
Disease related changes in proteomics, protein folding, protein-protein interaction
Curator: Larry H. Bernstein, MD, FCAP
LPBI
Frankenstein Proteins Stitched Together by Scientists
The Frankenstein monster, stitched together from disparate body parts, proved to be an abomination, but stitched together proteins may fare better. They may, for example, serve specific purposes in medicine, research, and industry. At least, that’s the ambition of scientists based at the University of North Carolina. They have developed a computational protocol called SEWING that builds new proteins from connected or disconnected pieces of existing structures. [Wikipedia]
Unlike Victor Frankenstein, who betrayed Promethean ambition when he sewed together his infamous creature, today’s biochemists are relatively modest. Rather than defy nature, they emulate it. For example, at the University of North Carolina (UNC), researchers have taken inspiration from natural evolutionary mechanisms to develop a technique called SEWING—Structure Extension With Native-substructure Graphs. SEWING is a computational protocol that describes how to stitch together new proteins from connected or disconnected pieces of existing structures.
“We can now begin to think about engineering proteins to do things that nothing else is capable of doing,” said UNC’s Brian Kuhlman, Ph.D. “The structure of a protein determines its function, so if we are going to learn how to design new functions, we have to learn how to design new structures. Our study is a critical step in that direction and provides tools for creating proteins that haven’t been seen before in nature.”
Traditionally, researchers have used computational protein design to recreate in the laboratory what already exists in the natural world. In recent years, their focus has shifted toward inventing novel proteins with new functionality. These design projects all start with a specific structural “blueprint” in mind, and as a result are limited. Dr. Kuhlman and his colleagues, however, believe that by removing the limitations of a predetermined blueprint and taking cues from evolution they can more easily create functional proteins.
Dr. Kuhlman’s UNC team developed a protein design approach that emulates natural mechanisms for shuffling tertiary structures such as pleats, coils, and furrows. Putting the approach into action, the UNC team mapped 50,000 stitched together proteins on the computer, and then it produced 21 promising structures in the laboratory. Details of this work appeared May 6 in the journal Science, in an article entitled, “Design of Structurally Distinct Proteins Using Strategies Inspired by Evolution.”
“Helical proteins designed with SEWING contain structural features absent from other de novo designed proteins and, in some cases, remain folded at more than 100°C,” wrote the authors. “High-resolution structures of the designed proteins CA01 and DA05R1 were solved by x-ray crystallography (2.2 angstrom resolution) and nuclear magnetic resonance, respectively, and there was excellent agreement with the design models.”
Essentially, the UNC scientists confirmed that the proteins they had synthesized contained the unique structural varieties that had been designed on the computer. The UNC scientists also determined that the structures they had created had new surface and pocket features. Such features, they noted, provide potential binding sites for ligands or macromolecules.
“We were excited that some had clefts or grooves on the surface, regions that naturally occurring proteins use for binding other proteins,” said the Science article’s first author, Tim M. Jacobs, Ph.D., a former graduate student in Dr. Kuhlman’s laboratory. “That’s important because if we wanted to create a protein that can act as a biosensor to detect a certain metabolite in the body, either for diagnostic or research purposes, it would need to have these grooves. Likewise, if we wanted to develop novel therapeutics, they would also need to attach to specific proteins.”
Currently, the UNC researchers are using SEWING to create proteins that can bind to several other proteins at a time. Many of the most important proteins are such multitaskers, including the blood protein hemoglobin.
Histone Mutation Deranges DNA Methylation to Cause Cancer
In some cancers, including chondroblastoma and a rare form of childhood sarcoma, a mutation in histone H3 reduces global levels of methylation (dark areas) in tumor cells but not in normal cells (arrowhead). The mutation locks the cells in a proliferative state to promote tumor development. [Laboratory of Chromatin Biology and Epigenetics at The Rockefeller University]
They have been called oncohistones, the mutated histones that are known to accompany certain pediatric cancers. Despite their suggestive moniker, oncohistones have kept their oncogenic secrets. For example, it has been unclear whether oncohistones are able to cause cancer on their own, or whether they need to act in concert with additional DNA mutations, that is, mutations other than those affecting histone structures.
While oncohistone mechanisms remain poorly understood, this particular question—the oncogenicity of lone oncohistones—has been resolved, at least in part. According to researchers based at The Rockefeller University, a change to the structure of a histone can trigger a tumor on its own.
This finding appeared May 13 in the journal Science, in an article entitled, “Histone H3K36 Mutations Promote Sarcomagenesis Through Altered Histone Methylation Landscape.” The article describes the Rockefeller team’s study of a histone protein called H3, which has been found in about 95% of samples of chondoblastoma, a benign tumor that arises in cartilage, typically during adolescence.
The Rockefeller scientists found that the H3 lysine 36–to–methionine (H3K36M) mutation impairs the differentiation of mesenchymal progenitor cells and generates undifferentiated sarcoma in vivo.
After the scientists inserted the H3 histone mutation into mouse mesenchymal progenitor cells (MPCs)—which generate cartilage, bone, and fat—they watched these cells lose the ability to differentiate in the lab. Next, the scientists injected the mutant cells into living mice, and the animals developed the tumors rich in MPCs, known as an undifferentiated sarcoma. Finally, the researchers tried to understand how the mutation causes the tumors to develop.
The scientists determined that H3K36M mutant nucleosomes inhibit the enzymatic activities of several H3K36 methyltransferases.
“Depleting H3K36 methyltransferases, or expressing an H3K36I mutant that similarly inhibits H3K36 methylation, is sufficient to phenocopy the H3K36M mutation,” the authors of the Science study wrote. “After the loss of H3K36 methylation, a genome-wide gain in H3K27 methylation leads to a redistribution of polycomb repressive complex 1 and de-repression of its target genes known to block mesenchymal differentiation.”
Essentially, when the H3K36M mutation occurs, the cell becomes locked in a proliferative state—meaning it divides constantly, leading to tumors. Specifically, the mutation inhibits enzymes that normally tag the histone with chemical groups known as methyls, allowing genes to be expressed normally.
In response to this lack of modification, another part of the histone becomes overmodified, or tagged with too many methyl groups. “This leads to an overall resetting of the landscape of chromatin, the complex of DNA and its associated factors, including histones,” explained co-author Peter Lewis, Ph.D., a professor at the University of Wisconsin-Madison and a former postdoctoral fellow in laboratory of C. David Allis, Ph.D., a professor at Rockefeller.
The finding—that a “resetting” of the chromatin landscape can lock the cell into a proliferative state—suggests that researchers should be on the hunt for more mutations in histones that might be driving tumors. For their part, the Rockefeller researchers are trying to learn more about how this specific mutation in histone H3 causes tumors to develop.
“We want to know which pathways cause the mesenchymal progenitor cells that carry the mutation to continue to divide, and not differentiate into the bone, fat, and cartilage cells they are destined to become,” said co-author Chao Lu, Ph.D., a postdoctoral fellow in the Allis lab.
Once researchers understand more about these pathways, added Dr. Lewis, they can consider ways of blocking them with drugs, particularly in tumors such as MPC-rich sarcomas—which, unlike chondroblastoma, can be deadly. In fact, drugs that block these pathways may already exist and may even be in use for other types of cancers.
“One long-term goal of our collaborative team is to better understand fundamental mechanisms that drive these processes, with the hope of providing new therapeutic approaches,” concluded Dr. Allis.
Histone H3K36 mutations promote sarcomagenesis through altered histone methylation landscape
Chao Lu, Siddhant U. Jain, Dominik Hoelper, …, C. David Allis1,†, Nada Jabado,†, Peter W. Lewis,†
Science 13 May 2016; 352(6287):844-849 http://dx.doi.org:/10.1126/science.aac7272 http://science.sciencemag.org/content/352/6287/844
An oncohistone deranges inhibitory chromatin
Missense mutations (that change one amino acid for another) in histone H3 can produce a so-called oncohistone and are found in a number of pediatric cancers. For example, the lysine-36–to-methionine (K36M) mutation is seen in almost all chondroblastomas. Lu et al. show that K36M mutant histones are oncogenic, and they inhibit the normal methylation of this same residue in wild-type H3 histones. The mutant histones also interfere with the normal development of bone-related cells and the deposition of inhibitory chromatin marks.
Science, this issue p. 844
Several types of pediatric cancers reportedly contain high-frequency missense mutations in histone H3, yet the underlying oncogenic mechanism remains poorly characterized. Here we report that the H3 lysine 36–to–methionine (H3K36M) mutation impairs the differentiation of mesenchymal progenitor cells and generates undifferentiated sarcoma in vivo. H3K36M mutant nucleosomes inhibit the enzymatic activities of several H3K36 methyltransferases. Depleting H3K36 methyltransferases, or expressing an H3K36I mutant that similarly inhibits H3K36 methylation, is sufficient to phenocopy the H3K36M mutation. After the loss of H3K36 methylation, a genome-wide gain in H3K27 methylation leads to a redistribution of polycomb repressive complex 1 and de-repression of its target genes known to block mesenchymal differentiation. Our findings are mirrored in human undifferentiated sarcomas in which novel K36M/I mutations in H3.1 are identified.
Mitochondria? We Don’t Need No Stinking Mitochondria!
| http://www.genengnews.com/Media/images/GENHighlight/thumb_fx11801711851.jpg |
| Diagram comparing typical eukaryotic cell to the newly discovered mitochondria-free organism. [Karnkowska et al., 2016, Current Biology 26, 1–11] |
- The organelle that produces a significant portion of energy for eukaryotic cells would seemingly be indispensable, yet over the years, a number of organisms have been discovered that challenge that biological pretense. However, these so-called amitochondrial species may lack a defined organelle, but they still retain some residual functions of their mitochondria-containing brethren. Even the intestinal eukaryotic parasite Giardia intestinalis, which was for many years considered to be mitochondria-free, was proven recently to contain a considerably shriveled version of the organelle.
- Now, an international group of scientists has released results from a new study that challenges the notion that mitochondria are essential for eukaryotes—discovering an organism that resides in the gut of chinchillas that contains absolutely no trace of mitochondria at all.
- “In low-oxygen environments, eukaryotes often possess a reduced form of the mitochondrion, but it was believed that some of the mitochondrial functions are so essential that these organelles are indispensable for their life,” explained lead study author Anna Karnkowska, Ph.D., visiting scientist at the University of British Columbia in Vancouver. “We have characterized a eukaryotic microbe which indeed possesses no mitochondrion at all.”
Mysterious Eukaryote Missing Mitochondria
Researchers uncover the first example of a eukaryotic organism that lacks the organelles.
By Anna Azvolinsky | May 12, 2016
http://www.the-scientist.com/images/News/May2016/620_Monocercomonides-Pa203.jpg
Monocercomonoides sp. PA203VLADIMIR HAMPL, CHARLES UNIVERSITY, PRAGUE, CZECH REPUBLIC
Scientists have long thought that mitochondria—organelles responsible for energy generation—are an essential and defining feature of a eukaryotic cell. Now, researchers from Charles University in Prague and their colleagues are challenging this notion with their discovery of a eukaryotic organism,Monocercomonoides species PA203, which lacks mitochondria. The team’s phylogenetic analysis, published today (May 12) in Current Biology,suggests that Monocercomonoides—which belong to the Oxymonadida group of protozoa and live in low-oxygen environments—did have mitochondria at one point, but eventually lost the organelles.
“This is quite a groundbreaking discovery,” said Thijs Ettema, who studies microbial genome evolution at Uppsala University in Sweden and was not involved in the work.
“This study shows that mitochondria are not so central for all lineages of living eukaryotes,” Toni Gabaldonof the Center for Genomic Regulation in Barcelona, Spain, who also was not involved in the work, wrote in an email to The Scientist. “Yet, this mitochondrial-devoid, single-cell eukaryote is as complex as other eukaryotic cells in almost any other aspect of cellular complexity.”
Charles University’s Vladimir Hampl studies the evolution of protists. Along with Anna Karnkowska and colleagues, Hampl decided to sequence the genome of Monocercomonoides, a little-studied protist that lives in the digestive tracts of vertebrates. The 75-megabase genome—the first of an oxymonad—did not contain any conserved genes found on mitochondrial genomes of other eukaryotes, the researchers found. It also did not contain any nuclear genes associated with mitochondrial functions.
“It was surprising and for a long time, we didn’t believe that the [mitochondria-associated genes were really not there]. We thought we were missing something,” Hampl told The Scientist. “But when the data kept accumulating, we switched to the hypothesis that this organism really didn’t have mitochondria.”
Because researchers have previously not found examples of eukaryotes without some form of mitochondria, the current theory of the origin of eukaryotes poses that the appearance of mitochondria was crucial to the identity of these organisms.
“We now view these mitochondria-like organelles as a continuum from full mitochondria to very small . Some anaerobic protists, for example, have only pared down versions of mitochondria, such as hydrogenosomes and mitosomes, which lack a mitochondrial genome. But these mitochondrion-like organelles perform essential functions of the iron-sulfur cluster assembly pathway, which is known to be conserved in virtually all eukaryotic organisms studied to date.
Yet, in their analysis, the researchers found no evidence of the presence of any components of this mitochondrial pathway.
Like the scaling down of mitochondria into mitosomes in some organisms, the ancestors of modernMonocercomonoides once had mitochondria. “Because this organism is phylogenetically nested among relatives that had conventional mitochondria, this is most likely a secondary adaptation,” said Michael Gray, a biochemist who studies mitochondria at Dalhousie University in Nova Scotia and was not involved in the study. According to Gray, the finding of a mitochondria-deficient eukaryote does not mean that the organelles did not play a major role in the evolution of eukaryotic cells.
To be sure they were not missing mitochondrial proteins, Hampl’s team also searched for potential mitochondrial protein homologs of other anaerobic species, and for signature sequences of a range of known mitochondrial proteins. While similar searches with other species uncovered a few mitochondrial proteins, the team’s analysis of Monocercomonoides came up empty.
“The data is very complete,” said Ettema. “It is difficult to prove the absence of something but [these authors] do a convincing job.”
To form the essential iron-sulfur clusters, the team discovered that Monocercomonoides use a sulfur mobilization system found in the cytosol, and that an ancestor of the organism acquired this system by lateral gene transfer from bacteria. This cytosolic, compensating system allowed Monocercomonoides to lose the otherwise essential iron-sulfur cluster-forming pathway in the mitochondrion, the team proposed.
“This work shows the great evolutionary plasticity of the eukaryotic cell,” said Karnkowska, who participated in the study while she was a postdoc at Charles University. Karnkowska, who is now a visiting researcher at the University of British Columbia in Canada, added: “This is a striking example of how far the evolution of a eukaryotic cell can go that was beyond our expectations.”
“The results highlight how many surprises may await us in the poorly studied eukaryotic phyla that live in under-explored environments,” Gabaldon said.
Ettema agreed. “Now that we’ve found one, we need to look at the bigger picture and see if there are other examples of eukaryotes that have lost their mitochondria, to understand how adaptable eukaryotes are.”
- Karnkowska et al., “A eukaryote without a mitochondrial organelle,” Current Biology,doi:10.1016/j.cub.2016.03.053, 2016.
organelles, mitochondria, genetics & genomics and evolution
A Eukaryote without a Mitochondrial Organelle
Anna Karnkowska, Vojtěch Vacek, Zuzana Zubáčová,…, Čestmír Vlček, Vladimír HamplDOI: http://dx.doi.org/10.1016/j.cub.2016.03.053 Article Info
PDF (2 MB) Extended PDF (2 MB) Download Images(.ppt) About Images & Usage
Highlights
- •Monocercomonoides sp. is a eukaryotic microorganism with no mitochondria
- •The complete absence of mitochondria is a secondary loss, not an ancestral feature
- •The essential mitochondrial ISC pathway was replaced by a bacterial SUF system
The presence of mitochondria and related organelles in every studied eukaryote supports the view that mitochondria are essential cellular components. Here, we report the genome sequence of a microbial eukaryote, the oxymonad Monocercomonoides sp., which revealed that this organism lacks all hallmark mitochondrial proteins. Crucially, the mitochondrial iron-sulfur cluster assembly pathway, thought to be conserved in virtually all eukaryotic cells, has been replaced by a cytosolic sulfur mobilization system (SUF) acquired by lateral gene transfer from bacteria. In the context of eukaryotic phylogeny, our data suggest that Monocercomonoides is not primitively amitochondrial but has lost the mitochondrion secondarily. This is the first example of a eukaryote lacking any form of a mitochondrion, demonstrating that this organelle is not absolutely essential for the viability of a eukaryotic cell.
http://www.cell.com/cms/attachment/2056332410/2061316405/fx1.jpg
HIV Particles Used to Trap Intact Mammalian Protein Complexes
Belgian scientists from VIB and UGent developed Virotrap, a viral particle sorting approach for purifying protein complexes under native conditions.
http://www.technologynetworks.com/Proteomics/news.aspx?ID=191122
This method catches a bait protein together with its associated protein partners in virus-like particles that are budded from human cells. Like this, cell lysis is not needed and protein complexes are preserved during purification.
With his feet in both a proteomics lab and an interactomics lab, VIB/UGent professor Sven Eyckerman is well aware of the shortcomings of conventional approaches to analyze protein complexes. The lysis conditions required in mass spectrometry–based strategies to break open cell membranes often affect protein-protein interactions. “The first step in a classical study on protein complexes essentially turns the highly organized cellular structure into a big messy soup”, Eyckerman explains.
Inspired by virus biology, Eyckerman came up with a creative solution. “We used the natural process of HIV particle formation to our benefit by hacking a completely safe form of the virus to abduct intact protein machines from the cell.” It is well known that the HIV virus captures a number of host proteins during its particle formation. By fusing a bait protein to the HIV-1 GAG protein, interaction partners become trapped within virus-like particles that bud from mammalian cells. Standard proteomic approaches are used next to reveal the content of these particles. Fittingly, the team named the method ‘Virotrap’.
The Virotrap approach is exceptional as protein networks can be characterized under natural conditions. By trapping protein complexes in the protective environment of a virus-like shell, the intact complexes are preserved during the purification process. The researchers showed the method was suitable for detection of known binary interactions as well as mass spectrometry-based identification of novel protein partners.
Virotrap is a textbook example of bringing research teams with complementary expertise together. Cross-pollination with the labs of Jan Tavernier (VIB/UGent) and Kris Gevaert (VIB/UGent) enabled the development of this platform.
Jan Tavernier: “Virotrap represents a new concept in co-complex analysis wherein complex stability is physically guaranteed by a protective, physical structure. It is complementary to the arsenal of existing interactomics methods, but also holds potential for other fields, like drug target characterization. We also developed a small molecule-variant of Virotrap that could successfully trap protein partners for small molecule baits.”
Kris Gevaert: “Virotrap can also impact our understanding of disease pathways. We were actually surprised to see that this virus-based system could be used to study antiviral pathways, like Toll-like receptor signaling. Understanding these protein machines in their natural environment is essential if we want to modulate their activity in pathology.“
Trapping mammalian protein complexes in viral particles
Sven Eyckerman, Kevin Titeca, …Kris Gevaert & Jan Tavernier
Nature Communications Apr 2016; 7(11416) http://dx.doi.org:/10.1038/ncomms11416
Cell lysis is an inevitable step in classical mass spectrometry–based strategies to analyse protein complexes. Complementary lysis conditions, in situ cross-linking strategies and proximal labelling techniques are currently used to reduce lysis effects on the protein complex. We have developed Virotrap, a viral particle sorting approach that obviates the need for cell homogenization and preserves the protein complexes during purification. By fusing a bait protein to the HIV-1 GAG protein, we show that interaction partners become trapped within virus-like particles (VLPs) that bud from mammalian cells. Using an efficient VLP enrichment protocol, Virotrap allows the detection of known binary interactions and MS-based identification of novel protein partners as well. In addition, we show the identification of stimulus-dependent interactions and demonstrate trapping of protein partners for small molecules. Virotrap constitutes an elegant complementary approach to the arsenal of methods to study protein complexes.
Proteins mostly exert their function within supramolecular complexes. Strategies for detecting protein–protein interactions (PPIs) can be roughly divided into genetic systems1 and co-purification strategies combined with mass spectrometry (MS) analysis (for example, AP–MS)2. The latter approaches typically require cell or tissue homogenization using detergents, followed by capture of the protein complex using affinity tags3 or specific antibodies4. The protein complexes extracted from this ‘soup’ of constituents are then subjected to several washing steps before actual analysis by trypsin digestion and liquid chromatography–MS/MS analysis. Such lysis and purification protocols are typically empirical and have mostly been optimized using model interactions in single labs. In fact, lysis conditions can profoundly affect the number of both specific and nonspecific proteins that are identified in a typical AP–MS set-up. Indeed, recent studies using the nuclear pore complex as a model protein complex describe optimization of purifications for the different proteins in the complex by examining 96 different conditions5. Nevertheless, for new purifications, it remains hard to correctly estimate the loss of factors in a standard AP–MS experiment due to washing and dilution effects during treatments (that is, false negatives). These considerations have pushed the concept of stabilizing PPIs before the actual homogenization step. A classical approach involves cross-linking with simple reagents (for example, formaldehyde) or with more advanced isotope-labelled cross-linkers (reviewed in ref. 2). However, experimental challenges such as cell permeability and reactivity still preclude the widespread use of cross-linking agents. Moreover, MS-generated spectra of cross-linked peptides are notoriously difficult to identify correctly. A recent lysis-independent solution involves the expression of a bait protein fused to a promiscuous biotin ligase, which results in labelling of proteins proximal to the activity of the enzyme-tagged bait protein6. When compared with AP–MS, this BioID approach delivers a complementary set of candidate proteins, including novel interaction partners7, 8. Such particular studies clearly underscore the need for complementary approaches in the co-complex strategies.
The evolutionary stress on viruses promoted highly condensed coding of information and maximal functionality for small genomes. Accordingly, for HIV-1 it is sufficient to express a single protein, the p55 GAG protein, for efficient production of virus-like particles (VLPs) from cells9, 10. This protein is highly mobile before its accumulation in cholesterol-rich regions of the membrane, where multimerization initiates the budding process11. A total of 4,000–5,000 GAG molecules is required to form a single particle of about 145 nm (ref. 12). Both VLPs and mature viruses contain a number of host proteins that are recruited by binding to viral proteins. These proteins can either contribute to the infectivity (for example, Cyclophilin/FKBPA13) or act as antiviral proteins preventing the spreading of the virus (for example, APOBEC proteins14).
We here describe the development and application of Virotrap, an elegant co-purification strategy based on the trapping of a bait protein together with its associated protein partners in VLPs that are budded from the cell. After enrichment, these particles can be analysed by targeted (for example, western blotting) or unbiased approaches (MS-based proteomics). Virotrap allows detection of known binary PPIs, analysis of protein complexes and their dynamics, and readily detects protein binders for small molecules.
Concept of the Virotrap system
Classical AP–MS approaches rely on cell homogenization to access protein complexes, a step that can vary significantly with the lysis conditions (detergents, salt concentrations, pH conditions and so on)5. To eliminate the homogenization step in AP–MS, we reasoned that incorporation of a protein complex inside a secreted VLP traps the interaction partners under native conditions and protects them during further purification. We thus explored the possibility of protein complex packaging by the expression of GAG-bait protein chimeras (Fig. 1) as expression of GAG results in the release of VLPs from the cells9, 10. As a first PPI pair to evaluate this concept, we selected the HRAS protein as a bait combined with the RAF1 prey protein. We were able to specifically detect the HRAS–RAF1 interaction following enrichment of VLPs via ultracentrifugation (Supplementary Fig. 1a). To prevent tedious ultracentrifugation steps, we designed a novel single-step protocol wherein we co-express the vesicular stomatitis virus glycoprotein (VSV-G) together with a tagged version of this glycoprotein in addition to the GAG bait and prey. Both tagged and untagged VSV-G proteins are probably presented as trimers on the surface of the VLPs, allowing efficient antibody-based recovery from large volumes. The HRAS–RAF1 interaction was confirmed using this single-step protocol (Supplementary Fig. 1b). No associations with unrelated bait or prey proteins were observed for both protocols.
Figure 1: Schematic representation of the Virotrap strategy.
http://www.nature.com/ncomms/2016/160428/ncomms11416/images_article/ncomms11416-f1.jpg
Expression of a GAG-bait fusion protein (1) results in submembrane multimerization (2) and subsequent budding of VLPs from cells (3). Interaction partners of the bait protein are also trapped within these VLPs and can be identified after purification by western blotting or MS analysis (4).
Virotrap for the detection of binary interactions
We next explored the reciprocal detection of a set of PPI pairs, which were selected based on published evidence and cytosolic localization15. After single-step purification and western blot analysis, we could readily detect reciprocal interactions between CDK2 and CKS1B, LCP2 and GRAP2, and S100A1 and S100B (Fig. 2a). Only for the LCP2 prey we observed nonspecific association with an irrelevant bait construct. However, the particle levels of the GRAP2 bait were substantially lower as compared with those of the GAG control construct (GAG protein levels in VLPs; Fig. 2a, second panel of the LCP2 prey). After quantification of the intensities of bait and prey proteins and normalization of prey levels using bait levels, we observed a strong enrichment for the GAG-GRAP2 bait (Supplementary Fig. 2).
…..
Virotrap for unbiased discovery of novel interactions
For the detection of novel interaction partners, we scaled up VLP production and purification protocols (Supplementary Fig. 5 and Supplementary Note 1 for an overview of the protocol) and investigated protein partners trapped using the following bait proteins: Fas-associated via death domain (FADD), A20 (TNFAIP3), nuclear factor-κB (NF-κB) essential modifier (IKBKG), TRAF family member-associated NF-κB activator (TANK), MYD88 and ring finger protein 41 (RNF41). To obtain specific interactors from the lists of identified proteins, we challenged the data with a combined protein list of 19 unrelated Virotrap experiments (Supplementary Table 1 for an overview). Figure 3 shows the design and the list of candidate interactors obtained after removal of all proteins that were found in the 19 control samples (including removal of proteins from the control list identified with a single peptide). The remaining list of confident protein identifications (identified with at least two peptides in at least two biological repeats) reveals both known and novel candidate interaction partners. All candidate interactors including single peptide protein identifications are given in Supplementary Data 2 and also include recurrent protein identifications of known interactors based on a single peptide; for example, CASP8 for FADD and TANK for NEMO. Using alternative methods, we confirmed the interaction between A20 and FADD, and the associations with transmembrane proteins (insulin receptor and insulin-like growth factor receptor 1) that were captured using RNF41 as a bait (Supplementary Fig. 6). To address the use of Virotrap for the detection of dynamic interactions, we activated the NF-κB pathway via the tumour necrosis factor (TNF) receptor (TNFRSF1A) using TNFα (TNF) and performed Virotrap analysis using A20 as bait (Fig. 3). This resulted in the additional enrichment of receptor-interacting kinase (RIPK1), TNFR1-associated via death domain (TRADD), TNFRSF1A and TNF itself, confirming the expected activated complex20.
Figure 3: Use of Virotrap for unbiased interactome analysis
http://www.nature.com/ncomms/2016/160428/ncomms11416/images_article/ncomms11416-f3.jpg
Figure 4: Use of Virotrap for detection of protein partners of small molecules.
http://www.nature.com/ncomms/2016/160428/ncomms11416/images_article/ncomms11416-f4.jpg
….
Lysis conditions used in AP–MS strategies are critical for the preservation of protein complexes. A multitude of lysis conditions have been described, culminating in a recent report where protein complex stability was assessed under 96 lysis/purification protocols5. Moreover, the authors suggest to optimize the conditions for every complex, implying an important workload for researchers embarking on protein complex analysis using classical AP–MS. As lysis results in a profound change of the subcellular context and significantly alters the concentration of proteins, loss of complex integrity during a classical AP–MS protocol can be expected. A clear evolution towards ‘lysis-independent’ approaches in the co-complex analysis field is evident with the introduction of BioID6 and APEX25 where proximal proteins, including proteins residing in the complex, are labelled with biotin by an enzymatic activity fused to a bait protein. A side-by-side comparison between classical AP–MS and BioID showed overlapping and unique candidate binding proteins for both approaches7, 8, supporting the notion that complementary methods are needed to provide a comprehensive view on protein complexes. This has also been clearly demonstrated for binary approaches15 and is a logical consequence of the heterogenic nature underlying PPIs (binding mechanism, requirement for posttranslational modifications, location, affinity and so on).
In this report, we explore an alternative, yet complementary method to isolate protein complexes without interfering with cellular integrity. By trapping protein complexes in the protective environment of a virus-like shell, the intact complexes are preserved during the purification process. This constitutes a new concept in co-complex analysis wherein complex stability is physically guaranteed by a protective, physical structure. A comparison of our Virotrap approach with AP–MS shows complementary data, with specific false positives and false negatives for both methods (Supplementary Fig. 7).
The current implementation of the Virotrap platform implies the use of a GAG-bait construct resulting in considerable expression of the bait protein. Different strategies are currently pursued to reduce bait expression including co-expression of a native GAG protein together with the GAG-bait protein, not only reducing bait expression but also creating more ‘space’ in the particles potentially accommodating larger bait protein complexes. Nevertheless, the presence of the bait on the forming GAG scaffold creates an intracellular affinity matrix (comparable to the early in vitro affinity columns for purification of interaction partners from lysates26) that has the potential to compete with endogenous complexes by avidity effects. This avidity effect is a powerful mechanism that aids in the recruitment of cyclophilin to GAG27, a well-known weak interaction (Kd=16 μM (ref. 28)) detectable as a background association in the Virotrap system. Although background binding may be increased by elevated bait expression, weaker associations are readily detectable (for example, MAL—MYD88-binding study; Fig. 2c).
The size of Virotrap particles (around 145 nm) suggests limitations in the size of the protein complex that can be accommodated in the particles. Further experimentation is required to define the maximum size of proteins or the number of protein complexes that can be trapped inside the particles.
….
In conclusion, Virotrap captures significant parts of known interactomes and reveals new interactions. This cell lysis-free approach purifies protein complexes under native conditions and thus provides a powerful method to complement AP–MS or other PPI data. Future improvements of the system include strategies to reduce bait expression to more physiological levels and application of advanced data analysis options to filter out background. These developments can further aid in the deployment of Virotrap as a powerful extension of the current co-complex technology arsenal.
New Autism Blood Biomarker Identified
Researchers at UT Southwestern Medical Center have identified a blood biomarker that may aid in earlier diagnosis of children with autism spectrum disorder, or ASD
http://www.technologynetworks.com/Proteomics/news.aspx?ID=191268
In a recent edition of Scientific Reports, UT Southwestern researchers reported on the identification of a blood biomarker that could distinguish the majority of ASD study participants versus a control group of similar age range. In addition, the biomarker was significantly correlated with the level of communication impairment, suggesting that the blood test may give insight into ASD severity.
“Numerous investigators have long sought a biomarker for ASD,” said Dr. Dwight German, study senior author and Professor of Psychiatry at UT Southwestern. “The blood biomarker reported here along with others we are testing can represent a useful test with over 80 percent accuracy in identifying ASD.”
ASD1 – was 66 percent accurate in diagnosing ASD. When combined with thyroid stimulating hormone level measurements, the ASD1-binding biomarker was 73 percent accurate at diagnosis
A Search for Blood Biomarkers for Autism: Peptoids
Sayed Zaman, Umar Yazdani,…, Laura Hewitson & Dwight C. German
Scientific Reports 2016; 6(19164) http://dx.doi.org:/10.1038/srep19164
Autism spectrum disorder (ASD) is a neurodevelopmental disorder characterized by impairments in social interaction and communication, and restricted, repetitive patterns of behavior. In order to identify individuals with ASD and initiate interventions at the earliest possible age, biomarkers for the disorder are desirable. Research findings have identified widespread changes in the immune system in children with autism, at both systemic and cellular levels. In an attempt to find candidate antibody biomarkers for ASD, highly complex libraries of peptoids (oligo-N-substituted glycines) were screened for compounds that preferentially bind IgG from boys with ASD over typically developing (TD) boys. Unexpectedly, many peptoids were identified that preferentially bound IgG from TD boys. One of these peptoids was studied further and found to bind significantly higher levels (>2-fold) of the IgG1 subtype in serum from TD boys (n = 60) compared to ASD boys (n = 74), as well as compared to older adult males (n = 53). Together these data suggest that ASD boys have reduced levels (>50%) of an IgG1 antibody, which resembles the level found normally with advanced age. In this discovery study, the ASD1 peptoid was 66% accurate in predicting ASD.
….
Peptoid libraries have been used previously to search for autoantibodies for neurodegenerative diseases19 and for systemic lupus erythematosus (SLE)21. In the case of SLE, peptoids were identified that could identify subjects with the disease and related syndromes with moderate sensitivity (70%) and excellent specificity (97.5%). Peptoids were used to measure IgG levels from both healthy subjects and SLE patients. Binding to the SLE-peptoid was significantly higher in SLE patients vs. healthy controls. The IgG bound to the SLE-peptoid was found to react with several autoantigens, suggesting that the peptoids are capable of interacting with multiple, structurally similar molecules. These data indicate that IgG binding to peptoids can identify subjects with high levels of pathogenic autoantibodies vs. a single antibody.
In the present study, the ASD1 peptoid binds significantly lower levels of IgG1 in ASD males vs. TD males. This finding suggests that the ASD1 peptoid recognizes antibody(-ies) of an IgG1 subtype that is (are) significantly lower in abundance in the ASD males vs. TD males. Although a previous study14 has demonstrated lower levels of plasma IgG in ASD vs. TD children, here, we additionally quantified serum IgG levels in our individuals and found no difference in IgG between the two groups (data not shown). Furthermore, our IgG levels did not correlate with ASD1 binding levels, indicating that ASD1 does not bind IgG generically, and that the peptoid’s ability to differentiate between ASD and TD males is related to a specific antibody(-ies).
ASD subjects underwent a diagnostic evaluation using the ADOS and ADI-R, and application of the DSM-IV criteria prior to study inclusion. Only those subjects with a diagnosis of Autistic Disorder were included in the study. The ADOS is a semi-structured observation of a child’s behavior that allows examiners to observe the three core domains of ASD symptoms: reciprocal social interaction, communication, and restricted and repetitive behaviors1. When ADOS subdomain scores were compared with peptoid binding, the only significant relationship was with Social Interaction. However, the positive correlation would suggest that lower peptoid binding is associated with better social interaction, not poorer social interaction as anticipated.
The ADI-R is a structured parental interview that measures the core features of ASD symptoms in the areas of reciprocal social interaction, communication and language, and patterns of behavior. Of the three ADI-R subdomains, only the Communication domain was related to ASD1 peptoid binding, and this correlation was negative suggesting that low peptoid binding is associated with greater communication problems. These latter data are similar to the findings of Heuer et al.14 who found that children with autism with low levels of plasma IgG have high scores on the Aberrant Behavior Checklist (p < 0.0001). Thus, peptoid binding to IgG1 may be useful as a severity marker for ASD allowing for further characterization of individuals, but further research is needed.
It is interesting that in serum samples from older men, the ASD1 binding is similar to that in the ASD boys. This is consistent with the observation that with aging there is a reduction in the strength of the immune system, and the changes are gender-specific25. Recent studies using parabiosis26, in which blood from young mice reverse age-related impairments in cognitive function and synaptic plasticity in old mice, reveal that blood constituents from young subjects may contain important substances for maintaining neuronal functions. Work is in progress to identify the antibody/antibodies that are differentially binding to the ASD1 peptoid, which appear as a single band on the electrophoresis gel (Fig. 4).
……..
The ADI-R is a structured parental interview that measures the core features of ASD symptoms in the areas of reciprocal social interaction, communication and language, and patterns of behavior. Of the three ADI-R subdomains, only the Communication domain was related to ASD1 peptoid binding, and this correlation was negative suggesting that low peptoid binding is associated with greater communication problems. These latter data are similar to the findings of Heuer et al.14 who found that children with autism with low levels of plasma IgG have high scores on the Aberrant Behavior Checklist (p < 0.0001). Thus, peptoid binding to IgG1 may be useful as a severity marker for ASD allowing for further characterization of individuals, but further research is needed.
- Titration of IgG binding to ASD1 using serum pooled from 10 TD males and 10 ASD males demonstrates ASD1’s ability to differentiate between the two groups. (B)Detecting IgG1 subclass instead of total IgG amplifies this differentiation. (C) IgG1 binding of individual ASD (n=74) and TD (n=60) male serum samples (1:100 dilution) to ASD1 significantly differs with TD>ASD. In addition, IgG1 binding of older adult male (AM) serum samples (n=53) to ASD1 is significantly lower than TD males, and not different from ASD males. The three groups were compared with a Kruskal-Wallis ANOVA, H = 10.1781, p<0.006. **p<0.005. Error bars show SEM. (D) Receiver-operating characteristic curve for ASD1’s ability to discriminate between ASD and TD males.
Association between peptoid binding and ADOS and ADI-R subdomains
Higher scores in any domain on the ADOS and ADI-R are indicative of more abnormal behaviors and/or symptoms. Among ADOS subdomains, there was no significant relationship between Communication and peptoid binding (z = 0.04, p = 0.966), Communication + Social interaction (z = 1.53, p = 0.127), or Stereotyped Behaviors and Restrictive Interests (SBRI) (z = 0.46, p = 0.647). Higher scores on the Social Interaction domain were significantly associated with higher peptoid binding (z = 2.04, p = 0.041).
Among ADI-R subdomains, higher scores on the Communication domain were associated with lower levels of peptoid binding (z = −2.28, p = 0.023). There was not a significant relationship between Social Interaction (z = 0.07, p = 0.941) or Restrictive/Repetitive Stereotyped Behaviors (z = −1.40, p = 0.162) and peptoid binding.
Computational Model Finds New Protein-Protein Interactions
Researchers at University of Pittsburgh have discovered 500 new protein-protein interactions (PPIs) associated with genes linked to schizophrenia.
http://www.technologynetworks.com/Proteomics/news.aspx?id=190995
Using a computational model they developed, researchers at the University of Pittsburgh School of Medicine have discovered more than 500 new protein-protein interactions (PPIs) associated with genes linked to schizophrenia. The findings, published online in npj Schizophrenia, a Nature Publishing Group journal, could lead to greater understanding of the biological underpinnings of this mental illness, as well as point the way to treatments.
There have been many genome-wide association studies (GWAS) that have identified gene variants associated with an increased risk for schizophrenia, but in most cases there is little known about the proteins that these genes make, what they do and how they interact, said senior investigator Madhavi Ganapathiraju, Ph.D., assistant professor of biomedical informatics, Pitt School of Medicine.
“GWAS studies and other research efforts have shown us what genes might be relevant in schizophrenia,” she said. “What we have done is the next step. We are trying to understand how these genes relate to each other, which could show us the biological pathways that are important in the disease.”
Each gene makes proteins and proteins typically interact with each other in a biological process. Information about interacting partners can shed light on the role of a gene that has not been studied, revealing pathways and biological processes associated with the disease and also its relation to other complex diseases.
Dr. Ganapathiraju’s team developed a computational model called High-Precision Protein Interaction Prediction (HiPPIP) and applied it to discover PPIs of schizophrenia-linked genes identified through GWAS, as well as historically known risk genes. They found 504 never-before known PPIs, and noted also that while schizophrenia-linked genes identified historically and through GWAS had little overlap, the model showed they shared more than 100 common interactors.
“We can infer what the protein might do by checking out the company it keeps,” Dr. Ganapathiraju explained. “For example, if I know you have many friends who play hockey, it could mean that you are involved in hockey, too. Similarly, if we see that an unknown protein interacts with multiple proteins involved in neural signaling, for example, there is a high likelihood that the unknown entity also is involved in the same.”
Dr. Ganapathiraju and colleagues have drawn such inferences on protein function based on the PPIs of proteins, and made their findings available on a website Schizo-Pi. This information can be used by biologists to explore the schizophrenia interactome with the aim of understanding more about the disease or developing new treatment drugs.
Schizophrenia interactome with 504 novel protein–protein interactions
MK Ganapathiraju, M Thahir,…, CE Loscher, EM Bauer & S Chaparala
npj Schizophrenia 2016; 2(16012) http://dx.doi.org:/10.1038/npjschz.2016.12
(GWAS) have revealed the role of rare and common genetic variants, but the functional effects of the risk variants remain to be understood. Protein interactome-based studies can facilitate the study of molecular mechanisms by which the risk genes relate to schizophrenia (SZ) genesis, but protein–protein interactions (PPIs) are unknown for many of the liability genes. We developed a computational model to discover PPIs, which is found to be highly accurate according to computational evaluations and experimental validations of selected PPIs. We present here, 365 novel PPIs of liability genes identified by the SZ Working Group of the Psychiatric Genomics Consortium (PGC). Seventeen genes that had no previously known interactions have 57 novel interactions by our method. Among the new interactors are 19 drug targets that are targeted by 130 drugs. In addition, we computed 147 novel PPIs of 25 candidate genes investigated in the pre-GWAS era. While there is little overlap between the GWAS genes and the pre-GWAS genes, the interactomes reveal that they largely belong to the same pathways, thus reconciling the apparent disparities between the GWAS and prior gene association studies. The interactome including 504 novel PPIs overall, could motivate other systems biology studies and trials with repurposed drugs. The PPIs are made available on a webserver, called Schizo-Pi at http://severus.dbmi.pitt.edu/schizo-pi with advanced search capabilities.
Schizophrenia (SZ) is a common, potentially severe psychiatric disorder that afflicts all populations.1 Gene mapping studies suggest that SZ is a complex disorder, with a cumulative impact of variable genetic effects coupled with environmental factors.2 As many as 38 genome-wide association studies (GWAS) have been reported on SZ out of a total of 1,750 GWAS publications on 1,087 traits or diseases reported in the GWAS catalog maintained by the National Human Genome Research Institute of USA3 (as of April 2015), revealing the common variants associated with SZ.4 The SZ Working Group of the Psychiatric Genomics Consortium (PGC) identified 108 genetic loci that likely confer risk for SZ.5 While the role of genetics has been clearly validated by this study, the functional impact of the risk variants is not well-understood.6,7 Several of the genes implicated by the GWAS have unknown functions and could participate in possibly hitherto unknown pathways.8 Further, there is little or no overlap between the genes identified through GWAS and ‘candidate genes’ proposed in the pre-GWAS era.9
Interactome-based studies can be useful in discovering the functional associations of genes. For example,disrupted in schizophrenia 1 (DISC1), an SZ related candidate gene originally had no known homolog in humans. Although it had well-characterized protein domains such as coiled-coil domains and leucine-zipper domains, its function was unknown.10,11 Once its protein–protein interactions (PPIs) were determined using yeast 2-hybrid technology,12 investigators successfully linked DISC1 to cAMP signaling, axon elongation, and neuronal migration, and accelerated the research pertaining to SZ in general, and DISC1 in particular.13 Typically such studies are carried out on known protein–protein interaction (PPI) networks, or as in the case of DISC1, when there is a specific gene of interest, its PPIs are determined by methods such as yeast 2-hybrid technology.
Knowledge of human PPI networks is thus valuable for accelerating discovery of protein function, and indeed, biomedical research in general. However, of the hundreds of thousands of biophysical PPIs thought to exist in the human interactome,14,15 <100,000 are known today (Human Protein Reference Database, HPRD16 and BioGRID17 databases). Gold standard experimental methods for the determination of all the PPIs in human interactome are time-consuming, expensive and may not even be feasible, as about 250 million pairs of proteins would need to be tested overall; high-throughput methods such as yeast 2-hybrid have important limitations for whole interactome determination as they have a low recall of 23% (i.e., remaining 77% of true interactions need to be determined by other means), and a low precision (i.e., the screens have to be repeated multiple times to achieve high selectivity).18,19Computational methods are therefore necessary to complete the interactome expeditiously. Algorithms have begun emerging to predict PPIs using statistical machine learning on the characteristics of the proteins, but these algorithms are employed predominantly to study yeast. Two significant computational predictions have been reported for human interactome; although they have had high false positive rates, these methods have laid the foundation for computational prediction of human PPIs.20,21
We have created a new PPI prediction model called High-Confidence Protein–Protein Interaction Prediction (HiPPIP) model. Novel interactions predicted with this model are making translational impact. For example, we discovered a PPI between OASL and DDX58, which on validation showed that an increased expression of OASL could boost innate immunity to combat influenza by activating the RIG-I pathway.22 Also, the interactome of the genes associated with congenital heart disease showed that the disease morphogenesis has a close connection with the structure and function of cilia.23Here, we describe the HiPPIP model and its application to SZ genes to construct the SZ interactome. After computational evaluations and experimental validations of selected novel PPIs, we present here 504 highly confident novel PPIs in the SZ interactome, shedding new light onto several uncharacterized genes that are associated with SZ.
We developed a computational model called HiPPIP to predict PPIs (see Methods and Supplementary File 1). The model has been evaluated by computational methods and experimental validations and is found to be highly accurate. Evaluations on a held-out test data showed a precision of 97.5% and a recall of 5%. 5% recall out of 150,000 to 600,000 estimated number of interactions in the human interactome corresponds to 7,500–30,000 novel PPIs in the whole interactome. Note that, it is likely that the real precision would be higher than 97.5% because in this test data, randomly paired proteins are treated as non-interacting protein pairs, whereas some of them may actually be interacting pairs with a small probability; thus, some of the pairs that are treated as false positives in test set are likely to be true but hitherto unknown interactions. In Figure 1a, we show the precision versus recall of our method on ‘hub proteins’ where we considered all pairs that received a score >0.5 by HiPPIP to be novel interactions. In Figure 1b, we show the number of true positives versus false positives observed in hub proteins. Both these figures also show our method to be superior in comparison to the prediction of membrane-receptor interactome by Qi et al’s.24 True positives versus false positives are also shown for individual hub proteins by our method in Figure 1cand by Qi et al’s.23 in Figure 1d. These evaluations showed that our predictions contain mostly true positives. Unlike in other domains where ranked lists are commonly used such as information retrieval, in PPI prediction the ‘false positives’ may actually be unlabeled instances that are indeed true interactions that are not yet discovered. In fact, such unlabeled pairs predicted as interactors of the hub gene HMGB1 (namely, the pairs HMGB1-KL and HMGB1-FLT1) were validated by experimental methods and found to be true PPIs (See the Figures e–g inSupplementary File 3). Thus, we concluded that the protein pairs that received a score of ⩾0.5 are highly confident to be true interactions. The pairs that receive a score less than but close to 0.5 (i.e., in the range of 0.4–0.5) may also contain several true PPIs; however, we cannot confidently say that all in this range are true PPIs. Only the PPIs predicted with a score >0.5 are included in the interactome.
Figure 1
Computational evaluation of predicted protein–protein interactions on hub proteins: (a) precision recall curve. (b) True positive versus false positives in ranked lists of hub type membrane receptors for our method and that by Qi et al. True positives versus false positives are shown for individual membrane receptors by our method in (c) and by Qi et al. in (d). Thick line is the average, which is also the same as shown in (b). Note:x-axis is recall in (a), whereas it is number of false positives in (b–d). The range of y-axis is observed by varying the threshold from 1.0–0 in (a), and to 0.5 in (b–d).
SZ interactome
By applying HiPPIP to the GWAS genes and Historic (pre-GWAS) genes, we predicted over 500 high confidence new PPIs adding to about 1400 previously known PPIs.
Schizophrenia interactome: network view of the schizophrenia interactome is shown as a graph, where genes are shown as nodes and PPIs as edges connecting the nodes. Schizophrenia-associated genes are shown as dark blue nodes, novel interactors as red color nodes and known interactors as blue color nodes. The source of the schizophrenia genes is indicated by its label font, where Historic genes are shown italicized, GWAS genes are shown in bold, and the one gene that is common to both is shown in italicized and bold. For clarity, the source is also indicated by the shape of the node (triangular for GWAS and square for Historic and hexagonal for both). Symbols are shown only for the schizophrenia-associated genes; actual interactions may be accessed on the web. Red edges are the novel interactions, whereas blue edges are known interactions. GWAS, genome-wide association studies of schizophrenia; PPI, protein–protein interaction.
Webserver of SZ interactome
We have made the known and novel interactions of all SZ-associated genes available on a webserver called Schizo-Pi, at the addresshttp://severus.dbmi.pitt.edu/schizo-pi. This webserver is similar to Wiki-Pi33 which presents comprehensive annotations of both participating proteins of a PPI side-by-side. The difference between Wiki-Pi which we developed earlier, and Schizo-Pi, is the inclusion of novel predicted interactions of the SZ genes into the latter.
Despite the many advances in biomedical research, identifying the molecular mechanisms underlying the disease is still challenging. Studies based on protein interactions were proven to be valuable in identifying novel gene associations that could shed new light on disease pathology.35 The interactome including more than 500 novel PPIs will help to identify pathways and biological processes associated with the disease and also its relation to other complex diseases. It also helps identify potential drugs that could be repurposed to use for SZ treatment.
Functional and pathway enrichment in SZ interactome
When a gene of interest has little known information, functions of its interacting partners serve as a starting point to hypothesize its own function. We computed statistically significant enrichment of GO biological process terms among the interacting partners of each of the genes using BinGO36 (see online at http://severus.dbmi.pitt.edu/schizo-pi).
Protein aggregation and aggregate toxicity: new insights into protein folding, misfolding diseases and biological evolution
Massimo Stefani · Christopher M. Dobson
Abstract The deposition of proteins in the form of amyloid fibrils and plaques is the characteristic feature of more than 20 degenerative conditions affecting either the central nervous system or a variety of peripheral tissues. As these conditions include Alzheimer’s, Parkinson’s and the prion diseases, several forms of fatal systemic amyloidosis, and at least one condition associated with medical intervention (haemodialysis), they are of enormous importance in the context of present-day human health and welfare. Much remains to be learned about the mechanism by which the proteins associated with these diseases aggregate and form amyloid structures, and how the latter affect the functions of the organs with which they are associated. A great deal of information concerning these diseases has emerged, however, during the past 5 years, much of it causing a number of fundamental assumptions about the amyloid diseases to be reexamined. For example, it is now apparent that the ability to form amyloid structures is not an unusual feature of the small number of proteins associated with these diseases but is instead a general property of polypeptide chains. It has also been found recently that aggregates of proteins not associated with amyloid diseases can impair the ability of cells to function to a similar extent as aggregates of proteins linked with specific neurodegenerative conditions. Moreover, the mature amyloid fibrils or plaques appear to be substantially less toxic than the prefibrillar aggregates that are their precursors. The toxicity of these early aggregates appears to result from an intrinsic ability to impair fundamental cellular processes by interacting with cellular membranes, causing oxidative stress and increases in free Ca2+ that eventually lead to apoptotic or necrotic cell death. The ‘new view’ of these diseases also suggests that other degenerative conditions could have similar underlying origins to those of the amyloidoses. In addition, cellular protection mechanisms, such as molecular chaperones and the protein degradation machinery, appear to be crucial in the prevention of disease in normally functioning living organisms. It also suggests some intriguing new factors that could be of great significance in the evolution of biological molecules and the mechanisms that regulate their behaviour.
The genetic information within a cell encodes not only the specific structures and functions of proteins but also the way these structures are attained through the process known as protein folding. In recent years many of the underlying features of the fundamental mechanism of this complex process and the manner in which it is regulated in living systems have emerged from a combination of experimental and theoretical studies [1]. The knowledge gained from these studies has also raised a host of interesting issues. It has become apparent, for example, that the folding and unfolding of proteins is associated with a whole range of cellular processes from the trafficking of molecules to specific organelles to the regulation of the cell cycle and the immune response. Such observations led to the inevitable conclusion that the failure to fold correctly, or to remain correctly folded, gives rise to many different types of biological malfunctions and hence to many different forms of disease [2]. In addition, it has been recognised recently that a large number of eukaryotic genes code for proteins that appear to be ‘natively unfolded’, and that proteins can adopt, under certain circumstances, highly organised multi-molecular assemblies whose structures are not specifically encoded in the amino acid sequence. Both these observations have raised challenging questions about one of the most fundamental principles of biology: the close relationship between the sequence, structure and function of proteins, as we discuss below [3].
It is well established that proteins that are ‘misfolded’, i.e. that are not in their functionally relevant conformation, are devoid of normal biological activity. In addition, they often aggregate and/or interact inappropriately with other cellular components leading to impairment of cell viability and eventually to cell death. Many diseases, often known as misfolding or conformational diseases, ultimately result from the presence in a living system of protein molecules with structures that are ‘incorrect’, i.e. that differ from those in normally functioning organisms [4]. Such diseases include conditions in which a specific protein, or protein complex, fails to fold correctly (e.g. cystic fibrosis, Marfan syndrome, amyotonic lateral sclerosis) or is not sufficiently stable to perform its normal function (e.g. many forms of cancer). They also include conditions in which aberrant folding behaviour results in the failure of a protein to be correctly trafficked (e.g. familial hypercholesterolaemia, α1-antitrypsin deficiency, and some forms of retinitis pigmentosa) [4]. The tendency of proteins to aggregate, often to give species extremely intractable to dissolution and refolding, is of course also well known in other circumstances. Examples include the formation of inclusion bodies during overexpression of heterologous proteins in bacteria and the precipitation of proteins during laboratory purification procedures. Indeed, protein aggregation is well established as one of the major difficulties associated with the production and handling of proteins in the biotechnology and pharmaceutical industries [5].
Considerable attention is presently focused on a group of protein folding diseases known as amyloidoses. In these diseases specific peptides or proteins fail to fold or to remain correctly folded and then aggregate (often with other components) so as to give rise to ‘amyloid’ deposits in tissue. Amyloid structures can be recognised because they possess a series of specific tinctorial and biophysical characteristics that reflect a common core structure based on the presence of highly organised βsheets [6]. The deposits in strictly defined amyloidoses are extracellular and can often be observed as thread-like fibrillar structures, sometimes assembled further into larger aggregates or plaques. These diseases include a range of sporadic, familial or transmissible degenerative diseases, some of which affect the brain and the central nervous system (e.g. Alzheimer’s and Creutzfeldt-Jakob diseases), while others involve peripheral tissues and organs such as the liver, heart and spleen (e.g. systemic amyloidoses and type II diabetes) [7, 8]. In other forms of amyloidosis, such as primary or secondary systemic amyloidoses, proteinaceous deposits are found in skeletal tissue and joints (e.g. haemodialysis-related amyloidosis) as well as in several organs (e.g. heart and kidney). Yet other components such as collagen, glycosaminoglycans and proteins (e.g. serum amyloid protein) are often present in the deposits protecting them against degradation [9, 10, 11]. Similar deposits to those in the amyloidoses are, however, found intracellularly in other diseases; these can be localised either in the cytoplasm, in the form of specialised aggregates known as aggresomes or as Lewy or Russell bodies or in the nucleus (see below).
The presence in tissue of proteinaceous deposits is a hallmark of all these diseases, suggesting a causative link between aggregate formation and pathological symptoms (often known as the amyloid hypothesis) [7, 8, 12]. At the present time the link between amyloid formation and disease is widely accepted on the basis of a large number of biochemical and genetic studies. The specific nature of the pathogenic species, and the molecular basis of their ability to damage cells, are however, the subject of intense debate [13, 14, 15, 16, 17, 18, 19, 20]. In neurodegenerative disorders it is very likely that the impairment of cellular function follows directly from the interactions of the aggregated proteins with cellular components [21, 22]. In the systemic non-neurological diseases, however, it is widely believed that the accumulation in vital organs of large amounts of amyloid deposits can by itself cause at least some of the clinical symptoms [23]. It is quite possible, however, that there are other more specific effects of aggregates on biochemical processes even in these diseases. The presence of extracellular or intracellular aggregates of a specific polypeptide molecule is a characteristic of all the 20 or so recognised amyloid diseases. The polypeptides involved include full length proteins (e.g. lysozyme or immunoglobulin light chains), biological peptides (amylin, atrial natriuretic factor) and fragments of larger proteins produced as a result of specific processing (e.g. the Alzheimer βpeptide) or of more general degradation [e.g. poly(Q) stretches cleaved from proteins with poly(Q) extensions such as huntingtin, ataxins and the androgen receptor]. The peptides and proteins associated with known amyloid diseases are listed in Table 1. In some cases the proteins involved have wild type sequences, as in sporadic forms of the diseases, but in other cases these are variants resulting from genetic mutations associated with familial forms of the diseases. In some cases both sporadic and familial diseases are associated with a given protein; in this case the mutational variants are usually associated with early-onset forms of the disease. In the case of the neurodegenerative diseases associated with the prion protein some forms of the diseases are transmissible. The existence of familial forms of a number of amyloid diseases has provided significant clues to the origins of the pathologies. For example, there are increasingly strong links between the age at onset of familial forms of disease and the effects of the mutations involved on the propensity of the affected proteins to aggregate in vitro. Such findings also support the link between the process of aggregation and the clinical manifestations of disease [24, 25].
The presence in cells of misfolded or aggregated proteins triggers a complex biological response. In the cytosol, this is referred to as the ‘heat shock response’ and in the endoplasmic reticulum (ER) it is known as the ‘unfolded protein response’. These responses lead to the expression, among others, of the genes for heat shock proteins (Hsp, or molecular chaperone proteins) and proteins involved in the ubiquitin-proteasome pathway [26]. The evolution of such complex biochemical machinery testifies to the fact that it is necessary for cells to isolate and clear rapidly and efficiently any unfolded or incorrectly folded protein as soon as it appears. In itself this fact suggests that these species could have a generally adverse effect on cellular components and cell viability. Indeed, it was a major step forward in understanding many aspects of cell biology when it was recognised that proteins previously associated only with stress, such as heat shock, are in fact crucial in the normal functioning of living systems. This advance, for example, led to the discovery of the role of molecular chaperones in protein folding and in the normal ‘housekeeping’ processes that are inherent in healthy cells [27, 28]. More recently a number of degenerative diseases, both neurological and systemic, have been linked to, or shown to be affected by, impairment of the ubiquitin-proteasome pathway (Table 2). The diseases are primarily associated with a reduction in either the expression or the biological activity of Hsps, ubiquitin, ubiquitinating or deubiquitinating enzymes and the proteasome itself, as we show below [29, 30, 31, 32], or even to the failure of the quality control mechanisms that ensure proper maturation of proteins in the ER. The latter normally leads to degradation of a significant proportion of polypeptide chains before they have attained their native conformations through retrograde translocation to the cytosol [33, 34].
….
It is now well established that the molecular basis of protein aggregation into amyloid structures involves the existence of ‘misfolded’ forms of proteins, i.e. proteins that are not in the structures in which they normally function in vivo or of fragments of proteins resulting from degradation processes that are inherently unable to fold [4, 7, 8, 36]. Aggregation is one of the common consequences of a polypeptide chain failing to reach or maintain its functional three-dimensional structure. Such events can be associated with specific mutations, misprocessing phenomena, aberrant interactions with metal ions, changes in environmental conditions, such as pH or temperature, or chemical modification (oxidation, proteolysis). Perturbations in the conformational properties of the polypeptide chain resulting from such phenomena may affect equilibrium 1 in Fig. 1 increasing the population of partially unfolded, or misfolded, species that are much more aggregation-prone than the native state.
Fig. 1 Overview of the possible fates of a newly synthesised polypeptide chain. The equilibrium ① between the partially folded molecules and the natively folded ones is usually strongly in favour of the latter except as a result of specific mutations, chemical modifications or partially destabilising solution conditions. The increased equilibrium populations of molecules in the partially or completely unfolded ensemble of structures are usually degraded by the proteasome; when this clearance mechanism is impaired, such species often form disordered aggregates or shift equilibrium ② towards the nucleation of pre-fibrillar assemblies that eventually grow into mature fibrils (equilibrium ③). DANGER! indicates that pre-fibrillar aggregates in most cases display much higher toxicity than mature fibrils. Heat shock proteins (Hsp) can suppress the appearance of pre-fibrillar assemblies by minimising the population of the partially folded molecules by assisting in the correct folding of the nascent chain and the unfolded protein response target incorrectly folded proteins for degradation.
……
Little is known at present about the detailed arrangement of the polypeptide chains themselves within amyloid fibrils, either those parts involved in the core βstrands or in regions that connect the various β-strands. Recent data suggest that the sheets are relatively untwisted and may in some cases at least exist in quite specific supersecondary structure motifs such as β-helices [6, 40] or the recently proposed µ-helix [41]. It seems possible that there may be significant differences in the way the strands are assembled depending on characteristics of the polypeptide chain involved [6, 42]. Factors including length, sequence (and in some cases the presence of disulphide bonds or post-translational modifications such as glycosylation) may be important in determining details of the structures. Several recent papers report structural models for amyloid fibrils containing different polypeptide chains, including the Aβ40 peptide, insulin and fragments of the prion protein, based on data from such techniques as cryo-electron microscopy and solid-state magnetic resonance spectroscopy [43, 44]. These models have much in common and do indeed appear to reflect the fact that the structures of different fibrils are likely to be variations on a common theme [40]. It is also emerging that there may be some common and highly organised assemblies of amyloid protofilaments that are not simply extended threads or ribbons. It is clear, for example, that in some cases large closed loops can be formed [45, 46, 47], and there may be specific types of relatively small spherical or ‘doughnut’ shaped structures that can result in at least some circumstances (see below).
…..
The similarity of some early amyloid aggregates with the pores resulting from oligomerisation of bacterial toxins and pore-forming eukaryotic proteins (see below) also suggest that the basic mechanism of protein aggregation into amyloid structures may not only be associated with diseases but in some cases could result in species with functional significance. Recent evidence indicates that a variety of micro-organisms may exploit the controlled aggregation of specific proteins (or their precursors) to generate functional structures. Examples include bacterial curli [52] and proteins of the interior fibre cells of mammalian ocular lenses, whose β-sheet arrays seem to be organised in an amyloid-like supramolecular order [53]. In this case the inherent stability of amyloid-like protein structure may contribute to the long-term structural integrity and transparency of the lens. Recently it has been hypothesised that amyloid-like aggregates of serum amyloid A found in secondary amyloidoses following chronic inflammatory diseases protect the host against bacterial infections by inducing lysis of bacterial cells [54]. One particularly interesting example is a ‘misfolded’ form of the milk protein α-lactalbumin that is formed at low pH and trapped by the presence of specific lipid molecules [55]. This form of the protein has been reported to trigger apoptosis selectively in tumour cells providing evidence for its importance in protecting infants from certain types of cancer [55]. ….
Amyloid formation is a generic property of polypeptide chains ….
It is clear that the presence of different side chains can influence the details of amyloid structures, particularly the assembly of protofibrils, and that they give rise to the variations on the common structural theme discussed above. More fundamentally, the composition and sequence of a peptide or protein affects profoundly its propensity to form amyloid structures under given conditions (see below).
Because the formation of stable protein aggregates of amyloid type does not normally occur in vivo under physiological conditions, it is likely that the proteins encoded in the genomes of living organisms are endowed with structural adaptations that mitigate against aggregation under these conditions. A recent survey involving a large number of structures of β-proteins highlights several strategies through which natural proteins avoid intermolecular association of β-strands in their native states [65]. Other surveys of protein databases indicate that nature disfavours sequences of alternating polar and nonpolar residues, as well as clusters of several consecutive hydrophobic residues, both of which enhance the tendency of a protein to aggregate prior to becoming completely folded [66, 67].
……
Precursors of amyloid fibrils can be toxic to cells
It was generally assumed until recently that the proteinaceous aggregates most toxic to cells are likely to be mature amyloid fibrils, the form of aggregates that have been commonly detected in pathological deposits. It therefore appeared probable that the pathogenic features underlying amyloid diseases are a consequence of the interaction with cells of extracellular deposits of aggregated material. As well as forming the basis for understanding the fundamental causes of these diseases, this scenario stimulated the exploration of therapeutic approaches to amyloidoses that focused mainly on the search for molecules able to impair the growth and deposition of fibrillar forms of aggregated proteins. ….
Structural basis and molecular features of amyloid toxicity
The presence of toxic aggregates inside or outside cells can impair a number of cell functions that ultimately lead to cell death by an apoptotic mechanism [95, 96]. Recent research suggests, however, that in most cases initial perturbations to fundamental cellular processes underlie the impairment of cell function induced by aggregates of disease-associated polypeptides. Many pieces of data point to a central role of modifications to the intracellular redox status and free Ca2+ levels in cells exposed to toxic aggregates [45, 89, 97, 98, 99, 100, 101]. A modification of the intracellular redox status in such cells is associated with a sharp increase in the quantity of reactive oxygen species (ROS) that is reminiscent of the oxidative burst by which leukocytes destroy invading foreign cells after phagocytosis. In addition, changes have been observed in reactive nitrogen species, lipid peroxidation, deregulation of NO metabolism [97], protein nitrosylation [102] and upregulation of heme oxygenase-1, a specific marker of oxidative stress [103]. ….
Results have recently been reported concerning the toxicity towards cultured cells of aggregates of poly(Q) peptides which argues against a disease mechanism based on specific toxic features of the aggregates. These results indicate that there is a close relationship between the toxicity of proteins with poly(Q) extensions and their nuclear localisation. In addition they support the hypotheses that the toxicity of poly(Q) aggregates can be a consequence of altered interactions with nuclear coactivator or corepressor molecules including p53, CBP, Sp1 and TAF130 or of the interaction with transcription factors and nuclear coactivators, such as CBP, endowed with short poly(Q) stretches ([95] and references therein)…..
Concluding remarks
The data reported in the past few years strongly suggest that the conversion of normally soluble proteins into amyloid fibrils and the toxicity of small aggregates appearing during the early stages of the formation of the latter are common or generic features of polypeptide chains. Moreover, the molecular basis of this toxicity also appears to display common features between the different systems that have so far been studied. The ability of many, perhaps all, natural polypeptides to ‘misfold’ and convert into toxic aggregates under suitable conditions suggests that one of the most important driving forces in the evolution of proteins must have been the negative selection against sequence changes that increase the tendency of a polypeptide chain to aggregate. Nevertheless, as protein folding is a stochastic process, and no such process can be completely infallible, misfolded proteins or protein folding intermediates in equilibrium with the natively folded molecules must continuously form within cells. Thus mechanisms to deal with such species must have co-evolved with proteins. Indeed, it is clear that misfolding, and the associated tendency to aggregate, is kept under control by molecular chaperones, which render the resulting species harmless assisting in their refolding, or triggering their degradation by the cellular clearance machinery [166, 167, 168, 169, 170, 171, 172, 173, 175, 177, 178].
Misfolded and aggregated species are likely to owe their toxicity to the exposure on their surfaces of regions of proteins that are buried in the interior of the structures of the correctly folded native states. The exposure of large patches of hydrophobic groups is likely to be particularly significant as such patches favour the interaction of the misfolded species with cell membranes [44, 83, 89, 90, 91, 93]. Interactions of this type are likely to lead to the impairment of the function and integrity of the membranes involved, giving rise to a loss of regulation of the intracellular ion balance and redox status and eventually to cell death. In addition, misfolded proteins undoubtedly interact inappropriately with other cellular components, potentially giving rise to the impairment of a range of other biological processes. Under some conditions the intracellular content of aggregated species may increase directly, due to an enhanced propensity of incompletely folded or misfolded species to aggregate within the cell itself. This could occur as the result of the expression of mutational variants of proteins with decreased stability or cooperativity or with an intrinsically higher propensity to aggregate. It could also occur as a result of the overproduction of some types of protein, for example, because of other genetic factors or other disease conditions, or because of perturbations to the cellular environment that generate conditions favouring aggregation, such as heat shock or oxidative stress. Finally, the accumulation of misfolded or aggregated proteins could arise from the chaperone and clearance mechanisms becoming overwhelmed as a result of specific mutant phenotypes or of the general effects of ageing [173, 174].
The topics discussed in this review not only provide a great deal of evidence for the ‘new view’ that proteins have an intrinsic capability of misfolding and forming structures such as amyloid fibrils but also suggest that the role of molecular chaperones is even more important than was thought in the past. The role of these ubiquitous proteins in enhancing the efficiency of protein folding is well established [185]. It could well be that they are at least as important in controlling the harmful effects of misfolded or aggregated proteins as in enhancing the yield of functional molecules.
Nutritional Status is Associated with Faster Cognitive Decline and Worse Functional Impairment in the Progression of Dementia: The Cache County Dementia Progression Study1
Sanders, Chelseaa | Behrens, Stephaniea | Schwartz, Sarahb | Wengreen, Heidic | Corcoran, Chris D.b; d | Lyketsos, Constantine G.e | Tschanz, JoAnn T.a; d;
Journal of Alzheimer’s Disease 2016; 52(1):33-42, http://content.iospress.com/articles/journal-of-alzheimers-disease/jad150528 http://dx.doi.org:/10.3233/JAD-150528
Nutritional status may be a modifiable factor in the progression of dementia. We examined the association of nutritional status and rate of cognitive and functional decline in a U.S. population-based sample. Study design was an observational longitudinal study with annual follow-ups up to 6 years of 292 persons with dementia (72% Alzheimer’s disease, 56% female) in Cache County, UT using the Mini-Mental State Exam (MMSE), Clinical Dementia Rating Sum of Boxes (CDR-sb), and modified Mini Nutritional Assessment (mMNA). mMNA scores declined by approximately 0.50 points/year, suggesting increasing risk for malnutrition. Lower mMNA score predicted faster rate of decline on the MMSE at earlier follow-up times, but slower decline at later follow-up times, whereas higher mMNA scores had the opposite pattern (mMNA by time β= 0.22, p = 0.017; mMNA by time2 β= –0.04, p = 0.04). Lower mMNA score was associated with greater impairment on the CDR-sb over the course of dementia (β= 0.35, p < 0.001). Assessment of malnutrition may be useful in predicting rates of progression in dementia and may provide a target for clinical intervention.
Shared Genetic Risk Factors for Late-Life Depression and Alzheimer’s Disease
Ye, Qing | Bai, Feng* | Zhang, Zhijun
Journal of Alzheimer’s Disease 2016; 52(1): 1-15. http://dx.doi.org:/10.3233/JAD-151129
Background: Considerable evidence has been reported for the comorbidity between late-life depression (LLD) and Alzheimer’s disease (AD), both of which are very common in the general elderly population and represent a large burden on the health of the elderly. The pathophysiological mechanisms underlying the link between LLD and AD are poorly understood. Because both LLD and AD can be heritable and are influenced by multiple risk genes, shared genetic risk factors between LLD and AD may exist. Objective: The objective is to review the existing evidence for genetic risk factors that are common to LLD and AD and to outline the biological substrates proposed to mediate this association. Methods: A literature review was performed. Results: Genetic polymorphisms of brain-derived neurotrophic factor, apolipoprotein E, interleukin 1-beta, and methylenetetrahydrofolate reductase have been demonstrated to confer increased risk to both LLD and AD by studies examining either LLD or AD patients. These results contribute to the understanding of pathophysiological mechanisms that are common to both of these disorders, including deficits in nerve growth factors, inflammatory changes, and dysregulation mechanisms involving lipoprotein and folate. Other conflicting results have also been reviewed, and few studies have investigated the effects of the described polymorphisms on both LLD and AD. Conclusion: The findings suggest that common genetic pathways may underlie LLD and AD comorbidity. Studies to evaluate the genetic relationship between LLD and AD may provide insights into the molecular mechanisms that trigger disease progression as the population ages.
Association of Vitamin B12, Folate, and Sulfur Amino Acids With Brain Magnetic Resonance Imaging Measures in Older Adults: A Longitudinal Population-Based Study
B Hooshmand, F Mangialasche, G Kalpouzos…, et al.
AMA Psychiatry. Published online April 27, 2016. http://dx.doi.org:/10.1001/jamapsychiatry.2016.0274
Importance Vitamin B12, folate, and sulfur amino acids may be modifiable risk factors for structural brain changes that precede clinical dementia.
Objective To investigate the association of circulating levels of vitamin B12, red blood cell folate, and sulfur amino acids with the rate of total brain volume loss and the change in white matter hyperintensity volume as measured by fluid-attenuated inversion recovery in older adults.
Design, Setting, and Participants The magnetic resonance imaging subsample of the Swedish National Study on Aging and Care in Kungsholmen, a population-based longitudinal study in Stockholm, Sweden, was conducted in 501 participants aged 60 years or older who were free of dementia at baseline. A total of 299 participants underwent repeated structural brain magnetic resonance imaging scans from September 17, 2001, to December 17, 2009.
Main Outcomes and Measures The rate of brain tissue volume loss and the progression of total white matter hyperintensity volume.
Results In the multi-adjusted linear mixed models, among 501 participants (300 women [59.9%]; mean [SD] age, 70.9 [9.1] years), higher baseline vitamin B12 and holotranscobalamin levels were associated with a decreased rate of total brain volume loss during the study period: for each increase of 1 SD, β (SE) was 0.048 (0.013) for vitamin B12 (P < .001) and 0.040 (0.013) for holotranscobalamin (P = .002). Increased total homocysteine levels were associated with faster rates of total brain volume loss in the whole sample (β [SE] per 1-SD increase, –0.035 [0.015]; P = .02) and with the progression of white matter hyperintensity among participants with systolic blood pressure greater than 140 mm Hg (β [SE] per 1-SD increase, 0.000019 [0.00001]; P = .047). No longitudinal associations were found for red blood cell folate and other sulfur amino acids.
Conclusions and Relevance This study suggests that both vitamin B12 and total homocysteine concentrations may be related to accelerated aging of the brain. Randomized clinical trials are needed to determine the importance of vitamin B12supplementation on slowing brain aging in older adults.
Notes from Kurzweill
This vitamin stops the aging process in organs, say Swiss researchers
A potential breakthrough for regenerative medicine, pending further studies
http://www.kurzweilai.net/this-vitamin-stops-the-aging-process-in-organs-say-swiss-researchers
Improved muscle stem cell numbers and muscle function in NR-treated aged mice: Newly regenerated muscle fibers 7 days after muscle damage in aged mice (left: control group; right: fed NR). (Scale bar = 50 μm). (credit: Hongbo Zhang et al./Science) http://www.kurzweilai.net/images/improved-muscle-fibers.png
EPFL researchers have restored the ability of mice organs to regenerate and extend life by simply administering nicotinamide riboside (NR) to them.
NR has been shown in previous studies to be effective in boosting metabolism and treating a number of degenerative diseases. Now, an article by PhD student Hongbo Zhang published in Science also describes the restorative effects of NR on the functioning of stem cells for regenerating organs.
As in all mammals, as mice age, the regenerative capacity of certain organs (such as the liver and kidneys) and muscles (including the heart) diminishes. Their ability to repair them following an injury is also affected. This leads to many of the disorders typical of aging.
Mitochondria —> stem cells —> organs
To understand how the regeneration process deteriorates with age, Zhang teamed up with colleagues from ETH Zurich, the University of Zurich, and universities in Canada and Brazil. By using several biomarkers, they were able to identify the molecular chain that regulates how mitochondria — the “powerhouse” of the cell — function and how they change with age. “We were able to show for the first time that their ability to function properly was important for stem cells,” said Auwerx.
Under normal conditions, these stem cells, reacting to signals sent by the body, regenerate damaged organs by producing new specific cells. At least in young bodies. “We demonstrated that fatigue in stem cells was one of the main causes of poor regeneration or even degeneration in certain tissues or organs,” said Zhang.
How to revitalize stem cells
Which is why the researchers wanted to “revitalize” stem cells in the muscles of elderly mice. And they did so by precisely targeting the molecules that help the mitochondria to function properly. “We gave nicotinamide riboside to 2-year-old mice, which is an advanced age for them,” said Zhang.
“This substance, which is close to vitamin B3, is a precursor of NAD+, a molecule that plays a key role in mitochondrial activity. And our results are extremely promising: muscular regeneration is much better in mice that received NR, and they lived longer than the mice that didn’t get it.”
Parallel studies have revealed a comparable effect on stem cells of the brain and skin. “This work could have very important implications in the field of regenerative medicine,” said Auwerx. This work on the aging process also has potential for treating diseases that can affect — and be fatal — in young people, like muscular dystrophy (myopathy).
So far, no negative side effects have been observed following the use of NR, even at high doses. But while it appears to boost the functioning of all cells, it could include pathological ones, so further in-depth studies are required.
Abstract of NAD+ repletion improves mitochondrial and stem cell function and enhances life span in mice
Adult stem cells (SCs) are essential for tissue maintenance and regeneration yet are susceptible to senescence during aging. We demonstrate the importance of the amount of the oxidized form of cellular nicotinamide adenine dinucleotide (NAD+) and its impact on mitochondrial activity as a pivotal switch to modulate muscle SC (MuSC) senescence. Treatment with the NAD+ precursor nicotinamide riboside (NR) induced the mitochondrial unfolded protein response (UPRmt) and synthesis of prohibitin proteins, and this rejuvenated MuSCs in aged mice. NR also prevented MuSC senescence in the Mdx mouse model of muscular dystrophy. We furthermore demonstrate that NR delays senescence of neural SCs (NSCs) and melanocyte SCs (McSCs), and increased mouse lifespan. Strategies that conserve cellular NAD+ may reprogram dysfunctional SCs and improve lifespan in mammals.
references:
Enhancer–promoter interactions are encoded by complex genomic signatures on looping chromatin
Sean Whalen, Rebecca M Truty & Katherine S Pollard
Nature Genetics 2016; 48:488–496 doi:10.1038/ng.3539
Discriminating the gene target of a distal regulatory element from other nearby transcribed genes is a challenging problem with the potential to illuminate the causal underpinnings of complex diseases. We present TargetFinder, a computational method that reconstructs regulatory landscapes from diverse features along the genome. The resulting models accurately predict individual enhancer–promoter interactions across multiple cell lines with a false discovery rate up to 15 times smaller than that obtained using the closest gene. By evaluating the genomic features driving this accuracy, we uncover interactions between structural proteins, transcription factors, epigenetic modifications, and transcription that together distinguish interacting from non-interacting enhancer–promoter pairs. Most of this signature is not proximal to the enhancers and promoters but instead decorates the looping DNA. We conclude that complex but consistent combinations of marks on the one-dimensional genome encode the three-dimensional structure of fine-scale regulatory interactions.































![Deep imaging of [agr]-catulin-GFP+ HSCs in digitally reconstructed bone marrow.](https://i0.wp.com/www.nature.com/nature/journal/v526/n7571/carousel/nature15250-f1.jpg?resize=210%2C200)
![[agr]-catulin-GFP expression among haematopoietic cells is highly restricted to HSCs.](https://i0.wp.com/www.nature.com/nature/journal/v526/n7571/images/nature15250-sf3.jpg?w=500)



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
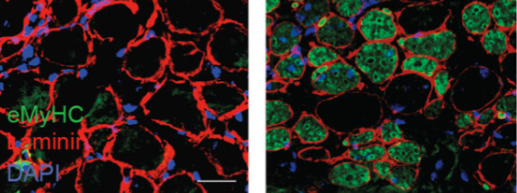{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}