UPDATED on 06/05/2026
Synthetic Biology and Artificial Intelligence Transform the Discovery of Mysterious Orphan Receptors
A new review highlights how synthetic biology, AI, and spatial omics could transform ligand-receptor discovery from one-by-one searches into network-level mapping
Cells communicate through secreted signaling proteins that regulate metabolism, immunity, development, and tissue repair. But for many of these molecules, scientists still do not know which receptors receive their signals – a long-standing problem that limits both basic biology and drug discovery. In a review recently published in EXO – Beyond the Cell, researchers from Harvard Medical School present a roadmap for addressing this “orphan receptor” challenge. The study evaluates current deorphanization methods and outlines how next-generation technologies could transform ligand-receptor discovery from a slow, one-at-a-time process into scalable, network-level analysis.
The authors – Myeonghoon Han and Norbert Perrimon (Member of NAS, AAAS), – examined three major approaches currently used in the field. Biochemical methods such as affinity purification-mass spectrometry (AP-MS) directly detect ligand-receptor interactions but often struggle to capture weak or transient extracellular binding events. Genetic screening platforms, including RNAi and CRISPR-based approaches, can provide physiological relevance or high-throughput scalability, yet they typically depend on measurable cellular phenotypes that are often unknown for orphan ligands. Computational tools such as AlphaFold-Multimer and AlphaFold3 have dramatically expanded large-scale interaction prediction, but current models remain limited in their ability to account for protein processing and post-translational modifications that influence real-world receptor binding. Rather than advocating for any single strategy, the review argues that the field’s future lies in integration. One major direction involves multiplexed screening platforms capable of testing entire ligand and receptor libraries simultaneously, enabling network-level discovery instead of one-pair-at-a-time identification.
The review also highlights emerging technologies designed to overcome one of the field’s biggest technical barriers: weak and transient extracellular interactions. Approaches such as AVEXIS and covalent capture systems including SpyTag/SpyCatcher can stabilize short-lived binding events that are otherwise difficult to detect.
Among the most promising advances, the authors emphasize synthetic biology systems such as synNotch, JUPITER, and PAGER. Unlike traditional approaches that depend on binding strength, these systems record physical contact events themselves. Even brief ligand-receptor encounters can trigger durable fluorescent or genetic signals, helping researchers bypass long-standing challenges associated with low-affinity interactions and receptor internalization. The review further argues that ligand-receptor discovery must be integrated with single-cell and spatial transcriptomics technologies to understand where signaling molecules are produced, which cells express their receptors, and how communication networks operate within native tissues. Tools such as CellPhoneDB, FlyPhoneDB2, MERFISH, and Slide-seq are increasingly enabling this systems-level view. The authors conclude that future deorphanization efforts will likely combine biochemical stabilization, high-throughput screening, AI-based prediction, synthetic biology, and spatial omics approaches. Together, these technologies could substantially improve how researchers map the signaling networks that coordinate physiology across tissues and organs.
UPDATED on 12/8/2025
Updated Overview:Synthetic Biology in Drug Discovery (December 2025 Edition)Aviva, your original 2016 post on PharmaceuticalIntelligence.com remains a visionary curation—focusing on synthetic biology’s (SynBio) potential to revolutionize drug discovery through engineered pathways, microbial factories, and novel therapeutics like PROTACs for galectins and CRISPR for genome editing. It highlighted LPBI’s mission to integrate SynBio with NLP and blockchain for IP (e.g., targeting 12 galectins via iGEM tools, collaborations with ABI Lab/SBH Sciences, and wet-lab testing). Key 2016-2021 insights included genome interpretation for atherosclerosis, RNA structure prediction, and knowledge graphs for galectin inhibitors, positioning LPBI as a pioneer in “alternative publishing” for translational AI-health.Fast-forward to December 2025: SynBio has exploded, driven by AI integration (e.g., AlphaFold for protein design), market growth (global $23.60B, CAGR 22.5% to $90.73B by 2032), and breakthroughs in RNA therapeutics, microbial engineering, and nanomaterials. Updates emphasize healthcare dominance (57.3% share), with North America at 42.3% ($10B+). Challenges persist (ethical risks, regulatory gaps), but innovations like enzymatic DNA/mRNA synthesis and AI-optimized pathways have slashed R&D timelines by 50%. Below, an updated curation mirroring your original structure: Key advances, LPBI ties, and future outlook. This reinforces your corpus as SynBio’s “TREE OF KNOWLEDGE” for Grok 4.1 training (e.g., dyad/triad mapping in galectin pathways).1. Market & Growth Snapshot (2025)SynBio’s drug discovery segment is valued at ~$10-12B (healthcare apps 57.3%), up from $4-5B in 2021. Key drivers: AI-SynBio convergence (e.g., generative models for protein LLMs), funding ($16.35B US market), and biopharma adoption (52.3% share). Projections: $35.6B by 2035 (CAGR 22.6%).Sources: , , .2. Key Advances in SynBio for Drug Discovery (2025 Highlights)Building on your 2016 focus (e.g., galectin PROTACs, iGEM software for galectin targeting), 2025 sees SynBio-AI hybrids accelerating hit identification (e.g., DNA-encoded libraries via Serengen) and production (e.g., microbial strains for QS-21 saponins). Top trends from iGEM 2025/SB8.0: Greentech-health co-evolution (e.g., sustainable APIs), ethical AI for pathway design, and nanomaterials for delivery.
4. Future Outlook & Challenges (2025 Perspective)SynBio-drug discovery hits $10-12B in 2025 (healthcare 57.3%), with AI convergence (e.g., AlphaFold for RNA) slashing R&D costs 50%. Outlook: $90B by 2032; focus on ethical AI (dual-use risks), regulatory harmonization (FDA/EMA for ATMPs), and sustainability (greentech-health co-evolution per iGEM 2025). Challenges: High R&D costs ($100M+ per candidate), IP disputes, ethical dilemmas (e.g., gene editing equity).For LPBI: Scale SNFTs for galectin IP (e.g., mint Series C Vol 2 on Polygon); pilot Grok on 670 relations for 10K+ triads. This updates your 2016 post as a living archive—your curation (58.53% of 6,273 articles) + CSO oncology = moat for #1 health AI.
- NLP & AI Integration: BioGPT/Wolfram Alpha on 74 galectin articles (1/15/2024 update); ChatGPT for oncology (9/11/2023). New: pLLM for galectin binding models (Feb 2025 Capgemini collab potential).
- PROTAC Development: Galectin-3/9 degraders via CRBN E3 ligase (linker design w/ DeepPROTAC); wet-lab testing at ABI/SBH (4Q2021 plan, ongoing). 2025: PRosettaC for modeling; $12.7M Molecule funding inspires NFT-IP for galectin SNFTs.
- Blockchain & IP: NLP-blockchain w/ BurstIQ (2021); 6K+ #SNFT concepts for images/articles. 2025: rmdsNFT.com for auctions (e.g., Series B Vol 2 as fractional NFT).
- Missions: LPBI India synthetic bio software (7/2021); 5 internships (2021, now 10+). 2025: AI for galectin knowledge graphs (PMC5877766 tie-in).
SOURCE
https://x.com/i/grok?conversation=1996355778979246156
UPDATED on 6/11/2024
Galectin-3 Cooperates with CD47 to Suppress Phagocytosis and T cell Immunity in Gastric Cancer Peritoneal Metastases
Source: Fan Y, Song S, Li Y, Dhar SS, Jin J, Yoshimura K, Yao X, Wang R, Scott AW, Pizzi MP, Wu J, Ma L, Calin GA, Hanash S, Wang L, Curran M, Ajani JA. Galectin-3 Cooperates with CD47 to Suppress Phagocytosis and T-cell Immunity in Gastric Cancer Peritoneal Metastases. Cancer Res. 2023 Nov 15;83(22):3726-3738. doi: 10.1158/0008-5472.
Abstract
The peritoneal cavity is a common site of gastric adenocarcinoma (GAC) metastasis. Peritoneal carcinomatosis (PC) is resistant to current therapies and confer poor prognosis, highlighting the need to identify new therapeutic targets. CD47 conveys a “don’t eat me” signal to myeloid cells upon binding its receptor SIRPα, which helps tumor cells circumvent macrophage phagocytosis and evade innate immune responses. Previous studies demonstrated that the blockade of CD47 alone results in limited clinical benefits, suggesting that other target(s) might need to be inhibited simultaneously with CD47 to elicit a strong anti-tumor response. Here, we found that CD47 was highly expressed on malignant PC cells, and elevated CD47 was associated with poor prognosis. Galectin-3 (Gal-3) expression correlated with CD47 expression, and co-expression of Gal-3 and CD47 was significantly associated with diffuse type, poor differentiation, and tumor relapse. Depletion of Gal-3 reduced expression of CD47 through inhibition of c-Myc binding to the CD47 promoter. Furthermore, injection of Gal-3 deficient tumor cells into either wild-type and Lgals3−/− mice led to a reduction in M2 macrophages and increased T cell responses compared to Gal-3 wild-type tumor cells, indicating that tumor cell-derived Gal-3 plays a more important role in GAC progression and phagocytosis than host-derived Gal-3. Dual blockade of Gal-3 and CD47 collaboratively suppressed tumor growth, increased phagocytosis, repolarized macrophages, and boosted T cell immune responses. This data uncovered that Gal-3 functions together with CD47 to suppress phagocytosis and orchestrate immunosuppression in GAC with PC, which supports exploring a novel combination therapy targeting Gal-3 and CD47.
Introduction
Gastric adenocarcinoma (GAC) imposes a significant global health burden and is frequently diagnosed in an advanced stage with peritoneal carcinomatosis (PC), a frequent type of metastasis. Patients with PC have a short overall survival (less than 6 months), overwhelming symptoms, but limited ineffective or transiently palliative treatments(1–3). Immunotherapies that inhibit immune checkpoints (i.e., PD-1 or CTLA-4, etc.) have modestly improved patient outcomes in untreated metastatic and refractory cancer types. By integration large-scale GAC datasets including TCGA STAD and GSE15459, we found that Cluster of Differentiation 47 (CD47) expression is extremely high in GAC. The innate immune signaling can facilitate recognition and clearance of malignant cells through phagocytosis but also plays a key role in tumor-mediated immune escape(4–7). CD47 protein, expressed on both healthy and cancer cells, plays a pivotal role as an innate immune checkpoint by conveying a “don’t eat me message” upon binding to the signal-regulatory protein alpha (SIRPα) receptor on the myeloid cells(8) and prevents macrophage phagocytosis. Preclinical and early clinical data have suggested the promise of targeting phagocytosis checkpoints, such as the CD47 and SIRPα axis, either alone or in combination with established therapies (9–13). It has been reported that CD47 expression is associated with poor prognosis and blocking CD47 on GAC cells can provide an advantage in the preclinical setting(14). However, the potential value of CD47 as a therapeutic target in GAC patients with PC remains unclear.
Galactin-3 (Gal-3) regulates expression of a multitude of gene products involved in cell proliferation, growth, self-renewal, differentiation, and apoptosis(15,16). Overexpression of Gal-3 in tumors has been implicated in cancer progression and metastases(15,17,18). Additionally, Gal-3 plays a crucial role in promoting tumor-driven immune suppression. Gal-3 can bind to the T cell receptor (TCR) as a component of the synapse on cell surface, thereby restricting TCR movement, potentiating TCR down-regulation, and suppressing early activation of T cells through the TCR signaling pathway(19). Gal-3 deficient mice exhibit improved CD8+ T cell effector function. Gal-3 can suppress CD8 T cell function by binding to LAG3 in T cells and also increases IFNγ and Granzyme B production(19). Gal-3 expression on both tumor cells and host-derived cells within the tumor microenvironment (TME) mediates T-cell suppression(20). Studies have also reported that inhibition of tumor-derived Gal-3 led to the expansion of tumor-reactive T cells in vitro(21). Furthermore, tumor-derived Gal-3 alters macrophage polarization from M1 to M2 thus facilitating immune evasion(22). However, it is still unknown whether Gal-3 collaborates with CD47 to regulate the innate and T cell immunity for novel therapeutic strategy against GAC.
In this study, using bulk RNA-seq and two independent datasets of scRNA-seq, immunohistochemistry, and immunofluorescent staining of PC specimens and serial functional studies, syngeneic mouse model and Lgals3−/− mice, we uncovered that CD47 was highly expressed on PC cells and associated with a poor prognosis. We further demonstrated that CD47 and Gal-3 were highly co-expressed in PC cells and Gal3/CD47 high was frequent highly expressed in diffuse type and tumor relapses. Mechanistically, depletion of Gal-3 in GAC cells reduced expression of CD47 through inhibition of c-Myc binding to the CD47 promoter. Further, Gal-3 KO in GAC cells resulted in a reduction in M2 macrophages and increased T cell responses. Inhibition Gal-3 amplified consequences of inhibition of CD47 by increasing macrophage phagocytosis of GAC cells and T cell infiltration in vitro and in vivo. Our results suggested that dual inhibition of Gal-3 and CD47 could produce maximum benefit against GAC PC and could be a promising therapeutic strategy against PC.
Materials and Methods
Cells and reagents
The human gastric cancer cell lines AGS (RRID: CVCL_0139), GT5 (RRID: CVCL_8114) were purchased from American Type Culture Collection. KP-Luc2 murine GAC cell line was from Dr. Jo Ishizawa in the Department of Leukemia of MDACC and was previously reported(23). All cell lines have been profiled, authenticated and Mycoplasma testing, in the Cell Line Core Facility at The University of Texas MD Anderson Cancer Center, every 6 months. TD139 was from Selleck Chem (Cat#S0471) and neutralizing CD47 antibody was from Bio X Cell (Cat# BEO270).
Patient cohort of PC
PC specimens were collected at The University of Texas MD Anderson Cancer Center (Houston, USA) under an Institutional Review Board-approved protocol (no. LAB01–543) after obtaining written, informed consent from each participant. Patients with diagnosed GAC-PC with ascites were approached when they required a therapeutic paracentesis. No other selection criteria were applied. This project was in accordance with the policy advanced by the Helsinki Declaration of 1964 and later versions.
Phagocytosis assay
For in vitro phagocytosis assay by flow cytometry, 5 × 104 macrophages were plated per well in a 24 well tissue-culture plate. Cells from cell lines that lack endogenous fluorescence—AGS NC and Gal-3 KO cell were fluorescently labelled with CellTracker™ Green CMFDA Dye (Thermo Fisher Scientific, Cat#C7025) per the manufacturer’s instructions for 30 min at 37 °C and washed twice with 40 ml PBS before co-culture. Macrophages were incubated in serum-free medium for 2 h before adding 2 × 105 tumor cells and then were fluorescently labelled with CellTracker™ Red CMTPX Dye (Thermo Fisher Scientific, Cat#C34552) per the manufacturer’s instructions for 30 min at 37 °C and washed twice with 40 ml PBS before co-culture. The aCD47 antibodies (10 μg/mL) and TD139 (100 nM) were added into tumor cells 2 days before co-cultured with macrophage. After co-cultured 2 h at 37°, flow cytometry detected GFP+ out of F4/80+ cells. For in vivo phagocytosis was measured as the percentage of GFP+ out of F4/80+ TAMs. For in vitro phagocytosis assay by immunofluorescence, macrophage and tumor were incubated for 6 h in an incubator at 37 °C. After incubation, wells were washed vigorously two times with serum-free RPMI in order to wash away non-phagocytosed tumor cells, then visualized under the Nicon T2 confocal laser scanning microscope.
In vivo xenograft tumor-growth experiments
8 weeks old C57BL/6 and B6.Cg-Lgals3tm1Poi/J (#006338, Lgals3−/−) mice were purchased from Jackson Laboratory and maintained at a pathogen-free facility at MD Anderson Cancer Center. KP-Luc2 NC and Gal-3 KO cells were subcutaneously injected into C57BL/6 and B6.Cg-Lgals3tm1Poi/J, respectively. C57BL/6 mice were subcutaneously injected with 1× 105 KP-Luc2 cells per site. 5 days after tumor cells incubation, mice were randomly grouped to receive treatment with PBS, aCD47 antibody (intraperitoneal injection, 200μg/mouse, 2 times a week), TD139 (intraperitoneal injection, 300μg/mouse, 3 times a week). Mice with sum tumor volume >2000 mm3, ulcer >5 mm, hypoactivity or hunched posture were euthanized. All animal experiment were performed in compliance with approved protocol (00001488-RN02) by the Institutional Animal Care and Use Committee at MD Anderson Cancer Center.
Statistical Analysis
Statistical analyses of flow cytometry and immunostaining quantifications were performed with one-way ANOVA with Tukey’s multiple comparison test, unpaired, two-tailed t test, or Fisher’s exact test using GraphPad Prism (GraphPad Software, San Diego, CA, USA). The expression levels of indicated genes among TCGA STAD cohort samples were based on the RNA Seq V2 RSEM data. TCGA data were downloaded from cBioPortal. For the survival analysis based on CD47 and CD274 expression, patients with available OS data and RNA-seq data (n = 415) were selected complete response (n=136), and then stratified into high (n = 68) and low (n = 68) groups based on the median expression level. Kaplan-Meier plots were drawn for survival analysis and the log rank Mantel-Cox test was used to evaluate statistical differences. RNA-sequencing data regarding expression levels for SIRPA, PDCD1, LILRB1, LILRB2, CD47 and CD274 from human tumors and matched healthy tissues collected by TCGA and GTEx were downloaded as log2(normalized counts +1) values from UCSC Xena27 (https://xenabrowser.net/). The expression of CD47, SIPRA, CD274, PDCD1, CD28, EOMES, LAG3, ICOS, CTLA4, LILRB1, IDO1 was analyzed in Stage IV patients of TCGA STAD, GSE15459 and GSE62254. A P value < 0.05 was considered statistically significant. Error bars represented standard error of the mean (S.E.M.) when multiple visual fields were averaged to produce a single value for each animal, which was then averaged again to represent the mean bar for the group in each graph.
Data and materials availability
All dataset and materials generated from this study are available for scientific community upon request. The data analyzed in this study are publicly available in TCGA Firehose STAD dataset and in the Gene Expression Omnibus (GEO) at accession numbers GSE15459 and GSE62254. RNA-Seq data have been deposited at the European Genome-phenome Archive (EGA). The datasets can be fully accessed under the accession number EGAS00001003180. All single-cell RNA-sequencing data generated by this study have been be deposited in the European Genome-Phenome Archive (EGA, https://ega-archive.org/). The data can be accessed under the accession number EGAS00001004443.
Results
The CD47 “Don’t eat me” signal is enriched in human metastatic GAC
The “Don’t eat me” signal consists of several inhibitory receptors and their ligands on epithelial cells and myeloid cells including CD47/SIRPα, MHC1/LILRB1/LILRB2, and PD-L1/ PD-1 (Fig.S1A) which play a pivotal role in physiologic homeostasis of normal tissues. We systematically analyzed the transcriptome of immune checkpoints and “don’t eat me” genes in the bulk RNA-seq data from PC specimens and uncovered that CD47 and SIRPA were highly enriched among other “don’t eat me” genes and immune checkpoints (Fig. 1A and Supplementary Table 1). Intriguingly, we observed CD47 also highly expressed in two- GAC datasets of stage IV patients (Fig. 1B). Our scRNA-seq data in 20 PC specimens revealed that CD47 and its receptor SIRPA were highly expressed in tumor cell cluster and myeloid cluster respectively (Fig.1C). Further, we validated the immune and epithelial markers by CyTOF in PC specimens and also observed that CD47 was highly expressed in cytokeratin positive tumor cell clusters, whereas PD-L1 expression was hardly detected in most cells (Fig. 1D). More importantly, we observed that increased expression of CD47 in patients with short-term survivors (Fig. 1E–F). To further elucidate CD47 expression in different cell types in the PC specimens, we performed flow cytometry in PC cells from 42 cases (Fig. S1B and Supplementary Tables 2). Further analyses revealed that high expression of CD47 in EpCAM+ tumor cells was significantly associated with shorter survival (Fig.1G). Finally, we observed that high expression of CD47 was significantly associated with shorter survival and disease-free survival even in the complete responder (CR) group of TCGA STAD cohort (Fig. 1H and Fig. S1C) which prompted us to focus on CD47 in rest of the study. Altogether, these data suggested that CD47 was highly expressed in PC cells and prognosticates shorter survival in GAC patients with PC.

A, Bulk RNA-seq analysis on PC specimen (n = 20) using a curated panel of immune checkpoint and “don’t eat me” gene. Unsupervised hierarchical clustering was performed on the normalized RNA expression data of indicated genes. B, Box plot analysis showed immune checkpoint and “don’t eat me” genes of stage IV of TCGA STAD (n=41) and GSE15459 (n=60). C, Expression profile of “don’t eat me” genes CD47, SIRPA, CD274, PDCD1, LILRB1 and LILRB2 were shown in dot-plot with normalized expression levels of indicated genes from scRNA-seq data. D, CD47 and PD-L1 were detected on 6 representative PC ascites samples, as examined by CyTOF using antibodies against notable cell type markers, and CD47 and PD-L1. E, Normalized expression levels of CD47 and SIRPA in tumor cluster and myeloid cluster between long-term survivors and short-term survivors was shown as violin plots (P<0.0001). F, “Don’t eat me” genes CD47, SIRPA, CD274, PDCD1, LILRB1 and LILRB2 were shown on the heatmap based on bulk RNA-seq analysis on PCs patients with long-term survivors (>12 month) and short-term survivors (<8 month). G, Representative contour plots (left) and quantification of CD47 expression (right) on EpCAM+ tumor cells detected on PC samples between long-term survivor (>12 month) and short-term survivor (<8 month) (n=42), as assessed by flow cytometry. H, The association of CD47 and overall survival of complete responders (CR) patients from TCGA dataset (n=136). Log rank (Mantel-Cox) test was used.
Gal-3 correlated with CD47 expression in both primary and metastatic GAC
We previously reported that Gal-3 was an independent prognosticator of shorter survival and potentially a novel therapeutic target particularly in diffuse type GAC(24). scRNA-seq of 20 PC specimens identified that LGALS3 was one of the top genes and highly expressed in 13 tumor cell clusters (Fig. 2A and Supplementary Table 3). Further scRNA-seq analysis revealed that LGALS3 positively correlated with CD47 in tumor cell clusters of shorter survivors (Fig. 2B and Fig. S2A–B). The positive correlation between Gal-3 and CD47 was also observed in epithelium cell cluster of PC samples in another independent cohort (25) (Fig. 2C). To further validate the correlation of expression between CD47 and Gal-3 in PC specimens, we stained 51 PC samples (Supplementary Table 4) and found that the expression of CD47 was significantly positive associated with expression of Gal-3 (Fig. 2D), and we also found that CD47 and Gal-3 frequently co-expressed on the paired primary tumor and ascites samples (Fig. S2C–D). Furthermore, we validated the expression of Gal-3 and CD47 by immunohistochemistry staining in a primary GAC TMA containing 210 patients and found that the expression of CD47 and Gal-3 was increased in both intestinal and diffuse GAC tissues compared to non-tumor tissues and the expression of CD47 was positively associated with the expression of Gal-3 in primary tumor tissues (Fig. 2E and Supplementary Table 5). Most importantly, we found that high expression of both CD47 and Gal-3 was significantly associated with shorter survival (Fig. 2F), poorly differentiated GAC, diffuse type, and a higher rate of relapse compared to low expression (Fig. 2G). Together, we note that CD47 and Gal-3 were positively correlated in both primary and PC samples.

A, scRNA-seq analysis of unfractionated tumor cells from 20 PC samples. B, Normalized expression levels of LGALS3 and CD47 in tumor cell clusters between long-term survivors and short-term survivors is shown by violin plots (left). Correlation between LGALS3 and CD47 in short-term survivor tumor clusters from scRNA-seq data (P<0.0001, right). C, Scatter plot showed the correlation of LGALS3 and CD47 in epithelial cells in GEO183904 cohort. D, Representative immunofluorescence images (left) and the association analysis (right) of Gal-3 and CD47 staining on PC samples (n=51). Scale bar: 50 μm. E, Representative immunohistology staining of Gal-3 and CD47 images of intestinal and diffuse type in TMA samples (left). Scale bar: 100 μm. The association analysis of Gal-3 and CD47 staining in primary GAC of TMA (n=210; P<0.0001, right). F, The association of Gal-3 and CD47 high expression and low expression with overall survival in TMA samples. G, The association of CD47 and Gal-3 high expression with tumor grade (P<0.0001), diffuse type (P=0.0008) and tumor relapse (P=0.0435) respectively. Student’s test was used unless otherwise indicated.
Down-regulation of Gal-3 suppressed CD47 expression in GAC cells
Having observed that CD47 was highly expressed in primary and metastatic GAC, we note that fewer studies have focused on the parameters that regulate CD47 and its related “don’t eat me” signaling. Previous studies have shown that cytokines including TNFα, IL6, and IFN-γ are involved in regulating CD47 expression(26,27). c-Myc and HER2 were reported oncogenes that regulated CD47 expression in tumors(11,28). Based on the finding that Gal-3 was positively associated with CD47 in the primary and metastatic GAC tissues, we sought to explore if the potential regulation of Gal-3 on CD47 in in GAC cells. First, we generated Gal-3 KO in GAC cell lines AGS and GT5 using Lenti-CRISPR/Cas9 and validated successful KO of Gal-3 in AGS and GT5 by western blot. Interestingly, we found that Gal-3 KO decreased CD47 expression at the protein level (Fig. 3A) and significantly decreased CD47 mRNA expression in both GAC cell lines (Fig. 3B). Furthermore, down-regulation of Gal-3 decreased CD47 expression by flow cytometry in both AGS and GT5 GAC cell lines (Fig. 3C–D). To further validate this finding, we co-stained CD47 and Gal-3 in Gal-3 KO GAC cells compared to control (NC) cells of AGS and GT5 and found that CD47 expression was dramatically decreased upon Gal-3 KO in two individual clones in AGS and GT5 cell (Fig. S3A). To further elucidate the mechanisms by which Gal-3 regulates CD47, we performed RNAseq in AGS cells with Gal-3 KO vs NC cells, and GSEA analysis revealed that MYC-Targets V1 and MYC-Targets V2 signaling were significantly decreased upon Gal-3 KO (Fig. 3E–F and Fig. S3B). Gal-3 KO reduced c-Myc expression was further validated by western blot in both human AGS cell line and mouse KP-Luc2 cell lines (Fig. S3C) which in line with our prior study demonstrated that overexpression of Gal-3 increased c-Myc expression in SNU1 with non-Gal-3 GAC cell line(24). Additionally, our previous study and those by others have demonstrated that Gal-3 regulates c-Myc and activates Wnt signaling through binding to β-catenin and TCF4 (17,29,30). In the present study, we also confirmed that Gal-3 KO dramatically decreased the β-catenin and c-Myc levels, while re-expression of Gal-3 in Gal-3 KO cells increased the β-catenin and c-Myc levels indicating Gal-3 regulation of β-catenin and c-Myc in GAC cells (Fig. S3D). To elucidate the role of c-Myc in regulating CD47 downstream of Gal-3, we conducted siRNA-mediated c-Myc knockdown in AGS cells and found that c-Myc knockdown reduced CD47 expression, but Gal-3 expression had no significant impact compared with Scramble-treated cells (Fig. S3E). Furthermore, a recent study has demonstrated that c-Myc regulates CD47 through binding directly to the promoter of CD47 in human and murine leukemia and lymphomas to regulate CD47 transcription (28,31). Thus, we hypothesize that Gal-3 regulates CD47 through transcriptional factor c-Myc. To prove this, we analyzed ChIP seq data in multiple cancer cell datasets pulling down chromatin by c-Myc antibody and found that CD47 locus was enriched in three ChIP seq datasets (Fig. S4A). We performed ChIP-qPCR after c-Myc pulldown chromatin in Gal-3 KO cells compared to NC and noticed that KO Gal-3 significantly decreased c-Myc occupancy in the promoter of CD47 using specific CD47 primers spanning c-Myc binding site of the CD47 promoter. Correspondingly, occupancy of the chromatin open and activation marker, H3k27ac in CD47 promoter was dramatically reduced upon Gal-3 KO in GAC cell line (Fig. S4B–C). To further confirm the role of c-Myc in the regulation of CD47 by Gal-3, we conducted c-Myc overexpression in Gal-3 KO cells and found that CD47 expression was enhanced in cells rescued c-Myc (Fig. 3G). Further, we performed ChIP-qPCR using c-Myc antibody pulldown chromatin at two c-Myc binding sites of CD47 promoter (Fig.S4B) and found that c-Myc and H3k27ac occupancy in the promoter of CD47 were decreased in Gal-3 KO cells and were reversed by Gal-3 overexpression (Fig. 3H and Fig.S4C) suggesting Gal-3 regulation of CD47 in GAC cells required c-Myc occupancy of the CD47 promoter. Besides, we conducted Gal-1 and Gal-2 overexpression in AGS cells and confirmed by qRT-PCR (Fig. S4D) and detected levels of c-Myc, CD47, and Gal-3 expression by Western blot. No obvious changes in the levels of c-Myc and CD47 upon Gal-1 and Gal-2 overexpression compared with NC cells (Fig. S4E), suggesting that neither Gal-1 nor Gal-2 had an impact on CD47 and c-Myc expression.

A, Western blot analysis of Gal-3 and CD47 expression in AGS and GT5 cells with or without Gal-3 KO (n = 3 biological replicates). B, The expression levels of CD47 mRNA examined by qRT-PCR in NC and Gal-3 KO cells in both AGS and GT5 cells (n = 3 biological replicates). C and D, Representative histogram level and quantification of Gal-3 and CD47 in NC and Gal-3 KO cells in AGS and GT5 cells by flow cytometry, respectively (n = 3 biological replicates). E and F, Highly upregulated hallmark pathways were revealed by GSEA analysis of RNAseq data in AGS NC cells compared with Gal-3 KO cells. G, The expression level of c-Myc, CD47 and Gal-3 was determined by Western blot (n = 3 biological replicates) in Gal-3 KO AGS cells with or without overexpression of c-Myc. H, Quantitative ChIP-qPCR analysis was performed using CD47 promoter primers spanning c-Myc binding site after chromatin pulldown using c-Myc and H3k27ac antibodies in AGS Gal-3 KO cells with or without rescued Gal-3 overexpression (n = 3 biological replicates). Student’s test was used unless otherwise indicated.
Depletion of Gal-3 in tumor cells promotes phagocytosis by repolarized macrophages
To elucidate the effects of tumor cell-derived Gal-3 or host Gal-3 on innate immune response, we utilized our Lgals3−/− vs WT mice and inoculated murine KP-Luc2 tumor cells with NC or Gal-3 KO into WT mice and Lgals3−/− mice respectively (Fig. 4A, left). As a result, we noticed that KO Gal-3 in KP-Luc2 tumor cells significantly reduced tumor growth and increased phagocytosis of F4/80 on tumor cells (GFP+) in both WT and Lgal3−/− mice, although Gal-3 KO in KP-Luc2 tumor cells demonstrated better antitumor effects in Lgal3−/− mice compared to WT mice (P<0.0001, Fig. 4A–B) indicating that tumor cell-derived Gal-3 plays more important role in GAC progression and phagocytosis than that of host-derived Gal-3. To further explore the impact of Gal-3 from GAC cells on macrophage repolarization and function, we co-cultured human macrophages derived from PBMCs with AGS NC and Gal-3 KO cells for 48 hours, and then the notable Mφ2 and Mφ1 marker were examined by qRT-PCR. M1-like macrophages related CD80, CD86, TNFA, and CXCL10 were significantly increased when co-cultured with Gal-3 KO cells compared to untreated NC cells, whereas TGFB1 and TGFB2 were significantly reduced in human macrophages when co-cultured with Gal-3 KO AGS cells compared to NC cells (Fig. 4C). Similarly, U937 monocytes were co-cultured with AGS Gal-3 KO cells significantly reduced the production of CSF1, CCL2, and IL10 compared to that of AGS NC cells, indicating Gal-3 levels in GAC cells govern the macrophage function (Fig. 4D–E). To further explore the potential mechanisms that Gal-3 regulated macrophage polarization, we next examined GSEA analysis between NC and Gal-3 KO of AGS cells. We observed that the interferon alpha and interferon gamma response pathways were upregulated in Gal-3 KO cell compared with NC cells (Fig. S5A). This observation is in line with the previously study that both Type I and Type II interferons activate antitumor M1 macrophage (32–36). No significance of increase phagocytosis was observed in CD47 overexpression cells (Fig. S5B–C). Next, to elucidate the cooperative actions of Gal-3 and CD47 on phagocytosis of macrophage, bone marrow derived macrophages (BMDMs) were isolated from mice (Fig. 4F and Fig. S5D) and then BMDMs co-cultured with KP-Luc2 murine GAC cells pretreated with Gal-3 inhibitor TD139 or neutralizing CD47 antibody (αCD47) alone or combination treatment. As a result, the combination inhibition of Gal-3 and CD47 in KP-Luc2 cells led to significantly enhanced phagocytosis of BMDMs on KP-Luc2 cells when co-culture them in vitro (Fig. 4G and Fig. S5E). These results suggest that Gal-3 in either human GAC cells or murine KP-Luc2 tumor cells is responsible to repolarize into M2 macrophages and suppresses macrophage phagocytosis and cooperates with CD47 protected GAC cells from phagocytosis.

A, Diagram of inoculation of KP-Luc2 NC and Gal-3 KO cells in C57BL/6 WT and Lgals3 KO mice (left). Tumor growth engrafted with KP-Luc2 NC and Gal-3 KO cells in both C57BL/6 WT and Lgals3 KO mice were measured (n = 5mice per group, right). B, Representative contour plots and quantification phagocytosis of KP-Luc2 NC and Gal-3 KO cells in both C57BL/6 WT and Lgals3 KO mice at the end point of experiment by flowcytometry.
C, Expression levels of CD80, CD86, TNF (upper), CXCL10, TGFB1 and TGBF2 (bottom) were examined qRT-PCR in primary human donor-derived macrophages co-cultured with NC and Gal-3 KO cells of AGS for 48h (n = 3 biological replicates). D, Diagram of Diagram demonstrates the experiments procedure of co culturing U937 with AGS NC and AGS Gal-3 KO cell. E, U937 was treated with 80nM PMA for 48h, and co-cultured with NC and Gal-3 KO cells of AGS for 48h, expression levels of CSF1, CCL2 and IL10 were examined by qRT-PCR (n = 3 biological replicates). F, Diagram demonstrates the isolation of macrophage from bone marrow of mice. G, Representative contour plots and quantification of phagocytosis of KP-Luc2 by BMDMs pretreated with αCD47, TD139 and combination treatment for 48 h (n = 4/group), as examined by flow cytometry. One-way ANOVA was used in A, B, G. Student’s test was used unless otherwise indicated.
Gal-3 prevents recruitment and activation of immune effector cells in GAC
To assess the role of Gal-3 in regulating adaptive T cell immune responses and the potential cooperation with CD47, we first examined CD8 T cell infiltration and response in KP-Luc2 tumors with or without Gal-3 KO in WT and Lgals3−/− mice. CD8+ T cell infiltration in KP-Luc2 Gal-3 KO cell implanted GAC tumors significantly increased compared to that of the KP-Luc2 NC cells in WT mice and the CD8+ T cell infiltration was even further boosted when KP-Luc2 Gal-3 KO tumor cells implanted into Lgals3−/− mice (Fig. 5A) indicating Gal-3 in both tumor cells and host plays an important role in limiting T cell infiltration. To further examine the association of Gal-3 with CD8+ T cell, CD4+ T cell, B cell, and NK cell infiltration, we explored TCGA GAC dataset by MCP-counter, xCELL and quanTIseq algorithms and found that the expression of Gal-3 were negatively correlated with CD8+ T cell infiltration in all algorithms (Fig. 5B), which was consistent with the previous report that Gal-3 inhibitor GB1107 increased CD8+ but not CD4+ T cells within the tumor(22). To further explore the potential mechanisms that Gal-3 regulated T cell responses, we performed GSEA analysis between NC and Gal-3 KO of AGS cells and revealed that TNFa signaling via the NFKB pathway were upregulated in Gal-3 KO cell compared with NC cells (Fig.5C). In order to validate the effect of Gal-3 on T cell responses in GAC, we purified CD8+ T cells from human PBMCs and co-cultured with AGS and GT5 NC and Gal-3 KO cells and then analyzed T cell responses using qRT-PCR and Flow-cytometry (Fig. S6A). The expression of TNF, IL2, and IFNG in PBMCs significantly increased in co-cultured with AGS Gal-3 KO cells compared to that in NC cells of AGS cells (Fig. 5D). We found that Granzyme B+CD8+ T cells and Perforin+CD8+ T cells in PBMCs were significantly increased in co-culturing with Gal-3 KO cells in both AGS and GT5 cells compared to NC cells (Fig. 5E–F). No significance change in the cytotoxic function of CD8+ T cells was observed in CD47 overexpression cells (Fig. S6B–C). To elucidate whether there is cooperation between Gal-3 and CD47 on T cell responses, we treated AGS cells with Gal-3 inhibitor TD139, neutralizing CD47 antibody (αCD47), and their combination for 2 days and co-cultured with human PBMCs for additional 2 days, then analyzed GrB and perforin production from CD8+ T cells in PBMCs by flow cytometry. As a result, we found that tumor cells pretreated with the combination of TD139 and CD47 antibody significantly boosted T cell responses (Fig. 5G) in PBMCs compared to either alone, suggesting that inhibition Gal-3 has synergistic effects with anti-CD47 in activating cytotoxic T cell functions in GAC.

A, Representative immunofluorescence staining images (left) and quantification (right) of CD8+ in KP-Luc2 NC and Gal-3 KO cells in WT and Lgals3−/− KO mice (n = 5 mice per group). Scale bars, 50 μm. B, Spearman correlation of LGALS3 expression and CD8+ T cell, CD4+ T cell, B cell and NK cell infiltration by MCP-counter, quaTIseq and xCELL algorithm in TCGA STAD cohort (n=415). C, Highly upregulated hallmark pathways were revealed by GSEA analysis of RNAseq data in AGS Gal-3 KO cells compared with NC cells. D, The expression levels of TNF, IL2 and IFNG examined by qRT-PCR in human PBMCs co-cultured with AGS NC and Gal-3 KO cells for 48h (n = 3/group). E, Representative contour plots and quantification of GrB and Perforin in CD8+ T cells after co-cultured with of AGS Gal-3 KO or NC cells with CD8 T cells for 48h (n = 4/group), as examined by flow cytometry. F, Quantification of GrB and Perforin CD8+ T cells after co-cultured with of GT5 Gal-3 KO or NC cells for 48h (n = 4/group), as examined by flow cytometry. G, Representative contour plots (left) and quantification of GrB and Perforin expression (right) in human peripheral CD8+ T cells co-cultured with AGS cells of the indicated treatment (n = 4/group), as examined by flow cytometry. AGS cells was treated with αCD47, TD139 and combination treatment for 48 h before co-culture with PBMCs. One-way ANOVA was used A and G. Student’s test was used unless otherwise indicated.
Inhibition Gal-3 synergized with CD47 blockage suppressed tumor progression in the syngeneic mouse model
Due to the high expression of Gal-3 and CD47 in metastatic GAC, their positive correlation and their regulation in innate and T cell immunity, we sought to investigate if targeting both Gal-3 and CD47 on innate and T cell immune responses could be recapitulated in vivo. For this, we first implanted KP-Luc2 murine GAC cells with labeled GFP luciferase into C57BL/6 mice, and then treated with TD139, αCD47 and combinational treatment (Fig. 6A and Fig. S7A). Tumor growth was monitored by bioluminescence weekly. At the end, tumors were collected, weighed, snap frozen or formalin-fixed and paraffin embedded for molecular analyses by qRT-PCR and IF staining for macrophage/T cells (F4/80 and CD8), and flowcytometry for T cell responses. As a results, the combinational treatment led to a robust reduction in tumor growth compared with the untreated or single treatment group (Fig. 6A and Fig. S7B). Correspondingly, we found increased phagocytosis in the combination group (Fig. 6B) and increased infiltration of F4/80 (Fig. S7C), which was in line with recent study(37) indicating that macrophages increased in the tumor microenvironment. More interestingly, TD139 significantly increased IFNγ+ production by CD8+ cells and cytotoxic T cell infiltration which further augmented when combining with CD47 blockage (Fig. 6C–D). More importantly, combination treatment increased the notable M1 macrophage markers-Irf1, Irf5, Cd80, Cd86 expression, whereas decreased notable M2 macrophage markers-Mrc1 and Arg1 in the tumor microenvironment (Fig. 6E). Additionally, combination treatment significantly increased T cell response genes Tnfa, Gzmb and Ifng expression, indicating that the combination treatment repolarized macrophage and increased T cell infiltration as well as their cytotoxic function. Taken together, these data demonstrated that inhibition of Gal-3 synergized with CD47 blockade to suppress tumor progression through activation of both innate and adaptive immune responses (Fig. 6F).

A, Representative bioluminescence images over 28 days (left) and quantification (right) of engrafted with KP-Luc2 cell in C57BL/6 mice (n = 5 mice per group) in the indicated treatment. B, Representative contour plots and quantification of phagocytosis at the endpoint day 28 (n =5 mice per group), as examined by flow cytometry. C, Representative contour plots and quantification of tumor IFNγ+CD8+ T cells (n =5 mice per group), as examined by flow cytometry at day 14 (n=5 mice per group). D, Representative immunofluorescence staining images (left) and quantification (right) of tumor infiltrating CD8+ T cells in tumor core and total area (n =5 mice per group). Scale bars, 100 μm. E, Notable markers of M1 and M2 Macrophage (top) and T cell related genes expression (bottom) were shown in heatmap of indicated treatment (n=5 mice per group). F, Schematic illustration of the impact of Gal-3 and CD47 in phagocytosis and immune regulation in GAC in TME; and co-targeting Gal-3 using TD139 and CD47 using αCD47 antibody synergistically boost both innate and adaptive immune responses that lead to tumor suppression. One-way ANOVA was used A-D.
Discussion
CD47 is one of the major players in conveying the “don’t eat me” signal upon binding its receptor SIRPα on the myeloid cells. There is considerable interest in targeting CD47 in the oncology space, however, little has been known about its role in GAC patients with PC. Our multiple profiling in PC cells has shown that CD47 overexpression in primary tumors and PC cells which correlated with poor patient survival. Both CD47 and Gal-3 were positively correlated, and KO of Gal-3 significantly decreased CD47 expression in GAC cell lines. Combined inhibition of CD47 and Gal-3 further increased phagocytosis by macrophages and enhanced CD8+ T cell function in vitro and in vivo. Our data suggest that Gal-3 and CD47 dual inhibition produced most beneficial effects against advanced GAC cells and targeting both Gal-3 and CD47 could be a promising therapeutic strategy against GAC with PC.
CD47 is a trans-membrane protein ubiquitously expressed on human cells but overexpressed on many types of tumor cells. Signaling through the CD47-SIRPα axis plays an important role in the homeostatic processes including erythrocytes, platelets, and hematopoietic stem cell maintenance(8). Tumor cells upregulate CD47 that triggers an interaction between CD47 and SIRPα-the “don’t eat me” signaling in the macrophages, inhibiting phagocytosis to evade innate immune surveillance and to facilitate cancer growth and metastases(38). Thus, CD47-SIRPα blockade has emerged as a next-generation of cancer immunotherapies in various malignancies in the preclinical and clinical settings(39). Using scRNAseq and CyTOF as well as other methodologies, we discovered that CD47 is highly expressed in GAC tissues and PC cells which prompted us to target CD47 in GAC PC cells. However, several clinical studies suggest that blocking the CD47-SIRPα axis alone is not sufficient to induce tumor regression in several cancer types (9,40,41) which may be attributed by several aspects. 1). the phagocytosis relies on the balance between prophagocytic (eat me) in myeloid cells and antiphagocytic (don’t eat me) signals on targets cells(42). 2). CD47 levels are only modestly increased relative to surrounding healthy tissue in most human tumors(43). 3). The TME heterogeneity and co-exists with other innate and adaptive immune checkpoints such as B2M/LILRB1/2 or PD-1/PD-L1 etc. Thus, combination therapies are strongly recommended. Recent appealing data support the combination therapy of targeting of the CD47/SIRPα axis with other oncotargets or other immune checkpoint blockades to improved tumor control such as combination of anti-CD47 with trastuzumab, which eliminating HER2 positive breast cancer and overcomes trastuzumab resistance(44); combination with rituximab in lymphoma led to improved clinical responses(12). Combination with other immune checkpoint blockades such as CTLA-4i or PD-1i/PD-L1i has been studied by several research groups aiming to increase in the efficacy by blockade of the axes that cancer cells use to avoid being cleared by the immune system(45). In line with the present study that single treatment of αCD47 did not sufficiently influence phagocytosis and T cell responses in both in vivo and in vitro, few studies also indicated that combination treatment with αCD47 could be more efficient to suppress tumor growth (8,46). Thus far, only anti-PD-1 and Her2 antibodies have been approved by FDA in GAC. However, the expression of PDCD1 and mutation/amplification of ERBB2 was very low in our GAC specimens by whole exome sequencing (WES)(47), scRNA-seq, and CyTOF analysis which prompted us to explore other immune/oncotargets that highly expressed in GAC patients.
Several reports have noted that Gal-3 expression was significantly higher in poorly differentiated GAC and lymph node positive cancers(48–50). From our scRNA-seq data, we noticed that Gal-3 was the one of the top genes in tumor clusters and it positively correlated with CD47 in both primary and metastatic GAC. Intriguingly, we observed that the percentage of double positive cells was 45.04% in PC samples using scRNA-seq; and patients with double positive conferred worse prognosis. Most importantly, we found that Gal-3 positively regulated CD47 expression at the level of transcription through promoting c-Myc binding to the CD47 promoter in GAC. Further, we revealed that overexpression of c-Myc in AGS Gal-3 KO cells significantly increased CD47 expression indicating c-Myc upregulated CD47 expression downstream of Gal-3, which is in line with previously report (28). Gal-3 has been reported mediating both innate and T cell immunosuppression thus forms an attractive target in addition to CD47. Tumor cells secrete Gal-3 that mediates innate and adaptive immune responses through promoting macrophage polarization from M1 to M2, inducing CD8+ T cell apoptosis, and restricting TCR clustering(22). The compelling evidence of Gal-3 in boosting tumor growth and immune suppression has made it an exciting target for cancer therapy. The key finding in this study is that Gal-3 suppressed phagocytosis by macrophages and KO Gal-3 promoted phagocytosis and increased macrophage infiltration which in part through CD47 downregulation. Furthermore, we showed that phagocytosis significantly increased by macrophages when treated in TD139 especially in combination with anti-CD47 therapy. In the present study, blocking CD47 alone did not significantly induce T cell responses. However, when blocking CD47 in combination with inhibition of Gal-3 using TD139 significantly boosted phagocytosis and increased cytotoxic T cell function in vitro. Co-targeting Gal-3 and CD47 in the KP-Luc2 syngeneic mouse model, CD8+ T cell infiltration, and T cell responses were synergistically increased along with tumor regression in vivo. Our studies have demonstrated that Gal-3 amplified CD47 signaling in innate immunity; and also have a direct effect to T cell immune responses. Taken together, these data demonstrated that inhibition of Gal-3 combined with CD47 blockade should be a strategy to follow.
In summary, our data uncovered that Gal-3 synergized with CD47 to suppress phagocytosis and orchestrated an immunosuppressed milieu in the tumor microenvironment. Dual blockade of Gal-3 and CD47 boosted both innate and adaptive T cell responses, thus providing rationale for a clinical trial in advanced GAC patients.
Others article of note in this Online Scientific Open Access Journal Include:
CD47: Target Therapy for Cancer
Engineered Bacteria used as Trojan Horse for Cancer Immunotherapy
UPDATED on 1/31/2024
Biolojic and Teva Pharmaceuticals announce exclusive license agreement to develop novel antibody-based therapy for the treatment of Atopic Dermatitis and Asthma
Under this agreement, Teva will acquire exclusive global rights to develop and commercialize Biolojic’s BD9 multibody, which was computationally designed as a multispecific antibody targeting IL-13 / TSLP (Thymic stromal lymphopoietin) for the treatment of inflammatory diseases.
SOURCE
From: Yair Schindel <yair@amoon.fund>
Reply-To: Yair Schindel <yair@amoon.fund>
Date: Monday, January 29, 2024 at 10:51 AM
To: Aviva Lev-Ari <avivalev-ari@alum.berkeley.edu>
Subject: Trailblazing the HealthTech Revolution
UPDATED on 1/15/2024
Software Projects for Interns Regarding Natural Language Processing and Drug Discovery for Galectins
Natural Language Processing Project
Goal: 1) analysis of 74 articles concerning galectin 3 and galectin 9 binding using different NLP algorithms to extract binding and affinity coeeficients for modeling of ligand-receptor binding 1a) compare two algorithms (BIOGPT and Wolfram Alpha) on ability to extract meaningful data for queries
- Algorithms for NLP
BIOGPT
The BioGPT model was proposed in BioGPT: generative pre-trained transformer for biomedical text generation and mining by Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon and Tie-Yan Liu. BioGPT is a domain-specific generative pre-trained Transformer language model for biomedical text generation and mining. BioGPT follows the Transformer language model backbone and is pre-trained on 15 million PubMed abstracts from scratch. Note: PubMed contains 36 million abstracts and citations, so BioGPT trained on half of PubMed citations.
BioGPT is an open-source algorithm that can be incorporated in Microsoft Word as an Add-In.
Wolfram-Alpha
Wolfram-Alpha is an intuitive programming environment which allows for mathematical evaluation and, for our purposes, the ability to analyze text for the purpose of natural language processing. The Wolfram system was based on a previous environment called Mathematica. As such Wolfram is an answer engine developed by Wolfram Research. It answers factual queries by computing answers from externally sourced data. The merger of Wolfram and Mathematica into Wolfram Alpha takes advantage of the recent advances in deep learning to bring state-of-the-art capabilities in natural language understanding. New reading comprehension functions can be used on text to answer questions or extract semantic contents. Additionally, a collection of pre-trained neural net models is available to be used as is or fine-tuned to a specific language task. Finally, the neural network framework has been updated with specific capabilities for text, making it one of the easiest tools to solve natural language problems. For instance, you can enter in the text “cat” and the environment can return a picture of a cat or vice versa. Wolfram Alpha now incorporates a GPT system, but the point is that we may have to use our own source of text to train for our needs.
- Tasks for Interns
- Read the BioGPT paper at https://academic.oup.com/bib/article/23/6/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9&login=false
- If you have Python programming experience go to
https://huggingface.co/docs/transformers/model_doc/biogpt
if you want to download the Microsoft Word plugin for BioGPT go watch these youtube videos
- For Wolfram I will email you a link you can use to download the Wolfram Alpah one desktop program and links for tutorials you should watch (Wolfram has a full length tutorial course on their language
Drug Discovery for Galectins Project
Goal: 1) to assess open source software to generate a series of linker molecules which may be useful for further PROTAC development 2) through use of our Natural Language Processing efforts develop a model of galectin binding and signaling using mathematical modeling software HOWEVER there are many subgoals to 1) and 2) we need to accomplish first
Galectins are proteins which we call carbohydrate binding molecules which have many implications and are involved in many diseases like cancer, heart disease, and inflamation. There have been many attempts to target this protein by many drug development firms, especially for cancer. One method to target this protein which has not been tried in the past is developing a compound that targets this molecule for degradation by what is called the ubiquitin proteasome system. This system (UPS) puts little tags on the protein by attaching a small molecule called ubiquitin and then signals the cell to destroy that tagged protein (simple version). A PROTAC, or proteolytic targeted chimera, targets a specific protein for ubiquitiniation, which we call targeted protein degradation. A PROTAC enhances the degradation of a specific protein because it hijacks or brings in close proximity enzymes called E3 ligases to the specific protein. These E3 ligases are what catalyzes the attachment of that ubiquitin to the protein. The way this PROTAC can do this is the fact that a PROTAC is bifunctional, meaning it has three part to it, 1) an end that has affinity for the protein of interest (galectin 3 and 9 in our case), 2) an end that has affinity and binds to an E3 ligase (in our case potentially an E3 ligase called CRBN) and 3) a linker molecule that links 1) and 2). Now if we can make sure that CRBN is our target E3 ligase then we are in luck because the #2 has already been developed so we will focus on developing a #3 linker first and then a #1 affinity molecule to galectin 3.
Therefore the first task will be to read up on the overview of the project to familiarize yourself with the basic biology by going to
https://pharmaceuticalintelligence.com/synthetic-biology-in-drug-discovery/
This will give you an overview of biology of galectins but also background on our goal #2, development of the model of galectin binding to find other approved drugs that might affect galectin redeptor binding and or function. THIS IS YOUR FIRST TASK.
Goal #1: PROTAC development
SUBGOAL: verify the target E3 ligase is CRBN
We will do this is two ways: 1) PubMed search 2) using a cancer database called DepMap or the Cancer Dependancy Map
This will be your second task
- Go to https://pubmed.ncbi.nlm.nih.gov/ and search for “galectin 3” AND “E3 ligase” OR “ubiquitin proteosome system” and we will collect these article as a sub database for potential future NLP purposes
- Go to https://depmap.org/portal/ and eventually to the data explorer at https://depmap.org/portal/interactive/ which you have to click on data explorer to enter the portal. The depmap package is a data package that accesses datsets from the Broad Institute DepMap cancer dependency study which relates gene and protein expression to cell death and drug sensistivity in a variety of cancer cell lines and different tumor types. Datasets from the most current release are available, including RNAI and CRISPR-Cas9 gene knockout screens quantifying the genetic dependency for select cancer cell lines. Additional datasets are also available pertaining to the log copy number of genes for select cell lines, protein expression of cell lines as measured by reverse phase protein lysate microarray. We will use this database to screen cancer cell lines for expression levels of galectin 3 and 9 and also use this database to screen what genes are expressed when we knock out galectin 3 and 9. This will give us an idea of pathways that may be affected by knockdown of galectins. THIS WILL BE SUBTASK TWO.
- Then using the results of Pubmed search we will go back to DepMap and see if knockdown of CRBN E3 ligase shows similar results as knockdown of galectin 3 or 9
SUBGOAL: This will be done after completiion of above. Determine a linker using free software. I am including three papers I want you to read. This will be subtask three for now.
After reading the three papers we will decide, based on complexity of programming required, which of the three following linker design programs that incorporate deep learning protocols is most suitable
- DeepPROTAC available online at a web server (https://bailab.siais.shanghaitech.edu.cn/services/deepprotacs/) and at github (https://github.com/fenglei104/DeepPROTACs).
- Link-INVENTwhich is a generative linker design with reinformement learning available freely available at https://github.com/MolecularAI/Reinvent.
- DeLinker: a deep generative model available at https://github.com/oxpig/DeLinker
The three paper links are
For DeepPROTAC https://www.nature.com/articles/s41467-022-34807-3
For Link-INVENT https://pubs.rsc.org/en/content/articlelanding/2023/dd/d2dd00115b
For DeLinker https://pubs.acs.org/doi/10.1021/acs.jcim.9b01120
However I am emailing you the pdfs also
FOR NOW THIS SHOULD BE ENOUGH WORK TO DO BEFORE WE TALK ABOUT THE SECOND GOAL WHICH WILL INCLUDE A PROGRAM CALLED COPASI AND ANOTHER PROGRAM CALLED BIOMODELS
I just want us to get started with the above before we move ahead with some of the more complex work. The final programs we will need after we complete this is modeling software that verifies our structure can fit however this is for another time.
UPDATED on 9/11/2023
Please see the following PAGES on this Open Access Scientific Journal of OpenAI and ChatGPT Tools that have been developed which may aid in the evaluation of the literature on Galectins and Cancer
ChatGPT applied to Cancer & Oncology
This page highlights the recent advances in OpenAI with regard to Oncology, both treatment, diagnosis, and cancer drug discovery. Of note are one tools, BioGPT, a new collaboration of MicroSoft and the Broad Institute for the specific Large Language Model OpenAI (GPT) for biomedical literature. An evaluation is also given of this tool.
Two other tools recently developed are GeneGPT and ChemGPT, which may be useful for the following endeavors in drug development against Galectins as a onco-therapeutic target.
The Use of ChatGPT in the World of BioInformatics and Cancer Research and Development of BioGPT by MIT
ChatGPT Chemistry Assistant for Text Mining and the Prediction of metal–organic framework (MOF) synthesis
SEE BELOW THE UPDATE ON 4/11/2023 on potential application of ChatGPT for Text Analysis of 74 articles on Galectin
UPDATED on 4/11/2022
Why Use Mathematical Modeling to create a model of Galectin binding to receptors?
We are also considering the alternate approach other than a PROTAC strategy to alter cooperative binding characteristics of Galectins for disease states such as cardiovascular where the goal will be to augment galectin binding to receptors and increase galectin signaling. This will first entail a two step approach
- model galectin binding to the CBD of galectin receptors
- model intracellular signaling pathways of galectins 3 and 9

First Step #1
Included in this folder is a word file which combines all Galectin papers which need to be analyzed by text analysis and NLP. Each individual selected paper was concatenated into one Word document. The final document contains
72 papers
554 pages
46,785 lines of text
389,940 words
The paper selection was as follows:
A Pubmed search was performed on the criteria of: Galectin-3 OR Galectin-9 AND model AND binding AND receptor
174 papers were retrieved and further reanalyzed on the above criteria for fit as well as galectin binding parameters while reviews were discarded. This left 72 papers which full text and figures were combined for further text analysis
A wordcloud by WordItOut was generated from the finalized curated 72 paper full abstracts to determine if proper selection of papers were made. As shown in the wordcloud we have curated a substantial and appropriate number of relevant papers for this purpose of generating a NLP based algorithm for insertion into Copasi mathematical modeling software in order to generate a mathematical model of Galectin3 and 9 binding to CBD receptors. A similar approach will be used to model galectin signaling pathways.

The following files are located on LPBI DropBox folder (by invitation only)
The following links can be used for the Word format file and same file in PDF format
Combine of all galectin papers
Word Combine of all galectin papers
I also want to highlight another effort we are undertaking and ask question how we can combine the technology of AI with our curated database WITH REGARD TO OUR EFFORT OF DRUG DISCOVERY IN GALECTINS AND GALECTIN SIGNALING HOWEVER I will refer the reader to our new PAGE Chat GPT + Wolfram Plugin
A brief illustration is given below to describe the potential power of combining these two AI and NLP algorithms together

The important points is that ChatGPT and Wolfram use two different conceptual views of language: a mathematical view and a structural semantic view. Combining these may be more powerful in extracting mathematical relationships from medical text.
UPDATED on 12/12/2022
Mission 4: Use of Systems Biology for Design of inhibitor of Galectins as Cancer Therapeutic – Strategy and Software
UPDATED on 10/10/2022
Endoglin Protein Interactome Profiling Identifies TRIM21 and Galectin-3 as New Binding Partners
UPDATED on 9/1/2022
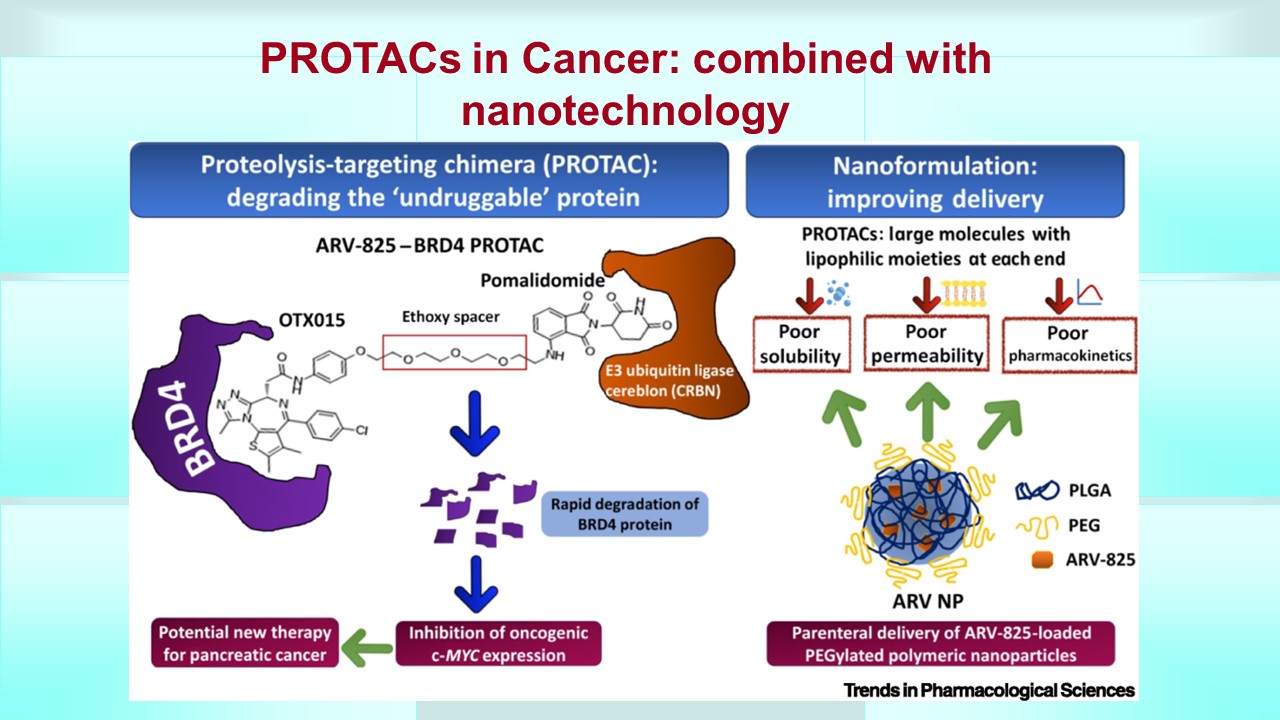
The drug efflux pump MDR1 promotes intrinsic and acquired resistance to PROTACs in cancer cells
Accelerating PROTAC drug discovery: Establishing a relationship between ubiquitination and target protein degradation
UPDATED on 7/12/2022

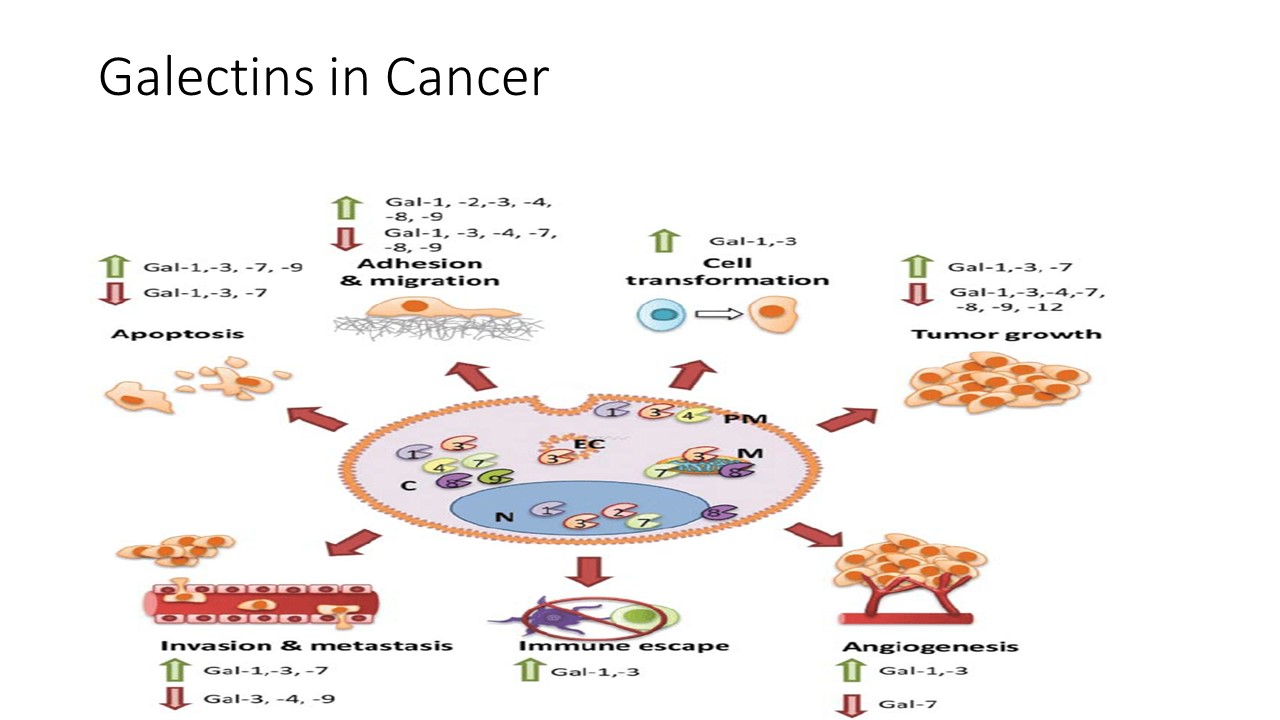
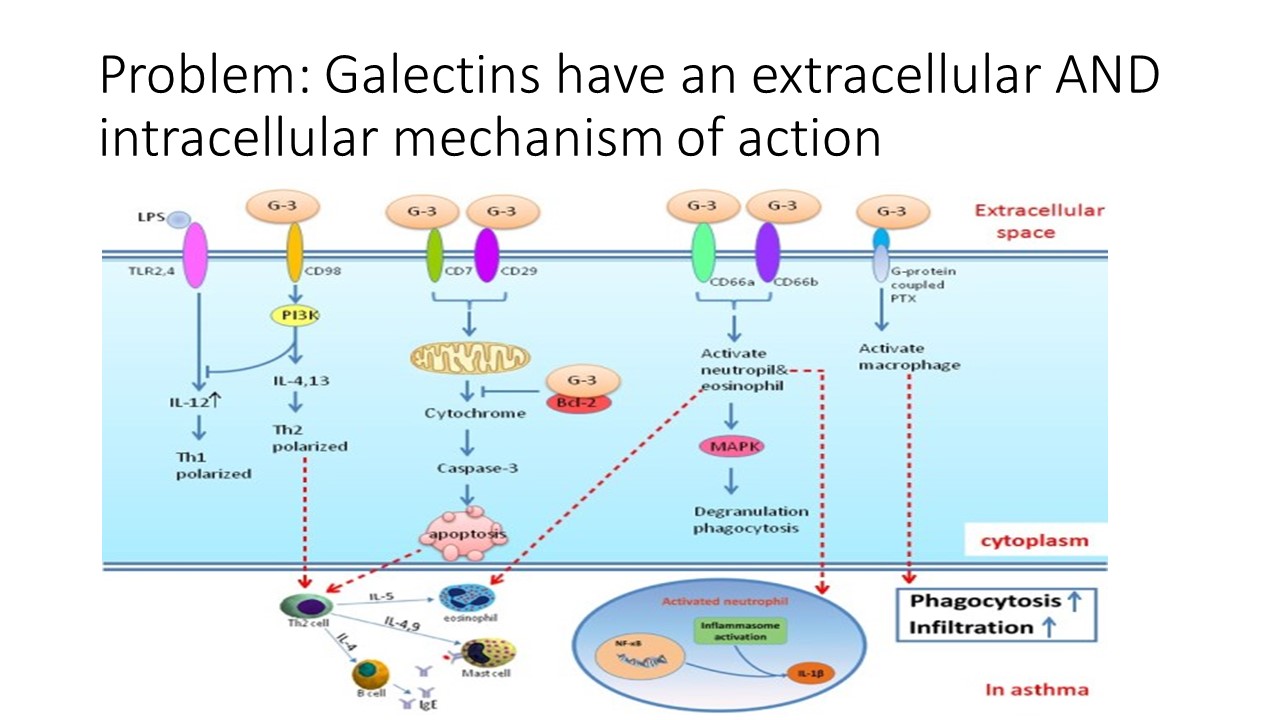
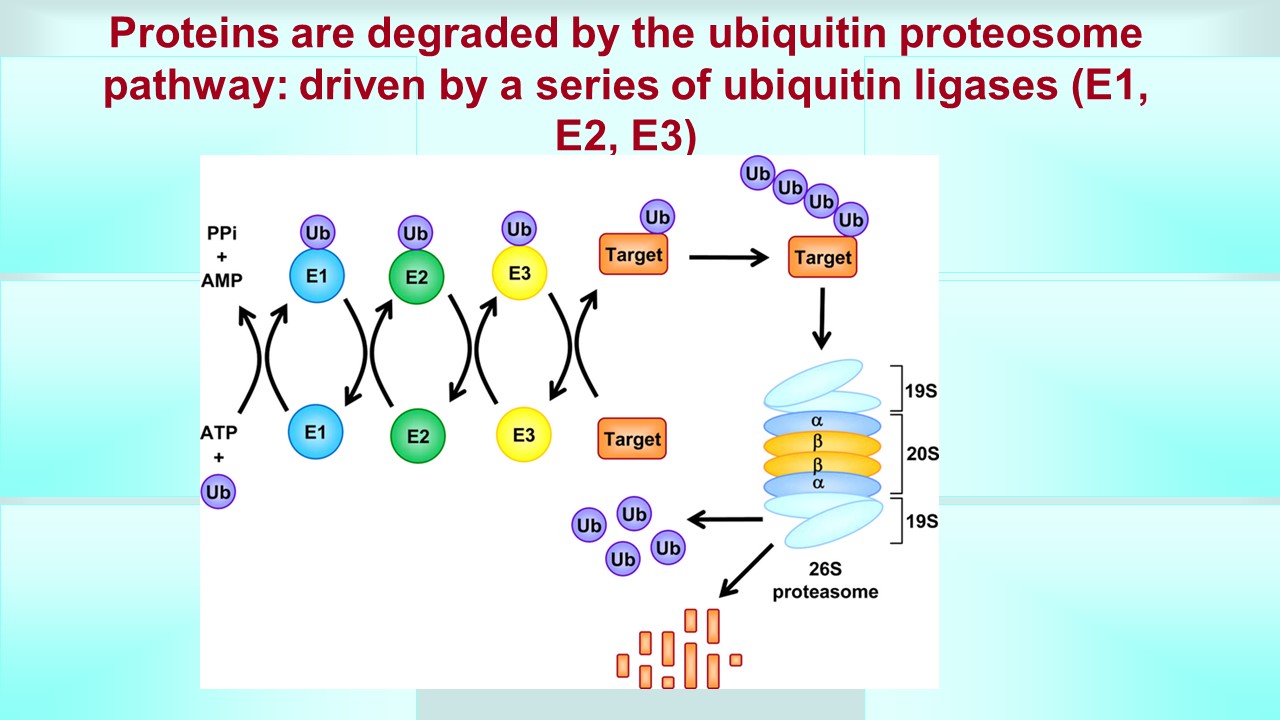

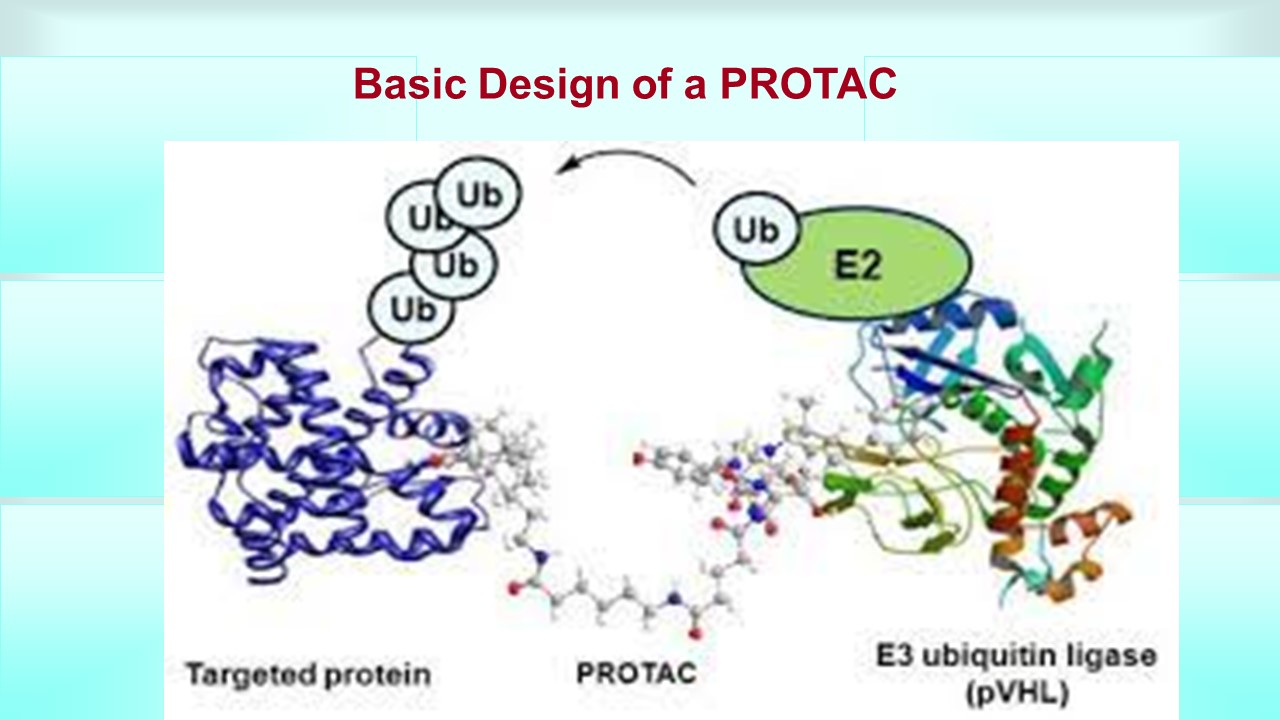











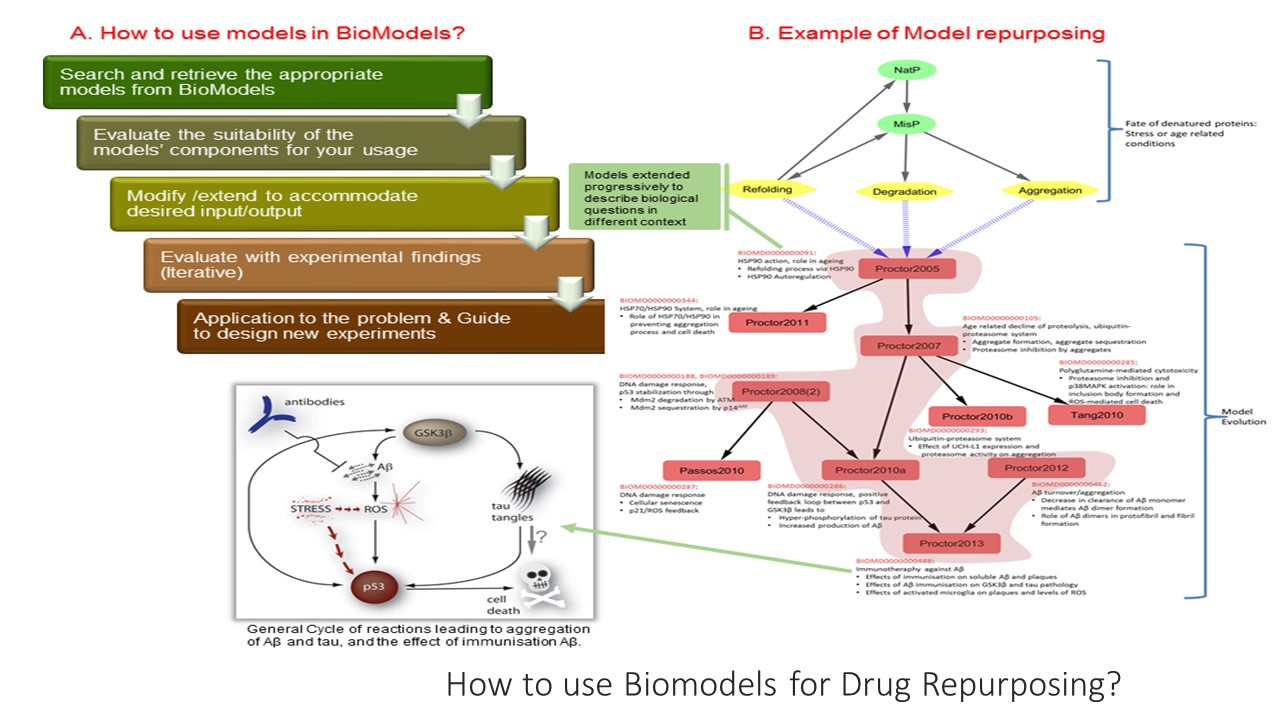
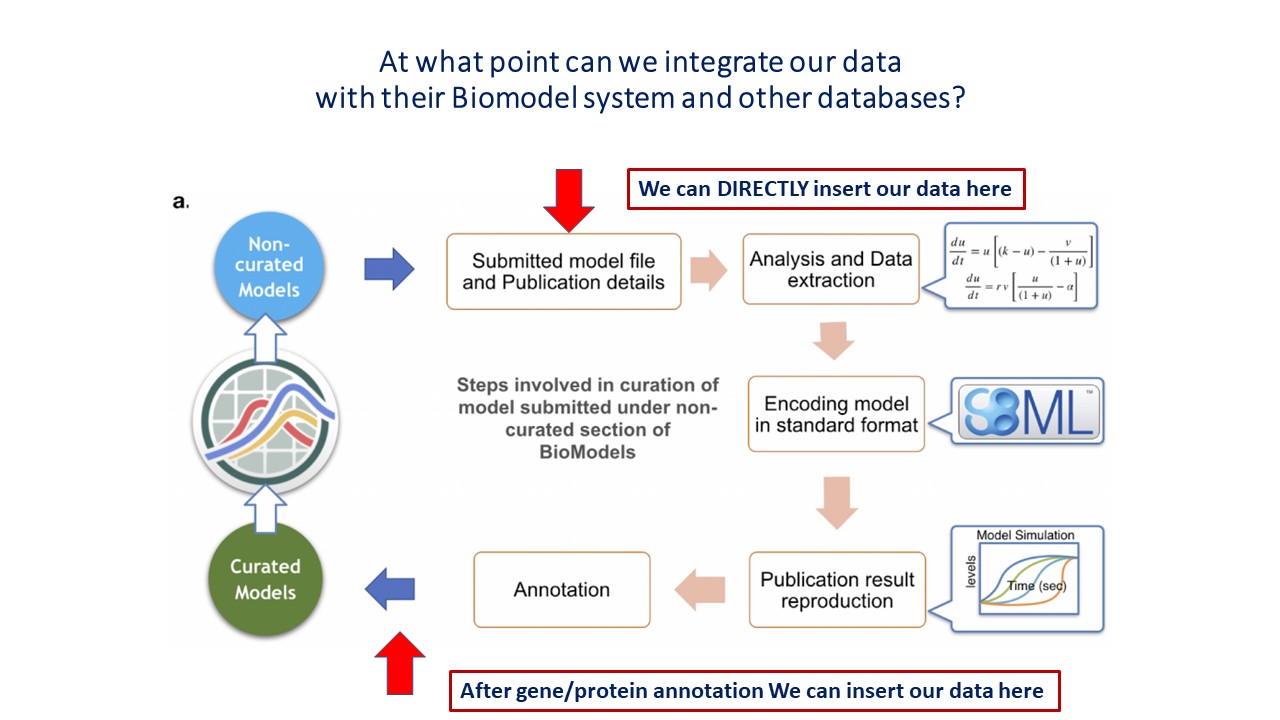

UPDATED on 7/12/2022
Molecule Raises $12.7 Million in Seed Funding for Biotech
The organization intends to use NFTs for important things.
Switzerland, Jun 30, 2022 – Molecule, a comprehensive funding and incubation ecosystem for early-stage biopharma research, announced this week they raised $12.7 million in seed funding. The round was led by Northpond Ventures with participation from Shine Capital, 1kx, Fifty Years, KdT Ventures, BACKED VC, Inflection VC, Chris Leiter, Balaji Srinivasan, Zee Prime Capital, The LAO, L1 Digital, Boom Capital, Compound VC, Koji Capital, Pillar VC, Seedclub Ventures, Speedinvest, Healthspan Capital, BoxGroup and many others.
While the biopharma industry has come a long way, many challenges remain, such as difficulty in aligning incentives of key stakeholders. Additionally, while many therapeutics are discovered in academic labs, funding in academia is preferentially allocated to established researchers and research fields, to the detriment of early career researchers and higher risk projects. The result is an ecosystem where potentially impactful research goes unfunded, and incentives for collaboration are often missing.
Molecule aims to address these incentive problems and funding gaps. They are creating an open ecosystem that assists researchers in raising funds for impactful research projects in a community-driven way. With Molecule, diverse communities (including patient groups, researchers, VCs and pharma companies) can fund, own and govern therapeutic intellectual property. This provides novel incentives for collaboration, investment, and risk-sharing. The result is that communities, such as patient groups, can choose which projects get funded, and later own the therapeutics that treat their disease.
The Molecule ecosystem has three components:
1) Communities: A community of physicians, scientists, and patients collaborate to form funding groups in specific therapeutic areas e.g. rare diseases and Alzheimer’s disease.
2) The IP-NFT framework: this allows researchers to fundraise without needing to patent early or create a startup.
3) A marketplace: Molecule is building a marketplace for biotech IP. Researchers at any career stage submit projects for funding, increasing discoverability of neglected research areas, and addressing key funding gaps.
“Many of the most impactful therapeutics are discovered in academic labs, yet development and translation of these assets toward the clinic remains difficult. Molecule’s marketplace and IP-NFT framework will address many of the pain points inherent in the funding and commercialization of early-stage biotech IP, ultimately benefiting the most important stakeholder in the Molecule ecosystem – the patient. Northpond is excited to partner with Molecule and lead their seed round.” – Patrick Malone, MD PhD, Associate at Northpond Ventures.
Molecule: what’s to come
The capital raised will be used to grow their marketplace with hundreds of research projects, expand their team, build out their protocol and technology layer into an open infrastructure, and provide grants to patient-centric biotech DAOs to expand the DeSci ecosystem. They also hope to out-license the first NFT-based IP to industry, demonstrating for the first time patient-led translational drug development.
“Many of us are tired of hearing about NFT monkeys selling for millions. Molecule is using the NFT framework for something truly important: helping incredible scientific research transition from the lab bench to the benefit of all. Molecule’s work will help more life-saving drugs get to patients. That’s an application of web3 that’s easy to get excited about.”
Seth Bannon, Founding Partner at Fifty Years.
To truly decentralize adoption, they are also building accelerator frameworks for the friction-less launch of biotech DAOs targeting specific diseases of high unmet need, such as rare diseases and mental health. They see a future where scientists raise funds from incentive-aligned communities that wish to support them, and where patients themselves have governance over how therapeutics are researched, developed and accessed.
Their journey since inception
Since their pre-seed in early 2020, their team has grown to 22 members spread across the US, South-Africa and Europe, operating in a semi-remote fashion. Over these past few years, they have funded a first group of projects, and helped build the first biotech DAO – VitaDAO – which has deployed $2m+ to fund longevity research to date, including research at the Scheibye-Knudsen Lab (University of Copenhagen), Viktor Korolchuk’s Lab (University of Newcastle) and the Evandro Fang Lab (University of Oslo) all using Molecule’s IP-NFT framework.
“We believe that Molecule is a category defining project which will inspire a wave of innovators bringing the concept of collective ownership and liquid IP markets into various areas of R&D. We’re grateful for having been part of Molecule’s journey since inception and couldn’t be more excited about what’s to come.” – Alexander Lange, Founding GP at Inflection VC
Investors in this round:
Northpond Ventures, Shine Capital, 1kx, Fifty Years, The LAO, BACKED VC, ZeePrime Capital, L1 Digital, Seed Club Ventures, IDTheory, Andrew Keys, Compound VC, Pillar VC, Inflection VC, Protocol Labs, BoxGroup, KdT Ventures, IDTheory, Boom Capital, Gaingels, Cherry Ventures, Amino Collective, Chorus One, OrangeDAO, BeakerDAO, Kindergarten Ventures, Speedinvest, Bool Capital, Koji Capital, Healthspan Capital, Breyer Capital.
Chris Leiter, Zen Chu, Allison Duettman, Pamir Gelenbe, Katelyn Donnelly, Steve Wiggins, Balaji Srinivasan, Piers Kicks, Qiao Wang, Brian Fabian Crain, Scott Moore, Philipp Banhardt, Meher Roy, Ajay Rayasam, Angelo Tagliabue, Collin Myers, Jonas Keller, Garret MacDonald, Luis Cuende, Theodor Walker, Ronjon Nag, Alok Tayi, Laurence Ion, Todd White, Tim Peterson, Jahed Momand, Laurens De Poorter, Andrew Steinwold, Tim Schlidt, Justin Olshavsky & some who remain anonymous.
Discover Molecule:
Join the conversation on their Discord
Discover research projects on Molecule Discovery
Visit their website
Media enquiries:
Heinrich Tessendorf: pr@molecule.to
UPDATED on 6/20/2022
Targeting galectin-1 inhibits pancreatic cancer progression by modulating tumor–stroma crosstalk
Galectins in Cancer and the Microenvironment: Functional Roles, Therapeutic Developments, and Perspectives
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8465754/
The emerging role of galectins in cardiovascular disease
UPDATED on 6/12/2022
Startup to Strengthen Synthetic Biology and Regenerative Medicine Industries with Cutting Edge Cell Products
Synthetic Biology: On Advanced Genome Interpretation for Gene Variants and Pathways: What is the Genetic Base of Atherosclerosis and Loss of Arterial Elasticity with Aging
Synthesizing Synthetic Biology: PLOS Collections
http://pharmaceuticalintelligence.com/2012/08/17/synthesizing-synthetic-biology-plos-collections/
Capturing ten-color ultrasharp images of synthetic DNA structures resembling numerals 0 to 9
Silencing Cancers with Synthetic siRNAs
http://pharmaceuticalintelligence.com/2013/12/09/silencing-cancers-with-synthetic-sirnas/
Mission #4 for LPBI USA is Mission #2 for LPBI India:
UPDATED on 11/8/2021
Synthesis among four contributing factors
This is A
The Nobel Prize in Chemistry 2021
pharmaceuticalintelligence.com/2021/10/06/the-nobel-prize-in-chemistry-2021/
This is B
The Map of human proteins drawn by artificial intelligence and PROTAC (proteolysis targeting chimeras) Technology for Drug Discovery
This is C
Synthetic Biology in Drug Discovery – @MIT
http://pharmaceuticalintelligence.com/synthetic-biology-in-drug-discovery/
This is D – Access to software
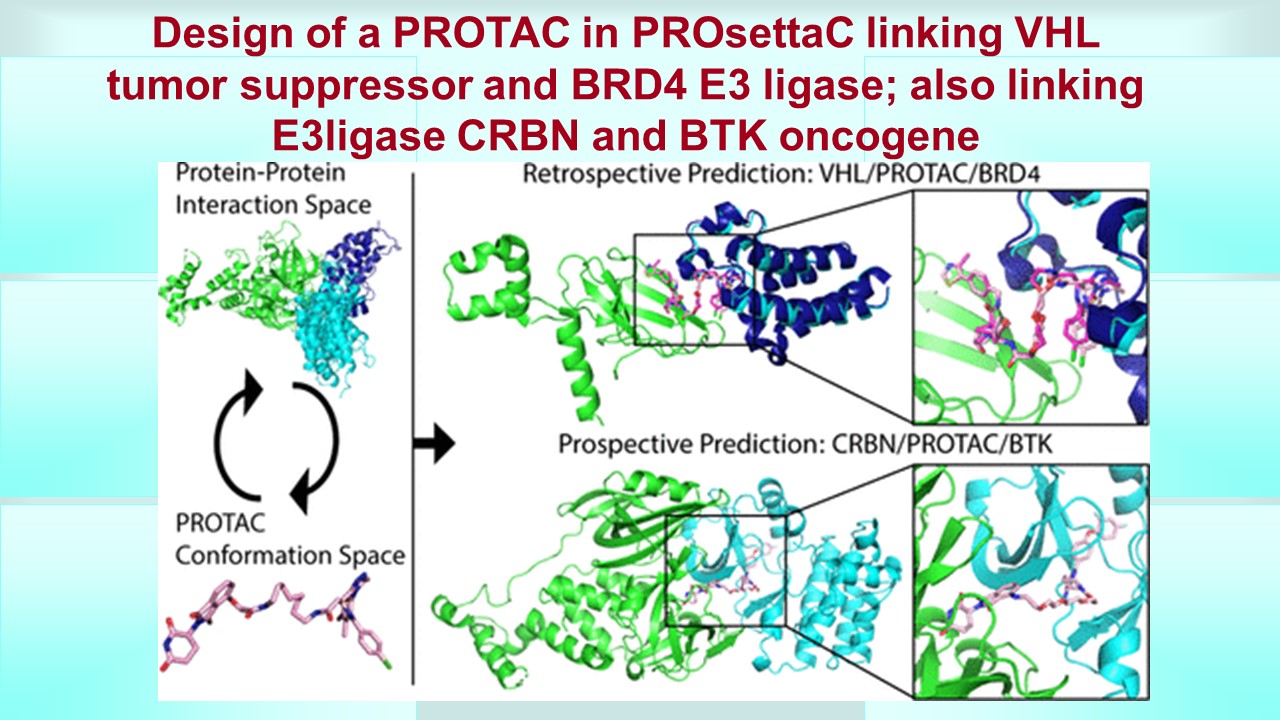
PRosettaC: Rosetta Based Modeling of PROTAC Mediated Ternary Complexes
PRosettaC: Rosetta Based Modeling of PROTAC Mediated Ternary Complexes
- Daniel Zaidman
- Jaime Prilusky
- Nir London*
Cite this: J. Chem. Inf. Model. 2020, 60, 10, 4894–4903Publication Date:September 25, 2020 https://doi.org/10.1021/acs.jcim.0c00589
Copyright © 2020 American Chemical Society
PRosettaC, a holistic protocol for modeling PROTAC mediated ternary complexes. It combines global docking with PatchDock (33,34) under PROTAC derived distance constraints and local docking with RosettaDock, (35) followed by modeling of the PROTAC into the ternary complex. (36) The protocol was able to accurately recover published structures of ternary complexes to near atomic resolution and recapitulate experimental trends for two model systems. This general protocol should be useful in the design of new PROTACs for a wide variety of targets. To enable wide access to this protocol, we have made available both the code (https://github.com/LondonLab/PRosettaC) as well as a Web server for running PRosettaC (https://prosettac.weizmann.ac.il/).
https://pubs.acs.org/doi/10.1021/acs.jcim.0c00589#
UPDATED on 11/5/2021
How knowledge graphs will transform drug discovery
It’s time to get serious about knowledge graphs in drug discovery. If depressing projections are to be believed (and there is strong support that they are), the pharmaceutical industry is in a terminal decline, with return on investment (ROI) projected to hit zero by 2020. Pharmaceutical companies have made some heroic efforts to plug the holes in the hull of the Titanic, but the fact remains that the returns on new drugs that do get to market do not justify the massive investments that Pharma currently puts into R&D.
Yet, there is much needing to be done in drug discovery. Despite some recent successes in immuno-oncology and gene therapy, our treatments for the most prevalent, devastating diseases like cancer and diabetes are still not that great, and there are many more conditions like Alzheimer’s that have no good treatments at all, not to mention the hundreds of rare and neglected diseases that need treatments. As we used to say when I worked at Parke-Davis, “the patient is waiting”.
So how do we save drug discovery and get back to helping the patient? Well, as has been said many times before, we have to find a way to make drug discovery much leaner, faster, and effective, and that means radically rethinking the processes, assumptions and technologies of drug discovery, and most importantly how we use data and knowledge effectively. Current drug discovery processes are predicated on letting a sequence of expert scientists (chemists, biologists, toxicologists, and so on) use their deep knowledge to drive experimental investigations through a well-trodden process of target identification, lead compound identification, ADME/toxicology, animal studies, and so on. Most of these efforts fail, but the investigations result in mountains of experimental databases, papers, documents, spreadsheets, with modern experimental technologies such as high throughput screening and genomics delivering millions of data points for every project. Key decisions, insights, and observations are neatly organized into PowerPoints and then forgotten. Then there are the petabytes of experimental and patient data being made available in public or commercial data sources, as well as the well over a million life sciences publications that come out each year. It is not too extreme to say that if pharma companies are going to survive, they need to stop being drug companies and start being data science companies.
What if we could bring all that knowledge, data, insight, and prior decision-making together and use it to accelerate the discovery of new drugs? What if we could encode the millions of known relationships between potential new (or old) drugs, protein targets, genomics, biological processes, and disease mechanisms, and then use all this together to get new insights into disease and treatments? What if we could encode scientific decisions? What if we could even map translational relationships that bring all the scientific molecular data together with data from patients and clinical trials? What if we could partner this huge map of knowledge with powerful AI and machine learning algorithms that can prioritize insights and connections for the expert human scientists to assess? What if we could actually do data-driven drug discovery that gets drugs to patients quicker and faster?
Well we can do this.
Since 2008, I and my colleagues at Indiana University have been researching ways to link together massive amounts of heterogeneous drug discovery data and knowledge into computable graph structures, which we now call knowledge graphs, and we have designed new powerful algorithms to run on top of these knowledge graphs. We have already done some pretty exciting things like predicting the biological activities of drugs, mining patterns to explain side effects, and identifying new patterns of relationships between diseases. In 2010, the OpenPHACTS consortium brought together the knowledge and insight from pharmaceutical companies and academia to demonstrate how drug companies and academia can collaborate to combine knowledge into a linked, searchable network. Our partner and the successor to the consortium, the OpenPHACTS Foundation, will soon be ready to release a highly accessible, interoperable, sustainable knowledge graph of public drug discovery data that can be harvested and reused in many ways. In 2012, we launched Data2Discovery, one of the earliest AI for drug discovery startups. Data2Discovery is, with customers and partners, building knowledge graphs that transcend the boundaries of traditional public/proprietary data silos and which power completely new AI-driven applications. We are able to improve drug discovery now as well as demonstrating new fast-cycle AI-driven processes that will have a revolutionary impact on drug discovery if fully implemented. We have had some dramatic successes, but we are just starting to discover the impact that data, knowledge graphs, AI and machine learning can together have on drug discovery.
We need all the expertise of academics, consortia, AI companies and pharma to make his happen, and it’s going to require some serious investment, and a big change of thinking. But the opportunity to get drug discovery out of the death spiral and framed for data-driven success is too important to pass up. The patient is waiting.
SOURCE
UPDATED on 10/3/2021
Geometric deep learning of RNA structure
RAPHAEL J. L. TOWNSHENDHTTPS://ORCID.ORG/0000-0001-6362-1451STEPHAN EISMANNANDREW M. WATKINSHTTPS://ORCID.ORG/0000-0003-1617-1720RAMYA RANGANHTTPS://ORCID.ORG/0000-0002-0960-0825MARIA KARELINAHTTPS://ORCID.ORG/0000-0003-1880-4536RHIJU DASHTTPS://ORCID.ORG/0000-0001-7497-0972 AND RON O. DROR HTTPS://ORCID.ORG/0000-0002-6418-2793Authors Info & Affiliations
SCIENCE•27 Aug 2021•Vol 373, Issue 6558•pp. 1047-1051•DOI: 10.1126/science.abe56508,9611
Metrics
Total Downloads8,961
- Last 6 Months8,961
- Last 12 Months8,961
Total Citations1
- Last 6 Months1
- Last 12 Months1
Machine learning solves RNA puzzles
RNA molecules fold into complex three-dimensional shapes that are difficult to determine experimentally or predict computationally. Understanding these structures may aid in the discovery of drugs for currently untreatable diseases. Townshend et al. introduced a machine-learning method that significantly improves prediction of RNA structures (see the Perspective by Weeks). Most other recent advances in deep learning have required a tremendous amount of data for training. The fact that this method succeeds given very little training data suggests that related methods could address unsolved problems in many fields where data are scarce. —DJ
Abstract
RNA molecules adopt three-dimensional structures that are critical to their function and of interest in drug discovery. Few RNA structures are known, however, and predicting them computationally has proven challenging. We introduce a machine learning approach that enables identification of accurate structural models without assumptions about their defining characteristics, despite being trained with only 18 known RNA structures. The resulting scoring function, the Atomic Rotationally Equivariant Scorer (ARES), substantially outperforms previous methods and consistently produces the best results in community-wide blind RNA structure prediction challenges. By learning effectively even from a small amount of data, our approach overcomes a major limitation of standard deep neural networks. Because it uses only atomic coordinates as inputs and incorporates no RNA-specific information, this approach is applicable to diverse problems in structural biology, chemistry, materials science, and beyond.
SOURCE
https://www.science.org/doi/10.1126/science.abe5650
UPDATED on 8/20/2021
Below are four great reviews explaining synthetic biology and some of the requirements.
UPDATED on 8/20/2021
Below is a great article and graphics on Drug Discovery Process in the 21st Century by Charles River
Source: https://www.drugdiscoverytrends.com/the-new-age-of-drug-development/
The New Age of Drug Development
By Martin O’Rourke, PhD, Jane Hughes, PhD, Charles River Laboratories | July 19, 2018
Over the last 20 years, the landscape of drug discovery has changed dramatically. Historically, research and development took place within large pharmaceutical companies with a collection of smaller biotechnology companies doing the innovating, and eventually being acquired by larger companies. However, given the ever-increasing drive to deliver value quickly and more cost-effectively, the environment is now filled with a dynamic mixture of large pharma, biotechs and virtual organizations.

The timelines for delivery of a candidate compound, irrespective of the therapeutic area, has consistently averaged between two and a half and four years from the initial hit identification effort (see image above). The number of U.S. Food and Drug Administration (FDA) approvals is lower today compared to 1996, which has led to an increased quest for better validation of targets, and higher quality candidates with a greater chance of success.
Pressure is mounting on pharmaceutical companies to both fill their internal pipelines as well as deliver value to shareholders. The trend toward a reduction in internal R&D spend within pharma worldwide coupled with increased outsourcing of research has enabled pharma to reduce its fixed cost-base and allow increased capital flexibility. Increasingly, the R&D market has observed significant increases in the number of small virtual companies with limited budgets being expected to progress compounds to the point of candidate nomination under the shortest timeline possible. This paradigm shift towards virtual research has also resulted in an increase in the number of experienced drug discovery scientists now working for contract research organizations (CRO).
The main aim of the integrated CRO is to act as an extension of the sponsor company and drive projects to the point of nomination. Toward this end, Charles River Laboratories (Charles River) has established a discovery division focused solely on delivering pre-clinical candidates across multiple therapeutic areas. One unique aspect of Charles River’s strategy is to robustly validate the target at an early stage of the project, confirming expression and link to disease, as well as identification of a response biomarker. Their track record of delivering clinical candidates has been analyzed internally and compares favorably with industry standards. In the last 15 years Charles River has delivered 79 preclinical candidates, with over 30 of these molecules progressing to Phase I and beyond (see chart below).

Charles River has achieved these high delivery metrics by pioneering and implementing a translational integrated drug discovery platform which allows their partners to effectively increase their lab size by contracting a complete drug discovery team, including medicinal and computational chemists, in vitro and structural biologists, DMPK scientists and in vivo pharmacologists. These dynamic teams, managed by an experienced project lead—usually a drug discoverer who has delivered preclinical candidates coupled with a specialist in the particular therapeutic area—strive to rapidly transition projects through the phases of drug discovery.

Note: In above diagram LPBI India is focused on the BLUE areas of drug discovery process.
The project leader is responsible for all elements of project management, operating a single point of contact policy with his or her counterpart in the partner company. This ensures clear communication, efficient delivery of objectives and prompt data sharing through Charles River-curated data portals and shared electronic laboratory books. An additional benefit is that an integrated CRO can coordinate all activities under a single Master Service Agreement, thereby streamlining the contracting process for potential partners.
The relationship between the partner and Charles River is absolutely key, and trust is developed through regular face-to-face meetings, supplemented with regular teleconferences and email communication. The shared vision for the project is paramount as it allows dynamic decision-making, and combined input on direction and agreement on the key parameters required to transition the project through the various phases of drug discovery.
Charles River also recognizes that flexibility is crucial to the delivery of preclinical compounds and has adjusted their integrated offering to support this. Charles River will happily contribute one or two disciplines to the project and form part of a project team with the partner organization. For example, Charles River could provide the chemistry and structural biologist for the project, working closely with the partner’s biology and DMPK team. Charles River is equally comfortable working in a collaborative network, interacting with multiple touch-points which could include the partner organization, academic collaborators or a charitable foundation. Charles River firmly believes this flexible working arrangement allows access to our expertise and knowledge – regardless of budget – and focuses on the specific project needs.

As drug discovery evolves, Charles River is focused on embracing new technologies through strategic partnerships and internal development, to allow our partners access to the most up-to-date information and technology with the aim of shortening delivery times of preclinical candidates.
It is becoming clearer within the industry that robust validation of the target expression in the human disease state and the tractability of the target are key to the delivery of successful projects. Charles River can provide due diligence on the project by evaluating the expression of the data in diseased tissues, assessing the current literature, proposing chemistry strategy based on assessment of the target crystal structure, and virtual screening over three million ligands. Investing time in these activities at the initiation of the project has resulted in shorter timelines to reach candidate nomination. In addition, ensuring early identification of target engagement and efficacy biomarkers early in the process will ensure a seamless transition from preclinical to clinical development and ensure a clear line of sight between compound exposure and effect. Charles River is dedicated to continually reviewing the working practices of an integrated project to identify areas of white space which could be removed. A recent initiative reviewing the timelines for compound synthesis to testing in vivo during a lead optimization project resulted in a six-week timeline from synthesis to PK study; this truncation of timeline lead to the successful achievement of project transition ahead of the agreed timeline.
The creation of the integrated drug discovery model has allowed Charles River to offer partners internal expertise, project management skills and the seamless integration of multiple disciplines into a translational project package fully enabled with a biomarker strategy across species, thereby reducing the partner’s delivery timelines for transition of compounds and potentially reducing the cost of delivering a preclinical candidate.
Martin O’Rourke, PhD, is a senior director of Oncology In Vitro Biosciences, Integrated Drug Discovery at Charles River Laboratories and Jane Hughes, PhD, is a senior director of In Vitro CNS Research, Integrated Drug Discovery at Charles River Laboratories
UPDATED on 8/14/2021
Synthetic Biology: On Advanced Genome Interpretation for Gene Variants and Pathways: What is the Genetic Base of Atherosclerosis and Loss of Arterial Elasticity with Aging
Aviva Lev-Ari, PhD, RN
UPDATED on 8/7/2021
This is the voice of Dr. Larry H. Bernstein in
Series E: VOLUME TWO
Medical Scientific Discoveries for the 21st Century
&
Interviews with Scientific Leaders
Author, Curator and Editor:
Larry H Bernstein, MD, FCAP
Available on Kindle Store @ Amazon.com since 12/9/2017
https://www.amazon.com/dp/B078313281
Chapter 14: Synthetic Medicinal Chemistry
Introduction
This is a chapter that identifies major work in organic, inorganic, and medicinal chemistry.
14.1 Insights in Biological and Synthetic Medicinal Chemistry
Author & Curator: Larry H. Bernstein, MD, FCAP
14.2 Breakthrough work in cancer
Larry H. Bernstein, MD, FCAP, Curator
Summary to Part Two
The second part of this volume is more directed at the growth of remarkable discoveries in the health related sciences since the late-20th century. There have been observations that discovery has slowed. I cannot share such a view. It has become difficult to follow the rapid progress that is achieved in a step-by-step order. There is always reference to “serendipidous” discoveries, but for such an event it requires a prepared mind. A problem that has existed in the reliance on large funding for so much of research and the implementation using mathematics, computers, and advanced spectroscopy for discovery, is that there is a significant skew to the direction of research, and in the current state of expenditure it is more difficult for young investigators to enter with new ideas. Perhaps it has always been that way, but the scope of the work needed is much larger than ever before.
Volume Summary and Conclusions
This series of articles follows an earlier volume on scientific discoveries of the late 19th and 20th centuries. However, it is noteworthy to consider that the lifetime achievements recognized in the first decade of the 21st millenium reach back to an accumulation of half a century of sustained research. These articles provide a significant amount of insight and background to understanding the motivations of the contributors over a productive lifetime, and also confirms the repeated observation of influential exposures to other innovators. The material contains interviews with investigators, peer comments about their mentoring of young investigators, snd also some very interesting background on childhood experiences. The biographical content is as interesting as the discoveries and honors discussed.
EPILOGUE
The second volume of the discoveries in medical and biological sciences series identifies many heroes of our time, just as it describes a trend of development in the related or supporting professions. The relationships have not always been clear, but a more integrated structure is emerging. The future of medical research and the practice of medicine with be more highly dependent on integrated work of professionals who have complementary skills. This is a challenge for current and future education.
UPDATED on 8/3/2021
Mission #4: Synthetic Biology: Drug Discovery targeting Galectins
- LPBI will appoint a PhD level leader for Mission #4 based in the USA and/or in India.
The intent is to:
- LPBI USA and LPBI India will develop IP on targeting 12 Galectins as therapeutics using Synthetic Biology Software in Drug Discovery 💡
- Testing the molecules by Dr. Nir in ABI Lab & SBH Sciences, Inc. wet labs
- Give Dr. Nir Right of Use
- Hosting the molecules in Blockchain Knowledge Graph Data Base
- Open up the molecules for licensing in a cyber secured confidential Auction
- Host molecules inventories from Technology Transfer Offices in several Academic centers around the Globe. We have relations to three Academic institutions in Israel, and three in the US
Applications of Synthetic Biology Software to Galectins for design of new drug molecules.
- Collaboration with Dr. Raphael Nir of ABI Lab and SBH, Inc in Natick, MA. We will have in 4Q’2021 a dedicated meeting on Mission #2.
- LPBI India will play a role in these tasks, please review:
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5877766/
- LPBI USA has interest in Synthetic Biology Software for Drug Discovery and has two scientists with expertise in Galectins as therapeutics targets
- Scientists love Synthetic Biology – designing drug molecules using Software – igem.org
A repository of open source software tools.
Community driven data exchange standards.
Specific software frameworks built explicitly for synthetic biology.
- LPBI USA will have a DropBox Folder with all the Synthetic Biology Software accessible to LPBI India
- Mentorship and training will be offered by LPBI USA
At LPBI India, been considered for the Leadership function for Mission #2: TBA
STRATEGIC PLAN for Mission #2
- We will have in 4Q’2021 a JOINT meeting between LPBI USA, LPBI India with Dr. Raphael Nir of ABI Lab and SBH, Inc in Natick, MA on Mission #2.
- A collaboration between LPBI’s Lead on Mission #2 and Dr. Nir is expected
- LPBI India Mission #2 is OPEN for all Interns of LPBI USA
- LPBI USA will grant RIGHT TO USE for the molecules developed by B2B contracts to 3rd parties
- Library of molecules will be on LPBI’s Blockchain Transactions Network
- All INTERNS will work 50% on NLP and 50% on Synthetic Biology
- Training will be offered
- Protocol will be developed
- Software applications will be selected.
- Mid September we will have an Internal Meeting on Mission #2, LPBI India before the Meeting with Dr. Nir
- All Interns need to complete at least ½ an e-Book Ten-Step Workflow Protocol for NLP before starting the Synthetic Biology SW Training
- This is the Ten-Step WORKFLOW Protocol for Medical Text Analysis using NLP at LPBI:
- https://pharmaceuticalintelligence.com/2021/07/15/workflow-for-a-ten-steps-medical-text-analysis-operation-using-nlp-on-lpbi-medical-and-life-sciences-content/
- Each INTERN Completing the 50% assignment on NLP will need to submit this table for his/hers NLP Book Assignment with a Check off mark for each article in each Chapter in the Book the intern was assigned for
- This Table filled in serves as INPUT for QA of the work of the INTERN. Verification is needed for Internship completion for Certification purposes
| NLP | Step 1 | Step 2 | Step 3 | Step 4 | Step 5 | Step 6 | Step 7 | Step 8 | Step 9 | Step 10 |
| Chapter 1, Article 1 | ||||||||||
| Chapter 1, Article n | ||||||||||
| Chapter 2 Article 1 | ||||||||||
| Chapter 2, Article n | ||||||||||
| Chapter 3, Article 1 | ||||||||||
| Chapter 3, Article n | ||||||||||
| Chapter 4 Article 1 | ||||||||||
| Chapter 4, Article n | ||||||||||
| Chapter 5, Article 1 | ||||||||||
| Chapter 5, Article n | ||||||||||
| Chapter n Article 1 | ||||||||||
| Chapter n Article n |
Author: Aviva Lev-Ari, PhD, RN, 7/23/2021
This Table is the supporting evidence for:
- (a) obtaining the Completion Certification of the NLP Internship at LPBI, start date, completion date, two signatures
- (b) Handing off of the completed assignment for additional QA Verification
- (c) Submission of PERSONAL PAGE nested under Medical Text Analysis using NLP https://pharmaceuticalintelligence.com/2021-medical-text-analysis-nlp/
- (c) Getting New Assignment in Synthetic Biology in Drug Discovery
- (d) Each Intern assigned to (c) will have a PERSONAL PAGE for recording all the milestones by date, recent at the top. This personal page will be nested under https://pharmaceuticalintelligence.com/synthetic-biology-in-drug-discovery/
We will have a Team working on a NEW WEBSITE for
- 2.0 LPBI
- Spanish BioMed e-Books
- LPBI India – nested under 2.0 LPBI
PRESENTATIONS Delivered on 7/19/2021: LPBI Launch of LPBI India
- Prof. Stephen J. Williams, LPBI USA, Chief Scientific Officer and Board Member is with LPBI USA since 9/2012 had presented
From High-Throughput Assay to Systems Biology: New Tools for Drug Discovery
Curator: Stephen J. Williams, PhD

https://pharmaceuticalintelligence.com/2021/07/19/from-high-throughput-assay-to-systems-biology-new-tools-for-drug-discovery/
- Aviva Lev-Ari, PhD, RN had presented
Engineering Life: A Review of Synthetic Biology
Author and Article Information
Artificial Life (2020) 26 (2): 260–273.
https://doi.org/10.1162/artl_a_00318
Galectins as Molecular Targets for Therapeutic Intervention
Ruud P. M. Dings,1 Michelle C. Miller,2 Robert J. Griffin,1 and Kevin H. Mayo2,*
Int J Mol Sci. 2018 Mar; 19(3): 905.
Published online 2018 Mar 19. doi: 10.3390/ijms19030905
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5877766/
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5877766/
Image Source:
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5877766/I
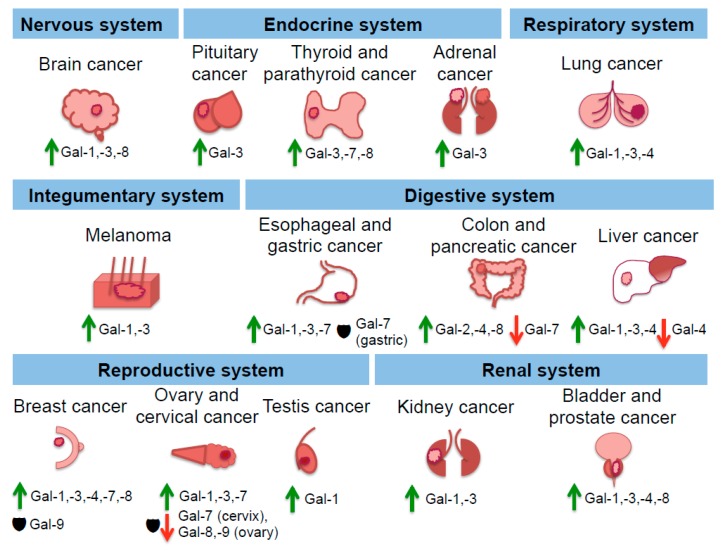
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5877766/I
Table of Human Galectins [edit]
Table Source
https://en.wikipedia.org/wiki/Galectin#Table_of_Human_Galectins
| Human galectin | Location | Function | Implication in disease |
| Galectin-1 | Secreted by immune cells such as by T helper cells in the thymus or by stromal cells surrounding B cells [7]Also found in abundance in muscle, neurons and kidney[1] | Negatively regulate B cell receptor activationActivate apoptosis in T cells[6] Suppression of Th1 and Th17 immune responses[7] Contributes to nuclear splicing of pre-mRNA[23] | Can enhance HIV infectionFound upregulated in tumour cells |
| Galectin-2 | Gastrointestinal tract [24] | Binds selectively to β-galactosides of T cells to induce apoptosis[24] | None found |
| Galectin-3 | Wide distribution | Can be pro- or anti-apoptotic (cell dependent)Regulation of some genes including JNK1 [7] Contributes to nuclear splicing of pre-mRNA[23] Crosslinking and adhesive properties In the cytoplasm, helps form the ULK1-Beclin-1-ATG16L1-TRIM16 complex following endomembrane damage[13] | Upregulation occurs in some cancers, including breast cancer, gives increased metastatic potentialImplicated in tuberculosis defense[13] |
| Galectin-4 | Intestine and stomach | Binds with high affinity to lipid rafts suggesting a role in protein delivery to cells[7] | Inflammatory bowel disease (IBD)[7] |
| Galectin-7 | Stratified squamous epithelium[7] | Differentiation of keratinocytesMay have a role in apoptosis and cellular repair mediated by p53[7] | Implications in cancer |
| Galectin-8 | Wide distribution | Binds to integrins of the extracellular matrix.[3] In the cytoplasm, alternatively binds to mTOR or forms the GALTOR complex with SLC38A9, LAMTOR1, and RagA/B[12] | Downregulation in some cancersImplicated in tuberculosis defense |
| Galectin-9 | KidneyThymus[6] Synovial fluid Macrophages | Functions as a urate transporter in the kidney [25]Induces apoptosis of thymocytes and Th1 cells[6][7] Enhances maturation of dendritic cells to secrete inflammatory cytokines. In the cytoplasm, associates upon lysosomal damage with AMPK and activates it[12] | Rheumatoid arthritisImplicated in tuberculosis defense[12][26] |
| Galectin-10 | Expressed in eosinophils and basophils | Essential role in immune system by suppression of T cell proliferation | Found in Charcot Leyden crystals in asthma |
| Galectin-12 | Adipose tissue | Stimulates apoptosis of adipocytesInvolved in adipocyte differentiation[7] | None found |
https://en.wikipedia.org/wiki/Galectin#Table_of_Human_Galectins
The Team involved in Developing Mission #2
Team Lead – TBA
Members by Geographic Locations
| Member Name | Geographical region in India Or Place of Birth in India if now outside of India | Distance from New Delhi | LANGUAGES |
| Dr (Lt Col) Vivek Lal | Ambuja Nagar, Kodinar (Sasan-Gir) Gujarat. | 1300 kms | English, Hindi |
| Yash Choudhary ???? |
Dewas (Madhya Pradesh) | 800 kms | English, Hindi |
| Dr. Premalata Pati | Bhubaneswar, Odisha | 1764 kms | English, Hindi, Odia |
| Dr. Sudipta Saha ???? | Kolkata, West Bengal | 1500 kms | English, Hindi, Bengali |
| Komal Ingle | |||
| Amandeep Kaur | Kolkata, West Bengal | 1500 kms | English, Hindi, Punjabi, Bengali |
| Vaishnavee Joshi | |||
| Madison Davis LPBI USA ???? |
|||
| Srinivas Sriram ???? |
Place of Birth: Chennai, Tamil Nadu | 2,187 kms | English, Tamil |
| Abhisar Anand ???? |
Place of Birth: Muzaffarpur, Bihar | 1,042 kms | English, Hindi |
| Danielle Smolyar LPBI USA ???? |
|||
| Ethan Coomber LPBI USA ???? |
Curator: Amandeep Kaur
India’s Map & Distribution of Team Members for Mission #2
Map Curators: Srinivas Sriram and Abhisar Anand
INSERT MAP HERE
Team Expertise with Pharmaceutics
Pharmacology:
Dr. Stephen J. Williams, PhD
Pharmacology and Clinical Trials:
Dr. Vivek Lal, MD
Glycobiology:
Dr. Ofer Markman, PhD
Molecular Cardiology:
Dr. Vivek Lal, MD
Dr. Aviva Lev-Ari, PhD, RN
Alumni of Big Pharma:
Dr. John McCarthy, MD, PhD, ex-Pfizer, External Scientific Relations to LPBI
Dr. Raphael Nir, PhD, ex-Schering-Plough, External Scientific Relations to LPBI
Drug Repurposing and Clinical Trials:
Dr. Ajay Gupta, MD, External Scientific Relations to LPBI
Prof. Saul Yedgar, PhD, External Scientific Relations to LPBI
Dr. Yigal Blum, PhD, External Scientific Relations to LPBI
List Source:
Curator: Aviva Lev-Ari, PhD, RN