Trends
Panelists:
Moderator: Dr. Martin Mackay, Co-Founder, Rallybio
5:00 PM – 5:05 PM Closing Remarks
5:05 PM – 6:15 PM Cocktails & Networking Reception
Posted in BioSimilars, Drug Development Process, drug repurposing, Patents, Patient Experience, Patient-centered Medicine, Pharmaceutical Discovery, Pharmaceutical Drug Discovery, Voices of Patients and Healthcare Providers, tagged Cancer Care, Celgene, Drug Price Competition and Patent Term Restoration Act, generic drugs, healthcare costs, Multiple myeloma, Patent portfolio, pharmaceutical cost, Pharmaceutical Pricing Strategy, Revlimid on March 28, 2019| Leave a Comment »
Curator: Stephen J. Williams, PhD
REVLIMID® (lenalidomide) in combination with dexamethasone is indicated for the treatment of patients with multiple myeloma (MM). as maintenance therapy in patients with MM following autologous hematopoietic stem cell transplantation (auto-HSCT). and indicated for the treatment of patients with transfusion-dependent anemia due to low- or intermediate-1–risk myelodysplastic syndromes (MDS) associated with a deletion 5q cytogenetic abnormality with or without additional cytogenetic abnormalities.
REVLIMID is also indicated for the treatment of patients with mantle cell lymphoma (MCL) whose disease has relapsed or progressed after two prior therapies, one of which included bortezomib.
REVLIMID® sales for the fourth quarter 2018 increased 16 percent to $2,549 million. Fourth quarter U.S. sales of $1,729 million and international sales of $820 million increased 17 percent and 15 percent, respectively. REVLIMID® sales growth was driven by increases in treatment duration and market share. Full year REVLIMID® sales were $9,685 million, an increase of 18 percent year-over-year. (from Celgene press release)
However, Celgene’s Revlimid basically has no competition in the multiple myeloma market and there are no generics of Revlimid, even though Revlimid is a conger of thalidomide, the 1950 era drug developed for depression and resulted in the infamous thalidomide baby cases.
The problem is highlighted in two reports:
As seen in Fortune: Celgene Boosted Price of Top Cancer Drug on Day of Mega Deal
On the same day Celgene Corp. was announcing that it would be acquired by Bristol-Myers Squibb Co. in the biggest pharma deal ever, the company was also raising the price of its blockbuster cancer drug. The Summit, New Jersey-based biotechnology company, which has routinely increased the prices of its top-selling drugs, boosted the price of a 10-milligram dose of Revlimid by 3.5 percent to $719.82 effective Jan. 3, according to price data compiled by Bloomberg Intelligence and First Databank. Cancer patients need many doses of Revlimid a year, and the overall cost can approach $200,000. The same dose cost $247.28 at the end of 2007.
As reported on NPR by Alison Kodjak: Celgene’s Patent Fortress Protects Revlimid, Thalidomide: How A DrugMaker Gamed the Patent System to Keep Generic Competition Away
When Celgene Corp. first started marketing the drug Revlimid to treat multiple myeloma in 2006, the price was $6,195 for 21 capsules, a month’s supply.By the time David Mitchell started taking Revlimid in November 2010, Celgene had bumped the price up to about $8,000 a month. When he took his last month’s worth of pills in April 2016, the sticker price had reached $10,691. By last March, the list price had reached $16,691. Revlimid appears to have caught the attention of Health and Human Services Secretary Alex Azar, who used it as an example Wednesday — without naming it outright — of how some drug’s prices rise with impunity. He said the copay for the average senior taking the drug rose from $115 to about $690 per month in the last year. Celgene can keep raising the price of Revlimid because the drug has no competition. It’s been around for more than a decade and its original patent expires next year. But today it looks like another four years could pass with no generic competitor to Revlimid.
Therefore, when the European company Alvogen tired to produce a generic version of this drug and took Celgene to court, Celgene quickly shored up its patent fight as outlined below.
As reported in Biopharmadive.com:
Revlimid (lenalidomide) is a crucial drug for Celgene and its nearly $10 billion in annual revenue is a key part of Bristol-Myers’ deal to buy the storied biotech.
Celgene and Bristol-Myers Squibb expect limited generic competition to the multiple myeloma therapy in March 2022, followed by full generic entry in early 2026. If that timeline holds, Bristol-Myers could count on years of substantial cash flow generation that would help pay down debt raised to afford the $74 billion deal.
The PTAB’s rejection of petitions from first Dr. Reddy’s and now Alvogen makes that prospect more likely, although district court litigation between Celgene and Dr. Reddy’s continues.
Dodging those challenges could also help convince investors skeptical of the deal. A shareholder vote is set for April 12 and a major institutional investor recently joined activist investor Starboard Value in opposing the business combination.
The looming expiration of market exclusivity for Revlimid is a central part of Starboard’s objection to the deal.
“Bristol-Myers is knowingly acquiring a massive patent cliff with significant deal value concentrated in the net present value of the cash flows from one product,” the activist investor wrote in a proxy solicitation to Bristol-Myers’ shareholders.
Even though Alvogen’s petition was not expected to succeed, its denial avoids “potential issue that could unnerve investors ahead of the merger votes,” wrote Brian Abrahams, an analyst at RBC Capital Markets, in a March 14 note to clients.
Alvogen had sought to overturn U.S. Patent No. 7,968,569, which covers dosing of Revlimid in multiple myeloma, on grounds of obviousness. The PTAB, however, found it unlikely that Alvogen would prevail in invalidating at least one of the claims contained within that patent and therefore denied the company’s petition.
Interestingly, Alvogen last month launched a generic version of Revlimid in Romania, Croatia, Bulgaria and several Baltic states — a development that took investors by surprise and triggered new worries over Revlimid’s patent position.
That launch, however, came via a confidential agreement with Celgene which permitted Alvogen and its partner Lotus to begin sales of their copycat version. Celgene doesn’t expect any broader launch in the EU to follow.
Whether the PTAB denials of petitions from Dr. Reddy’s and Alvogen do, in fact, boost investor confidence in sales projections by Bristol-Myers and Celgene leadership isn’t clear.
But Bristol-Myers CEO Giovanni Caforio has clarified there are no other offers on the table waiting.
“This is not a defensive deal,” Caforio told investors at a recent conference. “We didn’t do it because there was an offer on the table.”
Some notes:

United States
This application claims the benefit of U.S. provisional application No. 60/380,842, filed May 17, 2002, and No. 60/424,600, filed Nov. 6, 2002, the entireties of which are incorporated herein by reference.
1. FIELD OF THE INVENTION
This invention relates to methods of treating, preventing and/or managing specific cancers, and other diseases including, but not limited to, those associated with, or characterized by, undesired angiogenesis, by the administration of one or more immunomodulatory compounds alone or in combination with other therapeutics. In particular, the invention encompasses the use of specific combinations, or “cocktails,” of drugs and other therapy, e.g., radiation to treat these specific cancers, including those refractory to conventional therapy. The invention also relates to pharmaceutical compositions and dosing regimens.
2. BACKGROUND OF THE INVENTION
2.1 Pathobiology of Cancer and Other Diseases
Cancer is characterized primarily by an increase in the number of abnormal cells derived from a given normal tissue, invasion of adjacent tissues by these abnormal cells, or lymphatic or blood-borne spread of malignant cells to regional lymph nodes and to distant sites (metastasis). Clinical data and molecular biologic studies indicate that cancer is a multistep process that begins with minor preneoplastic changes, which may under certain conditions progress to neoplasia. The neoplastic lesion may evolve clonally and develop an increasing capacity for invasion, growth, metastasis, and heterogeneity, especially under conditions in which the neoplastic cells escape the host’s immune surveillance. Roitt, I., Brostoff, J and Kale, D., Immunology, 17.1-17.12 (3rd ed., Mosby, St. Louis, Mo., 1993).
There is an enormous variety of cancers which are described in detail in the medical literature. Examples includes cancer of the lung, colon, rectum, prostate, breast, brain, and intestine. The incidence of cancer continues to climb as the general population ages, as new cancers develop, and as susceptible populations (e.g., people infected with AIDS or excessively exposed to sunlight) grow. A tremendous demand therefore exists for new methods and compositions that can be used to treat patients with cancer.
Many types of cancers are associated with new blood vessel formation, a process known as angiogenesis. Several of the mechanisms involved in tumor-induced angiogenesis have been elucidated. The most direct of these mechanisms is the secretion by the tumor cells of cytokines with angiogenic properties. Examples of these cytokines include acidic and basic fibroblastic growth factor (a,b-FGF), angiogenin, vascular endothelial growth factor (VEGF), and TNF-α. Alternatively, tumor cells can release angiogenic peptides through the production of proteases and the subsequent breakdown of the extracellular matrix where some cytokines are stored (e.g., b-FGF). Angiogenesis can also be induced indirectly through the recruitment of inflammatory cells (particularly macrophages) and their subsequent release of angiogenic cytokines (e.g., TNF-α, bFGF).
A variety of other diseases and disorders are also associated with, or characterized by, undesired angiogenesis. For example, enhanced or unregulated angiogenesis has been implicated in a number of diseases and medical conditions including, but not limited to, ocular neovascular diseases, choroidal neovascular diseases, retina neovascular diseases, rubeosis (neovascularization of the angle), viral diseases, genetic diseases, inflammatory diseases, allergic diseases, and autoimmune diseases. Examples of such diseases and conditions include, but are not limited to: diabetic retinopathy; retinopathy of prematurity; corneal graft rejection; neovascular glaucoma; retrolental fibroplasia; and proliferative vitreoretinopathy.
Accordingly, compounds that can control angiogenesis or inhibit the production of certain cytokines, including TNF-α, may be useful in the treatment and prevention of various diseases and conditions.
2.2 Methods of Treating Cancer
Current cancer therapy may involve surgery, chemotherapy, hormonal therapy and/or radiation treatment to eradicate neoplastic cells in a patient (see, for example, Stockdale, 1998, Medicine, vol. 3, Rubenstein and Federman, eds., Chapter 12, Section IV). Recently, cancer therapy could also involve biological therapy or immunotherapy. All of these approaches pose significant drawbacks for the patient. Surgery, for example, may be contraindicated due to the health of a patient or may be unacceptable to the patient. Additionally, surgery may not completely remove neoplastic tissue. Radiation therapy is only effective when the neoplastic tissue exhibits a higher sensitivity to radiation than normal tissue. Radiation therapy can also often elicit serious side effects. Hormonal therapy is rarely given as a single agent. Although hormonal therapy can be effective, it is often used to prevent or delay recurrence of cancer after other treatments have removed the majority of cancer cells. Biological therapies and immunotherapies are limited in number and may produce side effects such as rashes or swellings, flu-like symptoms, including fever, chills and fatigue, digestive tract problems or allergic reactions.
With respect to chemotherapy, there are a variety of chemotherapeutic agents available for treatment of cancer. A majority of cancer chemotherapeutics act by inhibiting DNA synthesis, either directly, or indirectly by inhibiting the biosynthesis of deoxyribonucleotide triphosphate precursors, to prevent DNA replication and concomitant cell division. Gilman et al., Goodman and Gilman’s: The Pharmacological Basis of Therapeutics, Tenth Ed. (McGraw Hill, New York).
Despite availability of a variety of chemotherapeutic agents, chemotherapy has many drawbacks. Stockdale, Medicine, vol. 3, Rubenstein and Federman, eds., ch. 12, sect. 10, 1998. Almost all chemotherapeutic agents are toxic, and chemotherapy causes significant, and often dangerous side effects including severe nausea, bone marrow depression, and immunosuppression. Additionally, even with administration of combinations of chemotherapeutic agents, many tumor cells are resistant or develop resistance to the chemotherapeutic agents. In fact, those cells resistant to the particular chemotherapeutic agents used in the treatment protocol often prove to be resistant to other drugs, even if those agents act by different mechanism from those of the drugs used in the specific treatment. This phenomenon is referred to as pleiotropic drug or multidrug resistance. Because of the drug resistance, many cancers prove refractory to standard chemotherapeutic treatment protocols.
Other diseases or conditions associated with, or characterized by, undesired angiogenesis are also difficult to treat. However, some compounds such as protamine, hepain and steroids have been proposed to be useful in the treatment of certain specific diseases. Taylor et al., Nature 297:307 (1982); Folkman et al., Science 221:719 (1983); and U.S. Pat. Nos. 5,001,116 and 4,994,443. Thalidomide and certain derivatives of it have also been proposed for the treatment of such diseases and conditions. U.S. Pat. Nos. 5,593,990, 5,629,327, 5,712,291, 6,071,948 and 6,114,355 to D’Amato.
Still, there is a significant need for safe and effective methods of treating, preventing and managing cancer and other diseases and conditions, particularly for diseases that are refractory to standard treatments, such as surgery, radiation therapy, chemotherapy and hormonal therapy, while reducing or avoiding the toxicities and/or side effects associated with the conventional therapies.
2.3 IMIDS™
A number of studies have been conducted with the aim of providing compounds that can safely and effectively be used to treat diseases associated with abnormal production of TNF-α See, e.g., Marriott, J. B., et al., Expert Opin. Biol. Ther. 1(4):1-8 (2001); G. W. Muller, et al., Journal of Medicinal Chemistry 39(17): 3238-3240 (1996); and G. W. Muller, et al, Bioorganic & Medicinal Chemistry Letters 8: 2669-2674 (1998). Some studies have focused on a group of compounds selected for their capacity to potently inhibit TNF-α production by LPS stimulated PBMC. L. G. Corral, et al., Ann. Rheum. Dis. 58:(Suppl I) 1107-1113 (1999). These compounds, which are referred to as IMiDS™ (Celgene Corporation) or Immunomodulatory Drugs, show not only potent inhibition of TNF-α but also marked inhibition of LPS induced monocyte IL1β and IL12 production. LPS induced IL6 is also inhibited by immunomodulatory compounds, albeit partially. These compounds are potent stimulators of LPS induced IL10. Id. Particular examples of IMiD™s include, but are not limited to, the substituted 2-(2,6-dioxopiperidin-3-yl) phthalimides and substituted 2-(2,6-dioxopiperidin-3-yl)-1-oxoisoindoles described in U.S. Pat. Nos. 6,281,230 and 6,316,471, both to G. W. Muller, et al.
3. SUMMARY OF THE INVENTION
This invention encompasses methods of treating and preventing certain types of cancer, including primary and metastatic cancer, as well as cancers that are refractory or resistant to conventional chemotherapy. The methods comprise administering to a patient in need of such treatment or prevention a therapeutically or prophylactically effective amount of an immunomodulatory compound, or a pharmaceutically acceptable salt, solvate, hydrate, stereoisomer, clathrate, or prodrug thereof. The invention also encompasses methods of managing certain cancers (e.g., preventing or prolonging their recurrence, or lengthening the time of remission) which comprise administering to a patient in need of such management a prophylactically effective amount of an immunomodulatory compound of the invention, or a pharmaceutically acceptable salt, solvate, hydrate, stereoisomer, clathrate, or prodrug thereof.
In particular methods of the invention, an immunomodulatory compound is administered in combination with a therapy conventionally used to treat, prevent or manage cancer. Examples of such conventional therapies include, but are not limited to, surgery, chemotherapy, radiation therapy, hormonal therapy, biological therapy and immunotherapy.
This invention also encompasses methods of treating, managing or preventing diseases and disorders other than cancer that are associated with, or characterized by, undesired angiogenesis, which comprise administering to a patient in need of such treatment, management or prevention a therapeutically or prophylactically effective amount of an immunomodulatory compound, or a pharmaceutically acceptable salt, solvate, hydrate, stereoisomer, clathrate, or prodrug thereof.
In other methods of the invention, an immunomodulatory compound is administered in combination with a therapy conventionally used to treat, prevent or manage diseases or disorders associated with, or characterized by, undesired angiogenesis. Examples of such conventional therapies include, but are not limited to, surgery, chemotherapy, radiation therapy, hormonal therapy, biological therapy and immunotherapy.
This invention encompasses pharmaceutical compositions, single unit dosage forms, dosing regimens and kits which comprise an immunomodulatory compound, or a pharmaceutically acceptable salt, solvate, hydrate, stereoisomer, clathrate, or prodrug thereof, and a second, or additional, active agent. Second active agents include specific combinations, or “cocktails,” of drugs.
4. BRIEF DESCRIPTION OF FIGURE
FIG. 1 shows a comparison of the effects of 3-(4-amino-1-oxo-1,3-dihydro-isoindol-2-yl)-piperidine-2,6-dione (Revimid™) and thalidomide in inhibiting the proliferation of multiple myeloma (MM) cell lines in an in vitro study. The uptake of [3H]-thymidine by different MM cell lines (MM. 1S, Hs Sultan, U266 and RPMI-8226) was measured as an indicator of the cell proliferation.
5. DETAILED DESCRIPTION OF THE INVENTION
A first embodiment of the invention encompasses methods of treating, managing, or preventing cancer which comprises administering to a patient in need of such treatment or prevention a therapeutically or prophylactically effective amount of an immunomodulatory compound of the invention, or a pharmaceutically acceptable salt, solvate, hydrate, stereoisomer, clathrate, or prodrug thereof.
In particular methods encompassed by this embodiment, the immunomodulatory compound is administered in combination with another drug (“second active agent”) or method of treating, managing, or preventing cancer. Second active agents include small molecules and large molecules (e.g., proteins and antibodies), examples of which are provided herein, as well as stem cells. Methods, or therapies, that can be used in combination with the administration of the immunomodulatory compound include, but are not limited to, surgery, blood transfusions, immunotherapy, biological therapy, radiation therapy, and other non-drug based therapies presently used to treat, prevent or manage cancer.
Another embodiment of the invention encompasses methods of treating, managing or preventing diseases and disorders other than cancer that are characterized by undesired angiogenesis. These methods comprise the administration of a therapeutically or prophylactically effective amount of an immunomodulatory compound, or a pharmaceutically acceptable salt, solvate, hydrate, stereoisomer, clathrate, or prodrug thereof.
Examples of diseases and disorders associated with, or characterized by, undesired angiogenesis include, but are not limited to, inflammatory diseases, autoimmune diseases, viral diseases, genetic diseases, allergic diseases, bacterial diseases, ocular neovascular diseases, choroidal neovascular diseases, retina neovascular diseases, and rubeosis (neovascularization of the angle).
In particular methods encompassed by this embodiment, the immunomodulatory compound is administer in combination with a second active agent or method of treating, managing, or preventing the disease or condition. Second active agents include small molecules and large molecules (e.g., proteins and antibodies), examples of which are provided herein, as well as stem cells. Methods, or therapies, that can be used in combination with the administration of the immunomodulatory compound include, but are not limited to, surgery, blood transfusions, immunotherapy, biological therapy, radiation therapy, and other non-drug based therapies presently used to treat, prevent or manage disease and conditions associated with, or characterized by, undesired angiogenesis.
The invention also encompasses pharmaceutical compositions (e.g., single unit dosage forms) that can be used in methods disclosed herein. Particular pharmaceutical compositions comprise an immunomodulatory compound of the invention, or a pharmaceutically acceptable salt, solvate, hydrate, stereoisomer, clathrate, or prodrug thereof, and a second active agent.
5.1 Immunomodulatory Compounds
Compounds used in the invention include immunomodulatory compounds that are racemic, stereomerically enriched or stereomerically pure, and pharmaceutically acceptable salts, solvates, hydrates, stereoisomers, clathrates, and prodrugs thereof. Preferred compounds used in the invention are small organic molecules having a molecular weight less than about 1,000 g/mol, and are not proteins, peptides, oligonucleotides, oligosaccharides or other macromolecules.
As used herein and unless otherwise indicated, the terms “immunomodulatory compounds” and “IMiDs™” (Celgene Corporation) encompasses small organic molecules that markedly inhibit TNF-α, LPS induced monocyte IL1β and IL12, and partially inhibit IL6 production. Specific immunomodulatory compounds are discussed below.
TNF-α is an inflammatory cytokine produced by macrophages and monocytes during acute inflammation. TNF-α is responsible for a diverse range of signaling events within cells. TNF-α may play a pathological role in cancer. Without being limited by theory, one of the biological effects exerted by the immunomodulatory compounds of the invention is the reduction of synthesis of TNF-α. Immunomodulatory compounds of the invention enhance the degradation of TNF-αmRNA.
Further, without being limited by theory, immunomodulatory compounds used in the invention may also be potent co-stimulators of T cells and increase cell proliferation dramatically in a dose dependent manner. Immunomodulatory compounds of the invention may also have a greater co-stimulatory effect on the CD8+ T cell subset than on the CD4+ T cell subset. In addition, the compounds preferably have anti-inflammatory properties, and efficiently co-stimulate T cells.
Specific examples of immunomodulatory compounds of the invention, include, but are not limited to, cyano and carboxy derivatives of substituted styrenes such as those disclosed in U.S. Pat. No. 5,929,117; 1-oxo-2-(2,6-dioxo-3-fluoropiperidin-3-yl) isoindolines and 1,3-dioxo-2-(2,6-dioxo-3-fluoropiperidine-3-yl) isoindolines such as those described in U.S. Pat. No. 5,874,448; the tetra substituted 2-(2,6-dioxopiperdin-3-yl)-1-oxoisoindolines described in U.S. Pat. No. 5,798,368; 1-oxo and 1,3-dioxo-2-(2,6-dioxopiperidin-3-yl) isoindolines (e.g., 4-methyl derivatives of thalidomide and EM-12), including, but not limited to, those disclosed in U.S. Pat. No. 5,635,517; and a class of non-polypeptide cyclic amides disclosed in U.S. Pat. Nos. 5,698,579 and 5,877,200; analogs and derivatives of thalidomide, including hydrolysis products, metabolites, derivatives and precursors of thalidomide, such as those described in U.S. Pat. Nos. 5,593,990, 5,629,327, and 6,071,948 to D’Amato; aminothalidomide, as well as analogs, hydrolysis products, metabolites, derivatives and precursors of aminothalidomide, and substituted 2-(2,6-dioxopiperidin-3-yl) phthalimides and substituted 2-(2,6-dioxopiperidin-3-yl)-1-oxoisoindoles such as those described in U.S. Pat. Nos. 6,281,230 and 6,316,471; isoindole-imide compounds such as those described in U.S. patent application Ser. No. 09/972,487 filed on Oct. 5, 2001, U.S. patent application Ser. No. 10/032,286 filed on Dec. 21, 2001, and International Application No. PCT/US01/50401 (International Publication No. WO 02/059106). The entireties of each of the patents and patent applications identified herein are incorporated herein by reference. Immunomodulatory compounds of the invention do not include thalidomide.
Other specific immunomodulatory compounds of the invention include, but are not limited to, 1-oxo- and 1,3 dioxo-2-(2,6-dioxopiperidin-3-yl) isoindolines substituted with amino in the benzo ring as described in U.S. Pat. No. 5,635,517 which is incorporated herein by reference. These compounds have the structure I:

in which one of X and Y is C═O, the other of X and Y is C═O or CH2, and R2 is hydrogen or lower alkyl, in particular methyl. Specific immunomodulatory compounds include, but are not limited to:
Other specific immunomodulatory compounds of the invention belong to a class of substituted 2-(2,6-dioxopiperidin-3-yl) phthalimides and substituted 2-(2,6-dioxopiperidin-3-yl)-1-oxoisoindoles, such as those described in U.S. Pat. Nos. 6,281,230; 6,316,471; 6,335,349; and 6,476,052, and International Patent Application No. PCT/US97/13375 (International Publication No. WO 98/03502), each of which is incorporated herein by reference. Compounds representative of this class are of the formulas:

wherein R1 is hydrogen or methyl. In a separate embodiment, the invention encompasses the use of enantiomerically pure forms (e.g. optically pure (R) or (S) enantiomers) of these compounds.
Still other specific immunomodulatory compounds of the invention belong to a class of isoindole-imides disclosed in U.S. patent application Ser. Nos. 10/032,286 and 09/972,487, and International Application No. PCT/US01/50401 (International Publication No. WO 02/059106), each of which are incorporated herein by reference. Representative compounds are of formula II:

and pharmaceutically acceptable salts, hydrates, solvates, clathrates, enantiomers, diastereomers, racemates, and mixtures of stereoisomers thereof, wherein:
one of X and Y is C═O and the other is CH2 or C═O;
R1 is H, (C1-C8)alkyl, (C3-C7)cycloalkyl, (C2-C8)alkenyl, (C2-C8)alkynyl, benzyl, aryl, (C0-C4)alkyl-(C1-C6)heterocycloalkyl, (C0-C4)alkyl-(C2-C5)heteroaryl, C(O)R3, C(S)R3, C(O)OR4, (C1-C8)alkyl-N(R6)2, (C1-C8)alkyl-OR5, (C1-C8)alkyl-C(O)OR5, C(O)NHR3, C(S)NHR3, C(O)NR3R3′, C(S)NR3R3′ or (C1-C8)alkyl-O(CO)R5;
R2 is H, F, benzyl, (C1-C8)alkyl, (C2-C8)alkenyl, or (C2-C8)alkynyl;
R3 and R3′ are independently (C1-C8)alkyl, (C3-C7)cycloalkyl, (C2-C8)alkenyl, (C2-C8)alkynyl, benzyl, aryl, (C0-C4)alkyl(C1-C6)heterocycloalkyl, (C0-C4)alkyl-(C2-C5)heteroaryl, (C0-C8)alkyl-N(R6)2, (C1-C8)alkyl-OR5, (C1-C8)alkyl-C(O)OR5, (C1-C8)alkyl-O(CO)R5, or C(O)OR5;
R4 is (C1-C8)alkyl, (C2-C8)alkenyl, (C2-C8)alkynyl, (C1-C4)alkyl-OR5, benzyl, aryl, (C0-C4)alkyl-(C1-C6)heterocycloalkyl, or (C0-C4)alkyl-(C2-C5)heteroaryl;
R5 is (C1-C8)alkyl, (C2-C8)alkenyl, (C2-C8)alkynyl, benzyl, aryl, or (C2-C5)heteroaryl;
each occurrence of R6 is independently H, (C1-C8)alkyl, (C2-C8)alkenyl, (C2-C8)alkynyl, benzyl, aryl, (C2-C5)heteroaryl, or (C0-C8)alkyl-C(O)O—R5 or the R6groups can join to form a heterocycloalkyl group;
n is 0 or 1; and
* represents a chiral-carbon center.
In specific compounds of formula II, when n is 0 then R1 is (C3-C7)cycloalkyl, (C2-C8)alkenyl, (C2-C8)alkynyl, benzyl, aryl, (C0-C4)alkyl-(C1-C6)heterocycloalkyl, (C0-C4)alkyl-(C2-C5)heteroaryl, C(O)R3, C(O)OR4, (C1-C8)alkyl-N(R6)2, (C1-C8)alkyl-OR5, (C1-C8)alkyl-C(O)OR5, C(S)NHR3, or (C1-C8)alkyl O(CO)R5;
R2 is H or (C1-C8)alkyl; and
R3 is (C1-C8)alkyl, (C3-C7)cycloalkyl, (C2-C8)alkenyl, (C2-C8)alkynyl, benzyl, aryl, (C0-C4)alkyl-(C1-C6)heterocycloalkyl, (C0-C4)alkyl-(C2-C5)heteroaryl, (C5-C8)alkyl-N(R6)2; (C0-C8)alkyl-NH—C(O)O—R5; (C1-C8)alkyl-OR5, (C1-C8)alkyl-C(O)OR5, (C1-C8)alkyl-O(CO)R5, or C(O)OR5; and the other variables have the same definitions.
In other specific compounds of formula II, R2 is H or (C1-C4)alkyl.
In other specific compounds of formula II, R1 is (C1-C8)alkyl or benzyl.
In other specific compounds of formula II, R1 is H, (C1-C8)alkyl, benzyl, CH2OCH3, CH2CH2OCH3, or
In another embodiment of the compounds of formula II, R1 is

wherein Q is O or S, and each occurrence of R7 is independently H, (C1-C8)alkyl, benzyl, CH2OCH3, or CH2CH2OCH3.
In other specific compounds of formula II, R1 is C(O)R3.
In other specific compounds of formula II, R3 is (C0-C4)alkyl-(C2-C5)heteroaryl, (C1-C5)alkyl, aryl, or (C0-C4)alkyl-OR5.
In other specific compounds of formula II, heteroaryl is pyridyl, furyl, or thienyl.
In other specific compounds of formula II, R1 is C(O)OR4.
In other specific compounds of formula II, the H of C(O)NHC(O) can be replaced with (C1-C4)alkyl, aryl, or benzyl.
Still other specific immunomodulatory compounds of the invention belong to a class of isoindole-imides disclosed in U.S. patent application Ser. No. 09/781,179, International Publication No. WO 98/54170, and U.S. Pat. No. 6,395,754, each of which are incorporated herein by reference. Representative compounds are of formula III:

and pharmaceutically acceptable salts, hydrates, solvates, clathrates, enantiomers, diastereomers, racemates, and mixtures of stereoisomers thereof, wherein:
one of X and Y is C═O and the other is CH2 or C═O;
R is H or CH2OCOR′;
(i) each of R1, R2, R3, or R4, independently of the others, is halo, alkyl of 1 to 4 carbon atoms, or alkoxy of 1 to 4 carbon atoms or (ii) one of R1, R2, R3, or R4 is nitro or —NHR5 and the remaining of R1, R2, R3, or R4 are hydrogen;
R5 is hydrogen or alkyl of 1 to 8 carbons
R6 hydrogen, alkyl of 1 to 8 carbon atoms, benzo, chloro, or fluoro;
R′ is R7—CHR10—N(R8R9);
R7 is m-phenylene or p-phenylene or —(CnH2n)— in which n has a value of 0 to 4;
each of R8 and R9 taken independently of the other is hydrogen or alkyl of 1 to 8 carbon atoms, or R8 and R9 taken together are tetramethylene, pentamethylene, hexamethylene, or —CH2CH2[X]X1CH2CH2— in which [X]X1 is —O—, —S—, or —NH—;
R10 is hydrogen, alkyl of to 8 carbon atoms, or phenyl; and
* represents a chiral-carbon center.
The most preferred immunomodulatory compounds of the invention are 4-(amino)-2-(2,6-dioxo(3-piperidyl))-isoindoline-1,3-dione and 3-(4-amino-1-oxo-1,3-dihydro-isoindol-2-yl)-piperidine-2,6-dione. The compounds can be obtained via standard, synthetic methods (see e.g., U.S. Pat. No. 5,635,517, incorporated herein by reference). The compounds are available from Celgene Corporation, Warren, N.J. 4-(Amino)-2-(2,6-dioxo(3-piperidyl))-isoindoline-1,3-dione (ACTIMID™) has the following chemical structure:

The compound 3-(4-amino-1-oxo-1,3-dihydro-isoindol-2-yl)-piperidine-2,6-dione (REVIMID™) has the following chemical structure:

Compounds of the invention can either be commercially purchased or prepared according to the methods described in the patents or patent publications disclosed herein. Further, optically pure compounds can be asymmetrically synthesized or resolved using known resolving agents or chiral columns as well as other standard synthetic organic chemistry techniques.
As used herein and unless otherwise indicated, the term “pharmaceutically acceptable salt” encompasses non-toxic acid and base addition salts of the compound to which the term refers. Acceptable non-toxic acid addition salts include those derived from organic and inorganic acids or bases know in the art, which include, for example, hydrochloric acid, hydrobromic acid, phosphoric acid, sulfuric acid, methanesulphonic acid, acetic acid, tartaric acid, lactic acid, succinic acid, citric acid, malic acid, maleic acid, sorbic acid, aconitic acid, salicylic acid, phthalic acid, embolic acid, enanthic acid, and the like.
Compounds that are acidic in nature are capable of forming salts with various pharmaceutically acceptable bases. The bases that can be used to prepare pharmaceutically acceptable base addition salts of such acidic compounds are those that form non-toxic base addition salts, i.e., salts containing pharmacologically acceptable cations such as, but not limited to, alkali metal or alkaline earth metal salts and the calcium, magnesium, sodium or potassium salts in particular. Suitable organic bases include, but are not limited to, N,N-dibenzylethylenediamine, chloroprocaine, choline, diethanolamine, ethylenediamine, meglumaine (N-methylglucamine), lysine, and procaine.
As used herein and unless otherwise indicated, the term “prodrug” means a derivative of a compound that can hydrolyze, oxidize, or otherwise react under biological conditions (in vitro or in vivo) to provide the compound. Examples of prodrugs include, but are not limited to, derivatives of immunomodulatory compounds of the invention that comprise biohydrolyzable moieties such as biohydrolyzable amides, biohydrolyzable esters, biohydrolyzable carbamates, biohydrolyzable carbonates, biohydrolyzable ureides, and biohydrolyzable phosphate analogues. Other examples of prodrugs include derivatives of immunomodulatory compounds of the invention that comprise —NO, —NO2, —ONO, or —ONO2 moieties. Prodrugs can typically be prepared using well-known methods, such as those described in 1 Burger’s Medicinal Chemistry and Drug Discovery, 172-178, 949-982 (Manfred E. Wolff ed., 5th ed. 1995), and Design of Prodrugs (H. Bundgaard ed., Elselvier, N.Y. 1985).
As used herein and unless otherwise indicated, the terms “biohydrolyzable amide,” “biohydrolyzable ester,” “biohydrolyzable carbamate,” “biohydrolyzable carbonate,” “biohydrolyzable ureide,” “biohydrolyzable phosphate” mean an amide, ester, carbamate, carbonate, ureide, or phosphate, respectively, of a compound that either: 1) does not interfere with the biological activity of the compound but can confer upon that compound advantageous properties in vivo, such as uptake, duration of action, or onset of action; or 2) is biologically inactive but is converted in vivo to the biologically active compound. Examples of biohydrolyzable esters include, but are not limited to, lower alkyl esters, lower acyloxyalkyl esters (such as acetoxylmethyl, acetoxyethyl, aminocarbonyloxymethyl, pivaloyloxymethyl, and pivaloyloxyethyl esters), lactonyl esters (such as phthalidyl and thiophthalidyl esters), lower alkoxyacyloxyalkyl esters (such as methoxycarbonyl-oxymethyl, ethoxycarbonyloxyethyl and isopropoxycarbonyloxyethyl esters), alkoxyalkyl esters, choline esters, and acylamino alkyl esters (such as acetamidomethyl esters). Examples of biohydrolyzable amides include, but are not limited to, lower alkyl amides, α-amino acid amides, alkoxyacyl amides, and alkylaminoalkylcarbonyl amides. Examples of biohydrolyzable carbamates include, but are not limited to, lower alkylamines, substituted ethylenediamines, amino acids, hydroxyalkylamines, heterocyclic and heteroaromatic amines, and polyether amines.
Various immunomodulatory compounds of the invention contain one or more chiral centers, and can exist as racemic mixtures of enantiomers or mixtures of diastereomers. This invention encompasses the use of stereomerically pure forms of such compounds, as well as the use of mixtures of those forms. For example, mixtures comprising equal or unequal amounts of the enantiomers of a particular immunomodulatory compounds of the invention may be used in methods and compositions of the invention. These isomers may be asymmetrically synthesized or resolved using standard techniques such as chiral columns or chiral resolving agents. See, e.g., Jacques, J., et al., Enantiomers, Racemates and Resolutions(Wiley-Interscience, New York, 1981); Wilen, S. H., et al., Tetrahedron 33:2725 (1977); Eliel, E. L., Stereochemistry of Carbon Compounds (McGraw-Hill, N.Y., 1962); and Wilen, S. H., Tables of Resolving Agents and Optical Resolutions p. 268 (E. L. Eliel, Ed., Univ. of Notre Dame Press, Notre Dame, Ind., 1972).
As used herein and unless otherwise indicated, the term “stereomerically pure” means a composition that comprises one stereoisomer of a compound and is substantially free of other stereoisomers of that compound. For example, a stereomerically pure composition of a compound having one chiral center will be substantially free of the opposite enantiomer of the compound. A stereomerically pure composition of a compound having two chiral centers will be substantially free of other diastereomers of the compound. A typical stereomerically pure compound comprises greater than about 80% by weight of one stereoisomer of the compound and less than about 20% by weight of other stereoisomers of the compound, more preferably greater than about 90% by weight of one stereoisomer of the compound and less than about 10% by weight of the other stereoisomers of the compound, even more preferably greater than about 95% by weight of one stereoisomer of the compound and less than about 5% by weight of the other stereoisomers of the compound, and most preferably greater than about 97% by weight of one stereoisomer of the compound and less than about 3% by weight of the other stereoisomers of the compound. As used herein and unless otherwise indicated, the term “stereomerically enriched” means a composition that comprises greater than about 60% by weight of one stereoisomer of a compound, preferably greater than about 70% by weight, more preferably greater than about 80% by weight of one stereoisomer of a compound. As used herein and unless otherwise indicated, the term “enantiomerically pure” means a stereomerically pure composition of a compound having one chiral center. Similarly, the term “stereomerically enriched” means a stereomerically enriched composition of a compound having one chiral center.
It should be noted that if there is a discrepancy between a depicted structure and a name given that structure, the depicted structure is to be accorded more weight. In addition, if the stereochemistry of a structure or a portion of a structure is not indicated with, for example, bold or dashed lines, the structure or portion of the structure is to be interpreted as encompassing all stereoisomers of it.
5.2 Second Active Agents
Immunomodulatory compounds can be combined with other pharmacologically active compounds (“second active agents”) in methods and compositions of the invention. It is believed that certain combinations work synergistically in the treatment of particular types of cancer and certain diseases and conditions associated with, or characterized by, undesired angiogenesis. Immunomodulatory compounds can also work to alleviate adverse effects associated with certain second active agents, and some second active agents can be used to alleviate adverse effects associated with immunomodulatory compounds.
One or more second active ingredients or agents can be used in the methods and compositions of the invention together with an immunomodulatory compound. Second active agents can be large molecules (e.g., proteins) or small molecules (e.g., synthetic inorganic, organometallic, or organic molecules).
Examples of large molecule active agents include, but are not limited to, hematopoietic growth factors, cytokines, and monoclonal and polyclonal antibodies. Typical large molecule active agents are biological molecules, such as naturally occurring or artificially made proteins. Proteins that are particularly useful in this invention include proteins that stimulate the survival and/or proliferation of hematopoietic precursor cells and immunologically active poietic cells in vitro or in vivo. Others stimulate the division and differentiation of committed erythroid progenitors in cells in vitro or in vivo. Particular proteins include, but are not limited to: interleukins, such as IL-2 (including recombinant IL-II (“rIL2”) and canarypox IL-2), IL-10, IL-12, and IL-18; interferons, such as interferon alfa-2a, interferon alfa-2b, interferon alfa-n1, interferon alfa-n3, interferon beta-I a, and interferon gamma-I b; GM-CF and GM-CSF; and EPO.
Particular proteins that can be used in the methods and compositions of the invention include, but are not limited to: filgrastim, which is sold in the United States under the trade name Neupogen® (Amgen, Thousand Oaks, Calif.); sargramostim, which is sold in the United States under the trade name Leukine® (Immunex, Seattle, Wash.); and recombinant EPO, which is sold in the United States under the trade name Epogen® (Amgen, Thousand Oaks, Calif.).
Recombinant and mutated forms of GM-CSF can be prepared as described in U.S. Pat. Nos. 5,391,485; 5,393,870; and 5,229,496; all of which are incorporated herein by reference. Recombinant and mutated forms of G-CSF can be prepared as described in U.S. Pat. Nos. 4,810,643; 4,999,291; 5,528,823; and 5,580,755; all of which are incorporated herein by reference.
This invention encompasses the use of native, naturally occurring, and recombinant proteins. The invention further encompasses mutants and derivatives (e.g., modified forms) of naturally occurring proteins that exhibit, in vivo, at least some of the pharmacological activity of the proteins upon which they are based. Examples of mutants include, but are not limited to, proteins that have one or more amino acid residues that differ from the corresponding residues in the naturally occurring forms of the proteins. Also encompassed by the term “mutants” are proteins that lack carbohydrate moieties normally present in their naturally occurring forms (e.g., nonglycosylated forms). Examples of derivatives include, but are not limited to, pegylated derivatives and fusion proteins, such as proteins formed by fusing IgG1 or IgG3 to the protein or active portion of the protein of interest. See, e.g., Penichet, M. L. and Morrison, S. L., J. Immunol. Methods 248:91-101 (2001).
Antibodies that can be used in combination with compounds of the invention include monoclonal and polyclonal antibodies. Examples of antibodies include, but are not limited to, trastuzumab (Herceptin®), rituximab (Rituxan®), bevacizumab (Avastin™), pertuzumab (Omnitarg™), tositumomab (Bexxar®), edrecolomab (Panorex®), and G250. Compounds of the invention can also be combined with, or used in combination with, anti-TNF-α antibodies.
Posted in Drug Development Process, Drug Discovery Chemistry, drug repurposing, Pharmaceutical Drug Discovery on February 14, 2019| Leave a Comment »
Reporter: Aviva Lev-Ari, PhD, RN and Irina Robu, PhD
CLAIMER: most valuable information for Drug Repurposing is found in the following LPBI Group three Intellectual Property Asset Classes
Our intellectual property “IP” consists of three classes of assets as described in detail within live links in the below, listed article.
- First, the Journal, an ongoing journal of curated, current biomedical research;
- Second, the books, a collection of 16 volumes of e-books available via Amazon in five specialties of Medicine: Cardiovascular, Genomics, Cancer, Immunology and Precision Medicine; and
- Third, real-time curation of biotech and medical conferences yielding an e-Proceedings at the end of the conference in One-click operation.
These three IP asset classes are described in details with live links in
eScientific Publishing a Case in Point: Evolution of Platform Architecture Methodologies and of Intellectual Property Development (Content Creation by Curation) Business Model
M Corsello, Steven & A Bittker, Joshua & Liu, Zihan & Gould, Joshua & McCarren, Patrick & E Hirschman, Jodi & E Johnston, Stephen & Vrcic, Anita & Wong, Bang & Khan, Mariya & Asiedu, Jacob & Narayan, Rajiv & C Mader, Christopher & Subramanian, Aravind & R Golub, Todd. (2017). The Drug Repurposing Hub: A next-generation drug library and information resource. Nature Medicine. 23. 405-408. 10.1038/nm.4306.
… Published on January 3, 2018 as DOI: 10.1124/mol.117. Downloaded from additional source, we used data from the Broad repurposing hub ( Corsello et al, 2017), which employed high throughput screening to characterize drug-target interactions of approved drugs, natural products and nutraceuticals along with other entities. Our analysis yielded a list of currently ‘druggable’ GPCRs and the drugs that target them. …… Using a range of ~500 (conservative estimate) to ~700 GPCR-targeted drugs, we estimate that between ~25% and ~36% of approved drugs target GPCRs, with the upper figure the more likely. As additional studies such as the Broad repurposing initiative ( Corsello et al, 2017) characterize GPCR-drug interactions in more detail, we anticipate a growth in this number, as secondary interactions between GPCRs and drugs are defined ( Allen and Roth, 2011). IUPHAR lists more druggable GPCRs than CHEMBL or DRUGBANK but has the smallest number of GPCR-related and overall approved drugs ( Figure 3C shows the number of GPCR-targeted drugs based on target-ligand interactions annotated by either IUPHAR or CHEMBL; of the 476 such drugs listed in one or both sources, only a portion are common to both (50%). …
To date there has not been a systematic effort to identify such opportunities, limited in part by the lack of a comprehensive library of clinical compounds suitable for testing. To address this challenge, we hand-curated a collection of 4,707 compounds, experimentally confirmed their identity, and annotated them with literature-reported targets. The collection includes 3,422 drugs that are marketed around the world or that have been tested in human clinical trials. Compounds were obtained from more than 50 chemical vendors and the purity of each sample was established. We have thus established a blueprint for others to easily assemble such a repurposing library, and we have created an online Drug Repurposing Hub (www.broadinstitute.org/repurposing) containing detailed annotation for each of the compounds.
SOURCE
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5568558/