CRACKING THE CODE OF HUMAN LIFE: The Birth of BioInformatics & Computational Genomics
Author and Curator: Larry H Bernstein, MD, FCAP
The previous Part II: Cracking the Code of Human Life,
Part II From Molecular Biology to Translational Medicine:How Far Have We Come, and Where Does It Lead Us? Is broken into a three part series.
Part II A. “CRACKING THE CODE OF HUMAN LIFE: Milestones along the Way” reviews the Human Genome Project and the decade beyond.
Part IIB. “CRACKING THE CODE OF HUMAN LIFE: The Birth of BioInformatics & Computational Genomics” lays the manifold multivariate systems analytical tools that has moved the science forward to a groung that ensures clinical application.
Part IIC. “CRACKING THE CODE OF HUMAN LIFE: Recent Advances in Genomic Analysis and Disease “ extends the discussion to advances in the management of patients as well as providing a roadmap for pharmaceutical drug targeting.
Part III concludes with Ubiquitin, it’s role in Signaling and Regulatory Control.
This article is a continuation of a previous discussion on the role of genomics in discovery of therapeutic targets titled, Directions for Genomics in Personalized Medicine, which focused on: key drivers of cellular proliferation, stepwise mutational changes coinciding with cancer progression, and potential therapeutic targets for reversal of the process. And it is a direct extension of Cracking the Code of Human Life (Part I): “the initiation phase of molecular biology”.
These articles review a web-like connectivity between inter-connected scientific discoveries, as significant findings have led to novel hypotheses and many expectations over the last 75 years. This largely post WWII revolution has driven our understanding of biological and medical processes at an exponential pace owing to successive discoveries of chemical structure,
- the basic building blocks of DNA and proteins,
- of nucleotide and protein-protein interactions,
- protein folding, allostericity,
- genomic structure,
- DNA replication,
- nuclear polyribosome interaction, and
- metabolic control.
In addition, the emergence of methods
- for copying,
- removal and
- insertion, and
- improvements in structural analysis as well as
- developments in applied mathematics have transformed the research framework.
CRACKING THE CODE OF HUMAN LIFE: The Birth of BioInformatics & Computational Genomics Computational Genomics I. Three-Dimensional Folding and Functional Organization Principles of The Drosophila Genome Sexton T, Yaffe E, Kenigeberg E, Bantignies F,…Cavalli G. Institute de Genetique Humaine, Montpelliere GenomiX, and Weissman Institute, France and Israel. Cell 2012; 148(3): 458-472. http://dx.doi.org/10.1016/j.cell.2012.01.010/
Chromosomes are the physical realization of genetic information and thus
- form the basis for its readout and propagation.
Here we present a high-resolution chromosomal contact map derived from
- a modified genome-wide chromosome conformation capture approach
- applied to Drosophila embryonic nuclei.
the entire genome is linearly partitioned into
- well-demarcated physical domains that
- overlap extensively with
- active and repressive epigenetic marks.
Chromosomal contacts are hierarchically organized between domains.
Global modeling of contact density and clustering of domains show
- that inactive domains are condensed and
- confined to their chromosomal territories, whereas
- active domains reach out of the territory to form
- remote intra- and interchromosomal contacts.
Moreover, we systematically identify specific
- long-range intrachromosomal contacts between
- Polycomb-repressed domains.
Together, these observations allow for
- quantitative prediction of the Drosophila chromosomal contact map,
- laying the foundation for detailed studies of
- chromosome structure and function in
- a genetically tractable system.
Insert pictures

profiles validate the Hi-C Genome wide map
IIC. “Mr. President; The Genome is Fractal !” Eric Lander
(Science Adviser to the President and Director of Broad Institute) et al.
delivered the message on Science Magazine cover (Oct. 9, 2009) and
generated interest in this by the International HoloGenomics Society at
a Sept meeting.
- First, it may seem to be trivial to rectify the statement in “About cover”
of Science Magazine by AAAS. The statement “the Hilbert curve is a
one-dimensional fractal trajectory” needs mathematical clarification.
While the paper itself does not make this statement, the new Editorship
of the AAAS Magazine might be even more advanced if the previous
Editorship did not reject (without review) a Manuscript by 20+ Founders
of (formerly) International PostGenetics Society in December, 2006.
- Second, it may not be sufficiently clear for the reader that the
reasonable requirement for the DNA polymerase to crawl along
a “knot-free” (or “low knot”) structure does not need fractals. A
“knot-free” structure could be spooled by an ordinary “knitting globule”
(such that the DNA polymerase does not bump into a “knot” when
duplicating the strand; just like someone knitting can go through
the entire thread without encountering an annoying knot): Just to
be “knot-free” you don’t need fractals.
Note, however, that the “strand” can be accessed only at its beginning –
it is impossible to e.g.
- to pluck a segment from deep inside the “globulus”.
This is where certain fractals provide a major advantage – that could be
- the “Eureka” moment for many readers.
For instance, the mentioned Hilbert-curve is not only “knot free” – but
- provides an easy access to “linearly remote” segments of the strand.
If the Hilbert curve starts from the lower right corner and ends at the lower left corner,
- for instance the path shows the very easy access of what would be the mid-point
- if the Hilbert-curve is measured by
- the Euclidean distance along the zig-zagged path.
Likewise, even the path from the beginning of the Hilbert-curve is about equally easy to access –
- easier than to reach from the origin a point that is about 2/3 down the path.
The Hilbert-curve provides an easy access between two points
- within the “spooled thread”;
from a point that is about 1/5 of the overall length
- to about 3/5 is also in a “close neighborhood”.
This may be the “Eureka-moment” for some readers, to realize that
- the strand of “the Double Helix” requires quite a finess to fold into
- the densest possible globuli (the chromosomes) in a clever way
- that various segments can be easily accessed.
Moreover, in a way that distances
- between various segments are minimized.
This marvelous fractal structure
- is illustrated by the 3D rendering of the Hilbert-curve.
Once you observe such fractal structure, you’ll never again think of
- a chromosome as a “brillo mess”, would you?
It will dawn on you that the genome is orders of magnitudes more
- finessed than we ever thought so.
Insert picture
profiles validate the Hi-C Genome wide map
Those embarking at a somewhat complex review of some
- historical aspects of the power of fractals may wish to consult
- the ouvre of Mandelbrot (also, to celebrate his 85th birthday).
For the more sophisticated readers, even the fairly simple
Hilbert-curve (a representative of the Peano-class) becomes
- even more stunningly brilliant than just some “see through density”.
Those who are familiar with the classic “Traveling Salesman Problem”
- know that “the shortest path along which every given n locations can
- be visited once, and only once” requires fairly sophisticated algorithms
- (and tremendous amount of computation if n>10 (or much more).
Some readers will be amazed, therefore, that for n=9 the underlying Hilbert-curve
Briefly, the significance of the above realization, that the (recursive)
- Fractal Hilbert Curve is intimately connected to the
- (recursive) solution of TravelingSalesman Problem,
- a core-concept of Artificial Neural Networks summarized below.
Accomplished physicist John Hopfield aroused great excitement in 1982
(already a member of the National Academy of Science)
with his (recursive) design of artificial neural networks and learning algorithms
which were able to find reasonable solutions to combinatorial problems
such as the Traveling SalesmanProblem.
(Book review Clark Jeffries, 1991; 1. J. Anderson, R. Rosenfeld, and
A. Pellionisz (eds.), Neurocomputing 2: Directions for research, MIT
Press, Cambridge, MA, 1990):
“Perceptions were modeled chiefly with neural connections in a
- “forward” direction: A -> B -* C — D.
The analysis of networks with strong
- backward coupling proved intractable.
All our interesting results arise as consequences of the strong
- back-coupling” (Hopfield, 1982).
The Principle of Recursive Genome Function surpassed obsolete
- axioms that blocked, for half a Century,
- entry of recursive algorithms to interpretation
- of the structure-and function of (Holo)Genome.
This breakthrough, by uniting the two largely separate fields of
- Neural Networks and Genome Informatics,
is particularly important for those who focused on
- Biological (actually occurring) Neural Networks
- (rather than abstract algorithms that may not, or
- because of their core-axioms, simply could not
- represent neural networks under the governance of DNA information).
IIIA. The FractoGene Decade from Inception in 2002 to Proofs of Concept and
Impending Clinical Applications by 2012
- Junk DNA Revisited (SF Gate, 2002)
- The Future of Life, 50th Anniversary of DNA (Monterey, 2003)
- Mandelbrot and Pellionisz (Stanford, 2004)
- Morphogenesis, Physiology and Biophysics (Simons, Pellionisz 2005)
- PostGenetics; Genetics beyond Genes (Budapest, 2006)
- ENCODE-conclusion (Collins, 2007)
- The Principle of Recursive Genome Function (paper, YouTube, 2008)
- You Tube Cold Spring Harbor presentation of FractoGene (Cold Spring Harbor, 2009)
- Mr. President, the Genome is Fractal! (2009)
- HolGenTech, Inc. Founded (2010)
- Pellionisz on the Board of Advisers in the USA and India (2011)
- ENCODE – final admission (2012)
- Recursive Genome Function is Clogged by Fractal Defects in Hilbert-Curve (2012)
- Geometric Unification of Neuroscience and Genomics (2012)
- US Patent Office issues FractoGene 8,280,641 to Pellionisz (2012)
file:///C|/Documents_and_Settings/Andras/Desktop/The_FractoGene_Decade_cover_page.htm 2012.12.16. 12:36:55
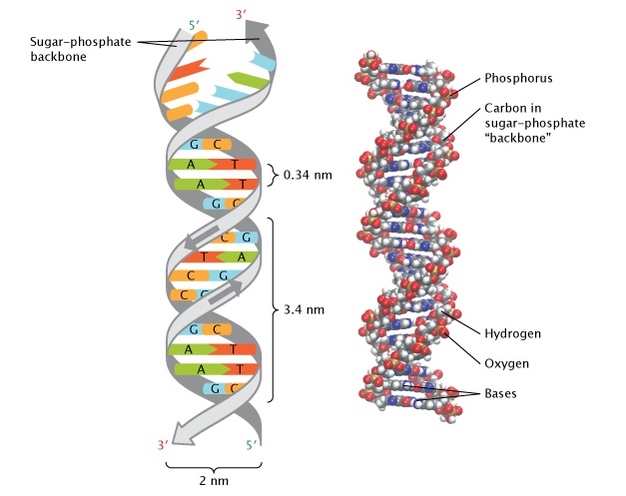
When the human genome was first sequenced in June 2000, there were two pretty big surprises.
The first was that humans have only about 30,000-40,000 identifiable genes,
- not the 100,000 or more many researchers were expecting.
The lower –and more humbling — number
- means humans have just one-third
- more genes than a common species of worm.
The second stunner was how much human genetic material — more than 90 percent —
- is made up of what scientists were calling “junk DNA.”
The term was coined to describe similar but
- not completely identical repetitive sequences of amino acids
(the same substances that make genes),
- which appeared to have no function or purpose.
The main theory at the time was that these apparently
- non-working sections of DNA were
- just evolutionary leftovers, much like our earlobes.
If biophysicist Andras Pellionisz is correct, genetic science
- may be on the verge of yielding its third — and
- by far biggest — surprise.
With a doctorate in physics, Pellionisz is the holder of Ph.D.’s
- in computer sciences and experimental biology from the
prestigious Budapest Technical University and
the Hungarian National Academy of Sciences.
A biophysicist by training, the 59-year-old is a former research
- associate professor of physiology and biophysics at New York University,
- author of numerous papers in respected scientific journals and textbooks,
- a past winner of the prestigious Humboldt Prize for scientific research,
- a former consultant to NASA and
- holder of a patent on the world’s first artificial cerebellum,
a technology that has already been integrated into research
on advanced avionics systems.
Because of his background, the Hungarian-born brain researcher might
- also become one of the first people to successfully launch a new company
- by using the Internet to gather momentum for a novel scientific idea.
The genes we know about today, Pellionisz says, can be thought of as something
- similar to machines that make bricks (proteins, in the case of genes), with certain
- junk-DNA sections providing a blueprint for the
- different ways those proteins are assembled.
The notion that at least certain parts of junk DNA might have a purpose for example,
- many researchers now refer to
- with a far less derogatory term: introns.
Insert picture

3-d-genome-map
In a provisional patent application filed July 31, Pellionisz claims to have
- unlocked a key to the hidden role junk DNA plays in growth — and in life itself.
His patent application covers all attempts to
- count,
- measure and
- compare
the fractal properties of introns
- for diagnostic and therapeutic purposes.
IIIB. The Hidden Fractal Language of Intron DNA
To fully understand Pellionisz’ idea,
- one must first know what a fractal is.
Fractals are a way that nature organizes matter.
Fractal patterns can be found
- in anything that has a nonsmooth surface (unlike a billiard ball),
- such as coastal seashores,
- the branches of a tree or
- the contours of a neuron (a nerve cell in the brain).
Some, but not all, fractals are self-similar and
- stop repeating their patterns at some stage
the branches of a tree, for example,
Because they are geometric, meaning they have a shape,
- fractals can be described in mathematical terms.
It’s similar to the way a circle can be described
- by using a number to represent its radius
(the distance from its center to its outer edge).
When that number is known, it’s possible to draw the circle it represents
- without ever having seen it before.
Although the math is much more complicated,
- the same is true of fractals.
If one has the formula for a given fractal,
- it’s possible to use that formula to construct, or reconstruct,
- an image of whatever structure it represents,
- no matter how complicated.
The mysteriously repetitive but not identical strands of genetic material
- are in reality building instructions organized in
- a special type of pattern known as a fractal.
It’s this pattern of fractal instructions, he says, that tells genes what they
- must do in order to form living tissue,
- everything from the wings of a fly to the entire body of a full-grown human.
In a move sure to alienate some scientists,
- Pellionisz has chosen the unorthodox route of
- making his initial disclosures online on his own Web site.
He picked that strategy, he says, because
- it is the fastest way he can document his claims
- and find scientific collaborators and investors.
Most mainstream scientists usually blanch at such approaches,
- preferring more traditionally credible methods, such as
- publishing articles in peer-reviewed journals.
Basically, Pellionisz’ idea is that
- a fractal set of building instructions in the DNA
- plays a similar role in organizing life itself.
Decode the way that language works, he says, and
- in theory it could be reverse engineered.
Just as knowing the radius of a circle lets one create that circle,
- the more complicated fractal-based formula
- would allow us to understand how nature creates a heart or
- simpler structures, such as disease-fighting antibodies.
At a minimum, we’d get a far better understanding of
- how nature gets that job done.
The complicated quality of the idea is helping encourage
- new collaborations across the boundaries that sometimes
- separate the increasingly intertwined disciplines of
- biology, mathematics and computer sciences.
Hal Plotkin, Special to SF Gate. Thursday, November 21, 2002.
http://www.junkdna.com/plotkin.htm
(1 of 10)2012.12.13. 12:11:58/ Hal Plotkin, Special to SF Gate.
Thursday, November 21, 2002
insert pictures

Hilbert3d

Hilbert512

Fractal Defects in the genome, repeat structural variants with their largest example of Copy Number Variants

Golden_ratio Fractal chaos Holographic neural network
IIIC. multifractal analysis
The human genome: a multifractal analysis.
Moreno PA, Vélez PE, Martínez E, et al. BMC Genomics 2011, 12:506.
http://www.biomedcentral.com/1471-2164/12/506
Background: Several studies have shown that genomes
- can be studied via a multifractal formalism.
Recently, we used a multifractal approach to study the
- genetic information content of the Caenorhabditis elegans genome.
Here we investigate the possibility that the human genome shows a
- similar behavior to that observed in the nematode.
Results: We report here multifractality in the human genome sequence.
This behavior correlates strongly on the presence of
- Alu elements and to a lesser extent on
- CpG islands and (G+C) content.
In contrast, no or low relationship was found for
- LINE, MIR, MER, LTRs elements and DNA regions
- poor in genetic information.
Gene function, cluster of orthologous genes, metabolic pathways, and exons
- tended to increase their frequencies with ranges of multifractality
- and large gene families were located in genomic regions with varied multifractality.
Additionally, a multifractal map and classification for human chromosomes are proposed.
Conclusions: we propose a descriptive non-linear model
for the structure of the human genome,
This model reveals a multifractal regionalization where
many regions coexist that are far from equilibrium and
this non-linear organization has significant molecular and medical genetic implications
- for understanding the role of Alu elements in genome stability
- and structure of the human genome.
Given the role of Alu sequences in
- adaptation and
- human genetic diversity,
- genetic diseases,
- gene regulation,
- phylogenetic analyses,
these quantifications are especially useful.
MiIP:The Monomer Identification and Isolation Program
Bun C, Ziccardi W, Doering J and Putonti C.
Evolutionary Bioinformatics 2012:8 293-300.
http://dx.doi.org:/10.4137/EBO.S9248
Repetitive elements within genomic DNA are
- both functionally and evolutionarilly informative.
Discovering these sequences ab initio
- is computationally challenging,
- compounded by the fact that sequence identity
- between repetitive elements can vary significantly.
Here we present a new application,
- the Monomer Identification and Isolation Program (MiIP),
- which provides functionality to both
- search for a particular repeat
- as well as discover repetitive elements within a larger genomic sequence.
To compare MiIP’s performance with other repeat detection tools,
- analysis was conducted for synthetic sequences as well as
- several a21-II clones and HC21 BAC sequences.
The primary benefit of MiIP is the fact that
- it is a single tool capable of searching for both known monomeric sequences
- as well as discovering the occurrence of repeats ab initio,
- per the user’s required sensitivity of the search
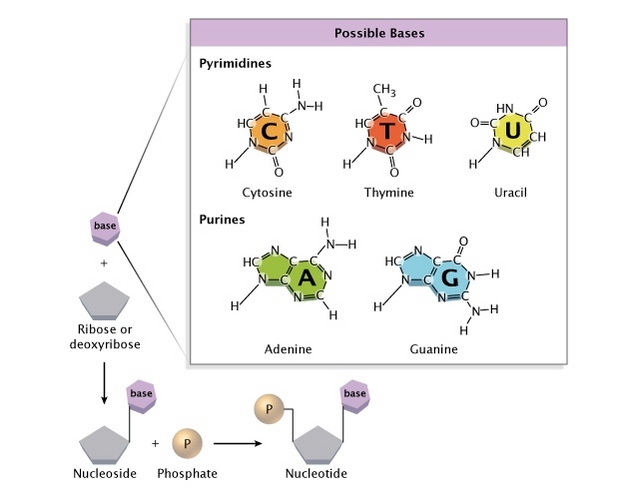
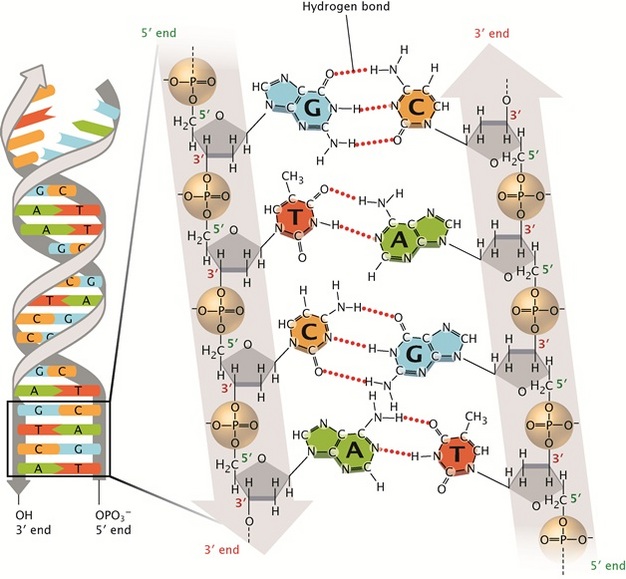
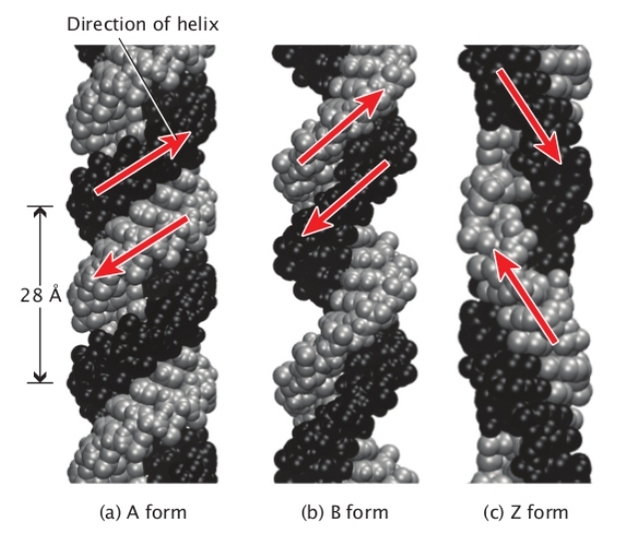
Triplex DNA A. A third strand for DNA
The DNA double helix can under certain conditions
- accommodate a third strand in its major groove.
Researchers in the UK have now presented a complete set of
- four variant nucleotides that makes it possible to use this phenomenon
- in gene regulation and mutagenesis.
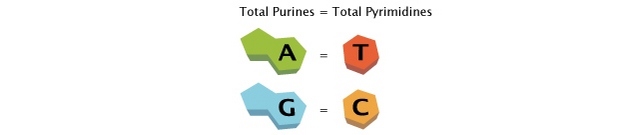
Natural DNA only forms a triplex
- if the targeted strand is rich in purines – guanine (G) and adenine (A) –
- which in addition to the bonds of the Watson-Crick base pairing
- can form two further hydrogen bonds, and the ‘third strand’ oligonucleotide
- has the matching sequence of pyrimidines – cytosine (C) and thymine (T).
Any Cs or Ts in the target strand of the duplex will only bind very weakly,
- as they contribute just one hydrogen bond.
Moreover, the recognition of G requires
- the C in the probe strand to be protonated,
- so triplex formation will only work at low pH.
To overcome all these problems, the groups of Tom Brown and Keith Fox
at the University of Southampton
- have developed modified building blocks, and have now
- completed a set of four new nucleotides, each of which will bind to one
- DNA nucleotide from the major groove of the double helix.1
They tested the binding of a 19-mer of these designer nucleotides
- to a double helix target sequence in comparison with the corresponding
- triplex-forming oligonucleotide made from natural DNA bases.
Using fluorescence-monitored thermal melting and DNase I footprinting,
- the researchers showed that their construct
- forms stable triplex even at neutral pH.
Tests with mutated versions of the target sequence showed that
- three of the novel nucleotides are highly selective for their target base pair,
- while the ‘S’ nucleotide, designed to bind to T, also tolerates C.
In principle, triplex formation has already been demonstrated as
- a way of inducing mutations in cell cultures and animal experiments.2
Michael Gross
References
1 DA Rusling et al, Nucleic Acids Res. 2005, 33, 3025
http://NucleicAcidsRes.com/Rusling_DA
2 KM Vasquez et al, Science 2000, 290, 530
http://Science.org/Vazquez_KM
B. Triplex DNA Structures.
Triplex DNA Structures. Frank-Kamenetskii, Mirkin SM. Annual Rev Biochem 1995; 64:69-95./ www.annualreviews.org/aronline
Since the pioneering work of Felsenfeld, Davies, & Rich (1),
- double-stranded polynucleotides containing purines in one strand
- and pydmidines in the other strand
[such as poly(A)/poly(U), poly(dA)/poly(dT), or poly(dAG)/poly(dCT)]
- have been known to be able to undergo a
- stoichiometric transition forming a triple-stranded structure containing
- one polypurine and two polypyrimidine strands.
Early on, it was assumed that the third strand was located in the major groove
- and associated with the duplex via non-Watson-Crick interactions
- now known as Hoogsteen pairing.
Insert pictures

triplex DNA
Triple helices consisting of one pyrimidine and
- two purine strands were also proposed.
However, notwithstanding the fact that single-base triads
- in tRNAs tructures were well-documented,
- triple-helical DNA escaped wide attention before the mid-1980s.
The considerable modern interest in DNA triplexes arose
- due to two partially independent developments.
First, homopurine-homopyrimidine stretches in supercoiled plasmids
- were found to adopt an unusual DNA structure, called H-DNA which
- includes a triplex as the major structural element.
Secondly, several groups demonstrated that homopyrimidine and
- some purine-rich oligonucleotides
- can form stable and sequence-specific complexes
- with corresponding homopurine-homopyrimidine sites on duplex DNA.
These complexes were shown to be triplex structures rather than D-loops,
- where the oligonucleotide invades the double helix
- and displaces one strand.
A characteristic feature of all these triplexes is that the two chemically
- homologous strands (both pyrimidine or both purine) are antiparallel.
These findings led explosive growth in triplex studies. One can easily imagine
- numerous “geometrical” ways to form a triplex, and
- those that have been studied experimentally.
The canonical intermolecular triplex consists of either
- three independent oligonucleotide chains or of
- a long DNA duplex carrying homopurine-homopyrimidine insert
- and the corresponding oligonucleotide.
Triplex formation strongly depends on the oligonucleotide(s) concentration.
A single DNA chain may also fold into a triplex connected by two loops.
To comply with the sequence and polarity requirements for triplex formation,
- such a DNA strand must have a peculiar sequence:
It contains a mirror repeat
(homopyrimidine for YR*Y triplexes and homopurine for YR*R triplexes)
- flanked by a sequence complementary to
- one half of this repeat.
Such DNA sequences fold into
- triplex configuration much more readily than do
- the corresponding intermolecular triplexes, because
- all triplex forming segments are brought together within the same molecule.
Insert pictures
It has become clear recently, however, that
- both sequence requirements and chain polarity rules for triplex formation
- can be met by DNA target sequences
- built of clusters of purines and pyrimidines.
The third strand consists of adjacent homopurine and homopyrimidine blocks
- forming Hoogsteen hydrogen bonds with purines
- on alternate strands of the target duplex, andthis strand switch
- preserves the proper chain polarity.
These structures, called alternate-strand triplexes,
- have been experimentally observed as both intra- and intermolecular triplexes.
These results increase the number of
- potential targets for triplex formation in natural DNAs
- somewhat by adding sequences composed of purine and pyrimidine clusters,
- although arbitrary sequences are still not targetable
- because strand switching is energetically unfavorable.
References:
Lyamichev VI, Mirkin SM, Frank-Kamenetskii MD.
J. Biomol. Stract. Dyn. 1986; 3:667-69.
http://JbiomolStractDyn.com/Lyamichev_VI/
Mirkin SM, Lyamichev VI, Drushlyak KN, Dobrynin VN0 Filippov SA, Frank-Kamenetskii MD.
Nature 1987; 330:495-97.
http://Nature.com/
Demidov V, Frank-Kamenetskii MD, Egholm M, Buchardt O, Nielsen PE.
Nucleic Acids Res. 1993; 21:2103-7.
http://NucleicAcidsResearch.com/
Mirkin SMo Frank-Kamenetskii MD.
Anna. Rev. Biophys. Biomol. Struct. 1994; 23:541-76.
http://AnnRevBiophysBiomolecStructure.com/
Hoogsteen K.
Acta Crystallogr. 1963; 16:907-16
http://ActaCrystallogr.com/
Malkov VA, Voloshin ON, Veselkov AG, Rostapshov VM, Jansen I, et al.
Nucleic Acids Res. 1993; 21:105-11.
http://NucleicAidsResearch.com/
Malkov VA, Voloshin ON, Soyfer VN, Frank-Kamenetskii MD.
Nucleic Acids Res. 1993; 21:585-91
Chemy DY, Belotserkovskii BP,Frank-Kamenetskii MD,
Egholm M, Buchardt O, et al.
Proc. Natl. Acad. Sci. USA 1993; 90:1667-70
http://PNAS.org/
C.Triplex forming oligonucleotides
Triplex forming oligonucleotides: sequence-specific tools for genetic targeting.
Knauert MP, Glazer PM. Human Molec Genetics 2001; 10(20):2243-2251. http://HumanMolecGenetics.com/Triplex_forming_oligonucleotides:
sequence-specific_tools_for _genetic_targeting.
Triplex forming oligonucleotides (TFOs) bind in the major groove of duplex DNA
- with a high specificity and affinity.
Because of these characteristics,
- TFOs have been proposed as homing devices
- for genetic manipulation in vivo.
These investigators review work demonstrating the ability of TFOs and
- related molecules to alter gene expression and
- mediate gene modification in mammalian cells.
TFOs can mediate targeted gene knock out in mice,
- providing a foundation for potential application
- of these molecules in human gene therapy.
D. Novagon DNA
John Allen Berger, founder of Novagon DNA and
- The Triplex Genetic Code Over the past 12+ years,
Novagon DNA has amassed a vast array of empirical findings
- which challenge the “validity” of the “central dogma theory”,
- especially the current five nucleotide Watson-Crick DNA and
- RNA genetic codes. DNA = A1T1G1C1, RNA =A2U1G2C2.
We propose that our new Novagon DNA 6 nucleotide Triplex Genetic Code
- has more validity than the existing 5 nucleotide (A1T1U1G1C1)
- Watson-Crick genetic codes.
Our goal is to conduct a “world class” validation study
- to replicate and extend our findings.
Methods for Examining Genomic and Proteomic Interactions
A. An Integrated Statistical Approach to Compare
Transcriptomics Data Across Experiments:
A Case Study on the Identification of Candidate Target Genes
of the Transcription Factor PPARα
Ullah MO, Müller M and Hooiveld GJEJ.
Bioinformatics and Biology Insights 2012:6 145–154.

binding-of-a-ppar-ligand-to-the-ppar-ligand-binding-domain
http://bionformaticsandBiologyInsights.com/An_Integrated_Statistical_Approach_to_Compare_ transcriptomic_Data_Across_Experiments-A-Case_Study_on_the_Identification_ of_Candidate_Target_Genes_of_the Transcription_Factor_PPARα/
Corresponding author email: guido.hooiveld@wur.nl
An effective strategy to elucidate the signal transduction cascades
- activated by a transcription factor is to compare the transcriptional profiles
- of wild type and transcription factor knockout models.
Many statistical tests have been proposed for analyzing gene expression data,
- but most tests are based on pair-wise comparisons.
Since the analysis of micro-arrays involves the testing of
- multiple hypotheses within one study, it is generally accepted that one should
- control for false positives by the false discovery rate (FDR).
However, it has been reported that
- this may be an inappropriate metric for
- comparing data across different experiments.
Here we propose an approach that addresses the above mentioned problem
- by the simultaneous testing and integration of the three hypotheses (contrasts)
- using the cell means ANOVA model.
These three contrasts test for the effect of a treatment in
- wild type,
- gene knockout, and
- globally over all experimental groups.
We illustrate our approach on microarray experiments that focused
- on the identification of candidate target genes and biological processes
- governed by the fatty acid sensing transcription factor PPARα in liver.
Compared to the often applied FDR based across experiment comparison,
- our approach identified a conservative
- but less noisy set of candidate genes
- with same sensitivity and specificity.
However, our method had the advantage of properly adjusting for
- multiple testing while integrating data from two experiments,
- and was driven by biological inference.
We present a simple, yet efficient strategy to compare
- differential expression of genes across experiments
- while controlling for multiple hypothesis testing.
B. Managing biological complexity across orthologs with a visual knowledge-base
of documented biomolecular interactions Vincent VanBuren & Hailin Chen
Scientific Reports 2, Article number: 1011
http://dx.doi.org:/10.1038/srep01011
Received 02 October 2012 Accepted 04 December 2012
The complexity of biomolecular interactions and influences
- is a major obstacle to their comprehension and elucidation.
Visualizing knowledge of biomolecular interactions
- increases comprehension and
- facilitates the development of new hypotheses.
The rapidly changing landscape of high-content experimental results
- also presents a challenge for the maintenance of comprehensive knowledgebases.
Distributing the responsibility for maintenance of a knowledgebase
- to a community of subject matter experts is an effective strategy
- for large, complex and rapidly changing knowledgebases.
Cognoscente serves these needs by building visualizations for queries
- of biomolecular interactions on demand,
- by managing the complexity of those visualizations, and by
- crowdsourcing to promote the incorporation of current knowledge
- from the literature.
Imputing functional associations between
- biomolecules and imputing directionality of regulation for those predictions
- each require a corpus of existing knowledge as a framework to build upon.
Comprehension of the complexity of this corpus of knowledge
- will be facilitated by effective visualizations of
- the corresponding biomolecular interaction networks.
Cognoscente (http://vanburenlab.medicine.tamhsc.edu/cognoscente.html)
- was designed and implemented to serve these roles as a knowledgebase
- and as an effective visualization tool for systems biology research and education.
Cognoscente currently contains over 413,000 documented interactions,
- with coverage across multiple species.
Perl, HTML, GraphViz1, and a MySQL database were used in the development of Cognoscente.
Cognoscente was motivated by the need to update the knowledgebase
- of biomolecular interactions at the user level, and
- flexibly visualize multi-molecule query results for
- heterogeneous interaction types across different orthologs.
Satisfying these needs provides a strong foundation for
- developing new hypotheses about regulatory and metabolic pathway topologies.
Several existing tools provide functions that are similar to Cognoscente, so we selected several popular alternatives to assess how their feature sets compare with Cognoscente ( Table 1 ). All databases assessed had easily traceable documentation for each interaction, and included protein-protein interactions in the database.
Most databases, with the exception of BIND, provide an open-access database that can be downloaded as a whole.
Most databases, with the exceptions of EcoCyc and HPRD, provide
- support for multiple organisms.
Most databases support web services for
- interacting with the database contents programmatically,
- whereas this is a planned feature for Cognoscente.
INT, STRING, IntAct, EcoCyc, DIP and Cognoscente provide built-in
- visualizations of query results, which we consider
- among the most important features for facilitating comprehension of query results.
BIND supports visualizations via Cytoscape.
Cognoscente is among a few other tools that support
- multiple organisms in the same query,
- protein->DNA interactions, and
- multi-molecule queries.
Cognoscente has planned support for
- small molecule interactants (i.e. pharmacological agents).
MINT, STRING, and IntAct provide a prediction (i.e. score)
- of functional associations, whereas
- Cognoscente does not currently support this.
Cognoscente provides support for multiple edge encodings
- to visualize different types of interactions in the same display,
- a crowdsourcing web portal that allows users to submit
- interactions that are then automatically incorporated in the knowledgebase,
- and displays orthologs as compound nodes
- to provide clues about potential orthologous interactions.
The main strengths of Cognoscente are that it provides a combined feature set that is superior to any existing database, it provides a unique visualization feature for orthologous molecules, and relatively unique support for multiple edge encodings, crowdsourcing, and connectivity parameterization. The current weaknesses of Cognoscente relative to these other tools are that it does not fully support web service interactions with the database, it does not fully support small molecule interactants, and it does not score interactions to predict functional associations. Web services and support for small molecule interactants are currently under development.
Related references from Leaders in Pharmaceutical Intelligence:
Big Data in Genomic Medicine larryhbern
http://pharmaceuticalintelligence.com/2012/12/17/big-data-in-genomic-medicine/
BRCA1 a tumour suppressor in breast and ovarian cancer – functions in
transcription, ubiquitination and DNA repair
S Saha
http://pharmaceuticalintelligence.com/2012/12/04/brca1-a-tumour-suppressor-in-breast-and-ovarian-cancer-functions-in-transcription-ubiquitination-and-dna-repair/
Computational Genomics Center: New Unification of Computational Technologies at Stanford
A Lev-Ari http://pharmaceuticalintelligence.com/2012/12/03/computational-genomics-center-new-unification-of-computational-technologies-at-stanford/
Personalized medicine gearing up to tackle cancer
ritu saxena
http://pharmaceuticalintelligence.com/2013/01/07/personalized-medicine-gearing-up-to-tackle-cancer/
Differentiation Therapy – Epigenetics Tackles Solid Tumors
SJ Williams http://pharmaceuticalintelligence.com/2013/01/03/differentiation-therapy-epigenetics-tackles-solid-tumors/
Mechanism involved in Breast Cancer Cell Growth: Function in Early Detection & Treatment
A Lev-Ari
http://pharmaceuticalintelligence.com/2013/01/17/mechanism-involved-in-breast-cancer-cell-growth-function-in-early-detection-treatment/
The Molecular pathology of Breast Cancer Progression
tilde barliya
http://pharmaceuticalintelligence.com/2013/01/10/the-molecular-pathology-of-breast-cancer-progression/
Gastric Cancer: Whole-genome reconstruction and mutational signatures
A Lev-Ari
http://pharmaceuticalintelligence.com/2012/12/24/gastric-cancer-whole-genome-reconstruction-and-mutational-signatures-2/
Paradigm Shift in Human Genomics – Predictive Biomarkers and Personalized Medicine – Part 1 (pharmaceuticalintelligence.com)
A Lev-Ari
http://pharmaceuticalintelligence.com/2013/01/13/paradigm-shift-in-human-genomics-predictive-biomarkers-and-personalized-medicine-part-1/
LEADERS in Genome Sequencing of Genetic Mutations for Therapeutic Drug Selection in Cancer Personalized Treatment: Part 2
A Lev-Ari
http://pharmaceuticalintelligence.com/2013/01/13/leaders-in-genome-sequencing-of-genetic-mutations-for-therapeutic-drug-selection-in-cancer-personalized-treatment-part-2/
Personalized Medicine: An Institute Profile – Coriell Institute for Medical Research: Part 3
A Lev-Ari
http://pharmaceuticalintelligence.com/2013/01/13/personalized-medicine-an-institute-profile-coriell-institute-for-medical-research-part-3/
Harnessing Personalized Medicine for Cancer Management, Prospects of Prevention and Cure: Opinions of Cancer Scientific Leaders @ http://pharmaceuticalintelligence.com
A Lev-Ari
http://pharmaceuticalintelligence.com/2013/01/13/7000/Harnessing_Personalized_Medicine_for_ Cancer_Management-Prospects_of_Prevention_and_Cure/
GSK for Personalized Medicine using Cancer Drugs needs Alacris systems biology model to determine the in silico effect of the inhibitor in its “virtual clinical trial”
A Lev-Ari
http://pharmaceuticalintelligence.com/2012/11/14/gsk-for-personalized-medicine-using-cancer-drugs-needs-alacris-systems-biology-model-to-determine-the-in-silico-effect-of-the-inhibitor-in-its-virtual-clinical-trial/
Recurrent somatic mutations in chromatin-remodeling and ubiquitin ligase complex genes in serous endometrial tumors
S Saha
http://pharmaceuticalintelligence.com/2012/11/19/recurrent-somatic-mutations-in-chromatin-remodeling-and-ubiquitin-ligase-complex-genes-in-serous-endometrial-tumors/
Personalized medicine-based cure for cancer might not be far away ritu saxena http://pharmaceuticalintelligence.com/2012/11/20/personalized-medicine-based-cure-for-cancer-might-not-be-far-away/
Human Variome Project: encyclopedic catalog of sequence variants indexed to the human genome sequence A Lev-Ari http://pharmaceuticalintelligence.com/2012/11/24/human-variome-project-encyclopedic-catalog-of-sequence-variants-indexed-to-the-human-genome-sequence/
Prostate Cancer Cells: Histone Deacetylase Inhibitors Induce Epithelial-to-Mesenchymal Transition
SJ Williams
http://pharmaceuticalintelligence.com/2012/11/30/histone-deacetylase-inhibitors-induce-epithelial-to-mesenchymal-transition-in-prostate-cancer-cells/
Inspiration From Dr. Maureen Cronin’s Achievements in Applying Genomic Sequencing to Cancer Diagnostics A Lev-Ari http://pharmaceuticalintelligence.com/2013/01/10/inspiration-from-dr-maureen-cronins-achievements-in-applying-genomic-sequencing-to-cancer-diagnostics/
The “Cancer establishments” examined by James Watson, co-discoverer of DNA w/Crick, 4/1953
A Lev-Ari http://pharmaceuticalintelligence.com/2013/01/09/the-cancer-establishments-examined-by-james-watson-co-discover-of-dna-wcrick-41953/
Directions for genomics in personalized medicine larryhbern
http://pharmaceuticalintelligence.com/2013/01/27/directions-for-genomics-in-personalized-medicine/
How mobile elements in “Junk” DNA promote cancer. Part 1: Transposon-mediated tumorigenesis. SJ Williams
http://pharmaceuticalintelligence.com/2012/10/31/how-mobile-elements-in-junk-dna-prote-cancer-part1-transposon-mediated-tumorigenesis/ Mitochondria: More than just the “powerhouse of the cell” ritu saxena http://pharmaceuticalintelligence.com/2012/07/09/mitochondria-more-than-just-the-powerhouse-of-the-cell/
Mitochondrial fission and fusion: potential therapeutic targets? Ritu saxena http://pharmaceuticalintelligence.com/2012/10/31/mitochondrial-fission-and-fusion-potential-therapeutic-target/
Mitochondrial mutation analysis might be “1-step” away ritu saxena http://pharmaceuticalintelligence.com/2012/08/14/mitochondrial-mutation-analysis-might-be-1-step-away/
mRNA interference with cancer expression larryhbern
http://pharmaceuticalintelligence.com/2012/10/26/mrna-interference-with-cancer-expression/
Expanding the Genetic Alphabet and linking the genome to the metabolome http://pharmaceuticalintelligence.com/2012/09/24/expanding-the-genetic-alphabet-and-linking-the-genome-to-the-metabolome/
Breast Cancer, drug resistance, and biopharmaceutical targets larryhbern
http://pharmaceuticalintelligence.com/2012/09/18/breast-cancer-drug-resistance-and-biopharmaceutical-targets/
Breast Cancer: Genomic profiling to predict Survival: Combination of Histopathology and Gene Expression Analysis
A Lev-Ari
http://pharmaceuticalintelligence.com/2012/12/24/breast-cancer-genomic-profiling-to-predict-survival-combination-of-histopathology-and-gene-expression-analysis/
Gastric Cancer: Whole-genome reconstruction and mutational signatures A Lev-Ari http://pharmaceuticalintelligence.com/2012/12/24/gastric-cancer-whole-genome-reconstruction-and-mutational-signatures-2/
Ubiquinin-Proteosome pathway, autophagy, the mitochondrion, proteolysis and cell apoptosis larryhbern http://pharmaceuticalintelligence.com/2012/10/30/ubiquinin-proteosome-pathway-autophagy-the-mitochondrion-proteolysis-and-cell-apoptosis/
Genomic Analysis: FLUIDIGM Technology in the Life Science and Agricultural Biotechnology A Lev-Ari http://pharmaceuticalintelligence.com/2012/08/22/genomic-analysis-fluidigm-technology-in-the-life-science-and-agricultural-biotechnology/
2013 Genomics: The Era Beyond the Sequencing Human Genome: Francis Collins, Craig Venter, Eric Lander, et al. http://pharmaceuticalintelligence.com/2013_Genomics
Paradigm Shift in Human Genomics – Predictive Biomarkers and Personalized Medicine – Part 1 http://pharmaceuticalintelligence.com/Paradigm Shift in Human Genomics_/
Related Articles Life Stands on the shoulders of Giants (Viruses) (bytesizebio.net)
New insights into the human genome by ENCODE project (slideshare.net)
Unraveling the Human Genome: 6 Molecular Milestones (livescience.com)
Melanoma Genes Found In “Junk” DNA (medicalnewstoday.com)
Learning the alphabet of gene control (esciencenews.com)
BEST OF THE WEB: On viral ‘junk’ DNA, a DNA-enhancing Ketogenic diet, and cometary kicks (sott.net)
Read Full Post »
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Sohan