Healthcare analytics, AI solutions for biological big data, providing an AI platform for the biotech, life sciences, medical and pharmaceutical industries, as well as for related technological approaches, i.e., curation and text analysis with machine learning and other activities related to AI applications to these industries.
Few cancer mechanisms are as devastating as the generation of cancer stem cells, which arise in leukemia from white blood cell precursors. The mechanisms of this transition have been obscure, but the consequences are all too clear. Leukemia stem cells promote an aggressive, therapy-resistant form of disease called blast crisis.
Delving into the mechanisms by which leukemia stem cells are primed, a team of scientists at the University of California, San Diego (UCSD), uncovered a misfiring RNA-editing system. The main problem the scientists found was an enzyme called ADAR1 (adenosine deaminase acting on RNA1), which mediates post-transcriptional adenosine-to-inosine (A-to-I) RNA editing.
ADAR1 can edit the sequence of microRNAs (miRNAs), small pieces of genetic material. By swapping out just one miRNA building block for another, ADAR1 alters the carefully orchestrated system cells use to control which genes are turned on or off at which times.
ADAR1 is known to promote cancer progression and resistance to therapy. To study ADAR1, the UCSD team used human blast crisis chronic myeloid leukemia (CML) cells in the lab, and mice transplanted with these cells, to determine the enzyme’s role in governing leukemia stem cells.
The scientists, led by Catriona Jamieson, M.D., Ph.D., published their work June 9 in Cell Stem Cell, in an article entitled, “ADAR1 Activation Drives Leukemia Stem Cell Self-Renewal by Impairing Let-7 Biogenesis.” The article presented the first mechanistic link between pro-cancer inflammatory signals and RNA editing–driven reprogramming of precursor cells into leukemia stem cells.
The article describes how ADAR1-mediated A-to-I RNA editing is activated by Janus kinase 2 (JAK2) signaling and BCR-ABL1 signaling. Also, it indicated, in a model of blast crisis (BC) CML, that combined JAK2 and BCR-ABL1 inhibition prevents leukemia stem cell self-renewal commensurate with ADAR1 downregulation.
Essentially, the scientists were able to trace a series of molecular events: First, white blood cells with a leukemia-promoting gene mutation become more sensitive to signs of inflammation. That inflammatory response activates ADAR1. Then, hyper-ADAR1 editing slows down the miRNAs known as let-7. Ultimately, this activity increases cellular regeneration, or self-renewal, turning white blood cell precursors into leukemia stem cells.
“Lentiviral ADAR1 wild-type, but not an editing-defective ADAR1E912A mutant, induces self-renewal gene expression and impairs biogenesis of stem cell regulatory let-7 microRNAs,” wrote the author of the Cell Stem Cell article. “Combined RNA sequencing, qRT-PCR, CLIP-ADAR1, and pri-let-7 mutagenesis data suggest that ADAR1 promotes LSC generation via let-7 pri-microRNA editing andLIN28B upregulation.”
After learning how the ADAR1 system works, Dr. Jamieson’s team looked for a way to stop it. By inhibiting sensitivity to inflammation or inhibiting ADAR1 with a small-molecule tool compound, the researchers were able to counter ADAR1’s effect on leukemia stem cell self-renewal and restore let-7. Self-renewal of blast crisis CML cells was reduced by approximately 40% when treated with the small molecule called 8-Aza as compared to untreated cells.
“A small-molecule tool compound antagonizes ADAR1’s effect on LSC self-renewal in stromal co-cultures and restores let-7 biogenesis,” the study’s authors noted. “Thus, ADAR1 activation represents a unique therapeutic vulnerability in LSCs with active JAK2 signaling.”
“In this study, we showed that cancer stem cells co-opt a RNA editing system to clone themselves. What’s more, we found a method to dial it down,” said Dr. Catriona Jamieson. “Based on this research, we believe that detecting ADAR1 activity will be important for predicting cancer progression.
“In addition, inhibiting this enzyme represents a unique therapeutic vulnerability in cancer stem cells with active inflammatory signaling that may respond to pharmacologic inhibitors of inflammation sensitivity or selective ADAR1 inhibitors that are currently being developed.”
Maria Anna Zipeto, Angela C. Court, Anil Sadarangani, Nathaniel P. Delos Santos, Larisa Balaian, Hye-Jung Chun, Gabriel Pineda, Sheldon R. Morris, Cayla N. Mason, Ifat Geron, Christian Barrett, Daniel J. Goff, Russell Wall, Maurizio Pellecchia, Mark Minden, Kelly A. Frazer, Marco A. Marra, Leslie A. Crews, Qingfei Jiang, Catriona H.M. Jamieson
•JAK2 and BCR-ABL1 signaling converge on ADAR1 activation through STAT5a
•ADAR1-mediated microRNA editing impairs let-7 biogenesis and enhances LSC self-renewal
•JAK2 and BCR-ABL1 inhibition reduces ADAR1 expression and prevents LSC self-renewal
Post-transcriptional adenosine-to-inosine RNA editing mediated by adenosine deaminase acting on RNA1 (ADAR1) promotes cancer progression and therapeutic resistance. However, ADAR1 editase-dependent mechanisms governing leukemia stem cell (LSC) generation have not been elucidated. In blast crisis chronic myeloid leukemia (BC CML), we show that increased JAK2 signaling and BCR-ABL1 amplification activate ADAR1. In a humanized BC CML mouse model, combined JAK2 and BCR-ABL1 inhibition prevents LSC self-renewal commensurate with ADAR1 downregulation. Lentiviral ADAR1 wild-type, but not an editing-defective ADAR1E912A mutant, induces self-renewal gene expression and impairs biogenesis of stem cell regulatory let-7 microRNAs. Combined RNA sequencing, qRT-PCR, CLIP-ADAR1, and pri-let-7 mutagenesis data suggest that ADAR1 promotes LSC generation via let-7 pri-microRNA editing and LIN28Bupregulation. A small-molecule tool compound antagonizes ADAR1’s effect on LSC self-renewal in stromal co-cultures and restores let-7 biogenesis. Thus, ADAR1 activation represents a unique therapeutic vulnerability in LSCs with active JAK2 signaling.
Chronic Myeloid Leukemia: Biology and Pathophysiology, excluding Therapy Program: Oral and Poster Abstracts Session: 631. Chronic Myeloid Leukemia: Biology and Pathophysiology, excluding Therapy: Poster III
Monday, December 7, 2015, 6:00 PM-8:00 PM
Hall A, Level 2 (Orange County Convention Center)
Maria Anna Zipeto, Ph.D1*, Angela Court Recart2*, Nathaniel Delos Santos3*, Qingfei Jiang, PhD4*, Leslie A Crews, PhD3* and Catriona HM Jamieson, MD, PhD3
1Sanford Consortium for Regenerative Medicine, University of California San Diego, La Jolla, CA 2University of California San Diego, LA JOLLA, CA 3Division of Regenerative Medicine, University of California, San Diego, La Jolla, CA 4University of California San Diego, La Jolla, CA
BackgroundIn advanced human malignancies, RNA sequencing (RNA-seq) has uncovered deregulation of adenosine deaminase acting on RNA (ADAR) editases that promote therapeutic resistance and leukemia stem cell (LSC) generation. Chronic myeloid leukemia (CML), an important paradigm for understanding LSC evolution, is initiated by BCR-ABL1 oncogene expression in hematopoietic stem cells (HSCs) but undergoes blast crisis (BC) transformation following aberrant self-renewal acquisition by myeloid progenitors harboring cytokine-responsive ADAR1 p150 overexpression. Emerging evidence suggests that adenosine to inosine editing at the level of primary (pri) or precursor (pre)-microRNA (miRNA), alters miRNA biogenesis and impairs biogenesis. However, relatively little is known about the role of inflammatory niche-driven ADAR1 miRNA editing in malignant reprogramming of progenitors into self-renewing LSCs.
Methods
Primary normal and CML progenitors were FACS-purified and RNA-Seq analysis as well as qRT-PCR validation were performed according to published methods (Jiang, 2013). MiRNAs were extracted from purified CD34+ cells derived from CP, BC CML and cord blood by RNeasy microKit (QIAGEN) and let-7 expression was evaluated by qRT-PCR using miScript Primer assay (QIAGEN). CD34+ cord blood (n=3) were transduced with lentiviral human JAK2, let-7a, wt-ADAR1 and mutant ADAR1, which lacks a functional deaminase domain. Because STAT signaling triggers ADAR1 transcriptional activation and both BCR-ABL1 and JAK2 activate STAT5a, nanoproteomics analysis of STAT5a levels was performed. Engrafted immunocompromised RAG2-/-γc-/- mice were treated with a JAK2 inhibitor, SAR302503, alone or in combination with a potent BCR-ABL1 TKI Dasatinib, for two weeks followed by FACS analysis of human progenitor engraftment in hematopoietic tissues and serial transplantation.
Results
RNA-seq and qRT-PCR analysis in FACS purified BC CML progenitors revealed an over-representation of inflammatory pathway activation and higher levels of JAK2-dependent inflammatory cytokine receptors, when compared to normal and chronic phase (CP) progenitors. Moreover, RNA-seq and qRT-PCR analysis showed decreased levels of mature let-7 family of stem cell regulatory miRNA in BC compared to normal and CP progenitors. Lentiviral human JAK2 transduction of CD34+ progenitors led to an increase of ADAR1 transcript levels and to a reduction in let-7 family members. Interestingly, lentiviral human JAK2 transduction of normal progenitors enhanced ADAR1 activity, as revealed by RNA editing-specific qRT-PCR and RNA-seq analysis. Moreover, qRT-PCR analysis of CD34+ progenitors transduced with wt-ADAR1, but not mutant ADAR1 lacking functional deaminase activity, reduced let-7 miRNA levels. These data suggested that ADAR1 impairs let-7 family biogenesis in a RNA editing dependent manner. Interestingly, RNA-seq analysis confirmed higher frequency of A-to-I editing events in pri- and pre-let-7 family members in CD34+ BC compared to CP progenitors, as well as normal progenitors transduced with human JAK2 and ADAR1-wt, but not mutant ADAR1. Lentiviral ADAR1 overexpression enhanced CP CML progenitor self-renewal and decreased levels of some members of the let-7 family. In contrast, lentiviral transduction of human let-7a significantly reduced self-renewal of progenitors. In vivo treatments with Dasatinib in combination with a JAK2 inhibitor, significantly reduced self-renewal of BCR-ABL1 expressing BC progenitors in the bone marrow thereby prolonging survival of serially transplanted mice. Finally, a reduction in ADAR1 p150 transcripts was also noted following combination treatment only suggesting a role for ADAR1 in CSC propagation.
Conclusion
This is the first demonstration that intrinsic BCR-ABL oncogenic signaling and extrinsic cytokines signaling through JAK2 converge on activation of ADAR1 that drives LSC generation by impairing let-7 miRNA biogenesis. Targeted reversal of ADAR1-mediated miRNA editing may enhance eradication of inflammatory niche resident cancer stem cells in a broad array of malignancies, including JAK2-driven myeloproliferative neoplasms.
Disclosures:Jamieson:J&J: Research Funding ; GSK: Research Funding .
Interferon Receptor Signaling in Malignancy: a Network of Cellular Pathways Defining Biological Outcomes
Interferons (IFNs) are cytokines with important anti-proliferative activity and exhibit key roles in immune surveillance against malignancies. Early work initiated over 3 decades ago led to the discovery of IFN receptor activated Jak-Stat pathways and provided important insights into mechanisms for transcriptional activation of interferon stimulated genes (ISGs) that mediate IFN-biological responses. Since then, additional evidence has established critical roles for other receptor activated signaling pathways in the induction of IFN-activities. These include MAPK pathways, mTOR cascades and PKC pathways. In addition, specific microRNAs (miRNAs) appear to play a significant role in the regulation of IFN-signaling responses. This review focuses on the emerging evidence for a model in which IFNs share signaling elements and pathways with growth factors and tumorigenic signals, but engage them in a distinctive manner to mediate anti-proliferative and antiviral responses.
Because of their antineoplastic, antiviral, and immunomodulatory properties, recombinant interferons (IFNs) have been used extensively in the treatment of various diseases in humans (1). IFNs have clinical activity against several malignancies and are actively used in the treatment of solid tumors such as malignant melanoma and renal cell carcinoma; and hematological malignancies, such as myeloproliferative neoplasms (MPNs) (1). In addition, IFNs play prominent roles in the treatment of viral syndromes, such as hepatitis B and C (2). In contrast to their beneficial therapeutic properties, IFNs have been also implicated in the pathophysiology of certain diseases in humans. In many cases this involvement reflects abnormal activation of the endogenous IFN system, which has important roles in various physiological processes. Diseases in which dysregulation of the Type I IFN system has been implicated as a pathogenetic mechanism include autoimmune disorders such as systemic lupus erythematosous (3), Sjogren’s syndrome (3,4), dermatomyositis (5) and systemic sclerosis (3, 4). In addition, Type II IFN (IFNγ) overproduction has been implicated in bone marrow failure syndromes, such as aplastic anemia (6). There is also recent evidence for opposing actions of distinct IFN subtypes in the pathophysiology of certain diseases. For instance, a recent study demonstrated that there is an inverse association between IFNβ and IFNγ gene expression in human leprosy, consistent with opposing functions between Type I and II IFNs in the pathophysiology of this disease (7). Thus, differential targeting of components of the IFN-system, to either promote or block induction of IFN-responses depending on the disease context, may be useful in the therapeutic management of various human illnesses. The emerging evidence for the complex regulation of the IFN-system underscores the need for a detailed understanding of the mechanisms of IFN-signaling in order to target IFN-responses effectively and selectively.
It took over 35 years from the original discovery of IFNs in 1957 to the discovery of Jak-Stat pathways (8). The identification of the functions of Jaks and Stats dramatically advanced our understanding of the mechanisms of IFN-signaling and had a broad impact on the cytokine research field as a whole, as it led to the identification of similar pathways from other cytokine receptors (8). Subsequently, several other IFN receptor (IFNR)-regulated pathways were identified (9). As discussed below, in recent years there has been accumulating evidence that beyond Stats, non-Stat pathways play important and essential roles in IFN-signaling. This has led to an evolution of our understanding of the complexity associated with IFN receptor activation and how interacting signaling networks determine the relevant IFN response.
Interferons and their functions
The interferons are classified in 3 major categories, Type I (α, β, ω, ε, τ, κ, ν); Type II (γ) and Type III IFNs (λ1, λ2, λ3) (1, 9, 10). The largest IFN-gene family is the group of Type I IFNs. This family includes 14 IFNα genes, one of which is a pseudogene, resulting in the expression of 13 IFNα protein subtypes (1, 9). There are 3 distinct IFNRs that are specific for the 3 different IFN types. All Type I IFN subtypes bind to and activate the Type I IFNR, while Type II and III IFNs bind to and activate the Type II and III IFNRs, respectively (9–11). It should be noted that although all the different Type I IFNs bind to and activate the Type I IFNR, differences in binding to the receptor may account for specific responses and biological effects (9). For instance, a recent study provided evidence that direct binding of mouse IFNβ to the Ifnar1 subunit, in the absence of Ifnar2, regulates engagement of signals that control expression of genes specifically induced by IFNβ, but not IFNα (12). This recent discovery followed original observations from the 90s that revealed differential interactions between the different subunits of the Type I IFN receptor in response to IFNβ binding as compared to IFNα binding and partially explained observed differences in functional responses between different Type I IFNs (9).
A common property of all IFNs, independently of type and subtype, is the induction of antiviral effects in vitro and in vivo (1). Because of their potent antiviral properties, IFNs constitute an important element of the immune defense against viral infections. There is emerging information indicating that specificity of the antiviral response is cell type dependent and/or reflects specific tissue expression of certain IFNs. As an example, a recent comparative analysis of the involvement of the Type I IFN system as compared to the Type III IFN system in antiviral protection against rotavirus infection of intestinal epithelial cells demonstrated an almost exclusive requirement for IFNλ (Type III IFN) (13). The antiviral effects of IFNα have led to the introduction of this cytokine in the treatment of hepatitis C and B in humans (2) and different viral genotypes have been associated with response or failure to IFN-therapy (14).
Most importantly, IFNs exhibit important antineoplastic effects, reflecting both direct antiproliferative responses mediated by IFNRs expressed on malignant cells, as well as indirect immunomodulatory effects (15). IFNα and its pegylated form (peg IFNα) have been widely used in the treatment of several neoplastic diseases, such as hairy cell leukemia (HCL), chronic myeloid leukemia (CML), cutaneous T cell lymphoma (CTCL), renal cell carcinoma (RCC), malignant melanoma, and myeloproliferative neoplasms (MPNs) (1, 16). Although the emergence of new targeted therapies and more effective agents have minimized the use of IFNs in the treatment of diseases like HCL and CML, IFNs are still used extensively in the treatment of melanoma, CTCL and MPNs (1, 16, 17). Notably, recent studies have provided evidence for long lasting molecular responses in patients with polycythemia vera (PV), essential thrombocytosis (ET) and myelofibrosis (MF) who were treated with IFNα (16). Beyond their inhibitory properties on malignant hematopoietic progenitors, IFNs are potent regulators of normal hematopoiesis (9) and contribute to the regulation of normal homeostasis in the human bone marrow (18). Related to its effects in the central nervous system, IFNβ has clinical activity in multiple sclerosis (MS) and has been used extensively for the treatment of patients with MS (19). The immunoregulatory properties of Type I IFNs include key roles in the control of innate and adaptive immune responses, as well as positive and negative effects on the activation of the inflammasome (15). Dysregulation of the Type I IFN response is seen in certain autoimmune diseases, such as Aicardi-Goutières syndrome (20). In fact, self-amplifying Type I IFN-production is a key pathophysiological mechanism in autoimmune syndromes (21). There is also emerging evidence that IFNλ may contribute to the IFN signature in autoimmune diseases (3).
Jak-Stat pathways
Jak kinases and DNA binding Stat-complexes
Tyrosine kinases of the Janus family (Jaks) are associated in unique combinations with different IFNRs and their functions are essential for IFN-inducible biological responses. Stats are transcriptional activators whose activation depends on tyrosine phosphorylation by Jaks (8, 9). In the case of the Type I IFN receptor, Tyk2 and Jak1 are constitutively associated with the IFNAR1 and IFNAR2 subunits, respectively (8, 9) (Fig. 1). For the Type II IFN receptor, Jak1 and Jak2 are associated with the IFNGR1 and IFNGR2 receptor subunits, respectively (8, 9) (Fig. 1). Finally, in the case of the Type III IFNR, Jak1 and Tyk2 are constitutively associated with the IFN-λR1 and IL-10R2 receptor chains, respectively (10) (Fig. 1). Upon engagement of the different IFNRs by the corresponding ligands, the kinase domains of the associated Jaks are activated and phosphorylate tyrosine residues in the intracellular domains of the receptor subunits that serve as recruitmenst sites for specific Stat proteins. Subsequently, the Jaks phosphorylate Stat proteins that form unique complexes and translocate to the nucleus where they bind to specific sequences in the promoters of ISGs to initiate transcription. A major Stat complex in IFN-signaling is the interferon stimulated gene factor 3 (ISGF3) complex. This IFN-inducible complex is composed or Stat1, Stat2 and IRF9 and regulates transcription by binding to IFN stimulated response elements (ISRE) in the promoters of a large group of IFN stimulated genes (ISGs) (8, 9). ISGF3 complexes are induced during engagement of the Type I and III IFN receptors, but not in response to activation of Type II IFN receptors (8–10) (Table 1). Beyond ISGF3, several other Stat-complexes involving different Stat homodimers or heterodimers are activated by IFNs and bind to IFNγ-activated (GAS) sequences in the promoters of groups of ISGs (8, 9). Such GAS binding complexes are induced by all different IFNs (I, II and III), although there is variability in the engagement and utilization of different Stats by the different IFN-receptors (Table 1). It should also be noted that engagement of certain Stats, such as Stat4 and Stat6, is cell type-specific and may be relevant for tissue specific functions (9). The significance of different Stat binding complexes in the induction of Type I and II IFN responses was in part addressed in a study in which Stat1 cooperative DNA binding was disrupted by generating knock-in mice expressing cooperativity-deficient STAT1 (22). As expected, Type II IFN-induced gene transcription and antibacterial responses were essentially lost in these mice, but Type I IFN-dependent recruitment of Stat1 to ISRE elements and antiviral responses were not affected (22), demonstrating the existence of important differences in Stat1 cooperative DNA binding between Type I and II IFN signaling.
Type I, II, III interferon receptors subunits, associated kinases of the Janus family, and effector Stat-pathways. Note: Stat:Stat reflects multiple potential Stat:Stat compexes, as outlined in Table 2.
Different Stat-DNA binding complexes induced by Type I, II and III IFNs.
Serine phosphorylation of Stats
The nuclear translocation of Stat-proteins occurs after their activation, following phosphorylation on specific sites by Jak kinases (8, 9). It is well established that phosphorylation on tyrosine 701 is required for activation of Stat1 and phosphorylation on tyrosine 705 is required for activation of Stat3 (8, 9). Beyond tyrosine phosphorylation, phosphorylation on serine 727 in the Stat1 and Stat3 transactivation domains is required for full and optimal transcriptional activation of ISGs (8, 9). There is evidence that serine phosphorylation occurs after the phosphorylation of Stat1 on tyrosine 701 and that translocation to the nucleus and recruitment to the chromatin are essential in order for Stat1 to undergo serine 727 phosphorylation (23). Several IFN-dependent serine kinases for Stat1 have been described, raising the possibility that this phosphorylation occurs in a cell type specific manner. After the original demonstration that protein kinase C (PKC) delta (PKCδ) is a serine kinase for Stat1 and is required for optimal transcriptional activation in response to IFNα (24), extensive work has confirmed the role of this PKC isoform in the regulation of serine 727 phosphorylation in Stat1 and has been extended to different cellular systems (25–29) (Table 2). In the Type II IFN system five different serine kinases for the transactivation domain (TAD) of Stat1/phosphorylation on serine 727 have been demonstrated in different cell systems. …..
Serine phosphorylation of Stats
The nuclear translocation of Stat-proteins occurs after their activation, following phosphorylation on specific sites by Jak kinases (8, 9). It is well established that phosphorylation on tyrosine 701 is required for activation of Stat1 and phosphorylation on tyrosine 705 is required for activation of Stat3 (8, 9). Beyond tyrosine phosphorylation, phosphorylation on serine 727 in the Stat1 and Stat3 transactivation domains is required for full and optimal transcriptional activation of ISGs (8, 9). There is evidence that serine phosphorylation occurs after the phosphorylation of Stat1 on tyrosine 701 and that translocation to the nucleus and recruitment to the chromatin are essential in order for Stat1 to undergo serine 727 phosphorylation (23). Several IFN-dependent serine kinases for Stat1 have been described, raising the possibility that this phosphorylation occurs in a cell type specific manner. After the original demonstration that protein kinase C (PKC) delta (PKCδ) is a serine kinase for Stat1 and is required for optimal transcriptional activation in response to IFNα (24), extensive work has confirmed the role of this PKC isoform in the regulation of serine 727 phosphorylation in Stat1 and has been extended to different cellular systems (25–29) (Table 2). In the Type II IFN system five different serine kinases for the transactivation domain (TAD) of Stat1/phosphorylation on serine 727 have been demonstrated in different cell systems. ….
Protein tyrosine phosphatases with regulatory effects on Jak-Stat pathways in IFN-signaling.
…….
MicroRNAs (miRs) and the IFN response
IFN-inducible JAK-STAT, MAPK and mTOR signaling cascades are also regulated potentially by microRNAs (miRs). miRs are important regulators of post-transcriptional events, leading to inhibition of mRNA translation or mRNA degradation (105). In recent years it has become apparent that the direct regulation of STAT activity by mIRs has profound effects on consequent gene expression, specifically in the context of cytokine-inducible events (106). Pertinent for this review of IFN-inducible STAT activation, miR-145, miR-146A and miR-221/222 target STAT1 and miR-221/222 target STAT2 (106). Numerous studies describe different miRs that target STAT3: mIR-17, miR-17-5p, mIR-17-3p, mIR-18a, miR-19b, mIR-92-1, miR-20b, Let-7a, miR-106a, miR-106-25, miR-106a-362 and miR-125b (106) (Fig. 4). mIR-132, miR-212 and miR-200a have been implicated in negatively regulating STAT4 expression in human NK cells (107) and miR-222 has been shown to regulate STAT5 expression (108). In addition, JAK-STAT signaling is affected by miR targeting of suppressors of cytokine signaling (SOCS) proteins. miR-122 and miR-155 targeting of SOCS1 releases the inhibition of STAT1 (and STAT5a/b) (109–111), and mIR-19a regulation of SOCS1 and SOCS3 effectively prolongs activation of both STAT1 and STAT3 (112). There is also evidence that miR-155 targets the inositol phosphatase SHIP1, effectively prolonging/inducing IFN-γ expression (113). Much of the evidence associated with miRs prolonging JAK-STAT activation relates to cancer studies, where tumor-secreted miRs promote cell migration and angiogenesis by prolonging JAK-STAT activation (114). miR-145 targeting of SOCS7 affects nuclear translocation of STAT3 and has been associated with enhanced IFNβ production (115). Beyond inhibition of SOCS proteins, miRs may influence the expression of other inhibitory factors associated with JAK-STAT signaling, and miR-301a and miR-18a have been shown to inhibit PIAS3, a negative regulator of STAT3 activation (116). There is also the potential for STATS to directly regulate miR gene expression. STAT5 suppresses expression of miR15/16 (117) and there is evidence that there are potential STAT3 binding sites in the promoters of about 200 miRs (118). Viewed altogether, there is compelling evidence for miR-STAT interactions, yet few studies have considered the contributions of miRs to IFN-inducible JAK-STAT signaling.
Targeting and regulation of various proteins known to be involved in IFN-signaling by different miRNAs. ….
Evolution of our understanding of IFN-signals and future perspectives
A substantial amount of knowledge has accumulated since the original discovery of the Jak-Stat pathway in the early 90s. It is now clear that several key signaling cascades are essential for the induction of Type I, II and III IFN-responses. The original view that IFN-signals can be transmitted from the cell surface to the nucleus in two simple steps involving tyrosine phosphorylation of Stat proteins (8) now appears somewhat simplistic, as it has been established that modifications of Jak-Stat signals by other pathways and/or simultaneous engagement of other essential complementary cellular cascades is essential for induction of ISG transcriptional activation, mRNA translation, protein expression and subsequent induction of IFN-responses. Such pathways include PKC and MAP kinase pathways and mTORC1 and mTORC2-dpendent signaling cascades.
Over the next decade our understanding of the mechanisms by which IFN-signals are induced will likely continue to evolve, with the anticipated outcome that it will be possible exploit this new knowledge for translational-therapeutic purposes. For instance, selective targeting of kinase-elements of the IFN-pathway with kinase inhibitors may be useful in the treatment of autoimmune diseases where dysregulated/excessive Type I IFN production contributes to the pathophysiology of disease. On the other hand, efforts to promote the induction of specific IFN-signals, may lead to novel, less toxic, therapeutic interventions for a variety of viral infectious diseases and neoplastic disorders.
Exploring the RNA World in Hematopoietic Cells Through the Lens of RNA-Binding Proteins
The discovery of microRNAs has renewed interest in post-transcriptional modes of regulation, fueling an emerging view of a rich RNA world within our cells that deserves further exploration. Much work has gone into elucidating genetic regulatory networks that orchestrate gene expression programs and direct cell fate decisions in the hematopoietic system. However, the focus has been to elucidate signaling pathways and transcriptional programs. To bring us one step closer to reverse engineering the molecular logic of cellular differentiation, it will be necessary to map post-transcriptional circuits as well and integrate them in the context of existing network models. In this regard, RNA-binding proteins (RBPs) may rival transcription factors as important regulators of cell fates and represent a tractable opportunity to connect the RNA world to the proteome. ChIP-seq has greatly facilitated genome-wide localization of DNA-binding proteins, helping us to understand genomic regulation at a systems level. Similarly, technological advances such as CLIP-seq allow transcriptome-wide mapping of RBP binding sites, aiding us to unravel post-transcriptional networks. Here, we review RBP-mediated post-transcriptional regulation, paying special attention to findings relevant to the immune system. As a prime example, we highlight the RBP Lin28B, which acts as a heterochronic switch between fetal and adult lymphopoiesis.
The basis of cellular differentiation and function can be represented as integrated circuits that are genetically programmed. Identification of the master regulators within these complex circuits that can switch on or off a genetic program will enable us to reprogram cells to suit biomedical needs. A remarkable example was the discovery by Takahashi and Yamanaka (1) that somatic cells could be reprogrammed into induced pluripotent stem (iPS) cells via the ectopic expression of four key transcription factors. Interestingly, a specific set of microRNAs (miRNAs) could also mediate this reprogramming (2, 3), revealing a powerful layer of post-transcriptional regulation that is able to override a pre-existing transcriptional program (4). Similarly, miR-9 and miR-124 were sufficient to mediate transdifferentiation of human fibroblasts into neurons (5). Accordingly, we are enamored by the RNA world and pay special attention in our investigations to regulatory non-coding RNAs (ncRNAs), particularly miRNAs and long non-coding RNAs (lncRNAs) and how they integrate with known genetic regulatory networks (Fig. 1). With the exception of certain ribozymes, regulatory RNAs generally do not work alone. Instead, they are physically organized as RNA-protein (RNP) complexes. Operationally, RNA-binding proteins (RBPs) and their interactome work in concert as post-transcriptional networks, or RNA regulons, in response to developmental and environmental cues (6). Inspired by this concept and other pioneering studies in the worm, we recently demonstrated that a single RBP Lin28 was sufficient to reprogram adult hematopoietic progenitors to adopt fetal-like properties (7). We discuss these and related findings, which begin to disentangle the complex functions of RBPs in the context of recent advances in post-transcriptional regulation, starting with the discovery of miRNAs.
Updated model of gene regulation that integrates RBPs and ncRNAs
The Lin28/let-7 circuit: from worm development to lymphopoiesis
Inspiration from the worm
Working in C. elegans, Ambros and Horvitz (8) identified a set of genes that control developmental timing, a category that they termed heterochronic genes. Heterochrony is a term coined by evolutionary biologists and popularized by the worm community to denote events that either positively or negatively regulate developmental timing in multicellular organisms. The discovery of two heterochronic genes, lin-4 and lin-28, which encode a miRNA and RBP respectively, is particularly relevant to this review. The lineage (lin) mutants were previously identified and named because they displayed abnormalities in cell lineage differentiation. Furthermore, some of them were considered heterochronic, as adult mutants harbored immature characteristics (retarded phenotype) or, conversely, larval mutants displayed adult characteristics (precocious phenotype). It was not until 1993 that lin-4 was characterized molecularly, because contrary to popular expectations, the gene did not encode a protein but instead a small RNA now appreciated as the first miRNA to be discovered (9). The lin-4 miRNA acts in part by inhibiting the expression of the LIN-14 transcription factor through imperfect basepairing to sites in the 3′ untranslated region (UTR) of lin-14 mRNA (9, 10). However, it was not apparent initially whether lin-4 or lin-14 is evolutionarily conserved, potentially relegating these findings to be relevant only to the worm. Interestingly, Lin28, a gene conserved in mammals, was later identified to be a direct target of the lin-4 miRNA (11). Lin28 loss-of-function resulted in a precocious phenotype, whereas gain-of-function resulted in a retarded phenotype; thus, Lin28 acts as a heterochronic switch during C. elegans larval development (11).
The possibility that lin-4 may be an oddity of the worm was dissolved with the discovery of the second miRNA, again in C. elegans, let-7 (12). Unlike lin-4, the evolutionary conservation of let-7 from sea urchin to human was quickly appreciated (13). Importantly, expression analysis showed that let-7 expression is temporally regulated from molluscs to vertebrates in all three major clades of bilaterian animals, implying that its role as a developmental timekeeper is conserved (14). This established miRNAs as a field unto its own that has progressed rapidly with the identification of Drosha, Dgcr8, Dicer, and Argonaute (Ago) RBPs as core components of the miRNA pathway (15). Orthologs of lin-4were eventually found in mammals (mir-125a, -b-1, and -b-2) (16) along with hundreds of novel miRNAs from numerous organisms (17). We now recognize that miRNAs, in complex with the RBP Ago, frequently bind their cognate targets via imperfect complementarity to evolutionarily conserved sequences in 3′ UTRs (18–20) and mediate post-transcriptional repression (21).
…..
One diverse group of RBPs appreciated to be important in the immune system, even before the discovery of miRNAs, is distinguished by their ability to bind to AU-rich elements (AREs) often found in 3′ UTRs of genes involved in inflammation, growth, and survival. Such RBPs are known as ARE-BPs and have been implicated in mRNA decay, alternative splicing, translation, as well as both alleviating and enhancing miRNA-mediated mRNA repression (104–107). Genetic inactivation of several ARE-BPs have been linked to aberrant cytokine expression due to impaired ARE-mediated decay (5, 108–111) (Table 1). In addition, deficiency of HuR and AUF1 has uncovered a pro-survival role for both in lymphocytes (112, 113), while ectopic expression of Tis11b (ZFP36L1) negatively regulates erythropoiesis by down-regulating Stat5b mRNA stability (114). The KH-type splicing regulatory protein (KSRP) originally identified as an alternative-splicing factor is a multi-functional RBP. It has been shown to associate with both Drosha and Dicer complexes to positively regulate the biogenesis of a subset of miRNAs including mir-155 and let-7 (73, 108, 115–120). In addition, KSRP, like many other ARE-BPs, mediate selective decay of mRNAs by recruitment of exosome complexes to mRNA targets (121) and constitutes a prime example of a multi-functional RBP.
……
Biological processes involved in the development and function of the immune system require programmed changes in protein production and constitute prime candidates for post-transcriptional regulation. While the ENCODE project initially aimed to identify all functional elements in the human DNA sequence, recent discoveries centered around miRNAs and multi-tasking RBPs, such as Lin28, have highlighted the need for a similar systematic effort in mapping post-transcriptional functional elements within the transcriptome. Integration of genomic, transcriptomic, and proteomic data remains a daunting but necessary task to achieve understanding of the full impact of genetic programs and the enigmatic roles of regulatory RNAs. Mastering the science of (re)programming cell fates promises to unleash the potential of stem cells for Regenerative Medicine.
New Studies toward Understanding Alzheimer Disease
Curators: Larry H. Bernstein, MD, FCAP and Aviva Lev-Ari, PhD, RN
There is no unifying concept of Alzheimer Disease beyond the Tau and beta amyloid roles. Recently, Ingenbleek and Bernstein (journal AD) made the connection between the age related decline of liver synthesis of plasma transthyretin and the more dramatic decline of transthyretin at the blood brain barrier, and the relationship to inability to transfer vitamin A via retinol binding protein to the brain. Related metabolic events are reported by several groups.
They show that Aβ oligomerization, a behavior traditionally viewed as intrinsically pathological, may be necessary for the antimicrobial activities of the peptide. Collectively, our data are consistent with a model in which soluble Aβ oligomers first bind to microbial cell wall carbohydrates via a heparin-binding domain. Developing protofibrils inhibited pathogen adhesion to host cells. Propagating β-amyloid fibrils mediate agglutination and eventual entrapment of unatttached microbes….Salmonella Typhimurium bacterial infection of the brains of transgenic 5XFAD mice resulted in rapid seeding and accelerated β-amyloid deposition, which closely colocalized with the invading bacteria.
This is quite interesting in that infection drives the production of acute phase reactants resulting in decreased production of transthyretin. Whether this also has ties to chronic disease in the elderly and risk of AD is not known.
Through whole-genome sequencing of 1345 individuals from 410 families with late-onset AD (LOAD), they identified three highly penetrant variants in PRKCA, the gene that encodes protein kinase Cα (PKCα), in five of the families. All three variants linked with LOAD displayed increased catalytic activity relative to wild-type PKCα as assessed in live-cell imaging experiments using a genetically encoded PKC activity reporter. Deleting PRKCA in mice or adding PKC antagonists to mouse hippocampal slices infected with a virus expressing the Aβ precursor CT100 revealed that PKCα was required for the reduced synaptic activity caused by Aβ. In PRKCA(-/-) neurons expressing CT100, introduction of PKCα, but not PKCα lacking a PDZ interaction moiety, rescued synaptic depression, suggesting that a scaffolding interaction bringing PKCα to the synapse is required for its mediation of the effects of Aβ. Thus, enhanced PKCα activity may contribute to AD, possibly by mediating the actions of Aβ on synapses.
Kim BM, You MH, Chen CH, Suh J, Tanzi RE, Ho Lee T.
Hum Mol Genet. 2016 Apr 19. pii: ddw114.
Extracellular deposition of amyloid-beta (Aβ) peptide, a metabolite of sequential cleavage of amyloid precursor protein (APP), is a critical step in the pathogenesis of Alzheimer’s disease (AD). While death-associated protein kinase 1 (DAPK1) is highly expressed in AD brains and its genetic variants are linked to AD risk, little is known about the impact of DAPK1 on APP metabolism and Aβ generation. This study demonstrated a novel effect of DAPK1 in the regulation of APP processing using cell culture and mouse models. DAPK1, but not its kinase deficient mutant (K42A), significantly increased human Aβ secretion in neuronal cell culture models. Moreover, knockdown of DAPK1 expression or inhibition of DAPK1 catalytic activity significantly decreased Aβ secretion. Furthermore, DAPK1, but not K42A, triggered Thr668 phosphorylation of APP, which may initiate and facilitate amyloidogenic APP processing leading to the generation of Aβ. In Tg2576 APPswe-overexpressing mice, knockout of DAPK1 shifted APP processing toward non-amyloidogenic pathway and decreased Aβ generation. Finally, in AD brains, elevated DAPK1 levels showed co-relation with the increase of APP phosphorylation. Combined together, these results suggest that DAPK1 promotes the phosphorylation and amyloidogenic processing of APP, and that may serve a potential therapeutic target for AD.
The “amyloid β hypothesis” of Alzheimer’s disease (AD) has been the reigning hypothesis explaining pathogenic mechanisms of AD over the last two decades. However, this hypothesis has not been fully validated in animal models, and several major unresolved issues remain. Our 3D human neural cell culture model system provides a premise for a new generation of cellular AD models that can serve as a novel platform for studying pathogenic mechanisms and for high-throughput drug screening in a human brain-like environment.
The two key pathological hallmarks of AD are senile plaques (amyloid plaques) and neurofibrillary tangles (NFTs), which develop in brain regions responsible for memory and cognitive functions (i.e. cerebral cortex and limbic system) 3. Senile plaques are extracellular deposits of amyloid-β (Aβ) peptides, while NFTs are intracellular, filamentous aggregates of hyperphosphorylated tau protein 4.
The identification of Aβ as the main component of senile plaques by Drs. Glenner and Wong in 1984 5 resulted in the original formation of the “amyloid hypothesis.” According to this hypothesis, which was later renamed the “amyloid-β cascade hypothesis” by Drs. Hardy and Higgins 6, the accumulation of Aβ is the initial pathological trigger in the disease, subsequently leading to hyperphosphorylation of tau, causing NFTs, and ultimately, neuronal death and dementia 4,7–10. Although the details have been modified to reflect new findings, the core elements of this hypothesis remain unchanged: excess accumulation of the pathogenic forms of Aβ, by altered Aβ production and/or clearance, triggers the vicious pathogenic cascades that eventually lead to NFTs and neuronal death.
Over the last two decades, the Aβ hypothesis of AD has reigned, providing the foundation for numerous basic studies and clinical trials 4,7,10,11. According to this hypothesis, the accumulation of Aβ, either by altered Aβ production and/or clearance, is the initial pathological trigger in the disease. The excess accumulation of Aβ then elicits a pathogenic cascade including synaptic deficits, altered neuronal activity, inflammation, oxidative stress, neuronal injury, hyperphosphorylation of tau causing NFTs and ultimately, neuronal death and dementia 4,7–10.
One of the major unresolved issues of the Aβ hypothesis is to show a direct causal link between Aβ and NFTs 12–14. Studies have demonstrated that treatments with various forms of soluble Aβ oligomers induced synaptic deficits and neuronal injury, as well as hyperphosphorylation of tau proteins, in mouse and rat neurons, which could lead to NFTs and neurodegeneration in vivo18–21. However, transgenic AD mouse models carrying single or multiple human familial AD (FAD) mutations in amyloid precursor protein (APP) and/or presenilin 1 (PS1) do not develop NFTs or robust neurodegeneration as observed in human patients, despite robust Aβ deposition 13,22,23. Double and triple transgenic mouse models, harboring both FAD and tau mutations linked with frontotemporal dementia (FTD), are the only rodent models to date displaying both amyloid plaques and NFTs. However, the NFT pathology in these models stems mainly from the overexpression of human tau as a result of the FTD, rather than the FAD mutations24,25.
Human neurons carrying FAD mutations are an optimal model to test whether elevated levels of pathogenic Aβ trigger pathogenic cascades including NFTs, since those cells truly share the same genetic background that induces FAD in humans. Indeed, Israel et al., observed elevated tau phosphorylation in neurons with an APP duplication FAD mutation 33. Blocking Aβ generation by β-secretase inhibitors significantly decreased tau phosphorylation in the same model, but γ-secretase inhibitor, another Aβ blocker, did not affect tau phosphorylation 33. Neurons with the APP V717I FAD mutation also showed an increase in levels of phospho tau and total tau levels 28. More importantly, Muratore and colleagues showed that treatments with Aβ-neutralizing antibodies in those cells significantly reduced the elevated total and phospho tau levels at the early stages of differentiation, suggesting that blocking pathogenic Aβ can reverse the abnormal tau accumulation in APP V717I neurons 28.
Recently, Moore et al. also reported that neurons harboring the APP V717I or the APP duplication FAD mutation showed increases in both total and phospho tau levels 27. Interestingly, altered tau levels were not detected in human neurons carrying PS1 FAD mutations, which significantly increased pathogenic Aβ42 species in the same cells 27. These data suggest that elevated tau levels in these models were not due to extracellular Aβ accumulation but may possibly represent a very early stage of tauopathy. It may also be due to developmental alterations induced by the APP FAD mutations.
As summarized, most human FAD neurons showed significant increases in pathogenic Aβ species, while only APP FAD neurons showed altered tau metabolism that may represent very early stages of tauopathy. However, all of these human FAD neurons failed to recapitulate robust extracellular amyloid plaques, NFTs, or any signs of neuronal death, as predicted in the amyloid hypothesis.
In our recent study, we moved one step closer to proving the amyloid hypothesis. By generating human neural stem cell lines carrying multiple mutations in APP together with PS1, we achieved high levels of pathogenic Aβ42 comparable to those in brains of AD patients 44–46.
Platform for AD drug screening in human neural progenitor cells with FAD mutations in a 3D culture system, which successfully reproduce human AD pathogenesis (amyloid plaques-driven tauopathy).
In addition to the impact on toxic Aβ species, our 3D culture model can test if these antibodies can block tau pathologies in 3D human neural cell culture systems 44–46. Human cellular AD models can also be used to determine optimal doses of candidate AD drugs to block Aβ and/or tau pathology without affecting neuronal survival (Fig. 1).
While much progress has been made, many challenges still lie on the path to creating human neural cell culture models that comprehensively recapitulate pathogenic cascades of AD. A major difficulty lies in reconstituting the brain regions most affected in AD: the hippocampus and specific cortical layers. Recent progress in 3D culture technology, such as “cerebral organoids,” may also be helpful in rebuilding the brain structures that are affected by AD in a dish 52,53. These “cerebral organoids” were able to model various discrete brain regions including human cortical areas 52, which enabled them to reproduce microcephaly, a brain developmental disorder. Similarly, pathogenic cascades of AD may be recapitulated in cortex-like structures using this model. Adding neuroinflammatory components, such as microglial cells, which are critical in AD pathogenesis, will illuminate the validity of the amyloid β hypothesis. Reconstitution of robust neuronal death stemming from Aβ and tau pathologies will be the next major step in comprehensively recapitulating AD in a cellular model.
Natunen T, Takalo M, Kemppainen S, Leskelä S, Marttinen M, Kurkinen KM, Pursiheimo JP, Sarajärvi T, Viswanathan J, Gabbouj S, Solje E, Tahvanainen E, Pirttimäki T, Kurki M, Paananen J, Rauramaa T, Miettinen P, Mäkinen P, Leinonen V, Soininen H, Airenne K, Tanzi RE, Tanila H, Haapasalo A, Hiltunen M.
Accumulation of β-amyloid (Aβ) and phosphorylated tau in the brain are central events underlying Alzheimer’s disease (AD) pathogenesis. Aβ is generated from amyloid precursor protein (APP) by β-site APP-cleaving enzyme 1 (BACE1) and γ-secretase-mediated cleavages. Ubiquilin-1, a ubiquitin-like protein, genetically associates with AD and affects APP trafficking, processing and degradation. Here, we have investigated ubiquilin-1 expression in human brain in relation to AD-related neurofibrillary pathology and the effects of ubiquilin-1 overexpression on BACE1, tau, neuroinflammation, and neuronal viability in vitro in co-cultures of mouse embryonic primary cortical neurons and microglial cells under acute neuroinflammation as well as neuronal cell lines, and in vivo in the brain of APdE9 transgenic mice at the early phase of the development of Aβ pathology. Ubiquilin-1 expression was decreased in human temporal cortex in relation to the early stages of AD-related neurofibrillary pathology (Braak stages 0-II vs. III-IV). There was a trend towards a positive correlation between ubiquilin-1 and BACE1 protein levels. Consistent with this, ubiquilin-1 overexpression in the neuron-microglia co-cultures with or without the induction of neuroinflammation resulted in a significant increase in endogenously expressed BACE1 levels. Sustained ubiquilin-1 overexpression in the brain of APdE9 mice resulted in a moderate, but insignificant increase in endogenous BACE1 levels and activity, coinciding with increased levels of soluble Aβ40 and Aβ42. BACE1 levels were also significantly increased in neuronal cells co-overexpressing ubiquilin-1 and BACE1. Ubiquilin-1 overexpression led to the stabilization of BACE1 protein levels, potentially through a mechanism involving decreased degradation in the lysosomal compartment. Ubiquilin-1 overexpression did not significantly affect the neuroinflammation response, but decreased neuronal viability in the neuron-microglia co-cultures under neuroinflammation. Taken together, these results suggest that ubiquilin-1 may mechanistically participate in AD molecular pathogenesis by affecting BACE1 and thereby APP processing and Aβ accumulation.
At this year’s meeting there was a palpable buzz around subjects ranging from microbiomics to the tumor microenvironment and cancer vaccines, big data to in vitro and in vivo modeling and drug delivery (to name just a few).
Josh P. Roberts
2.1.3.8 AACR2016 – Cancer immunotherapy, Volume 2 (Volume Two: Latest in Genomics Methodologies for Therapeutics: Gene Editing, NGS and BioInformatics, Simulations and the Genome Ontology), Part 2: CRISPR for Gene Editing and DNA Repair
By all accounts, this year’s American Association of Cancer Research’s 2016 annual meeting (AACR) was dominated by immunotherapy writ large. Which is not to say the meeting was devoid of other topics – there was certainly palpable buzz around subjects ranging from microbiomics to the tumor microenvironment and cancer vaccines, big data to in vitro and in vivo modeling and drug delivery (to name just a few), that kept the meeting’s 19,500 attendees rapt in New Orleans April 16-20. Yet in the 12-13 years that David R. Soto-Pantoja, Ph.D., has been attending AACR, the Wake Forest University School of Medicine assistant professor of Cancer Biology has “never seen anything take over so much like immunotherapy.”
That being said, it’s not always easy to put cancer research into neat little boxes. Researchers interested in cell signaling, and oncologists concerned with genomics, may have found themselves in sessions dedicated to finding and exploiting neo-antigens (one of immunotherapy’s buckets).
Immunotherapy Buckets
For years there have been certain pillars used to target cancer: chemotherapy, surgery, radiation therapy, and more recently targeted therapies. “And now immunotherapy,” says Wafik El-Deiry, M.D., Ph.D., Deputy Director for Translational Research at the Fox Chase Cancer Center. “This is an emerging and expanding field that is going to be very intensely explored in every direction you can imagine. I wouldn’t even try to pretend that we know what all the buckets are at this point.”
One known bucket that isfast being filled is the area of checkpoint inhibitors (checkpoint blockades). Over the past few years several therapeutics have been developed that had to do with getting the immune system to either better recognize, better target, or better fight, a tumor, with some success. Recall that last year former president Jimmy Carter, earlier diagnosed with metastatic melanoma, was declared “cancer free” following treatment with radiation and an antibody targeted against the immune programmed cell death – 1 (PD-1) antigen. PD-1 keeps the immune cells in check; blockading PD-1 de-inhibits, or “releases the brakes” of these cells and allow them free rein to attack the cancer. Encouraging results from several trials and follow-ups of PD-1 and other checkpoint inhibitors, such as anti-PDL-1 and anti-CTLA-4, were presented. These are in some cases being combined for even greater efficacy.
In addition to trials, “a lot of people, whether in posters or in other smaller talks, delve into the scientific mechanism at the cellular and immunological level of how those worked,” remarked Emil Lou, M.D., Ph.D., assistant professor of Medicine in the Division of Hematology, Oncology and Transplantation at the University of Minnesota.
Another bucket receiving many contributions is the area of CAR-T cells: T cells imbued with a chimeric antigen receptor. T cells that have been harvested from a patient are given a receptor that will recognize a new protein – CD-19, found on B cells, for example – expanded, and re-infused (adoptively transferred) back into the patient to attack the cancer — B cell lymphomas, in the present example. There were many hurdles and pitfalls to be overcome – from finding the right antigen and designing the CAR, to controlling the CAR-T cell’s response – yet the field “has gone at such a rapid pace that it’s very clinically relevant,” says Dr. Lou.
Much familiar (and not-so-familiar) technology, such as high content (phenotypic) screening platforms like the IntelliCyt, is being leveraged to help with array testing, selection, and even manufacturing of CAR-T cells, says Janette Phi, the company’s CBO.
Miltenyi Biotec touted their CliniMACS Prodigy, a benchtop-sized automated cell processing and separation platform, for manufacturing CAR-T cells. It can take a patient’s cells from apheresis and selection on beads, through viral transduction to final product “in 8-10 days,” says clinical instrument specialist Kevin Longin. “It’s a GMP lab without a GMP lab.”
But making bespoke CAR-Ts is a “very expensive approach,” notes Dr. Soto-Pantoja. There were discussions at the meeting about generating off-the-shelf CAR-T cells.
Gene Editing
One way to do this is to use gene editing techniques such as CRISPR/Cas9 to knock out the proteins that could cause rejection of these foreign cells by the patient’s own immune system, or graft-versus-host disease (in which the introduced cells treat the host as foreign).
CRISPR has really become a hot buzz word, says Dr. Lou. “More from the basic science side, and slowly making its way into the clinical talks – it’s not ready for prime time.” While gene editing spins off a different conversation about ethics – people are hesitant about its capacity to create designer babies — he notes that “in cancer it’s helpful to be able to study and reproduce the genes that are driving cancer, in the lab.”
CRISPR is not just for knocking genes in or out, either. In his plenary talk, MIT’s W. M. Keck Career Development Professor of Biomedical Engineering Feng Zhang, Ph.D., discussed a host of other uses to which his lab and others have put the CRISPR/Cas9 system and its relatives. They can be used to create selective transcriptional activation or repression, for example, to recruit epigenetic writers, erasers, and readers, to edit RNA transcripts, and even to identify non-coding regions of the genome.
Neo-antigens and Other Biomarkers
Gene therapy and gene editing are not the only ways in which the complement of expressed proteins is altered. Among the hallmarks of cancer is genetic mutation of oncogenes, tumor suppressor genes, and others – whether as point mutations, duplications, insertions and deletions (indels), or fusions. Because they’re mutated and encode other amino acids, they are “foreign” and may be recognized by the immune system as such, Dr. El-Deiry points out. “One needs to analyze these neo-antigens — to figure out what they are – as well as to analyze the various immune cell subsets that may react with those neo-antigens.” There are many tools that researchers are using to do just that, and there was no shortage of vendors from instrument and assay manufacturers and software developers to service providers – in areas like next-generation genomic sequencing (for both genomics and transcriptomics) and its associated preparatory and analytics, flow cytometry, and antibody development, to name just a few – vying for the attention of AACR conventioneers.
Neo-antigens are, of course, only one mark of a cancerous cell or tissue. In fact, most biomarkers used to diagnose or track cancers in the lab or the clinic rely on “signatures” — collections of multiple markers, each of which in and of themselves may be considered within the normal range but taken together (at the levels expressed) correlate with disease, prognosis, or likely response to treatment. Many panels, available on different platforms, are currently approved for clinical testing and others are working toward that goal.
It’s important to realize that cancers are often not static – they evolve, often as the result of treatment, sometimes selecting for a resistant population. “We’re trying to overcome the mistake of treating a patient’s cancer, after their tumor has grown despite different types of chemotherapies, based on what the information was at the time of diagnosis, when in reality the tumor has potentially transformed into something different,” relates Dr. Lou. Serial biopsies under the auspices of clinical trials, mostly in lung cancer, have revealed the evolution of cancer genomics and an understanding of how to better target therapy to the patient’s tumor at the time of recurrence and progression.
But taking a biopsy is an invasive and sometimes risky procedure.
Liquid Biopsy
It has been known for many years that cells, nucleic acids, and even vesicles derived from tumors can be found in blood and other fluids. “The idea that we can biopsy less invasively by using blood-based biomarkers is really coming to maturity just in the last two years or so,” says Dr. Lou. There is currently a lot of excitement about the possibility of using these as liquid biopsies to “provide a window into the cancer,” says Shane Booth, D. Phil., CTO of Angle LLC. They can look for the presence or evolution of a tumor, for example to monitor the effect of therapy.
Only a single circulating tumor cell (CTC) platform, CELLSEARCH, has thus far been approved for clinical use. Dr. Booth estimates that there are currently perhaps 20-30 different companies with technologies to isolate CTCs, most (like CELLSEARCH) based on affinity capture or (like Angle’s Parsortix platform) on “very sophisticated, bleeding-edge filtration techniques”. These differ from each other in a variety of ways including whether the platform performs analysis, whether it is specific or agnostic to the type of cancer, whether cells can be recovered (and whether they can be recovered alive) for downstream use, the purity of CTCs, and the sample preparation required.
Several companies are offering platforms or services to look at cell free DNA (cfDNA, aka circulating tumor DNA, ctDNA). Trovagene, for example, has assays to examine DNA in blood or urine for common BRAF, KRAS, and EGFR mutations. Meanwhile Nanostring Technologies uses digital molecular barcoding to multiplex hundreds of assays from single molecules without amplification.
Caris Life Sciences’ ADAPT Biotargeting System can profile the different proteins, miRNAs, and DNA found in exosomes. “It’s still early times, but these kinds of test will in the future be used to try and make some predictions about prognosis or response to therapy,” says Dr. El-Deiry.
Personalized Medicine
If there was a theme (implicitly) pervading AACR 2016 more than that of immunotherapy it was that of personalized medicine (aka precision medicine, individualized medicine). From genomic sequencing to determine whether a patient will benefit from (or be harmed by) a given therapy, to examining the microenvironment in which a tumor is found, one size no longer fits all.
The challenge, notes Dr. Soto-Pantoja, is to take the results seen in cases such as checkpoint inhibitor therapy, in which about one third of patients are seen to benefit, and figure out how to extend that to other patients and apply that to other types of cancer.
Disease related changes in proteomics, protein folding, protein-protein interaction, Volume 2 (Volume Two: Latest in Genomics Methodologies for Therapeutics: Gene Editing, NGS and BioInformatics, Simulations and the Genome Ontology), Part 1: Next Generation Sequencing (NGS)
Disease related changes in proteomics, protein folding, protein-protein interaction
Curator: Larry H. Bernstein, MD, FCAP
LPBI
Frankenstein Proteins Stitched Together by Scientists
The Frankenstein monster, stitched together from disparate body parts, proved to be an abomination, but stitched together proteins may fare better. They may, for example, serve specific purposes in medicine, research, and industry. At least, that’s the ambition of scientists based at the University of North Carolina. They have developed a computational protocol called SEWING that builds new proteins from connected or disconnected pieces of existing structures. [Wikipedia]
Unlike Victor Frankenstein, who betrayed Promethean ambition when he sewed together his infamous creature, today’s biochemists are relatively modest. Rather than defy nature, they emulate it. For example, at the University of North Carolina (UNC), researchers have taken inspiration from natural evolutionary mechanisms to develop a technique called SEWING—Structure Extension With Native-substructure Graphs. SEWING is a computational protocol that describes how to stitch together new proteins from connected or disconnected pieces of existing structures.
“We can now begin to think about engineering proteins to do things that nothing else is capable of doing,” said UNC’s Brian Kuhlman, Ph.D. “The structure of a protein determines its function, so if we are going to learn how to design new functions, we have to learn how to design new structures. Our study is a critical step in that direction and provides tools for creating proteins that haven’t been seen before in nature.”
Traditionally, researchers have used computational protein design to recreate in the laboratory what already exists in the natural world. In recent years, their focus has shifted toward inventing novel proteins with new functionality. These design projects all start with a specific structural “blueprint” in mind, and as a result are limited. Dr. Kuhlman and his colleagues, however, believe that by removing the limitations of a predetermined blueprint and taking cues from evolution they can more easily create functional proteins.
Dr. Kuhlman’s UNC team developed a protein design approach that emulates natural mechanisms for shuffling tertiary structures such as pleats, coils, and furrows. Putting the approach into action, the UNC team mapped 50,000 stitched together proteins on the computer, and then it produced 21 promising structures in the laboratory. Details of this work appeared May 6 in the journal Science, in an article entitled, “Design of Structurally Distinct Proteins Using Strategies Inspired by Evolution.”
“Helical proteins designed with SEWING contain structural features absent from other de novo designed proteins and, in some cases, remain folded at more than 100°C,” wrote the authors. “High-resolution structures of the designed proteins CA01 and DA05R1 were solved by x-ray crystallography (2.2 angstrom resolution) and nuclear magnetic resonance, respectively, and there was excellent agreement with the design models.”
Essentially, the UNC scientists confirmed that the proteins they had synthesized contained the unique structural varieties that had been designed on the computer. The UNC scientists also determined that the structures they had created had new surface and pocket features. Such features, they noted, provide potential binding sites for ligands or macromolecules.
“We were excited that some had clefts or grooves on the surface, regions that naturally occurring proteins use for binding other proteins,” said the Science article’s first author, Tim M. Jacobs, Ph.D., a former graduate student in Dr. Kuhlman’s laboratory. “That’s important because if we wanted to create a protein that can act as a biosensor to detect a certain metabolite in the body, either for diagnostic or research purposes, it would need to have these grooves. Likewise, if we wanted to develop novel therapeutics, they would also need to attach to specific proteins.”
Currently, the UNC researchers are using SEWING to create proteins that can bind to several other proteins at a time. Many of the most important proteins are such multitaskers, including the blood protein hemoglobin.
Histone Mutation Deranges DNA Methylation to Cause Cancer
In some cancers, including chondroblastoma and a rare form of childhood sarcoma, a mutation in histone H3 reduces global levels of methylation (dark areas) in tumor cells but not in normal cells (arrowhead). The mutation locks the cells in a proliferative state to promote tumor development. [Laboratory of Chromatin Biology and Epigenetics at The Rockefeller University]
They have been called oncohistones, the mutated histones that are known to accompany certain pediatric cancers. Despite their suggestive moniker, oncohistones have kept their oncogenic secrets. For example, it has been unclear whether oncohistones are able to cause cancer on their own, or whether they need to act in concert with additional DNA mutations, that is, mutations other than those affecting histone structures.
While oncohistone mechanisms remain poorly understood, this particular question—the oncogenicity of lone oncohistones—has been resolved, at least in part. According to researchers based at The Rockefeller University, a change to the structure of a histone can trigger a tumor on its own.
This finding appeared May 13 in the journal Science, in an article entitled, “Histone H3K36 Mutations Promote Sarcomagenesis Through Altered Histone Methylation Landscape.” The article describes the Rockefeller team’s study of a histone protein called H3, which has been found in about 95% of samples of chondoblastoma, a benign tumor that arises in cartilage, typically during adolescence.
The Rockefeller scientists found that the H3 lysine 36–to–methionine (H3K36M) mutation impairs the differentiation of mesenchymal progenitor cells and generates undifferentiated sarcoma in vivo.
After the scientists inserted the H3 histone mutation into mouse mesenchymal progenitor cells (MPCs)—which generate cartilage, bone, and fat—they watched these cells lose the ability to differentiate in the lab. Next, the scientists injected the mutant cells into living mice, and the animals developed the tumors rich in MPCs, known as an undifferentiated sarcoma. Finally, the researchers tried to understand how the mutation causes the tumors to develop.
The scientists determined that H3K36M mutant nucleosomes inhibit the enzymatic activities of several H3K36 methyltransferases.
“Depleting H3K36 methyltransferases, or expressing an H3K36I mutant that similarly inhibits H3K36 methylation, is sufficient to phenocopy the H3K36M mutation,” the authors of the Science study wrote. “After the loss of H3K36 methylation, a genome-wide gain in H3K27 methylation leads to a redistribution of polycomb repressive complex 1 and de-repression of its target genes known to block mesenchymal differentiation.”
Essentially, when the H3K36M mutation occurs, the cell becomes locked in a proliferative state—meaning it divides constantly, leading to tumors. Specifically, the mutation inhibits enzymes that normally tag the histone with chemical groups known as methyls, allowing genes to be expressed normally.
In response to this lack of modification, another part of the histone becomes overmodified, or tagged with too many methyl groups. “This leads to an overall resetting of the landscape of chromatin, the complex of DNA and its associated factors, including histones,” explained co-author Peter Lewis, Ph.D., a professor at the University of Wisconsin-Madison and a former postdoctoral fellow in laboratory of C. David Allis, Ph.D., a professor at Rockefeller.
The finding—that a “resetting” of the chromatin landscape can lock the cell into a proliferative state—suggests that researchers should be on the hunt for more mutations in histones that might be driving tumors. For their part, the Rockefeller researchers are trying to learn more about how this specific mutation in histone H3 causes tumors to develop.
“We want to know which pathways cause the mesenchymal progenitor cells that carry the mutation to continue to divide, and not differentiate into the bone, fat, and cartilage cells they are destined to become,” said co-author Chao Lu, Ph.D., a postdoctoral fellow in the Allis lab.
Once researchers understand more about these pathways, added Dr. Lewis, they can consider ways of blocking them with drugs, particularly in tumors such as MPC-rich sarcomas—which, unlike chondroblastoma, can be deadly. In fact, drugs that block these pathways may already exist and may even be in use for other types of cancers.
“One long-term goal of our collaborative team is to better understand fundamental mechanisms that drive these processes, with the hope of providing new therapeutic approaches,” concluded Dr. Allis.
Histone H3K36 mutations promote sarcomagenesis through altered histone methylation landscape
Missense mutations (that change one amino acid for another) in histone H3 can produce a so-called oncohistone and are found in a number of pediatric cancers. For example, the lysine-36–to-methionine (K36M) mutation is seen in almost all chondroblastomas. Lu et al. show that K36M mutant histones are oncogenic, and they inhibit the normal methylation of this same residue in wild-type H3 histones. The mutant histones also interfere with the normal development of bone-related cells and the deposition of inhibitory chromatin marks.
Several types of pediatric cancers reportedly contain high-frequency missense mutations in histone H3, yet the underlying oncogenic mechanism remains poorly characterized. Here we report that the H3 lysine 36–to–methionine (H3K36M) mutation impairs the differentiation of mesenchymal progenitor cells and generates undifferentiated sarcoma in vivo. H3K36M mutant nucleosomes inhibit the enzymatic activities of several H3K36 methyltransferases. Depleting H3K36 methyltransferases, or expressing an H3K36I mutant that similarly inhibits H3K36 methylation, is sufficient to phenocopy the H3K36M mutation. After the loss of H3K36 methylation, a genome-wide gain in H3K27 methylation leads to a redistribution of polycomb repressive complex 1 and de-repression of its target genes known to block mesenchymal differentiation. Our findings are mirrored in human undifferentiated sarcomas in which novel K36M/I mutations in H3.1 are identified.
Mitochondria? We Don’t Need No Stinking Mitochondria!
Diagram comparing typical eukaryotic cell to the newly discovered mitochondria-free organism. [Karnkowska et al., 2016, Current Biology 26, 1–11]
The organelle that produces a significant portion of energy for eukaryotic cells would seemingly be indispensable, yet over the years, a number of organisms have been discovered that challenge that biological pretense. However, these so-called amitochondrial species may lack a defined organelle, but they still retain some residual functions of their mitochondria-containing brethren. Even the intestinal eukaryotic parasite Giardia intestinalis, which was for many years considered to be mitochondria-free, was proven recently to contain a considerably shriveled version of the organelle.
Now, an international group of scientists has released results from a new study that challenges the notion that mitochondria are essential for eukaryotes—discovering an organism that resides in the gut of chinchillas that contains absolutely no trace of mitochondria at all.
“In low-oxygen environments, eukaryotes often possess a reduced form of the mitochondrion, but it was believed that some of the mitochondrial functions are so essential that these organelles are indispensable for their life,” explained lead study author Anna Karnkowska, Ph.D., visiting scientist at the University of British Columbia in Vancouver. “We have characterized a eukaryotic microbe which indeed possesses no mitochondrion at all.”
Mysterious Eukaryote Missing Mitochondria
Researchers uncover the first example of a eukaryotic organism that lacks the organelles.
Monocercomonoides sp. PA203VLADIMIR HAMPL, CHARLES UNIVERSITY, PRAGUE, CZECH REPUBLIC
Scientists have long thought that mitochondria—organelles responsible for energy generation—are an essential and defining feature of a eukaryotic cell. Now, researchers from Charles University in Prague and their colleagues are challenging this notion with their discovery of a eukaryotic organism,Monocercomonoides species PA203, which lacks mitochondria. The team’s phylogenetic analysis, published today (May 12) in Current Biology,suggests that Monocercomonoides—which belong to the Oxymonadida group of protozoa and live in low-oxygen environments—did have mitochondria at one point, but eventually lost the organelles.
“This is quite a groundbreaking discovery,” said Thijs Ettema, who studies microbial genome evolution at Uppsala University in Sweden and was not involved in the work.
“This study shows that mitochondria are not so central for all lineages of living eukaryotes,” Toni Gabaldonof the Center for Genomic Regulation in Barcelona, Spain, who also was not involved in the work, wrote in an email to The Scientist. “Yet, this mitochondrial-devoid, single-cell eukaryote is as complex as other eukaryotic cells in almost any other aspect of cellular complexity.”
Charles University’s Vladimir Hampl studies the evolution of protists. Along with Anna Karnkowska and colleagues, Hampl decided to sequence the genome of Monocercomonoides, a little-studied protist that lives in the digestive tracts of vertebrates. The 75-megabase genome—the first of an oxymonad—did not contain any conserved genes found on mitochondrial genomes of other eukaryotes, the researchers found. It also did not contain any nuclear genes associated with mitochondrial functions.
“It was surprising and for a long time, we didn’t believe that the [mitochondria-associated genes were really not there]. We thought we were missing something,” Hampl told The Scientist. “But when the data kept accumulating, we switched to the hypothesis that this organism really didn’t have mitochondria.”
Because researchers have previously not found examples of eukaryotes without some form of mitochondria, the current theory of the origin of eukaryotes poses that the appearance of mitochondria was crucial to the identity of these organisms.
“We now view these mitochondria-like organelles as a continuum from full mitochondria to very small . Some anaerobic protists, for example, have only pared down versions of mitochondria, such as hydrogenosomes and mitosomes, which lack a mitochondrial genome. But these mitochondrion-like organelles perform essential functions of the iron-sulfur cluster assembly pathway, which is known to be conserved in virtually all eukaryotic organisms studied to date.
Yet, in their analysis, the researchers found no evidence of the presence of any components of this mitochondrial pathway.
Like the scaling down of mitochondria into mitosomes in some organisms, the ancestors of modernMonocercomonoides once had mitochondria. “Because this organism is phylogenetically nested among relatives that had conventional mitochondria, this is most likely a secondary adaptation,” said Michael Gray, a biochemist who studies mitochondria at Dalhousie University in Nova Scotia and was not involved in the study. According to Gray, the finding of a mitochondria-deficient eukaryote does not mean that the organelles did not play a major role in the evolution of eukaryotic cells.
To be sure they were not missing mitochondrial proteins, Hampl’s team also searched for potential mitochondrial protein homologs of other anaerobic species, and for signature sequences of a range of known mitochondrial proteins. While similar searches with other species uncovered a few mitochondrial proteins, the team’s analysis of Monocercomonoides came up empty.
“The data is very complete,” said Ettema. “It is difficult to prove the absence of something but [these authors] do a convincing job.”
To form the essential iron-sulfur clusters, the team discovered that Monocercomonoides use a sulfur mobilization system found in the cytosol, and that an ancestor of the organism acquired this system by lateral gene transfer from bacteria. This cytosolic, compensating system allowed Monocercomonoides to lose the otherwise essential iron-sulfur cluster-forming pathway in the mitochondrion, the team proposed.
“This work shows the great evolutionary plasticity of the eukaryotic cell,” said Karnkowska, who participated in the study while she was a postdoc at Charles University. Karnkowska, who is now a visiting researcher at the University of British Columbia in Canada, added: “This is a striking example of how far the evolution of a eukaryotic cell can go that was beyond our expectations.”
“The results highlight how many surprises may await us in the poorly studied eukaryotic phyla that live in under-explored environments,” Gabaldon said.
Ettema agreed. “Now that we’ve found one, we need to look at the bigger picture and see if there are other examples of eukaryotes that have lost their mitochondria, to understand how adaptable eukaryotes are.”
Karnkowska et al., “A eukaryote without a mitochondrial organelle,” Current Biology,doi:10.1016/j.cub.2016.03.053, 2016.
•Monocercomonoides sp. is a eukaryotic microorganism with no mitochondria
•The complete absence of mitochondria is a secondary loss, not an ancestral feature
•The essential mitochondrial ISC pathway was replaced by a bacterial SUF system
The presence of mitochondria and related organelles in every studied eukaryote supports the view that mitochondria are essential cellular components. Here, we report the genome sequence of a microbial eukaryote, the oxymonad Monocercomonoides sp., which revealed that this organism lacks all hallmark mitochondrial proteins. Crucially, the mitochondrial iron-sulfur cluster assembly pathway, thought to be conserved in virtually all eukaryotic cells, has been replaced by a cytosolic sulfur mobilization system (SUF) acquired by lateral gene transfer from bacteria. In the context of eukaryotic phylogeny, our data suggest that Monocercomonoides is not primitively amitochondrial but has lost the mitochondrion secondarily. This is the first example of a eukaryote lacking any form of a mitochondrion, demonstrating that this organelle is not absolutely essential for the viability of a eukaryotic cell.
This method catches a bait protein together with its associated protein partners in virus-like particles that are budded from human cells. Like this, cell lysis is not needed and protein complexes are preserved during purification.
With his feet in both a proteomics lab and an interactomics lab, VIB/UGent professor Sven Eyckerman is well aware of the shortcomings of conventional approaches to analyze protein complexes. The lysis conditions required in mass spectrometry–based strategies to break open cell membranes often affect protein-protein interactions. “The first step in a classical study on protein complexes essentially turns the highly organized cellular structure into a big messy soup”, Eyckerman explains.
Inspired by virus biology, Eyckerman came up with a creative solution. “We used the natural process of HIV particle formation to our benefit by hacking a completely safe form of the virus to abduct intact protein machines from the cell.” It is well known that the HIV virus captures a number of host proteins during its particle formation. By fusing a bait protein to the HIV-1 GAG protein, interaction partners become trapped within virus-like particles that bud from mammalian cells. Standard proteomic approaches are used next to reveal the content of these particles. Fittingly, the team named the method ‘Virotrap’.
The Virotrap approach is exceptional as protein networks can be characterized under natural conditions. By trapping protein complexes in the protective environment of a virus-like shell, the intact complexes are preserved during the purification process. The researchers showed the method was suitable for detection of known binary interactions as well as mass spectrometry-based identification of novel protein partners.
Virotrap is a textbook example of bringing research teams with complementary expertise together. Cross-pollination with the labs of Jan Tavernier (VIB/UGent) and Kris Gevaert (VIB/UGent) enabled the development of this platform.
Jan Tavernier: “Virotrap represents a new concept in co-complex analysis wherein complex stability is physically guaranteed by a protective, physical structure. It is complementary to the arsenal of existing interactomics methods, but also holds potential for other fields, like drug target characterization. We also developed a small molecule-variant of Virotrap that could successfully trap protein partners for small molecule baits.”
Kris Gevaert: “Virotrap can also impact our understanding of disease pathways. We were actually surprised to see that this virus-based system could be used to study antiviral pathways, like Toll-like receptor signaling. Understanding these protein machines in their natural environment is essential if we want to modulate their activity in pathology.“
Trapping mammalian protein complexes in viral particles
Cell lysis is an inevitable step in classical mass spectrometry–based strategies to analyse protein complexes. Complementary lysis conditions, in situ cross-linking strategies and proximal labelling techniques are currently used to reduce lysis effects on the protein complex. We have developed Virotrap, a viral particle sorting approach that obviates the need for cell homogenization and preserves the protein complexes during purification. By fusing a bait protein to the HIV-1 GAG protein, we show that interaction partners become trapped within virus-like particles (VLPs) that bud from mammalian cells. Using an efficient VLP enrichment protocol, Virotrap allows the detection of known binary interactions and MS-based identification of novel protein partners as well. In addition, we show the identification of stimulus-dependent interactions and demonstrate trapping of protein partners for small molecules. Virotrap constitutes an elegant complementary approach to the arsenal of methods to study protein complexes.
Proteins mostly exert their function within supramolecular complexes. Strategies for detecting protein–protein interactions (PPIs) can be roughly divided into genetic systems1 and co-purification strategies combined with mass spectrometry (MS) analysis (for example, AP–MS)2. The latter approaches typically require cell or tissue homogenization using detergents, followed by capture of the protein complex using affinity tags3 or specific antibodies4. The protein complexes extracted from this ‘soup’ of constituents are then subjected to several washing steps before actual analysis by trypsin digestion and liquid chromatography–MS/MS analysis. Such lysis and purification protocols are typically empirical and have mostly been optimized using model interactions in single labs. In fact, lysis conditions can profoundly affect the number of both specific and nonspecific proteins that are identified in a typical AP–MS set-up. Indeed, recent studies using the nuclear pore complex as a model protein complex describe optimization of purifications for the different proteins in the complex by examining 96 different conditions5. Nevertheless, for new purifications, it remains hard to correctly estimate the loss of factors in a standard AP–MS experiment due to washing and dilution effects during treatments (that is, false negatives). These considerations have pushed the concept of stabilizing PPIs before the actual homogenization step. A classical approach involves cross-linking with simple reagents (for example, formaldehyde) or with more advanced isotope-labelled cross-linkers (reviewed in ref. 2). However, experimental challenges such as cell permeability and reactivity still preclude the widespread use of cross-linking agents. Moreover, MS-generated spectra of cross-linked peptides are notoriously difficult to identify correctly. A recent lysis-independent solution involves the expression of a bait protein fused to a promiscuous biotin ligase, which results in labelling of proteins proximal to the activity of the enzyme-tagged bait protein6. When compared with AP–MS, this BioID approach delivers a complementary set of candidate proteins, including novel interaction partners7, 8. Such particular studies clearly underscore the need for complementary approaches in the co-complex strategies.
The evolutionary stress on viruses promoted highly condensed coding of information and maximal functionality for small genomes. Accordingly, for HIV-1 it is sufficient to express a single protein, the p55 GAG protein, for efficient production of virus-like particles (VLPs) from cells9, 10. This protein is highly mobile before its accumulation in cholesterol-rich regions of the membrane, where multimerization initiates the budding process11. A total of 4,000–5,000 GAG molecules is required to form a single particle of about 145 nm (ref. 12). Both VLPs and mature viruses contain a number of host proteins that are recruited by binding to viral proteins. These proteins can either contribute to the infectivity (for example, Cyclophilin/FKBPA13) or act as antiviral proteins preventing the spreading of the virus (for example, APOBEC proteins14).
We here describe the development and application of Virotrap, an elegant co-purification strategy based on the trapping of a bait protein together with its associated protein partners in VLPs that are budded from the cell. After enrichment, these particles can be analysed by targeted (for example, western blotting) or unbiased approaches (MS-based proteomics). Virotrap allows detection of known binary PPIs, analysis of protein complexes and their dynamics, and readily detects protein binders for small molecules.
Concept of the Virotrap system
Classical AP–MS approaches rely on cell homogenization to access protein complexes, a step that can vary significantly with the lysis conditions (detergents, salt concentrations, pH conditions and so on)5. To eliminate the homogenization step in AP–MS, we reasoned that incorporation of a protein complex inside a secreted VLP traps the interaction partners under native conditions and protects them during further purification. We thus explored the possibility of protein complex packaging by the expression of GAG-bait protein chimeras (Fig. 1) as expression of GAG results in the release of VLPs from the cells9, 10. As a first PPI pair to evaluate this concept, we selected the HRAS protein as a bait combined with the RAF1 prey protein. We were able to specifically detect the HRAS–RAF1 interaction following enrichment of VLPs via ultracentrifugation (Supplementary Fig. 1a). To prevent tedious ultracentrifugation steps, we designed a novel single-step protocol wherein we co-express the vesicular stomatitis virus glycoprotein (VSV-G) together with a tagged version of this glycoprotein in addition to the GAG bait and prey. Both tagged and untagged VSV-G proteins are probably presented as trimers on the surface of the VLPs, allowing efficient antibody-based recovery from large volumes. The HRAS–RAF1 interaction was confirmed using this single-step protocol (Supplementary Fig. 1b). No associations with unrelated bait or prey proteins were observed for both protocols.
Figure 1: Schematic representation of the Virotrap strategy.
Expression of a GAG-bait fusion protein (1) results in submembrane multimerization (2) and subsequent budding of VLPs from cells (3). Interaction partners of the bait protein are also trapped within these VLPs and can be identified after purification by western blotting or MS analysis (4).
Virotrap for the detection of binary interactions
We next explored the reciprocal detection of a set of PPI pairs, which were selected based on published evidence and cytosolic localization15. After single-step purification and western blot analysis, we could readily detect reciprocal interactions between CDK2 and CKS1B, LCP2 and GRAP2, and S100A1 and S100B (Fig. 2a). Only for the LCP2 prey we observed nonspecific association with an irrelevant bait construct. However, the particle levels of the GRAP2 bait were substantially lower as compared with those of the GAG control construct (GAG protein levels in VLPs; Fig. 2a, second panel of the LCP2 prey). After quantification of the intensities of bait and prey proteins and normalization of prey levels using bait levels, we observed a strong enrichment for the GAG-GRAP2 bait (Supplementary Fig. 2).
…..
Virotrap for unbiased discovery of novel interactions
For the detection of novel interaction partners, we scaled up VLP production and purification protocols (Supplementary Fig. 5 and Supplementary Note 1 for an overview of the protocol) and investigated protein partners trapped using the following bait proteins: Fas-associated via death domain (FADD), A20 (TNFAIP3), nuclear factor-κB (NF-κB) essential modifier (IKBKG), TRAF family member-associated NF-κB activator (TANK), MYD88 and ring finger protein 41 (RNF41). To obtain specific interactors from the lists of identified proteins, we challenged the data with a combined protein list of 19 unrelated Virotrap experiments (Supplementary Table 1 for an overview). Figure 3 shows the design and the list of candidate interactors obtained after removal of all proteins that were found in the 19 control samples (including removal of proteins from the control list identified with a single peptide). The remaining list of confident protein identifications (identified with at least two peptides in at least two biological repeats) reveals both known and novel candidate interaction partners. All candidate interactors including single peptide protein identifications are given in Supplementary Data 2 and also include recurrent protein identifications of known interactors based on a single peptide; for example, CASP8 for FADD and TANK for NEMO. Using alternative methods, we confirmed the interaction between A20 and FADD, and the associations with transmembrane proteins (insulin receptor and insulin-like growth factor receptor 1) that were captured using RNF41 as a bait (Supplementary Fig. 6). To address the use of Virotrap for the detection of dynamic interactions, we activated the NF-κB pathway via the tumour necrosis factor (TNF) receptor (TNFRSF1A) using TNFα (TNF) and performed Virotrap analysis using A20 as bait (Fig. 3). This resulted in the additional enrichment of receptor-interacting kinase (RIPK1), TNFR1-associated via death domain (TRADD), TNFRSF1A and TNF itself, confirming the expected activated complex20.
Figure 3: Use of Virotrap for unbiased interactome analysis
Lysis conditions used in AP–MS strategies are critical for the preservation of protein complexes. A multitude of lysis conditions have been described, culminating in a recent report where protein complex stability was assessed under 96 lysis/purification protocols5. Moreover, the authors suggest to optimize the conditions for every complex, implying an important workload for researchers embarking on protein complex analysis using classical AP–MS. As lysis results in a profound change of the subcellular context and significantly alters the concentration of proteins, loss of complex integrity during a classical AP–MS protocol can be expected. A clear evolution towards ‘lysis-independent’ approaches in the co-complex analysis field is evident with the introduction of BioID6 and APEX25 where proximal proteins, including proteins residing in the complex, are labelled with biotin by an enzymatic activity fused to a bait protein. A side-by-side comparison between classical AP–MS and BioID showed overlapping and unique candidate binding proteins for both approaches7, 8, supporting the notion that complementary methods are needed to provide a comprehensive view on protein complexes. This has also been clearly demonstrated for binary approaches15 and is a logical consequence of the heterogenic nature underlying PPIs (binding mechanism, requirement for posttranslational modifications, location, affinity and so on).
In this report, we explore an alternative, yet complementary method to isolate protein complexes without interfering with cellular integrity. By trapping protein complexes in the protective environment of a virus-like shell, the intact complexes are preserved during the purification process. This constitutes a new concept in co-complex analysis wherein complex stability is physically guaranteed by a protective, physical structure. A comparison of our Virotrap approach with AP–MS shows complementary data, with specific false positives and false negatives for both methods (Supplementary Fig. 7).
The current implementation of the Virotrap platform implies the use of a GAG-bait construct resulting in considerable expression of the bait protein. Different strategies are currently pursued to reduce bait expression including co-expression of a native GAG protein together with the GAG-bait protein, not only reducing bait expression but also creating more ‘space’ in the particles potentially accommodating larger bait protein complexes. Nevertheless, the presence of the bait on the forming GAG scaffold creates an intracellular affinity matrix (comparable to the early in vitro affinity columns for purification of interaction partners from lysates26) that has the potential to compete with endogenous complexes by avidity effects. This avidity effect is a powerful mechanism that aids in the recruitment of cyclophilin to GAG27, a well-known weak interaction (Kd=16 μM (ref. 28)) detectable as a background association in the Virotrap system. Although background binding may be increased by elevated bait expression, weaker associations are readily detectable (for example, MAL—MYD88-binding study; Fig. 2c).
The size of Virotrap particles (around 145 nm) suggests limitations in the size of the protein complex that can be accommodated in the particles. Further experimentation is required to define the maximum size of proteins or the number of protein complexes that can be trapped inside the particles.
….
In conclusion, Virotrap captures significant parts of known interactomes and reveals new interactions. This cell lysis-free approach purifies protein complexes under native conditions and thus provides a powerful method to complement AP–MS or other PPI data. Future improvements of the system include strategies to reduce bait expression to more physiological levels and application of advanced data analysis options to filter out background. These developments can further aid in the deployment of Virotrap as a powerful extension of the current co-complex technology arsenal.
New Autism Blood Biomarker Identified
Researchers at UT Southwestern Medical Center have identified a blood biomarker that may aid in earlier diagnosis of children with autism spectrum disorder, or ASD
In a recent edition of Scientific Reports, UT Southwestern researchers reported on the identification of a blood biomarker that could distinguish the majority of ASD study participants versus a control group of similar age range. In addition, the biomarker was significantly correlated with the level of communication impairment, suggesting that the blood test may give insight into ASD severity.
“Numerous investigators have long sought a biomarker for ASD,” said Dr. Dwight German, study senior author and Professor of Psychiatry at UT Southwestern. “The blood biomarker reported here along with others we are testing can represent a useful test with over 80 percent accuracy in identifying ASD.”
ASD1 – was 66 percent accurate in diagnosing ASD. When combined with thyroid stimulating hormone level measurements, the ASD1-binding biomarker was 73 percent accurate at diagnosis
A Search for Blood Biomarkers for Autism: Peptoids
Autism spectrum disorder (ASD) is a neurodevelopmental disorder characterized by impairments in social interaction and communication, and restricted, repetitive patterns of behavior. In order to identify individuals with ASD and initiate interventions at the earliest possible age, biomarkers for the disorder are desirable. Research findings have identified widespread changes in the immune system in children with autism, at both systemic and cellular levels. In an attempt to find candidate antibody biomarkers for ASD, highly complex libraries of peptoids (oligo-N-substituted glycines) were screened for compounds that preferentially bind IgG from boys with ASD over typically developing (TD) boys. Unexpectedly, many peptoids were identified that preferentially bound IgG from TD boys. One of these peptoids was studied further and found to bind significantly higher levels (>2-fold) of the IgG1 subtype in serum from TD boys (n = 60) compared to ASD boys (n = 74), as well as compared to older adult males (n = 53). Together these data suggest that ASD boys have reduced levels (>50%) of an IgG1 antibody, which resembles the level found normally with advanced age. In this discovery study, the ASD1 peptoid was 66% accurate in predicting ASD.
….
Peptoid libraries have been used previously to search for autoantibodies for neurodegenerative diseases19 and for systemic lupus erythematosus (SLE)21. In the case of SLE, peptoids were identified that could identify subjects with the disease and related syndromes with moderate sensitivity (70%) and excellent specificity (97.5%). Peptoids were used to measure IgG levels from both healthy subjects and SLE patients. Binding to the SLE-peptoid was significantly higher in SLE patients vs. healthy controls. The IgG bound to the SLE-peptoid was found to react with several autoantigens, suggesting that the peptoids are capable of interacting with multiple, structurally similar molecules. These data indicate that IgG binding to peptoids can identify subjects with high levels of pathogenic autoantibodies vs. a single antibody.
In the present study, the ASD1 peptoid binds significantly lower levels of IgG1 in ASD males vs. TD males. This finding suggests that the ASD1 peptoid recognizes antibody(-ies) of an IgG1 subtype that is (are) significantly lower in abundance in the ASD males vs. TD males. Although a previous study14 has demonstrated lower levels of plasma IgG in ASD vs. TD children, here, we additionally quantified serum IgG levels in our individuals and found no difference in IgG between the two groups (data not shown). Furthermore, our IgG levels did not correlate with ASD1 binding levels, indicating that ASD1 does not bind IgG generically, and that the peptoid’s ability to differentiate between ASD and TD males is related to a specific antibody(-ies).
ASD subjects underwent a diagnostic evaluation using the ADOS and ADI-R, and application of the DSM-IV criteria prior to study inclusion. Only those subjects with a diagnosis of Autistic Disorder were included in the study. The ADOS is a semi-structured observation of a child’s behavior that allows examiners to observe the three core domains of ASD symptoms: reciprocal social interaction, communication, and restricted and repetitive behaviors1. When ADOS subdomain scores were compared with peptoid binding, the only significant relationship was with Social Interaction. However, the positive correlation would suggest that lower peptoid binding is associated with better social interaction, not poorer social interaction as anticipated.
The ADI-R is a structured parental interview that measures the core features of ASD symptoms in the areas of reciprocal social interaction, communication and language, and patterns of behavior. Of the three ADI-R subdomains, only the Communication domain was related to ASD1 peptoid binding, and this correlation was negative suggesting that low peptoid binding is associated with greater communication problems. These latter data are similar to the findings of Heuer et al.14 who found that children with autism with low levels of plasma IgG have high scores on the Aberrant Behavior Checklist (p < 0.0001). Thus, peptoid binding to IgG1 may be useful as a severity marker for ASD allowing for further characterization of individuals, but further research is needed.
It is interesting that in serum samples from older men, the ASD1 binding is similar to that in the ASD boys. This is consistent with the observation that with aging there is a reduction in the strength of the immune system, and the changes are gender-specific25. Recent studies using parabiosis26, in which blood from young mice reverse age-related impairments in cognitive function and synaptic plasticity in old mice, reveal that blood constituents from young subjects may contain important substances for maintaining neuronal functions. Work is in progress to identify the antibody/antibodies that are differentially binding to the ASD1 peptoid, which appear as a single band on the electrophoresis gel (Fig. 4).
……..
The ADI-R is a structured parental interview that measures the core features of ASD symptoms in the areas of reciprocal social interaction, communication and language, and patterns of behavior. Of the three ADI-R subdomains, only the Communication domain was related to ASD1 peptoid binding, and this correlation was negative suggesting that low peptoid binding is associated with greater communication problems. These latter data are similar to the findings of Heuer et al.14 who found that children with autism with low levels of plasma IgG have high scores on the Aberrant Behavior Checklist (p < 0.0001). Thus, peptoid binding to IgG1 may be useful as a severity marker for ASD allowing for further characterization of individuals, but further research is needed.
Titration of IgG binding to ASD1 using serum pooled from 10 TD males and 10 ASD males demonstrates ASD1’s ability to differentiate between the two groups. (B)Detecting IgG1 subclass instead of total IgG amplifies this differentiation. (C) IgG1 binding of individual ASD (n=74) and TD (n=60) male serum samples (1:100 dilution) to ASD1 significantly differs with TD>ASD. In addition, IgG1 binding of older adult male (AM) serum samples (n=53) to ASD1 is significantly lower than TD males, and not different from ASD males. The three groups were compared with a Kruskal-Wallis ANOVA, H = 10.1781, p<0.006. **p<0.005. Error bars show SEM. (D) Receiver-operating characteristic curve for ASD1’s ability to discriminate between ASD and TD males.
Association between peptoid binding and ADOS and ADI-R subdomains
Higher scores in any domain on the ADOS and ADI-R are indicative of more abnormal behaviors and/or symptoms. Among ADOS subdomains, there was no significant relationship between Communication and peptoid binding (z = 0.04, p = 0.966), Communication + Social interaction (z = 1.53, p = 0.127), or Stereotyped Behaviors and Restrictive Interests (SBRI) (z = 0.46, p = 0.647). Higher scores on the Social Interaction domain were significantly associated with higher peptoid binding (z = 2.04, p = 0.041).
Among ADI-R subdomains, higher scores on the Communication domain were associated with lower levels of peptoid binding (z = −2.28, p = 0.023). There was not a significant relationship between Social Interaction (z = 0.07, p = 0.941) or Restrictive/Repetitive Stereotyped Behaviors (z = −1.40, p = 0.162) and peptoid binding.
Computational Model Finds New Protein-Protein Interactions
Researchers at University of Pittsburgh have discovered 500 new protein-protein interactions (PPIs) associated with genes linked to schizophrenia.
Using a computational model they developed, researchers at the University of Pittsburgh School of Medicine have discovered more than 500 new protein-protein interactions (PPIs) associated with genes linked to schizophrenia. The findings, published online in npj Schizophrenia, a Nature Publishing Group journal, could lead to greater understanding of the biological underpinnings of this mental illness, as well as point the way to treatments.
There have been many genome-wide association studies (GWAS) that have identified gene variants associated with an increased risk for schizophrenia, but in most cases there is little known about the proteins that these genes make, what they do and how they interact, said senior investigator Madhavi Ganapathiraju, Ph.D., assistant professor of biomedical informatics, Pitt School of Medicine.
“GWAS studies and other research efforts have shown us what genes might be relevant in schizophrenia,” she said. “What we have done is the next step. We are trying to understand how these genes relate to each other, which could show us the biological pathways that are important in the disease.”
Each gene makes proteins and proteins typically interact with each other in a biological process. Information about interacting partners can shed light on the role of a gene that has not been studied, revealing pathways and biological processes associated with the disease and also its relation to other complex diseases.
Dr. Ganapathiraju’s team developed a computational model called High-Precision Protein Interaction Prediction (HiPPIP) and applied it to discover PPIs of schizophrenia-linked genes identified through GWAS, as well as historically known risk genes. They found 504 never-before known PPIs, and noted also that while schizophrenia-linked genes identified historically and through GWAS had little overlap, the model showed they shared more than 100 common interactors.
“We can infer what the protein might do by checking out the company it keeps,” Dr. Ganapathiraju explained. “For example, if I know you have many friends who play hockey, it could mean that you are involved in hockey, too. Similarly, if we see that an unknown protein interacts with multiple proteins involved in neural signaling, for example, there is a high likelihood that the unknown entity also is involved in the same.”
Dr. Ganapathiraju and colleagues have drawn such inferences on protein function based on the PPIs of proteins, and made their findings available on a website Schizo-Pi. This information can be used by biologists to explore the schizophrenia interactome with the aim of understanding more about the disease or developing new treatment drugs.
Schizophrenia interactome with 504 novel protein–protein interactions
(GWAS) have revealed the role of rare and common genetic variants, but the functional effects of the risk variants remain to be understood. Protein interactome-based studies can facilitate the study of molecular mechanisms by which the risk genes relate to schizophrenia (SZ) genesis, but protein–protein interactions (PPIs) are unknown for many of the liability genes. We developed a computational model to discover PPIs, which is found to be highly accurate according to computational evaluations and experimental validations of selected PPIs. We present here, 365 novel PPIs of liability genes identified by the SZ Working Group of the Psychiatric Genomics Consortium (PGC). Seventeen genes that had no previously known interactions have 57 novel interactions by our method. Among the new interactors are 19 drug targets that are targeted by 130 drugs. In addition, we computed 147 novel PPIs of 25 candidate genes investigated in the pre-GWAS era. While there is little overlap between the GWAS genes and the pre-GWAS genes, the interactomes reveal that they largely belong to the same pathways, thus reconciling the apparent disparities between the GWAS and prior gene association studies. The interactome including 504 novel PPIs overall, could motivate other systems biology studies and trials with repurposed drugs. The PPIs are made available on a webserver, called Schizo-Pi at http://severus.dbmi.pitt.edu/schizo-pi with advanced search capabilities.
Schizophrenia (SZ) is a common, potentially severe psychiatric disorder that afflicts all populations.1 Gene mapping studies suggest that SZ is a complex disorder, with a cumulative impact of variable genetic effects coupled with environmental factors.2 As many as 38 genome-wide association studies (GWAS) have been reported on SZ out of a total of 1,750 GWAS publications on 1,087 traits or diseases reported in the GWAS catalog maintained by the National Human Genome Research Institute of USA3 (as of April 2015), revealing the common variants associated with SZ.4 The SZ Working Group of the Psychiatric Genomics Consortium (PGC) identified 108 genetic loci that likely confer risk for SZ.5 While the role of genetics has been clearly validated by this study, the functional impact of the risk variants is not well-understood.6,7 Several of the genes implicated by the GWAS have unknown functions and could participate in possibly hitherto unknown pathways.8 Further, there is little or no overlap between the genes identified through GWAS and ‘candidate genes’ proposed in the pre-GWAS era.9
Interactome-based studies can be useful in discovering the functional associations of genes. For example,disrupted in schizophrenia 1 (DISC1), an SZ related candidate gene originally had no known homolog in humans. Although it had well-characterized protein domains such as coiled-coil domains and leucine-zipper domains, its function was unknown.10,11 Once its protein–protein interactions (PPIs) were determined using yeast 2-hybrid technology,12 investigators successfully linked DISC1 to cAMP signaling, axon elongation, and neuronal migration, and accelerated the research pertaining to SZ in general, and DISC1 in particular.13 Typically such studies are carried out on known protein–protein interaction (PPI) networks, or as in the case of DISC1, when there is a specific gene of interest, its PPIs are determined by methods such as yeast 2-hybrid technology.
Knowledge of human PPI networks is thus valuable for accelerating discovery of protein function, and indeed, biomedical research in general. However, of the hundreds of thousands of biophysical PPIs thought to exist in the human interactome,14,15 <100,000 are known today (Human Protein Reference Database, HPRD16 and BioGRID17 databases). Gold standard experimental methods for the determination of all the PPIs in human interactome are time-consuming, expensive and may not even be feasible, as about 250 million pairs of proteins would need to be tested overall; high-throughput methods such as yeast 2-hybrid have important limitations for whole interactome determination as they have a low recall of 23% (i.e., remaining 77% of true interactions need to be determined by other means), and a low precision (i.e., the screens have to be repeated multiple times to achieve high selectivity).18,19Computational methods are therefore necessary to complete the interactome expeditiously. Algorithms have begun emerging to predict PPIs using statistical machine learning on the characteristics of the proteins, but these algorithms are employed predominantly to study yeast. Two significant computational predictions have been reported for human interactome; although they have had high false positive rates, these methods have laid the foundation for computational prediction of human PPIs.20,21
We have created a new PPI prediction model called High-Confidence Protein–Protein Interaction Prediction (HiPPIP) model. Novel interactions predicted with this model are making translational impact. For example, we discovered a PPI between OASL and DDX58, which on validation showed that an increased expression of OASL could boost innate immunity to combat influenza by activating the RIG-I pathway.22 Also, the interactome of the genes associated with congenital heart disease showed that the disease morphogenesis has a close connection with the structure and function of cilia.23Here, we describe the HiPPIP model and its application to SZ genes to construct the SZ interactome. After computational evaluations and experimental validations of selected novel PPIs, we present here 504 highly confident novel PPIs in the SZ interactome, shedding new light onto several uncharacterized genes that are associated with SZ.
We developed a computational model called HiPPIP to predict PPIs (see Methods and Supplementary File 1). The model has been evaluated by computational methods and experimental validations and is found to be highly accurate. Evaluations on a held-out test data showed a precision of 97.5% and a recall of 5%. 5% recall out of 150,000 to 600,000 estimated number of interactions in the human interactome corresponds to 7,500–30,000 novel PPIs in the whole interactome. Note that, it is likely that the real precision would be higher than 97.5% because in this test data, randomly paired proteins are treated as non-interacting protein pairs, whereas some of them may actually be interacting pairs with a small probability; thus, some of the pairs that are treated as false positives in test set are likely to be true but hitherto unknown interactions. In Figure 1a, we show the precision versus recall of our method on ‘hub proteins’ where we considered all pairs that received a score >0.5 by HiPPIP to be novel interactions. In Figure 1b, we show the number of true positives versus false positives observed in hub proteins. Both these figures also show our method to be superior in comparison to the prediction of membrane-receptor interactome by Qi et al’s.24 True positives versus false positives are also shown for individual hub proteins by our method in Figure 1cand by Qi et al’s.23 in Figure 1d. These evaluations showed that our predictions contain mostly true positives. Unlike in other domains where ranked lists are commonly used such as information retrieval, in PPI prediction the ‘false positives’ may actually be unlabeled instances that are indeed true interactions that are not yet discovered. In fact, such unlabeled pairs predicted as interactors of the hub gene HMGB1 (namely, the pairs HMGB1-KL and HMGB1-FLT1) were validated by experimental methods and found to be true PPIs (See the Figures e–g inSupplementary File 3). Thus, we concluded that the protein pairs that received a score of ⩾0.5 are highly confident to be true interactions. The pairs that receive a score less than but close to 0.5 (i.e., in the range of 0.4–0.5) may also contain several true PPIs; however, we cannot confidently say that all in this range are true PPIs. Only the PPIs predicted with a score >0.5 are included in the interactome.
Computational evaluation of predicted protein–protein interactions on hub proteins: (a) precision recall curve. (b) True positive versus false positives in ranked lists of hub type membrane receptors for our method and that by Qi et al. True positives versus false positives are shown for individual membrane receptors by our method in (c) and by Qi et al. in (d). Thick line is the average, which is also the same as shown in (b). Note:x-axis is recall in (a), whereas it is number of false positives in (b–d). The range of y-axis is observed by varying the threshold from 1.0–0 in (a), and to 0.5 in (b–d).
SZ interactome
By applying HiPPIP to the GWAS genes and Historic (pre-GWAS) genes, we predicted over 500 high confidence new PPIs adding to about 1400 previously known PPIs.
Schizophrenia interactome: network view of the schizophrenia interactome is shown as a graph, where genes are shown as nodes and PPIs as edges connecting the nodes. Schizophrenia-associated genes are shown as dark blue nodes, novel interactors as red color nodes and known interactors as blue color nodes. The source of the schizophrenia genes is indicated by its label font, where Historic genes are shown italicized, GWAS genes are shown in bold, and the one gene that is common to both is shown in italicized and bold. For clarity, the source is also indicated by the shape of the node (triangular for GWAS and square for Historic and hexagonal for both). Symbols are shown only for the schizophrenia-associated genes; actual interactions may be accessed on the web. Red edges are the novel interactions, whereas blue edges are known interactions. GWAS, genome-wide association studies of schizophrenia; PPI, protein–protein interaction.
We have made the known and novel interactions of all SZ-associated genes available on a webserver called Schizo-Pi, at the addresshttp://severus.dbmi.pitt.edu/schizo-pi. This webserver is similar to Wiki-Pi33 which presents comprehensive annotations of both participating proteins of a PPI side-by-side. The difference between Wiki-Pi which we developed earlier, and Schizo-Pi, is the inclusion of novel predicted interactions of the SZ genes into the latter.
Despite the many advances in biomedical research, identifying the molecular mechanisms underlying the disease is still challenging. Studies based on protein interactions were proven to be valuable in identifying novel gene associations that could shed new light on disease pathology.35 The interactome including more than 500 novel PPIs will help to identify pathways and biological processes associated with the disease and also its relation to other complex diseases. It also helps identify potential drugs that could be repurposed to use for SZ treatment.
Functional and pathway enrichment in SZ interactome
When a gene of interest has little known information, functions of its interacting partners serve as a starting point to hypothesize its own function. We computed statistically significant enrichment of GO biological process terms among the interacting partners of each of the genes using BinGO36 (see online at http://severus.dbmi.pitt.edu/schizo-pi).
Protein aggregation and aggregate toxicity: new insights into protein folding, misfolding diseases and biological evolution
Massimo Stefani · Christopher M. Dobson
Abstract The deposition of proteins in the form of amyloid fibrils and plaques is the characteristic feature of more than 20 degenerative conditions affecting either the central nervous system or a variety of peripheral tissues. As these conditions include Alzheimer’s, Parkinson’s and the prion diseases, several forms of fatal systemic amyloidosis, and at least one condition associated with medical intervention (haemodialysis), they are of enormous importance in the context of present-day human health and welfare. Much remains to be learned about the mechanism by which the proteins associated with these diseases aggregate and form amyloid structures, and how the latter affect the functions of the organs with which they are associated. A great deal of information concerning these diseases has emerged, however, during the past 5 years, much of it causing a number of fundamental assumptions about the amyloid diseases to be reexamined. For example, it is now apparent that the ability to form amyloid structures is not an unusual feature of the small number of proteins associated with these diseases but is instead a general property of polypeptide chains. It has also been found recently that aggregates of proteins not associated with amyloid diseases can impair the ability of cells to function to a similar extent as aggregates of proteins linked with specific neurodegenerative conditions. Moreover, the mature amyloid fibrils or plaques appear to be substantially less toxic than the prefibrillar aggregates that are their precursors. The toxicity of these early aggregates appears to result from an intrinsic ability to impair fundamental cellular processes by interacting with cellular membranes, causing oxidative stress and increases in free Ca2+ that eventually lead to apoptotic or necrotic cell death. The ‘new view’ of these diseases also suggests that other degenerative conditions could have similar underlying origins to those of the amyloidoses. In addition, cellular protection mechanisms, such as molecular chaperones and the protein degradation machinery, appear to be crucial in the prevention of disease in normally functioning living organisms. It also suggests some intriguing new factors that could be of great significance in the evolution of biological molecules and the mechanisms that regulate their behaviour.
The genetic information within a cell encodes not only the specific structures and functions of proteins but also the way these structures are attained through the process known as protein folding. In recent years many of the underlying features of the fundamental mechanism of this complex process and the manner in which it is regulated in living systems have emerged from a combination of experimental and theoretical studies [1]. The knowledge gained from these studies has also raised a host of interesting issues. It has become apparent, for example, that the folding and unfolding of proteins is associated with a whole range of cellular processes from the trafficking of molecules to specific organelles to the regulation of the cell cycle and the immune response. Such observations led to the inevitable conclusion that the failure to fold correctly, or to remain correctly folded, gives rise to many different types of biological malfunctions and hence to many different forms of disease [2]. In addition, it has been recognised recently that a large number of eukaryotic genes code for proteins that appear to be ‘natively unfolded’, and that proteins can adopt, under certain circumstances, highly organised multi-molecular assemblies whose structures are not specifically encoded in the amino acid sequence. Both these observations have raised challenging questions about one of the most fundamental principles of biology: the close relationship between the sequence, structure and function of proteins, as we discuss below [3].
It is well established that proteins that are ‘misfolded’, i.e. that are not in their functionally relevant conformation, are devoid of normal biological activity. In addition, they often aggregate and/or interact inappropriately with other cellular components leading to impairment of cell viability and eventually to cell death. Many diseases, often known as misfolding or conformational diseases, ultimately result from the presence in a living system of protein molecules with structures that are ‘incorrect’, i.e. that differ from those in normally functioning organisms [4]. Such diseases include conditions in which a specific protein, or protein complex, fails to fold correctly (e.g. cystic fibrosis, Marfan syndrome, amyotonic lateral sclerosis) or is not sufficiently stable to perform its normal function (e.g. many forms of cancer). They also include conditions in which aberrant folding behaviour results in the failure of a protein to be correctly trafficked (e.g. familial hypercholesterolaemia, α1-antitrypsin deficiency, and some forms of retinitis pigmentosa) [4]. The tendency of proteins to aggregate, often to give species extremely intractable to dissolution and refolding, is of course also well known in other circumstances. Examples include the formation of inclusion bodies during overexpression of heterologous proteins in bacteria and the precipitation of proteins during laboratory purification procedures. Indeed, protein aggregation is well established as one of the major difficulties associated with the production and handling of proteins in the biotechnology and pharmaceutical industries [5].
Considerable attention is presently focused on a group of protein folding diseases known as amyloidoses. In these diseases specific peptides or proteins fail to fold or to remain correctly folded and then aggregate (often with other components) so as to give rise to ‘amyloid’ deposits in tissue. Amyloid structures can be recognised because they possess a series of specific tinctorial and biophysical characteristics that reflect a common core structure based on the presence of highly organised βsheets [6]. The deposits in strictly defined amyloidoses are extracellular and can often be observed as thread-like fibrillar structures, sometimes assembled further into larger aggregates or plaques. These diseases include a range of sporadic, familial or transmissible degenerative diseases, some of which affect the brain and the central nervous system (e.g. Alzheimer’s and Creutzfeldt-Jakob diseases), while others involve peripheral tissues and organs such as the liver, heart and spleen (e.g. systemic amyloidoses and type II diabetes) [7, 8]. In other forms of amyloidosis, such as primary or secondary systemic amyloidoses, proteinaceous deposits are found in skeletal tissue and joints (e.g. haemodialysis-related amyloidosis) as well as in several organs (e.g. heart and kidney). Yet other components such as collagen, glycosaminoglycans and proteins (e.g. serum amyloid protein) are often present in the deposits protecting them against degradation [9, 10, 11]. Similar deposits to those in the amyloidoses are, however, found intracellularly in other diseases; these can be localised either in the cytoplasm, in the form of specialised aggregates known as aggresomes or as Lewy or Russell bodies or in the nucleus (see below).
The presence in tissue of proteinaceous deposits is a hallmark of all these diseases, suggesting a causative link between aggregate formation and pathological symptoms (often known as the amyloid hypothesis) [7, 8, 12]. At the present time the link between amyloid formation and disease is widely accepted on the basis of a large number of biochemical and genetic studies. The specific nature of the pathogenic species, and the molecular basis of their ability to damage cells, are however, the subject of intense debate [13, 14, 15, 16, 17, 18, 19, 20]. In neurodegenerative disorders it is very likely that the impairment of cellular function follows directly from the interactions of the aggregated proteins with cellular components [21, 22]. In the systemic non-neurological diseases, however, it is widely believed that the accumulation in vital organs of large amounts of amyloid deposits can by itself cause at least some of the clinical symptoms [23]. It is quite possible, however, that there are other more specific effects of aggregates on biochemical processes even in these diseases. The presence of extracellular or intracellular aggregates of a specific polypeptide molecule is a characteristic of all the 20 or so recognised amyloid diseases. The polypeptides involved include full length proteins (e.g. lysozyme or immunoglobulin light chains), biological peptides (amylin, atrial natriuretic factor) and fragments of larger proteins produced as a result of specific processing (e.g. the Alzheimer βpeptide) or of more general degradation [e.g. poly(Q) stretches cleaved from proteins with poly(Q) extensions such as huntingtin, ataxins and the androgen receptor]. The peptides and proteins associated with known amyloid diseases are listed in Table 1. In some cases the proteins involved have wild type sequences, as in sporadic forms of the diseases, but in other cases these are variants resulting from genetic mutations associated with familial forms of the diseases. In some cases both sporadic and familial diseases are associated with a given protein; in this case the mutational variants are usually associated with early-onset forms of the disease. In the case of the neurodegenerative diseases associated with the prion protein some forms of the diseases are transmissible. The existence of familial forms of a number of amyloid diseases has provided significant clues to the origins of the pathologies. For example, there are increasingly strong links between the age at onset of familial forms of disease and the effects of the mutations involved on the propensity of the affected proteins to aggregate in vitro. Such findings also support the link between the process of aggregation and the clinical manifestations of disease [24, 25].
The presence in cells of misfolded or aggregated proteins triggers a complex biological response. In the cytosol, this is referred to as the ‘heat shock response’ and in the endoplasmic reticulum (ER) it is known as the ‘unfolded protein response’. These responses lead to the expression, among others, of the genes for heat shock proteins (Hsp, or molecular chaperone proteins) and proteins involved in the ubiquitin-proteasome pathway [26]. The evolution of such complex biochemical machinery testifies to the fact that it is necessary for cells to isolate and clear rapidly and efficiently any unfolded or incorrectly folded protein as soon as it appears. In itself this fact suggests that these species could have a generally adverse effect on cellular components and cell viability. Indeed, it was a major step forward in understanding many aspects of cell biology when it was recognised that proteins previously associated only with stress, such as heat shock, are in fact crucial in the normal functioning of living systems. This advance, for example, led to the discovery of the role of molecular chaperones in protein folding and in the normal ‘housekeeping’ processes that are inherent in healthy cells [27, 28]. More recently a number of degenerative diseases, both neurological and systemic, have been linked to, or shown to be affected by, impairment of the ubiquitin-proteasome pathway (Table 2). The diseases are primarily associated with a reduction in either the expression or the biological activity of Hsps, ubiquitin, ubiquitinating or deubiquitinating enzymes and the proteasome itself, as we show below [29, 30, 31, 32], or even to the failure of the quality control mechanisms that ensure proper maturation of proteins in the ER. The latter normally leads to degradation of a significant proportion of polypeptide chains before they have attained their native conformations through retrograde translocation to the cytosol [33, 34].
….
It is now well established that the molecular basis of protein aggregation into amyloid structures involves the existence of ‘misfolded’ forms of proteins, i.e. proteins that are not in the structures in which they normally function in vivo or of fragments of proteins resulting from degradation processes that are inherently unable to fold [4, 7, 8, 36]. Aggregation is one of the common consequences of a polypeptide chain failing to reach or maintain its functional three-dimensional structure. Such events can be associated with specific mutations, misprocessing phenomena, aberrant interactions with metal ions, changes in environmental conditions, such as pH or temperature, or chemical modification (oxidation, proteolysis). Perturbations in the conformational properties of the polypeptide chain resulting from such phenomena may affect equilibrium 1 in Fig. 1 increasing the population of partially unfolded, or misfolded, species that are much more aggregation-prone than the native state.
Fig. 1 Overview of the possible fates of a newly synthesised polypeptide chain. The equilibrium ① between the partially folded molecules and the natively folded ones is usually strongly in favour of the latter except as a result of specific mutations, chemical modifications or partially destabilising solution conditions. The increased equilibrium populations of molecules in the partially or completely unfolded ensemble of structures are usually degraded by the proteasome; when this clearance mechanism is impaired, such species often form disordered aggregates or shift equilibrium ② towards the nucleation of pre-fibrillar assemblies that eventually grow into mature fibrils (equilibrium ③). DANGER! indicates that pre-fibrillar aggregates in most cases display much higher toxicity than mature fibrils. Heat shock proteins (Hsp) can suppress the appearance of pre-fibrillar assemblies by minimising the population of the partially folded molecules by assisting in the correct folding of the nascent chain and the unfolded protein response target incorrectly folded proteins for degradation.
……
Little is known at present about the detailed arrangement of the polypeptide chains themselves within amyloid fibrils, either those parts involved in the core βstrands or in regions that connect the various β-strands. Recent data suggest that the sheets are relatively untwisted and may in some cases at least exist in quite specific supersecondary structure motifs such as β-helices [6, 40] or the recently proposed µ-helix [41]. It seems possible that there may be significant differences in the way the strands are assembled depending on characteristics of the polypeptide chain involved [6, 42]. Factors including length, sequence (and in some cases the presence of disulphide bonds or post-translational modifications such as glycosylation) may be important in determining details of the structures. Several recent papers report structural models for amyloid fibrils containing different polypeptide chains, including the Aβ40 peptide, insulin and fragments of the prion protein, based on data from such techniques as cryo-electron microscopy and solid-state magnetic resonance spectroscopy [43, 44]. These models have much in common and do indeed appear to reflect the fact that the structures of different fibrils are likely to be variations on a common theme [40]. It is also emerging that there may be some common and highly organised assemblies of amyloid protofilaments that are not simply extended threads or ribbons. It is clear, for example, that in some cases large closed loops can be formed [45, 46, 47], and there may be specific types of relatively small spherical or ‘doughnut’ shaped structures that can result in at least some circumstances (see below).
…..
The similarity of some early amyloid aggregates with the pores resulting from oligomerisation of bacterial toxins and pore-forming eukaryotic proteins (see below) also suggest that the basic mechanism of protein aggregation into amyloid structures may not only be associated with diseases but in some cases could result in species with functional significance. Recent evidence indicates that a variety of micro-organisms may exploit the controlled aggregation of specific proteins (or their precursors) to generate functional structures. Examples include bacterial curli [52] and proteins of the interior fibre cells of mammalian ocular lenses, whose β-sheet arrays seem to be organised in an amyloid-like supramolecular order [53]. In this case the inherent stability of amyloid-like protein structure may contribute to the long-term structural integrity and transparency of the lens. Recently it has been hypothesised that amyloid-like aggregates of serum amyloid A found in secondary amyloidoses following chronic inflammatory diseases protect the host against bacterial infections by inducing lysis of bacterial cells [54]. One particularly interesting example is a ‘misfolded’ form of the milk protein α-lactalbumin that is formed at low pH and trapped by the presence of specific lipid molecules [55]. This form of the protein has been reported to trigger apoptosis selectively in tumour cells providing evidence for its importance in protecting infants from certain types of cancer [55]. ….
Amyloid formation is a generic property of polypeptide chains ….
It is clear that the presence of different side chains can influence the details of amyloid structures, particularly the assembly of protofibrils, and that they give rise to the variations on the common structural theme discussed above. More fundamentally, the composition and sequence of a peptide or protein affects profoundly its propensity to form amyloid structures under given conditions (see below).
Because the formation of stable protein aggregates of amyloid type does not normally occur in vivo under physiological conditions, it is likely that the proteins encoded in the genomes of living organisms are endowed with structural adaptations that mitigate against aggregation under these conditions. A recent survey involving a large number of structures of β-proteins highlights several strategies through which natural proteins avoid intermolecular association of β-strands in their native states [65]. Other surveys of protein databases indicate that nature disfavours sequences of alternating polar and nonpolar residues, as well as clusters of several consecutive hydrophobic residues, both of which enhance the tendency of a protein to aggregate prior to becoming completely folded [66, 67].
……
Precursors of amyloid fibrils can be toxic to cells
It was generally assumed until recently that the proteinaceous aggregates most toxic to cells are likely to be mature amyloid fibrils, the form of aggregates that have been commonly detected in pathological deposits. It therefore appeared probable that the pathogenic features underlying amyloid diseases are a consequence of the interaction with cells of extracellular deposits of aggregated material. As well as forming the basis for understanding the fundamental causes of these diseases, this scenario stimulated the exploration of therapeutic approaches to amyloidoses that focused mainly on the search for molecules able to impair the growth and deposition of fibrillar forms of aggregated proteins. ….
Structural basis and molecular features of amyloid toxicity
The presence of toxic aggregates inside or outside cells can impair a number of cell functions that ultimately lead to cell death by an apoptotic mechanism [95, 96]. Recent research suggests, however, that in most cases initial perturbations to fundamental cellular processes underlie the impairment of cell function induced by aggregates of disease-associated polypeptides. Many pieces of data point to a central role of modifications to the intracellular redox status and free Ca2+ levels in cells exposed to toxic aggregates [45, 89, 97, 98, 99, 100, 101]. A modification of the intracellular redox status in such cells is associated with a sharp increase in the quantity of reactive oxygen species (ROS) that is reminiscent of the oxidative burst by which leukocytes destroy invading foreign cells after phagocytosis. In addition, changes have been observed in reactive nitrogen species, lipid peroxidation, deregulation of NO metabolism [97], protein nitrosylation [102] and upregulation of heme oxygenase-1, a specific marker of oxidative stress [103]. ….
Results have recently been reported concerning the toxicity towards cultured cells of aggregates of poly(Q) peptides which argues against a disease mechanism based on specific toxic features of the aggregates. These results indicate that there is a close relationship between the toxicity of proteins with poly(Q) extensions and their nuclear localisation. In addition they support the hypotheses that the toxicity of poly(Q) aggregates can be a consequence of altered interactions with nuclear coactivator or corepressor molecules including p53, CBP, Sp1 and TAF130 or of the interaction with transcription factors and nuclear coactivators, such as CBP, endowed with short poly(Q) stretches ([95] and references therein)…..
Concluding remarks
The data reported in the past few years strongly suggest that the conversion of normally soluble proteins into amyloid fibrils and the toxicity of small aggregates appearing during the early stages of the formation of the latter are common or generic features of polypeptide chains. Moreover, the molecular basis of this toxicity also appears to display common features between the different systems that have so far been studied. The ability of many, perhaps all, natural polypeptides to ‘misfold’ and convert into toxic aggregates under suitable conditions suggests that one of the most important driving forces in the evolution of proteins must have been the negative selection against sequence changes that increase the tendency of a polypeptide chain to aggregate. Nevertheless, as protein folding is a stochastic process, and no such process can be completely infallible, misfolded proteins or protein folding intermediates in equilibrium with the natively folded molecules must continuously form within cells. Thus mechanisms to deal with such species must have co-evolved with proteins. Indeed, it is clear that misfolding, and the associated tendency to aggregate, is kept under control by molecular chaperones, which render the resulting species harmless assisting in their refolding, or triggering their degradation by the cellular clearance machinery [166, 167, 168, 169, 170, 171, 172, 173, 175, 177, 178].
Misfolded and aggregated species are likely to owe their toxicity to the exposure on their surfaces of regions of proteins that are buried in the interior of the structures of the correctly folded native states. The exposure of large patches of hydrophobic groups is likely to be particularly significant as such patches favour the interaction of the misfolded species with cell membranes [44, 83, 89, 90, 91, 93]. Interactions of this type are likely to lead to the impairment of the function and integrity of the membranes involved, giving rise to a loss of regulation of the intracellular ion balance and redox status and eventually to cell death. In addition, misfolded proteins undoubtedly interact inappropriately with other cellular components, potentially giving rise to the impairment of a range of other biological processes. Under some conditions the intracellular content of aggregated species may increase directly, due to an enhanced propensity of incompletely folded or misfolded species to aggregate within the cell itself. This could occur as the result of the expression of mutational variants of proteins with decreased stability or cooperativity or with an intrinsically higher propensity to aggregate. It could also occur as a result of the overproduction of some types of protein, for example, because of other genetic factors or other disease conditions, or because of perturbations to the cellular environment that generate conditions favouring aggregation, such as heat shock or oxidative stress. Finally, the accumulation of misfolded or aggregated proteins could arise from the chaperone and clearance mechanisms becoming overwhelmed as a result of specific mutant phenotypes or of the general effects of ageing [173, 174].
The topics discussed in this review not only provide a great deal of evidence for the ‘new view’ that proteins have an intrinsic capability of misfolding and forming structures such as amyloid fibrils but also suggest that the role of molecular chaperones is even more important than was thought in the past. The role of these ubiquitous proteins in enhancing the efficiency of protein folding is well established [185]. It could well be that they are at least as important in controlling the harmful effects of misfolded or aggregated proteins as in enhancing the yield of functional molecules.
Nutritional Status is Associated with Faster Cognitive Decline and Worse Functional Impairment in the Progression of Dementia: The Cache County Dementia Progression Study1
Nutritional status may be a modifiable factor in the progression of dementia. We examined the association of nutritional status and rate of cognitive and functional decline in a U.S. population-based sample. Study design was an observational longitudinal study with annual follow-ups up to 6 years of 292 persons with dementia (72% Alzheimer’s disease, 56% female) in Cache County, UT using the Mini-Mental State Exam (MMSE), Clinical Dementia Rating Sum of Boxes (CDR-sb), and modified Mini Nutritional Assessment (mMNA). mMNA scores declined by approximately 0.50 points/year, suggesting increasing risk for malnutrition. Lower mMNA score predicted faster rate of decline on the MMSE at earlier follow-up times, but slower decline at later follow-up times, whereas higher mMNA scores had the opposite pattern (mMNA by time β= 0.22, p = 0.017; mMNA by time2 β= –0.04, p = 0.04). Lower mMNA score was associated with greater impairment on the CDR-sb over the course of dementia (β= 0.35, p < 0.001). Assessment of malnutrition may be useful in predicting rates of progression in dementia and may provide a target for clinical intervention.
Shared Genetic Risk Factors for Late-Life Depression and Alzheimer’s Disease
Background: Considerable evidence has been reported for the comorbidity between late-life depression (LLD) and Alzheimer’s disease (AD), both of which are very common in the general elderly population and represent a large burden on the health of the elderly. The pathophysiological mechanisms underlying the link between LLD and AD are poorly understood. Because both LLD and AD can be heritable and are influenced by multiple risk genes, shared genetic risk factors between LLD and AD may exist. Objective: The objective is to review the existing evidence for genetic risk factors that are common to LLD and AD and to outline the biological substrates proposed to mediate this association. Methods: A literature review was performed. Results: Genetic polymorphisms of brain-derived neurotrophic factor, apolipoprotein E, interleukin 1-beta, and methylenetetrahydrofolate reductase have been demonstrated to confer increased risk to both LLD and AD by studies examining either LLD or AD patients. These results contribute to the understanding of pathophysiological mechanisms that are common to both of these disorders, including deficits in nerve growth factors, inflammatory changes, and dysregulation mechanisms involving lipoprotein and folate. Other conflicting results have also been reviewed, and few studies have investigated the effects of the described polymorphisms on both LLD and AD. Conclusion: The findings suggest that common genetic pathways may underlie LLD and AD comorbidity. Studies to evaluate the genetic relationship between LLD and AD may provide insights into the molecular mechanisms that trigger disease progression as the population ages.
Association of Vitamin B12, Folate, and Sulfur Amino Acids With Brain Magnetic Resonance Imaging Measures in Older Adults: A Longitudinal Population-Based Study
Importance Vitamin B12, folate, and sulfur amino acids may be modifiable risk factors for structural brain changes that precede clinical dementia.
Objective To investigate the association of circulating levels of vitamin B12, red blood cell folate, and sulfur amino acids with the rate of total brain volume loss and the change in white matter hyperintensity volume as measured by fluid-attenuated inversion recovery in older adults.
Design, Setting, and Participants The magnetic resonance imaging subsample of the Swedish National Study on Aging and Care in Kungsholmen, a population-based longitudinal study in Stockholm, Sweden, was conducted in 501 participants aged 60 years or older who were free of dementia at baseline. A total of 299 participants underwent repeated structural brain magnetic resonance imaging scans from September 17, 2001, to December 17, 2009.
Main Outcomes and Measures The rate of brain tissue volume loss and the progression of total white matter hyperintensity volume.
Results In the multi-adjusted linear mixed models, among 501 participants (300 women [59.9%]; mean [SD] age, 70.9 [9.1] years), higher baseline vitamin B12 and holotranscobalamin levels were associated with a decreased rate of total brain volume loss during the study period: for each increase of 1 SD, β (SE) was 0.048 (0.013) for vitamin B12 (P < .001) and 0.040 (0.013) for holotranscobalamin (P = .002). Increased total homocysteine levels were associated with faster rates of total brain volume loss in the whole sample (β [SE] per 1-SD increase, –0.035 [0.015]; P = .02) and with the progression of white matter hyperintensity among participants with systolic blood pressure greater than 140 mm Hg (β [SE] per 1-SD increase, 0.000019 [0.00001]; P = .047). No longitudinal associations were found for red blood cell folate and other sulfur amino acids.
Conclusions and Relevance This study suggests that both vitamin B12 and total homocysteine concentrations may be related to accelerated aging of the brain. Randomized clinical trials are needed to determine the importance of vitamin B12supplementation on slowing brain aging in older adults.
Notes from Kurzweill
This vitamin stops the aging process in organs, say Swiss researchers
A potential breakthrough for regenerative medicine, pending further studies
Improved muscle stem cell numbers and muscle function in NR-treated aged mice: Newly regenerated muscle fibers 7 days after muscle damage in aged mice (left: control group; right: fed NR). (Scale bar = 50 μm). (credit: Hongbo Zhang et al./Science) http://www.kurzweilai.net/images/improved-muscle-fibers.png
EPFL researchers have restored the ability of mice organs to regenerate and extend life by simply administering nicotinamide riboside (NR) to them.
NR has been shown in previous studies to be effective in boosting metabolism and treating a number of degenerative diseases. Now, an article by PhD student Hongbo Zhang published in Science also describes the restorative effects of NR on the functioning of stem cells for regenerating organs.
As in all mammals, as mice age, the regenerative capacity of certain organs (such as the liver and kidneys) and muscles (including the heart) diminishes. Their ability to repair them following an injury is also affected. This leads to many of the disorders typical of aging.
Mitochondria —> stem cells —> organs
To understand how the regeneration process deteriorates with age, Zhang teamed up with colleagues from ETH Zurich, the University of Zurich, and universities in Canada and Brazil. By using several biomarkers, they were able to identify the molecular chain that regulates how mitochondria — the “powerhouse” of the cell — function and how they change with age. “We were able to show for the first time that their ability to function properly was important for stem cells,” said Auwerx.
Under normal conditions, these stem cells, reacting to signals sent by the body, regenerate damaged organs by producing new specific cells. At least in young bodies. “We demonstrated that fatigue in stem cells was one of the main causes of poor regeneration or even degeneration in certain tissues or organs,” said Zhang.
How to revitalize stem cells
Which is why the researchers wanted to “revitalize” stem cells in the muscles of elderly mice. And they did so by precisely targeting the molecules that help the mitochondria to function properly. “We gave nicotinamide riboside to 2-year-old mice, which is an advanced age for them,” said Zhang.
“This substance, which is close to vitamin B3, is a precursor of NAD+, a molecule that plays a key role in mitochondrial activity. And our results are extremely promising: muscular regeneration is much better in mice that received NR, and they lived longer than the mice that didn’t get it.”
Parallel studies have revealed a comparable effect on stem cells of the brain and skin. “This work could have very important implications in the field of regenerative medicine,” said Auwerx. This work on the aging process also has potential for treating diseases that can affect — and be fatal — in young people, like muscular dystrophy (myopathy).
So far, no negative side effects have been observed following the use of NR, even at high doses. But while it appears to boost the functioning of all cells, it could include pathological ones, so further in-depth studies are required.
Abstract of NAD+ repletion improves mitochondrial and stem cell function and enhances life span in mice
Adult stem cells (SCs) are essential for tissue maintenance and regeneration yet are susceptible to senescence during aging. We demonstrate the importance of the amount of the oxidized form of cellular nicotinamide adenine dinucleotide (NAD+) and its impact on mitochondrial activity as a pivotal switch to modulate muscle SC (MuSC) senescence. Treatment with the NAD+ precursor nicotinamide riboside (NR) induced the mitochondrial unfolded protein response (UPRmt) and synthesis of prohibitin proteins, and this rejuvenated MuSCs in aged mice. NR also prevented MuSC senescence in the Mdx mouse model of muscular dystrophy. We furthermore demonstrate that NR delays senescence of neural SCs (NSCs) and melanocyte SCs (McSCs), and increased mouse lifespan. Strategies that conserve cellular NAD+ may reprogram dysfunctional SCs and improve lifespan in mammals.
Discriminating the gene target of a distal regulatory element from other nearby transcribed genes is a challenging problem with the potential to illuminate the causal underpinnings of complex diseases. We present TargetFinder, a computational method that reconstructs regulatory landscapes from diverse features along the genome. The resulting models accurately predict individual enhancer–promoter interactions across multiple cell lines with a false discovery rate up to 15 times smaller than that obtained using the closest gene. By evaluating the genomic features driving this accuracy, we uncover interactions between structural proteins, transcription factors, epigenetic modifications, and transcription that together distinguish interacting from non-interacting enhancer–promoter pairs. Most of this signature is not proximal to the enhancers and promoters but instead decorates the looping DNA. We conclude that complex but consistent combinations of marks on the one-dimensional genome encode the three-dimensional structure of fine-scale regulatory interactions.
A little adversity builds character, or so the saying goes. True or not, the saying does seem an apt description of a developmental phenomenon that shapes gene expression. While it knows nothing of character, the gene expression apparatus appears to respond well to short-term mitochondrial stress that occurs early in development. In fact, transient stress seems to result in lasting benefits. These benefits, which include improved metabolic function and increased longevity, have been observed in both worms and mice, and may even occur—or be made to occur—in humans.
Gene expression is known to be subject to reprogramming by epigenetic modifiers, but such modifiers generally affect metabolism or lifespan, not both. A new set of epigenetic modifiers, however, has been found to trigger changes that do just that—both improve metabolism and extend lifespan.
Scientists based at the University of California, Berkeley, and the École Polytechnique Fédérale de Lausanne (EPFL) have discovered enzymes that are ramped up after mild stress during early development and continue to affect the expression of genes throughout the animal’s life. When the scientists looked at strains of inbred mice that have radically different lifespans, those with the longest lifespans had significantly higher expression of these enzymes than did the short-lived mice.
“Two of the enzymes we discovered are highly, highly correlated with lifespan; it is the biggest genetic correlation that has ever been found for lifespan in mice, and they’re both naturally occurring variants,” said Andrew Dillin, a UC Berkeley professor of molecular and cell biology. “Based on what we see in worms, boosting these enzymes could reprogram your metabolism to create better health, with a possible side effect of altering lifespan.”
Details of the work, which appeared online April 29 in the journal Cell, are presented in a pair of papers. One paper (“Two Conserved Histone Demethylases Regulate Mitochondrial Stress-Induced Longevity”) resulted from an effort led by Dillin and the EPFL’s Johan Auwerx. The other paper (“Mitochondrial Stress Induces Chromatin Reorganization to Promote Longevity and UPRmt”) resulted from an effort led by Dillin and his UC Berkeley colleague Barbara Meyer.
According to these papers, mitochondrial stress activates enzymes in the brain that affect DNA folding, exposing a segment of DNA that contains the 1500 genes involved in the work of the mitochondria. A second set of enzymes then tags these genes, affecting their activation for much or all of the lifetime of the animal and causing permanent changes in how the mitochondria generates energy.
The first set of enzymes—methylases, in particular LIN-65—add methyl groups to the DNA, which can silence promoters and thus suppress gene expression. By also opening up the mitochondrial genes, these methylases set the stage for the second set of enzymes—demethylases, in this case jmjd-1.2 and jmjd-3.1—to ramp up transcription of the mitochondrial genes. When the researchers artificially increased production of the demethylases in worms, all the worms lived longer, a result identical to what is observed after mitochondrial stress.
“By changing the epigenetic state, these enzymes are able to switch genes on and off,” Dillin noted. This happens only in the brain of the worm, however, in areas that sense hunger or satiety. “These genes are expressed in neurons that are sensing the nutritional status of the animal, and these signals emanate out to the periphery to change peripheral metabolism,” he continued.
When the scientists profiled enzymes in short- and long-lived mice, they found upregulation of these genes in the brains of long-lived mice, but not in other tissues or in the brains of short-lived mice. “These genes are expressed in the hypothalamus, exactly where, when you eat, the signals are generated that tell you that you are full. And when you are hungry, signals in that region tell you to go and eat,” Dillin explained said. “These genes are all involved in peripheral feedback.”
Among the mitochondrial genes activated by these enzymes are those involved in the body’s response to proteins that unfold, which is a sign of stress. Increased activity of the proteins that refold other proteins is another hallmark of longer life.
These observations suggest that the reversal of aging by epigenetic enzymes could also take place in humans.
“It seems that, while extreme metabolic stress can lead to problems later in life, mild stress early in development says to the body, ‘Whoa, things are a little bit off-kilter here, let’s try to repair this and make it better.’ These epigenetic switches keep this up for the rest of the animal’s life,” Dillin stated.
Two Conserved Histone Demethylases Regulate Mitochondrial Stress-Induced Longevity
Carsten Merkwirth6, Virginija Jovaisaite6, Jenni Durieux,…., Reuben J. Shaw, Johan Auwerx, Andrew Dillin
•H3K27 demethylases jmjd-1.2 and jmjd-3.1 are required for ETC-mediated longevity
•jmjd-1.2 and jmjd-3.1 extend lifespan and are sufficient for UPRmt activation
•UPRmt is required for increased lifespan due to jmjd-1.2 or jmjd-3.1 overexpression
•JMJD expression is correlated with UPRmt and murine lifespan in inbred BXD lines
Across eukaryotic species, mild mitochondrial stress can have beneficial effects on the lifespan of organisms. Mitochondrial dysfunction activates an unfolded protein response (UPRmt), a stress signaling mechanism designed to ensure mitochondrial homeostasis. Perturbation of mitochondria during larval development in C. elegans not only delays aging but also maintains UPRmt signaling, suggesting an epigenetic mechanism that modulates both longevity and mitochondrial proteostasis throughout life. We identify the conserved histone lysine demethylases jmjd-1.2/PHF8 and jmjd-3.1/JMJD3 as positive regulators of lifespan in response to mitochondrial dysfunction across species. Reduction of function of the demethylases potently suppresses longevity and UPRmt induction, while gain of function is sufficient to extend lifespan in a UPRmt-dependent manner. A systems genetics approach in the BXD mouse reference population further indicates conserved roles of the mammalian orthologs in longevity and UPRmt signaling. These findings illustrate an evolutionary conserved epigenetic mechanism that determines the rate of aging downstream of mitochondrial perturbations.
Mitochondrial Stress Induces Chromatin Reorganization to Promote Longevity and UPRmt
Ye Tian, Gilberto Garcia, Qian Bian, Kristan K. Steffen, Larry Joe, Suzanne Wolff, Barbara J. Meyer, Andrew Dillin
•LIN-65 accumulates in the nucleus in response to mitochondrial stress
•Mitochondrial stress-induced chromatin changes depend on MET-2 and LIN-65
•LIN-65 and DVE-1 exhibit interdependence in nuclear accumulation
•met-2 and atfs-1 act in parallel to affect mitochondrial stress-induced longevity
Organisms respond to mitochondrial stress through the upregulation of an array of protective genes, often perpetuating an early response to metabolic dysfunction across a lifetime. We find that mitochondrial stress causes widespread changes in chromatin structure through histone H3K9 di-methylation marks traditionally associated with gene silencing. Mitochondrial stress response activation requires the di-methylation of histone H3K9 through the activity of the histone methyltransferase met-2 and the nuclear co-factor lin-65. While globally the chromatin becomes silenced by these marks, remaining portions of the chromatin open up, at which point the binding of canonical stress responsive factors such as DVE-1 occurs. Thus, a metabolic stress response is established and propagated into adulthood of animals through specific epigenetic modifications that allow for selective gene expression and lifespan extension
Siddharta Mukherjee’s Writing Career Just Got Dealt a Sucker Punch
Siddharha Mukherjee won the 2011 Pulitzer Prize in non-fiction for his book, The Emperor of All Maladies. The book has received widespread acclaim among lay audience, physicians, and scientists alike. Last year the book was turned into a special PBS series. But, according to a slew of scientists, we should all be skeptical of his next book scheduled to hit book shelves this month, The Gene, An Intimate History.
Publishing an article on epigenetics in the New Yorker this week–perhaps a selection from his new book–Mukherjee has waltzed into one of the most active scientific debates in all of biology: that of gene regulation, or epigenetics.
Jerry Coyne, the evolutionary biologist known for keeping journalists honest, has published a two part critique of Mukherjee’s New Yorker piece. The first part–wildly tweeted yesterday–is a list of quotes from Coyne’s colleagues and those who have written in to the New Yorker, including two Nobel prize winners, Wally Gilbert and Sidney Altman, offering some very unfriendly sentences.
Wally Gilbert: “The New Yorker article is so wildly wrong that it defies rational analysis.”
Sidney Altman: “I am not aware that there is such a thing as an epigenetic code. It is unfortunate to inflict this article, without proper scientific review, on the audience of the New Yorker.”
The second part is a thorough scientific rebuttal of the Mukherjee piece. It all serves as a great drama about one of the most contested ideas in biology and also as a cautionary tale to journalists, even experienced writers such as Mukherjee, about the dangers of wading into scientific arguments. Readers may remember that a few years ago, science writer, David Dobbs, similarly skated into the same topic with his piece, Die, Selfish Gene, Die, and which raised a similar shitstorm, much of it from Coyne.
Mukherjee’s mistake is in giving credence to only one side of a very fierce debate–that the environment causes changes in the genome which can be passed on; another kind of evolution–as though it were settled science. Either Mukherjee, a physicisan coming off from a successful book and PBS miniseries on cancer, is setting himself up as a scientist, or he has been a truly naive science reporter. If he got this chapter so wrong, what does it mean about an entire book on the gene?
Coyne quotes one of his colleagues who raised some questions about the New Yorker’s science reporting, one particular question we’ve been asking here at Mendelspod. How do we know what we know? Does science now have an edge on any other discipline for being able to create knowledge?
Coyne’s colleague is troubled by science coverage in the New Yorker, and goes so far as to write that the New Yorker has been waging a “war on behalf of cultural critics and literary intellectuals against scientists and technologists.”
From my experience, it’s not quite that tidy. First of all, the New Yorker is the best writing I read each week. Period. Second, I haven’t found their science writing to have the slant claimed in the quote above. For example, most other mainstream outlets–including the New York Times with the Amy Harmon pieces–have given the anti-GMO crowd an equal say in the mistaken search for a “balance” on whether GMOs are harmful. (Remember John Stewart’s criticism of Fox News? That they give a false equivalent between two sides even when there is no equivalent on the other side?)
But the New Yorker has not fallen into this trap on GMOs and most of their pieces on the topic–mainly by Michael Specter–have been decidedly pro science and therefore decided pro GMO.
So what led Mukherjee to play scientist as well as journalist? There’s no question about whether I enjoy his prose. His writing beautifully whisks me away so that I don’t feel that I’m really working to understand. There is a poetic complexity that constantly brings different threads effortlessly together, weaving them into the same light. At one point he uses the metaphor of a web for the genome, with the epigenome being the stuff that sticks to the web. He borrows the metaphor from the Hindu notion of “being”, or jaal.
“Genes form the threads of the web; the detritus that adheres to it transforms every web into a singular being.”
There have been a few writers on Twitter defending Mukherjee’s piece. Tech Review’s Antonio Regalado called Coyne and his colleagues “tedious literalists” who have an “issue with epigenetic poetry.”
At his best, Mukherjee can take us down the sweet alleys of his metaphors and family stories with a new curiosity for the scientific truth. He can hold a mirror up to scientists, or put the spotlight on their work. At their worst, Coyne and his scientific colleagues can reek of a fear of language and therefore metaphor. The always outspoken scientist and author, Richard Dawkins, who made his name by personifying the gene, was quick to personify epigentics in a tweet: “It’s high time the 15 minutes of underserved fame for “epigenetics” came to an overdue end.” Dawkins is that rare scientist who has consistently been as comfortable with rhetoric and language as he is with data.
Hats off to Coyne who reminds us that a metaphor–however lovely–does not some science make. If Mukherjee wants to play scientist, let him create and gather data. If it’s the role of science journalist he wants, let him collect all the science he can before he begins to pour it into his poetry.
Same but Different
How epigenetics can blur the line between nature and nurture.
The author’s mother (right) and her twin are a study in difference and identity. CREDIT: PHOTOGRAPH BY DAYANITA SINGH FOR THE NEW YORKER
October 6, 1942, my mother was born twice in Delhi. Bulu, her identical twin, came first, placid and beautiful. My mother, Tulu, emerged several minutes later, squirming and squalling. The midwife must have known enough about infants to recognize that the beautiful are often the damned: the quiet twin, on the edge of listlessness, was severely undernourished and had to be swaddled in blankets and revived.
The first few days of my aunt’s life were the most tenuous. She could not suckle at the breast, the story runs, and there were no infant bottles to be found in Delhi in the forties, so she was fed through a cotton wick dipped in milk, and then from a cowrie shell shaped like a spoon. When the breast milk began to run dry, at seven months, my mother was quickly weaned so that her sister could have the last remnants.
Tulu and Bulu grew up looking strikingly similar: they had the same freckled skin, almond-shaped face, and high cheekbones, unusual among Bengalis, and a slight downward tilt of the outer edge of the eye, something that Italian painters used to make Madonnas exude a mysterious empathy. They shared an inner language, as so often happens with twins; they had jokes that only the other twin understood. They even smelled the same: when I was four or five and Bulu came to visit us, my mother, in a bait-and-switch trick that amused her endlessly, would send her sister to put me to bed; eventually, searching in the half-light for identity and difference—for the precise map of freckles on her face—I would realize that I had been fooled.
But the differences were striking, too. My mother was boisterous. She had a mercurial temper that rose fast and died suddenly, like a gust of wind in a tunnel. Bulu was physically timid yet intellectually more adventurous. Her mind was more agile, her tongue sharper, her wit more lancing. Tulu was gregarious. She made friends easily. She was impervious to insults. Bulu was reserved, quieter, and more brittle. Tulu liked theatre and dancing. Bulu was a poet, a writer, a dreamer.
….. more
Why are identical twins alike? In the late nineteen-seventies, a team of scientists in Minnesota set out to determine how much these similarities arose from genes, rather than environments—from “nature,” rather than “nurture.” Scouring thousands of adoption records and news clips, the researchers gleaned a rare cohort of fifty-six identical twins who had been separated at birth. Reared in different families and different cities, often in vastly dissimilar circumstances, these twins shared only their genomes. Yet on tests designed to measure personality, attitudes, temperaments, and anxieties, they converged astonishingly. Social and political attitudes were powerfully correlated: liberals clustered with liberals, and orthodoxy was twinned with orthodoxy. The same went for religiosity (or its absence), even for the ability to be transported by an aesthetic experience. Two brothers, separated by geographic and economic continents, might be brought to tears by the same Chopin nocturne, as if responding to some subtle, common chord struck by their genomes.
One pair of twins both suffered crippling migraines, owned dogs that they had named Toy, married women named Linda, and had sons named James Allan (although one spelled the middle name with a single “l”). Another pair—one brought up Jewish, in Trinidad, and the other Catholic, in Nazi Germany, where he joined the Hitler Youth—wore blue shirts with epaulets and four pockets, and shared peculiar obsessive behaviors, such as flushing the toilet before using it. Both had invented fake sneezes to diffuse tense moments. Two sisters—separated long before the development of language—had invented the same word to describe the way they scrunched up their noses: “squidging.” Another pair confessed that they had been haunted by nightmares of being suffocated by various metallic objects—doorknobs, fishhooks, and the like.
The Minnesota twin study raised questions about the depth and pervasiveness of qualities specified by genes: Where in the genome, exactly, might one find the locus of recurrent nightmares or of fake sneezes? Yet it provoked an equally puzzling converse question: Why are identical twins different? Because, you might answer, fate impinges differently on their bodies. One twin falls down the crumbling stairs of her Calcutta house and breaks her ankle; the other scalds her thigh on a tipped cup of coffee in a European station. Each acquires the wounds, calluses, and memories of chance and fate. But how are these changes recorded, so that they persist over the years? We know that the genome can manufacture identity; the trickier question is how it gives rise to difference.
….. more
But what turns those genes on and off, and keeps them turned on or off? Why doesn’t a liver cell wake up one morning and find itself transformed into a neuron? Allis unpacked the problem further: suppose he could find an organism with two distinct sets of genes—an active set and an inactive set—between which it regularly toggled. If he could identify the molecular switches that maintain one state, or toggle between the two states, he might be able to identify the mechanism responsible for cellular memory. “What I really needed, then, was a cell with these properties,” he recalled when we spoke at his office a few weeks ago. “Two sets of genes, turned ‘on’ or ‘off’ by some signal.”
more…
“Histones had been known as part of the inner scaffold for DNA for decades,” Allis went on. “But most biologists thought of these proteins merely as packaging, or stuffing, for genes.” When Allis gave scientific seminars in the early nineties, he recalled, skeptics asked him why he was so obsessed with the packing material, the stuff in between the DNA. …. A skein of silk tangled into a ball has very different properties from that same skein extended; might the coiling or uncoiling of DNA change the activity of genes?
In 1996, Allis and his research group deepened this theory with a seminal discovery. “We became interested in the process of histone modification,” he said. “What is the signal that changes the structure of the histone so that DNA can be packed into such radically different states? We finally found a protein that makes a specific chemical change in the histone, possibly forcing the DNA coil to open. And when we studied the properties of this protein it became quite clear that it was also changing the activity of genes.” The coils of DNA seemed to open and close in response to histone modifications—inhaling, exhaling, inhaling, like life.
Allis walked me to his lab, a fluorescent-lit space overlooking the East River, divided by wide, polished-stone benches. A mechanical stirrer, whirring in a corner, clinked on the edge of a glass beaker. “Two features of histone modifications are notable,” Allis said. “First, changing histones can change the activity of a gene without affecting the sequence of the DNA.” It is, in short, formally epi-genetic, just as Waddington had imagined. “And, second, the histone modifications are passed from a parent cell to its daughter cells when cells divide. A cell can thus record ‘memory,’ and not just for itself but for all its daughter cells.”
…..
The New Yorker screws up big time with science: researchers criticize the Mukherjee piece on epigenetics
Abstract: This is a two part-post about a science piece on gene regulation that just appeared in the New Yorker. Today I give quotes from scientists criticizing that piece; tomorrow I’ll present a semi-formal critique of the piece by two experts in the field.
esterday I gave readers an assignment: read the new New Yorkerpiece by Siddhartha Mukherjee about epigenetics. The piece, called “Same but different” (subtitle: “How epigenetics can blur the line between nature and nurture”) was brought to my attention by two readers, both of whom praised it. Mukherjee, a physician, is well known for writing the Pulitzer-Prize-winning book (2011) The Emperor of All Maladies: A Biography of Cancer. (I haven’t read it yet, but it’s on my list.) Mukherjee has a new book that will be published in May: The Gene: An Intimate History. As I haven’t seen it, the New Yorker piece may be an excerpt from this book.
Everyone I know who has read The Emperor of All Maladies gives it high praise. I wish I could say the same for Mukherjee’s New Yorker piece. When I read it at the behest of the two readers, I found his analysis of gene regulation incomplete and superficial. Although I’m not an expert in that area, I knew that there was a lot of evidence that regulatory proteins called “transcription factors”, and not “epigenetic markers” (see discussion of this term tomorrow) or modified histones—the factors emphasized by Mukherjee—played hugely important roles in gene regulation. The speculations at the end of the piece about “Lamarckian evolution” via environmentally induced epigenetic changes in the genome were also unfounded, for we have no evidence for that kind of adaptive evolution. Mukherjee does, however, mention that lack of evidence, though I wish he’d done so more strongly given that environmental modification of DNA bases is constantly touted as an important and neglected factor in evolution.
Unbeknownst to me, there was a bit of a kerfuffle going on in the community of scientists who study gene regulation, with many of them finding serious mistakes and omissions in Mukherjee’s piece. There appears to have been some back-and-forth emailing among them, and several wrote letters to the New Yorker, urging them to correct the misconceptions, omissions, and scientific errors in “Same but different.” As I understand it, both Mukherjee and the New Yorker simply batted these criticisms away, and, as far as I know, will not publish any corrections. So today and tomorrow I’ll present the criticisms here, just so they’ll be on the record.
Because Mukherjee writes very well, and because even educated laypeople won’t know the story of gene regulation revealed over the last few decades, they may not see the big lacunae in his piece. It is, then, important to set matters straight, for at least we should know what science has told us about how genes are turned on and off. The criticism of Mukherjee’s piece, coming from scientists who really are experts in gene regulation, shows a lack of care on the part of Mukherjee and theNew Yorker: both a superficial and misleading treatment of the state of the science, and a failure of the magazine to properly vet this piece (I have no idea whether they had it “refereed” not just by editors but by scientists not mentioned in the piece).
Let me add one thing about science and the New Yorker. I believe I’ve said this before, but the way the New Yorker treats science is symptomatic of the “two cultures” problem. This is summarized in an email sent me a while back by a colleague, which I quote with permission:
The New Yorker is fine with science that either serves a literary purpose (doctors’ portraits of interesting patients) or a political purpose (environmental writing with its implicit critique of modern technology and capitalism). But the subtext of most of its coverage (there are exceptions) is that scientists are just a self-interested tribe with their own narrative and no claim to finding the truth, and that science must concede the supremacy of literary culture when it comes to anything human, and never try to submit human affairs to quantification or consilience with biology. Because the magazine is undoubtedly sophisticated in its writing and editing they don’t flaunt their postmodernism or their literary-intellectual proprietariness, but once you notice it you can make sense of a lot of their material.
. . . Obviously there are exceptions – Atul Gawande is consistently superb – but as soon as you notice it, their guild war on behalf of cultural critics and literary intellectuals against scientists, technologists, and analytic scholars becomes apparent.
…. more
Researchers criticize the Mukherjee piece on epigenetics: Part 2
Trigger warning: Long science post!
Yesterday I provided a bunch of scientists’ reactions—and these were big names in the field of gene regulation—to Siddhartha Mukherjee’s ill-informed piece in The New Yorker, “Same but different” (subtitle: “How epigenetics can blur the line between nature and nurture”). Today, in part 2, I provide a sentence-by-sentence analysis and reaction by two renowned researchers in that area. We’ll start with a set of definitions (provided by the authors) that we need to understand the debate, and then proceed to the critique.
Let me add one thing to avoid confusion: everything below the line, including the definition (except for my one comment at the end) was written by Ptashne and Greally.
by Mark Ptashne and John Greally
Introduction
Ptashne is The Ludwig Professor of Molecular Biology at the Memorial Sloan Kettering Cancer Center in New York. He wrote A Genetic Switch, now in its third edition, which describes the principles of gene regulation and the workings of a ‘switch’; and, with Alex Gann, Genes and Signals, which extends these principles and ideas to higher organisms and to other cellular processes as well. John Greally is the Director of the Center for Epigenomics at the Albert Einstein College of Medicine in New York.
The New Yorker (May 2, 2016) published an article entitled “Same But Different” written by Siddhartha Mukherjee. As readers will have gathered from the letters posted yesterday, there is a concern that the article is misleading, especially for a non-scientific audience. The issue concerns our current understanding of “gene regulation” and how that understanding has been arrived at.
First some definitions/concepts:
Gene regulation refers to the “turning on and off of genes”. The primary event in turning a gene “on” is to transcribe (copy) it into messenger RNA (mRNA). That mRNA is then decoded, usually, into a specific protein. Genes are transcribed by the enzyme called RNA polymerase.
Development: the process in which a fertilized egg (e.g., a human egg) divides many times and eventually forms an organism. During this process, many of the roughly 23,000 genes of a human are turned “on” or “off” in different combinations, at different times and places in the developing organism. The process produces many different cell types in different organs (e.g. liver and brain), but all retain the original set of genes.
Transcription factors: proteins that bind to specific DNA sequences near specific genes and turn transcription of those genes on and off. A transcriptional ‘activator’, for example, bears two surfaces: one binds a specific sequence in DNA, and the other binds to, and thereby recruits to the gene, protein complexes that include RNA polymerase. It is widely acknowledged that the identity of a cell in the body depends on the array of transcription factors present in the cell, and the cell’s history. RNA molecules can also recognize specific genomic sequences, and they too sometimes work as regulators. Neither transcription factors nor these kinds of RNA molecules – the fundamental regulators of gene expression and development – are mentioned in the New Yorker article.
Signals: these come in many forms (small molecules like estrogen, larger molecules (often proteins such as cytokines) that determine the ability of transcription factors to work. For example, estrogen binds directly to a transcription factor (the estrogen receptor) and, by changing its shape, permits it to bind DNA and activate transcription.
“Memory”: a dividing cell can (often does) produce daughters that are identical, and that express identical genes as does the mother cell. This occurs because the transcription factors present in the mother cell are passively transmitted to the daughters as the cell divides, and they go to work in their new contexts as before. To make two different daughters, the cell must distribute its transcription factors asymmetrically.
PositiveFeedback: An activator can maintain its own expression by positive feedback. This requires, simply, that a copy of the DNA sequence to which the activator binds is present near its own gene. Expression of the activator then becomes self-perpetuating. The activator (of which there now are many copies in the cell) activates other target genes as it maintains its own expression. This kind of ‘memory circuit’, first described in bacteria, is found in higher organisms as well. Positive feedback can explain how a fully differentiated cell (that is, a cell that has reached its developmental endpoint) maintains its identity.
Nucleosomes: DNA in higher organisms (eukaryotes) is wrapped, like beads on a string, around certain proteins (called histones), to form nucleosomes. The histones are subject to enzymatic modifications: e.g., acetyl, methyl, phosphate, etc. groups can be added to these structures. In bacteria there are no nucleosomes, and the DNA is more or less ‘naked’.
“Epigenetic modifications”: please don’t worry about the word ”epigenetic”; it is misused in any case. What Mukherjee refers to by this term are the histone modifications mentioned above, and a modification to DNA itself: the addition of methyl groups. Keep in mind that the organisms that have taught us the most about development – flies (Drosophila) and worms (C. elegans)—do not have the enzymes required for DNA methylation. That does not mean that DNA methylation cannot do interesting things in humans, for example, but it is obviously not at the heart of gene regulation.
Specificity Development requires the highly specific sequential turning on and off of sets of genes. Transcription factors and RNA supply this specificity, but enzymes that impart modifications to histones cannot: every nucleosome (and hence every gene) appears the same to the enzyme. Thus such enzymes cannot pick out particular nucleosomes associated with particular genes to modify. Histone modifications might be imagined to convey ‘memory’ as cells divide – but there are no convincing indications that this happens, nor are there molecular models that might explain why they would have the imputed effects.
Analysis and critique of Mukherjee’s article
The picture we have just sketched has taken the combined efforts of many scientists over 50 years to develop. So what, then, is the problem with the New Yorker article?
There are two: first, the picture we have just sketched, emphasizing the primary role of transcription factors and RNA, is absent. Second, that picture is replaced by highly dubious speculations, some of which don’t make sense, and none of which has been shown to work as imagined in the article.
(Quotes from the Mukherjee article are indented and in plain text; they are followed by comments, flush left and in bold, by Ptashne and Greally.)
In 1978, having obtained a Ph.D. in biology at Indiana University, Allis began to tackle a problem that had long troubled geneticists and cell biologists: if all the cells in the body have the same genome, how does one become a nerve cell, say, and another a blood cell, which looks and functions very differently?
The problems referred to were recognized long before 1978. In fact, these were exactly the problems that the great French scientists François Jacob and Jacques Monod took on in the 1950s-60s. In a series of brilliant experiments, Jacob and Monod showed that in bacteria, certain genes encode products that regulate (turn on and off) specific other genes. Those regulatory molecules turned out to be proteins, some of which respond to signals from the environment. Much of the story of modern biology has been figuring out how these proteins – in bacteria and in higher organisms – bind to and regulate specific genes. Of note is that in higher organisms, the regulatory proteins look and act like those in bacteria, despite the fact that eukaryotic DNA is wrapped in nucleosomes whereas bacterial DNA is not. We have also learned that certain RNA molecules can play a regulatory role, a phenomenon made possible by the fact that RNA molecules, like regulatory proteins, can recognize specific genomic sequences.
In the nineteen-forties, Conrad Waddington, an English embryologist, had proposed an ingenious answer: cells acquired their identities just as humans do—by letting nurture (environmental signals) modify nature (genes). For that to happen, Waddington concluded, an additional layer of information must exist within a cell—a layer that hovered, ghostlike, above the genome. This layer would carry the “memory” of the cell, recording its past and establishing its future, marking its identity and its destiny but permitting that identity to be changed, if needed. He termed the phenomenon “epigenetics”—“above genetics.”
This description greatly misrepresents the original concept. Waddington argued that development proceeds not by the loss (or gain) of genes, which would be a “genetic” process, but rather that some genes would be selectively expressed in specific and complex cellular patterns as development proceeds. He referred to this intersection of embryology (then called “epigenesis”) and genetics as “epigenetic”.We now understand that regulatory proteins work in combinations to turn on and off genes, including their own genes, and that sometimes the regulatory proteins respond to signals sent by other cells. It should be emphasized that Waddington never proposed any “ghost-like” layer of additional information hovering above the gene. This is a later misinterpretation of a literal translation of the term epigenetics, with “epi-“ meaning “above/upon” the genetic information encoded in DNA sequence. Unfortunately, this new and pervasive definition encompasses all of transcriptional regulation and is of no practical value.
…..more
By 2000, Allis and his colleagues around the world had identified a gamut of proteins that could modify histones, and so modulate the activity of genes. Other systems, too, that could scratch different kinds of code on the genome were identified (some of these discoveries predating the identification of histone modifications). One involved the addition of a chemical side chain, called a methyl group, to DNA. The methyl groups hang off the DNA string like Christmas ornaments, and specific proteins add and remove the ornaments, in effect “decorating” the genome. The most heavily methylated parts of the genome tend to be dampened in their activity.
It is true that enzymes that modify histones have been found—lots of them. A striking problem is that, after all this time, it is not at all clear what the vast majority of these modifications do. When these enzymatic activities are eliminated by mutation of their active sites (a task substantially easier to accomplish in yeast than in higher organisms) they mostly have little or no effect on transcription. It is not even clear that histones are the biologically relevant substrates of most of these enzymes.
In the ensuing decade, Allis wrote enormous, magisterial papers in which a rich cast of histone-modifying proteins appear and reappear through various roles, mapping out a hatchwork of complexity. . . These protein systems, overlaying information on the genome, interacted with one another, reinforcing or attenuating their signals. Together, they generated the bewildering intricacy necessary for a cell to build a constellation of other cells out of the same genes, and for the cells to add “memories” to their genomes and transmit these memories to their progeny. “There’s an epigenetic code, just like there’s a genetic code,” Allis said. “There are codes to make parts of the genome more active, and codes to make them inactive.”
By ‘epigenetic code’ the author seems to mean specific arrays of nucleosome modifications, imparted over time and cell divisions, marking genes for expression. This idea has been tested in many experiments and has been found not to hold.
….. and more
Larry H. Bernstein, MD, FCAP
I hope that this piece brings greater clarity to the discussion. I have heard the use of the term “epigenetics” for over a decade. The term was never so clear. I think that the New Yorker article was a reasonable article for the intended audience. It was not intended to clarify debates about a mechanism for epigenetic based changes in evolutionary science. I think it actually punctures the “classic model” of the cell depending only on double stranded DNA and transcription, which deflates our concept of the living cell. The concept of epigenetics was never really formulated as far as I have seen, and I have done serious work in enzymology and proteins at a time that we did not have the technology that exists today. I have considered with the critics that protein folding, protein misfolding, protein interactions with proximity of polar and nonpolar groups, and the regulatory role of microRNAs that are not involved in translation, and the evolving concept of what is “dark (noncoding) DNA” lend credence to the complexity of this discussion. Even more interesting is the fact that enzymes (and isoforms of enzymes) have a huge role in cellular metabolic differences and in the function of metabolic pathways. What is less understood is the extremely fast reactions involved in these cellular reactions. These reactions are in my view critical drivers. This is brought out by Erwin Schroedinger in the book What is Life? which infers that there can be no mathematical expression of life processes.
Alpha-linolenic acid given as enteral or parenteral nutritional intervention against sensorimotor and cognitive deficits in a mouse model of ischemic stroke
Stroke is a leading cause of disability and death worldwide. Numerous therapeutics applied acutely after stroke have failed to improve long-term clinical outcomes. An emerging direction is nutritional intervention with omega-3 polyunsaturated fatty acids acting as disease-modifying factors and targeting post-stroke disabilities. Our previous studies demonstrated that the omega-3 precursor, alpha-linolenic acid (ALA) administrated by injections or dietary supplementation reduces stroke damage by direct neuroprotection, and triggering brain artery vasodilatation and neuroplasticity. Successful translation of putative therapies will depend on demonstration of robust efficacy on common deficits resulting from stroke like loss of motor control and memory/learning. This study evaluated the value of ALA as adjunctive therapy for stroke recovery by comparing whether oral or intravenous supplementation of ALA best support recovery from ischemia. Motor and cognitive deficits were assessed using rotarod, pole and Morris water maze tests. ALA supplementation in diet was better than intravenous treatment in improving motor coordination, but this improvement was not due to a neuroprotective effect since infarct size was not reduced. Both types of ALA supplementation improved spatial learning and memory after stroke. This cognitive improvement correlated with higher survival of hippocampal neurons. These results support clinical investigation establishing therapeutic plans using ALA supplementation
A research team led by scientists at SUNY Downstate Medical Center has identified a brain receptor that appears to initiate adolescent synaptic pruning, a process believed necessary for learning, but one that appears to go awry in both autism and schizophrenia.
Sheryl Smith, Ph.D., professor of physiology and pharmacology at SUNY Downstate, explained that “Memories are formed at structures in the brain known as dendritic spines that communicate with other brain cells through synapses. The number of brain connections decreases by half after puberty, a finding shown in many brain areas and for many species, including humans and rodents.”
This process is referred to as adolescent “synaptic pruning” and is thought to be important for normal learning in adulthood. Synaptic pruning is believed to remove unnecessary synaptic connections to make room for relevant new memories, but because it is disrupted in diseases such as autism and schizophrenia, there has recently been widespread interest in the subject.
“Our report is the first to identify the process which initiates synaptic pruning at puberty. Previous studies have shown that scavenging by the immune system cleans up the debris from these pruned connections, likely the final step in the pruning process,” added Dr. Smith. “Working with a mouse model we have shown that, at puberty, there is an increase in inhibitory GABA [gamma-aminobutyric acid] receptors, which are targets for brain chemicals that quiet down nerve cells. We now report that these GABA receptors trigger synaptic pruning at puberty in the mouse hippocampus, a brain area involved in learning and memory.”
The study (“Synaptic Pruning in the Female Hippocampus Is Triggered at Puberty by Extrasynaptic GABAA Receptors on Dendritic Spines”) is published online in eLife.
Dr. Smith noted that by reducing brain activity, these GABA receptors also reduce levels of a protein in the dendritic spine, kalirin-7, which stabilizes the scaffolding in the spine to maintain its structure. Mice that do not have these receptors maintain the same high level of brain connections throughout adolescence.
Dr. Smith pointed out that the mice with too many brain connections, which do not undergo synaptic pruning, are able to learn spatial locations, but are unable to relearn new locations after the initial learning, suggesting that too many brain connections may limit learning potential.
These findings may suggest new treatments targeting GABA receptors for “normalizing” synaptic pruning in diseases such as autism and schizophrenia, where synaptic pruning is abnormal. Research has suggested that children with autism may have an over-abundance of synapses in some parts of the brain. Other research suggests that prefrontal brain areas in persons with schizophrenia have fewer neural connections than the brains of those who do not have the condition.
Synaptic pruning in the female hippocampus is triggered at puberty by extrasynaptic GABAAreceptors on dendritic spines
JulieParato
Department of Physiology and Pharmacology, SUNY Downstate Medical Center, Brooklyn, United States
No competing interests declared
</div>”>Sonia Afroz, JulieParato,
HuiShen
School of Biomedical Engineering, Tianjin Medical University, Tianjin, China
No competing interests declared
</div>”>HuiShen,
Sheryl SueSmith
Department of Physiology and Pharmacology, SUNY Downstate Medical Center, Brooklyn, United Statessheryl.smith@downstate.edu
Adolescent synaptic pruning is thought to enable optimal cognition because it is disrupted in certain neuropathologies, yet the initiator of this process is unknown. One factor not yet considered is the α4βδ GABAA receptor (GABAR), an extrasynaptic inhibitory receptor which first emerges on dendritic spines at puberty in female mice. Here we show that α4βδ GABARs trigger adolescent pruning. Spine density of CA1 hippocampal pyramidal cells decreased by half post-pubertally in female wild-type but not α4 KO mice. This effect was associated with decreased expression of kalirin-7 (Kal7), a spine protein which controls actin cytoskeleton remodeling. Kal7 decreased at puberty as a result of reduced NMDAR activation due to α4βδ-mediated inhibition. In the absence of this inhibition, Kal7 expression was unchanged at puberty. In the unpruned condition, spatial re-learning was impaired. These data suggest that pubertal pruning requires α4βδ GABARs. In their absence, pruning is prevented and cognition is not optimal.
Searches Related to Synaptic Pruning in the Female Hippocampus Is Triggered at Puberty by Extrasynaptic GABAA Receptors on Dendritic Spines
Researchers at Ruhr University Bochum (RUB; Germany) coupled nerve cell receptors to light-sensitive retinal pigments to understand how the serotonin neurotransmitter works and, therefore, learn what causes anxiety anddepression.
Prof. Dr. Olivia Masseck, who led the work, researches the causes of anxiety and depression. For more than 60 years, researchers have been hypothesising that the diseases are caused by, among other factors, changes to the level of serotonin. But understanding how the serotonin system works is quite difficult, says Masseck, who became junior professor for Super-Resolution Fluorescence Microscopy at RUB in April 2016.
With a method called optogenetics, Olivia Masseck (right) creates nerve cell receptors that are controllable with light. (Copyright: RUB, Damian Gorczany)
The number of receptors for serotonin in the brain amounts to 14, occurring in different cell types. Consequently, determining the functions that different receptors fulfill in the individual cell types is a complicated task. If, however, the proteins are coupled to light-sensitive pigments, they can be switched on and off with light of a specific color at high spatial and temporal precision. Masseck used this method, known as optogenetics, to characterize, for example, the properties of different light-sensitive proteins and identified the ones that are best suited as optogenetic tools. She has analyzed several light-sensitive varieties of the serotonin receptors 5-HT1A and 5-HT2C in great detail. Together with her collaborators, she has demonstrated in several studies that both receptors can control the anxiety behavior of mice.
To investigate the serotonin system more closely, Masseck and her research team is currently developing a sensor that is going to indicate the neurotransmitter in real time. One potential approach involves the integration of a modified form of a green fluorescent protein into a serotonin receptor.
In a brain slice, Olivia Masseck measures the activity of nerve cells in which she switches on their receptors using light stimulation. Via the pipette a red dye diffuses into the cell, rendering them visible in the brain slice. (Copyright: RUB, Damian Gorczany)
This protein produces green light only if it is embedded in a specific spatial structure. If a serotonin molecule binds to a receptor, the receptor changes its three-dimensional conformation. The objective is to integrate the fluorescent protein in the receptor so that its spatial structure changes together with that of the receptor when it binds a serotonin molecule, in such a way that the protein begins to glow.
New optogenetic tools by Julia Weiler
Anxiety and depression are two of the most frequently occurring mental disorders worldwide. Light-activated nerve cells may indicate how they are formed.
Statistically, every fifth individual suffers from depression or anxiety in the course of his or her life. The mechanisms that trigger these disorders are not yet fully understood, despite the fact that researchers have been studying the hypothesis that one of the underlying cause are changes to the level of the neurotransmitter serotonin for 60 years.
“Unfortunately, it is very difficult to understand how the serotonin system works,” says Prof Dr Olivia Masseck, who is junior professor for Super-Resolution Fluorescence Microscopy since the end of April 2016. She intends to fathom the mysteries of the complex system. The number of receptors for the neurotransmitter in the brain amounts to 14 in total, and they occur in different cell types. Consequently, determining the functions that different receptors fulfil in the individual cell types is a complicated task.
In order to fathom the purpose of such receptors, researchers used to observe which functions were inhibited after they had been activated or blocked with the aid of pharmaceutical drugs. However, many substances affect not just one receptor, but several at the same time. Moreover, researchers cannot tell receptors in the individual cell types apart when pharmaceutical drugs have been applied. “It had been impossible to study serotonin signalling pathways at high spatial and temporal resolution,” adds Masseck. Until the development of optogenetics.
“This method has revolutionised neuroscience,” says Olivia Masseck, whose collaborator Prof Dr Stefan Herlitze was one of the pioneers in this field. Optogenetics allows precise control over the activity of specific nerve cells or receptors with light. What sounds like science fiction, is routine at RUB’s Neuroscience Research Department. Masseck: “Until now, we had been passive observers, and monitoring cell activity was all we could do; now, we are able to manipulate it precisely.”
The researcher from Bochum is mainly interested in the 5-HT1A and 5-HT1B receptors, the so-called autoreceptors of the serotonin system. They occur in serotonin-producing cells, where they regulate the amount of released neurotransmitters; that means they determine the serotonin level in the brain.
Normally, 5-HT1A and 5-HT1B are activated when a serotonin molecule bonds to the receptor. The docking triggers a chain reaction in the cell. The effects of this signalling cascade include a reduced activity of the neural cell, which releases less neurotransmitter.
By modifying certain brain cells in the brains of mice, Olivia Masseck successfully activated the 5-HT1Areceptor without the aid of serotonin. She combined it with a visual pigment – so-called opsin. More specifically, she utilised blue or red visual pigments from the cones responsible for colour vision. This is how she generated a serotonin receptor that she could switch on with red or blue light. This method enables the RUB researcher to identify the role the 5-HT1A receptor plays in anxiety and depression.
To this end, she delivered the combined protein made up of light-sensitive opsin and serotonin receptor into the brain of mice using a virus that had been rendered harmless. Like a shuttle, it transports genetic information which contains the blueprint for the combined protein. Once injected into brain tissue, the virus implants the gene for the light-activated receptor in specific nerve cells. There, it is read, and the light-activated receptor is incorporated into the cell membrane.
The researcher was now able to switch the receptors on and off in a living mouse using light. She analysed in what way this manipulation affected the animals’ behaviour in an anxiety test, i.e. Open Field Test. For the purpose of the experiment, she placed individual mice in a large, empty Plexiglas box.
Under normal circumstances, the animals avoid the centre of the brightly-lit box, because it doesn’t offer any cover. Most of the time, they stay close to the walls. When Olivia Masseck switched on the 5-HT1Areceptor using light, the behaviour of the mice changed. They were less anxious and spent more time in the middle of the Plexiglas box.
These results were confirmed in a further test. Olivia Masseck stopped the time it took the mice to eat a food pellet in the middle of a large Plexiglas box. Normal animals waited between six and seven minutes before they ventured into the centre to feed. However, mice whose serotonin receptor was switched on started to feed after one or two minutes. “This is important evidence indicating that the 5-HT1A receptor signalling pathway in the serotonin system is linked to anxiety,” concludes Masseck.
In the next step, the researcher intends to find out in what way depressive behaviour is affected by the activation of the 5-HT1A receptor. “If the animals are exposed to chronic stress, they develop symptoms similar to those in humans with depression,” describes Masseck. “They might, for example, withdraw from social interactions.”
However, just like in humans, this applies to only a certain percentage of the mice. “Not every individual who suffers from chronic stress or experiences negative situations develops depression,” points out Masseck. What happens in the serotonin system of animals that are susceptible to depression, as opposed to that of animals that do not present any depressive symptoms? This is what the researcher intends to find out by deploying the optogenetic methods described above; in addition, she is currently developing a custom-built serotonin sensor.
Olivia Masseck’s assumption is that her findings regarding the neuronal circuits and molecular mechanisms of anxiety and depression are applicable to humans. Mice have similar cell functions, and their nervous system has a similar structure. The neuroscientist expects that optogenetics will one day be deployed in human applications.
“Genetic manipulation of cells for the purpose of controlling them with light might sound like science fiction,” she says, “but I am convinced that optogenetics will be used in human applications in the next decades.” It could, for example, be utilised for deep brain stimulation in Parkinson’s patients, because it facilitates precise activation of the required signalling pathways, with fewer side effects, at that.
“In the first step, optogenetics will be used in therapy of retinal diseases,” believes Olivia Masseck. Researchers are currently conducting experiments aiming at restoring the visual function in blind mice.
Olivia Masseck is aware that her research raises ethical questions. “We have to discuss in which applications we want or don’t want to use these techniques,” she says. Her research demonstrates how easily the lines between science-fiction films and scientific research can blur.
Detect cancer hallmarks with targeted fluorescent probes.
The smart iABP™ targeted imaging probes are based on cysteine cathepsin activity, which are highly expressed in tumor and tumor-associated cells of numerous cancers. Additionally, cathepsins are consistently expressed across multiple tumor types compared to other affinity based probes such as integrin or MMPs, which are inconsistently expressed.
The small molecule iABP™ probes are based on smart, activatable technology:
Penetrates tumor tissues quickly
Gives you superior target localization and retention at the proteolytic site
only fluorescences once it’s bound to the active target giving extremely low background fluorescence and high signal to noise ratio
Eliminates any need to wash prior to staining cells or tissue in ex vivo analysis.
The probes are suitable for use in non-invasive small animal imaging studies, live cell imaging, fluorescence microscopy, flow cytometry and SDS-PAGE applications.
Somatic Mutation Theory – Why it’s Wrong for Most Cancers, Volume 2 (Volume Two: Latest in Genomics Methodologies for Therapeutics: Gene Editing, NGS and BioInformatics, Simulations and the Genome Ontology), Part 1: Next Generation Sequencing (NGS)
Somatic Mutation Theory – Why it’s Wrong for Most Cancers
Reporter: Aviva Lev-Ari, PhD, RN
Somatic Mutation Theory – Why it’s Wrong for Most Cancers.
Hysteron proteron reverses both temporal and logical order and this syllogism occurs in carcinogenesis and the somatic mutation theory (SMT): the first (somatic mutation) occurs only after the second (onset of cancer) and, therefore, observed somatic mutations in most cancers appear well after the early cues of carcinogenesis are in place. It is no accident that mutations are increasingly being questioned as the causal event in the origin of the vast majority of cancers as clinical data show little support for this theory when compared against the metrics of patient outcomes. Ever since the discovery of the double helical structure of DNA, virtually all chronic diseases came to be viewed as causally linked to one degree or another to mutations, even though we now know that genes are not simply blueprints, but rather an assemblage of alphabets that can, under non-genetic influences, be used to assemble a business letter or a work of Shakespearean literature. A minority of all cancers is indeed caused by mutations but the SMT has been applied to all cancers, and even to chemical carcinogenesis, in the absence of hard evidence of causality. Herein, we review the 100 year story of SMT and aspects that show why genes are not just blueprints, how radiation and mutation are associated in a more nuanced view, the proposed risk of cancer and bad luck, and the in vitro and in vivo evidence for a new cancer paradigm. This paradigm is scientifically applicable for the majority of non-heritable cancers and consists of a six-step sequence for the origin of cancer. This new cancer paradigm proclaims that somatic mutations are epiphenomena or later events occurring after carcinogenesis is already underway. This serves not just as a plausible alternative to SMT and explains the origin of the majority of cancers, but also provides opportunities for early interventions and prevention of the onset of cancer as a disease.
Conclusions
The incorrect interpretation of data can sometimes appear to be the more parsimonious explanation especially when it has acquired the mantle of a paradigm, as in the case of the SMT. Summa Cancerologica is not hypothetical or ontological. Its syllogism of carcinogenesis needs the consideration of all reasonable perspectives such as whether somatic mutations are later events or epiphenomena occurring at the end of the sequence of events in carcinogenesis. This mutatio praemissarum leads to a reflection of reasoned judgments of correct findings in cancer (mutations within tumors) together with clinical observations (relevance of such mutations to cancer therapy). An overemphasis of the SMT as the sole reason of the origin of carcinogenesis elevated it to the status of a dogma which downplays significant findings of mutations and genetics in different fields of nature, biology and science. However, there is hope that hereditary cancers can be treated in the near future as new technologies make it possible to manipulate proteins packaging DNA to turn on specific gene promoters and enhancers [164]. If this were applicable to the mass of non-hereditary cancers this approach would still be only symptomatic as the genesis of non-hereditary cancers is not caused by somatic mutations though somatic mutations occur within tumors. Focusing on the tumor cell without its origin including the microenvironment won’t be enough [165]. The reasoning on the origin of carcinogenesis, including different step-wise sequences, may help unmask mechanisms of the transition of a normal into a cancer cell (cancer genesis) as well as its different primary pathogenic stimulus, which can serve to prevent or retard cancers instead of concentrating on symptomatic strategies or for a cure for all cancers. It is scientifically valid based on in vitro and in vivo genetic findings that carcinogenesis consists of a six-step multi sequence process [17, 18]. This serves not just as a plausible alternative to the SMT to explain the origin of the majority of cancers, but could also suggest early interventions and thereby prevent the onset of cancer as a disease.
Fusion detection can be carried out with traditional opposing primer-based library preparation methods, which require target- and fusion-specific primers that define the region to be sequenced. With these methods, primers are needed that flank the target region and the fusion partner, so only known fusions can be detected. An alternative method, ArcherDX’ Anchored Multiplex PCR (AMP), can be used to detect the target of interest, plus any known and unknown fusion partners. This is because AMP uses target-specific unidirectional primers, along with reverse primers, that hybridize to the sequencing adapter that is ligated to each fragment prior to amplification.
In time, the narrow, tortuous paths followed by pioneers become wider and straighter, whether the pioneers are looking to settle new land or bring new biomarkers to the clinic.
In the case of biomarkers, we’re still at the stage where pioneers need to consult guides and outfitters or, in modern parlance, consultants and technology providers. These hardy souls tend to congregate at events like the Biomarker Conference, which was held recently in San Diego.
At this event, biomarker experts discussed ways to avoid unfortunate detours on the trail from discovery and development to clinical application and regulatory approval. Of particular interest were topics such as the identification of accurate biomarkers, the explication of disease mechanisms, the stratification of patient groups, and the development of standard protocols and assay platforms. In each of these areas, presenters reported progress.
Another crucial subject is the integration of techniques such as next-generation sequencing (NGS). This particular technique has been instrumental in advancing clinical cancer genomics and continues to be the most feasible way of simultaneously interrogating multiple genes for driver mutations.
Enriching nucleic acid libraries for target genes of interest prior to NGS greatly enhances the sensitivity of
detecting mutations, as the enriched regions are sequenced multiple times. This is particularly useful when analyzing clinical samples, which generate low amounts of poor-quality nucleic acids.
However, NGS has been limited in its ability to identify gene fusions and translocations, which underlie oncogenesis in a variety of cancers. “These challenges are largely related to the enrichment chemistry used to produce sequencing libraries,” commented Joshua Stahl, chief scientific officer and general manager, ArcherDX.
Most target-enrichment strategies require prior knowledge of both ends of the target region to be sequenced. Therefore, only gene fusions with known partners can be amplified for downstream NGS assays.
Archer’s Anchored Multiplex PCR (AMP™) technology overcomes this limitation, as it can enrich for novel fusions, while only requiring knowledge of one end of the fusion pair. At the heart of the AMP chemistry are unique Molecular Barcode (MBC) adapters, ligated to the 5′ ends of DNA fragments prior to amplification. The MBCs contain universal primer binding sites for PCR and a molecular barcode for identifying unique molecules. When combined with 3′ gene-specific primers, MBCs enable amplification of target regions with unknown 5′ ends.
“AMP is ideal for identifying gene fusions and other driver mutations from FFPE samples,” asserted Mr. Stahl. “Its robust utility was demonstrated for detection of gene fusions, point mutations, insertions, deletions, and copy number changes from low amounts of clinical formalin-fixed, paraffin-embedded (FFPE) RNA and DNA samples.
“Tagging each molecule of input nucleic acid with a unique molecular barcode allows for de-duplication, error correction, and quantitative analysis, resulting in high sequencing consensus. With its low error rate and low limits of detection, AMP is revolutionizing the field of cancer genomics.”
In a proof-of-concept study, a single-tube 23-plex panel was designed to amplify the kinase domains of ALK, RET, ROS1, and MUSK genes by AMP. This enrichment strategy enabled identification of gene fusions with multiple partners and alternative splicing events in lung cancer, thyroid cancer, and glioblastoma specimens by NGS.
Ignyta, a precision medicine company, adopted Archer’s AMP technology in Trailblaze Pharos™, a multiplex assay employed in their STARTRK-2 trial for identifying actionable NTRK, ROS1, and ALK gene rearrangements in solid tumors that can be treated with the novel kinase inhibitor, entrectinib. “Gene fusions are incredibly important in personalized medicine right now,” stated Mr. Stahl. “Archer’s FusionPlex assays are quickly becoming the new gold standard.”
Reading Cancer Signatures
This image, from the Massachusetts General Hospital Cancer Center, shows multicolor fluorescence in situ hybridization (FISH) analysis of cells from a patient with esophagogastric cancer. Remarkably, the FISH analysis revealed that co-amplification of the MET gene (red signal) and the EGFR gene (green signal) existed simultaneously in the same tumor cells. A chromosome 7 control probe is shown in blue.
“Each year 23,000 kidneys are transplanted, and over 175,000 kidney transplants are functional today,” noted Daniel R. Salomon, M.D., medical program director, Scripps Center for Organ Transplantation, Scripps Research Institute. “However, in just 5 years, 3 out of every 10 patients will be back on dialysis, and in 15 years, at least 75% of all patients will lose their kidney grafts.“Tumor biomarkers are critical for predicting and following patient responses to today’s cancer therapies,” said Darrell Borger, Ph.D., co-director of the Translational Research Laboratory and director of the Biomarker Laboratory, Massachussetts General Hospital (MGH) Cancer Center, Harvard Medical School. “If we understand what drives the malignancy in any given patient, we are able to match existing therapies to the patient’s genotype.”
Over the last decade, the Biomarker/Translational Research Laboratory has focused on developing clinical genotyping and fluorescent in situ hybridization (FISH) assays for rapid personalized genomic testing.
“Initially, we analyzed the most prevalent hotspot mutations, about 160 in 25 cancer genes,” continued Dr. Borger. “However, this approach revealed mutations in only half of our patients. With the advent of NGS, we are able to sequence 190 exons in 39 cancer genes and obtain significantly richer genetic fingerprints, finding genetic aberrations in 92% of our cancer patients.”
Using multiplexed approaches, Dr. Borger’s team within the larger Center for Integrated Diagnostics (CID) program at MGH has established high-throughput genotyping service as an important component of routine care. While only a few susceptible molecular alterations may currently have a corresponding drug, the NGS-driven analysis may supply new information for inclusion of patients into ongoing clinical trials, or bank the result for future research and development.
“A significant impediment to discovery of clinically relevant genomic signatures is our current inability to interconnect the data,” explained Dr. Borger. “On the local level, we are striving to compile the data from clinical observations, including responses to therapy and genotyping. Globally, it is imperative that comprehensive public databases become available to the research community.”
Tumor profiling at MGH have already yielded significant discoveries. Dr. Borger’s lab, in collaboration with oncologists at the MGH Cancer Center, found significant correlations between mutations in the genes encoding the metabolic enzymes isocitrate dehydrogenase (IDH1 and IDH2) and certain types of cancers, such as cholangiocarcinoma and acute myelogenous leukemia (AML).
Historically, cancer signatures largely focus on signaling proteins. Discovery of a correlative metabolic enzyme offered a promise of diagnostics based on metabolic byproducts that may be easily identified in blood. Indeed, the metabolite 2-hydroxyglutarate accumulates to high levels in the tissues of patients carrying IDH1 and IDH2 mutations. They have reported that circulating 2-hydroxyglutarate as measured in the blood correlates with tumor burden, and could serve as an important surrogate marker of treatment response.
“We believe that this is caused by chronic immune-mediated rejection. Failure of effective immunosuppression reduces functional life of these patients and adds in $9–13 billion in yearly healthcare costs.” Dr. Salomon emphasized that ineffective use of immunosuppressive drugs is partially due to the lack of an objective biomarker which could provide decision support for just-in-time adjustment in therapeutic regimens.
“Our research aims to provide that objective measure to clinicians,” explained Dr. Salomon.
To date, kidney transplant biopsies remain the gold standard, even though they are not suitable for continuous monitoring and have both costs and risks. Dr. Salomon’s team developed a minimally invasive diagnostic approach based on unbiased whole-genome expression profiling of blood samples. Using Affymetrix Human Genome U133 Plus 2.0 Gene Chips, the team analyzed 275 bloodsamples of kidney transplant patients with biopsy-proved acute rejection, acute dysfunction without rejection and transplant excellent phenotype.
The data was passed through several machine-learning algorithms to identify a group of about 250 classifiers that predict subacute or acute rejection with 80% accuracy. This signature is locked while the team continues to expand the core dataset aiming to reach a thousand samples by the end of this year.
“As opposed to classical approaches to biomarker discoveries limited to just a few classifiers, our methodology provides for the first use of unbiased whole-genome profiling in the identification of multiple molecular predictors,” declared Dr. Salomon. “We can use this molecular diagnostic strategy to reveal a subacute rejection prior to significant tissue injury leading to transplant dysfunction. Continuous monitoring would inform physicians on the balance between over-suppression and effective/optimal therapy.”
Dr. Salomon is a chief scientific advisor for Transplant Genomics (TGI), a start-up company created to translate the blood-based molecular diagnostics into clinical tests. In late 2016, TGI will begin providing its TruGraf blood tests for kidney transplant recipients for use by four to six U.S. transplant centers through an early-access program (EAP).
Additional tests designed to be used serially to diagnose and treat subclinical episodes of rejection including biopsy gene profiling are in the final stages of development. Validation and will be made available through the EAP in the upcoming months.
BioAgilytix’ MultiMuscle Analysis is a process that can split sample analysis into multiple parallel tracks to minimize antibody cross-reactivity and allow for use of the best-fit platform or kit for each biomarker analysis. The process may require only one tube of sample with only one F/T cycle.
Focusing on Large Molecules
BioAgilytix, a specialized bioanalytical laboratory, is a global leader in large molecule bioanalysis. The company’s business encompasses pharmacokinetic/pharmacodynamic (PK/PD) studies of large biomolecules, in addition to immunogenicity, biomarkers, and cell-based assays. In less than 10 years,BioAgilytix has grown from a start-up to an international powerhouse with over 100 employees—more than half possessing advanced scientific degrees—because of its team’s expertise in the complexities of large molecule drug development.
“In contrast to small molecule analysis, which has become more of a commodity due to its semiautomated and process-oriented nature, large molecule analysis is inherently challenging,” said Afshin Safavi, Ph.D., founder and chief science officer of BioAgilytix. “In large molecule bioanalysis, we rely heavily on analytical reagents, such as antibodies and recombinant proteins, which are known to show considerable variability from lot to lot.
BioAgilytix’ MultiMuscle Analysis is a process that can split sample analysis into multiple parallel tracks to minimize antibody cross-reactivity and allow for use of the best-fit platform or kit for each biomarker analysis. The process may require only one tube of sample with only one F/T cycle.
“Therefore, designing an effective analytical process for large biomolecules requires scientific personnel with years of experience. It also requires careful management of critical reagents, and a deep understanding of the capabilities and limitations of the platforms selected for use.”
Dr. Safavi explains that the biomarker field has been trending away from a gunshot approach traditionally favored by large pharma to more focused analyses of a few key biomarkers.
“Unlike several years ago, most biotech and pharma companies now perform careful due diligence and literature research before approaching us, to narrow down their investigation to just a handful of biomarkers,” he explained. Limited samples may drive the desire to multiplex as many biomarkers as possible, but a multiplex approach may often result in low quality data due to reagent cross-reactivity.
A recent process innovation developed by BioAgilytix, called MultiMuscle Analysis™, uses a customized parallel process to drastically reduce analytical process time and increase data quality. MultiMuscle Analysis splits the sample analysis into multiple parallel tracks, each performed on specialized equipment by scientists experienced in that particular platform.
“Say, for example, a customer requests measurements of 10 biomarkers,” ventured Dr. Safavi. “If we know some of the antibodies may cross-react, then we may, for example, end up with one heptaplex and three as uniplexes, all done in parallel.”
Using this approach, BioAgilytix is able to perform large biomarker analyses on a very large number of samples in near real-time. “We now receive samples from over 20 countries,” Dr. Safavi stated. “We have used the MultiMuscle approach successfully over and over.”
Feature ArticlesMore » May 1, 2016 (Vol. 36, No. 9)
Paving the Road for Clinical Biomarkers
Where Trackless Terrain Once Challenged Biomarker Development, Clearer Paths Are Emerging
Kate Marusina, Ph.D.
Focusing on Large Molecules
BioAgilytix’ MultiMuscle Analysis is a process that can split sample analysis into multiple parallel tracks to minimize antibody cross-reactivity and allow for use of the best-fit platform or kit for each biomarker analysis. The process may require only one tube of sample with only one F/T cycle.
BioAgilytix, a specialized bioanalytical laboratory, is a global leader in large molecule bioanalysis. The company’s business encompasses pharmacokinetic/pharmacodynamic (PK/PD) studies of large biomolecules, in addition to immunogenicity, biomarkers, and cell-based assays. In less than 10 years, BioAgilytix has grown from a start-up to an international powerhouse with over 100 employees—more than half possessing advanced scientific degrees—because of its team’s expertise in the complexities of large molecule drug development.
“In contrast to small molecule analysis, which has become more of a commodity due to its semiautomated and process-oriented nature, large molecule analysis is inherently challenging,” said Afshin Safavi, Ph.D., founder and chief science officer of BioAgilytix. “In large molecule bioanalysis, we rely heavily on analytical reagents, such as antibodies and recombinant proteins, which are known to show considerable variability from lot to lot.
“Therefore, designing an effective analytical process for large biomolecules requires scientific personnel with years of experience. It also requires careful management of critical reagents, and a deep understanding of the capabilities and limitations of the platforms selected for use.”
Dr. Safavi explains that the biomarker field has been trending away from a gunshot approach traditionally favored by large pharma to more focused analyses of a few key biomarkers.
“Unlike several years ago, most biotech and pharma companies now perform careful due diligence and literature research before approaching us, to narrow down their investigation to just a handful of biomarkers,” he explained. Limited samples may drive the desire to multiplex as many biomarkers as possible, but a multiplex approach may often result in low quality data due to reagent cross-reactivity.
A recent process innovation developed by BioAgilytix, called MultiMuscle Analysis™, uses a customized parallel process to drastically reduce analytical process time and increase data quality. MultiMuscle Analysis splits the sample analysis into multiple parallel tracks, each performed on specialized equipment by scientists experienced in that particular platform.
“Say, for example, a customer requests measurements of 10 biomarkers,” ventured Dr. Safavi. “If we know some of the antibodies may cross-react, then we may, for example, end up with one heptaplex and three as uniplexes, all done in parallel.”
Using this approach, BioAgilytix is able to perform large biomarker analyses on a very large number of samples in near real-time. “We now receive samples from over 20 countries,” Dr. Safavi stated. “We have used the MultiMuscle approach successfully over and over.”
Predicting Clotting or Hemorrhaging
Venous thromboembolism (VTE) is a disease that includes both deep vein thrombosis (DVT) and pulmonary embolism (PE). It is a common, lethal disorder, symptoms of which are often overlooked. VTE is the third most common cardiovascular illness after acute coronary syndrome and stroke.
Venous thrombi, composed predominately of red blood cells bound together by fibrin, form in sites of vessel damage and areas of stagnant blood flow. Once VTE is diagnosed, anticoagulation therapy is indicated.
A novel anticoagulant that reversibly and directly inhibits factor Xa, a key factor in the coagulation system, has been developed by Daiichi Sankyo. “Once on the path of development of an anticoagulant, we recognized the lack of a rapid and sensitive coagulation test that would not be affected by blood traces of anticoagulant therapies,” said Michele Mercuri, M.D., Ph.D., the company’s senior vice president. “An improved diagnostic test would speed up recognition and treatment of thrombosis, and would aid in development of reversing agents that reduce the effect of anticoagulant therapies when needed.”
When Daiichi Sankyo entered in collaboration with Perosphere to develop a novel broad-spectrum reversing agent, the company also supported development of a point-of-care coagulometer (still under development), a hand-held device designed for broad-spectrum monitoring of the activity of anticoagulants and their corresponding reversing agents, across drug classes. A single test requires only 10 µL of fresh or citrated whole blood from a venous draw or finger stick. It optically measures clotting starting with Factor XII activation to fibrin assembly.
Dr. Mercuri explains that none of the existing tests are able to predict whether a patient is at risk for either clotting or hemorrhaging. “Together with Prof. Zahi Fayad’s Team from the Icahn School of Medicine at Mt Sinai, we used magnetic resonance imaging with the gadolinium-based contrast reagent to detect the venous thrombi and follow their dissolution with edoxaban treatment,” reported Dr. Mercuri.
This study, the edoxaban Thrombus Reduction Imaging Study (eTRIS), was focused on developing and validating a magnetic resonance venography (MRV) image acquisition and analysis protocol for the quantification of thrombus volume in deep vein thrombosis. The multicenter study demonstrated excellent reproducibility of analysis of quantifying thrombus volume.
Sequence and Epigenetic Factors Determine Overall DNA Structure
Researchers at Ulsan National Institute of Science and Technology (UNIST) in South Korea found that DNA molecules directly interact with one another in ways that are dependent on the sequence of the DNA and epigenetic factors.
The researchers found evidence for sequence-dependent attractive interactions between double-stranded DNA molecules that neither involve intermolecular strand exchange nor are mediated by DNA-binding proteins.
“DNA molecules tend to repel each other in water, but in the presence of special types of cations, they can attract each other just like nuclei pulling each other by sharing electrons in between,” explained lead study author Hajin Kim, Ph.D., assistant professor of biophysics at UNIST. “Our study suggests that the attractive force strongly depends on the nucleic acid sequence and also the epigenetic modifications.”
The investigators used atomic-level simulations to measure forces between double-stranded DNA helices, proposing that the distribution of methyl groups on DNA were the key to regulating this sequence-dependent attraction.
The findings from this study were published recently in Nature Communications through an article entitled “Direct evidence for sequence-dependent attraction between double-stranded DNA controlled by methylation.”
The researchers surmised that direct DNA-DNA interactions could play a central role in how chromosomes are organized and packaged, determining the ultimate fate of many cell types.
Dr. Kim concluded by stating that “in our lab, we try to unravel the mysteries within human cells based on the principles of physics and the mechanisms of biology—seeking for ways to prevent chronic illnesses and diseases associated with aging.”
Searches Related to Direct evidence for sequence-dependent attraction between double-stranded DNA controlled by methylation
Although proteins mediate highly ordered DNA organization in vivo, theoretical studies suggest that homologous DNA duplexes can preferentially associate with one another even in the absence of proteins. Here we combine molecular dynamics simulations with single-molecule fluorescence resonance energy transfer experiments to examine the interactions between duplex DNA in the presence of spermine, a biological polycation. We find that AT-rich DNA duplexes associate more strongly than GC-rich duplexes, regardless of the sequence homology. Methyl groups of thymine acts as a steric block, relocating spermine from major grooves to interhelical regions, thereby increasing DNA–DNA attraction. Indeed, methylation of cytosines makes attraction between GC-rich DNA as strong as that between AT-rich DNA. Recent genome-wide chromosome organization studies showed that remote contact frequencies are higher for AT-rich and methylated DNA, suggesting that direct DNA–DNA interactions that we report here may play a role in the chromosome organization and gene regulation.
Formation of a DNA double helix occurs through Watson–Crick pairing mediated by the complementary hydrogen bond patterns of the two DNA strands and base stacking. Interactions between double-stranded (ds)DNA molecules in typical experimental conditions containing mono- and divalent cations are repulsive1, but can turn attractive in the presence of high-valence cations2. Theoretical studies have identified the ion–ion correlation effect as a possible microscopic mechanism of the DNA condensation phenomena3, 4, 5. Theoretical investigations have also suggested that sequence-specific attractive forces might exist between two homologous fragments of dsDNA6, and this ‘homology recognition’ hypothesis was supported by in vitro atomic force microscopy7 and in vivo point mutation assays8. However, the systems used in these measurements were too complex to rule out other possible causes such as Watson–Crick strand exchange between partially melted DNA or protein-mediated association of DNA.
Here we present direct evidence for sequence-dependent attractive interactions between dsDNA molecules that neither involve intermolecular strand exchange nor are mediated by proteins. Further, we find that the sequence-dependent attraction is controlled not by homology—contradictory to the ‘homology recognition’ hypothesis6—but by a methylation pattern. Unlike the previous in vitro study that used monovalent (Na+) or divalent (Mg2+) cations7, we presumed that for the sequence-dependent attractive interactions to operate polyamines would have to be present. Polyamine is a biological polycation present at a millimolar concentration in most eukaryotic cells and essential for cell growth and proliferation9, 10. Polyamines are also known to condense DNA in a concentration-dependent manner2, 11. In this study, we use spermine4+(Sm4+) that contains four positively charged amine groups per molecule.
Methylation determines the strength of DNA–DNA attraction
Analysis of the MD simulations revealed the molecular mechanism of the polyamine-mediated sequence-dependent attraction (Fig. 2). In the case of the AT-rich fragments, the bulky methyl group of thymine base blocks Sm4+ binding to the N7 nitrogen atom of adenine, which is the cation-binding hotspot21, 22. As a result, Sm4+ is not found in the major grooves of the AT-rich duplexes and resides mostly near the DNA backbone (Fig. 2a,d). Such relocated Sm4+ molecules bridge the two DNA duplexes better, accounting for the stronger attraction16, 23, 24, 25. In contrast, significant amount of Sm4+ is adsorbed to the major groove of the GC-rich helices that lacks cation-blocking methyl group (Fig. 2b,e).
Figure 2: Molecular mechanism of polyamine-mediated DNA sequence recognition.
(a–c) Representative configurations of Sm4+ molecules at the DNA–DNA distance of 28 Å for the (AT)10–(AT)10 (a), (GC)10–(GC)10 (b) and (GmC)10–(GmC)10 (c) DNA pairs. The backbone and bases of DNA are shown as ribbon and molecular bond, respectively; Sm4+ molecules are shown as molecular bonds. Spheres indicate the location of the N7 atoms and the methyl groups. (d–f) The average distributions of cations for the three sequence pairs featured in a–c. Top: density of Sm4+ nitrogen atoms (d=28 Å) averaged over the corresponding MD trajectory and the z axis. White circles (20 Å in diameter) indicate the location of the DNA helices. Bottom: the average density of Sm4+ nitrogen (blue), DNA phosphate (black) and sodium (red) atoms projected onto the DNA–DNA distance axis (x axis). The plot was obtained by averaging the corresponding heat map data over y=[−10, 10] Å. See Supplementary Figs 4 and 5 for the cation distributions at d=30, 32, 34 and 36 Å.
Genome-wide investigations of chromosome conformations using the Hi–C technique revealed that AT-rich loci form tight clusters in human nucleus27, 28. Gene or chromosome inactivation is often accompanied by increased methylation of DNA29 and compaction of facultative heterochromatin regions30. The consistency between those phenomena and our findings suggest the possibility that the polyamine-mediated sequence-dependent DNA–DNA interaction might play a role in chromosome folding and epigenetic regulation of gene expression.
Phenotypic and Biomarker-based Drug Discovery
Organizers: Michael Foley (Tri-Institutional Therapeutics Discovery Institute), Ralph Garippa (Memorial Sloan-Kettering Cancer Center), David Mark (F. Hoffmann-La Roche), Lorenz Mayr (Astra Zeneca), John Moffat (Genentech), Marco Prunotto (F. Hoffmann-La Roche), and Sonya Dougal (The New York Academy of Sciences)Presented by the Biochemical Pharmacology Discussion Group
Reported by Robert Frawley | Posted January 12, 2016
There are two major methods for designing pharmaceutical drugs. In traditional drug discovery (TDD), or empiric design, researchers target a particular domain or protein after working to understand its mechanisms and molecular biology. In phenotypic drug discovery (PDD), many different compounds are tested on a system until one results in an observable phenotype of success, and the compounds’ mechanisms of action are not considered. The Phenotypic and Biomarker-based Drug Discovery symposium, presented by the Academy’s Biochemical Pharmacology Discussion Group on October 27, 2015, featured current work in PDD and highlighted the need to bridge commercial and academic research to improve phenotypic drug design.
Phenotypic drug discovery—screening of thousands of substances for functional cellular outputs such as gene expression, growth arrest, and cancer cell death—has led to the development of more commercial drugs than TDD, the more common method of discovery. Indeed, as Jonathan A. Lee of Eli Lilly noted, spending on TDD is out of sync with the rate of new drugs reaching approval; the number of new drugs per billion dollars spent dropped sharply in the last few decades. He argued that the need for functionally validated drugs could be met through a renewed focus on PDD.
Bruce A. Posner started the morning session with a discussion of a phenotypic screen conducted at the University of Texas Southwestern Medical Center which identified two chemical scaffolds that are effective in killing non-small cell lung cancer (NSCLC) cells but are harmless to the non-cancer cells tested. In further studies, the group showed that an optimized analog of one scaffold arrested tumor growth in a mouse xenograft model of NSCLC. Both chemical scaffolds appear to work through a novel mechanism targeting stearoyl-CoA desaturase (SCD), which is known to be important in unsaturated fatty acid synthesis. These compounds were found to be specific, effective, and potent in NSCLC cell lines that express elevated levels of Cyp4F11 and/or related Cyp family members. The group also showed that these scaffolds function as prodrugs that are activated only in cancer cells expressing these Cyp isoforms and that the Cyps produce metabolites of the prodrug that bring about cancer-specific cell toxicity. The group is working to improve these scaffolds and to develop a putative biomarker based on Cyp expression.
The Broad Institute’s LINCS (Library of Network-based Cellular Signatures) database is designed to keep track of small-molecule therapeutics, collecting data on cellular responses to “perturbagens” (drugs, factors, and others stimuli). Data are generated using the L1000 assay, which assesses the expression of 1000 genes known to explain 80% of genetic variation in assayed cell lines. Aravind Subramanian explained that the technique can identify the majority of drug effects for a fraction of the cost of RNA sequencing. Although it examines only a subset of molecules and relies on measuring genetic responses, the technique can help predict the likelihood that new compounds will elicit desired effects.
Martin Main of AstraZeneca described phenotypic drug discovery at AstraZeneca. The company’s model for discovery is to check phenotypic markers at every step, as drugs are moved from cell lines to patients. Main’s team identified a molecule that enhances the regenerative function of cardiac myocytes after infarction. Using cells from several donors, the team validated a promising compound that increases proliferation of cardiac myocytes and drives epicardium-derived progenitor cells to assume a myocyte lineage. In another discovery, the team used islet β-cell regeneration as the phenotype, discovering a compound the researchers believe will reach clinical trials for type 2 diabetes.
Andras J. Bauer of Boehringer Ingelheim discussed a method to increase predictive strength in compound selection before phenotypic screening. By cataloging the structures of known target–reference compound binding pairs, the team can compare those structures to untested compounds, and then assess only the most promising compounds. The THICK (Target Hypothesis Information from Curated Knowledge bases) database gives interaction-probability scores to untested compounds on the basis of structure. Bauer also described a method to verify target–compound interaction without labeling the molecules, in which phenotypic results were verified with mass spectrometry.
In the afternoon session, Myles Fennell of Memorial Sloan-Kettering Cancer Center described his work testing small interfering RNA (siRNA) libraries to find siRNAs that alter macropinocytosis (MP), cell-surface ruffling that is seen in prostate cancer cells. The surface phenotype allows TMR-dextran uptake, which the researchers measured in the screen. MP is driven by RAS (a commonly affected gene family in cancers) and the pathways are already popular drug targets. The researchers tested two libraries of siRNAs, which block translation of specific proteins, using TMR as a marker to report MP severity, as well as sensitive single-cell assays to determine siRNA efficacy. The team identified promising target sequences and used a data-analysis pipeline called KNIME to define several hits, which the researchers are pursuing in therapeutic development.
TMR-dextran is able to work into cells undergoing macropinocytosis and thus these cells can be separated by phenotype as seen in the controls above. (Image courtesy of Myles Fennell)
Giulio Superti-Furga of the Austrian Academy of Sciences is a proponent of understanding the mechanisms of action (MOA) of candidate drugs. He began by explaining that the genome is an incomplete indicator of disease; epigenetics, altered protein function, metabolism, and other factors are also important. He then introduced pharmacoscopy and the “thermal shiftome” as methods to phenotypically screen compounds. Pharmacoscopy uses high-power automated microscopy to describe how compounds affect cell populations by using specific stains for different cell types; a computer then counts the cells expressing each stain, yielding results similar to those obtained via fluorescence-activated cell sorting but generated through an automated process. The thermal shiftome catalogs changes in thermal stability after protein binding in known reactions and is used to characterize the stability of new reactions. Superti-Furga offered a perspective that tempered the enthusiasm for pure PDD and advocated a mechanistic approach to drug discovery.
Michael R. Jackson, at one of the largest academic screening facilities, the Sanford Burnham Prebys Medical Discovery Institute, led a reexamination of drug screens performed by pharmaceutical companies. His team conducted millions of assays and accumulated a large data library with few new hits. However, the researchers were able to closely characterize the chemistry of one hit, an undisclosed interaction, and Jackson’s group is proceeding to develop a drug to modulate nuclear receptor signaling. The researchers also have a procedure that can screen for the differentiation of human induced pluripotent stem cells (iPSCs) into neurons for potential neuro-regenerative therapies. They developed high-throughput morphology, endpoint-measurement, and proliferation assays that generate tightly clustered, repeatable data. The team has produced consistent results screening 10 immune modulators and various cytokines to assess the reactivity and stability of the cells, providing reliable compound characterization. This success in human cells shows that a disease-relevant patient-derived screening platform to characterize differentiation and immune response is possible with robust assays.
In the next set of talks, Friedrich Metzger and Susanne Swalley described the parallel work of Hoffmann-La Roche and Novartis, respectively, toward treating spinal muscular atrophy (SMA). A devastating disease that leads to loss of motor function and affects motor nerve cells in the spinal cord, SMA presents a unique drug development opportunity. The condition is caused by the loss of function of a single gene product called survival of motor neuron (SMN1). Humans encode an unstable gene product, called SMN2, which is nearly homologous to SMN1.
Metzger explained that the inactive SMN2 variant is largely the same as active SMN1 but, missing exon 7, cannot compensate in its absence. The group from Hoffmann-La Roche aimed to stabilize SMN2 by promoting the inclusion of exon 7. The researchers conducted a phenotypic screen seeking a compound that could change the splicing in patient fibroblasts in vitro and produce a stable, functional SMN2 protein including exon 7. In studies with an SMN2Δ7 mouse model (lacking exon 7), mice drugged with the compound experienced full phenotypic rescue. The compound has been shown to induce alternative splicing of SMN2 to include exon 7 in healthy human volunteers; it was well tolerated and is moving to human patient trials.
Swalley discussed the target identification and MOA of the Novartis compound. After a screening process similar to Roche’s, Novartis moved its compound into animal models while also beginning parallel experimentation to find out why it worked. The group found that U1-snRNP, a spliceosome component required for the splicing process, is bound at two essential nucleotides by the compound. In the SMN2Δ7 mice, the compound improved survival and rescued full SMN2 protein expression. The Novartis compound stabilizes the appropriate spliceosome components to produce SMN2 with exon 7 intact. This novel mechanism demonstrates that a sequence-selective small molecule therapy can alter splicing activity to treat SMA. Together these talks demonstrated the power of PDD and the importance of validating drug mechanisms.
The final talk of the day was given by Hoffmann-La Roche’s Jitao David Zhang, who suggested that pathway reporter genes, which are only modulated when a specific signaling pathway is activated or inhibited, can be used as phenotypic readouts. It is known that gene expression data can predict cell phenotype. Using transcriptomics as a surrogate for downstream phenotypes, for example by using expression data from a gene subset to predict outcomes, would save time and effort. In an iPSC cardiomyocyte model of diabetic stress, machine learning (guided by pathway information) characterizes the response of the iPSCs to a library of compounds, highlighting compounds and pathways worthy of further investigation. This new platform for molecular phenotyping using pathway reporter genes, sequencing, and early analysis speeds compound characterization.
Use the tabs above to find multimedia from this event.
Presentations available from:
Andras J. Bauer, PhD, PharmD (Boehringer Ingelheim)
Myles Fennell, PhD (Memorial Sloan-Kettering Cancer Center)
Jonathan A. Lee, PhD (Eli Lilly)
Martin Main, PhD (AstraZeneca)
Yao Shen, PhD (Columbia University)
Susanne Swalley, PhD (Novartis Institutes for BioMedical Research)
Jitao David Zhang, PhD (F. Hoffmann-La Roche)
Two immunotherapies that target the cell programmed death (PD) pathway are now available, and both nivolumab (Opdivo, Bristol-Myers Squibb Company) and pembrolizumab (Keytruda, Merck Sharp & Dohme Corp) are approved for treating advanced, refractory, non–small cell lung cancer (NSCLC). Across several studies in patients with NSCLC, response to these agents has been correlated with PD-L1 staining, which determines PD-L1 levels in the tumor tissue. How do the available assays for PD-L1 compare?
The linear correlation between three commercially available assays is good across a range of cutoff points, concluded a presentation at the 2016 American Association for Clinical Research Annual Meeting.
Cutoffs are defined as the percentage of cells expressing PD-L1 when analyzed histochemically. “The dataset builds confidence that the assays may be used according to the cutoff clinically validated for the drug in question,” Marianne J. Radcliffe, MD, diagnostic associate director at AstraZeneca, toldMedscape Medical News.
“The correlation is good between the assays across the range examined,” she added.
However, a recently published study showed a high rate of discordance between another set of PD-L1 assays that were tested.
Dr Marianne Radcliffe
“Different diagnostic tests yield different results, depending on the cutoff for each assay. We need to harmonize the assays so clinicians are talking about the same thing,” Brendon Stiles, MD, associate professor of cardiothoracic surgery at Weill Cornell Medicine and New York-Presbyterian Hospital, New York City, told Medscape Medical News.
For Dr Stiles, these studies raise the issue that it is difficult to compare results of diagnostic testing across the different drugs and even with the same drug that are derived from different assays. “More importantly, it raises confusion in clinical practice when a patient’s sample stains positive for PD-L1 with one assay and negative with another,” he said.
“The commercial strategy for developing companion diagnostics for each drug is not in the best interests of the patients. It generates confusion among both clinicians and patients,” Dr Stiles commented. “We need to know if these assays can be used interchangeably,” he said.
As new agents come into the clinic, Dr Stiles believes there should be a universal yes-or-no answer, so that clinicians can use the assay to help decide on the use of immunotherapy.
Three Assays Tested
The study presented by Dr Radcliffe and colleagues investigated three commercially available assays, Ventana SP263, Dako 22C3, and Dako 28-8, with regard to how they compare at different cutoffs. Different studies use different cutoffs to express positivity.
Ventana SP263 was developed as a companion diagnostic for durvalumab (under development by AstraZeneca) using a rabbit monoclonal antibody. Positivity is defined as ≥25% staining of tumor cells.
Dako 22C3 was developed, and is approved, as a companion diagnostic for pembrolizumab. It uses a mouse monoclonal antibody. Positivity is defined as ≥1% and ≥50% staining of tumor cells.
Dako 28-8 was developed as a companion diagnostic for nivolumab and uses a rabbit monoclonal antibody (different from the one used in the Ventana SP263). In clinical practice, this assay is used as a complementary diagnostic for nivolumab, but the drug is approved for use regardless of PD-L1 expression. Positivity is defined as ≥1%, ≥5%, or ≥10% staining of tumor cells.
Ventana SP142 was not included in the study because it is not commercially available, Dr Ratcliffe indicated.
The three assays were used on consecutive sections of 500 archival NSCLC tumor samples obtained from commercial vendors. A single pathologist trained by the manufacturer read all samples in batches on an assay-by-assay basis. Samples were assessed per package inserts provided by Ventana and Dako in a Clinical Laboratory Improvement Amendments program-certified laboratory.
Dr Ratcliffe indicated that between reads of samples from the same patient, there was a washout period for the pathologist to remove bias.
The NSCLC samples included patients with stage I (38%), II (39%), III (20%), and IV (<1%) disease. Histologies included nonsquamous (54%) and squamous (43%) cancers.
All three PD-L1 assays showed similar patterns of staining in the range of 0% to 100%, Dr Ratcliffe indicated.
The correlation between any two of the assays was determined from tumor cell membrane staining. The correlation was linear with Spearman correlation of 0.911 for Ventana SP263 vs Dako 22C3; 0.935 for Ventana SP263 vs Dako 28-8; and 0.954 for Dako 28-8 vs Dako 22C3.
“With an overall predictive value of >90%, the assays have closely aligned dynamic ranges, but more work is needed,” Dr Ratcliffe said. “In general, scoring of immunohistochemical assays can be more variable between 1% and 10%, and we plan to look at this in more detail,” she said. These samples need to be reviewed by an independent pathologist, she added.
Dr Radcliffe said that currently, “Direct clinical efficacy data supporting a specific diagnostic test should still be considered as the highest standard of proof for diagnostic clinical utility.”
Why Correlations Are Needed
Pembrolizumab is approved for use only in patients with PD-L1-positive, previously treated NSCLC. A similar patient profile is being considered for nivolumab, for which testing for PD-L1 expression is not required.
For new PD-immunotherapy agents in clinical development, it is not clear whether PD-L1 testing will be mandated.
However, in clinical practice, it is clear that some patients respond to therapy, even if they are PD-L1 negative, as defined from the study. “Is it a failure of the assay, tumor heterogeneity, or is there another time point when PD-L1 expression is turned on?” Dr Stiles asked.
Dr Stiles also pointed out that a recent publication from Yale researchers showed a high a rate of discordance. In this study, PD-L1 expression was determined using two rabbit monoclonal antibodies. Both of these were different from the ones used in the Ventana SP263 and Dako 28-8 assays.
In this study, whole-tissue sections from 49 NSCLC samples were used, and a corresponding tissue microarray was also used with the same 49 samples. Researchers showed that in 49 NSCLC tissue samples, there was intra-assay variability, with results showing fair to poor concordance with the two antibodies. “Assessment of 588 serial section fields of view from whole tissue showed discordant expression at a frequency of 25%.
“Objective determination of PD-L1 protein levels in NSCLC reveals heterogeneity within tumors and prominent interassay variability or discordance. This could be due to different antibody affinities, limited specificity, or distinct target epitopes. Efforts to determine the clinical value of these observations are under way,” the study authors conclude.
The Blueprint Proposal
Coincidentally, a blueprint proposal was announced here at the AACR meeting at a workshop entitled FDA-AACR-ASCO Complexities in Personalized Medicine: Harmonizing Companion Diagnostics across a Class of Targeted Therapies.
The blueprint proposal was developed by four pharmaceutical giants (Bristol-Myers Squibb Company, Merck & Co, Inc, AstraZeneca PLC, and Genentech, Inc) and two diagnostic companies (Agilent Technologies, Inc/Dako Corp and Roche/Ventana Medical Systems, Inc).
In this proposal, the development of an evidence base for PD-1/PD-L1 companion diagnostic characterization for NSCLC would be built into studies conducted in the preapproval stage. Once the tests are approved, the information will lay the foundation for postapproval studies to inform stakeholders (eg, patients, physicians, pathologists) on how the test results can best be used to make treatment decisions.
Importance Early-phase trials with monoclonal antibodies targeting PD-1 (programmed cell death protein 1) and PD-L1 (programmed cell death 1 ligand 1) have demonstrated durable clinical responses in patients with non–small-cell lung cancer (NSCLC). However, current assays for the prognostic and/or predictive role of tumor PD-L1 expression are not standardized with respect to either quantity or distribution of expression.
Objective To demonstrate PD-L1 protein distribution in NSCLC tumors using both conventional immunohistochemistry (IHC) and quantitative immunofluorescence (QIF) and compare results obtained using 2 different PD-L1 antibodies.
Design, Setting, and Participants PD-L1 was measured using E1L3N and SP142, 2 rabbit monoclonal antibodies, in 49 NSCLC whole-tissue sections and a corresponding tissue microarray with the same 49 cases. Non–small-cell lung cancer biopsy specimens from 2011 to 2012 were collected retrospectively from the Yale Thoracic Oncology Program Tissue Bank. Human melanoma Mel 624 cells stably transfected with PD-L1 as well as Mel 624 parental cells, and human term placenta whole tissue sections were used as controls and for antibody validation. PD-L1 protein expression in tumor and stroma was assessed using chromogenic IHC and the AQUA (Automated Quantitative Analysis) method of QIF. Tumor-infiltrating lymphocytes (TILs) were scored in hematoxylin-eosin slides using current consensus guidelines. The association between PD-L1 protein expression, TILs, and clinicopathological features were determined.
Main Outcomes and Measures PD-L1 expression discordance or heterogeneity using the diaminobenzidine chromogen and QIF was the main outcome measure selected prior to performing the study.
Results Using chromogenic IHC, both antibodies showed fair to poor concordance. The PD-L1 antibodies showed poor concordance (Cohen κ range, 0.124-0.340) using conventional chromogenic IHC and showed intra-assay heterogeneity (E1L3N coefficient of variation [CV], 6.75%-75.24%; SP142 CV, 12.17%-109.61%) and significant interassay discordance using QIF (26.6%). Quantitative immunofluorescence showed that PD-L1 expression using both PD-L1 antibodies was heterogeneous. Using QIF, the scores obtained with E1L3N and SP142 for each tumor were significantly different according to nonparametric paired test (P < .001). Assessment of 588 serial section fields of view from whole tissue showed discordant expression at a frequency of 25%. Expression of PD-L1 was correlated with high TILs using both E1L3N (P = .007) and SP142 (P = .02).
Conclusions and Relevance Objective determination of PD-L1 protein levels in NSCLC reveals heterogeneity within tumors and prominent interassay variability or discordance. This could be due to different antibody affinities, limited specificity, or distinct target epitopes. Efforts to determine the clinical value of these observations are under way.
A Blueprint Proposal for Companion Diagnostic Comparability
A highlight of the FDA-AACR-ASCO Complexities in Personalized Medicine: Harmonizing Companion Diagnostics across a Class of Targeted Therapies workshop was the unveiling of a blueprint proposal developed by four pharmaceutical companies (Bristol-Myers Squibb Company, Merck & Co. Inc., AstraZeneca PLC, and Genentech, Inc.) and two diagnostic companies (Agilent Technologies, Inc./Dako Corp and Roche/Ventana Medical Systems, Inc.). The proposed study would help build an evidence base for PD-1/PD-L1 companion diagnostic characterization for non-small cell lung cancer in the pre-approval stage, such that once the tests are approved, the information generated can lay the groundwork for post-approval studies that will help inform patients, physicians, pathologists, and others on how best to use the test results to determine treatment decisions.
Introduction We are in an era of rapid incorporation of basic scientific discoveries into the drug development pipeline. Currently, numerous sponsors are developing therapeutic products that may use similar or identical biomarkers for therapeutic selection, measured or detected by an in vitro companion diagnostic device. The current practice is to independently develop a companion diagnostic for each therapeutic. Thus, the matrix of therapeutics and companion diagnostics, if each therapeutic were approved in conjunction with a companion diagnostic, may present a complex challenge for testing and decision making in the clinic, potentially putting patients at risk if inappropriate diagnostic tests were used to make treatment decisions. To address this challenge, there is a desire to understand assay comparability and/or standardize analytical and clinical performance characteristics supporting claims that are shared across companion diagnostic devices. Pathologists and oncologists also need clarity on how to interpret test results to inform downstream treatment options for their patients.
Clearly using each of the companion diagnostics to select one of the several available targeted therapies in the same class is not practical and may be impossible. Likewise, having a single test or assay as a sole companion test for all of the multiple therapeutic options within a class is also impractical since the individual therapies have differing modes of action, intended use populations, specificities, safety and efficacy outcomes. Thus, a single assay or test may not adequately capture the appropriate patient population that may benefit (or not) from each individual therapeutic option within a class of therapies. Furthermore, aligning multiple sponsors’ study designs and timelines in order that they all adopt a single companion test may inadvertently slow down development of critical therapeutic products and delay patient access to these life-saving products.
Any solution to this challenge will be multifaceted and will, by necessity, involve multiple stakeholders. Thus, the US Food and Drug Administration (FDA), the American Association for Cancer Research (AACR) and American Society of Clinical Oncology (ASCO) convened a workshop titled “Complexities in Personalized Medicine: Harmonizing Companion Diagnostics Across a Class of Targeted Therapies” to draw out and assess possible solutions. Recognizing that the complex scientific, regulatory and market forces at play here require a collaborative effort, an industry workgroup volunteered to develop a blueprint proposal of potential solutions using nonsmall cell lung cancer (NSCLC) as the use case indication.
Goal and Scope of Blueprint The imminent arrival to the market of multiple PD1 / PD-L1 compounds and the possibility of one or more associated companion diagnostics is unprecedented in the field of oncology. Some may assume that since these products target the same biological pathway, they are interchangeable; however, each PD1/PD-L1 compound is unique with respect to its clinical pharmacology and each compound is being developed in the context of a unique biological scientific hypothesis and registration strategy. Similarly, each companion diagnostic has been optimized within the individual therapeutic development programs to meet specific development goals, e.g., 1) validation for patient selection, 2) subgroup analysis as a prognostic variable, or 3) enrichment.
Further, each companion diagnostic test is optimized for its specific therapy and with its own unique performance characteristics and scoring/interpretation guidelines.
The blueprint development group recognizes that to assume that any one of the available tests could be used for guiding the treatment decision with any one or all of the drugs available in this class presents a potential risk to patients that must be addressed.
The goal of this proposal is to agree and deliver, via cross industry collaboration, a package of information /data upon which analytic comparison of the various diagnostic assays may be conducted, potentially paving the way for post-market standardization and/or practice guideline development as appropriate.
A comparative study of PD-L1 diagnostic assays and the classification of patients as PD-L1 positive and PD-L1 negative
Presentation Time:
Monday, Apr 18, 2016, 8:00 AM -12:00 PM
Location:
Section 10
Poster Board Number:
18
Author Block:
Marianne J. Ratcliffe1, Alan Sharpe2, Anita Midha1, Craig Barker2, Paul Scorer2, Jill Walker2. 1AstraZeneca, Alderley Park, United Kingdom; 2AstraZeneca, Cambridge, United Kingdom
Abstract Body:
Background: PD-1/PD-L1 directed antibodies are emerging as effective therapeutics in multiple oncology settings. Keynote 001 and Checkmate 057 have shown more frequent response to PD-1 targeted therapies in NSCLC patients with high tumour PD-L1 expression than patients with low or no PD-L1 expression. Multiple diagnostic PD-L1 tests are available using different antibody clones, different staining protocols and diverse scoring algorithms. It is vital to compare these assays to allow appropriate interpretation of clinical outcomes. Such understanding will promote harmonization of PD-L1 testing in clinical practice.
Methods: Approximately 500 tumour biopsy samples from NSCLC patients, including squamous and non-squamous histologies, will be assessed using three leading PD-L1 diagnostics assays. PD-L1 assessment by the Ventana SP263 assay that is currently being used in Durvalumab clinical trials (positivity cut off: ≥25% tumour cells with membrane staining) will be compared with the Dako 28-8 assay (used in the Nivolumab Checkmate 057 trial at the 1%, 5% and 10% tumour membrane positivity cut offs), and the Dako 22C3 assay (used in the Pembrolizumab Keynote 001 trial) at the 1% and 50% cut offs).
Results: Preliminary data from 81 non-squamous patients indicated good concordance between the Ventana SP263 and Dako 28-8 assays. Optimal overall percent agreement (OPA) was observed between Dako 28-8 at the 10% cut off and the Ventana SP263 assay (OPA; 96%, Positive percent agreement (PPA); 91%, Negative percent agreement (NPA); 98%), where the Ventana SP263 assay was set as the reference. Data on the full cohort will be presented for all three assays, and a lower 95% confidence interval calculated using the Clopper-Pearson method.
Conclusions: This study indicates that the patient population defined by Ventana SP263 at the 25% cut off is similar to that identified by the Dako-28-8 assay at the 10% tumour membrane cut off. This, together with data on the 22C3 assay, will enable cross comparison of studies using different PD-L1 tests, and widen options for harmonization of PD-L1 diagnostic testing.
Approximately two-thirds of cancer patients who received a programmed death 1 (PD-1) or programmed death ligand 1 (PD-L1) inhibitor in clinical trials experienced treatment-related adverse events, according to a systematic review and meta-analysis recently published in JAMA Oncology. The study findings may facilitate discussions with cancer patients who are considering PD-1 or PD-L1 therapy.
“The vast majority of patients with advanced cancer want to be on the [PD-1 or PD-L1] therapy,” Eric H. Bernicker, MD, a thoracic medical oncologist with Houston Methodist Cancer Center, told Cancer Network. Not involved in the current study, Bernicker explained that patients perceive these therapies to have “very different” side effects and risks from chemotherapy.
While they do, Bernicker explained, it’s important to underscore, which this study does, that these are not “completely innocuous” therapies. The study findings allow physicians to give numbers to patients and families when counseling them about the risks involved, he said.
The systematic review and meta-analysis is based on data from 125 clinical trials and 20,128 participants. Clinical trials were identified by systematically searching for published clinical trials that evaluated single-agent PD-1 and PD-L1 inhibitors and reported treatment-related adverse events in PubMed, Web of Science, Embase, and Scopus. The majority of trials evaluated nivolumab (n = 46) or pembrolizumab (n = 49), and the most common cancer types were lung cancer (n = 26), genitourinary cancer (n = 22), melanoma (n = 16), and gastrointestinal cancer (n = 14).
In all, 66.0% of clinical trial participants reported at least 1 adverse event of any grade, and 14.0% reported at least 1 grade 3 or higher adverse event. The most frequently reported adverse events of any grade were fatigue (18.26%), pruritus (10.61%), and diarrhea (9.47%). As for grade 3 or higher events, the most commonly reported were fatigue (0.89%), anemia (0.78%), and aspartate aminotransferase (AST) increase (0.75%).
Frequently reported immune-related adverse events of any grade included diarrhea (9.47%), AST increase (3.39%), vitiligo (3.26%), alanine aminotransferase (ALT) increase (3.14%), pneumonitis (2.79%), and colitis (1.24%). Grade 3 or higher immune-related adverse events included AST increase (0.75%), ALT increase (0.70%), pneumonitis (0.67%), diarrhea (0.59%), and colitis (0.47%).
If present, certain adverse events had increased likelihood of being grade 3 or higher, including hepatitis (risk ratio [RR], 50.59%), pneumonitis (RR, 24.01%), type 1 diabetes (RR, 41.86%), and colitis (RR, 37.90%).
“In terms of the rough percentage of side effects and the breadth of the side effects, this is pretty much what most of us see in the clinic,” Bernicker said, noting that none of the findings were particularly surprising.
Although no differences in adverse event incidence were found across different cancer types, differences were found between PD-1 and PD-L1 inhibitors in a subgroup analysis. Overall, compared with PD-L1 inhibitors, PD-1 inhibitors had a higher mean incidence of grade 3 or higher events (odds ratio [OR], 1.58; 95% CI, 1.00–2.54). Specifically, nivolumab had a higher mean incidence of grade 3 or higher events (OR, 1.81; 95% CI, 1.04–3.01) compared with PD-L1 inhibitors.
Bernicker commented that these incidence differences on the basis of drug type were “intriguing” but not clinically useful, given that PD-1 and PD-L1 inhibitors are not interchangeable. He said the finding “needs to be further looked at.”













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
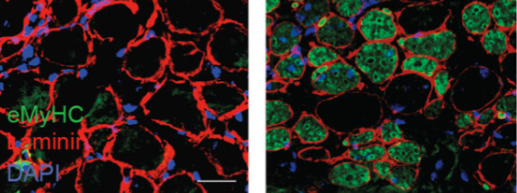{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}