Healthcare analytics, AI solutions for biological big data, providing an AI platform for the biotech, life sciences, medical and pharmaceutical industries, as well as for related technological approaches, i.e., curation and text analysis with machine learning and other activities related to AI applications to these industries.
Unlocking the Secrets of Longevity: A 117-Year-Old Woman’s Genes Defied Aging
Curator: Dr. Sudipta Saha, Ph.D.
A recent study led by the University of Barcelona has shed light on the genetic factors contributing to exceptional human longevity. The research focused on Maria Branyas Morera, who was recognized as the world’s oldest living person until her passing at age 117 in August 2024. The findings revealed that her unique genetic makeup allowed her cells to function as if they were 17 years younger, and her gut microbiota resembled that of an infant.
Branyas Morera attributed her remarkable lifespan to “luck and good genetics.” Beyond her genetic advantages, she maintained a healthy lifestyle characterized by a Mediterranean diet, regular physical activity, and strong family bonds. These factors likely contributed to her prolonged cognitive clarity and minimal health issues, primarily limited to joint pain and hearing loss.
This study adds to a growing body of research exploring the genetic foundations of longevity. For instance, the Okinawa Centenarian Study has examined over 600 centenarians from Okinawa, Japan, uncovering genetic markers associated with extended lifespan and reduced incidence of age-related diseases.
Similarly, the New England Centenarian Study has identified specific genetic variations linked to longevity, providing insights into the biological mechanisms that allow some individuals to live significantly longer than average.
Researchers hope that understanding these genetic factors can inform the development of treatments for age-related diseases, challenging the notion that aging and illness are inextricably linked. By studying individuals like Branyas Morera, scientists aim to uncover strategies to promote healthier aging across the broader population.
However, it’s important to note that while genetics play a crucial role in exceptional longevity, lifestyle factors such as diet, exercise, and social connections also significantly impact overall health and lifespan. The interplay between genetic predisposition and environmental influences continues to be a critical area of research in understanding human aging.
Recent genetic studies have identified variants associated with bipolar disorder (BD), but it remains unclear how brain gene expression is altered in BD and how genetic risk for BD may contribute to these alterations. Here, we obtained transcriptomes from subgenual anterior cingulate cortex and amygdala samples from post-mortem brains of individuals with BD and neurotypical controls, including 511 total samples from 295 unique donors. We examined differential gene expression between cases and controls and the transcriptional effects of BD-associated genetic variants. We found two coexpressed modules that were associated with transcriptional changes in BD: one enriched for immune and inflammatory genes and the other with genes related to the postsynaptic membrane. Over 50% of BD genome-wide significant loci contained significant expression quantitative trait loci (QTL) (eQTL), and these data converged on several individual genes, including SCN2A and GRIN2A. Thus, these data implicate specific genes and pathways that may contribute to the pathology of BP.
Gene Expression Markers for Bipolar Disorder Pinpointed
The work was led by researchers at Johns Hopkins’ Lieber Institute for Brain Development. The findings, published this week in Nature Neuroscience, represent the first time that researchers have been able to apply large-scale genetic research to brain samples from hundreds of patients with bipolar disorder (BD). They used 511 total samples from 295 unique donors.
“This is the first deep dive into the molecular biology of the brain in people who died with bipolar disorder—studying actual genes, not urine, blood or skin samples,” said Thomas Hyde of the Lieber Institute and a lead author of the paper. “If we can figure out the mechanisms behind BD, if we can figure out what’s wrong in the brain, then we can begin to develop new targeted treatments of what has long been a mysterious condition.”
Bipolar disorder is characterized by extreme mood swings, with episodes of mania alternating with episodes of depression. It usually emerges in people in their 20s and 30s and remains with them for life. This condition affects approximately 2.8% of the adult American population, or about 7 million people. Patients face higher rates of suicide, poorer quality of life, and lower productivity than the general population. Some estimates put the annual cost of the condition in the U.S. alone at $219.1 billion.
While drugs can be useful in treating BD, many patients find they have bothersome side effects, and for some patients, current medications don’t work at all.
In this study, researchers measured levels of messenger RNA in the brain samples. They observed almost eight times more differentially expressed gene features in the sACC versus the amygdala, suggesting that the sACC may play an especially prominent role—both in mood regulation in general and BD specifically.
In patients who died with BD, the researchers found abnormalities in two families of genes: one containing genes related to the synapse and the second related to immune and inflammatory function.
“There finally is a study using modern technology and our current understanding of genetics to uncover how the brain is doing,” Hyde said. “We know that BD tends to run in families, and there is strong evidence that there are inherited genetic abnormalities that put an individual at risk for bipolar disorder. Unlike diseases such as sickle-cell anemia, bipolar disorder does not result from a single genetic abnormality. Rather, most patients have inherited a group of variants spread across a number of genes.”
“Bipolar disorder, also known as manic-depressive disorder, is a highly damaging and paradoxical condition,” said Daniel R. Weinberger, chief executive and director of the Lieber Institute and a co-author of the study. “It can make people very productive so they can lead countries and companies, but it can also hurl them into the meat grinder of dysfunction and depression. Patients with BD may live on two hours of sleep a night, saving the world with their abundance of energy, and then become so self-destructive that they spend their family’s fortune in a week and lose all friends as they spiral downward. Bipolar disorder also has some shared genetic links to other psychiatric disorders, such as schizophrenia, and is implicated in overuse of drugs and alcohol.”
Despite heated discussion over whether it works, the FDA has approved Aduhelm, bringing a new ray of hope to the Alzheimer’s patients.
Curator and Reporter: Dr. Premalata Pati, Ph.D., Postdoc
Despite heated discussion over whether it works, the FDA has approved Aduhelm, bringing a new ray of hope to the Alzheimer’s patients.
On Monday, 7th June 2021, a controversial new Alzheimer’sDisease treatment was licensed in the United States for the first time in nearly 20 years, sparking calls for it to be made available worldwide despite conflicting evidence about its usefulness. The drug was designed for people with mild cognitive impairment, not severe dementia, and it was designed to delay the progression of Alzheimer’s disease rather than only alleviate symptoms.
The route to FDA clearance for Aducanumab has been bumpy – and contentious.
Though doctors, patients, and the organizations that assist them are in desperate need of therapies that can delay mental decline, scientists question the efficacy of the new medicine, Aducanumab or Aduhelm. In March 2019, two trials were halted because the medications looked to be ineffective. “The futility analysis revealed that the studies were most likely to fail,” said Isaacson of Weill Cornell Medicine and NewYork-Presbyterian. Biogen, the drug’s manufacturer revealed several months later that a fresh analysis with more participants found that individuals who got high doses of Aducanumab exhibited a reduction in clinical decline in one experiment. Patients treated with high-dose Aducanumab had 22% reduced clinical impairment in their cognitive health at 18 months, indicating that the advancement of their early Alzheimer’s disease was halted, according to FDA briefing documents from last year.
When the FDA’s members were split on the merits of the application in November, it was rejected. Three of its advisers went public, claiming that there was insufficient evidence that it worked in a scientific journal. They were concerned that if the medicine was approved, it might reduce the threshold for future approvals, owing to the scarcity of Alzheimer’s treatments.
Dr. Caleb Alexander, a drug safety and effectiveness expert at the Johns Hopkins Bloomberg School of Public Health, was one of the FDA advisers who was concerned that the data presented to the agency was a reanalysis after the experiment was stopped. It was “like the Texas sharpshooter fallacy,” he told the New York Times, “where the sharpshooter blows up a barn and then goes and paints a bullseye around the cluster of holes he loves.”
Some organizations, such as the non-profit Public Citizen’s Health Research Group, claimed that the FDA should not approve Aducanumab for the treatment of Alzheimer’s disease because there is insufficient proof of its efficacy.
The drug is a monoclonal antibody that inhibits the formation of amyloid protein plaques in the brain, which are thought to be the cause of Alzheimer’s disease. The majority of Alzheimer’s medications have attempted to erase these plaques.
Aducanumab appears to do this in some patients, but only when the disease is in its early stages. This means that people must be checked to see if they have the disease. Many persons with memory loss are hesitant to undergo testing because there is now no treatment available.
The few Alzheimer’s medications available appear to have limited effectiveness. When Aricept, also known as Donepezil, was approved more than 20 years ago, there was a major battle to get it. It was heralded as a breakthrough at the time – partly due to the lack of anything else. It has become obvious that it slows mental decline for a few months but makes little effect in the long run.
The findings of another trial for some patients backed up those conclusions.
Biogen submitted a Biologics License Application to the FDA in July 2020, requesting approval of the medicine.
The FDA’s decision has been awaited by Alzheimer’s disease researchers, clinicians, and patients since then.
Support for approval of the drug
Other groups, such as the Alzheimer’s Association, have supported the drug’s approval.
The Alzheimer’s Association‘s website stated on Friday, “This is a critical time, regardless of the FDA’s final judgment. We’ve never been this close to approving an Alzheimer’s drug that could affect the disease’s development rather than just the symptoms. We can keep working together to achieve our goal of a world free of Alzheimer’s disease and other dementias.”
The drug has gotten so much attention that the Knight Alzheimer Disease Research Center at Washington University in St. Louis issued a statement on Friday stating that even if it is approved, “it will still likely take several months for the medication to pass other regulatory steps and become available to patients.”
Biogen officials told KGO-TV on Monday that the medicine will be ready to ship in about two weeks and that they have identified more than 900 facilities across the United States that they feel will be medically and commercially suitable.
Officials stated the corporation will also provide financial support to qualifying patients so that their out-of-pocket payments are as low as possible. Biogen has also pledged not to raise the price for at least the next four years.
Most Medicare customers with supplemental plans, according to the firm, will have a limited or capped co-pay.
Case studies connected to the Drug Approval
Case 1
Ann Lange, one of several Chicago-area clinical trial volunteers who received the breakthrough Alzheimer’s treatment, said,
It really offers us so much hope for a long, healthy life.
Lange, 60, has Alzheimer’s disease, which she was diagnosed with five years ago. Her memory has improved as a result of the monthly infusions, she claims.
She said,
I’d forget what I’d done in the shower, so I’d scribble ‘shampoo, conditioner, face, body’ on the door. Otherwise, I’d lose track of what I’m doing “Lange remarked. “I’m not required to do that any longer.
Case 2
Jenny Knap, 69, has been receiving infusions of the Aducanumab medication for about a year as part of two six-month research trials. She told CNN that she had been receiving treatment for roughly six months before the trial was halted in 2019, and that she had recently resumed treatment.
Knap said,
I can’t say I noticed it on a daily basis, but I do think I’m doing a lot better in terms of checking for where my glasses are and stuff like that.
When Knap was diagnosed with mild cognitive impairment, a clinical precursor to Alzheimer’s disease, in 2015, the symptoms were slight but there.
Her glasses were frequently misplaced, and she would repeat herself, forgetting previous talks, according to her husband, Joe Knap.
Joe added,
We were aware that things were starting to fall between the cracks as these instances got more often
Jenny went to the Lou Ruvo Center for Brain Health at the Cleveland Clinic in Ohio for testing and obtained her diagnosis. Jenny found she was qualified to join in clinical trials for the Biogen medicine Aducanumab at the Cleveland Clinic a few years later, in early 2017. She volunteered and has been a part of the trial ever since.
It turns out that Jenny was in the placebo category for the first year and a half, Joe explained, meaning she didn’t get the treatment.
They didn’t realize she was in the placebo group until lately because the trial was blind. Joe stated she was given the medicine around August 2018 and continued until February 2019 as the trial progressed. The trial was halted by Biogen in March 2019, but it was restarted last October, when Jenny resumed getting infusions.
Jenny now receives Aducanumab infusions every four weeks at the Cleveland Clinic, which is roughly a half-hour drive from their house, with Joe by her side. Jenny added that, despite the fact that she has only recently begun therapy, she believes it is benefiting her, combined with a balanced diet and regular exercise (she runs four miles).
The hope of Aducanumab is to halt the progression of the disease rather than to improve cognition. We didn’t appreciate any significant reduction in her condition, Jenny’s doctor, Dr. Babak Tousi, who headed Aducanumab clinical studies at the Cleveland Clinic, wrote to CNN in an email.
This treatment is unlike anything we’ve ever received before. There has never been a drug that has slowed the growth of Alzheimer’s disease, he stated, Right now, existing medications like donepezil and memantine aid with symptoms but do not slow the disease’s progression.
Jenny claims that the medicine has had no significant negative effects on her.
There was signs of some very minor bleeding in the brain at one point, which was quite some time ago. It was at very low levels, in fact, Joe expressed concern about Jenny, but added that the physicians were unconcerned.
According to Tousi, with repeated therapy, “blood vessels may become leaky, allowing fluid and red blood cells to flow out to the surrounding area,” and “micro hemorrhages have been documented in 19.1% of trial participants who got” the maximal dose of therapy”.
Jenny and Joe’s attitude on the future has improved as a result of the infusions and keeping a healthy lifestyle, according to Joe. They were also delighted to take part in the trial, which they saw as an opportunity to make a positive influence in other people’s lives.
There was this apprehension of what was ahead before we went into the clinical trial, Joe recalled. “The medical aspect of the infusion gives us reason to be optimistic. However, doing the activity on a daily basis provides us with immediate benefits.”
The drug’s final commercialization announcement
Aducanumab, which will be marketed as Aduhelm, is a monthly intravenous infusion that is designed to halt cognitive decline in patients with mild memory and thinking issues. It is the first FDA-approved medication for Alzheimer’s disease that targets the disease process rather than just the symptoms.
The manufacturer, Biogen, stated Monday afternoon that the annual list price will be $56,000. In addition, diagnostic tests and brain imaging will very certainly cost tens of thousands of dollars.
The FDA approved approval for the medicine to be used but ordered Biogen to conduct a new clinical trial, recognizing that prior trials of the medicine had offered insufficient evidence to indicate effectiveness.
Biogen Inc said on Tuesday that it expects to start shipping Aduhelm, a newly licensed Alzheimer’s medicine, in approximately two weeks and that it has prepared over 900 healthcare facilities for the intravenous infusion treatment.
Other Relevant Articles
Gene Therapy could be a Boon to Alzheimer’s disease (AD): A first-in-human clinical trial proposed
Alnylam Announces First-Ever FDA Approval of an RNAi Therapeutic, ONPATTRO™ (patisiran) for the Treatment of the Polyneuropathy of Hereditary Transthyretin-Mediated Amyloidosis in Adults
Disease related changes in proteomics, protein folding, protein-protein interaction, Volume 2 (Volume Two: Latest in Genomics Methodologies for Therapeutics: Gene Editing, NGS and BioInformatics, Simulations and the Genome Ontology), Part 1: Next Generation Sequencing (NGS)
Disease related changes in proteomics, protein folding, protein-protein interaction
Curator: Larry H. Bernstein, MD, FCAP
LPBI
Frankenstein Proteins Stitched Together by Scientists
The Frankenstein monster, stitched together from disparate body parts, proved to be an abomination, but stitched together proteins may fare better. They may, for example, serve specific purposes in medicine, research, and industry. At least, that’s the ambition of scientists based at the University of North Carolina. They have developed a computational protocol called SEWING that builds new proteins from connected or disconnected pieces of existing structures. [Wikipedia]
Unlike Victor Frankenstein, who betrayed Promethean ambition when he sewed together his infamous creature, today’s biochemists are relatively modest. Rather than defy nature, they emulate it. For example, at the University of North Carolina (UNC), researchers have taken inspiration from natural evolutionary mechanisms to develop a technique called SEWING—Structure Extension With Native-substructure Graphs. SEWING is a computational protocol that describes how to stitch together new proteins from connected or disconnected pieces of existing structures.
“We can now begin to think about engineering proteins to do things that nothing else is capable of doing,” said UNC’s Brian Kuhlman, Ph.D. “The structure of a protein determines its function, so if we are going to learn how to design new functions, we have to learn how to design new structures. Our study is a critical step in that direction and provides tools for creating proteins that haven’t been seen before in nature.”
Traditionally, researchers have used computational protein design to recreate in the laboratory what already exists in the natural world. In recent years, their focus has shifted toward inventing novel proteins with new functionality. These design projects all start with a specific structural “blueprint” in mind, and as a result are limited. Dr. Kuhlman and his colleagues, however, believe that by removing the limitations of a predetermined blueprint and taking cues from evolution they can more easily create functional proteins.
Dr. Kuhlman’s UNC team developed a protein design approach that emulates natural mechanisms for shuffling tertiary structures such as pleats, coils, and furrows. Putting the approach into action, the UNC team mapped 50,000 stitched together proteins on the computer, and then it produced 21 promising structures in the laboratory. Details of this work appeared May 6 in the journal Science, in an article entitled, “Design of Structurally Distinct Proteins Using Strategies Inspired by Evolution.”
“Helical proteins designed with SEWING contain structural features absent from other de novo designed proteins and, in some cases, remain folded at more than 100°C,” wrote the authors. “High-resolution structures of the designed proteins CA01 and DA05R1 were solved by x-ray crystallography (2.2 angstrom resolution) and nuclear magnetic resonance, respectively, and there was excellent agreement with the design models.”
Essentially, the UNC scientists confirmed that the proteins they had synthesized contained the unique structural varieties that had been designed on the computer. The UNC scientists also determined that the structures they had created had new surface and pocket features. Such features, they noted, provide potential binding sites for ligands or macromolecules.
“We were excited that some had clefts or grooves on the surface, regions that naturally occurring proteins use for binding other proteins,” said the Science article’s first author, Tim M. Jacobs, Ph.D., a former graduate student in Dr. Kuhlman’s laboratory. “That’s important because if we wanted to create a protein that can act as a biosensor to detect a certain metabolite in the body, either for diagnostic or research purposes, it would need to have these grooves. Likewise, if we wanted to develop novel therapeutics, they would also need to attach to specific proteins.”
Currently, the UNC researchers are using SEWING to create proteins that can bind to several other proteins at a time. Many of the most important proteins are such multitaskers, including the blood protein hemoglobin.
Histone Mutation Deranges DNA Methylation to Cause Cancer
In some cancers, including chondroblastoma and a rare form of childhood sarcoma, a mutation in histone H3 reduces global levels of methylation (dark areas) in tumor cells but not in normal cells (arrowhead). The mutation locks the cells in a proliferative state to promote tumor development. [Laboratory of Chromatin Biology and Epigenetics at The Rockefeller University]
They have been called oncohistones, the mutated histones that are known to accompany certain pediatric cancers. Despite their suggestive moniker, oncohistones have kept their oncogenic secrets. For example, it has been unclear whether oncohistones are able to cause cancer on their own, or whether they need to act in concert with additional DNA mutations, that is, mutations other than those affecting histone structures.
While oncohistone mechanisms remain poorly understood, this particular question—the oncogenicity of lone oncohistones—has been resolved, at least in part. According to researchers based at The Rockefeller University, a change to the structure of a histone can trigger a tumor on its own.
This finding appeared May 13 in the journal Science, in an article entitled, “Histone H3K36 Mutations Promote Sarcomagenesis Through Altered Histone Methylation Landscape.” The article describes the Rockefeller team’s study of a histone protein called H3, which has been found in about 95% of samples of chondoblastoma, a benign tumor that arises in cartilage, typically during adolescence.
The Rockefeller scientists found that the H3 lysine 36–to–methionine (H3K36M) mutation impairs the differentiation of mesenchymal progenitor cells and generates undifferentiated sarcoma in vivo.
After the scientists inserted the H3 histone mutation into mouse mesenchymal progenitor cells (MPCs)—which generate cartilage, bone, and fat—they watched these cells lose the ability to differentiate in the lab. Next, the scientists injected the mutant cells into living mice, and the animals developed the tumors rich in MPCs, known as an undifferentiated sarcoma. Finally, the researchers tried to understand how the mutation causes the tumors to develop.
The scientists determined that H3K36M mutant nucleosomes inhibit the enzymatic activities of several H3K36 methyltransferases.
“Depleting H3K36 methyltransferases, or expressing an H3K36I mutant that similarly inhibits H3K36 methylation, is sufficient to phenocopy the H3K36M mutation,” the authors of the Science study wrote. “After the loss of H3K36 methylation, a genome-wide gain in H3K27 methylation leads to a redistribution of polycomb repressive complex 1 and de-repression of its target genes known to block mesenchymal differentiation.”
Essentially, when the H3K36M mutation occurs, the cell becomes locked in a proliferative state—meaning it divides constantly, leading to tumors. Specifically, the mutation inhibits enzymes that normally tag the histone with chemical groups known as methyls, allowing genes to be expressed normally.
In response to this lack of modification, another part of the histone becomes overmodified, or tagged with too many methyl groups. “This leads to an overall resetting of the landscape of chromatin, the complex of DNA and its associated factors, including histones,” explained co-author Peter Lewis, Ph.D., a professor at the University of Wisconsin-Madison and a former postdoctoral fellow in laboratory of C. David Allis, Ph.D., a professor at Rockefeller.
The finding—that a “resetting” of the chromatin landscape can lock the cell into a proliferative state—suggests that researchers should be on the hunt for more mutations in histones that might be driving tumors. For their part, the Rockefeller researchers are trying to learn more about how this specific mutation in histone H3 causes tumors to develop.
“We want to know which pathways cause the mesenchymal progenitor cells that carry the mutation to continue to divide, and not differentiate into the bone, fat, and cartilage cells they are destined to become,” said co-author Chao Lu, Ph.D., a postdoctoral fellow in the Allis lab.
Once researchers understand more about these pathways, added Dr. Lewis, they can consider ways of blocking them with drugs, particularly in tumors such as MPC-rich sarcomas—which, unlike chondroblastoma, can be deadly. In fact, drugs that block these pathways may already exist and may even be in use for other types of cancers.
“One long-term goal of our collaborative team is to better understand fundamental mechanisms that drive these processes, with the hope of providing new therapeutic approaches,” concluded Dr. Allis.
Histone H3K36 mutations promote sarcomagenesis through altered histone methylation landscape
Missense mutations (that change one amino acid for another) in histone H3 can produce a so-called oncohistone and are found in a number of pediatric cancers. For example, the lysine-36–to-methionine (K36M) mutation is seen in almost all chondroblastomas. Lu et al. show that K36M mutant histones are oncogenic, and they inhibit the normal methylation of this same residue in wild-type H3 histones. The mutant histones also interfere with the normal development of bone-related cells and the deposition of inhibitory chromatin marks.
Several types of pediatric cancers reportedly contain high-frequency missense mutations in histone H3, yet the underlying oncogenic mechanism remains poorly characterized. Here we report that the H3 lysine 36–to–methionine (H3K36M) mutation impairs the differentiation of mesenchymal progenitor cells and generates undifferentiated sarcoma in vivo. H3K36M mutant nucleosomes inhibit the enzymatic activities of several H3K36 methyltransferases. Depleting H3K36 methyltransferases, or expressing an H3K36I mutant that similarly inhibits H3K36 methylation, is sufficient to phenocopy the H3K36M mutation. After the loss of H3K36 methylation, a genome-wide gain in H3K27 methylation leads to a redistribution of polycomb repressive complex 1 and de-repression of its target genes known to block mesenchymal differentiation. Our findings are mirrored in human undifferentiated sarcomas in which novel K36M/I mutations in H3.1 are identified.
Mitochondria? We Don’t Need No Stinking Mitochondria!
Diagram comparing typical eukaryotic cell to the newly discovered mitochondria-free organism. [Karnkowska et al., 2016, Current Biology 26, 1–11]
The organelle that produces a significant portion of energy for eukaryotic cells would seemingly be indispensable, yet over the years, a number of organisms have been discovered that challenge that biological pretense. However, these so-called amitochondrial species may lack a defined organelle, but they still retain some residual functions of their mitochondria-containing brethren. Even the intestinal eukaryotic parasite Giardia intestinalis, which was for many years considered to be mitochondria-free, was proven recently to contain a considerably shriveled version of the organelle.
Now, an international group of scientists has released results from a new study that challenges the notion that mitochondria are essential for eukaryotes—discovering an organism that resides in the gut of chinchillas that contains absolutely no trace of mitochondria at all.
“In low-oxygen environments, eukaryotes often possess a reduced form of the mitochondrion, but it was believed that some of the mitochondrial functions are so essential that these organelles are indispensable for their life,” explained lead study author Anna Karnkowska, Ph.D., visiting scientist at the University of British Columbia in Vancouver. “We have characterized a eukaryotic microbe which indeed possesses no mitochondrion at all.”
Mysterious Eukaryote Missing Mitochondria
Researchers uncover the first example of a eukaryotic organism that lacks the organelles.
Monocercomonoides sp. PA203VLADIMIR HAMPL, CHARLES UNIVERSITY, PRAGUE, CZECH REPUBLIC
Scientists have long thought that mitochondria—organelles responsible for energy generation—are an essential and defining feature of a eukaryotic cell. Now, researchers from Charles University in Prague and their colleagues are challenging this notion with their discovery of a eukaryotic organism,Monocercomonoides species PA203, which lacks mitochondria. The team’s phylogenetic analysis, published today (May 12) in Current Biology,suggests that Monocercomonoides—which belong to the Oxymonadida group of protozoa and live in low-oxygen environments—did have mitochondria at one point, but eventually lost the organelles.
“This is quite a groundbreaking discovery,” said Thijs Ettema, who studies microbial genome evolution at Uppsala University in Sweden and was not involved in the work.
“This study shows that mitochondria are not so central for all lineages of living eukaryotes,” Toni Gabaldonof the Center for Genomic Regulation in Barcelona, Spain, who also was not involved in the work, wrote in an email to The Scientist. “Yet, this mitochondrial-devoid, single-cell eukaryote is as complex as other eukaryotic cells in almost any other aspect of cellular complexity.”
Charles University’s Vladimir Hampl studies the evolution of protists. Along with Anna Karnkowska and colleagues, Hampl decided to sequence the genome of Monocercomonoides, a little-studied protist that lives in the digestive tracts of vertebrates. The 75-megabase genome—the first of an oxymonad—did not contain any conserved genes found on mitochondrial genomes of other eukaryotes, the researchers found. It also did not contain any nuclear genes associated with mitochondrial functions.
“It was surprising and for a long time, we didn’t believe that the [mitochondria-associated genes were really not there]. We thought we were missing something,” Hampl told The Scientist. “But when the data kept accumulating, we switched to the hypothesis that this organism really didn’t have mitochondria.”
Because researchers have previously not found examples of eukaryotes without some form of mitochondria, the current theory of the origin of eukaryotes poses that the appearance of mitochondria was crucial to the identity of these organisms.
“We now view these mitochondria-like organelles as a continuum from full mitochondria to very small . Some anaerobic protists, for example, have only pared down versions of mitochondria, such as hydrogenosomes and mitosomes, which lack a mitochondrial genome. But these mitochondrion-like organelles perform essential functions of the iron-sulfur cluster assembly pathway, which is known to be conserved in virtually all eukaryotic organisms studied to date.
Yet, in their analysis, the researchers found no evidence of the presence of any components of this mitochondrial pathway.
Like the scaling down of mitochondria into mitosomes in some organisms, the ancestors of modernMonocercomonoides once had mitochondria. “Because this organism is phylogenetically nested among relatives that had conventional mitochondria, this is most likely a secondary adaptation,” said Michael Gray, a biochemist who studies mitochondria at Dalhousie University in Nova Scotia and was not involved in the study. According to Gray, the finding of a mitochondria-deficient eukaryote does not mean that the organelles did not play a major role in the evolution of eukaryotic cells.
To be sure they were not missing mitochondrial proteins, Hampl’s team also searched for potential mitochondrial protein homologs of other anaerobic species, and for signature sequences of a range of known mitochondrial proteins. While similar searches with other species uncovered a few mitochondrial proteins, the team’s analysis of Monocercomonoides came up empty.
“The data is very complete,” said Ettema. “It is difficult to prove the absence of something but [these authors] do a convincing job.”
To form the essential iron-sulfur clusters, the team discovered that Monocercomonoides use a sulfur mobilization system found in the cytosol, and that an ancestor of the organism acquired this system by lateral gene transfer from bacteria. This cytosolic, compensating system allowed Monocercomonoides to lose the otherwise essential iron-sulfur cluster-forming pathway in the mitochondrion, the team proposed.
“This work shows the great evolutionary plasticity of the eukaryotic cell,” said Karnkowska, who participated in the study while she was a postdoc at Charles University. Karnkowska, who is now a visiting researcher at the University of British Columbia in Canada, added: “This is a striking example of how far the evolution of a eukaryotic cell can go that was beyond our expectations.”
“The results highlight how many surprises may await us in the poorly studied eukaryotic phyla that live in under-explored environments,” Gabaldon said.
Ettema agreed. “Now that we’ve found one, we need to look at the bigger picture and see if there are other examples of eukaryotes that have lost their mitochondria, to understand how adaptable eukaryotes are.”
Karnkowska et al., “A eukaryote without a mitochondrial organelle,” Current Biology,doi:10.1016/j.cub.2016.03.053, 2016.
•Monocercomonoides sp. is a eukaryotic microorganism with no mitochondria
•The complete absence of mitochondria is a secondary loss, not an ancestral feature
•The essential mitochondrial ISC pathway was replaced by a bacterial SUF system
The presence of mitochondria and related organelles in every studied eukaryote supports the view that mitochondria are essential cellular components. Here, we report the genome sequence of a microbial eukaryote, the oxymonad Monocercomonoides sp., which revealed that this organism lacks all hallmark mitochondrial proteins. Crucially, the mitochondrial iron-sulfur cluster assembly pathway, thought to be conserved in virtually all eukaryotic cells, has been replaced by a cytosolic sulfur mobilization system (SUF) acquired by lateral gene transfer from bacteria. In the context of eukaryotic phylogeny, our data suggest that Monocercomonoides is not primitively amitochondrial but has lost the mitochondrion secondarily. This is the first example of a eukaryote lacking any form of a mitochondrion, demonstrating that this organelle is not absolutely essential for the viability of a eukaryotic cell.
This method catches a bait protein together with its associated protein partners in virus-like particles that are budded from human cells. Like this, cell lysis is not needed and protein complexes are preserved during purification.
With his feet in both a proteomics lab and an interactomics lab, VIB/UGent professor Sven Eyckerman is well aware of the shortcomings of conventional approaches to analyze protein complexes. The lysis conditions required in mass spectrometry–based strategies to break open cell membranes often affect protein-protein interactions. “The first step in a classical study on protein complexes essentially turns the highly organized cellular structure into a big messy soup”, Eyckerman explains.
Inspired by virus biology, Eyckerman came up with a creative solution. “We used the natural process of HIV particle formation to our benefit by hacking a completely safe form of the virus to abduct intact protein machines from the cell.” It is well known that the HIV virus captures a number of host proteins during its particle formation. By fusing a bait protein to the HIV-1 GAG protein, interaction partners become trapped within virus-like particles that bud from mammalian cells. Standard proteomic approaches are used next to reveal the content of these particles. Fittingly, the team named the method ‘Virotrap’.
The Virotrap approach is exceptional as protein networks can be characterized under natural conditions. By trapping protein complexes in the protective environment of a virus-like shell, the intact complexes are preserved during the purification process. The researchers showed the method was suitable for detection of known binary interactions as well as mass spectrometry-based identification of novel protein partners.
Virotrap is a textbook example of bringing research teams with complementary expertise together. Cross-pollination with the labs of Jan Tavernier (VIB/UGent) and Kris Gevaert (VIB/UGent) enabled the development of this platform.
Jan Tavernier: “Virotrap represents a new concept in co-complex analysis wherein complex stability is physically guaranteed by a protective, physical structure. It is complementary to the arsenal of existing interactomics methods, but also holds potential for other fields, like drug target characterization. We also developed a small molecule-variant of Virotrap that could successfully trap protein partners for small molecule baits.”
Kris Gevaert: “Virotrap can also impact our understanding of disease pathways. We were actually surprised to see that this virus-based system could be used to study antiviral pathways, like Toll-like receptor signaling. Understanding these protein machines in their natural environment is essential if we want to modulate their activity in pathology.“
Trapping mammalian protein complexes in viral particles
Cell lysis is an inevitable step in classical mass spectrometry–based strategies to analyse protein complexes. Complementary lysis conditions, in situ cross-linking strategies and proximal labelling techniques are currently used to reduce lysis effects on the protein complex. We have developed Virotrap, a viral particle sorting approach that obviates the need for cell homogenization and preserves the protein complexes during purification. By fusing a bait protein to the HIV-1 GAG protein, we show that interaction partners become trapped within virus-like particles (VLPs) that bud from mammalian cells. Using an efficient VLP enrichment protocol, Virotrap allows the detection of known binary interactions and MS-based identification of novel protein partners as well. In addition, we show the identification of stimulus-dependent interactions and demonstrate trapping of protein partners for small molecules. Virotrap constitutes an elegant complementary approach to the arsenal of methods to study protein complexes.
Proteins mostly exert their function within supramolecular complexes. Strategies for detecting protein–protein interactions (PPIs) can be roughly divided into genetic systems1 and co-purification strategies combined with mass spectrometry (MS) analysis (for example, AP–MS)2. The latter approaches typically require cell or tissue homogenization using detergents, followed by capture of the protein complex using affinity tags3 or specific antibodies4. The protein complexes extracted from this ‘soup’ of constituents are then subjected to several washing steps before actual analysis by trypsin digestion and liquid chromatography–MS/MS analysis. Such lysis and purification protocols are typically empirical and have mostly been optimized using model interactions in single labs. In fact, lysis conditions can profoundly affect the number of both specific and nonspecific proteins that are identified in a typical AP–MS set-up. Indeed, recent studies using the nuclear pore complex as a model protein complex describe optimization of purifications for the different proteins in the complex by examining 96 different conditions5. Nevertheless, for new purifications, it remains hard to correctly estimate the loss of factors in a standard AP–MS experiment due to washing and dilution effects during treatments (that is, false negatives). These considerations have pushed the concept of stabilizing PPIs before the actual homogenization step. A classical approach involves cross-linking with simple reagents (for example, formaldehyde) or with more advanced isotope-labelled cross-linkers (reviewed in ref. 2). However, experimental challenges such as cell permeability and reactivity still preclude the widespread use of cross-linking agents. Moreover, MS-generated spectra of cross-linked peptides are notoriously difficult to identify correctly. A recent lysis-independent solution involves the expression of a bait protein fused to a promiscuous biotin ligase, which results in labelling of proteins proximal to the activity of the enzyme-tagged bait protein6. When compared with AP–MS, this BioID approach delivers a complementary set of candidate proteins, including novel interaction partners7, 8. Such particular studies clearly underscore the need for complementary approaches in the co-complex strategies.
The evolutionary stress on viruses promoted highly condensed coding of information and maximal functionality for small genomes. Accordingly, for HIV-1 it is sufficient to express a single protein, the p55 GAG protein, for efficient production of virus-like particles (VLPs) from cells9, 10. This protein is highly mobile before its accumulation in cholesterol-rich regions of the membrane, where multimerization initiates the budding process11. A total of 4,000–5,000 GAG molecules is required to form a single particle of about 145 nm (ref. 12). Both VLPs and mature viruses contain a number of host proteins that are recruited by binding to viral proteins. These proteins can either contribute to the infectivity (for example, Cyclophilin/FKBPA13) or act as antiviral proteins preventing the spreading of the virus (for example, APOBEC proteins14).
We here describe the development and application of Virotrap, an elegant co-purification strategy based on the trapping of a bait protein together with its associated protein partners in VLPs that are budded from the cell. After enrichment, these particles can be analysed by targeted (for example, western blotting) or unbiased approaches (MS-based proteomics). Virotrap allows detection of known binary PPIs, analysis of protein complexes and their dynamics, and readily detects protein binders for small molecules.
Concept of the Virotrap system
Classical AP–MS approaches rely on cell homogenization to access protein complexes, a step that can vary significantly with the lysis conditions (detergents, salt concentrations, pH conditions and so on)5. To eliminate the homogenization step in AP–MS, we reasoned that incorporation of a protein complex inside a secreted VLP traps the interaction partners under native conditions and protects them during further purification. We thus explored the possibility of protein complex packaging by the expression of GAG-bait protein chimeras (Fig. 1) as expression of GAG results in the release of VLPs from the cells9, 10. As a first PPI pair to evaluate this concept, we selected the HRAS protein as a bait combined with the RAF1 prey protein. We were able to specifically detect the HRAS–RAF1 interaction following enrichment of VLPs via ultracentrifugation (Supplementary Fig. 1a). To prevent tedious ultracentrifugation steps, we designed a novel single-step protocol wherein we co-express the vesicular stomatitis virus glycoprotein (VSV-G) together with a tagged version of this glycoprotein in addition to the GAG bait and prey. Both tagged and untagged VSV-G proteins are probably presented as trimers on the surface of the VLPs, allowing efficient antibody-based recovery from large volumes. The HRAS–RAF1 interaction was confirmed using this single-step protocol (Supplementary Fig. 1b). No associations with unrelated bait or prey proteins were observed for both protocols.
Figure 1: Schematic representation of the Virotrap strategy.
Expression of a GAG-bait fusion protein (1) results in submembrane multimerization (2) and subsequent budding of VLPs from cells (3). Interaction partners of the bait protein are also trapped within these VLPs and can be identified after purification by western blotting or MS analysis (4).
Virotrap for the detection of binary interactions
We next explored the reciprocal detection of a set of PPI pairs, which were selected based on published evidence and cytosolic localization15. After single-step purification and western blot analysis, we could readily detect reciprocal interactions between CDK2 and CKS1B, LCP2 and GRAP2, and S100A1 and S100B (Fig. 2a). Only for the LCP2 prey we observed nonspecific association with an irrelevant bait construct. However, the particle levels of the GRAP2 bait were substantially lower as compared with those of the GAG control construct (GAG protein levels in VLPs; Fig. 2a, second panel of the LCP2 prey). After quantification of the intensities of bait and prey proteins and normalization of prey levels using bait levels, we observed a strong enrichment for the GAG-GRAP2 bait (Supplementary Fig. 2).
…..
Virotrap for unbiased discovery of novel interactions
For the detection of novel interaction partners, we scaled up VLP production and purification protocols (Supplementary Fig. 5 and Supplementary Note 1 for an overview of the protocol) and investigated protein partners trapped using the following bait proteins: Fas-associated via death domain (FADD), A20 (TNFAIP3), nuclear factor-κB (NF-κB) essential modifier (IKBKG), TRAF family member-associated NF-κB activator (TANK), MYD88 and ring finger protein 41 (RNF41). To obtain specific interactors from the lists of identified proteins, we challenged the data with a combined protein list of 19 unrelated Virotrap experiments (Supplementary Table 1 for an overview). Figure 3 shows the design and the list of candidate interactors obtained after removal of all proteins that were found in the 19 control samples (including removal of proteins from the control list identified with a single peptide). The remaining list of confident protein identifications (identified with at least two peptides in at least two biological repeats) reveals both known and novel candidate interaction partners. All candidate interactors including single peptide protein identifications are given in Supplementary Data 2 and also include recurrent protein identifications of known interactors based on a single peptide; for example, CASP8 for FADD and TANK for NEMO. Using alternative methods, we confirmed the interaction between A20 and FADD, and the associations with transmembrane proteins (insulin receptor and insulin-like growth factor receptor 1) that were captured using RNF41 as a bait (Supplementary Fig. 6). To address the use of Virotrap for the detection of dynamic interactions, we activated the NF-κB pathway via the tumour necrosis factor (TNF) receptor (TNFRSF1A) using TNFα (TNF) and performed Virotrap analysis using A20 as bait (Fig. 3). This resulted in the additional enrichment of receptor-interacting kinase (RIPK1), TNFR1-associated via death domain (TRADD), TNFRSF1A and TNF itself, confirming the expected activated complex20.
Figure 3: Use of Virotrap for unbiased interactome analysis
Lysis conditions used in AP–MS strategies are critical for the preservation of protein complexes. A multitude of lysis conditions have been described, culminating in a recent report where protein complex stability was assessed under 96 lysis/purification protocols5. Moreover, the authors suggest to optimize the conditions for every complex, implying an important workload for researchers embarking on protein complex analysis using classical AP–MS. As lysis results in a profound change of the subcellular context and significantly alters the concentration of proteins, loss of complex integrity during a classical AP–MS protocol can be expected. A clear evolution towards ‘lysis-independent’ approaches in the co-complex analysis field is evident with the introduction of BioID6 and APEX25 where proximal proteins, including proteins residing in the complex, are labelled with biotin by an enzymatic activity fused to a bait protein. A side-by-side comparison between classical AP–MS and BioID showed overlapping and unique candidate binding proteins for both approaches7, 8, supporting the notion that complementary methods are needed to provide a comprehensive view on protein complexes. This has also been clearly demonstrated for binary approaches15 and is a logical consequence of the heterogenic nature underlying PPIs (binding mechanism, requirement for posttranslational modifications, location, affinity and so on).
In this report, we explore an alternative, yet complementary method to isolate protein complexes without interfering with cellular integrity. By trapping protein complexes in the protective environment of a virus-like shell, the intact complexes are preserved during the purification process. This constitutes a new concept in co-complex analysis wherein complex stability is physically guaranteed by a protective, physical structure. A comparison of our Virotrap approach with AP–MS shows complementary data, with specific false positives and false negatives for both methods (Supplementary Fig. 7).
The current implementation of the Virotrap platform implies the use of a GAG-bait construct resulting in considerable expression of the bait protein. Different strategies are currently pursued to reduce bait expression including co-expression of a native GAG protein together with the GAG-bait protein, not only reducing bait expression but also creating more ‘space’ in the particles potentially accommodating larger bait protein complexes. Nevertheless, the presence of the bait on the forming GAG scaffold creates an intracellular affinity matrix (comparable to the early in vitro affinity columns for purification of interaction partners from lysates26) that has the potential to compete with endogenous complexes by avidity effects. This avidity effect is a powerful mechanism that aids in the recruitment of cyclophilin to GAG27, a well-known weak interaction (Kd=16 μM (ref. 28)) detectable as a background association in the Virotrap system. Although background binding may be increased by elevated bait expression, weaker associations are readily detectable (for example, MAL—MYD88-binding study; Fig. 2c).
The size of Virotrap particles (around 145 nm) suggests limitations in the size of the protein complex that can be accommodated in the particles. Further experimentation is required to define the maximum size of proteins or the number of protein complexes that can be trapped inside the particles.
….
In conclusion, Virotrap captures significant parts of known interactomes and reveals new interactions. This cell lysis-free approach purifies protein complexes under native conditions and thus provides a powerful method to complement AP–MS or other PPI data. Future improvements of the system include strategies to reduce bait expression to more physiological levels and application of advanced data analysis options to filter out background. These developments can further aid in the deployment of Virotrap as a powerful extension of the current co-complex technology arsenal.
New Autism Blood Biomarker Identified
Researchers at UT Southwestern Medical Center have identified a blood biomarker that may aid in earlier diagnosis of children with autism spectrum disorder, or ASD
In a recent edition of Scientific Reports, UT Southwestern researchers reported on the identification of a blood biomarker that could distinguish the majority of ASD study participants versus a control group of similar age range. In addition, the biomarker was significantly correlated with the level of communication impairment, suggesting that the blood test may give insight into ASD severity.
“Numerous investigators have long sought a biomarker for ASD,” said Dr. Dwight German, study senior author and Professor of Psychiatry at UT Southwestern. “The blood biomarker reported here along with others we are testing can represent a useful test with over 80 percent accuracy in identifying ASD.”
ASD1 – was 66 percent accurate in diagnosing ASD. When combined with thyroid stimulating hormone level measurements, the ASD1-binding biomarker was 73 percent accurate at diagnosis
A Search for Blood Biomarkers for Autism: Peptoids
Autism spectrum disorder (ASD) is a neurodevelopmental disorder characterized by impairments in social interaction and communication, and restricted, repetitive patterns of behavior. In order to identify individuals with ASD and initiate interventions at the earliest possible age, biomarkers for the disorder are desirable. Research findings have identified widespread changes in the immune system in children with autism, at both systemic and cellular levels. In an attempt to find candidate antibody biomarkers for ASD, highly complex libraries of peptoids (oligo-N-substituted glycines) were screened for compounds that preferentially bind IgG from boys with ASD over typically developing (TD) boys. Unexpectedly, many peptoids were identified that preferentially bound IgG from TD boys. One of these peptoids was studied further and found to bind significantly higher levels (>2-fold) of the IgG1 subtype in serum from TD boys (n = 60) compared to ASD boys (n = 74), as well as compared to older adult males (n = 53). Together these data suggest that ASD boys have reduced levels (>50%) of an IgG1 antibody, which resembles the level found normally with advanced age. In this discovery study, the ASD1 peptoid was 66% accurate in predicting ASD.
….
Peptoid libraries have been used previously to search for autoantibodies for neurodegenerative diseases19 and for systemic lupus erythematosus (SLE)21. In the case of SLE, peptoids were identified that could identify subjects with the disease and related syndromes with moderate sensitivity (70%) and excellent specificity (97.5%). Peptoids were used to measure IgG levels from both healthy subjects and SLE patients. Binding to the SLE-peptoid was significantly higher in SLE patients vs. healthy controls. The IgG bound to the SLE-peptoid was found to react with several autoantigens, suggesting that the peptoids are capable of interacting with multiple, structurally similar molecules. These data indicate that IgG binding to peptoids can identify subjects with high levels of pathogenic autoantibodies vs. a single antibody.
In the present study, the ASD1 peptoid binds significantly lower levels of IgG1 in ASD males vs. TD males. This finding suggests that the ASD1 peptoid recognizes antibody(-ies) of an IgG1 subtype that is (are) significantly lower in abundance in the ASD males vs. TD males. Although a previous study14 has demonstrated lower levels of plasma IgG in ASD vs. TD children, here, we additionally quantified serum IgG levels in our individuals and found no difference in IgG between the two groups (data not shown). Furthermore, our IgG levels did not correlate with ASD1 binding levels, indicating that ASD1 does not bind IgG generically, and that the peptoid’s ability to differentiate between ASD and TD males is related to a specific antibody(-ies).
ASD subjects underwent a diagnostic evaluation using the ADOS and ADI-R, and application of the DSM-IV criteria prior to study inclusion. Only those subjects with a diagnosis of Autistic Disorder were included in the study. The ADOS is a semi-structured observation of a child’s behavior that allows examiners to observe the three core domains of ASD symptoms: reciprocal social interaction, communication, and restricted and repetitive behaviors1. When ADOS subdomain scores were compared with peptoid binding, the only significant relationship was with Social Interaction. However, the positive correlation would suggest that lower peptoid binding is associated with better social interaction, not poorer social interaction as anticipated.
The ADI-R is a structured parental interview that measures the core features of ASD symptoms in the areas of reciprocal social interaction, communication and language, and patterns of behavior. Of the three ADI-R subdomains, only the Communication domain was related to ASD1 peptoid binding, and this correlation was negative suggesting that low peptoid binding is associated with greater communication problems. These latter data are similar to the findings of Heuer et al.14 who found that children with autism with low levels of plasma IgG have high scores on the Aberrant Behavior Checklist (p < 0.0001). Thus, peptoid binding to IgG1 may be useful as a severity marker for ASD allowing for further characterization of individuals, but further research is needed.
It is interesting that in serum samples from older men, the ASD1 binding is similar to that in the ASD boys. This is consistent with the observation that with aging there is a reduction in the strength of the immune system, and the changes are gender-specific25. Recent studies using parabiosis26, in which blood from young mice reverse age-related impairments in cognitive function and synaptic plasticity in old mice, reveal that blood constituents from young subjects may contain important substances for maintaining neuronal functions. Work is in progress to identify the antibody/antibodies that are differentially binding to the ASD1 peptoid, which appear as a single band on the electrophoresis gel (Fig. 4).
……..
The ADI-R is a structured parental interview that measures the core features of ASD symptoms in the areas of reciprocal social interaction, communication and language, and patterns of behavior. Of the three ADI-R subdomains, only the Communication domain was related to ASD1 peptoid binding, and this correlation was negative suggesting that low peptoid binding is associated with greater communication problems. These latter data are similar to the findings of Heuer et al.14 who found that children with autism with low levels of plasma IgG have high scores on the Aberrant Behavior Checklist (p < 0.0001). Thus, peptoid binding to IgG1 may be useful as a severity marker for ASD allowing for further characterization of individuals, but further research is needed.
Titration of IgG binding to ASD1 using serum pooled from 10 TD males and 10 ASD males demonstrates ASD1’s ability to differentiate between the two groups. (B)Detecting IgG1 subclass instead of total IgG amplifies this differentiation. (C) IgG1 binding of individual ASD (n=74) and TD (n=60) male serum samples (1:100 dilution) to ASD1 significantly differs with TD>ASD. In addition, IgG1 binding of older adult male (AM) serum samples (n=53) to ASD1 is significantly lower than TD males, and not different from ASD males. The three groups were compared with a Kruskal-Wallis ANOVA, H = 10.1781, p<0.006. **p<0.005. Error bars show SEM. (D) Receiver-operating characteristic curve for ASD1’s ability to discriminate between ASD and TD males.
Association between peptoid binding and ADOS and ADI-R subdomains
Higher scores in any domain on the ADOS and ADI-R are indicative of more abnormal behaviors and/or symptoms. Among ADOS subdomains, there was no significant relationship between Communication and peptoid binding (z = 0.04, p = 0.966), Communication + Social interaction (z = 1.53, p = 0.127), or Stereotyped Behaviors and Restrictive Interests (SBRI) (z = 0.46, p = 0.647). Higher scores on the Social Interaction domain were significantly associated with higher peptoid binding (z = 2.04, p = 0.041).
Among ADI-R subdomains, higher scores on the Communication domain were associated with lower levels of peptoid binding (z = −2.28, p = 0.023). There was not a significant relationship between Social Interaction (z = 0.07, p = 0.941) or Restrictive/Repetitive Stereotyped Behaviors (z = −1.40, p = 0.162) and peptoid binding.
Computational Model Finds New Protein-Protein Interactions
Researchers at University of Pittsburgh have discovered 500 new protein-protein interactions (PPIs) associated with genes linked to schizophrenia.
Using a computational model they developed, researchers at the University of Pittsburgh School of Medicine have discovered more than 500 new protein-protein interactions (PPIs) associated with genes linked to schizophrenia. The findings, published online in npj Schizophrenia, a Nature Publishing Group journal, could lead to greater understanding of the biological underpinnings of this mental illness, as well as point the way to treatments.
There have been many genome-wide association studies (GWAS) that have identified gene variants associated with an increased risk for schizophrenia, but in most cases there is little known about the proteins that these genes make, what they do and how they interact, said senior investigator Madhavi Ganapathiraju, Ph.D., assistant professor of biomedical informatics, Pitt School of Medicine.
“GWAS studies and other research efforts have shown us what genes might be relevant in schizophrenia,” she said. “What we have done is the next step. We are trying to understand how these genes relate to each other, which could show us the biological pathways that are important in the disease.”
Each gene makes proteins and proteins typically interact with each other in a biological process. Information about interacting partners can shed light on the role of a gene that has not been studied, revealing pathways and biological processes associated with the disease and also its relation to other complex diseases.
Dr. Ganapathiraju’s team developed a computational model called High-Precision Protein Interaction Prediction (HiPPIP) and applied it to discover PPIs of schizophrenia-linked genes identified through GWAS, as well as historically known risk genes. They found 504 never-before known PPIs, and noted also that while schizophrenia-linked genes identified historically and through GWAS had little overlap, the model showed they shared more than 100 common interactors.
“We can infer what the protein might do by checking out the company it keeps,” Dr. Ganapathiraju explained. “For example, if I know you have many friends who play hockey, it could mean that you are involved in hockey, too. Similarly, if we see that an unknown protein interacts with multiple proteins involved in neural signaling, for example, there is a high likelihood that the unknown entity also is involved in the same.”
Dr. Ganapathiraju and colleagues have drawn such inferences on protein function based on the PPIs of proteins, and made their findings available on a website Schizo-Pi. This information can be used by biologists to explore the schizophrenia interactome with the aim of understanding more about the disease or developing new treatment drugs.
Schizophrenia interactome with 504 novel protein–protein interactions
(GWAS) have revealed the role of rare and common genetic variants, but the functional effects of the risk variants remain to be understood. Protein interactome-based studies can facilitate the study of molecular mechanisms by which the risk genes relate to schizophrenia (SZ) genesis, but protein–protein interactions (PPIs) are unknown for many of the liability genes. We developed a computational model to discover PPIs, which is found to be highly accurate according to computational evaluations and experimental validations of selected PPIs. We present here, 365 novel PPIs of liability genes identified by the SZ Working Group of the Psychiatric Genomics Consortium (PGC). Seventeen genes that had no previously known interactions have 57 novel interactions by our method. Among the new interactors are 19 drug targets that are targeted by 130 drugs. In addition, we computed 147 novel PPIs of 25 candidate genes investigated in the pre-GWAS era. While there is little overlap between the GWAS genes and the pre-GWAS genes, the interactomes reveal that they largely belong to the same pathways, thus reconciling the apparent disparities between the GWAS and prior gene association studies. The interactome including 504 novel PPIs overall, could motivate other systems biology studies and trials with repurposed drugs. The PPIs are made available on a webserver, called Schizo-Pi at http://severus.dbmi.pitt.edu/schizo-pi with advanced search capabilities.
Schizophrenia (SZ) is a common, potentially severe psychiatric disorder that afflicts all populations.1 Gene mapping studies suggest that SZ is a complex disorder, with a cumulative impact of variable genetic effects coupled with environmental factors.2 As many as 38 genome-wide association studies (GWAS) have been reported on SZ out of a total of 1,750 GWAS publications on 1,087 traits or diseases reported in the GWAS catalog maintained by the National Human Genome Research Institute of USA3 (as of April 2015), revealing the common variants associated with SZ.4 The SZ Working Group of the Psychiatric Genomics Consortium (PGC) identified 108 genetic loci that likely confer risk for SZ.5 While the role of genetics has been clearly validated by this study, the functional impact of the risk variants is not well-understood.6,7 Several of the genes implicated by the GWAS have unknown functions and could participate in possibly hitherto unknown pathways.8 Further, there is little or no overlap between the genes identified through GWAS and ‘candidate genes’ proposed in the pre-GWAS era.9
Interactome-based studies can be useful in discovering the functional associations of genes. For example,disrupted in schizophrenia 1 (DISC1), an SZ related candidate gene originally had no known homolog in humans. Although it had well-characterized protein domains such as coiled-coil domains and leucine-zipper domains, its function was unknown.10,11 Once its protein–protein interactions (PPIs) were determined using yeast 2-hybrid technology,12 investigators successfully linked DISC1 to cAMP signaling, axon elongation, and neuronal migration, and accelerated the research pertaining to SZ in general, and DISC1 in particular.13 Typically such studies are carried out on known protein–protein interaction (PPI) networks, or as in the case of DISC1, when there is a specific gene of interest, its PPIs are determined by methods such as yeast 2-hybrid technology.
Knowledge of human PPI networks is thus valuable for accelerating discovery of protein function, and indeed, biomedical research in general. However, of the hundreds of thousands of biophysical PPIs thought to exist in the human interactome,14,15 <100,000 are known today (Human Protein Reference Database, HPRD16 and BioGRID17 databases). Gold standard experimental methods for the determination of all the PPIs in human interactome are time-consuming, expensive and may not even be feasible, as about 250 million pairs of proteins would need to be tested overall; high-throughput methods such as yeast 2-hybrid have important limitations for whole interactome determination as they have a low recall of 23% (i.e., remaining 77% of true interactions need to be determined by other means), and a low precision (i.e., the screens have to be repeated multiple times to achieve high selectivity).18,19Computational methods are therefore necessary to complete the interactome expeditiously. Algorithms have begun emerging to predict PPIs using statistical machine learning on the characteristics of the proteins, but these algorithms are employed predominantly to study yeast. Two significant computational predictions have been reported for human interactome; although they have had high false positive rates, these methods have laid the foundation for computational prediction of human PPIs.20,21
We have created a new PPI prediction model called High-Confidence Protein–Protein Interaction Prediction (HiPPIP) model. Novel interactions predicted with this model are making translational impact. For example, we discovered a PPI between OASL and DDX58, which on validation showed that an increased expression of OASL could boost innate immunity to combat influenza by activating the RIG-I pathway.22 Also, the interactome of the genes associated with congenital heart disease showed that the disease morphogenesis has a close connection with the structure and function of cilia.23Here, we describe the HiPPIP model and its application to SZ genes to construct the SZ interactome. After computational evaluations and experimental validations of selected novel PPIs, we present here 504 highly confident novel PPIs in the SZ interactome, shedding new light onto several uncharacterized genes that are associated with SZ.
We developed a computational model called HiPPIP to predict PPIs (see Methods and Supplementary File 1). The model has been evaluated by computational methods and experimental validations and is found to be highly accurate. Evaluations on a held-out test data showed a precision of 97.5% and a recall of 5%. 5% recall out of 150,000 to 600,000 estimated number of interactions in the human interactome corresponds to 7,500–30,000 novel PPIs in the whole interactome. Note that, it is likely that the real precision would be higher than 97.5% because in this test data, randomly paired proteins are treated as non-interacting protein pairs, whereas some of them may actually be interacting pairs with a small probability; thus, some of the pairs that are treated as false positives in test set are likely to be true but hitherto unknown interactions. In Figure 1a, we show the precision versus recall of our method on ‘hub proteins’ where we considered all pairs that received a score >0.5 by HiPPIP to be novel interactions. In Figure 1b, we show the number of true positives versus false positives observed in hub proteins. Both these figures also show our method to be superior in comparison to the prediction of membrane-receptor interactome by Qi et al’s.24 True positives versus false positives are also shown for individual hub proteins by our method in Figure 1cand by Qi et al’s.23 in Figure 1d. These evaluations showed that our predictions contain mostly true positives. Unlike in other domains where ranked lists are commonly used such as information retrieval, in PPI prediction the ‘false positives’ may actually be unlabeled instances that are indeed true interactions that are not yet discovered. In fact, such unlabeled pairs predicted as interactors of the hub gene HMGB1 (namely, the pairs HMGB1-KL and HMGB1-FLT1) were validated by experimental methods and found to be true PPIs (See the Figures e–g inSupplementary File 3). Thus, we concluded that the protein pairs that received a score of ⩾0.5 are highly confident to be true interactions. The pairs that receive a score less than but close to 0.5 (i.e., in the range of 0.4–0.5) may also contain several true PPIs; however, we cannot confidently say that all in this range are true PPIs. Only the PPIs predicted with a score >0.5 are included in the interactome.
Computational evaluation of predicted protein–protein interactions on hub proteins: (a) precision recall curve. (b) True positive versus false positives in ranked lists of hub type membrane receptors for our method and that by Qi et al. True positives versus false positives are shown for individual membrane receptors by our method in (c) and by Qi et al. in (d). Thick line is the average, which is also the same as shown in (b). Note:x-axis is recall in (a), whereas it is number of false positives in (b–d). The range of y-axis is observed by varying the threshold from 1.0–0 in (a), and to 0.5 in (b–d).
SZ interactome
By applying HiPPIP to the GWAS genes and Historic (pre-GWAS) genes, we predicted over 500 high confidence new PPIs adding to about 1400 previously known PPIs.
Schizophrenia interactome: network view of the schizophrenia interactome is shown as a graph, where genes are shown as nodes and PPIs as edges connecting the nodes. Schizophrenia-associated genes are shown as dark blue nodes, novel interactors as red color nodes and known interactors as blue color nodes. The source of the schizophrenia genes is indicated by its label font, where Historic genes are shown italicized, GWAS genes are shown in bold, and the one gene that is common to both is shown in italicized and bold. For clarity, the source is also indicated by the shape of the node (triangular for GWAS and square for Historic and hexagonal for both). Symbols are shown only for the schizophrenia-associated genes; actual interactions may be accessed on the web. Red edges are the novel interactions, whereas blue edges are known interactions. GWAS, genome-wide association studies of schizophrenia; PPI, protein–protein interaction.
We have made the known and novel interactions of all SZ-associated genes available on a webserver called Schizo-Pi, at the addresshttp://severus.dbmi.pitt.edu/schizo-pi. This webserver is similar to Wiki-Pi33 which presents comprehensive annotations of both participating proteins of a PPI side-by-side. The difference between Wiki-Pi which we developed earlier, and Schizo-Pi, is the inclusion of novel predicted interactions of the SZ genes into the latter.
Despite the many advances in biomedical research, identifying the molecular mechanisms underlying the disease is still challenging. Studies based on protein interactions were proven to be valuable in identifying novel gene associations that could shed new light on disease pathology.35 The interactome including more than 500 novel PPIs will help to identify pathways and biological processes associated with the disease and also its relation to other complex diseases. It also helps identify potential drugs that could be repurposed to use for SZ treatment.
Functional and pathway enrichment in SZ interactome
When a gene of interest has little known information, functions of its interacting partners serve as a starting point to hypothesize its own function. We computed statistically significant enrichment of GO biological process terms among the interacting partners of each of the genes using BinGO36 (see online at http://severus.dbmi.pitt.edu/schizo-pi).
Protein aggregation and aggregate toxicity: new insights into protein folding, misfolding diseases and biological evolution
Massimo Stefani · Christopher M. Dobson
Abstract The deposition of proteins in the form of amyloid fibrils and plaques is the characteristic feature of more than 20 degenerative conditions affecting either the central nervous system or a variety of peripheral tissues. As these conditions include Alzheimer’s, Parkinson’s and the prion diseases, several forms of fatal systemic amyloidosis, and at least one condition associated with medical intervention (haemodialysis), they are of enormous importance in the context of present-day human health and welfare. Much remains to be learned about the mechanism by which the proteins associated with these diseases aggregate and form amyloid structures, and how the latter affect the functions of the organs with which they are associated. A great deal of information concerning these diseases has emerged, however, during the past 5 years, much of it causing a number of fundamental assumptions about the amyloid diseases to be reexamined. For example, it is now apparent that the ability to form amyloid structures is not an unusual feature of the small number of proteins associated with these diseases but is instead a general property of polypeptide chains. It has also been found recently that aggregates of proteins not associated with amyloid diseases can impair the ability of cells to function to a similar extent as aggregates of proteins linked with specific neurodegenerative conditions. Moreover, the mature amyloid fibrils or plaques appear to be substantially less toxic than the prefibrillar aggregates that are their precursors. The toxicity of these early aggregates appears to result from an intrinsic ability to impair fundamental cellular processes by interacting with cellular membranes, causing oxidative stress and increases in free Ca2+ that eventually lead to apoptotic or necrotic cell death. The ‘new view’ of these diseases also suggests that other degenerative conditions could have similar underlying origins to those of the amyloidoses. In addition, cellular protection mechanisms, such as molecular chaperones and the protein degradation machinery, appear to be crucial in the prevention of disease in normally functioning living organisms. It also suggests some intriguing new factors that could be of great significance in the evolution of biological molecules and the mechanisms that regulate their behaviour.
The genetic information within a cell encodes not only the specific structures and functions of proteins but also the way these structures are attained through the process known as protein folding. In recent years many of the underlying features of the fundamental mechanism of this complex process and the manner in which it is regulated in living systems have emerged from a combination of experimental and theoretical studies [1]. The knowledge gained from these studies has also raised a host of interesting issues. It has become apparent, for example, that the folding and unfolding of proteins is associated with a whole range of cellular processes from the trafficking of molecules to specific organelles to the regulation of the cell cycle and the immune response. Such observations led to the inevitable conclusion that the failure to fold correctly, or to remain correctly folded, gives rise to many different types of biological malfunctions and hence to many different forms of disease [2]. In addition, it has been recognised recently that a large number of eukaryotic genes code for proteins that appear to be ‘natively unfolded’, and that proteins can adopt, under certain circumstances, highly organised multi-molecular assemblies whose structures are not specifically encoded in the amino acid sequence. Both these observations have raised challenging questions about one of the most fundamental principles of biology: the close relationship between the sequence, structure and function of proteins, as we discuss below [3].
It is well established that proteins that are ‘misfolded’, i.e. that are not in their functionally relevant conformation, are devoid of normal biological activity. In addition, they often aggregate and/or interact inappropriately with other cellular components leading to impairment of cell viability and eventually to cell death. Many diseases, often known as misfolding or conformational diseases, ultimately result from the presence in a living system of protein molecules with structures that are ‘incorrect’, i.e. that differ from those in normally functioning organisms [4]. Such diseases include conditions in which a specific protein, or protein complex, fails to fold correctly (e.g. cystic fibrosis, Marfan syndrome, amyotonic lateral sclerosis) or is not sufficiently stable to perform its normal function (e.g. many forms of cancer). They also include conditions in which aberrant folding behaviour results in the failure of a protein to be correctly trafficked (e.g. familial hypercholesterolaemia, α1-antitrypsin deficiency, and some forms of retinitis pigmentosa) [4]. The tendency of proteins to aggregate, often to give species extremely intractable to dissolution and refolding, is of course also well known in other circumstances. Examples include the formation of inclusion bodies during overexpression of heterologous proteins in bacteria and the precipitation of proteins during laboratory purification procedures. Indeed, protein aggregation is well established as one of the major difficulties associated with the production and handling of proteins in the biotechnology and pharmaceutical industries [5].
Considerable attention is presently focused on a group of protein folding diseases known as amyloidoses. In these diseases specific peptides or proteins fail to fold or to remain correctly folded and then aggregate (often with other components) so as to give rise to ‘amyloid’ deposits in tissue. Amyloid structures can be recognised because they possess a series of specific tinctorial and biophysical characteristics that reflect a common core structure based on the presence of highly organised βsheets [6]. The deposits in strictly defined amyloidoses are extracellular and can often be observed as thread-like fibrillar structures, sometimes assembled further into larger aggregates or plaques. These diseases include a range of sporadic, familial or transmissible degenerative diseases, some of which affect the brain and the central nervous system (e.g. Alzheimer’s and Creutzfeldt-Jakob diseases), while others involve peripheral tissues and organs such as the liver, heart and spleen (e.g. systemic amyloidoses and type II diabetes) [7, 8]. In other forms of amyloidosis, such as primary or secondary systemic amyloidoses, proteinaceous deposits are found in skeletal tissue and joints (e.g. haemodialysis-related amyloidosis) as well as in several organs (e.g. heart and kidney). Yet other components such as collagen, glycosaminoglycans and proteins (e.g. serum amyloid protein) are often present in the deposits protecting them against degradation [9, 10, 11]. Similar deposits to those in the amyloidoses are, however, found intracellularly in other diseases; these can be localised either in the cytoplasm, in the form of specialised aggregates known as aggresomes or as Lewy or Russell bodies or in the nucleus (see below).
The presence in tissue of proteinaceous deposits is a hallmark of all these diseases, suggesting a causative link between aggregate formation and pathological symptoms (often known as the amyloid hypothesis) [7, 8, 12]. At the present time the link between amyloid formation and disease is widely accepted on the basis of a large number of biochemical and genetic studies. The specific nature of the pathogenic species, and the molecular basis of their ability to damage cells, are however, the subject of intense debate [13, 14, 15, 16, 17, 18, 19, 20]. In neurodegenerative disorders it is very likely that the impairment of cellular function follows directly from the interactions of the aggregated proteins with cellular components [21, 22]. In the systemic non-neurological diseases, however, it is widely believed that the accumulation in vital organs of large amounts of amyloid deposits can by itself cause at least some of the clinical symptoms [23]. It is quite possible, however, that there are other more specific effects of aggregates on biochemical processes even in these diseases. The presence of extracellular or intracellular aggregates of a specific polypeptide molecule is a characteristic of all the 20 or so recognised amyloid diseases. The polypeptides involved include full length proteins (e.g. lysozyme or immunoglobulin light chains), biological peptides (amylin, atrial natriuretic factor) and fragments of larger proteins produced as a result of specific processing (e.g. the Alzheimer βpeptide) or of more general degradation [e.g. poly(Q) stretches cleaved from proteins with poly(Q) extensions such as huntingtin, ataxins and the androgen receptor]. The peptides and proteins associated with known amyloid diseases are listed in Table 1. In some cases the proteins involved have wild type sequences, as in sporadic forms of the diseases, but in other cases these are variants resulting from genetic mutations associated with familial forms of the diseases. In some cases both sporadic and familial diseases are associated with a given protein; in this case the mutational variants are usually associated with early-onset forms of the disease. In the case of the neurodegenerative diseases associated with the prion protein some forms of the diseases are transmissible. The existence of familial forms of a number of amyloid diseases has provided significant clues to the origins of the pathologies. For example, there are increasingly strong links between the age at onset of familial forms of disease and the effects of the mutations involved on the propensity of the affected proteins to aggregate in vitro. Such findings also support the link between the process of aggregation and the clinical manifestations of disease [24, 25].
The presence in cells of misfolded or aggregated proteins triggers a complex biological response. In the cytosol, this is referred to as the ‘heat shock response’ and in the endoplasmic reticulum (ER) it is known as the ‘unfolded protein response’. These responses lead to the expression, among others, of the genes for heat shock proteins (Hsp, or molecular chaperone proteins) and proteins involved in the ubiquitin-proteasome pathway [26]. The evolution of such complex biochemical machinery testifies to the fact that it is necessary for cells to isolate and clear rapidly and efficiently any unfolded or incorrectly folded protein as soon as it appears. In itself this fact suggests that these species could have a generally adverse effect on cellular components and cell viability. Indeed, it was a major step forward in understanding many aspects of cell biology when it was recognised that proteins previously associated only with stress, such as heat shock, are in fact crucial in the normal functioning of living systems. This advance, for example, led to the discovery of the role of molecular chaperones in protein folding and in the normal ‘housekeeping’ processes that are inherent in healthy cells [27, 28]. More recently a number of degenerative diseases, both neurological and systemic, have been linked to, or shown to be affected by, impairment of the ubiquitin-proteasome pathway (Table 2). The diseases are primarily associated with a reduction in either the expression or the biological activity of Hsps, ubiquitin, ubiquitinating or deubiquitinating enzymes and the proteasome itself, as we show below [29, 30, 31, 32], or even to the failure of the quality control mechanisms that ensure proper maturation of proteins in the ER. The latter normally leads to degradation of a significant proportion of polypeptide chains before they have attained their native conformations through retrograde translocation to the cytosol [33, 34].
….
It is now well established that the molecular basis of protein aggregation into amyloid structures involves the existence of ‘misfolded’ forms of proteins, i.e. proteins that are not in the structures in which they normally function in vivo or of fragments of proteins resulting from degradation processes that are inherently unable to fold [4, 7, 8, 36]. Aggregation is one of the common consequences of a polypeptide chain failing to reach or maintain its functional three-dimensional structure. Such events can be associated with specific mutations, misprocessing phenomena, aberrant interactions with metal ions, changes in environmental conditions, such as pH or temperature, or chemical modification (oxidation, proteolysis). Perturbations in the conformational properties of the polypeptide chain resulting from such phenomena may affect equilibrium 1 in Fig. 1 increasing the population of partially unfolded, or misfolded, species that are much more aggregation-prone than the native state.
Fig. 1 Overview of the possible fates of a newly synthesised polypeptide chain. The equilibrium ① between the partially folded molecules and the natively folded ones is usually strongly in favour of the latter except as a result of specific mutations, chemical modifications or partially destabilising solution conditions. The increased equilibrium populations of molecules in the partially or completely unfolded ensemble of structures are usually degraded by the proteasome; when this clearance mechanism is impaired, such species often form disordered aggregates or shift equilibrium ② towards the nucleation of pre-fibrillar assemblies that eventually grow into mature fibrils (equilibrium ③). DANGER! indicates that pre-fibrillar aggregates in most cases display much higher toxicity than mature fibrils. Heat shock proteins (Hsp) can suppress the appearance of pre-fibrillar assemblies by minimising the population of the partially folded molecules by assisting in the correct folding of the nascent chain and the unfolded protein response target incorrectly folded proteins for degradation.
……
Little is known at present about the detailed arrangement of the polypeptide chains themselves within amyloid fibrils, either those parts involved in the core βstrands or in regions that connect the various β-strands. Recent data suggest that the sheets are relatively untwisted and may in some cases at least exist in quite specific supersecondary structure motifs such as β-helices [6, 40] or the recently proposed µ-helix [41]. It seems possible that there may be significant differences in the way the strands are assembled depending on characteristics of the polypeptide chain involved [6, 42]. Factors including length, sequence (and in some cases the presence of disulphide bonds or post-translational modifications such as glycosylation) may be important in determining details of the structures. Several recent papers report structural models for amyloid fibrils containing different polypeptide chains, including the Aβ40 peptide, insulin and fragments of the prion protein, based on data from such techniques as cryo-electron microscopy and solid-state magnetic resonance spectroscopy [43, 44]. These models have much in common and do indeed appear to reflect the fact that the structures of different fibrils are likely to be variations on a common theme [40]. It is also emerging that there may be some common and highly organised assemblies of amyloid protofilaments that are not simply extended threads or ribbons. It is clear, for example, that in some cases large closed loops can be formed [45, 46, 47], and there may be specific types of relatively small spherical or ‘doughnut’ shaped structures that can result in at least some circumstances (see below).
…..
The similarity of some early amyloid aggregates with the pores resulting from oligomerisation of bacterial toxins and pore-forming eukaryotic proteins (see below) also suggest that the basic mechanism of protein aggregation into amyloid structures may not only be associated with diseases but in some cases could result in species with functional significance. Recent evidence indicates that a variety of micro-organisms may exploit the controlled aggregation of specific proteins (or their precursors) to generate functional structures. Examples include bacterial curli [52] and proteins of the interior fibre cells of mammalian ocular lenses, whose β-sheet arrays seem to be organised in an amyloid-like supramolecular order [53]. In this case the inherent stability of amyloid-like protein structure may contribute to the long-term structural integrity and transparency of the lens. Recently it has been hypothesised that amyloid-like aggregates of serum amyloid A found in secondary amyloidoses following chronic inflammatory diseases protect the host against bacterial infections by inducing lysis of bacterial cells [54]. One particularly interesting example is a ‘misfolded’ form of the milk protein α-lactalbumin that is formed at low pH and trapped by the presence of specific lipid molecules [55]. This form of the protein has been reported to trigger apoptosis selectively in tumour cells providing evidence for its importance in protecting infants from certain types of cancer [55]. ….
Amyloid formation is a generic property of polypeptide chains ….
It is clear that the presence of different side chains can influence the details of amyloid structures, particularly the assembly of protofibrils, and that they give rise to the variations on the common structural theme discussed above. More fundamentally, the composition and sequence of a peptide or protein affects profoundly its propensity to form amyloid structures under given conditions (see below).
Because the formation of stable protein aggregates of amyloid type does not normally occur in vivo under physiological conditions, it is likely that the proteins encoded in the genomes of living organisms are endowed with structural adaptations that mitigate against aggregation under these conditions. A recent survey involving a large number of structures of β-proteins highlights several strategies through which natural proteins avoid intermolecular association of β-strands in their native states [65]. Other surveys of protein databases indicate that nature disfavours sequences of alternating polar and nonpolar residues, as well as clusters of several consecutive hydrophobic residues, both of which enhance the tendency of a protein to aggregate prior to becoming completely folded [66, 67].
……
Precursors of amyloid fibrils can be toxic to cells
It was generally assumed until recently that the proteinaceous aggregates most toxic to cells are likely to be mature amyloid fibrils, the form of aggregates that have been commonly detected in pathological deposits. It therefore appeared probable that the pathogenic features underlying amyloid diseases are a consequence of the interaction with cells of extracellular deposits of aggregated material. As well as forming the basis for understanding the fundamental causes of these diseases, this scenario stimulated the exploration of therapeutic approaches to amyloidoses that focused mainly on the search for molecules able to impair the growth and deposition of fibrillar forms of aggregated proteins. ….
Structural basis and molecular features of amyloid toxicity
The presence of toxic aggregates inside or outside cells can impair a number of cell functions that ultimately lead to cell death by an apoptotic mechanism [95, 96]. Recent research suggests, however, that in most cases initial perturbations to fundamental cellular processes underlie the impairment of cell function induced by aggregates of disease-associated polypeptides. Many pieces of data point to a central role of modifications to the intracellular redox status and free Ca2+ levels in cells exposed to toxic aggregates [45, 89, 97, 98, 99, 100, 101]. A modification of the intracellular redox status in such cells is associated with a sharp increase in the quantity of reactive oxygen species (ROS) that is reminiscent of the oxidative burst by which leukocytes destroy invading foreign cells after phagocytosis. In addition, changes have been observed in reactive nitrogen species, lipid peroxidation, deregulation of NO metabolism [97], protein nitrosylation [102] and upregulation of heme oxygenase-1, a specific marker of oxidative stress [103]. ….
Results have recently been reported concerning the toxicity towards cultured cells of aggregates of poly(Q) peptides which argues against a disease mechanism based on specific toxic features of the aggregates. These results indicate that there is a close relationship between the toxicity of proteins with poly(Q) extensions and their nuclear localisation. In addition they support the hypotheses that the toxicity of poly(Q) aggregates can be a consequence of altered interactions with nuclear coactivator or corepressor molecules including p53, CBP, Sp1 and TAF130 or of the interaction with transcription factors and nuclear coactivators, such as CBP, endowed with short poly(Q) stretches ([95] and references therein)…..
Concluding remarks
The data reported in the past few years strongly suggest that the conversion of normally soluble proteins into amyloid fibrils and the toxicity of small aggregates appearing during the early stages of the formation of the latter are common or generic features of polypeptide chains. Moreover, the molecular basis of this toxicity also appears to display common features between the different systems that have so far been studied. The ability of many, perhaps all, natural polypeptides to ‘misfold’ and convert into toxic aggregates under suitable conditions suggests that one of the most important driving forces in the evolution of proteins must have been the negative selection against sequence changes that increase the tendency of a polypeptide chain to aggregate. Nevertheless, as protein folding is a stochastic process, and no such process can be completely infallible, misfolded proteins or protein folding intermediates in equilibrium with the natively folded molecules must continuously form within cells. Thus mechanisms to deal with such species must have co-evolved with proteins. Indeed, it is clear that misfolding, and the associated tendency to aggregate, is kept under control by molecular chaperones, which render the resulting species harmless assisting in their refolding, or triggering their degradation by the cellular clearance machinery [166, 167, 168, 169, 170, 171, 172, 173, 175, 177, 178].
Misfolded and aggregated species are likely to owe their toxicity to the exposure on their surfaces of regions of proteins that are buried in the interior of the structures of the correctly folded native states. The exposure of large patches of hydrophobic groups is likely to be particularly significant as such patches favour the interaction of the misfolded species with cell membranes [44, 83, 89, 90, 91, 93]. Interactions of this type are likely to lead to the impairment of the function and integrity of the membranes involved, giving rise to a loss of regulation of the intracellular ion balance and redox status and eventually to cell death. In addition, misfolded proteins undoubtedly interact inappropriately with other cellular components, potentially giving rise to the impairment of a range of other biological processes. Under some conditions the intracellular content of aggregated species may increase directly, due to an enhanced propensity of incompletely folded or misfolded species to aggregate within the cell itself. This could occur as the result of the expression of mutational variants of proteins with decreased stability or cooperativity or with an intrinsically higher propensity to aggregate. It could also occur as a result of the overproduction of some types of protein, for example, because of other genetic factors or other disease conditions, or because of perturbations to the cellular environment that generate conditions favouring aggregation, such as heat shock or oxidative stress. Finally, the accumulation of misfolded or aggregated proteins could arise from the chaperone and clearance mechanisms becoming overwhelmed as a result of specific mutant phenotypes or of the general effects of ageing [173, 174].
The topics discussed in this review not only provide a great deal of evidence for the ‘new view’ that proteins have an intrinsic capability of misfolding and forming structures such as amyloid fibrils but also suggest that the role of molecular chaperones is even more important than was thought in the past. The role of these ubiquitous proteins in enhancing the efficiency of protein folding is well established [185]. It could well be that they are at least as important in controlling the harmful effects of misfolded or aggregated proteins as in enhancing the yield of functional molecules.
Nutritional Status is Associated with Faster Cognitive Decline and Worse Functional Impairment in the Progression of Dementia: The Cache County Dementia Progression Study1
Nutritional status may be a modifiable factor in the progression of dementia. We examined the association of nutritional status and rate of cognitive and functional decline in a U.S. population-based sample. Study design was an observational longitudinal study with annual follow-ups up to 6 years of 292 persons with dementia (72% Alzheimer’s disease, 56% female) in Cache County, UT using the Mini-Mental State Exam (MMSE), Clinical Dementia Rating Sum of Boxes (CDR-sb), and modified Mini Nutritional Assessment (mMNA). mMNA scores declined by approximately 0.50 points/year, suggesting increasing risk for malnutrition. Lower mMNA score predicted faster rate of decline on the MMSE at earlier follow-up times, but slower decline at later follow-up times, whereas higher mMNA scores had the opposite pattern (mMNA by time β= 0.22, p = 0.017; mMNA by time2 β= –0.04, p = 0.04). Lower mMNA score was associated with greater impairment on the CDR-sb over the course of dementia (β= 0.35, p < 0.001). Assessment of malnutrition may be useful in predicting rates of progression in dementia and may provide a target for clinical intervention.
Shared Genetic Risk Factors for Late-Life Depression and Alzheimer’s Disease
Background: Considerable evidence has been reported for the comorbidity between late-life depression (LLD) and Alzheimer’s disease (AD), both of which are very common in the general elderly population and represent a large burden on the health of the elderly. The pathophysiological mechanisms underlying the link between LLD and AD are poorly understood. Because both LLD and AD can be heritable and are influenced by multiple risk genes, shared genetic risk factors between LLD and AD may exist. Objective: The objective is to review the existing evidence for genetic risk factors that are common to LLD and AD and to outline the biological substrates proposed to mediate this association. Methods: A literature review was performed. Results: Genetic polymorphisms of brain-derived neurotrophic factor, apolipoprotein E, interleukin 1-beta, and methylenetetrahydrofolate reductase have been demonstrated to confer increased risk to both LLD and AD by studies examining either LLD or AD patients. These results contribute to the understanding of pathophysiological mechanisms that are common to both of these disorders, including deficits in nerve growth factors, inflammatory changes, and dysregulation mechanisms involving lipoprotein and folate. Other conflicting results have also been reviewed, and few studies have investigated the effects of the described polymorphisms on both LLD and AD. Conclusion: The findings suggest that common genetic pathways may underlie LLD and AD comorbidity. Studies to evaluate the genetic relationship between LLD and AD may provide insights into the molecular mechanisms that trigger disease progression as the population ages.
Association of Vitamin B12, Folate, and Sulfur Amino Acids With Brain Magnetic Resonance Imaging Measures in Older Adults: A Longitudinal Population-Based Study
Importance Vitamin B12, folate, and sulfur amino acids may be modifiable risk factors for structural brain changes that precede clinical dementia.
Objective To investigate the association of circulating levels of vitamin B12, red blood cell folate, and sulfur amino acids with the rate of total brain volume loss and the change in white matter hyperintensity volume as measured by fluid-attenuated inversion recovery in older adults.
Design, Setting, and Participants The magnetic resonance imaging subsample of the Swedish National Study on Aging and Care in Kungsholmen, a population-based longitudinal study in Stockholm, Sweden, was conducted in 501 participants aged 60 years or older who were free of dementia at baseline. A total of 299 participants underwent repeated structural brain magnetic resonance imaging scans from September 17, 2001, to December 17, 2009.
Main Outcomes and Measures The rate of brain tissue volume loss and the progression of total white matter hyperintensity volume.
Results In the multi-adjusted linear mixed models, among 501 participants (300 women [59.9%]; mean [SD] age, 70.9 [9.1] years), higher baseline vitamin B12 and holotranscobalamin levels were associated with a decreased rate of total brain volume loss during the study period: for each increase of 1 SD, β (SE) was 0.048 (0.013) for vitamin B12 (P < .001) and 0.040 (0.013) for holotranscobalamin (P = .002). Increased total homocysteine levels were associated with faster rates of total brain volume loss in the whole sample (β [SE] per 1-SD increase, –0.035 [0.015]; P = .02) and with the progression of white matter hyperintensity among participants with systolic blood pressure greater than 140 mm Hg (β [SE] per 1-SD increase, 0.000019 [0.00001]; P = .047). No longitudinal associations were found for red blood cell folate and other sulfur amino acids.
Conclusions and Relevance This study suggests that both vitamin B12 and total homocysteine concentrations may be related to accelerated aging of the brain. Randomized clinical trials are needed to determine the importance of vitamin B12supplementation on slowing brain aging in older adults.
Notes from Kurzweill
This vitamin stops the aging process in organs, say Swiss researchers
A potential breakthrough for regenerative medicine, pending further studies
Improved muscle stem cell numbers and muscle function in NR-treated aged mice: Newly regenerated muscle fibers 7 days after muscle damage in aged mice (left: control group; right: fed NR). (Scale bar = 50 μm). (credit: Hongbo Zhang et al./Science) http://www.kurzweilai.net/images/improved-muscle-fibers.png
EPFL researchers have restored the ability of mice organs to regenerate and extend life by simply administering nicotinamide riboside (NR) to them.
NR has been shown in previous studies to be effective in boosting metabolism and treating a number of degenerative diseases. Now, an article by PhD student Hongbo Zhang published in Science also describes the restorative effects of NR on the functioning of stem cells for regenerating organs.
As in all mammals, as mice age, the regenerative capacity of certain organs (such as the liver and kidneys) and muscles (including the heart) diminishes. Their ability to repair them following an injury is also affected. This leads to many of the disorders typical of aging.
Mitochondria —> stem cells —> organs
To understand how the regeneration process deteriorates with age, Zhang teamed up with colleagues from ETH Zurich, the University of Zurich, and universities in Canada and Brazil. By using several biomarkers, they were able to identify the molecular chain that regulates how mitochondria — the “powerhouse” of the cell — function and how they change with age. “We were able to show for the first time that their ability to function properly was important for stem cells,” said Auwerx.
Under normal conditions, these stem cells, reacting to signals sent by the body, regenerate damaged organs by producing new specific cells. At least in young bodies. “We demonstrated that fatigue in stem cells was one of the main causes of poor regeneration or even degeneration in certain tissues or organs,” said Zhang.
How to revitalize stem cells
Which is why the researchers wanted to “revitalize” stem cells in the muscles of elderly mice. And they did so by precisely targeting the molecules that help the mitochondria to function properly. “We gave nicotinamide riboside to 2-year-old mice, which is an advanced age for them,” said Zhang.
“This substance, which is close to vitamin B3, is a precursor of NAD+, a molecule that plays a key role in mitochondrial activity. And our results are extremely promising: muscular regeneration is much better in mice that received NR, and they lived longer than the mice that didn’t get it.”
Parallel studies have revealed a comparable effect on stem cells of the brain and skin. “This work could have very important implications in the field of regenerative medicine,” said Auwerx. This work on the aging process also has potential for treating diseases that can affect — and be fatal — in young people, like muscular dystrophy (myopathy).
So far, no negative side effects have been observed following the use of NR, even at high doses. But while it appears to boost the functioning of all cells, it could include pathological ones, so further in-depth studies are required.
Abstract of NAD+ repletion improves mitochondrial and stem cell function and enhances life span in mice
Adult stem cells (SCs) are essential for tissue maintenance and regeneration yet are susceptible to senescence during aging. We demonstrate the importance of the amount of the oxidized form of cellular nicotinamide adenine dinucleotide (NAD+) and its impact on mitochondrial activity as a pivotal switch to modulate muscle SC (MuSC) senescence. Treatment with the NAD+ precursor nicotinamide riboside (NR) induced the mitochondrial unfolded protein response (UPRmt) and synthesis of prohibitin proteins, and this rejuvenated MuSCs in aged mice. NR also prevented MuSC senescence in the Mdx mouse model of muscular dystrophy. We furthermore demonstrate that NR delays senescence of neural SCs (NSCs) and melanocyte SCs (McSCs), and increased mouse lifespan. Strategies that conserve cellular NAD+ may reprogram dysfunctional SCs and improve lifespan in mammals.
Discriminating the gene target of a distal regulatory element from other nearby transcribed genes is a challenging problem with the potential to illuminate the causal underpinnings of complex diseases. We present TargetFinder, a computational method that reconstructs regulatory landscapes from diverse features along the genome. The resulting models accurately predict individual enhancer–promoter interactions across multiple cell lines with a false discovery rate up to 15 times smaller than that obtained using the closest gene. By evaluating the genomic features driving this accuracy, we uncover interactions between structural proteins, transcription factors, epigenetic modifications, and transcription that together distinguish interacting from non-interacting enhancer–promoter pairs. Most of this signature is not proximal to the enhancers and promoters but instead decorates the looping DNA. We conclude that complex but consistent combinations of marks on the one-dimensional genome encode the three-dimensional structure of fine-scale regulatory interactions.
Scientists from the University of Leicester and the University of Maryland have reversed Alzheimer’s and Parkinson’s symptoms by inhibiting an enzyme in fruit fly models, highlighting a new avenue to treat neurodegenerative diseases.
Maryland’s Robert Schwarcz and Leicester’s Flaviano Giorgini studied the amino acid tryptophan, which degrades in the body into several metabolites that have different effects on the nervous system. These include 3-hydroxykynurenine (3-HK), which can damage the nervous system, and kynurenic acid (KYNA), which can prevent nerve degeneration. The relative abundance of these two compounds in the brain could be critical in Parkinson’s, Alzheimer’s and Huntington’s disease, the University of Maryland said in a statement.
3-HK and KYNA exist in a balance between “good” and “bad” metabolites in the body. In neurodegenerative disease, the balance shifts toward the “bad,” Giorgini said in a statement. The researchers shifted the balance back toward “good” by giving genetically modified fruit flies a chemical that selectively inhibits the enzyme TDO, which controls the relationship between 3-HK and KYNA. This increased levels of the “protective” KYNA, and improved movement and lengthened life span in fruit flies genetically modified to model neurodegenerative disease.
Giorgini’s team at Leicester has previously used genetic approaches to inhibit TDO and another enzyme, KMO. The treatment lowered the levels of toxic tryptophan metabolites and reduced neuron loss in fruit fly models of Huntington’s disease.
It is estimated that 5 million Americans have Alzheimer’s disease and as many as 1 million have Parkinson’s. Current treatments may help to control symptoms but do not halt or delay disease progression. “Our hope is that by improving our knowledge of how these nerve cells become sick and die in the brain, we can help devise ways to interfere with these processes, and thereby either delay disease onset or prevent disease altogether,” Giorgini said in the Leicester statement. Giorgini’s next step will be to validate the work in mammalian models.
Meanwhile, a UC San Diego team recently spotlighted the dendritic spines of neurons as a possible target in Alzheimer’s. And The Wall Street Journalreported this week that seniors are clamoring to participate in a clinical trial to see if the diabetes drug metformin can stave off the diseases that come with aging, including cognitive decline.
– here’s a statement from the University of Maryland
– and here’s the University of Leicester’s statement
– read the study abstract
Tryptophan-2,3-dioxygenase (TDO) inhibition ameliorates neurodegeneration by modulation of kynurenine pathway metabolites
Neurodegenerative diseases such as Alzheimer’s (AD), Parkinson’s (PD), and Huntington’s (HD) present a significant and increasing burden on society. Perturbations in the kynurenine pathway (KP) of tryptophan degradation have been linked to the pathogenesis of these disorders, and thus manipulation of this pathway may have therapeutic relevance. Here we show that genetic inhibition of two KP enzymes—kynurenine-3-monooxygenase and tryptophan-2,3-dioxygenase (TDO)—improved neurodegeneration and other disease symptoms in fruit fly models of AD, PD, and HD, and that alterations in levels of neuroactive KP metabolites likely underlie the beneficial effects. Furthermore, we find that inhibition of TDO using a drug-like compound reverses several disease phenotypes, underscoring the therapeutic promise of targeting this pathway in neurodegenerative disease.
Abstract
Metabolites of the kynurenine pathway (KP) of tryptophan (TRP) degradation have been closely linked to the pathogenesis of several neurodegenerative disorders. Recent work has highlighted the therapeutic potential of inhibiting two critical regulatory enzymes in this pathway—kynurenine-3-monooxygenase (KMO) and tryptophan-2,3-dioxygenase (TDO). Much evidence indicates that the efficacy of KMO inhibition arises from normalizing an imbalance between neurotoxic [3-hydroxykynurenine (3-HK); quinolinic acid (QUIN)] and neuroprotective [kynurenic acid (KYNA)] KP metabolites. However, it is not clear if TDO inhibition is protective via a similar mechanism or if this is instead due to increased levels of TRP—the substrate of TDO. Here, we find that increased levels of KYNA relative to 3-HK are likely central to the protection conferred by TDO inhibition in a fruit fly model of Huntington’s disease and that TRP treatment strongly reduces neurodegeneration by shifting KP flux toward KYNA synthesis. In fly models of Alzheimer’s and Parkinson’s disease, we provide genetic evidence that inhibition of TDO or KMO improves locomotor performance and ameliorates shortened life span, as well as reducing neurodegeneration in Alzheimer’s model flies. Critically, we find that treatment with a chemical TDO inhibitor is robustly protective in these models. Consequently, our work strongly supports targeting of the KP as a potential treatment strategy for several major neurodegenerative disorders and suggests that alterations in the levels of neuroactive KP metabolites could underlie several therapeutic benefits.
The kynurenine pathway (KP), the major catabolic route of tryptophan (TRP) metabolism in mammals (Fig. 1), has been closely linked to the pathogenesis of several brain disorders (1). This pathway contains several neuroactive metabolites, including 3-hydroxykynurenine (3-HK), quinolinic acid (QUIN) and kynurenic acid (KYNA) (2). QUIN is a well-characterized endogenous neurotoxin that specifically activates N-methyl-D-aspartate (NMDA) receptors, thereby inducing excitotoxicity (3, 4). The metabolites 3-HK and QUIN are also neurotoxic via the generation of free radicals and oxidative stress (5, 6). Conversely, KYNA—synthesized by kynurenine aminotransferases (KATs)—is neuroprotective through its antioxidant properties and antagonism of both the α7 nicotinic acetylcholine receptor and the glycine coagonist site of the NMDA receptor (7⇓⇓⇓⇓⇓–13). Levels of these metabolites are regulated at two critical points in the KP: (i) the initial, rate-limiting conversion of TRP into N-formylkynurenine by either tryptophan-2,3-dioxygenase (TDO) or indoleamine-2,3-dioxygenase 1 and 2 (IDO1 and IDO2); and (ii) synthesis of 3-HK from kynurenine by the flavoprotein kynurenine-3-monoxygenase (KMO) (1).
Consequences of KP manipulation. KP metabolites and enzymatic steps are indicated in black, whereas the key KP enzymes TDO, KMO, and KATs are indicated in purple. The metabolites 3-HK and QUIN are neurotoxic (as indicated by red arrows), whereas KYNA and TRP are neuroprotective (as indicated by green arrows). Inhibition of TDO results in increased TRP levels, and either TDO or KMO inhibition leads to a reduction in the 3-HK/KYNA ratio (highlighted in blue). The enzyme 3-hydroxyanthranilic acid dioxygenase is not present in flies, and thus QUIN is not synthesized.
Alterations in levels of the KP metabolites have been observed in a broad range of brain disorders, including both neurodegenerative and psychiatric conditions (14). In neurodegenerative diseases such as Huntington’s (HD), Parkinson’s (PD), and Alzheimer’s (AD), a shift toward increased synthesis of the neurotoxic metabolites QUIN and 3-HK relative to KYNA may contribute to disease (1). Indeed, in patients with HD and HD model mice, 3-HK and QUIN levels are increased in the neostriatum and cortex (15, 16). Moreover, KYNA levels are reduced in the striatum of patients with HD (17). Several studies have also found perturbation in KP metabolites in the blood and cerebrospinal fluid of patients with AD, with decreased levels of KYNA correlating with reduced cognitive performance (18, 19). Similarly, in the basal ganglia of patients with PD, a reduction in KYNA levels combined with increased 3-HK has been observed (20, 21).
Drosophila melanogaster has provided a useful model for interrogation of the KP in both normal physiology and in neurodegenerative disease (22, 23). In fruit flies, TDO and KMO are encoded by vermillion (v) andcinnabar (cn), respectively, and both are implicated in Drosophila eye color pigmentation and brain plasticity (24, 25). In flies, TDO is the sole enzyme that catalyzes the initial step of the KP, as IDO1 and IDO2 are not present (Fig. 1), and so provides a distinctive model for examining the role of this critical step in the pathway. Moreover, we have previously found that downregulating cn and v gene expression significantly reduces neurodegeneration in flies expressing a mutant huntingtin (HTT) fragment—the central causative insult underlying HD (22). We also observed that pharmacological manipulations that reduced the 3-HK/KYNA ratio were always associated with neuroprotection. Notably, reintroduction of physiological levels of 3-HK in HD flies that lacked this metabolite due to KMO inhibition was sufficient to abolish neuroprotection (22). Furthermore, in a Caenorhabditis elegans model of PD, genetic down-regulation of TDO ameliorates α-synuclein (aSyn) toxicity (26). This effect appeared to be independent of changes in the levels of serotonin or KP metabolites but was correlated with increased TRP levels. Supplementing worms with TRP also suppressed aSyn-dependent phenotypes (26). The present study was designed to further define the mechanism(s) that underlies the neuroprotection conferred by TRP treatment and TDO inhibition and to extend our analyses of the neuroprotective potential of the KP to fruit fly models of AD and PD.
Discussion
Impairments in KP metabolism have been linked to several neurodegenerative disorders, and in particular to the pathogenesis of HD (37). Notably, increased levels of 3-HK and QUIN have been measured in the neostriatum and cortex of patients with early stage HD (15), and these changes are associated with an up-regulation of IDO1 transcription (38) and a reduction in the activity of KAT, which is critical for KYNA synthesis (17). These data in patients with HD are supported by observations in HD mice, which show increased cerebral KMO activity (39). We previously found that either genetic or pharmacological inhibition of KMO is protective in HD flies and leads to a corresponding increase in KYNA levels relative to 3-HK (22). Furthermore, we reported that KYNA treatment reduced neurodegeneration in these flies. Here, we have extended this work by generating transgenic flies that overexpress hKAT and thereby synthesize ∼20-fold more KYNA than control flies. This increased formation of KYNA reduced neurodegeneration and eclosion defects in HD model flies. Furthermore, KMO inhibition by RNAi revealed beneficial effects in several behavioral and disease-relevant outcome measures, including larval crawling, longevity, climbing, and rhabdomere degeneration, in AD and PD model flies. These results strongly support the notion that KMO inhibition has relevance as a treatment strategy in a broad range of neurodegenerative diseases. In addition, these data also suggest that the design of small molecules capable of increasing KAT activity could have therapeutic relevance for neurodegenerative disorders.
The present results, demonstrating that both genetic and pharmacological inhibition of TDO provides robust neuroprotection in fly models of AD and PD, also confirmed and extended the results of our previous study, which had identified TDO as a candidate drug target in HD flies (22). These protective effects are associated with a decrease in the 3-HK/KYNA ratio, i.e., a shift toward increased KYNA synthesis. Work inC. elegans has revealed that TDO inhibition is also protective in models of proteotoxicity, although amelioration of the phenotypes occurred independently of changes in the levels of KP metabolites and was instead associated with elevated TRP levels (26). Although the underlying mechanism remained unclear, the favorable effects of high TRP levels in the nematode were substantiated by the fact that TRP treatment conferred robust protection from disease-related phenotypes (Fig. 1). In the present study, too, TRP supplementation of the diet was effective, ameliorating rhabdomere degeneration and eclosion defects in HD flies. However, TRP feeding was also associated with a reduction in the 3-HK/KYNA ratio, suggesting that the protective effects of the amino acid may be linked to an increase in the production of the neuroprotective metabolite KYNA (Fig. 1). Indeed, partial inhibition of KYNA synthesis in TDO-deficient flies proved sufficient to completely reverse neuroprotection. In addition, restoration of physiological 3-HK levels in TDO-deficient HD flies did not reverse neuroprotection, in contrast to KMO-deficient flies (22). In primary neurons, 3-HK toxicity is dependent upon its uptake via neutral amino acid transporters, and coapplication of TRP can block this toxicity by competing for the same transporters (6). Thus, it is possible that the vast excess of TRP observed in the heads of HTT93Q v−/− flies (approximately eightfold versus controls) competes with 3-HK for rhabdomere uptake, thereby requiring hyperphysiological levels of 3-HK to reverse TDO-dependent neuroprotection. A similar mechanism may also contribute to the neuroprotection observed with TRP treatment in general. Herein, we have also found that RNAi knockdown of either cn or v does not increase TRP levels, and thus the neuroprotection observed in the AD and PD flies strongly correlates with a decrease in the 3-HK/KYNA ratio. The mechanism causing TRP treatment to favor KYNA synthesis over the formation of 3-HK in Drosophila, as well as the unexpected qualitative differences in the effects of TDO inhibition and TRP administration on KP metabolism between fruit flies and nematodes, clearly requires further investigation.
Interestingly, we found that QUIN—which is not normally synthesized in fruit flies (30)—potentiated neurodegeneration in HD flies, and reversed the protective effects of KMO inhibition. As the same QUIN treatment did not cause neuron loss in wild-type flies, mutant HTT may potentiate vulnerability by enhancing NMDA receptor function (40, 41) and/or by increasing susceptibility to toxic free radicals (42), i.e., by augmenting the two major mechanisms known to be involved in QUIN-induced neurotoxicity (43). If verified in mammals, a reduction in brain QUIN levels—along with a decrease in 3-HK levels—relative to KYNA could therefore be especially promising in the treatment of HD (44). Our observation of increased levels of QUIN in HTT93Q versus WT flies is enigmatic, but may be due to altered feeding behavior, increased permeability of the blood–brain barrier (45, 46), or differences in KP metabolism, and would be interesting to explore in future studies.
In conclusion, the present set of experiments further validates the hypothesis that KP metabolism is causally linked to neuronal viability and that modulation of the KP constitutes a promising therapeutic strategy for a variety of major neurodegenerative disorders. Notably, we provide the first genetic evidence to our knowledge that KMO inhibition is protective in animal models of PD and AD and that pharmacological targeting of TDO is also neuroprotective. We have clarified the mechanism underlying the protective effects of TDO inhibition, which will stimulate efforts to target this step of the KP in neurodegenerative disease. These results, together with supportive studies in flies (47) and rodents (48), raise the possibility that inhibition of TDO and KMO—or combinatorial treatment—may offer therapeutic advantages. The availability of new TDO inhibitors (49, 50), and access to the crystal structures of both TDO (51) and KMO (52), should allow further testing of these hypotheses in the near future.
Cancer detection and therapeutics, Volume 2 (Volume Two: Latest in Genomics Methodologies for Therapeutics: Gene Editing, NGS and BioInformatics, Simulations and the Genome Ontology), Part 1: Next Generation Sequencing (NGS)
Two announcements yesterday (April 21) suggest that deep learning algorithms rival human skills in detecting cancer from ultrasound images and in identifying cancer in pathology reports.
Samsung Medison RS80A ultrasound imaging system (credit: Samsung)
Samsung Medison, a global medical equipment company and an affiliate of Samsung Electronics, has just updated its RS80A ultrasound imaging system with a deep learning algorithm for breast-lesion analysis.
The “S-Detect for Breast” feature uses big data collected from breast-exam cases and recommends whether the selected lesion is benign or malignant. It’s used in in lesion segmentation, characteristic analysis, and assessment processes, providing “more accurate results.”
“We saw a high level of conformity from analyzing and detecting lesion in various cases by using the S-Detect,” said professor Han Boo Kyung, a radiologist at Samsung Medical Center.
“Users can reduce taking unnecessary biopsies and doctors-in-training will likely have more reliable support in accurately detecting malignant and suspicious lesions.”
Deep learning is better than humans in extracting meaning from cancer pathology reports
Meanwhile, researchers from the Regenstrief Institute and Indiana University School of Informatics and Computing at Indiana University-Purdue University Indianapolis say they’ve found that open-source machine learning tools are as good as — or better than — humans in extracting crucial meaning from free-text (unstructured) pathology reports and detecting cancer cases. The computer tools are also faster and less resource-intensive.
(U.S. states require cancer cases to be reported to statewide cancer registries for disease tracking, identification of at-risk populations, and recognition of unusual trends or clusters. This free-text information can be difficult for health officials to interpret, which can further delay health department action, when action is needed.)
“We think that its no longer necessary for humans to spend time reviewing text reports to determine if cancer is present or not,” said study senior author Shaun Grannis*, M.D., M.S., interim director of the Regenstrief Center of Biomedical Informatics.
Awash in oceans of data
“We have come to the point in time that technology can handle this. A human’s time is better spent helping other humans by providing them with better clinical care. Everything — physician practices, health care systems, health information exchanges, insurers, as well as public health departments — are awash in oceans of data. How can we hope to make sense of this deluge of data? Humans can’t do it — but computers can.”
This is especially relevant for underserved nations, where a majority of clinical data is collected in the form of unstructured free text, he said.
The researchers sampled 7,000 free-text pathology reports from over 30 hospitals that participate in the Indiana Health Information Exchange and used open source tools, classification algorithms, and varying feature selection approaches to predict if a report was positive or negative for cancer. The results indicated that a fully automated review yielded results similar or better than those of trained human reviewers, saving both time and money.
Major infrastructure advance
“We found that artificial intelligence was as least as accurate as humans in identifying cancer cases from free-text clinical data. For example the computer ‘learned’ that the word ‘sheet’ or ‘sheets’ signified cancer as ‘sheet’ or ‘sheets of cells’ are used in pathology reports to indicate malignancy.
“This is not an advance in ideas; it’s a major infrastructure advance — we have the technology, we have the data, we have the software from which we saw accurate, rapid review of vast amounts of data without human oversight or supervision.”
The study was published in the April 2016 issue of the Journal of Biomedical Informatics. It was conducted with support from the Centers for Disease Control and Prevention.
Co-authors of the study include researchers at the IU Fairbanks School of Public Health, the IU School of Medicine and the School of Science at IUPUI.
* Grannis, a Regenstrief Institute investigator and an associate professor of family medicine at the IU School of Medicine, is the architect of the Regenstrief syndromic surveillance detector for communicable diseases and led the technical implementation of Indiana’s Public Health Emergency Surveillance System — one of the nation’s largest. Studies over the past decade have shown that this system detects outbreaks of communicable diseases seven to nine days earlier and finds four times as many cases as human reporting while providing more complete data.
Yann Lecun is Director of AI Research, Facebook and a noted deep-learning expert.
Toward better public health reporting using existing off the shelf approaches: A comparison of alternative cancer detection approaches using plaintext medical data and non-dictionary based feature selection
• Cancer cases can be identified in unstructured clinical data to support public health reporting.
• Such cancer detection methods do not require complex external ontologies or human intervention.
• Such approaches can identify cases with sensitivity, specificity, PPV, accuracy, and AUC exceeding 80–90%.
• Automated cancer detection methods perform as well as approaches that require costly clinician input.
• These approaches may be generalized for other health analytics applications and healthcare domains.
Abstract
Objectives
Increased adoption of electronic health records has resulted in increased availability of free text clinical data for secondary use. A variety of approaches to obtain actionable information from unstructured free text data exist. These approaches are resource intensive, inherently complex and rely on structured clinical data and dictionary-based approaches. We sought to evaluate the potential to obtain actionable information from free text pathology reports using routinely available tools and approaches that do not depend on dictionary-based approaches.
Materials and methods
We obtained pathology reports from a large health information exchange and evaluated the capacity to detect cancer cases from these reports using 3 non-dictionary feature selection approaches, 4 feature subset sizes, and 5 clinical decision models: simple logistic regression, naïve bayes, k-nearest neighbor, random forest, and J48 decision tree. The performance of each decision model was evaluated using sensitivity, specificity, accuracy, positive predictive value, and area under the receiver operating characteristics (ROC) curve.
Results
Decision models parameterized using automated, informed, and manual feature selection approaches yielded similar results. Furthermore, non-dictionary classification approaches identified cancer cases present in free text reports with evaluation measures approaching and exceeding 80–90% for most metrics.
Conclusion
Our methods are feasible and practical approaches for extracting substantial information value from free text medical data, and the results suggest that these methods can perform on par, if not better, than existing dictionary-based approaches. Given that public health agencies are often under-resourced and lack the technical capacity for more complex methodologies, these results represent potentially significant value to the public health field.
Schematic of a magnetic microbubble used in the study, containing gas core (blue) and shell of magnetic iron-oxide nanoparticles (red) that form a dense shell (center) around drug-containing nanoparticles. When stimulated by ultrasound at resonant frequencies, the microbubbles explode, releasing the nanoparticles, which can travel hundreds of micrometers into tumor tissue to deliver anticancer drugs and can also be imaged on an MRI machine. (credit: Yu Gao et al./NPG Asia Materials) http://www.kurzweilai.net/images/magnetic-microbubble.jpg
They created micro-sized gas bubbles coated with anticancer drug particles embedded in iron oxide nanoparticles and used MRI or other magnetic sources to direct these microbubbles to gather around a specific tumor. Then they used ultrasound to vibrate the microbubbles, providing the energy to direct the drug particles into a targeted kill zone in the tumor. The magnetic nanoparticles also allow for imaging in an MRI machine.
The microbubbles were successfully tested in mice and the study has been published by the Nature Publishing Groupin Asia Materials.
Overcoming limitations of chemotherapy
This innovative technique was developed by a multidisciplinary team of scientists led by Asst Prof C. J. Xu from the School of Chemical and Biomedical Engineering and Assoc. Prof Claus-Dieter Ohl from the School of Physical and Mathematical Sciences.
Xu, who is also a researcher at the NTU-Northwestern Institute for Nanomedicine, said their new method may solve some of the most pressing problems faced in chemotherapy used to treat cancer.
The main problem is that current chemotherapy drugs cannot be easily targeted. The drug particles flow in the bloodstream, damaging both healthy and cancerous cells. Typically, these drugs are flushed away quickly in organs such as the lungs and liver, limiting their effectiveness.
The remaining drugs are also unable to penetrate deep into the core of the tumor, leaving some cancer cells alive, which could lead to a resurgence in tumor growth.
The microbubbles are magnetic, so after injecting them into the bloodstream, they can be clustered around the tumor using magnets to ensure that they don’t kill the healthy cells, explains Xu, who has been working on cancer diagnosis and drug delivery systems since 2004.
“More importantly, our invention is the first of its kind that allows drug particles to be directed deep into a tumor in a few milliseconds. They can penetrate a depth of 50 cell layers or more (about 200 micrometers) — twice the width of a human hair. This helps to ensure that the drugs can reach the cancer cells on the surface and also inside the core of the tumor.”
According to Clinical Associate Professor Chia Sing Joo, a Senior Consultant at the Tan Tock Seng Hospital’s Endoscopy Centre and the Urology & Continence Clinic, “For anticancer drugs to achieve their best effectiveness, they need to penetrate into the tumor efficiently in order to reach the cytoplasm of all the cancer cells that are being targeted without affecting the normal cells.
“Currently, this can [only] be achieved by means of a direct injection into the tumor or by administering a large dosage of anticancer drugs, which can be painful, expensive, impractical and might have various side effects. If successful, I envisage [the new drug-delivery system] can be a good alternative treatment in the future, one which is low cost and yet effective for the treatment of cancers involving solid tumors, as it might minimize the side effects of drugs.” Joo is a surgeon experienced in the treatment of prostate, bladder and kidney cancer and a consultant for this study.
According to Ohl, an expert in biophysics who has published previous studies involving drug delivery systems and bubble dynamics, “most prototype drug delivery systems on the market face three main challenges before they can be commercially successful: they have to be non-invasive, patient-friendly, and yet cost-effective. We were able to come up with our solution that addresses these three challenges.”
The 12-person study team included scientists from City University of Hong Kong and Technion – Israel Institute of Technology (Technion). The team plans to use this new drug delivery system in studies on lung and liver cancer using animal models, and eventually clinical studies.
They estimate that it will take another eight to ten years before it reaches human clinical trials.
Abstract of Controlled nanoparticle release from stable magnetic microbubble oscillations
Magnetic microbubbles (MMBs) are microbubbles (MBs) coated with magnetic nanoparticles (NPs). MMBs not only maintain the acoustic properties of MBs, but also serve as an important contrast agent for magnetic resonance imaging. Such dual-modality functionality makes MMBs particularly useful for a wide range of biomedical applications, such as localized drug/gene delivery. This article reports the ability of MMBs to release their particle cargo on demand under stable oscillation. When stimulated by ultrasound at resonant frequencies, MMBs of 450 nm to 200 μm oscillate in volume and surface modes. Above an oscillation threshold, NPs are released from the MMB shell and can travel hundreds of micrometers from the surface of the bubble. The migration of NPs from MMBs can be described with a force balance model. With this technology, we deliver doxorubicin-containing poly(lactic-co-glycolic acid) particles across a physiological barrier bothin vitro and in vivo, with a 18-fold and 5-fold increase in NP delivery to the heart tissue of zebrafish and tumor tissue of mouse, respectively. The penetration of released NPs in tissues is also improved. The ability to remotely control the release of NPs from MMBs suggests opportunities for targeted drug delivery through/into tissues that are not easily diffused through or penetrated.
Artificial protein controls first self-assembly of C60 fullerenes
New discovery expected to lead to new materials with properties such as higher strength, lighter weight, and greater chemical reactivity, resulting in applications ranging from medicine to energy and electronics
A Dartmouth College scientist and his collaborators* have created the first high-resolution co-assembly between a protein and buckminsterfullerene (C60), aka fullerene and buckyball (a sphere-like molecule composed of 60 carbon atoms and shaped like a soccer ball).
“This is a proof-of-principle study demonstrating that proteins can be used as effective vehicles for organizing nanomaterials by design,” says senior author Gevorg Grigoryan, an assistant professor of computer science at Dartmouth and senior author of a study discussed in an open-access paper in the journal in Nature Communications.
Proteins organize and orchestrate essentially all molecular processes in our cells. The goal of the new study was to create a new artificial protein that can direct the self-assembly of fullerene into ordered superstructures.
COP, a stable tetramer (a polymer derived from four identical single molecule) in isolation, interacts with C60 (fullerene) molecules via a surface-binding site and further self-assembles into a co-crystalline array called C60Sol–COP (credit: Kook-Han Kim et al./Nature Communications) http://www.kurzweilai.net/images/self-assembly-with-fullernene.jpg
Grigoryan and his colleagues show that that their artificial protein organizes a fullerene into a lattice called C60Sol–COP. COP, a protein that is a stable tetramer (a polymer derived from four identical single molecules), interacted with fullerene molecules via a surface-binding site and further self-assembled into an ordered crystalline superstructure. Interestingly, the superstructure exhibits high charge conductance, whereas both the protein-alone crystal and amorphous C60 are electrically insulating.
Grigoryan says that if we learn to do the programmable self-assembly of precisely organized molecular building blocks more generally, it will lead to a range of new materials with properties such as higher strength, lighter weight, and greater chemical reactivity, resulting in a host of applications, from medicine to energy and electronics.
Fullerenes are currently used in nanotechnology because of their high heat resistance and electrical superconductivity (when doped), but the molecule has been difficult to organize in useful ways.
* The study also included researchers from Dartmouth College, Sungkyunkwan University, the New Jersey Institute of Technology, the National Institute of Science Education and Research, the University of California-San Francisco, the University of Pennsylvania, and the Institute for Basic Science.
Abstract of Protein-directed self-assembly of a fullerene crystal
Learning to engineer self-assembly would enable the precise organization of molecules by design to create matter with tailored properties. Here we demonstrate that proteins can direct the self-assembly of buckminsterfullerene (C60) into ordered superstructures. A previously engineered tetrameric helical bundle binds C60 in solution, rendering it water soluble. Two tetramers associate with one C60, promoting further organization revealed in a 1.67-Å crystal structure. Fullerene groups occupy periodic lattice sites, sandwiched between two Tyr residues from adjacent tetramers. Strikingly, the assembly exhibits high charge conductance, whereas both the protein-alone crystal and amorphous C60 are electrically insulating. The affinity of C60 for its crystal-binding site is estimated to be in the nanomolar range, with lattices of known protein crystals geometrically compatible with incorporating the motif. Taken together, these findings suggest a new means of organizing fullerene molecules into a rich variety of lattices to generate new properties by design.
Programmable self-assembly of molecular building blocks is a highly desirable way of achieving bottom-up control over novel functions and materials. Applications of molecular assemblies are well explored in the literature, ranging from optoelectronic1, 2, magnetic3, and photovoltaic4 devices to chemical and bioanalytical sensing5, and medicine6. However, it has been a daunting challenge to quantitatively describe and control the driving forces that govern self-assembly, particularly given the broad range of molecular building blocks one would like to organize. In this respect, nature’s self-assembling macromolecules hold considerable promise as standard chassis for encoding precise organization. By learning to engineer the assembly of these molecules, myriad other molecular building blocks can be co-organized in desired ways through non-covalent or covalent attachment. The protein polymer is a particularly attractive candidate for a standard assembly chassis given its rich chemical alphabet, diversity of available assembly geometries, broad ability to engage other molecular moieties, and the possibility of engineered function. Considerable progress has been made in the area of engineering protein assemblies7, 8, using either computational9, 10,11, 12, 13, 14 or rational approaches15, 16, 17, 18, but the problem remains a grand challenge. A major difficulty lies in accounting for the enormous continuum of possible assembly geometries available to proteins to engineer a sequence that predictably prefers just one. General design principles, which provide predictive rules of assembly, are thus of enormous utility in limiting the geometric search space and enabling robust design11, 19.
In this work, we demonstrate the first ever high-resolution structure of co-assembly between a protein and buckminsterfullerene (C60), which suggests a simple structural mode for protein–fullerene co-organization. Three separate crystal structures, resolved to 1.67, 1.76 and 2.35Å, reveal a protein lattice with C60 groups occupying periodic sites wedged between two helical segments, each donating a Tyr residue. A half site of the motif is estimated to have nM-scale affinity for C60, such that binding of fullerene appears to direct the organization of protein units in the co-crystal. The assembly exhibits a nm-spaced helical arrangement of fullerenes along a crystallographic axis, endowing the crystal with electrical conductance properties. We closely investigate the interfacial geometry of the C60-binding motif, finding it to be common among protein crystal lattices. C60 and its derivatives have been previously reported to interact with several proteins20, 21, 22, 23, 24, 25, although a high-resolution structure of a protein–C60 has been lacking. Still, prior evidence of interaction indicates that fullerenes and proteins are compatible as materials. This, together with the simple (and naturally recurrent) geometry of the C60-binding motif we discover, suggests that it may be possible to use the structural principles emergent from our study to generate a variety of C60–protein co-assemblies to further explore and exploit the properties of fullerenes26.
The aim of programmable self-assembly is to anticipate and harness unique collective properties that arise from precisely organized molecular building blocks. To this end, achieving atomic-level precision is crucial. This work demonstrates the first atomic resolution structures of a fullerene–protein assembly, establishing the feasibility of creating such objects, and further suggests a possible design principle for engineering such assemblies in general. How robust the discovered C60-binding motif is towards designing novel assemblies will need to be tested through a number of future design studies. However, the straightforward manner in which self-organization arose in our case, the simplicity of the C60-organizing motif in the lattice, together with its high affinity and the ubiquity of associated interfaces in natural protein lattices, are certainly promising with respect to the general applicability of the design principle. Our work also demonstrates the potential utility of exploring C60/protein co-organization, as derived supercrystals already showed synergistic charge conductance properties. Taken together, these results point to an exciting direction of inquiry towards generating protein–fullerene assemblies for the study and design of novel properties.
Scientists turn skin cells into heart and brain cells using only drugs — no stem cells required
Closer to the natural regeneration that happens in animals like newts and salamanders and no medical-safety and embryo concerns
Neurons created from chemically induced neural stem cells. The cells were created from skin cells that were reprogrammed into neural stem cells using a cocktail of only nine chemicals. This is the first time cellular reprogramming has been accomplished without adding external genes to the cells. (credit: Mingliang Zhang, PhD, Gladstone Institutes) http://www.kurzweilai.net/images/Neurons-Created-From-Chemically-Induced-Neural-Stem-Cells.jpg
Scientists at the Gladstone Institutes have used chemicals to transform skin cells into heart cells and brain cells, instead of adding external genes — making this accomplishment a breakthrough, according to the scientists.
The research lays the groundwork for one day being able to regenerate lost or damaged cells directly with pharmaceutical drugs — a more efficient and reliable method to reprogram cells and one that avoids medical concerns surrounding genetic engineering.
Instead, in two studies published in an open-access paper in Science and in Cell Stem Cell, the team of scientists at the Roddenberry Center for Stem Cell Biology and Medicine at Gladstone used chemical cocktails to gradually coax skin cells to change into organ-specific stem-cell-like cells and ultimately into heart or brain cells.
“This method brings us closer to being able to generate new cells at the site of injury in patients,” said Gladstone senior investigator Sheng Ding, PhD, the senior author on both studies. “Our hope is to one day treat diseases like heart failure or Parkinson’s disease with drugs that help the heart and brain regenerate damaged areas from their own existing tissue cells. This process is much closer to the natural regeneration that happens in animals like newts and salamanders, which has long fascinated us.”
Transplanted adult heart cells do not survive or integrate properly into the heart and few stem cells can be coaxed into becoming heart cells.
Instead, in the Science study, the researchers used a cocktail of nine chemicals to change human skin cells into beating heart cells. By trial and error, they found the best combination of chemicals to begin the process by changing the cells into a state resembling multipotent stem cells (cells that can turn into many different types of cells in a particular organ). A second cocktail of chemicals and growth factors then helped transition the cells to become heart muscle cells.
With this method, more than 97% of the cells began beating, a characteristic of fully developed, healthy heart cells. The cells also responded appropriately to hormones, and molecularly, they resembled heart muscle cells, not skin cells. What’s more, when the cells were transplanted into a mouse heart early in the process, they developed into healthy-looking heart muscle cells within the organ.
“The ultimate goal in treating heart failure is a robust, reliable way for the heart to create new muscle cells,” said Srivastava, co-senior author on the Science paper. “Reprogramming a patient’s own cells could provide the safest and most efficient way to regenerate dying or diseased heart muscle.”
Rejuvenating the brain with neural stem cell-like cells
In the second study, authored by Gladstone postdoctoral scholar Mingliang Zhang, PhD, and published in Cell Stem Cell, the scientists created neural stem-cell-like cells from mouse skin cells using a similar approach.
The chemical cocktail again consisted of nine molecules, some of which overlapped with those used in the first study. Over ten days, the cocktail changed the identity of the cells, until all of the skin-cell genes were turned off and the genes of the neural stem-cell-like cells were gradually turned on.
When transplanted into mice, the neural stem-cell-like cells spontaneously developed into the three basic types of brain cells: neurons, oligodendrocytes, and astrocytes. The neural stem-cell-like cells were also able to self-replicate, making them ideal for treating neurodegenerative diseases or brain injury.
With their improved safety, these neural stem-cell-like cells could one day be used for cell replacement therapy in neurodegenerative diseases like Parkinson’s disease and Alzheimer’s disease, according to co-senior author Yadong Huang, MD, PhD, a senior investigator at Gladstone. “In the future, we could even imagine treating patients with a drug cocktail that acts on the brain or spinal cord, rejuvenating cells in the brain in real time.”
Abstract of Conversion of human fibroblasts into functional cardiomyocytes by small molecules
Reprogramming somatic fibroblasts into alternative lineages would provide a promising source of cells for regenerative therapy. However, transdifferentiating human cells to specific homogeneous, functional cell types is challenging. Here we show that cardiomyocyte-like cells can be generated by treating human fibroblasts with a combination of nine compounds (9C). The chemically induced cardiomyocyte-like cells (ciCMs) uniformly contracted and resembled human cardiomyocytes in their transcriptome, epigenetic, and electrophysiological properties. 9C treatment of human fibroblasts resulted in a more open-chromatin conformation at key heart developmental genes, enabling their promoters/enhancers to bind effectors of major cardiogenic signals. When transplanted into infarcted mouse hearts, 9C-treated fibroblasts were efficiently converted to ciCMs. This pharmacological approach for lineage-specific reprogramming may have many important therapeutic implications after further optimization to generate mature cardiac cells.
Abstract of Pharmacological Reprogramming of Fibroblasts into Neural Stem Cells by Signaling-Directed Transcriptional Activation
Cellular reprogramming using chemically defined conditions, without genetic manipulation, is a promising approach for generating clinically relevant cell types for regenerative medicine and drug discovery. However, small-molecule approaches for inducing lineage-specific stem cells from somatic cells across lineage boundaries have been challenging. Here, we report highly efficient reprogramming of mouse fibroblasts into induced neural stem cell-like cells (ciNSLCs) using a cocktail of nine components (M9). The resulting ciNSLCs closely resemble primary neural stem cells molecularly and functionally. Transcriptome analysis revealed that M9 induces a gradual and specific conversion of fibroblasts toward a neural fate. During reprogramming specific transcription factors such as Elk1 and Gli2 that are downstream of M9-induced signaling pathways bind and activate endogenous master neural genes to specify neural identity. Our study provides an effective chemical approach for generating neural stem cells from mouse fibroblasts and reveals mechanistic insights into underlying reprogramming processes.
A research group at VU University Amsterdam (The Netherlands) has shown that an ultrafast laser technique can reveal exactly where brain tumors are, producing images in less than a minute and enabling surgeons to removetumors without compromising healthy tissue.
Pathologists typically use staining methods, in which chemicals like hematoxylin and eosin turn different tissue components blue and red, revealing its structure and whether there are any tumor cells. But for a definitive diagnosis, this process can take up to 24 hours—which means surgeons may not realize some cancerous tissue has escaped from their attention until after surgery, requiring a second operation and more risk.
But the research team’s new ultrafast laser technique is label-free—instead, they fire short, 20-fs-long laser pulses into the tissue, and when three photons converge at the same time and place, the photons interact with the nonlinear optical properties of the tissue. Through well-known phenomena in optics called second- and third-harmonic generation, these interactions produce a single photon.
The key is that the incoming and outgoing photons have different wavelengths. The incoming photons are at 1200 nm, long enough to penetrate deep into the tissue. The single photon that is produced, however, is at 600 or 400 nm, depending on if it’s second- or third-harmonic generation. The shorter wavelengths mean the photon can scatter in the tissue. The scattered photon thus contains information about the tissue, and when it reaches a detector—in this case, a high-sensitivity gallium arsenide phosphide (GaAsP) photomultiplier tube—it reveals what the tissue looks like inside.
Tissue from a patient diagnosed with low-grade glioma. The green image is taken with the new method, while the pink uses conventional hematoxylin and eosin staining. Going from the upper left to the lower right, both images show increasing cell density because of more tumor tissue. The insets reveal the high density of tumor cells. (Credit: N.V. Kuzmin et al, VU University Amsterdam, The Netherlands)
The research team used the technique to analyze glial brain tumors, which are particularly deadly because it’s hard to get rid of tumor cells by surgery, irradiation, and chemotherapy without substantial collateral damage to the surrounding brain tissue. They tested their method on samples of glial brain tumors from humans, finding that the histological detail in these images was as good—if not better—than those made with conventional staining techniques. They were able to make most images in under a minute. The smaller ones took less than a second, while larger images of a few square millimeters took five minutes—making it possible to do it in real time in the operating room, according to Marloes Groot of VU University Amsterdam, who led the work.
Now that they’ve shown their approach works, the researchers are developing a handheld device that a surgeon can use to identify a tumor’s border during surgery. The incoming laser pulses can only reach a depth of about 100 µm into the tissue. To reach farther, Groot envisions attaching a needle that can pierce the tissue and deliver photons deeper, allowing diagnosis during an operation and possibly before surgery begins.
Third harmonic generation imaging for fast, label-free pathology of human brain tumors
N. V. Kuzmin, P. Wesseling, P. C. de Witt Hamer, D. P. Noske, G. D. Galgano, H. D. Mansvelder, J. C. Baayen, and M. L. Groot Biomedical Optics Express > Volume 7 > Issue 5 > Page 1889
In brain tumor surgery, recognition of tumor boundaries is key. However, intraoperative assessment of tumor boundaries by the neurosurgeon is difficult. Therefore, there is an urgent need for tools that provide the neurosurgeon with pathological information during the operation. We show that third harmonic generation (THG) microscopy provides label-free, real-time images of histopathological quality; increased cellularity, nuclear pleomorphism, and rarefaction of neuropil in fresh, unstained human brain tissue could be clearly recognized. We further demonstrate THG images taken with a GRIN objective, as a step toward in situ THG microendoscopy of tumor boundaries. THG imaging is thus a promising tool for optical biopsies.
We evaluated the effect of cognitive stimulation (CS) on platelet total phospholipases A2activity (tPLA2A) in patients with mild cognitive impairment (MCI_P). At baseline, tPLA2A negatively correlated with Mini-Mental State Examination score (MMSE_s): patients with MMSE_s <26 (Subgroup 1) had significantly higher activity than those with MMSE_s ≥26 (Subgroup 2), who had values similar to the healthy elderly. Regarding CS effect, Subgroup 1 had a significant tPLA2A reduction, whereas Subgroup 2 did not significantly changes after training. Our results showed for the first time that tPLA2A correlates with the cognitive conditions of MCI_P, and that CS acts selectively on subjects with a dysregulated tPLA2A.
Phospholipases A2 (PLA2) form a superfamily of enzymes that catalyze production of lyso-phospholipids and free fatty acids by the hydrolysis of phospholipids sn-2 ester bond. They play a pivotal role in many physiological processes, including membrane remodelingand cell signaling [1, 2], and are involved in neurodegenerative disorders [3, 4].
PLA2 modulation is a potential therapeutic target [5, 6]; in this context, cognitive stimulation (CS) is particularly promising, not only because in animal models it has effective regulating properties [7], but also because it is non-invasive, has no side effects, and presents no contraindications.
To date, only one study has been performed in humans: in a little cohort of healthy elderly subjects, a memory training intervention was proved to modulate platelet PLA2 activity [8]. The use of platelet PLA2 as peripheral biomarker of the neuronal enzyme is convincing in light of the recent finding that total PLA2 (tPLA2) activity in thrombocytes may mirror thetotal activity in the brain [9]. Moreover, platelets are widely considered “circulating neurons” because of the similarities existing between the two cells in terms of enzymes, receptors, and metabolic products [10, 11].
On these grounds, we evaluated the effects of CS on platelet tPLA2 activity in a cohort of subjects with mild cognitive impairment (MCI).
The present study showed that in subjects with MCI, platelet tPLA2 activity correlates with patients’ cognitive conditions, and that CS acts selectively on the enzyme, i.e., it modulates the parameter only in individuals with deregulated values in comparison to the healthy elderly.
Based on the MMSE score, it was possible to subdivide at baseline the MCI cohort into two subgroups: patients with more evident cognitive impairment (MMSE score <26) and significantly higher tPLA2 activity, and individuals cognitively more preserved (MMSE score ≥26), who had tPLA2 activity similar to the healthy elderly. The finding that the increase of tPLA2 activity and the severity of the global cognitive status impairment are significantly linked suggests a possible role of tPLA2 in MCI progression. PLA2 activity alterations may lead to the synthesis of excessive proinflammatory mediators and peroxidative products [19], and inflammation and oxidative stress may contribute to the pathogenesis of Alzheimer’s disease (AD) [20, 21], of which MCI could be a prodromal condition. It is therefore conceivable that the more deregulated tPLA2 is, the more harmful molecules might be released, and the more severe the pathological consequences might become. The finding that in patients affected by AD tPLA2 activity is significantly higher than in healthy controls [22, 23] as well as in MCI subjects [23] is in line with this hypothesis.
As far as the therapeutic potentialities of CS are concerned, the protocol not only exerted positive effects on several cognitive outcomes, but also counteracted the peripheral enzymatic deregulation. Indeed, CS improved parameters linked to memory, attention, and verbal, confirming the results of others [24]. It is worth noting that CS acts on tPLA2 activity in a “dysfunction-dependent” mode: in subjects with an initial enzymatic activity higher than in the healthy elderly (Subgroup 1), CS reduced the value; in subjects with an initial enzymatic activity similar to the healthy elderly (Subgroup 2) CS did not induce any significant change. Thus, CS seems to have homeostatic properties on tPLA2 activity. This result may seem in contradictionwith the observation that in the healthy elderly CS induces platelet tPLA2 increase [8]. Actually, it is conceivable that, in absence of pathology, increased activity produced by the training improves cell functioning while in MCI, where the increased values might be linked to inflammation and oxidative stress, the protocol acts in the opposite way. Indeed, recent evidence supports the use of specific PLA2 inhibitors as preventive/therapeutic agents for inflammatory disorders [25], and several studies showed that environmental enrichment exert anti-inflammatory and neuromodulatory effects [26]. Thus, in MCI and AD, where the involvement of neuroinflammation is well established [27, 28], CS may produce a down regulation effect in the central nervous system, which might influence also circulation blood components.
In conclusion, this study suggests that platelet tPLA2 activity may be useful as peripheral biomarker to differentiate MCI patients at different pathological stages, and sustains the use of CS as non-pharmacological therapeutic strategy.
JNK: A Putative Link Between Insulin Signaling and VGLUT1 in Alzheimer’s Disease
In the present work, the involvement of JNK in insulin signaling alterations and its role in glutamatergic deficits in Alzheimer’s disease (AD) has been studied. In postmortem cortical tissues, pJNK levels were increased, while insulin signaling and the expression of VGLUT1 were decreased. A significant correlation was found between reduced expression of insulin receptor and VGLUT1. The administration of a JNK inhibitor reversed the decrease in VGLUT1 expression found in a mice model of insulin resistance. It is suggested that activation of JNK in AD inhibits insulin signaling which could lead to a decreased expression of VGLUT1, therefore contributing to the glutamatergic deficit in AD.
Normal Amplitude of Electroretinography and Visual Evoked Potential Responses in AβPP/PS1 Mice
Alzheimer’s disease has been shown to affect vision in human patients and animal models. This may pose the risk of bias in behavior studies and therefore requires comprehensive investigation. We recorded electroretinography (ERG) under isoflurane anesthesia and visual evoked potentials (VEP) in awake amyloid expressing AβPPswe/PS1dE9 (AβPP/PS1) and wild-type littermate mice at a symptomatic age. The VEPs in response to patterned stimuli were normal in AβPP/PS1 mice. They also showed normal ERG amplitude but slightly shortened ERG latency in dark-adapted conditions. Our results indicate subtle changes in visual processing in aged male AβPP/PS1 mice specifically at a retinal level.
Brain Metabolism Correlates of The Free and Cued Selective Reminding Test in Mild Cognitive Impairment
Free and Cued Selective Reminding Test (FCSRT) measures immediate and delayed episodic memory and cueing sensitivity and is suitable to detect prodromal Alzheimer’s disease (AD). The present study aimed at investigating the segregation effect of FCSRT scores on brain metabolism of memory-related structures, usually affected by AD pathology, in the Mild Cognitive Impairment (MCI) stage. A cohort of forty-eight MCI patients underwent FCSRT and 18F-FDG-PET. Multiple regression analysis showed that Immediate Free Recall correlated with brain metabolism in the bilateral anterior cingulate and delayed free recall with the left anterior cingulate and medial frontal gyrus, whereas semantic cueing sensitivity with the left posterior cingulate. FCSRT in MCI is associated with neuro-functional activity of specific regions of memory-related structures connected to hippocampal formation, such as the cingulate cortex, usually damaged in AD.
The Presence of Select Tau Species in Human Peripheral Tissues and Their Relation to Alzheimer’s Disease
Tau becomes excessively phosphorylated in Alzheimer’s disease (AD) and is widely studied within the brain. Further examination of the extent and types of tau present in peripheral tissues and their relation to AD is warranted given recent publications on pathologic spreading. Cases were selected based on the presence of pathological tau spinal cord deposits (n = 18). Tissue samples from sigmoid colon, scalp, abdominal skin, liver, and submandibular gland were analyzed by western blot and enzyme-linked immunosorbent assays (ELISAs) for certain tau species; frontal cortex gray matter was used for comparison. ELISAs revealed brain to have the highest total tau levels, followed by submandibular gland, sigmoid colon, liver, scalp, and abdominal skin. Western blots with antibodies recognizing tau phosphorylated at threonine 231(pT231), serine 396 and 404 (PHF-1), and an unmodified total human tau between residues 159 and 163 (HT7) revealed multiple banding patterns, some of which predominated in peripheral tissues. As submandibular gland had the highest levels of peripheral tau, a second set of submandibular gland samples were analyzed (n = 36; 19 AD, 17 non-demented controls). ELISAs revealed significantly lower levels of pS396 (p = 0.009) and pT231 (p = 0.005) in AD cases but not total tau (p = 0.18). Furthermore, pT231 levels in submandibular gland inversely correlated with Braak neurofibrillary tangle stage (p = 0.04), after adjusting for age at death, gender, and postmortem interval. These results provide evidence that certain tau species are present in peripheral tissues. Of potential importance, submandibular gland pT231 is progressively less abundant with increasing Braak neurofibrillary tangle stage.
Non-Verbal Episodic Memory Deficits in Primary Progressive Aphasias are Highly Predictive of Underlying Amyloid Pathology
Diagnostic distinction of primary progressive aphasias (PPA) remains challenging, in particular for the logopenic (lvPPA) and nonfluent/agrammatic (naPPA) variants. Recent findings highlight that episodic memory deficits appear to discriminate these PPA variants from each other, as only lvPPA perform poorly on these tasks while having underlying amyloid pathology similar to that seen in amnestic dementias like Alzheimer’s disease (AD). Most memory tests are, however, language based and thus potentially confounded by the prevalent language deficits in PPA. The current study investigated this issue across PPA variants by contrasting verbal and non-verbal episodic memory measures while controlling for their performance on a language subtest of a general cognitive screen. A total of 203 participants were included (25 lvPPA; 29 naPPA; 59 AD; 90 controls) and underwent extensive verbal and non-verbal episodic memory testing, with a subset of patients (n = 45) with confirmed amyloid profiles as assessed by Pittsburgh Compound B and PET. The most powerful discriminator between naPPA and lvPPA patients was a non-verbal recall measure (Rey Complex Figure delayed recall), with 81% of PPA patients classified correctly at presentation. Importantly, AD and lvPPA patients performed comparably on this measure, further highlighting the importance of underlying amyloid pathology in episodic memory profiles. The findings demonstrate that non-verbal recall emerges as the best discriminator of lvPPA and naPPA when controlling for language deficits in high load amyloid PPA cases.
Prion and other amyloid-forming diseases represent a group of neurodegenerative disorders that affect both animals and humans. The role of metal ions, especially copper and zinc is studied intensively in connection with these diseases. Their involvement in protein misfolding and aggregation and their role in creation of reactive oxygen species have been shown. Recent data also show that metal ions not only bind the proteins with high affinity, but also modify their biochemical properties, making them important players in prion-related diseases. In particular, the level of zinc ions is tightly regulated by several mechanisms, including transporter proteins and the low molecular mass thiol-rich metallothioneins. From four metallothionein isoforms, metallothionein-3, a unique brain-specific metalloprotein, plays a crucial role only in this regulation. This review critically evaluates the involvement of metallothioneins in prion- and amyloid-related diseases in connection with the relationship between metallothionein isoforms and metal ion regulation of their homeostasis.
Do Microglia Default on Network Maintenance in Alzheimer’s Disease?
Although the cause of Alzheimer’s disease (AD) remains unknown, a number of new findings suggest that the immune system may play a critical role in the early stages of the disease. Genome-wide association studies have identified a wide array of risk-associated genes for AD, many of which are associated with abnormal functioning of immune cells. Microglia are the brain’s immune cells. They play an important role in maintaining the brain’s extracellular environment, including clearance of aggregated proteins such as amyloid-β (Aβ). Recent studies suggest that microglia play a more active role in the brain than initially considered. Specifically, microglia provide trophic support to neurons and also regulate synapses. Microglial regulation of neuronal activity may have important consequences for AD. In this article we review the function of microglia in AD and examine the possible relationship between microglial dysfunction and network abnormalities, which occur very early in disease pathogenesis.
Alzheimer’s disease (AD) is a progressive, neurodegenerative disease that primarily affects the regions of the brain that are associated with high functioning. AD is characterized by progressive dementia that begins with mood changes, memory loss, and reduced cognition [1]. The primary pathogenic process in AD is the accumulation of amyloid-β protein (Aβ) [1–3]. Aβ aggregates into extracellular amyloid plaques that are a hallmark pathological feature of the disease. Aβ is cleaved from the larger amyloid-β protein precursor (AβPP) [4–6]. However, it remains unclear why Aβ, a protein fragment normally only present in small amounts within the brain, is able to accumulate in the AD brain and cause toxicity. In a small percentage (5%) of AD sufferers, the cause of the disease is genetic. Inherited mutations within the AβPP gene itself appear to predispose the protein to Aβ production [7]. Mutations within the presenilin 1 and 2 genes, encoding proteins that form part of the secretase complex that cleaves the Aβ peptide from AβPP, also result in inherited AD due to accumulations of Aβ [8–11].
The cause of AD is largely unknown for the remaining 95% of cases of sporadic AD, which typically develops a decade or two later than familial AD [12]. However, the degenerative processes are nearly identical between the two forms of the disease. Therefore, it is reasonable to assume that the underlying disease process is the same between the two forms of the disease. Genetic studies have identified a number of genetic risk factors for AD. An early discovery was that allelic variants of apolipoprotein E (ApoE) carry inherently different risks of AD [13–15]. In particular, the ɛ4 allele carries a high risk of AD, with risk of disease occurring in a dose-dependent manner based onzygosity. The ApoE ɛ4 allele is associated with increased Aβ aggregation, reduced lipid transport, and reduced receptor-mediated Aβ clearance [16]. Interestingly, ApoE is predominantly expressed by non-neuronal cells— astrocytes and microglia, rather than by neurons [17]. These findings suggested that although clinical AD manifests from neuronal degeneration, other cells of the central nervous system (CNS) may be intimately involved in pathogenesis or disease progression.
More recently, genome-wide association studies (GWAS) have been used to identify a large number of risk genes for AD. In 2013, a mutation in the triggering receptor expressed on myeloid cells 2 (TREM2) was identified [18, 19]. TREM2 is almost exclusively expressed by immune cells within the brain, and mutations to TREM2 are associated with decreased phagocytosis and an increased pro-inflammatory reactive phenotype. Individuals heterozygous for TREM2 mutations have a high risk of developing AD, however the mutation is rare [18, 19]. Additional AD risk factor genes that have been identified include genes associated with lipid processing, endocytosis, and the immune response, which have recently been covered in excellent reviews [20, 21]. The common unifying feature of these immune-associated mutations is that they are proposed to interfere with microglial function, in particular, the efficiency of phagocytosis [20]. Specifically, mutations to complement receptor 1 (CR1) and cluster of differentiation 33 (CD33) can result in reduced activity of the complement system and reduced phagocytosis [22, 23]. Phosphatidylinositol binding clathrin assembly protein (PICALM) and bridging integrator 1 (BIN1) mutations affect clathrin-mediated endocytosis [24, 25] and SORL1 mutations reduce intracellular trafficking of AβPP [26]. The function of some of these proteins in relation to phagocytosis is discussed later in this review. The identification of such a wide array of risk genes associated with reduced immune cell function now leads us to believe that abnormal functioning of immune cells may play a more important role in the early stages of disease than previously considered.
MICROGLIA
Microglia are the immune cells of the CNS and account for approximately 10% of the CNS cellpopulation, with regional variation in density [27, 28]. During embryonic development, microglia originate from yolk sac progenitor cells that migrate into the developing CNS during early embryogenesis [29,30].Following construction of the blood-brain barrier (BBB), microglia are renewed by local turnover [31]. In the healthy brain, microglia actively support neurons through the release of insulin-like growth factor 1, nerve growth factor, ciliary neurotrophic factor, and brain-derived neurotrophic factor (BDNF) [32–34]. Microglia also provide indirect support to neurons by clearance of debris to maintain the extracellular environment, and phagocytosis of apoptotic cells to facilitate neurogenesis [35, 36]. In the adult brain, microglia coordinate much of their activity with astrocytes and activate in response to similar stimuli [37, 38]. Dysfunctional signaling between microglia and astrocytes often results in chronic inflammation, a characteristic of many neurodegenerative diseases [39, 40].
Historically, it has been thought that microglia ‘rest’ when not responding to inflammatory stimuli or damage [41, 42]. However, this notion is being increasingly recognized as inaccurate [43]. When not involved in active inflammatory signaling, microglia constantly patrol the neuropil by extension and retraction of their finely branched processes [44]. Microglial activation is often broadly classified into two states; pro-inflammatory (M1) or anti-inflammatory (M2) [36, 45], based on similar phenotypes in peripheral macrophages [46]. M1 activated microglia are characterized by increased expression of pro-inflammatory mediators and cytokines, including inducible nitric oxide synthase, tumor necrosis factor-α, and interleukin-1β, often under the control of the transcription factor nuclear factor-κB [45]. Pro-inflammatory microglia rapidly retract their processes and adopt an amoeboid morphology and often migrate closer to the site of injury [47]. Anti-inflammatory M2 activation of microglia, often referred to as alternative activation, represents the other side of microglial behavior. Anti-inflammatory activation is characterized by increased expression of cytokines including arginase 1 and interleukin-10, and is associated with increased ramification of processes [45]. The polarization of microglia into M1 or M2 throughout the brain is well characterized, especially in neurodegenerative diseases [48]. In the AD brain, microglia expressing markers of M1 activation are typically localized to brain regions such as the hippocampus that are most heavily affected in the disease [49]. However, it is important to note that M1 and M2 classifications of microglia may over-simplify microglial phenotypes and may only represent the extremes of microglial activation [50]. It has been more recently proposed that microglia likely occupy a continuum between these phenotypes [39, 51].
Do microglia have multiple roles in AD?
Classical pro-inflammatory activation of microglia has long been associated with AD [39, 49]. Samples taken from late-stage AD brains contain characteristic signs of inflammation, including amoeboid morphology of microglia, high levels of pro-inflammatory cytokines in the cerebrospinal fluid, and evidence of neuronal damage due to chronic exposure to pro-inflammatory cytokines and oxidative stress [52, 53]. The cause of this inflammation may be in response to direct toxicity of Aβ to neurons resulting in activation of nearby microglia and astrocytes [53, 54]. However, Aβ may also induce inflammatory activation of microglia and astrocytes. Activated immune cells are typically present surrounding amyloid plaques [55–57], with such peri-plaque cells exhibiting strong evidence of pro-inflammatory activation [56, 58–60]. The presence of undigested Aβ particles within these activated microglia may suggest that the Aβ peptide itself is a pro-inflammatory signal for microglia [61–64]. In vitro experiments provide supporting evidence for the in vivo studies, with Aβ promoting pro-inflammatory microglial activation [65, 66], and also acting as a potent chemotactic signal [67].
However, it is important to note that although widespread inflammation is characteristic of late-stage AD, it remains unclear what role inflammation could play in early stages of the disease. Some evidence suggests that reducing inflammation through the long-term use of some non-steroidal anti-inflammatory drugs (NSAIDs) can reduce the risk of AD [68]. However, these findings have not yet been verified in clinical trials [69, 70]. Little is understood about how NSAIDs and related compounds affect the delicate balance of pro- versus anti-inflammatory microglial activity within the brain. Although there is considerable evidence to suggest that chronic inflammation may contribute to pathology in the later stages of AD, it is important to note that inflammation normally only represents a small aspect of microglial function. The non-inflammatory functions of microglia may play a more important role in early disease; specifically, microglial functions relating to maintenance of the CNS.
Phagocytosis: A vital role of microglia that may be lost in AD
SYNAPTIC PRUNING: MICROGLIA CAN REGULATE NETWORK ACTIVITY
Recently, a new function has been proposed for microglia. A number of studies have provided evidence that microglia prune synapses throughout life. Microglia are known to remove extraneous synapses during development to ensure that only meaningful connections remain [43]. It was, however, thought that differentiated astrocytes performed the majority of synaptic pruning in the adult brain [91]. The discovery that microglial processes are constantly active within the brain and are often positioned near synapses raised the question of whether microglial synaptic pruning continued throughout life [44, 47, 92–94]. This question was answered in 2014 in a study that demonstrated that microglia do prune synapses into adulthood, and that this activity is important for normal brain function [95]. These findings supported those found a year earlier in a study reporting that ablation of microglia from brain slices increases synapse density and results in abnormal firing of hippocampalneurons [96].
Altered microglial behavior may underlie altered neuronal firing in AD
Altered neuronal activity is an early phenomenon in AD
The cause of DMN hypoactivity in AD is not yet clear; however studies performed in cohorts that are genetically predisposed to AD suggest that DMN hypoactivity is preceded by a period of hyperactivity and increased functional connectivity [123, 136], often manifesting as an absence of normal DMN deactivation during external tasks [137–140]. DMN hyperactivity may interfere with hippocampal memory encoding, leading to the memory deficits that are present in mild cognitive impairment [141, 142]. It has been proposed that hippocampal hyperexcitability in AD may develop as a protective mechanism against increased input from the DMN [142–144]. As AD progresses, the initial hyperexcitability of the DMN and hippocampus may result in hypoactivity due to exhaustion of compensatory mechanisms [123, 136]. Evidence from both transgenic AD mice and longitudinal human studies supports an exhaustion model of hyperactivation leading to later hypoactivation [143, 145–147]. Interestingly, a number of studies report a lower incidence of AD among those who regularly practice meditation which specifically ‘calms’ the DMN [148].
Our understanding of AD as a disease is changing. Historically considered to be primarily a disease of neuronal degeneration, this neurocentric view has widened to encompass non-neuronal cells such as astrocytes into our understanding of the disease process and pathogenesis. A proposed model for microglia in AD is shown in Fig. 2. Microglia perform a wide range of functions in the CNS and although this includes induction of an inflammatory reaction in response to damage, they also have critical roles for maintaining normal function in the brain. Recent evidence shows that microglia regulate neuronal activity through synaptic pruning throughout life as an extension on their normal phagocytosis behavior. The discovery of a large number of AD risk genes associated with reduced immune cell function suggests that perturbed microglial phagocytosis could lead to AD. In our model, altered microglial phagocytosis of synapses results in network dysfunction and onset of AD, occurring downstream of Aβ.
The immune system and microglia represent a novel target for intervention in AD. Importantly, a large number of anti-inflammatory drugs are already in use for other conditions. What is important to know at this stage is exactly how to best target immune cell function. The studies outlined here provide evidence that an indiscriminate dampening down of all microglial activity may result in a worse outcome for individuals by suppressing normal microglial regulatory functions. We currently do not know whether future microglial-based therapies should focus on reducing chronic inflammation or conversely, whether they should be aimed at boosting microglial phagocytosis. It is also likely that future treatment strategies may use a combination of approaches to target Aβ, immune cell phagocytosis and network activity. An increasing view in the AD field is that any drug or therapy needs to be provided very early in the disease process to maximize its beneficial effects. Although we are currently unable to effectively target those at risk of AD at such an early stage, advances in neuroimaging for subtle changes in network activity, or in assays for immune cell function, may provide new avenues for identification of early damage and risk of disease.
REFERENCES
[1]
Selkoe DJ ((2011) ) Alzheimer’s disease. Cold Spring Harb Perspect Biol 3: , pii: a004457.
[2]
Masters CL , Simms G , Weinman NA , Multhaup G , McDonald BL , Beyreuther K ((1985) ) Amyloid plaque core protein in Alzheimer disease and Down syndrome. Proc Natl Acad Sci U S A 82: , 4245–4249.
[3]
Glenner GG , Wong CW ((1984) ) Alzheimer’s disease: Initial report of the purification and characterization of a novel cerebrovascular amyloid protein. Biochem Biophys Res Commun 120: , 885–890.
[4]
Goldgaber D , Lerman MI , McBride OW , Saffiotti U , Gajdusek DC ((1987) ) Characterization and chromosomal localization of a cDNA encoding brain amyloid of Alzheimer’s disease. Science 235: , 877–880.
[5]
Kang J , Lemaire HG , Unterbeck A , Salbaum JM , Masters CL , Grzeschik KH , Multhaup G , Beyreuther K , Muller-Hill B ((1987) ) The precursor of Alzheimer’s disease amyloid A4 protein resembles a cell-surface receptor. Nature 325: , 733–736.
[6]
Robakis NK , Ramakrishna N , Wolfe G , Wisniewski HM ((1987) ) Molecular cloning and characterization of a cDNA encoding the cerebrovascular and the neuritic plaque amyloid peptides. Proc Natl Acad Sci U S A 84: , 4190–4194.
[7]
Levy E , Carman MD , Fernandez-Madrid IJ , Power MD , Lieberburg I , van Duinen SG , Bots GT , Luyendijk W , Frangione B ((1990) ) Mutation of the Alzheimer’s disease amyloid gene in hereditary cerebral hemorrhage, Dutch type. Science 248: , 1124–1126.
[8]
Levy-Lahad E , Wasco W , Poorkaj P , Romano DM , Oshima J , Pettingell WH , Yu CE , Jondro PD , Schmidt SD , Wang K , et al ((1995) ) Candidate gene for the chromosome 1 familial Alzheimer’s disease locus. Science 269: , 973–977.
[9]
Rogaev EI , Sherrington R , Rogaeva EA , Levesque G , Ikeda M , Liang Y , Chi H , Lin C , Holman K , Tsuda T , et al ((1995) ) Familial Alzheimer’s disease in kindreds with missense mutations in a gene on chromosome 1 related to the Alzheimer’s disease type 3 gene. Nature 376: , 775–778.
[10]
Sherrington R , Rogaev EI , Liang Y , Rogaeva EA , Levesque G , Ikeda M , Chi H , Lin C , Li G , Holman K , Tsuda T , Mar L , Foncin JF , Bruni AC , Montesi MP , Sorbi S , Rainero I , Pinessi L , Nee L , Chumakov I , Pollen D , Brookes A , Sanseau P , Polinsky RJ , Wasco W , Da Silva HA , Haines JL , Perkicak-Vance MA , Tanzi RE , Roses AD , Fraser PE , Rommens JM , St George-Hyslop PH ((1995) ) Cloning of a gene bearing missense mutations in early-onset familial Alzheimer’s disease. Nature 375: , 754–760.
Late-Onset Metachromatic Leukodystrophy with Early Onset Dementia Associated with a Novel Missense Mutation in the Arylsulfatase A Gene
A 48-year-old male patient presented with personality changes and progressive memory loss over 2 years with initially suspected Hashimoto’s encephalopathy. Strategy of diagnostic workup of early onset dementia included dementia from neurodegenerative, neuroinflammatory, metabolic/toxic, and psychiatric origin. The patient’s neurological exam was normal. MRI revealed a leukencephalopathy, predominantly in the frontal periventricular white matter, without notable changes over 2 years. On neurophysiological examination, prolonged central conduction times and a sensorimotor polyneuropathy were noted. Neuropsychological impairment included disorientation in place and a reduced short time memory. Behavioral alterations were predominated by sudden mood changes and disinhibition. Cerebrospinal fluid was normal. Despite presence of thyroid autoantibodies, glucocorticosteroid treatment did not improve the dementia. A metachromatic leukodystrophy was diagnosed by decreased arylsulfatase-A activity in leucocytes/fibroblasts and identification of a compound heterozygous mutation in the ARSA gene: c.542T>G (exon 3) and the novel mutation c.1013T>C (exon 6). Pathogenic function was suggested by bioinformatic mutation search. In a patient with early onset dementia, strategic diagnostic workup including genetic assessment revealed an adult-onset metachromatic leukodystrophy with a novel mutation in the arylsulfatase A gene.
Most-Read JAD Articles in March 2016
Microbes and Alzheimer’s Disease – Openly Available Itzhaki, Ruth F. | Lathe, Richard | Balin, Brian J. | Ball, Melvyn J. | Bearer, Elaine L. | Braak, Heiko | Bullido, Maria J. | Carter, Chris | Clerici, Mario | Cosby, S. Louise | Del Tredici, Kelly | Field, Hugh | Fulop, Tamas | Grassi, Claudio | Griffin, W. Sue T. | Haas, Jürgen | Hudson, Alan P. | Kamer, Angela R. | Kell, Douglas B. | Licastro, Federico | Letenneur, Luc | Lövheim, Hugo | Mancuso, Roberta | Miklossy, Judith | Otth, Carola | Palamara, Anna Teresa | Perry, George | Preston, Christopher | Pretorius, Etheresia | Strandberg, Timo | Tabet, Naji | Taylor-Robinson, Simon D. | Whittum-Hudson, Judith A.
Genomics and epigenetics link to DNA structure, Volume 2 (Volume Two: Latest in Genomics Methodologies for Therapeutics: Gene Editing, NGS and BioInformatics, Simulations and the Genome Ontology), Part 1: Next Generation Sequencing (NGS)
Genomics and epigenetics link to DNA structure
Larry H. Bernstein, MD, FCAP, Curator
LPBI
Sequence and Epigenetic Factors Determine Overall DNA Structure
Atomic-level simulations show electrostatic forces between each atom. [Alek Aksimentiev, University of Illinois at Urbana-Champaign]
The traditionally held hypothesis about the highly ordered organization of DNA describes the interaction of various proteins with DNA sequences to mediate the dynamic structure of the molecule. However, recent evidence has emerged that stretches of homologous DNA sequences can associate preferentially with one another, even in the absence of proteins.
Researchers at the University of Illinois Center for the Physics of Living Cells, Johns Hopkins University, and Ulsan National Institute of Science and Technology (UNIST) in South Korea found that DNA molecules interact directly with one another in ways that are dependent on the sequence of the DNA and epigenetic factors, such as methylation.
The researchers described evidence they found for sequence-dependent attractive interactions between double-stranded DNA molecules that neither involve intermolecular strand exchange nor are mediated by DNA-binding proteins.
“DNA molecules tend to repel each other in water, but in the presence of special types of cations, they can attract each other just like nuclei pulling each other by sharing electrons in between,” explained lead study author Hajin Kim, Ph.D., assistant professor of biophysics at UNIST. “Our study suggests that the attractive force strongly depends on the nucleic acid sequence and also the epigenetic modifications.”
The investigators used atomic-level supercomputer simulations to measure the forces between a pair of double-stranded DNA helices and proposed that the distribution of methyl groups on the DNA was the key to regulating this sequence-dependent attraction. To verify their findings experimentally, the scientists were able to observe a single pair of DNA molecules within nanoscale bubbles.
“Here we combine molecular dynamics simulations with single-molecule fluorescence resonance energy transfer experiments to examine the interactions between duplex DNA in the presence of spermine, a biological polycation,” the authors wrote. “We find that AT-rich DNA duplexes associate more strongly than GC-rich duplexes, regardless of the sequence homology. Methyl groups of thymine act as a steric block, relocating spermine from major grooves to interhelical regions, thereby increasing DNA–DNA attraction.”
The findings from this study were published recently in Nature Communications in an article entitled “Direct Evidence for Sequence-Dependent Attraction Between Double-Stranded DNA Controlled by Methylation.”
After conducting numerous further simulations, the research team concluded that direct DNA–DNA interactions could play a central role in how chromosomes are organized in the cell and which ones are expanded or folded up compactly, ultimately determining functions of different cell types or regulating the cell cycle.
“Biophysics is a fascinating subject that explores the fundamental principles behind a variety of biological processes and life phenomena,” Dr. Kim noted. “Our study requires cross-disciplinary efforts from physicists, biologists, chemists, and engineering scientists and we pursue the diversity of scientific disciplines within the group.”
Dr. Kim concluded by stating that “in our lab, we try to unravel the mysteries within human cells based on the principles of physics and the mechanisms of biology. In the long run, we are seeking for ways to prevent chronic illnesses and diseases associated with aging.”
Direct evidence for sequence-dependent attraction between double-stranded DNA controlled by methylation
Jejoong Yoo, Hajin Kim, Aleksei Aksimentiev, and Taekjip Ha Nature Communications 7 11045 (2016) DOI:10.1038/ncomms11045BibTex
Although proteins mediate highly ordered DNA organization in vivo, theoretical studies suggest that homologous DNA duplexes can preferentially associate with one another even in the absence of proteins. Here we combine molecular dynamics simulations with single-molecule fluorescence resonance energy transfer experiments to examine the interactions between duplex DNA in the presence of spermine, a biological polycation. We find that AT-rich DNA duplexes associate more strongly than GC-rich duplexes, regardless of the sequence homology. Methyl groups of thymine acts as a steric block, relocating spermine from major grooves to interhelical regions, thereby increasing DNA–DNA attraction. Indeed, methylation of cytosines makes attraction between GC-rich DNA as strong as that between AT-rich DNA. Recent genome-wide chromosome organization studies showed that remote contact frequencies are higher for AT-rich and methylated DNA, suggesting that direct DNA–DNA interactions that we report here may play a role in the chromosome organization and gene regulation.
Formation of a DNA double helix occurs through Watson–Crick pairing mediated by the complementary hydrogen bond patterns of the two DNA strands and base stacking. Interactions between double-stranded (ds)DNA molecules in typical experimental conditions containing mono- and divalent cations are repulsive1, but can turn attractive in the presence of high-valence cations2. Theoretical studies have identified the ion–ion correlation effect as a possible microscopic mechanism of the DNA condensation phenomena3, 4, 5. Theoretical investigations have also suggested that sequence-specific attractive forces might exist between two homologous fragments of dsDNA6, and this ‘homology recognition’ hypothesis was supported by in vitro atomic force microscopy7 and in vivo point mutation assays8. However, the systems used in these measurements were too complex to rule out other possible causes such as Watson–Crick strand exchange between partially melted DNA or protein-mediated association of DNA.
Here we present direct evidence for sequence-dependent attractive interactions between dsDNA molecules that neither involve intermolecular strand exchange nor are mediated by proteins. Further, we find that the sequence-dependent attraction is controlled not by homology—contradictory to the ‘homology recognition’ hypothesis6—but by a methylation pattern. Unlike the previous in vitro study that used monovalent (Na+) or divalent (Mg2+) cations7, we presumed that for the sequence-dependent attractive interactions to operate polyamines would have to be present. Polyamine is a biological polycation present at a millimolar concentration in most eukaryotic cells and essential for cell growth and proliferation9, 10. Polyamines are also known to condense DNA in a concentration-dependent manner2, 11. In this study, we use spermine4+(Sm4+) that contains four positively charged amine groups per molecule.
Sequence dependence of DNA–DNA forces
To characterize the molecular mechanisms of DNA–DNA attraction mediated by polyamines, we performed molecular dynamics (MD) simulations where two effectively infinite parallel dsDNA molecules, 20 base pairs (bp) each in a periodic unit cell, were restrained to maintain a prescribed inter-DNA distance; the DNA molecules were free to rotate about their axes. The two DNA molecules were submerged in 100mM aqueous solution of NaCl that also contained 20 Sm4+molecules; thus, the total charge of Sm4+, 80 e, was equal in magnitude to the total charge of DNA (2 × 2 × 20 e, two unit charges per base pair; Fig. 1a). Repeating such simulations at various inter-DNA distances and applying weighted histogram analysis12 yielded the change in the interaction free energy (ΔG) as a function of the DNA–DNA distance (Fig. 1b,c). In a broad agreement with previous experimental findings13, ΔG had a minimum, ΔGmin, at the inter-DNA distance of 25−30Å for all sequences examined, indeed showing that two duplex DNA molecules can attract each other. The free energy of inter-duplex attraction was at least an order of magnitude smaller than the Watson–Crick interaction free energy of the same length DNA duplex. A minimum of ΔG was not observed in the absence of polyamines, for example, when divalent or monovalent ions were used instead14, 15.
Figure 1: Polyamine-mediated DNA sequence recognition observed in MD simulations and smFRET experiments.
(a) Set-up of MD simulations. A pair of parallel 20-bp dsDNA duplexes is surrounded by aqueous solution (semi-transparent surface) containing 20 Sm4+ molecules (which compensates exactly the charge of DNA) and 100mM NaCl. Under periodic boundary conditions, the DNA molecules are effectively infinite. A harmonic potential (not shown) is applied to maintain the prescribed distance between the dsDNA molecules. (b,c) Interaction free energy of the two DNA helices as a function of the DNA–DNA distance for repeat-sequence DNA fragments (b) and DNA homopolymers (c). (d) Schematic of experimental design. A pair of 120-bp dsDNA labelled with a Cy3/Cy5 FRET pair was encapsulated in a ~200-nm diameter lipid vesicle; the vesicles were immobilized on a quartz slide through biotin–neutravidin binding. Sm4+ molecules added after immobilization penetrated into the porous vesicles. The fluorescence signals were measured using a total internal reflection microscope. (e) Typical fluorescence signals indicative of DNA–DNA binding. Brief jumps in the FRET signal indicate binding events. (f) The fraction of traces exhibiting binding events at different Sm4+ concentrations for AT-rich, GC-rich, AT nonhomologous and CpG-methylated DNA pairs. The sequence of the CpG-methylated DNA specifies the methylation sites (CG sequence, orange), restriction sites (BstUI, triangle) and primer region (underlined). The degree of attractive interaction for the AT nonhomologous and CpG-methylated DNA pairs was similar to that of the AT-rich pair. All measurements were done at [NaCl]=50mM and T=25°C. (g) Design of the hybrid DNA constructs: 40-bp AT-rich and 40-bp GC-rich regions were flanked by 20-bp common primers. The two labelling configurations permit distinguishing parallel from anti-parallel orientation of the DNA. (h) The fraction of traces exhibiting binding events as a function of NaCl concentration at fixed concentration of Sm4+ (1mM). The fraction is significantly higher for parallel orientation of the DNA fragments.
Unexpectedly, we found that DNA sequence has a profound impact on the strength of attractive interaction. The absolute value of ΔG at minimum relative to the value at maximum separation, |ΔGmin|, showed a clearly rank-ordered dependence on the DNA sequence: |ΔGmin| of (A)20>|ΔGmin| of (AT)10>|ΔGmin| of (GC)10>|ΔGmin| of (G)20. Two trends can be noted. First, AT-rich sequences attract each other more strongly than GC-rich sequences16. For example, |ΔGmin| of (AT)10 (1.5kcalmol−1 per turn) is about twice |ΔGmin| of (GC)10 (0.8kcalmol−1 per turn) (Fig. 1b). Second, duplexes having identical AT content but different partitioning of the nucleotides between the strands (that is, (A)20 versus (AT)10 or (G)20 versus (GC)10) exhibit statistically significant differences (~0.3kcalmol−1 per turn) in the value of |ΔGmin|.
To validate the findings of MD simulations, we performed single-molecule fluorescence resonance energy transfer (smFRET)17 experiments of vesicle-encapsulated DNA molecules. Equimolar mixture of donor- and acceptor-labelled 120-bp dsDNA molecules was encapsulated in sub-micron size, porous lipid vesicles18 so that we could observe and quantitate rare binding events between a pair of dsDNA molecules without triggering large-scale DNA condensation2. Our DNA constructs were long enough to ensure dsDNA–dsDNA binding that is stable on the timescale of an smFRET measurement, but shorter than the DNA’s persistence length (~150bp (ref. 19)) to avoid intramolecular condensation20. The vesicles were immobilized on a polymer-passivated surface, and fluorescence signals from individual vesicles containing one donor and one acceptor were selectively analysed (Fig. 1d). Binding of two dsDNA molecules brings their fluorescent labels in close proximity, increasing the FRET efficiency (Fig. 1e).
FRET signals from individual vesicles were diverse. Sporadic binding events were observed in some vesicles, while others exhibited stable binding; traces indicative of frequent conformational transitions were also observed (Supplementary Fig. 1A). Such diverse behaviours could be expected from non-specific interactions of two large biomolecules having structural degrees of freedom. No binding events were observed in the absence of Sm4+ (Supplementary Fig. 1B) or when no DNA molecules were present. To quantitatively assess the propensity of forming a bound state, we chose to use the fraction of single-molecule traces that showed any binding events within the observation time of 2min (Methods). This binding fraction for the pair of AT-rich dsDNAs (AT1, 100% AT in the middle 80-bp section of the 120-bp construct) reached a maximum at ~2mM Sm4+(Fig. 1f), which is consistent with the results of previous experimental studies2, 3. In accordance with the prediction of our MD simulations, GC-rich dsDNAs (GC1, 75% GC in the middle 80bp) showed much lower binding fraction at all Sm4+ concentrations (Fig. 1b,c). Regardless of the DNA sequence, the binding fraction reduced back to zero at high Sm4+ concentrations, likely due to the resolubilization of now positively charged DNA–Sm4+ complexes2, 3, 13.
Because the donor and acceptor fluorophores were attached to the same sequence of DNA, it remained possible that the sequence homology between the donor-labelled DNA and the acceptor-labelled DNA was necessary for their interaction6. To test this possibility, we designed another AT-rich DNA construct AT2 by scrambling the central 80-bp section of AT1 to remove the sequence homology (Supplementary Table 1). The fraction of binding traces for this nonhomologous pair of donor-labelled AT1 and acceptor-labelled AT2 was comparable to that for the homologous AT-rich pair (donor-labelled AT1 and acceptor-labelled AT1) at all Sm4+ concentrations tested (Fig. 1f). Furthermore, this data set rules out the possibility that the higher binding fraction observed experimentally for the AT-rich constructs was caused by inter-duplex Watson–Crick base pairing of the partially melted constructs.
Next, we designed a DNA construct named ATGC, containing, in its middle section, a 40-bp AT-rich segment followed by a 40-bp GC-rich segment (Fig. 1g). By attaching the acceptor to the end of either the AT-rich or GC-rich segments, we could compare the likelihood of observing the parallel binding mode that brings the two AT-rich segments together and the anti-parallel binding mode. Measurements at 1mM Sm4+ and 25 or 50mM NaCl indicated a preference for the parallel binding mode by ~30% (Fig. 1h). Therefore, AT content can modulate DNA–DNA interactions even in a complex sequence context. Note that increasing the concentration of NaCl while keeping the concentration of Sm4+ constant enhances competition between Na+ and Sm4+ counterions, which reduces the concentration of Sm4+ near DNA and hence the frequency of dsDNA–dsDNA binding events (Supplementary Fig. 2).
Methylation determines the strength of DNA–DNA attraction
Analysis of the MD simulations revealed the molecular mechanism of the polyamine-mediated sequence-dependent attraction (Fig. 2). In the case of the AT-rich fragments, the bulky methyl group of thymine base blocks Sm4+ binding to the N7 nitrogen atom of adenine, which is the cation-binding hotspot21, 22. As a result, Sm4+ is not found in the major grooves of the AT-rich duplexes and resides mostly near the DNA backbone (Fig. 2a,d). Such relocated Sm4+ molecules bridge the two DNA duplexes better, accounting for the stronger attraction16, 23, 24, 25. In contrast, significant amount of Sm4+ is adsorbed to the major groove of the GC-rich helices that lacks cation-blocking methyl group (Fig. 2b,e).
Figure 2: Molecular mechanism of polyamine-mediated DNA sequence recognition.
(a–c) Representative configurations of Sm4+ molecules at the DNA–DNA distance of 28Å for the (AT)10–(AT)10 (a), (GC)10–(GC)10 (b) and (GmC)10–(GmC)10 (c) DNA pairs. The backbone and bases of DNA are shown as ribbon and molecular bond, respectively; Sm4+ molecules are shown as molecular bonds. Spheres indicate the location of the N7 atoms and the methyl groups. (d–f) The average distributions of cations for the three sequence pairs featured in a–c. Top: density of Sm4+ nitrogen atoms (d=28Å) averaged over the corresponding MD trajectory and the z axis. White circles (20Å in diameter) indicate the location of the DNA helices. Bottom: the average density of Sm4+ nitrogen (blue), DNA phosphate (black) and sodium (red) atoms projected onto the DNA–DNA distance axis (x axis). The plot was obtained by averaging the corresponding heat map data over y=[−10, 10] Å. See Supplementary Figs 4 and 5 for the cation distributions at d=30, 32, 34 and 36Å.
If indeed the extra methyl group in thymine, which is not found in cytosine, is responsible for stronger DNA–DNA interactions, we can predict that cytosine methylation, which occurs naturally in many eukaryotic organisms and is an essential epigenetic regulation mechanism26, would also increase the strength of DNA–DNA attraction. MD simulations showed that the GC-rich helices containing methylated cytosines (mC) lose the adsorbed Sm4+ (Fig. 2c,f) and that |ΔGmin| of (GC)10 increases on methylation of cytosines to become similar to |ΔGmin| of (AT)10 (Fig. 1b).
To experimentally assess the effect of cytosine methylation, we designed another GC-rich construct GC2 that had the same GC content as GC1 but a higher density of CpG sites (Supplementary Table 1). The CpG sites were then fully methylated using M. SssI methyltransferase (Supplementary Fig. 3; Methods). As predicted from the MD simulations, methylation of the GC-rich constructs increased the binding fraction to the level of the AT-rich constructs (Fig. 1f).
The sequence dependence of |ΔGmin| and its relation to the Sm4+ adsorption patterns can be rationalized by examining the number of Sm4+ molecules shared by the dsDNA molecules (Fig. 3a). An Sm4+ cation adsorbed to the major groove of one dsDNA is separated from the other dsDNA by at least 10Å, contributing much less to the effective DNA–DNA attractive force than a cation positioned between the helices, that is, the ‘bridging’ Sm4+ (ref. 23). An adsorbed Sm4+ also repels other Sm4+ molecules due to like-charge repulsion, lowering the concentration of bridging Sm4+. To demonstrate that the concentration of bridging Sm4+ controls the strength of DNA–DNA attraction, we computed the number of bridging Sm4+ molecules, Nspm (Fig. 3b). Indeed, the number of bridging Sm4+ molecules ranks in the same order as |ΔGmin|: Nspm of (A)20>Nspm of (AT)10≈Nspm of (GmC)10>Nspm of (GC)10>Nspm of (G)20. Thus, the number density of nucleotides carrying a methyl group (T and mC) is the primary determinant of the strength of attractive interaction between two dsDNA molecules. At the same time, the spatial arrangement of the methyl group carrying nucleotides can affect the interaction strength as well (Fig. 3c). The number of methyl groups and their distribution in the (AT)10 and (GmC)10 duplex DNA are identical, and so are their interaction free energies, |ΔGmin| of (AT)10≈|ΔGmin| of (GmC)10. For AT-rich DNA sequences, clustering of the methyl groups repels Sm4+ from the major groove more efficiently than when the same number of methyl groups is distributed along the DNA (Fig. 3b). Hence, |ΔGmin| of (A)20>|ΔGmin| of (AT)10. For GC-rich DNA sequences, clustering of the cation-binding sites (N7 nitrogen) attracts more Sm4+ than when such sites are distributed along the DNA (Fig. 3b), hence |ΔGmin| is larger for (GC)10 than for (G)20.
Figure 3: Methylation modulates the interaction free energy of two dsDNA molecules by altering the number of bridging Sm4+.
(a) Typical spatial arrangement of Sm4+ molecules around a pair of DNA helices. The phosphates groups of DNA and the amine groups of Sm4+ are shown as red and blue spheres, respectively. ‘Bridging’ Sm4+molecules reside between the DNA helices. Orange rectangles illustrate the volume used for counting the number of bridging Sm4+ molecules. (b) The number of bridging amine groups as a function of the inter-DNA distance. The total number of Sm4+ nitrogen atoms was computed by averaging over the corresponding MD trajectory and the 10Å (x axis) by 20Å (y axis) rectangle prism volume (a) centred between the DNA molecules. (c) Schematic representation of the dependence of the interaction free energy of two DNA molecules on their nucleotide sequence. The number and spatial arrangement of nucleotides carrying a methyl group (T or mC) determine the interaction free energy of two dsDNA molecules.
Genome-wide investigations of chromosome conformations using the Hi–C technique revealed that AT-rich loci form tight clusters in human nucleus27, 28. Gene or chromosome inactivation is often accompanied by increased methylation of DNA29 and compaction of facultative heterochromatin regions30. The consistency between those phenomena and our findings suggest the possibility that the polyamine-mediated sequence-dependent DNA–DNA interaction might play a role in chromosome folding and epigenetic regulation of gene expression.
Rau, D. C., Lee, B. & Parsegian, V. A.Measurement of the repulsive force between polyelectrolyte molecules in ionic solution: hydration forces between parallel DNA double helices. Proc. Natl Acad. Sci. USA81, 2621–2625 (1984).
Raspaud, E., Olvera de la Cruz, M., Sikorav, J. L. & Livolant, F.Precipitation of DNA by polyamines: a polyelectrolyte behavior. Biophys. J.74, 381–393 (1998).
Grosberg, A. Y., Nguyen, T. T. & Shklovskii, B. I.The physics of charge inversion in chemical and biological systems. Rev. Mod. Phys.74, 329–345 (2002).
Thomas, T. & Thomas, T. J.Polyamines in cell growth and cell death: molecular mechanisms and therapeutic applications. Cell. Mol. Life Sci.58, 244–258 (2001).
The author and his father have seen several relatives succumb to mental illness.CREDIT PHOTOGRAPH BY DAYANITA SINGH FOR THE NEW YORKER
In the winter of 2012, I travelled from New Delhi, where I grew up, to Calcutta to visit my cousin Moni. My father accompanied me as a guide and companion, but he was a sullen and brooding presence, lost in a private anguish. He is the youngest of five brothers, and Moni is his firstborn nephew—the eldest brother’s son. Since 2004, Moni, now fifty-two, has been confined to an institution for the mentally ill (a “lunatic home,” as my father calls it), with a diagnosis of schizophrenia. He is kept awash in antipsychotics and sedatives, and an attendant watches, bathes, and feeds him through the day.
My father has never accepted Moni’s diagnosis. Over the years, he has waged a lonely campaign against the psychiatrists charged with his nephew’s care, hoping to convince them that their diagnosis was a colossal error, or that Moni’s broken psyche would somehow mend itself. He has visited the institution in Calcutta twice—once without warning, hoping to see a transformed Moni, living a secretly normal life behind the barred gates. But there was more than just avuncular love at stake for him in these visits. Moni is not the only member of the family with mental illness. Two of my father’s four brothers suffered from various unravellings of the mind. Madness has been among the Mukherjees for generations, and at least part of my father’s reluctance to accept Moni’s diagnosis lies in a grim suspicion that something of the illness may be buried, like toxic waste, in himself.
Rajesh, my father’s third-born brother, had once been the most promising of the Mukherjee boys—the nimblest, the most charismatic, the most admired. But in the summer of 1946, at the age of twenty-two, he began to behave oddly, as if a wire had been tripped in his brain. The most obvious change in his personality was a volatility: good news triggered uncontained outbursts of joy; bad news plunged him into inconsolable desolation. By that winter, the sine curve of Rajesh’s psyche had tightened in its frequency and gained in its amplitude. My father recalls an altered brother: fearful at times, reckless at others, descending and ascending steep slopes of mood, irritable one morning and overjoyed the next. When Rajesh received news of a successful performance on his college exams, he vanished, elated, on a two-night excursion, supposedly “exercising” at a wrestling camp. He was feverish and hallucinating when he returned, and died of pneumonia soon afterward. Only years later, in medical school, did I realize that Rajesh was likely in the throes of an acute manic phase. His mental breakdown was the result of a near-textbook case of bipolar disorder.
Jagu, the fourth-born of my father’s siblings, came to live with us in Delhi in 1975, when I was five years old and he was forty-five. His mind, too, was failing. Tall and rail thin, with a slightly feral look in his eyes and a shock of matted, overgrown hair, he resembled a Bengali Jim Morrison. Unlike Rajesh, whose illness had surfaced in his twenties, Jagu had been troubled from his adolescence. Socially awkward, withdrawn from everyone except my grandmother, he was unable to hold a job or live by himself. By 1975, he had visions, phantasms, and voices in his head that told him what to do. He was still capable of extraordinary bursts of tenderness—when I accidentally smashed a beloved Venetian vase at home, he hid me in his bedclothes and informed my mother that he had “mounds of cash” stashed away, enough to buy “a thousand” replacement vases. But this episode was symptomatic: even his love for me extended the fabric of his psychosis and confabulation.
Unlike Rajesh, Jagu was formally diagnosed. In the late nineteen-seventies, a physician in Delhi examined him and determined that he had schizophrenia. But no medicines were prescribed. Instead, Jagu continued to live at home, half hidden away in my grandmother’s room. (As in many families in India, my grandmother lived with us.) For nearly a decade, she and my father maintained a fragile truce, with Jagu living under her care, eating meals in her room and wearing clothes that she stitched for him. At night, when Jagu was consumed by his fears and fantasies, she put him to bed like a child, with her hand on his forehead. She was his nurse, his housekeeper, his only friend, and, more important, his public defender. When my grandmother died, in 1985, Jagu joined a religious sect in Delhi and disappeared, until his death, a dozen years later.
……
at schizophrenia runs in families was evident even to the person who first defined the illness. In 1911, Eugen Bleuler, a Swiss-German psychiatrist, published a book describing a series of cases of men and women, typically in their teens and early twenties, whose thoughts had begun to tangle and degenerate. “In this malady, the associations lose their continuity,” Bleuler wrote. “The threads between thoughts are torn.” Psychotic visions and paranoid thoughts flashed out of nowhere. Some patients “feel themselves weak, their spirit escapes, they will never survive the day. There is a growth in their heads. Their bones have turned liquid; their hearts have turned into stone. . . . The patient’s wife must not use eggs in cooking, otherwise he will grow feathers.” His patients were often trapped between flickering emotional states, unable to choose between two radically opposed visions, Bleuler noted. “You devil, you angel, you devil, you angel,” one woman said to her lover.
Bleuler tried to find an explanation for the mysterious symptoms, but there was only one seemingly common element: schizophrenic patients tended to have first-degree relatives who were also schizophrenic. He had no tools to understand the mechanism behind the heredity. The word “gene” had been coined just two years before Bleuler published his book. The notion that a mental illness could be carried across generations by unitary, indivisible factors—corpuscles of information threading through families—would have struck most of Bleuler’s contemporaries as mad in its own right. Still, Bleuler was astonishingly prescient about the complex nature of inheritance. “If one is looking for ‘theheredity,’ one can nearly always find it,” he wrote. “We will not be able to do anything about it even later on, unless the single factor of heredity can be broken down into many hereditary factors along specific lines.”
In the nineteen-sixties, Bleuler’s hunch was confirmed by twin studies. Psychiatrists determined that if an identical twin was schizophrenic the other twin had a forty-to-fifty-per-cent chance of developing the disease—fiftyfold higher than the risk in the general population. By the early two-thousands, large population studies had revealed a strong genetic link between schizophrenia and bipolar disorder. Some of the families described in these studies had a crisscrossing history that was achingly similar to my own: one sibling affected with schizophrenia, another with bipolar disorder, and a nephew or niece also schizophrenic.
“The twin studies clarified two important features of schizophrenia and bipolar disorder,” Jeffrey Lieberman, a Columbia University psychiatrist who has studied schizophrenia for thirty years, told me. “First, it was clear that there wasn’t a single gene, but dozens of genes involved in causing schizophrenia—each perhaps exerting a small effect. And, second, even if you inherited the entire set of risk genes, as identical twins do, you still might not develop the disease. Obviously, there were other triggers or instigators involved in releasing the illness.” But while these studies established that schizophrenia had a genetic basis, they revealed nothing about the nature of the genes involved. “For doctors, patients, and families in the schizophrenia community, genetics became the ultimate mystery,” Lieberman said. “If we knew the identity of the genes, we would find the causes, and if we found the causes we could find medicines.”
In 2006, an international consortium of psychiatric geneticists launched a genomic survey of schizophrenia, hoping to advance the search for the implicated genes. With 3,322 patients and 3,587 controls, this was one of the largest and most rigorous such studies in the history of the disease. Researchers scanned through the nearly seven thousand genomes to find variations in gene segments that were correlated with schizophrenia. This strategy, termed an “association study,” does not pinpoint a gene, but it provides a general location where a disease-linked gene may be found, like a treasure map with a large “X” scratched in a corner of the genome.
The results, reported in 2009 (and updated in 2014) in the journal Nature, were a dispiriting validation of Bleuler’s hunch about multiple hereditary factors: more than a hundred independent segments of the genome were associated with schizophrenia. “There are lots of small, common genetic effects, scattered across the genome,” one researcher said. “There are many different biological processes involved.” Some of the putative culprits made biological sense—if dimly. There were genes linked to transmitters that relay messages between neurons, and genes for molecular channels that move electrical signals up and down nerve cells. But by far the most surprising association involved a gene segment on chromosome 6. This region of the genome—termed the MHC region—carries hundreds of genes typically associated with the immune system.
“The MHC-segment finding was so strange and striking that you had to sit up and take notice,” Lieberman told me. “Here was the most definitive evidence that something in the immune system might have something to do with schizophrenia. There had been hints about an immunological association before, but this was impossible to argue with. It raised an endlessly fascinating question: what was the link between immune-response genes and schizophrenia?”
In the first years of her career in brain research, Beth Stevens thought of microglia with annoyance if she thought of them at all. When she gazed into a microscope and saw these ubiquitous cells with their spidery tentacles, she did what most neuroscientists had been doing for generations: she looked right past them and focused on the rest of the brain tissue, just as you might look through specks of dirt on a windshield.
“What are they doing there?” she thought. “They’re in the way.’”
Stevens never would have guessed that just a few years later, she would be running a laboratory at Harvard and Boston’s Children’s Hospital devoted to the study of these obscure little clumps. Or that she would be arguing in the world’s top scientific journals that microglia might hold the key to understanding not just normal brain development but also what causes Alzheimer’s, Huntington’s, autism, schizophrenia, and other intractable brain disorders.
Microglia are part of a larger class of cells—known collectively as glia—that carry out an array of functions in the brain, guiding its development and serving as its immune system by gobbling up diseased or damaged cells and carting away debris. Along with her frequent collaborator and mentor, Stanford biologist Ben Barres, and a growing cadre of other scientists, Stevens, 45, is showing that these long-overlooked cells are more than mere support workers for the neurons they surround. Her work has raised a provocative suggestion: that brain disorders could somehow be triggered by our own bodily defenses gone bad.
A type of glial cell known as an oligodendrocyte
In one groundbreaking paper, in January, Stevens and researchers at the Broad Institute of MIT and Harvard showed that aberrant microglia might play a role in schizophrenia—causing or at least contributing to the massive cell loss that can leave people with devastating cognitive defects. Crucially, the researchers pointed to a chemical pathway that might be targeted to slow or stop the disease. Last week, Stevens and other researchers published a similar finding for Alzheimer’s.
This might be just the beginning. Stevens is also exploring the connection between these tiny structures and other neurological diseases—work that earned her a $625,000 MacArthur Foundation “genius” grant last September.
All of this raises intriguing questions. Is it possible that many common brain disorders, despite their wide-ranging symptoms, are caused or at least worsened by the same culprit, a component of the immune system? If so, could many of these disorders be treated in a similar way—by stopping these rogue cells?
Schizophrenia is a heritable brain illness with unknown pathogenic mechanisms. Schizophrenia’s strongest genetic association at a population level involves variation in the major histocompatibility complex (MHC) locus, but the genes and molecular mechanisms accounting for this have been challenging to identify. Here we show that this association arises in part from many structurally diverse alleles of the complement component 4 (C4) genes. We found that these alleles generated widely varying levels of C4A and C4B expression in the brain, with each common C4 allele associating with schizophrenia in proportion to its tendency to generate greater expression of C4A. Human C4 protein localized to neuronal synapses, dendrites, axons, and cell bodies. In mice, C4 mediated synapse elimination during postnatal development. These results implicate excessive complement activity in the development of schizophrenia and may help explain the reduced numbers of synapses in the brains of individuals with schizophrenia.
Science 31 Mar 2016; http://dx.doi.org:/10.1126/science.aad8373Complement and microglia mediate early synapse loss in Alzheimer mouse models. Soyon Hong1, Victoria F. Beja-Glasser1,*, Bianca M. Nfonoyim1,*,…., Ben A. Barres6, Cynthia A. Lemere,2, Dennis J. Selkoe2,7, Beth Stevens1,8,†
Synapse loss in Alzheimer’s disease (AD) correlates with cognitive decline. Involvement of microglia and complement in AD has been attributed to neuroinflammation, prominent late in disease. Here we show in mouse models that complement and microglia mediate synaptic loss early in AD. C1q, the initiating protein of the classical complement cascade, is increased and associated with synapses before overt plaque deposition. Inhibition of C1q, C3 or the microglial complement receptor CR3, reduces the number of phagocytic microglia as well as the extent of early synapse loss. C1q is necessary for the toxic effects of soluble β-amyloid (Aβ) oligomers on synapses and hippocampal long-term potentiation (LTP). Finally, microglia in adult brains engulf synaptic material in a CR3-dependent process when exposed to soluble Aβ oligomers. Together, these findings suggest that the complement-dependent pathway and microglia that prune excess synapses in development are inappropriately activated and mediate synapse loss in AD.
Genome-wide association studies (GWAS) implicate microglia and complement-related pathways in AD (1). Previous research has demonstrated both beneficial and detrimental roles of complement and microglia in plaque-related neuropathology (2, 3); however, their roles in synapse loss, a major pathological correlate of cognitive decline in AD (4), remain to be identified. Emerging research implicates microglia and immune-related mechanisms in brain wiring in the healthy brain (1). During development, C1q and C3 localize to synapses and mediate synapse elimination by phagocytic microglia (5–7). We hypothesized that this normal developmental synaptic pruning pathway is activated early in the AD brain and mediates synapse loss.
Complex machinery
It’s not surprising that scientists for years have ignored microglia and other glial cells in favor of neurons. Neurons that fire together allow us to think, breathe, and move. We see, hear, and feel using neurons, and we form memories and associations when the connections between different neurons strengthen at the junctions between them, known as synapses. Many neuroscientists argue that neurons create our very consciousness.
Glia, on the other hand, have always been considered less important and interesting. They have pedestrian duties such as supplying nutrients and oxygen to neurons, as well as mopping up stray chemicals and carting away the garbage.
Scientists have known about glia for some time. In the 1800s, the pathologist Rudolf Virchow noted the presence of small round cells packing the spaces between neurons and named them “nervenkitt” or “neuroglia,” which can be translated as nerve putty or glue. One variety of these cells, known as astrocytes, was defined in 1893. And then in the 1920s, the Spanish scientist Pio del Río Hortega developed novel ways of staining cells taken from the brain. This led him to identify and name two more types of glial cells, including microglia, which are far smaller than the others and are characterized by their spidery shape and multiple branches. It is only when the brain is damaged in adulthood, he suggested, that microglia spring to life—rushing to the injury, where it was thought they helped clean up the area by eating damaged and dead cells. Astrocytes often appeared on the scene as well; it was thought that they created scar tissue.
This emergency convergence of microglia and astrocytes was dubbed “gliosis,” and by the time Ben Barres entered medical school in the late 1970s, it was well established as a hallmark of neurodegenerative diseases, infection, and a wide array of other medical conditions. But no one seemed to understand why it occurred. That intrigued Barres, then a neurologist in training, who saw it every time he looked under a microscope at neural tissue in distress. “It was just really fascinating,” he says. “The great mystery was: what is the point of this gliosis? Is it good? Is it bad? Is it driving the disease process, or is it trying to repair the injured brain?”
Barres began looking for the answer. He learned how to grow glial cells in a dish and apply a new recording technique to them. He could measure their electrical qualities, which determine the biochemical signaling that all brain cells use to communicate and coördinate activity.
“From the second I started recording the glial cells, I thought ‘Oh, my God!’” Barres recalls. The electrical activity was more dynamic and complex than anyone had thought. These strange electrical properties could be explained only if the glial cells were attuned to the conditions around them, and to the signals released from nearby neurons. Barres’s glial cells, in other words, had all the machinery necessary to engage in a complex dialogue with neurons, and presumably to respond to different kinds of conditions in the brain.
Why would they need this machinery, though, if they were simply involved in cleaning up dead cells? What could they possibly be doing? It turns out that in the absence of chemicals released by glia, the neurons committed the biochemical version of suicide. Barres also showed that the astrocytes appeared to play a crucial role in forming synapses, the microscopic connections between neurons that encode memory. In isolation, neurons were capable of forming the spiny appendages necessary to reach the synapses. But without astrocytes, they were incapable of connecting to one another.
Hardly anyone believed him. When he was a young faculty member at Stanford in the 1990s, one of his grant applications to the National Institutes of Health was rejected seven times. “Reviewers kept saying, ‘Nah, there’s no way glia could be doing this,’” Barres recalls. “And even after we published two papers in Science showing that [astrocytes] had profound, almost all-or-nothing effects in controlling synapses’ formation or synapse activity, I still couldn’t get funded! I think it’s still hard to get people to think about glia as doing anything active in the nervous system.”
Marked for elimination
Beth Stevens came to study glia by accident. After graduating from Northeastern University in 1993, she followed her future husband to Washington, D.C., where he had gotten work in the U.S. Senate. Stevens had been pre-med in college and hoped to work in a lab at the National Institutes of Health. But with no previous research experience, she was soundly rebuffed. So she took a job waiting tables at a Chili’s restaurant in nearby Rockville, Maryland, and showed up at NIH with her résumé every week.
After a few months, Stevens received a call from a researcher named Doug Fields, who needed help in his lab. Fields was studying the intricacies of the process in which neurons become insulated in a coating called myelin. That insulation is essential for the transmission of electrical impulses.
As Stevens spent the following years pursuing a PhD at the University of Maryland, she was intrigued by the role that glial cells played in insulating neurons. Along the way, she became familiar with other insights into glial cells that were beginning to emerge, especially from the lab of Ben Barres. Which is why, soon after completing her PhD in 2003, Stevens found herself a postdoc in Barres’s lab at Stanford, about to make a crucial discovery.
Barres’s group had begun to identify the specific compounds astrocytes secreted that seemed to cause neurons to grow synapses. And eventually, they noticed that these compounds also stimulated production of a protein called C1q.
Conventional wisdom held that C1q was activated only in sick cells—the protein marked them to be eaten up by immune cells—and only outside the brain. But Barres had found it in the brain. And it was in healthy neurons that were arguably at their most robust stage: in early development. What was the C1q protein doing there?
The answer lies in the fact that marking cells for elimination is not something that happens only in diseased brains; it is also essential for development. As brains develop, their neurons form far more synaptic connections than they will eventually need. Only the ones that are used are allowed to remain. This pruning allows for the most efficient flow of neural transmissions in the brain, removing noise that might muddy the signal.
But it was unknown how exactly the process worked. Was it possible that C1q helped signal the brain to prune unused synapses? Stevens focused her postdoctoral research on finding out. “We could have been completely wrong,” she recalls. “But we went for it.”
It paid off. In a 2007 paper, Barres and Stevens showed that C1q indeed plays a role in eliminating unneeded neurons in the developing brain. And they found that the protein is virtually absent in healthy adult neurons.
Now the scientists faced a new puzzle. Does C1q show up in brain diseases because the same mechanism involved in pruning a developing brain later goes awry? Indeed, evidence was already growing that one of the earliest events in neurodegenerative diseases such as Alzheimer’s, Parkinson’s, and Huntington’s was significant loss of synapses.
When Stevens and Barres examined mice bred to develop glaucoma, a neurodegenerative disease that kills neurons in the optic system, they found that C1q appeared long before any other detectable sign that the disease was taking hold. It cropped up even before the cells started dying.
This suggested the immune cells might in fact cause the disease, or at the very least accelerate it. And that offered an intriguing possibility: that something could be made to halt the process. Barres founded a company, Annexon Biosciences, to develop drugs that could block C1q. Last week’s paper published by Barres, Stevens, and other researchers shows that a compound being tested by Annexon appears to be able to prevent the onset of Alzheimer’s in mice bred to develop the disease. Now the company hopes to test it in humans in the next two years.
Paths to treatments
To better understand the process that C1q helps trigger, Stevens and Barres wanted to figure out what actually plays the role of Pac-Man, eating up the synapses marked for death. It was well known that white blood cells known as macrophages gobbled up diseased cells and foreign invaders in the rest of the body. But macrophages are not usually present in the brain. For their theory to work, there had to be some other mechanism. And further research has shown that the cells doing the eating even in healthy brains are those mysterious clusters of material that Beth Stevens, for years, had been gazing right past in the microscope—the microglia that Río Hortega identified almost 100 years ago.
Now Stevens’s lab at Harvard, which she opened in 2008, devotes half its efforts to figuring out what microglia are doing and what causes them to do it. These cells, it turns out, appear in the mouse embryo at day eight, before any other brain cell, which suggests they might help guide the rest of brain development—and could contribute to any number of neurodevelopmental diseases when they go wrong.
Meanwhile, she is also expanding her study of the way different substances determine what happens in the brain. C1q is actually just the first in a series of proteins that accumulate on synapses marked for elimination. Stevens has begun to uncover evidence that there is a wide array of protective “don’t eat me” molecules too. It’s the balance between all these cues that regulates whether microglia are summoned to destroy synapses. Problems in any one could, conceivably, mess up the system.
Evidence is now growing that microglia are involved in several neurodevelopmental and psychiatric problems. The potential link to schizophrenia that was revealed in January emerged after researchers at the Broad Institute, led by Steven McCarroll and a graduate student named Aswin Sekar, followed a trail of genetic clues that led them directly to Stevens’s work. In 2009, three consortia from around the globe had published papers comparing DNA in people with and without schizophrenia. It was Sekar who identified a possible pattern: the more a specific type of protein was present in synapses, the higher the risk of developing the disease. The protein, C4, was closely related to C1q, the one first identified in the brain by Stevens and Barres.
McCarroll knew that schizophrenia strikes in late adolescence and early adulthood, a time when brain circuits in the prefrontal cortex undergo extensive pruning. Others had found that areas of the prefrontal cortex are among those most ravaged by the disease, which leads to massive synapse loss. Could it be that over-pruning by rogue microglia is part of what causes schizophrenia?
To find out, Sekar and McCarroll got in touch with Stevens, and the two labs began to hold joint weekly meetings. They soon demonstrated that C4 also had a role in pruning synapses in the brains of young mice, suggesting that excessive levels of the protein could indeed lead to over-pruning—and to the thinning out of brain tissue that appears to occur as symptoms such as psychotic episodes grow worse.
If the brain damage seen in Parkinson’s and Alzheimer’s stems from over-pruning that might begin early in life, why don’t symptoms of those diseases show up until later? Barres thinks he knows. He notes that the brain can normally compensate for injury by rewiring itself and generating new synapses. It also contains a lot of redundancy. That would explain why patients with Parkinson’s disease don’t show discernible symptoms until they have lost 90 percent of the neurons that produce dopamine.
It also might mean that subtle symptoms could in fact be detected much earlier. Barres points to a study of nuns published in 2000. When researchers analyzed essays the nuns had written upon entering their convents decades before, they found that women who went on to develop Alzheimer’s had shown less “idea density” even in their 20s. “I think the implication of that is they could be lifelong diseases,” Barres says. “The disease process could be going on for decades and the brain is just compensating, rewiring, making new synapses.” At some point, the microglia are triggered to remove too many cells, Barres argues, and the symptoms of the disease begin to manifest fully.
Turning this insight into a treatment is far from straightforward, because much remains unclear. Perhaps an overly aggressive response from microglia is determined by some combination of genetic variants not shared by everyone. Stevens also notes that diseases like schizophrenia are not caused by one mutation; rather, a wide array of mutations with small effects cause problems when they act in concert. The genes that control the production of C4 and other immune-system proteins may be only part of the story. That may explain why not everyone who has a C4 mutation will go on to develop schizophrenia.
Nonetheless, if Barres and Stevens are right that the immune system is a common mechanism behind devastating brain disorders, that in itself is a fundamental breakthrough. Because we have not known the mechanisms that trigger such diseases, medical researchers have been able only to alleviate the symptoms rather than attack the causes. There are no drugs available to halt or even slow neurodegeneration in diseases like Alzheimer’s. Some drugs elevate neurotransmitters in ways that briefly make it easier for individuals with dementia to form new synaptic connections, but they don’t reduce the rate at which existing synapses are destroyed. Similarly, there are no treatments that tackle the causes of autism or schizophrenia. Even slowing the progress of these disorders would be a major advance. We might finally go after diseases that have run unchecked for generations.
“We’re a ways away from a cure,” Stevens says. “But we definitely have a path forward.”
The complement protein C4 is a non-enzymatic component of the C3 and C5 convertases and thus essential for the propagation of the classical complement pathway. The covalent binding of C4 to immunoglobulins and immune complexes (IC) also enhances the solubilization of immune aggregates, and the clearance of IC through complement receptor one (CR1) on erythrocytes. Human C4 is the most polymorphic protein of the complement system. In this review, we summarize the current concepts on the 1-2-3 loci model of C4A and C4B genes in the population, factors affecting the expression levels of C4 transcripts and proteins, and the structural, functional and serological diversities of the C4A and C4B proteins. The diversities and polymorphisms of the mouse homologues Slp and C4 proteins are described and contrasted with their human homologues. The human C4 genes are located in the MHC class III region on chromosome 6. Each human C4 gene consists of 41 exons coding for a 5.4-kb transcript. The long gene is 20.6 kb and the short gene is 14.2 kb. In the Caucasian population 55% of the MHC haplotypes have the 2-locus, C4A-C4B configurations and 45% have an unequal number of C4A and C4B genes. Moreover, three-quarters of C4 genes harbor the 6.4 kb endogenous retrovirus HERV-K(C4) in the intron 9 of the long genes. Duplication of a C4 gene always concurs with its adjacent genes RP, CYP21 and TNX, which together form a genetic unit termed an RCCX module. Monomodular, bimodular and trimodular RCCX structures with 1, 2 and 3 complement C4 genes have frequencies of 17%, 69% and 14%, respectively. Partial deficiencies of C4A and C4B, primarily due to the presence of monomodular haplotypes and homo-expression of C4A proteins from bimodular structures, have a combined frequency of 31.6%. Multiple structural isoforms of each C4A and C4B allotype exist in the circulation because of the imperfect and incomplete proteolytic processing of the precursor protein to form the beta-alpha-gamma structures. Immunofixation experiments of C4A and C4B demonstrate > 41 allotypes in the two classes of proteins. A compilation of polymorphic sites from limited C4 sequences revealed the presence of 24 polymophic residues, mostly clustered C-terminal to the thioester bond within the C4d region of the alpha-chain. The covalent binding affinities of the thioester carbonyl group of C4A and C4B appear to be modulated by four isotypic residues at positions 1101, 1102, 1105 and 1106. Site directed mutagenesis experiments revealed that D1106 is responsible for the effective binding of C4A to form amide bonds with immune aggregates or protein antigens, and H1106 of C4B catalyzes the transacylation of the thioester carbonyl group to form ester bonds with carbohydrate antigens. The expression of C4 is inducible or enhanced by gamma-interferon. The liver is the main organ that synthesizes and secretes C4A and C4B to the circulation but there are many extra-hepatic sites producing moderate quantities of C4 for local defense. The plasma protein levels of C4A and C4B are mainly determined by the corresponding gene dosage. However, C4B proteins encoded by monomodular short genes may have relatively higher concentrations than those from long C4A genes. The 5′ regulatory sequence of a C4 gene contains a Spl site, three E-boxes but no TATA box. The sequences beyond–1524 nt may be completely different as the C4 genes at RCCX module I have RPI-specific sequences, while those at Modules II, III and IV have TNXA-specific sequences. The remarkable genetic diversity of human C4A and C4B probably promotes the exchange of genetic information to create and maintain the quantitative and qualitative variations of C4A and C4B proteins in the population, as driven by the selection pressure against a great variety of microbes. An undesirable accompanying byproduct of this phenomenon is the inherent deleterious recombinations among the RCCX constituents leading to autoimmune and genetic disorders.
C4A isotype is responsible for effective binding to form amide bonds with immune aggregates or protein antigens, while C4B isotype catalyzes the transacylation of the thioester carbonyl group to form ester bonds with carbohydrate antigens.
Derived from proteolytic degradation of complement C4, C4a anaphylatoxin is a mediator of local inflammatory process.
Schizophrenia and the Synapse
Genetic evidence suggests that overactive synaptic pruning drives development of schizophrenia.
Compared to the brains of healthy individuals, those of people with schizophrenia have higher expression of a gene called C4, according to a paper published inNature today (January 27). The gene encodes an immune protein that moonlights in the brain as an eradicator of unwanted neural connections (synapses). The findings, which suggest increased synaptic pruning is a feature of the disease, are a direct extension of genome-wide association studies (GWASs) that pointed to the major histocompatibility (MHC) locus as a key region associated with schizophrenia risk.
“The MHC [locus] is the first and the strongest genetic association for schizophrenia, but many people have said this finding is not useful,” said psychiatric geneticist Patrick Sullivan of the University of North Carolina School of Medicine who was not involved in the study. “The value of [the present study is] to show that not only is it useful, but it opens up new and extremely interesting ideas about the biology and therapeutics of schizophrenia.”
Schizophrenia has a strong genetic component—it runs in families—yet, because of the complex nature of the condition, no specific genes or mutations have been identified. The pathological processes driving the disease remain a mystery.
Researchers have turned to GWASs in the hope of finding specific genetic variations associated with schizophrenia, but even these have not provided clear candidates.
“There are some instances where genome-wide association will literally hit one base [in the DNA],” explained Sullivan. While a 2014 schizophrenia GWAS highlighted the MHC locus on chromosome 6 as a strong risk area, the association spanned hundreds of possible genes and did not reveal specific nucleotide changes. In short, any hope of pinpointing the MHC association was going to be “really challenging,” said geneticist Steve McCarroll of Harvard who led the new study.
Nevertheless, McCarroll and colleagues zeroed in on the particular region of the MHC with the highest GWAS score—the C4 gene—and set about examining how the area’s structural architecture varied in patients and healthy people.
The C4 gene can exist in multiple copies (from one to four) on each copy of chromosome 6, and has four different forms: C4A-short, C4B-short, C4A-long, and C4B-long. The researchers first examined the “structural alleles” of the C4 locus—that is, the combinations and copy numbers of the different C4 forms—in healthy individuals. They then examined how these structural alleles related to expression of both C4Aand C4B messenger RNAs (mRNAs) in postmortem brain tissues.
…………..
Schizophrenia risk from complex variation of complement component 4
Schizophrenia is a heritable brain illness with unknown pathogenic mechanisms. Schizophrenia’s strongest genetic association at a population level involves variation in the major histocompatibility complex (MHC) locus, but the genes and molecular mechanisms accounting for this have been challenging to identify. Here we show that this association arises in part from many structurally diverse alleles of the complement component 4 (C4) genes. We found that these alleles generated widely varying levels of C4A and C4B expression in the brain, with each common C4 allele associating with schizophrenia in proportion to its tendency to generate greater expression of C4A. Human C4 protein localized to neuronal synapses, dendrites, axons, and cell bodies. In mice, C4 mediated synapse elimination during postnatal development. These results implicate excessive complement activity in the development of schizophrenia and may help explain the reduced numbers of synapses in the brains of individuals with schizophrenia.
Cannon, T. D. et al. Cortex mapping reveals regionally specific patterns of genetic and disease-specific gray-matter deficits in twins discordant for schizophrenia. Proc. Natl Acad. Sci. USA99, 3228–3233 (2002)
Cannon, T. D. et al. Progressive reduction in cortical thickness as psychosis develops: a multisite longitudinal neuroimaging study of youth at elevated clinical risk. Biol. Psychiatry77,147–157 (2015)
Garey, L. J. et al. Reduced dendritic spine density on cerebral cortical pyramidal neurons in schizophrenia. J. Neurol. Neurosurg. Psychiatry65, 446–453 (1998)
Glantz, L. A. & Lewis, D. A. Decreased dendritic spine density on prefrontal cortical pyramidal neurons in schizophrenia. Arch. Gen. Psychiatry57, 65–73 (2000)
Schizophrenia Working Group of the Psychiatric Genomics Consortium. Biological insights from 108 schizophrenia-associated genetic loci. Nature511, 421–427 (2014)
International Schizophrenia Consortium et al. Common polygenic variation contributes to risk of schizophrenia and bipolar disorder. Nature460, 748–752 (2009)
Schizophrenia Psychiatric Genome-Wide Association Study Consortium. Genome-wide association study identifies five new schizophrenia loci. Nature Genet . 43, 969–976 (2011)
The strongest genetic association found in schizophrenia is its association to genetic markers across the major histocompatibility complex (MHC) locus, first described in three Nature papers in 2009. …
Schizophrenia: From genetics to physiology at last
Jianxin Shi1, et al. Common variants on chromosome 6p22.1 are associated with schizophrenia. Nature 460, 753-757 (6 August 2009) | doi:10.1038/nature08192; Received 29 May 2009; Accepted 10 June 2009; Published online 1 July 2009; Corrected 6 August 2009
Schizophrenia, a devastating psychiatric disorder, has a prevalence of 0.5–1%, with high heritability (80–85%) and complex transmission1. Recent studies implicate rare, large, high-penetrance copy number variants in some cases2, but the genes or biological mechanisms that underlie susceptibility are not known. Here we show that schizophrenia is significantly associated with single nucleotide polymorphisms (SNPs) in the extended major histocompatibility complex region on chromosome 6. We carried out a genome-wide association study of common SNPs in the Molecular Genetics of Schizophrenia (MGS) case-control sample, and then a meta-analysis of data from the MGS, International Schizophrenia Consortium and SGENE data sets. No MGS finding achieved genome-wide statistical significance. In the meta-analysis of European-ancestry subjects (8,008 cases, 19,077 controls), significant association with schizophrenia was observed in a region of linkage disequilibrium on chromosome 6p22.1 (P = 9.54 × 10-9). This region includes a histone gene cluster and several immunity-related genes—possibly implicating aetiological mechanisms involving chromatin modification, transcriptional regulation, autoimmunity and/or infection. These results demonstrate that common schizophrenia susceptibility alleles can be detected. The characterization of these signals will suggest important directions for research on susceptibility mechanisms.
Editor’s Summary 6 August 2009
Schizophrenia risk: link to chromosome 6p22.1
A genome-wide association study using the Molecular Genetics of Schizophrenia case-control data set, followed by a meta-analysis that included over 8,000 cases and 19,000 controls, revealed that while common genetic variation that underlies risk to schizophrenia can be identified, there probably are few or no single common loci with large effects. The common variants identified here lie on chromosome 6p22.1 in a region that includes a histone gene cluster and several genes implicated in immunity.
Letter
Hreinn Stefansson1,48, et al. Common variants conferring risk of schizophrenia. Nature460, 744-747 (6 August 2009) | doi:10.1038/nature08186; Received 16 March 2009; Accepted 5 June 2009; Published online 1 July 2009
Schizophrenia is a complex disorder, caused by both genetic and environmental factors and their interactions. Research on pathogenesis has traditionally focused on neurotransmitter systems in the brain, particularly those involving dopamine. Schizophrenia has been considered a separate disease for over a century, but in the absence of clear biological markers, diagnosis has historically been based on signs and symptoms. A fundamental message emerging from genome-wide association studies of copy number variations (CNVs) associated with the disease is that its genetic basis does not necessarily conform to classical nosological disease boundaries. Certain CNVs confer not only high relative risk of schizophrenia but also of other psychiatric disorders1, 2, 3. The structural variations associated with schizophrenia can involve several genes and the phenotypic syndromes, or the ‘genomic disorders’, have not yet been characterized4. Single nucleotide polymorphism (SNP)-based genome-wide association studies with the potential to implicate individual genes in complex diseases may reveal underlying biological pathways. Here we combined SNP data from several large genome-wide scans and followed up the most significant association signals. We found significant association with several markers spanning the major histocompatibility complex (MHC) region on chromosome 6p21.3-22.1, a marker located upstream of the neurogranin gene (NRGN) on 11q24.2 and a marker in intron four of transcription factor 4 (TCF4) on 18q21.2. Our findings implicating the MHC region are consistent with an immune component to schizophrenia risk, whereas the association with NRGN and TCF4 points to perturbation of pathways involved in brain development, memory and cognition.
Letter
The International Schizophrenia Consortium. Common polygenic variation contributes to risk of schizophrenia and bipolar disorder. Nature460, 748-752 (6 August 2009) | doi:10.1038/nature08185; Received 11 February 2009; Accepted 8 June 2009; Published online 1 July 2009; Corrected 6 August 2009
Schizophrenia is a severe mental disorder with a lifetime risk of about 1%, characterized by hallucinations, delusions and cognitive deficits, with heritability estimated at up to 80%1, 2. We performed a genome-wide association study of 3,322 European individuals with schizophrenia and 3,587 controls. Here we show, using two analytic approaches, the extent to which common genetic variation underlies the risk of schizophrenia. First, we implicate the major histocompatibility complex. Second, we provide molecular genetic evidence for a substantial polygenic component to the risk of schizophrenia involving thousands of common alleles of very small effect. We show that this component also contributes to the risk of bipolar disorder, but not to several non-psychiatric diseases.
The Psychiatric GWAS Consortium Steering Committee. A framework for interpreting genome-wide association studies of psychiatric disorders. Molecular Psychiatry (2009) 14, 10–17; doi:10.1038/mp.2008.126; published online 11 November 2008
Genome-wide association studies (GWAS) have yielded a plethora of new findings in the past 3 years. By early 2009, GWAS on 47 samples of subjects with attention-deficit hyperactivity disorder, autism, bipolar disorder, major depressive disorder and schizophrenia will be completed. Taken together, these GWAS constitute the largest biological experiment ever conducted in psychiatry (59 000 independent cases and controls, 7700 family trios and >40 billion genotypes). We know that GWAS can work, and the question now is whether it will work for psychiatric disorders. In this review, we describe these studies, the Psychiatric GWAS Consortium for meta-analyses of these data, and provide a logical framework for interpretation of some of the conceivable outcomes.
The purpose of this article is to consider the ‘big picture’ and to provide a logical framework for the possible outcomes of these studies. This is not a review of GWAS per se as many excellent reviews of this technically and statistically intricate methodological approach are available.7, 8, 9, 10, 11, 12 This is also not a review of the advantages and disadvantages of different study designs and sampling strategies for the dissection of complex psychiatric traits. We would like to consider how the dozens of GWAS papers that will soon be in the literature can be synthesized: what can integrated mega-analyses (meta-analysis is based on summary data (for example, odds ratios) from all available studies whereas ‘mega-analysis’ uses individual-level genotype and phenotype data) of all available GWAS data tell us about the etiology of these psychiatric disorders? This is an exceptional opportunity as positive or negative results will enable us to learn hard facts about these critically important psychiatric disorders. We suggest that it is not a matter of ‘success versus failure’ or ‘optimism versus pessimism’ but rather an opportunity for systematic and logical approaches to empirical data whereby both positive and appropriately qualified negative findings are informative.
The studies that comprise the Psychiatric GWAS Consortium (PGC; http://pgc.unc.edu) are shown in Table 1. GWAS data for ADHD, autism, bipolar disorder, major depressive disorder and schizophrenia from 42 samples of European subjects should be available for mega-analyses by early 2009 (>59 000 independent cases and controls and >7700 family trios). To our knowledge, the PGC will have access to the largest set of GWAS data available.
A major change in human genetics in the past 5 years has been in the growth of controlled-access data repositories, and individual phenotype and genotype data are now available for many of the studies in Table 1. When the PGC mega-analyses are completed, most data will be available to researchers via the NIMH Human Genetics Initiative (http://nimhgenetics.org). Although the ready availability of GWAS data is a benefit to the field by allowing rapid application of a wide range of analytic strategies to GWAS data, there are potential disadvantages. GWAS mega-analysis is complex and requires considerable care and expertise to be done validly. For psychiatric phenotypes, there is the additional challenge of working with disease entities based largely on clinical description, with unknown biological validity and having both substantial clinical variation within diagnostic categories as well as overlaps across categories.13 Given the urgent need to know if there are replicable genotype–phenotype associations, a new type of collaboration was required.
The purpose of the PGC is to conduct rigorous and comprehensive within- and cross-disorder GWAS mega-analyses. The PGC began in early 2007 with the principal investigators of the four GAIN GWAS,14 and within six months had grown to 110 participating scientists from 54 institutions in 11 countries. The PGC has a coordinating committee, five disease-working groups, a cross-disorder group, a statistical analysis and computational group, and a cluster computer for statistical analysis. It is remarkable that almost all investigators approached agreed to participate and that no one has left the PGC. Most effort is donated but we have obtained funding from the NIMH, the Netherlands Scientific Organization, Hersenstichting Nederland and NARSAD.
The PGC has two major specific aims. (1) Within-disorder mega-analyses: conduct separate mega-analyses of all available GWAS data for ADHD, autism, bipolar disorder, major depressive disorder, and schizophrenia to attempt to identify genetic variation convincingly associated with any one of these five disorders. (2) Cross-disorder mega-analyses: the clinically-derived DSM-IV and ICD-10 definitions may not directly reflect the fundamental genetic architecture.15 There are two subaims. (2a) Conduct mega-analysis to identify genetic variation convincingly associated with conventional definitions of two or more disorders. This nosological aim could assist in delineating the boundaries of this set of disorders. (2b) An expert working group will convert epidemiological and genetic epidemiological evidence into explicit hypotheses about overlap among these disorders, and then conduct mega-analyses based on these definitions (for example, to examine the lifetime presence of idiopathic psychotic features without regard to diagnostic context).
The goal of the PGC is to identify convincing genetic variation-disease associations. A convincing association would be extremely unlikely to result from chance, show consistent effect sizes across all or almost all samples and be impervious to vigorous attempts to disprove the finding (for example, by investigating sources of bias, confirmatory genotyping, and so on). Careful attention will be paid to the impact of potential sources of heterogeneity17 with the goal of assessing its impact without minimizing its presence.
Biological plausibility is not an initial requirement for a convincing statistical association, as there are many examples in human genetics of previously unsuspected candidate genes nonetheless showing highly compelling associations. For example, multiple SNPs in intron 1 of the FTO gene were associated with body mass index in 13 cohorts with 38 759 participants18 and yet ‘FTO’ does not appear in an exhaustive 116 page compilation of genetic studies of obesity.19 Some strong associations are in gene deserts: multiple studies have found convincing association between prostate cancer and a region on 8q24 that is ~250 kb from the nearest annotated gene.20 Both of these examples are being intensively investigated and we suspect that a compelling mechanistic ‘story’ will emerge in the near future. The presence of a compelling association without an obvious biological mechanism establishes a priority research area for molecular biology and neuroscience of a psychiatric disorder.
The PGC will use mega-analysis as the main analytic tool as individual-level data will be available from almost all samples. To wield this tool appropriately, a number of preconditions must be met. First, genotype data from different GWAS platforms must be made comparable as the direct overlap between platforms is often modest. This requires meticulous quality control for the inclusion of both SNPs and subjects and attention to the factors that can cause bias (for example, population stratification, cryptic relatedness or genotyping batch effects). Genotype harmonization can be accomplished using imputation (21, 22, for example) so that the same set of ~2 million23, 24 directly or imputed SNP genotypes are available for all subjects. Second, phenotypes need to be harmonized across studies. This is one of the most crucial components of the PGC and we are fortunate to have world experts directing the work. Third, the mega-analyses will assess potential heterogeneity of associations across samples.
A decision-tree schematic of the potential outcomes of the PGC mega-analyses is shown in Figure 1. Note that many of the possibilities in Figure 1 are not mutually exclusive and different disorders may take different paths through this framework. It is possible that there eventually will be dozens or hundreds of sequence variants strictly associated with these disorders with frequencies ranging from very rare to common.
………
GWAS has the potential to yield considerable insights but it is no panacea and may well perform differently for psychiatric disorders. Even if these psychiatric GWAS efforts are successful, the outcomes will be complex. GWAS may help us learn that clinical syndromes are actually many different things—for example, proportions of individuals with schizophrenia might evidence associations with rare CNVs of major effect,5, 6 with more common genetic variation in dozens (perhaps hundreds) of genomic regions, between genetic variation strongly modified by environmental risk factors, and some proportion may be genetically indistinguishable from the general population. Moreover, as fuel to long-standing ‘lumper versus splitter’ debates in psychiatric nosology, empirical data might show that some clinical disorders or identifiable subsets of subjects might overlap considerably.
The critical advantage of GWAS is the search of a ‘closed’ hypothesis space. If the large amount of GWAS data being generated are analyzed within a strict and coherent framework, it should be possible to establish hard facts about the fundamental genetic architecture of a set of important psychiatric disorders—which might include positive evidence of what these disorders are or exclusionary evidence of what they are not. Whatever the results, these historically large efforts should yield hard facts about ADHD, autism, bipolar disorder, major depressive disorder and schizophrenia that may help guide the next era of psychiatric research.
Pe’er I, Yelensky R, Altshuler D, Daly MJ. Estimation of the multiple testing burden for genomewide association studies of nearly all common variants. Genet Epidemiol 2008; 32: 381–385. | Article | PubMed |
Weiss LA, Shen Y, Korn JM, Arking DE, Miller DT, Fossdal R et al. Association between microdeletion and microduplication at 16p11.2 and autism. N Engl J Med 2008; 358: 667–675. | Article | PubMed | ChemPort |
Letter
Hreinn Stefansson1,36, et al. Large recurrent microdeletions associated with schizophrenia. Nature455, 232-236 (11 September 2008) | doi:10.1038/nature07229; Received 17 April 2008; Accepted 8 July 2008; Corrected 11 September 2008
Reduced fecundity, associated with severe mental disorders1, places negative selection pressure on risk alleles and may explain, in part, why common variants have not been found that confer risk of disorders such as autism2, schizophrenia3 and mental retardation4. Thus, rare variants may account for a larger fraction of the overall genetic risk than previously assumed. In contrast to rare single nucleotide mutations, rare copy number variations (CNVs) can be detected using genome-wide single nucleotide polymorphism arrays. This has led to the identification of CNVs associated with mental retardation4, 5 and autism2. In a genome-wide search for CNVs associating with schizophrenia, we used a population-based sample to identify de novoCNVs by analysing 9,878 transmissions from parents to offspring. The 66 de novo CNVs identified were tested for association in a sample of 1,433 schizophrenia cases and 33,250 controls. Three deletions at 1q21.1, 15q11.2 and 15q13.3 showing nominal association with schizophrenia in the first sample (phase I) were followed up in a second sample of 3,285 cases and 7,951 controls (phase II). All three deletions significantly associate with schizophrenia and related psychoses in the combined sample. The identification of these rare, recurrent risk variants, having occurred independently in multiple founders and being subject to negative selection, is important in itself. CNV analysis may also point the way to the identification of additional and more prevalent risk variants in genes and pathways involved in schizophrenia.
The C4 gene can exist in multiple copies (from one to four) on each copy of chromosome 6, and has four different forms: C4A-short, C4B-short, C4A-long, and C4B-long. The researchers first examined the “structural alleles” of the C4 locus—that is, the combinations and copy numbers of the different C4 forms—in healthy individuals. They then examined how these structural alleles related to expression of both C4Aand C4B messenger RNAs (mRNAs) in postmortem brain tissues.
From this the researchers had a clear picture of how the architecture of the C4 locus affected expression ofC4A and C4B. Next, they compared DNA from roughly 30,000 schizophrenia patients with that from 35,000 healthy controls, and a correlation emerged: the alleles most strongly associated with schizophrenia were also those that were associated with the highest C4A expression. Measuring C4A mRNA levels in the brains of 35 schizophrenia patients and 70 controls then revealed that, on average, C4A levels in the patients’ brains were 1.4-fold higher.
C4 is an immune system “complement” factor—a small secreted protein that assists immune cells in the targeting and removal of pathogens. The discovery of C4’s association to schizophrenia, said McCarroll, “would have seemed random and puzzling if it wasn’t for work . . . showing that other complement components regulate brain wiring.” Indeed, complement protein C3 locates at synapses that are going to be eliminated in the brain, explained McCarroll, “and C4 was known to interact with C3 . . . so we thought well, actually, this might make sense.”
McCarroll’s team went on to perform studies in mice that revealed C4 is necessary for C3 to be deposited at synapses. They also showed that the more copies of the C4 gene present in a mouse, the more the animal’s neurons were pruned.
Synaptic pruning is a normal part of development and is thought to reflect the process of learning, where the brain strengthens some connections and eradicates others. Interestingly, the brains of deceased schizophrenia patients exhibit reduced neuron density. The new results, therefore, “make a lot of sense,” said Cardiff University’s Andrew Pocklington who did not participate in the work. They also make sense “in terms of the time period when synaptic pruning is occurring, which sort of overlaps with the period of onset for schizophrenia: around adolescence and early adulthood,” he added.
“[C4] has not been on anybody’s radar for having anything to do with schizophrenia, and now it is and there’s a whole bunch of really neat stuff that could happen,” said Sullivan. For one, he suggested, “this molecule could be something that is amenable to therapeutics.”
UniProtKB
Derived from proteolytic degradation of complement C4, C4a anaphylatoxin is a mediator of local inflammatory process. It induces the contraction of smooth muscle, increases vascular permeability and causes histamine release from mast cells and basophilic leukocytes.
Non-enzymatic component of C3 and C5 convertases and thus essential for the propagation of the classical complement pathway. Covalently binds to immunoglobulins and immune complexes and enhances the solubilization of immune aggregates and the clearance of IC through CR1 on erythrocytes. C4A isotype is responsible for effective binding to form amide bonds with immune aggregates or protein antigens, while C4B isotype catalyzes the transacylation of the thioester carbonyl group to form ester bonds with carbohydrate antigens.
The mirror self-recognition (MSR) test is commonly used to evaluate nonhuman animals’ self-awareness, and has been reportedly passed by several mammals and birds including apes, elephants, dolphins, and magpies. According to a study published earlier this month (March 11) in TheJournal of Ethology, there’s now evidence to add manta rays to that list.
Contingency checking and self-directed behaviors in giant manta rays: Do elasmobranchs have self-awareness?
Elaborate cognitive skills arose independently in different taxonomic groups. Self-recognition is conventionally identified by the understanding that one’s own mirror reflection does not represent another individual but oneself, which has never been proven in any elasmobranch species to date. Manta rays have a high encephalization quotient, similar to those species that have passed the mirror self-recognition test, and possess the largest brain of all fish species. In this study, mirror exposure experiments were conducted on two captive giant manta rays to document their response to their mirror image. The manta rays did not show signs of social interaction with their mirror image. However, frequent unusual and repetitive movements in front of the mirror suggested contingency checking; in addition, unusual self-directed behaviors could be identified when the manta rays were exposed to the mirror. The present study shows evidence for behavioral responses to a mirror that are prerequisite of self-awareness and which has been used to confirm self-recognition in apes.
X-RAY MAG: How did you become interested in studying the behavior of manta rays?
CA: I knew that I wanted to dedicate my life to study and protect marine life since I was 13 years old. It was during a family vacation in Croatia when I first had the chance to try scuba diving. I was so mesmerized by the experience that when I surfaced I decided to try to find out more about this magical world. I became especially fascinated by the majestic and mysterious manta rays after watching a nature documentary, soon after this first dive. It described how little we know about them and how vulnerable they are.
But growing up in Hungary, a landlocked country, I did not have much option to pursue my dream as a marine biologist, so I got my master’s degree in zoology and my doctorate in neurobiology, while volunteering at oceanography institutes in different countries during the summers. During my PhD studies, I worked on the neuroanatomy and neurohistology of several shark and ray species, including mobulids (mantas and mobulas). During these years, I had the chance to explore the brain structures of mantas and mobulas, which reflected some very unique and surprising features. It was the unusual enlargement of some of their brain parts that got me interested in focusing on their behavior.
“Manta rays are likely the first fish species found to exhibit self-awareness, which implies higher order brain function, as well as sophisticated cognitive and social skills,” study coauthor Csilla Ari told X-Ray Mag.
Observing two rays in a tank at the Atlantis Aquarium in the Bahamas, the researchers noticed that the animals changed their behavior when a mirror was placed on one of the walls. New behaviors included apparently checking out their fins (see this video) and blowing bubbles at their reflections. https://youtu.be/LQ1KErB_2oU
X-RAY MAG: What were the findings that caused you to conclude that these animals are using cognition?
CA: Animal cognition, often referred to as animal intelligence, is an exciting scientific field that attempts to describe the mental capacity of an animal. It developed from the field of comparative psychology and it includes exciting research questions, such as perception, attention, selective learning, memory, spatial cognition, tool use, problem solving or consciousness.
There are no easy ways to test these on manta rays, but I found a widely-used and well-established test that can give us insight on their cognitive abilities. The mirror self-recognition (MSR) test is considered to be a reliable behavioral index to show the animal’s ability for self-recognition/self-awareness. Recognizing oneself in a mirror is a very rare capacity among animals. Only a few, large-brained species have passed this test so far, including Asian elephants, bottlenose dolphins and great apes, but no fish species so far.
So, employing a protocol adapted from primates and bottlenose dolphin MSR studies, I exposed captive manta rays to a large mirror and recorded their behavior. The manta rays showed significantly higher frequency of repetitive behavior, such as circling at the mirror or high frequency cephalic fin movements when the mirror was placed in the tank. Contingency checking and self-directed behavior included body turns into a vertical direction, exposing the ventral side of the body to the mirror while staying visually oriented to the mirror. Most surprisingly, such self-directed behaviors were sometimes accompanied with bubble blowing front of the mirror and sharp downward swims.
“This new discovery is incredibly important,” Marc Bekoff of the University of Colorado in Boulder who was not involved in the study told New Scientist. “It shows that we really need to expand the range of animals we study.”
But the MSR test’s developer, Gordon Gallup of the State University of New York at Albany, told New Scientist that the observed movements might reflect curious, rather than self-aware, behavior. “Humans, chimpanzees, and orangutans are the only species for which there is compelling, reproducible evidence for mirror self-recognition,” he said.
Manta ray hears the dinner bell Norbert Wu/Minden Pictures/FLPA
Giant manta rays have been filmed checking out their reflections in a way that suggests they are self-aware.
Harmless but zippy
Rattlesnakes and other vipers are well-known for their lightning-quick bites, but nonvenomous snakes may be just as speedy, according to a study published this month (March 15) in Biology Letters.
Debunking the viper’s strike: harmless snakes kill a common assumption
To survive, organisms must avoid predation and acquire nutrients and energy. Sensory systems must correctly differentiate between potential predators and prey, and elicit behaviours that adjust distances accordingly. For snakes, strikes can serve both purposes. Vipers are thought to have the fastest strikes among snakes. However, strike performance has been measured in very few species, especially non-vipers. We measured defensive strike performance in harmless Texas ratsnakes and two species of vipers, western cottonmouths and western diamond-backed rattlesnakes, using high-speed video recordings. We show that ratsnake strike performance matches or exceeds that of vipers. In contrast with the literature over the past century, vipers do not represent the pinnacle of strike performance in snakes. Both harmless and venomous snakes can strike with very high accelerations that have two key consequences: the accelerations exceed values that can cause loss of consciousness in other animals, such as the accelerations experienced by jet pilots during extreme manoeuvres, and they make the strikes faster than the sensory and motor responses of mammalian prey and predators. Both harmless and venomous snakes can strike faster than the blink of an eye and often reach a target before it can move.
“There’s this kind of pre-emptive discussion that [vipers] are faster,” study coauthor David Penning of the University of Louisiana, Lafayette, told Smithsonian. But, he added, “as sexy as the topic sounds, there’s not that much research on it.”
To Scientists’ Surprise, Even Nonvenomous Snakes Can Strike at Ridiculous Speeds By Marcus Woo
The Texas rat snake was just as much of a speed demon as deadly vipers, challenging long-held notions about snake adaptations
To put the assumption to the test, Penning and his colleagues used a high-speed camera to film strikes from three snake species—the western cottonmouth and the western diamond-backed rattlesnake (both vipers), and a relatively harmless Texas rat snake that kills its prey using constriction.
When a snake strikes, it literally moves faster than the blink of an eye, whipping its head forward so quickly that it can experience accelerations of more than 20 Gs. “It’s the lynchpin of their strategy as predators,” says Rulon Clark at San Diego State University. “Natural selection has optimized a series of adaptations around striking and using venom that really helps them be effective predators.”
When Penning and his colleagues compared strike speeds in three types of snakes, they found that at least one nonvenomous species was just as quick as the vipers. The results hint that serpents’ need for speed may be much more widespread than thought, which raises questions about snake evolution and physiology. They compared the western cottonmouth and the western diamond-backed rattlesnake, which are both vipers, and the nonvenomous Texas rat snake. They put each snake inside a container and inserted a stuffed glove on the end of a stick. They waved the glove around until the animal struck, recording the whole thing with a high-speed camera. The team tested 14 rat snakes, 6 cottonmouths and 12 rattlesnakes, recording several strikes for each individual.
The recordings revealed that although the highest head acceleration—279 meters per second squared, or nearly 29 g—did indeed come from a rattlesnake, one of the rat snakes followed close behind, accelerating its head at 274 meters per second squared. All the snakes turned out to be speed demons, the team reports this week in Biology Letters. The rattlesnake scored the highest measured acceleration, at 279 meters per second squared. But to their surprise, the nonvenomous rat snake came in a close second at 274 meters per second squared. That’s lightning-quick, considering that a Formula One race car accelerates at less than 27 meters per second squared to go from 0 to 60 in just one second.
“I was really surprised, because this comparison hadn’t been made before,” Rulon Clark of San Diego Statue University who was not involved in the work told Smithsonian. “It’s not that the vipers are slow, it’s that this very high-speed striking ability is something that seems common to a lot of snake species—or a wider array than people might’ve expected.”
Penning told Discover Magazine that the results make sense, since even nonvenomous snakes have to catch their food. “Prey are not passively waiting to be eaten by snakes,” he said.
Rather than offering the snakes some sacrificial prey animals, the researchers baited the snakes into striking in self-defense. They used a stuffed glove on a stick. The glove would move around the snake until the animal realized the glove was “clearly not going away,” Penning says, and struck at it. High-speed cameras and mirrors captured these attacks, which happened in the blink of an eye.
Emerging evidence suggests that both humans and superb fairywrens begin learning the vocal patterns of their mothers even before birth. Now, a study published this month (March 16) in The Auk: Ornithological Advances indicates that the same is true of the red-backed fairywren, offering the possibility of studying the phenomenon across related species.
“Fairywrens have become a new model system in which to test new dimensions in the ontogeny of parent-offspring communication in vertebrates,” study coauthor Mark Hauber of New York City’s Hunter College said in a statement.
Following on their previous discovery of prenatal learning in superb fairywrens, the researchers compared the structure of nestling calls in the red-backed fairywren to the calls of the birds’ mothers. The team found that the more calls per hour that nestlings received when in the egg, the higher the similarity to maternal calls after hatching. (The number of calls received during the nestling period had no effect on call similarity.)
“Prenatal vocal learning has rarely been described in any animal, with the exception of humans and Australian superb fairywrens,” William Feeney of the University of Queensland, Australia, who was not involved in the work said in the statement. “This result is exciting as it opens the door to investigating the taxonomic diversity of this ability, which could provide insights into why it evolves.”
Diane Colombelli-Négrel, Michael S. Webster, Jenélle L. Dowling, Mark E. Hauber, andSonia Kleindorfer (2016) Vocal imitation of mother’s calls by begging Red-backed Fairywren nestlings increases parental provisioning. The Auk: April 2016, Vol. 133, No. 2, pp. 273-285.
Prenatal imitative learning is an emerging research area in both human and non-human animals. Previous studies in Superb Fairywrens (Malurus cyaneus) showed that mothers are vocal tutors to their embryos and that better imitation of maternal calls yields more parental provisions after hatching. To begin to test if such adaptive behavior is widespread amongst Australasian wrens in Maluridae, we investigated maternal in-nest calling patterns in Red-backed Fairywrens (Malurus melanocephalus). We first compared the structure of maternal and nestling call elements. Next, we examined how in-nest calling behavior varied with parental behaviors and ecological contexts (i.e. prevalence of brood parasitism and nest predation). All Red-backed Fairywren females called to their eggs during incubation and they continued to do so for several days after hatching at a lower rate. Embryos that received more calls per hour during the incubation period (but not the nestling period) developed into hatchlings with higher call element similarity between mother and young. Female call rate was mostly independent of nest predation but in years with more interspecific brood parasitism, nestling element similarity was greater and female call rates tended to be higher. Playback experiments showed that broods with higher element similarity to their mother received more successful feeds. The potential for prenatal tutoring and imitative begging calls in 2 related fairywren taxa sets the stage for a full-scale comparative analysis of the evolution and function of these behaviors across Maluridae and in other vocal-learning lineages.
Traveling junk-foodies
White storks may be addicted to junk food, in some cases making migratory trips of tens of kilometers to landfill sites during the breeding season, according to a study published earlier this month (March 15) in Movement Ecology.
“We found that the continuous availability of junk food from landfill has influenced nest use, daily travel distances, and foraging ranges,” study coauthor Aldina Franco of the University of East Anglia said in a statement. “Storks now rely on landfill sites for food—especially during the non-breeding season when other food sources are more scarce.”
Using GPS tracking, the researchers focused on 17 storks traveling between nesting and feeding areas over the course of a year. They found that most long-distance trips were made to landfill sites, and that “having a nest close to a guaranteed food supply also means that the storks are less inclined to leave for the winter,” Franco explained in the statement. “They instead spend their non-breeding season defending their highly desirable nest locations.”
“It’s clear migratory behaviors are quite plastic, in that the [storks] are adaptable and can change quickly,” Andrew Farnsworth of the Cornell Lab of Ornithology who was not involved in the work told National Geographic. He added that the new, detailed dataset will help scientists “consider how such changes in behavior may affect the future population of these birds.”
Are white storks addicted to junk food? Impacts of landfill use on the movement and behaviour of resident white storks (Ciconia ciconia) from a partially migratory population
Nathalie I. Gilbert Email author, Ricardo A. Correia, João Paulo Silva,…, Jenny A. Gill and Aldina M. A. Franco
The migratory patterns of animals are changing in response to global environmental change with many species forming resident populations in areas where they were once migratory. The white stork (Ciconia ciconia) was wholly migratory in Europe but recently guaranteed, year-round food from landfill sites has facilitated the establishment of resident populations in Iberia. In this study 17 resident white storks were fitted with GPS/GSM data loggers (including accelerometer) and tracked for 9.1 ± 3.7 months to quantify the extent and consistency of landfill attendance by individuals during the non-breeding and breeding seasons and to assess the influence of landfill use on daily distances travelled, percentage of GPS fixes spent foraging and non-landfill foraging ranges. Results Resident white storks used landfill more during non-breeding (20.1 % ± 2.3 of foraging GPS fixes) than during breeding (14.9 % ± 2.2). Landfill attendance declined with increasing distance between nest and landfill in both seasons. During non-breeding a large percentage of GPS fixes occurred on the nest throughout the day (27 % ± 3.0 of fixes) in the majority of tagged storks. This study provides first confirmation of year-round nest use by resident white storks. The percentage of GPS fixes on the nest was not influenced by the distance between nest and the landfill site. Storks travelled up to 48.2 km to visit landfills during non-breeding and a maximum of 28.1 km during breeding, notably further than previous estimates. Storks nesting close to landfill sites used landfill more and had smaller foraging ranges in non-landfill habitat indicating higher reliance on landfill. The majority of non-landfill foraging occurred around the nest and long distance trips were made specifically to visit landfill. Conclusions The continuous availability of food resources on landfill has facilitated year-round nest use in white storks and is influencing their home ranges and movement behaviour. White storks rely on landfill sites for foraging especially during the non-breeding season when other food resources are scarcer and this artificial food supplementation probably facilitated the establishment of resident populations. The closure of landfills, as required by EU Landfill Directives, will likely cause dramatic impacts on white stork populations.
WEIRD & WILDJunk Food-Loving Birds Diss Migration, Live on Landfill By Brian Handwerk
Spain and Portugal’s white storks are forgoing their annual journeys to African wintering grounds, a new study says
You’ve heard of the staycation. Some white storks in Europe are now opting for the staygration.
The big birds are skipping their annual trip to African wintering grounds to remain year-round in Spain and Portugal, a new study shows.
Why? They’ve developed an addiction to junk food at landfills.
“White storks used to be wholly migratory. Before the 1980s, there were no white storks staying in” Spain and Portugal, says study leader Aldina Franco, a conservation ecologist at the University of East Anglia in the U.K.
Israel’s barren Negev desert is home to striped hyenas and gray wolves—two large scavenger species with considerably overlapping diets. But although such conditions might be expected to create fierce competition, researchers in Israel and the U.S. have now presented evidence that—at least in some cases—these animals form alliances and may even hunt collaboratively for food. The findings were published last month (February 10) in Zoology in the Middle East.
Wolves and hyenas in the desert might “just need each other to survive, because food is so, so limited,” study coauthor Vladimir Dinets of the University of Tennessee in Knoxville told The Washington Post.
Collating observations made over the past two decades (including reports of overlapping paw prints, and sightings of hyenas among packs of wolves), the researchers note that the findings could reflect the behavior of a few, oddly behaving hyenas, or a more widespread commensal, or even cooperative, relationship between the species.
“Animal behavior is often more flexible than described in textbooks,” Dinets said in a press release. “When necessary, animals can abandon their usual strategies and learn something completely new and unexpected. It’s a very useful skill for people, too.”






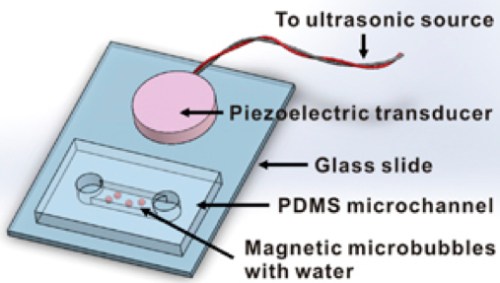















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
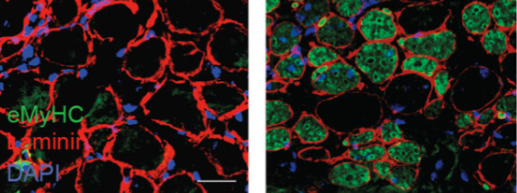{kind=link}
{kind=link}
{kind=link}
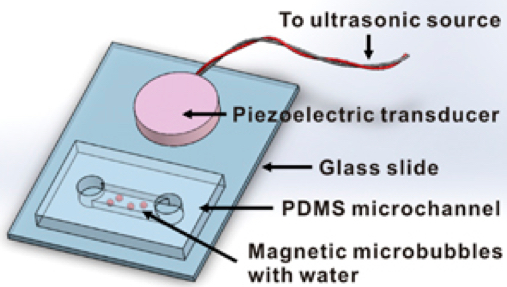{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}