Healthcare analytics, AI solutions for biological big data, providing an AI platform for the biotech, life sciences, medical and pharmaceutical industries, as well as for related technological approaches, i.e., curation and text analysis with machine learning and other activities related to AI applications to these industries.
Controlling Mesenchymal Stem Cell Activity With Microparticles Loaded With Small Molecules
M. Butyrov Beyond the Dish
Mesenchymal stem cells are the subject of many clinical trials and show a potent ability to down-regulate unwanted immune responses and quell inflammation. A genuine challenge with mesenchymal stem cells (MSCs) is controlling the genes they express and the proteins they secrete.
A new publication details the strategy of one enterprising laboratory to control MSC function. Work by Jeffery Karp from the Harvard Stem Cell Institute and Maneesha Inamdar from the Institute for Stem Cell Biology and Regenerative Medicine in Bangalore, India and their colleagues had use microparticles that are loaded with small molecules and are readily taken up by cultures MSCs.
In this paper, which appeared in Stem Cell Reports (DOI:http://dx.doi.org/10.1016/j.stemcr.2016.05.003), human MSCs were stimulated with a small signaling protein called Tumor Necrosis Factor-alpha (TNF-alpha). TNF-alpha makes MSCs “angry” and they pour out pro-inflammatory molecules upon stimulation with TNF-alpha. However, to these TNF-alpha-stimulated, MSC, Karp and others added tiny microparticles loaded with a small molecule called TPCA-1. TPCA-1 inhibits the NF-κB signaling pathway, which is one of the major signal transduction pathways involved in inflammation.
Delivery of these TPCA-1-containing microparticles thinned-out the production of pro-inflammatory molecules by these TNF-alpha-treated MSCs for at least 6 days. When the culture medium from TPCA-1-loaded MSCs was given to different cell types, the molecules secreted by these cells reduced the recruitment of white blood cells called monocytes. This is indicative of the anti-inflammatory nature of TPCA-1-treated MSCs. The culture medium from these cells also prevented the differentiation of human cardiac fibroblasts into collagen-making cells called “myofibroblasts.” Myofibroblasts lay down the collagen that produces the heart scar after a heart attack. This is a further indication of the anti-inflammatory nature of the molecules made by these TPCA-1-treated MSCs.
These results are important because it shows that MSC activities can be manipulated without gene therapy. It is possible that such non-gene therapy-based approached can be used to fine-tune MSC activity and the types of molecules secreted by implanted MSCs. Furthermore, given the effect of these cells on monocytes and cardiac fibroblasts, perhaps microparticle-treated MSCs can prevent the adverse remodeling that occurs in the heart after a heart attack.
Controlled Inhibition of the Mesenchymal Stromal Cell Pro-inflammatory Secretome via Microparticle Engineering
Mesenchymal stromal cells (MSCs) are promising therapeutic candidates given their potent immunomodulatory and anti-inflammatory secretome. However, controlling the MSC secretome post-transplantation is considered a major challenge that hinders their clinical efficacy. To address this, we used a microparticle-based engineering approach to non-genetically modulate pro-inflammatory pathways in human MSCs (hMSCs) under simulated inflammatory conditions. Here we show that microparticles loaded with TPCA-1, a smallmolecule NF-kB inhibitor, when delivered to hMSCs can attenuate secretion of pro-inflammatory factors for at least 6 days in vitro. Conditioned medium (CM) derived from TPCA-1-loaded hMSCs also showed reduced ability to attract human monocytes and prevented differentiation of human cardiac fibroblasts to myofibroblasts, compared with CM from untreated or TPCA-1-preconditioned hMSCs. Thus, we provide a broadly applicable bioengineering solution to facilitate intracellular sustained release of agents that modulate signaling. We propose that this approach could be harnessed to improve control over MSC secretome post-transplantation, especially to prevent adverse remodeling post-myocardial infarction.
Mesenchymal stromal cells (MSCs; also known as bone marrow stromal cells and earlier known as mesenchymal stem cells) are being explored as therapeutics in over 550 clinical trials registered with the US Food and Drug Administration (www.FDA.gov) for the treatment of a wide range of diseases (Ankrum et al., 2014c). Their immuneevasive properties (Ankrum et al., 2014c) and safe transplant record, allowing allogeneic administration without an immunosuppressive regimen, positions MSCs as an appealing candidate for a potential off-the-shelf product. One of the primary mechanisms exploited in MSC therapeutics is a secretome-based paracrine effect as evidenced in many pre-clinical studies (Ranganath et al., 2012). However, controlling the MSC secretome post-transplantation is considered a major challenge that hinders their clinical efficacy. For instance, upon transplantation, MSCs are subjected to a complex inflammatory milieu (soluble mediators and immune cells) in most injury settings. MSCs not only secrete anti-inflammatory factors, but also produce pro-inflammatory factors that may compromise their therapeutic efficacy. Table S1 lists a few in vitro and in vivo conditions that demonstrate the complex microenvironment under which MSCs switch between anti-inflammatory and pro-inflammatory phenotypes.
Levels of pro- or anti-inflammatory cytokines are not always predictive of the response, possibly due to the dynamic cytokine combinations (and concentrations) present in the cell microenvironment (Table S1). For example, relatively low inflammatory stimulus (<20 ng/ml tumor necrosis factor alpha [TNF-a] alone or along with interferon-g [IFN-g]) can polarize MSCs toward pro-inflammatory effects (Bernardo and Fibbe, 2013) resulting in increased inflammation characterized by T cell proliferation and transplant rejection. Conversely, exposure to high levels of the inflammatory cytokine TNF-a has been shown in certain studies to result in MSC-mediated anti-inflammatory effects via secretion of potent mediators such as TSG6, PGE2, STC-1, IL-1Ra, and sTNFR1 as demonstrated in multiple inflammation-associated disease models (Prockop and Oh, 2012; Ylostalo et al., 2012). These effects are mediated via molecular pathways such as NF-kB, PI3K, Akt, and JAK-STAT (Ranganath et al., 2012). However, it is not clear that low and high levels of TNF-a always exert the same effect on anti- versus pro-inflammatory MSC secretome. NF-kB is a central regulator of the anti-inflammatory secretome response in monolayer (Yagi et al., 2010), spheroid MSCs (Bartosh et al., 2013; Ylostalo et al., 2012) and TNFa-mediated (20 ng/ml for 120 min) apoptosis (Peng et al., 2011). Given that NF-kB can promote secretion of proinflammatory components in the MSC secretome (Lee et al., 2010), we hypothesized that NF-kB inhibition via small molecules in MSC subjected to a representative in- flammatory stimulus (10 ng/ml TNF-a) would inhibit their pro-inflammatory responses.
Adverse remodeling or cardiac fibrosis due to differentiation of cardiac fibroblasts (CF) into cardiac myofibroblasts (CMF) with pro-inflammatory phenotype and collagen deposition is the leading cause for heart failure. The secretome from exogenous MSCs has anti-fibrotic and angiogenic effects that can reduce scar formation (Preda et al., 2014) and improve ejection fraction when administered early or prior to adverse remodeling (Preda et al., 2014; Tang et al., 2010; Williams et al., 2013). Unfortunately in many cases, due to poor prognosis, MSCs may not be administered in time to prevent adverse remodeling to inhibit CF differentiation to CMF (Virag and Murry, 2003) or to prevent myocardial expression of TNF-a (Bozkurt et al., 1998; Mann, 2001). Also, when administered following an adverse remodeling event including CMF differentiation, MSCs may assume a pro-inflammatory phenotype and secretome (Naftali-Shani et al., 2013) under TNF-a (typically 5 pg/mg of total protein in myocardial infarction (MI) rat myocardium which is not significantly higher than 1–3 pg/mg protein in control rat myocardium) (Moro et al., 2007) resulting in impaired heart function. Hence, if the pro-inflammatory response of hMSCs can be suppressed it may maximize efficacy.
While the MSC phenotype can be controlled under regulated conditions in vitro, the in vivo response of MSCs post-transplantation is poorly controlled as it is dictated by highly dynamic and complex host microenvironments (Discher et al., 2009; Rodrigues et al., 2010). Factors including MSC tissue source (Melief et al., 2013; NaftaliShani et al., 2013), donor and batch-to-batch variability with respect to cytokine secretion and response to inflammatory stimuli (Zhukareva et al., 2010), gender (Crisostomo et al., 2007), and age (Liang et al., 2013) also affect the response of MSCs. Thus, it is important to develop approaches to control the MSC secretome post-transplantation regardless of their source or expansion conditions. We hypothesized that engineering MSCs to induce a specific secretome profile under a simulated host microenvironment may maximize their therapeutic utility. Previously, the MSC secretome has been regulated via genetic engineering (Gnecchi et al., 2006; Wang et al., 2009) or cytokine/small-molecule preconditioning approaches (Crisostomo et al., 2008; Mias et al., 2008). Genetically engineered human MSCs (hMSCs) pose challenging long-term regulatory hurdles given that the potential tumorigenicity has not been well characterized, and while preconditioning hMSCs with cytokines/small molecules may be safer, the phenotype-altering effects are transient. …
While TPCA-1 pretreatment of hMSCs before TNF-a stimulation showed a significant reduction in CMF numbers, this was greatly enhanced when TPCA-1 was available intracellularly via the microparticles. CM from TNF + TPCAmP-hMSC likely prevented differentiation of CF to CMF due to the continued intracellular inhibition of IKK-mediated NF-kB activation, thus preventing the release of an hMSC pro-inflammatory secretome. Surprisingly, the CMF number was reduced by over 2-fold, suggesting that TPCA-1 may activate hMSC pathways that revert the CMF phenotype. We cannot rule out the possibility that other contributors in the hMSC secretome that were not profiled might also be contributing, and their action is facilitated by intracellular TPCA-1. For instance, in an in vitro 3D model of cardiac fibrosis under hypoxic conditions, reversal of CMF to the CF phenotype was shown to be due to reduced MSC TGF-b levels (Galie and Stegemann, 2014). Our assay revealed a similar trend in terms of collagen production from CF. CF treated with CM from control-hMSCs, or TPCApre + TNF-hMSCs or mP-hMSCs secreted elevated levels of collagen into the media suggesting that only inhibited levels of pro-inflammatory mediators could not be implicated in the reduction in collagen secretion. The reduced number of a-SMA+ CMF in CM from TNF + TPCAmP-hMSCs possibly contributed to the lower secretion level of collagen in the media (Figure 5B). Upon dedifferentiation or lowered a-SMA expression, it is possible that CMFs lose collagen secretion ability. In regions of MI, CF switch to the myofibroblast phenotype due to stress from the infarct scar (Tomasek et al., 2002). High expression of a-SMA typical in such CMF (Teunissen et al., 2007) has been implicated for remodeling due to their high contractility (Santiago et al., 2010). In addition, the collagen secretion capacity of CMF is very high (Petrov et al., 2002). Overall, attenuation in the number of collagen-secreting a-SMA+ CMF could be beneficial in preventing pathological remodeling or irreversible scar formation and allowing cardiac regeneration.
Here we have demonstrated that the pro-inflammatory hMSC secretome could be inhibited using a microparticle engineering approach delivering an intracellular NF-kB inhibitor, TPCA-1. It is however important to note that the MSC secretome composition may change depending on the level of TNF-a encountered in vivo following transplantation. Nevertheless, a similar approach could be beneficial in inflammatory disease settings such as chronic inflammation and macrophage-mediated atherosclerosis. The approach of microparticle engineering of an exogenous cell population by modulating a central regulatory pathway, may find application in other cell types and pathways and could provide an attractive strategy for harnessing any cell secretome for therapy. This approach could also be potentially employed to modulate the composition of extracellular vesicles (exosomes) for therapy.
Dr. Ahmad Masri and Dr. C Michael Gibson discuss outpatient worsening heart failure in transthyretin amyloid cardiomyopathy in the Attribute-CM trial, May 29, 2026
The following are key points to remember from this update on the treatment of cardiac transthyretin amyloidosis:
Transthyretin (TTR) is a highly conserved protein involved in transportation of thyroxine (T4) and retinol-binding protein. TTR is synthesized mostly by the liver and is rich in beta strands with an intrinsic propensity to aggregate into insoluble amyloid fibers, which deposit within tissue leading to the development of TTR-related amyloidosis (ATTR). ATTR can follow the deposition of either variant TTR (ATTRv, previously known as mutant ATTR) or wild type TTR (ATTRwt).
Cardiac ATTR has a favorable survival rate compared to light chain (AL) amyloidosis, with a median survival of 75 versus 11 months. However, ATTR cardiomyopathy is a progressive disorder but newer therapeutic options include tafamidis (positive phase 3 clinical trial), and possibly patisiran and inotersen.
Inhibition of the Synthesis of Mutated Transthyretin
Liver transplantation removes the source of mutated TTR molecules and prolongs survival, with a 20-year survival of 55.3%. However, tissue accumulation of TTR can continue after liver transplantation because TTR amyloid fibers promote subsequent deposition of ATTRwt. Combined liver–heart transplantation is feasible in younger patients with ATTRv cardiomyopathy and a small series suggests better prognosis than cardiac transplantation.
Inhibition of TTR gene expression: Patisiran is a small interfering RNA blocking the expression of both variant and wt TTR. On the basis of the APOLLO trial, it was approved for therapy of adults with ATTRv-related polyneuropathy both in the United States and European Union. In this trial, patisiran promoted favorable myocardial remodeling based on echocardiographic and N-terminal B-type natriuretic peptide (NT-BNP) changes (this effect was not demonstrated for inotersen) and is still under investigation for tafamidis.
Antisense oligonucleotides inotersen inhibits the production of both variant and wt TTR. Based on the findings of the NEURO-TTR trial, the Food and Drug Administration (FDA) approved this agent for patients with ATTRv-related polyneuropathy. In the NEURO-TTR trial, cardiomyopathy was present in 63%, but the study was not powered to measure effects of inotersen on heart disease. Inotersen can cause thrombocytopenia and must be used cautiously with bleeding risk.
Tetramer Stabilization
Selective stabilizers include tafamidis and AG10. Tafamidis is a benzoxazole and a small molecule that inhibits the dissociation of TTR tetramers by binding the T4-binding sites. The phase ATTR-ACT study showed that when comparing the pooled tafamidis arms (80 and 20 mg) with the placebo arm, tafamidis was associated with lower all-cause mortality than placebo (78 of 264 [29.5%] vs. 76 of 177 [42.9%]; hazard ratio, 0.70; 95% confidence interval, 0.51-0.96) and a lower rate of cardiovascular hospitalizations. Based on the results of the ATTR-ACT trial, it has received Breakthrough Therapy designation from the FDA for treatment of ATTR cardiomyopathy.
Nonselective agents: Diflunisal, a nonsteroidal anti-inflammatory drug, is reported to stabilize TTR tetramers. More studies are needed to confirm its clinical efficacy.
Inhibition of Oligomer Aggregation and Oligomer Disruption
Epigallocatechin gallate is the most abundant catechin in green tea. One single-center open-label 12-month study did not show survival benefits or any change in echocardiographic parameters or NT-BNP compared to baseline.
Degradation and Reabsorption of Amyloid Fibers
Doxycycline-taurosodeoxycholic acid (TUDCA) has been evaluated in two small studies and the results appear to be modest. More data are needed to confirm its efficacy.
Antibodies targeting serum amyloid P protein or amyloid fibrils: Patient enrollment for miridesap followed by anti-SAP antibodies was suspended, and this approach is not being evaluated currently. However, a monoclonal antibody designed to specifically target TTR amyloid deposits (PRX004) has entered clinical evaluation, with an ongoing phase 1 study on ATTRv.
Supportive Treatment of Cardiac Involvement
Drug therapies: Although angiotensin-converting enzyme (ACE) inhibitors/angiotensin-receptor blockers (ARBs) and beta-blockers may have been poorly tolerated in the ATTR-ACT trial, 30% of the patients were on ACE inhibitors/ARBs. There are no data with digoxin in TTR amyloid, and non-dihydropyridine calcium channel blockers are contraindicated due to negative inotropy.
Implantable cardioverter-defibrillators (ICDs): In one study, which included 53 patients with amyloid, ICD shocks occurred exclusively in the AL amyloid group and none in the TTR amyloid patients. Higher defibrillation thresholds and complication rates are of concern.
Cardiac pacing: In a large series of ATTRv-related polyneuropathy (n = 262), a pacemaker was implanted in 110 patients with His ventricular interval >700 ms. The authors recommend that any conduction disturbance on 12-lead electrocardiogram (ECG) warrants further investigation with Holter monitoring to determine candidacy for a pacemaker.
Left ventricular assist device (LVAD): Although an LVAD is technically feasible, it is associated with high short-term mortality and worse outcomes than in dilated cardiomyopathy.
Cardiac transplantation: This is a valuable option for patients with end-stage heart failure when significant extracardiac disease is excluded. In one study with 10 patients, only episodes of amyloid recurrence occurred.
This is an outstanding overview of this topic and recommended reading for anyone who cares for patients with cardiac transthyretin amyloid.
First-Ever Evidence that Patisiran Reduces Pathogenic, Misfolded TTR Monomers and Oligomers in FAP Patients
We reported data from our ongoing Phase 2 open-label extension (OLE) study of patisiran, an investigational RNAi therapeutic targeting transthyretin (TTR) for the treatment of TTR-mediated amyloidosis (ATTR amyloidosis) patients with familial amyloidotic polyneuropathy (FAP). Alnylam scientists and collaborators from The Scripps Research Institute and Misfolding Diagnostics, Inc. were able to measure the effects of patisiran on pathogenic, misfolded TTR monomers and oligomers in FAP patients. Results showed a rapid and sustained reduction in serum non-native conformations of TTR (NNTTR) of approximately 90%. Since NNTTR is pathogenic in ATTR amyloidosis and the level of NNTTR reduction correlated with total TTR knockdown, these results provide direct mechanistic evidence supporting the therapeutic hypothesis that TTR knockdown has the potential to result in clinical benefit. Furthermore, complete 12-month data from all 27 patients that enrolled in the patisiran Phase 2 OLE study showed sustained mean maximum reductions in total serum TTR of 91% for over 18 months and a mean 3.1-point decrease in mNIS+7 at 12 months, which compares favorably to an estimated increase in mNIS+7 of 13 to 18 points at 12 months based upon analysis of historical data sets in untreated FAP patients with similar baseline characteristics. Importantly, patisiran administration continues to be generally well tolerated out to 21 months of treatment.
We are encouraged by these new data that provide continued support for our hypothesis that patisiran has the potential to halt neuropathy progression in patients with FAP. If these results are replicated in a randomized, double-blind, placebo-controlled study, we believe that patisiran could emerge as an important treatment option for patients suffering from this debilitating, progressive and life-threatening disease.
Hereditary ATTR Amyloidosis with Polyneuropathy (hATTR-PN)
ATTR amyloidosis is a progressive, life-threatening disease caused by misfolded transthyretin (TTR) proteins that accumulate as amyloid fibrils in multiple organs, but primarily in the peripheral nerves and heart. ATTR amyloidosis can lead to significant morbidity, disability, and mortality. The TTR protein is produced primarily in the liver and is normally a carrier for retinol binding protein – one of the vehicles used to transport vitamin A around the body. Mutations in the TTR gene cause misfolding of the protein and the formation of amyloid fibrils that typically contain both mutant and wild-type TTR that deposit in tissues such as the peripheral nerves and heart, resulting in intractable peripheral sensory neuropathy, autonomic neuropathy, and/or cardiomyopathy.
ATTR represents a major unmet medical need with significant morbidity and mortality. There are over 100 reported TTR mutations; the particular TTR mutation and the site of amyloid deposition determine the clinical manifestations of the disease whether it is predominantly symptoms of neuropathy or cardiomyopathy.
Specifically, hereditary ATTR amyloidosis with polyneuropathy (hATTR-PN), also known as familial amyloidotic polyneuropathy (FAP), is an inherited, progressive disease leading to death within 5 to 15 years. It is due to a mutation in the transthyretin (TTR) gene, which causes misfolded TTR proteins to accumulate as amyloid fibrils predominantly in peripheral nerves and other organs. hATTR-PN can cause sensory, motor, and autonomic dysfunction, resulting in significant disability and death.
It is estimated that hATTR-PN, also known as FAP, affects approximately 10,000 people worldwide. Patients have a life expectancy of 5 to 15 years from symptom onset, and the only treatment options for early stage disease are liver transplantation and TTR stabilizers such as tafamidis (approved in Europe) and diflunisal. Unfortunately liver transplantation has limitations, including limited organ availability as well as substantial morbidity and mortality. Furthermore, transplantation eliminates the production of mutant TTR but does not affect wild-type TTR, which can further deposit after transplantation, leading to cardiomyopathy and worsening of neuropathy. There is a significant need for novel therapeutics to treat patients who have inherited mutations in the TTR gene.
Our ATTR program is the lead effort in our Genetic Medicine Strategic Therapeutic Area (STAr) product development and commercialization strategy, which is focused on advancing innovative RNAi therapeutics toward genetically defined targets for the treatment of rare diseases with high unmet medical need. We are developing patisiran (ALN-TTR02), an intravenously administered RNAi therapeutic, to treat the hATTR-PN form of the disease.
Patisiran for the Treatment hATTR-PN
APOLLO Phase 3 Trial
In 2012, Alnylam entered into an exclusive alliance with Genzyme, a Sanofi company, to develop and commercialize RNAi therapeutics, including patisiran and revusiran, for the treatment of ATTR amyloidosis in Japan and the broader Asian-Pacific region. In early 2014, this relationship was extended as a significantly broader alliance to advance RNAi therapeutics as genetic medicines. Under this new agreement, Alnylam will lead development and commercialization of patisiran in North America and Europe while Genzyme will develop and commercialize the product in the rest of world.
Hereditary ATTR Amyloidosis with Cardiomyopathy (hATTR-CM)
ATTR amyloidosis is a progressive, life-threatening disease caused by misfolded transthyretin (TTR) proteins that accumulate as amyloid fibrils in multiple organs, but primarily in the peripheral nerves and heart. ATTR amyloidosis can lead to significant morbidity, disability, and mortality. The TTR protein is produced primarily in the liver and is normally a carrier for retinol binding protein – one of the vehicles used to transport vitamin A around the body. Mutations in the TTR gene cause misfolding of the protein and the formation of amyloid fibrils that typically contain both mutant and wild-type TTR that deposit in tissues such as the peripheral nerves and heart, resulting in intractable peripheral sensory neuropathy, autonomic neuropathy, and/or cardiomyopathy.
ATTR represents a major unmet medical need with significant morbidity and mortality. There are over 100 reported TTR mutations; the particular TTR mutation and the site of amyloid deposition determine the clinical manifestations of the disease, whether it is predominantly symptoms of neuropathy or cardiomyopathy.
Specifically, hereditary ATTR amyloidosis with cardiomyopathy (hATTR-CM), also known as familial amyloidotic cardiomyopathy (FAC), is an inherited, progressive disease leading to death within 2 to 5 years. It is due to a mutation in the transthyretin (TTR) gene, which causes misfolded TTR proteins to accumulate as amyloid fibrils primarily in the heart. Hereditary ATTR amyloidosis with cardiomyopathy can result in heart failure and death.
While the exact numbers are not known, it is estimated hATTR-CM, also known as FAC affects at least 40,000 people worldwide. hATTR-CM is fatal within 2 to 5 years of diagnosis and treatment is currently limited to supportive care. Wild-type ATTR amyloidosis (wtATTR amyloidosis), also known as senile systemic amyloidosis, is a nonhereditary, progressive disease leading to death within 2 to 5 years. It is caused by misfolded transthyretin (TTR) proteins that accumulate as amyloid fibrils in the heart. Wild-type ATTR amyloidosis can cause cardiomyopathy and result in heart failure and death. There are no approved therapies for the treatment of hATTR-CM or SSA; hence there is a significant unmet need for novel therapeutics to treat these patients.
Our ATTR program is the lead effort in our Genetic Medicine Strategic Therapeutic Area (STAr) product development and commercialization strategy, which is focused on advancing innovative RNAi therapeutics toward genetically defined targets for the treatment of rare diseases with high unmet medical need. We are developing revusiran (ALN-TTRsc), a subcutaneously administered RNAi therapeutic for the treatment of hATTR-CM.
Revusiran for the Treatment of hATTR-CM
ENDEAVOUR Phase 3 Trial
In 2012, Alnylam entered into an exclusive alliance with Genzyme, a Sanofi company, to develop and commercialize RNAi therapeutics, including patisiran and revusiran, for the treatment of ATTR amyloidosis in Japan and the broader Asian-Pacific region. In early 2014, this relationship was extended as a broader alliance to advance RNAi therapeutics as genetic medicines. Under this new agreement, Alnylam and Genzyme have agreed to co-develop and co-commercialize revusiran in North America and Europe, with Genzyme developing and commercializing the product in the rest of world. This broadened relationship on revusiran is aimed at expanding and accelerating the product’s global value.
We presented pre-clinical data with ALN-TTRsc02, an investigational RNAi therapeutic targeting transthyretin (TTR) for the treatment of TTR-mediated amyloidosis (ATTR amyloidosis). In pre-clinical studies, including those in non-human primates (NHPs), ALN-TTRsc02 achieved potent and highly durable knockdown of serum TTR of up to 99% with multi-month durability achieved after just a single dose, supportive of a potentially once quarterly dose regimen. Results from studies comparing TTR knockdown activity of ALN-TTRsc02 to that of revusiran showed that ALN-TTRsc02 has a markedly superior TTR knockdown profile. Further, in initial rat toxicology studies, ALN-TTRsc02 was found to be generally well tolerated with no significant adverse events at doses as high as 100 mg/kg.
Heart failure with a preserved ejection fraction (HFPEF) is a clinical syndrome that has no pharmacologic therapies approved for this use to date. In light of failed medicines, cardiologists have refocused treatment strategies based on the theory that HFPEF is a heterogeneous clinical syndrome with different etiologies. Classification of HFPEF according to etiologic subtype may, therefore, identify cohorts with treatable pathophysiologic mechanisms and may ultimately pave the way forward for developing meaningful HFPEF therapies.1
A wealth of data now indicates that amyloid infiltration is an important mechanism underlying HFPEF. Inherited mutations in transthyretin cardiac amyloidosis (ATTRm) or the aging process in wild-type disease (ATTRwt) cause destabilization of the transthyretin (TTR) protein into monomers or oligomers, which aggregate into amyloid fibrils. These insoluble fibrils accumulate in the myocardium and result in diastolic dysfunction, restrictive cardiomyopathy, and eventual congestive heart failure (Figure 1). In an autopsy study of HFPEF patients, almost 20% without antemortem suspicion of amyloid had left ventricular (LV) TTR amyloid deposition.2 Even more resounding evidence for the contribution of TTR amyloid to HFPEF was a study in which 120 hospitalized HFPEF patients with LV wall thickness ≥12 mm underwent technetium-99m 3,3-diphosphono-1,2-propranodicarboxylic acid (99mTc-DPD) cardiac imaging,3,4 a bone isotope known to have high sensitivity and specificity for diagnosing TTR cardiac amyloidosis.5,6 Moderate-to-severe myocardial uptake indicative of TTR cardiac amyloid deposition was detected in 13.3% of HFPEF patients who did not have TTR gene mutations. Therefore, TTR cardiac amyloid deposition, especially in older adults, is not rare, can be easily identified, and may contribute to the underlying pathophysiology of HFPEF.
Figure 1
As no U.S. Food and Drug Administration-approved drugs are currently available for the treatment of HFPEF or TTR cardiac amyloidosis, the development of medications that attenuate or prevent TTR-mediated organ toxicity has emerged as an important therapeutic goal. Over the past decade, a host of therapies and therapeutic drug classes have emerged in clinical trials (Table 1), and these may herald a new direction for treating HFPEF secondary to TTR amyloid.
Table 1
TTR Silencers (siRNA and Antisense Oligonucleotides)
siRNA
Ribonucleic acid interference (RNAi) has surfaced as an endogenous cellular mechanism for controlling gene expression. Small interfering RNAs (siRNAs) delivered into cells can disrupt the production of target proteins.7,8 A formulation of lipid nanoparticle and triantennary N-acetylgalactosamine (GalNAc) conjugate that delivers siRNAs to hepatocytes is currently in clinical trials.9 Prior research demonstrated these GalNAc-siRNA conjugates result in robust and durable knockdown of a variety of hepatocyte targets across multiple species and appear to be well suited for suppression of TTR gene expression and subsequent TTR protein production.
The TTR siRNA conjugated to GalNAc, ALN-TTRSc, is now under active investigation as a subcutaneous injection in phase 3 clinical trials in patients with TTR cardiac amyloidosis.10 Prior phase 2 results demonstrated that ALN-TTRSc was generally well tolerated in patients with significant TTR disease burden and that it reduced both wild-type and mutant TTR gene expression by a mean of 87%. Harnessing RNAi technology appears to hold great promise for treating patients with TTR cardiac amyloidosis. The ability of ALN-TTRSc to lower both wild-type and mutant proteins may provide a major advantage over liver transplantation, which affects the production of only mutant protein and is further limited by donor shortage, cost, and need for immunosuppression.
Antisense Oligonucleotides
Antisense oligonucleotides (ASOs) are under clinical investigation for their ability to inhibit hepatic expression of amyloidogenic TTR protein. Currently, the ASO compound, ISIS-TTRRx, is under investigation in a phase 3 multicenter, randomized, double-blind, placebo-controlled clinical trial in patients with familial amyloid polyneuropathy (FAP).11 The primary objective is to evaluate its efficacy as measured by change in neuropathy from baseline relative to placebo. Secondary measures will evaluate quality of life (QOL), modified body mass index (mBMI) by albumin, and pharmacodynamic effects on retinol binding protein. Exploratory objectives in a subset of patients with LV wall thickness ≥13 mm without a history of persistent hypertension will examine echocardiographic parameters, N-terminal pro–B-type natriuretic peptide (NT-proBNP), and polyneuropathy disability score relative to placebo. These data will facilitate analysis of the effect of antisense oligonucleotide-mediated TTR suppression on the TTR cardiac phenotype with a phase 3 trial anticipated to begin enrollment in 2016.
TTR Stabilizers (Diflunisal, Tafamidis)
Diflunisal
Several TTR-stabilizing agents are in various stages of clinical trials. Diflunisal, a traditionally used and generically available nonsteroidal anti-inflammatory drug (NSAID), binds and stabilizes familial TTR variants against acid-mediated fibril formation in vitro and is now in human clinical trials.12,13 The use of diflunisal in patients with TTR cardiac amyloidosis is controversial given complication of chronic inhibition of cyclooxygenase (COX) enzymes, including gastrointestinal bleeding, renal dysfunction, fluid retention, and hypertension that may precipitate or exacerbate heart failure in vulnerable individuals.14-17 In TTR cardiac amyloidosis, an open-label cohort study suggested that low-dose diflunisal with careful monitoring along with a prophylactic proton pump inhibitor could be safely administered to compensated patients.18 An association was observed, however, between chronic diflunisal use and adverse changes in renal function suggesting that advanced kidney disease may be prohibitive in diflunisal therapy.In FAP patients with peripheral or autonomic neuropathy randomized to diflunisal or placebo, diflunisal slowed progression of neurologic impairment and preserved QOL over two years of follow-up.19 Echocardiography demonstrated cardiac involvement in approximately 50% of patients.20 Longer-term safety and efficacy data over an average 38 ± 31 months in 40 Japanese patients with hereditary ATTR amyloidosis who were not candidates for liver transplantation showed that diflunisal was mostly well tolerated.12 The authors cautioned the need for attentive monitoring of renal function and blood cell counts. Larger multicenter collaborations are needed to determine diflunisal’s true efficacy in HFPEF patients with TTR cardiac amyloidosis.
Tafamidis
Tafamidis is under active investigation as a novel compound that binds to the thyroxine-binding sites of the TTR tetramer, inhibiting its dissociation into monomers and blocking the rate-limiting step in the TTR amyloidogenesis cascade.21 The TTR compound was shown in an 18-month double-blind, placebo-controlled trial to slow progression of neurologic symptoms in patients with early-stage ATTRm due to the V30M mutation.22 When focusing on cardiomyopathy in a phase 2, open-label trial, tafamidis also appeared to effectively stabilize TTR tetramers in non-V30M variants, wild-type and V122I, as well as biochemical and echocardiographic parameters.23,24 Preliminary data suggests that clinically stabilized patients had shorter disease duration, lower cardiac biomarkers, less myocardial thickening, and higher EF than those who were not stabilized, suggesting early institution of therapy may be beneficial. A phase 3 trial has completed enrollment and will evaluate the efficacy, safety, and tolerability of tafamidis 20 or 80 mg orally vs. placebo.25 This will contribute to long-term safety and efficacy data needed to determine the therapeutic effects of tafamidis among ATTRm variants.
Amyloid Degraders (Doxycycline/TUDCA and Anti-SAP Antibodies)
Doxycycline/TUDCA
While silencer and stabilizer drugs are aimed at lowering amyloidogenic precursor protein production, they cannot remove already deposited fibrils in an infiltrated heart. Removal of already deposited fibrils by amyloid degraders would be an important therapeutic strategy, particularly in older adults with heavily infiltrated hearts reflected by thick walls, HFPEF, systolic heart failure, and restrictive cardiomyopathy. Combined doxycycline and tauroursodeoxycholic acid (TUDCA) disrupt TTR amyloid fibrils and appeared to have an acceptable safety profile in a small phase 2 open-label study among 20 TTR patients. No serious adverse reactions or clinical progression of cardiac or neuropathic involvement was observed over one year.26 An active phase 2, single-center, open-label, 12-month study will assess primary outcome measures including mBMI, neurologic impairment score, and NT-proBNP.27 Another phase 2 study is examining the tolerability and efficacy of doxycycline/TUDCA over an 18-month period in patients with TTR amyloid cardiomyopathy.28 Additionally, a study in patients with TTR amyloidosis is ongoing to determine the effect of doxycycline alone on neurologic function, cardiac biomarkers, echocardiographic parameters, modified body mass index, and autonomic neuropathy.29
Anti-SAP Antibodies
In order to safely clear established amyloid deposits, the role of the normal, nonfibrillar plasma glycoprotein present in all human amyloid deposits, serum amyloid P component (SAP), needs to be more clearly understood.30 In mice with amyloid AA type deposits, administration of antihuman SAP antibody triggered a potent giant cell reaction that removed massive visceral amyloid deposits without adverse effects.31 In humans with TTR cardiac amyloidosis, anti-SAP antibody treatments could be feasible because the bis-D proline compound, CPHPC, is capable of clearing circulating human SAP, which allow anti-SAP antibodies to reach residual deposited SAP. In a small, open-label, single-dose-escalation, phase 1 trial involving 15 patients with systemic amyloidosis, none of whom had clinical evidence of cardiac amyloidosis, were treated with CPHPC followed by human monoclonal IgG1 anti-SAP antibody.32 No serious adverse events were reported and amyloid deposits were cleared from the liver, kidney, and lymph node. Anti-SAP antibodies hold promise as a potential amyloid therapy because of their potential to target all forms of amyloid deposits across multiple tissue types.
Mutant or wild-type TTR cardiac amyloidoses are increasingly recognized as a cause of HFPEF. Clinicians need to be aware of this important HFPEF etiology because the diverse array of emerging disease-modifying agents for TTR cardiac amyloidosis in human clinical trials has the potential to herald a new era for the treatment of HFPEF.
References
Maurer MS, Mancini D. HFpEF: is splitting into distinct phenotypes by comorbidities the pathway forward? J Am Coll Cardiol 2014;64:550-2.
Mohammed SF, Mirzoyev SA, Edwards WD, et al. Left ventricular amyloid deposition in patients with heart failure and preserved ejection fraction. JACC Heart Fail 2014;2:113-22.
González-López E, Gallego-Delgado M, Guzzo-Merello G, et al. Wild-type transthyretin amyloidosis as a cause of heart failure with preserved ejection fraction. Eur Heart J 2015.
Castano A, Bokhari S, Maurer MS. Unveiling wild-type transthyretin cardiac amyloidosis as a significant and potentially modifiable cause of heart failure with preserved ejection fraction. Eur Heart J 2015 Jul 28. [Epub ahead of print]
Rapezzi C, Merlini G, Quarta CC, et al. Systemic cardiac amyloidoses: disease profiles and clinical courses of the 3 main types. Circulation 2009;120:1203-12.
Bokhari S, Castano A, Pozniakoff T, Deslisle S, Latif F, Maurer MS. (99m)Tc-pyrophosphate scintigraphy for differentiating light-chain cardiac amyloidosis from the transthyretin-related familial and senile cardiac amyloidoses. Circ Cardiovasc Imaging 2013;6:195-201.
Fire A, Xu S, Montgomery MK, Kostas SA, Driver SE, Mello CC. Potent and specific genetic interference by double-stranded RNA in Caenorhabditis elegans. Nature 1998;391:806-11.
Elbashir SM, Harborth J, Lendeckel W, Yalcin A, Weber K, Tuschl T. Duplexes of 21-nucleotide RNAs mediate RNA interference in cultured mammalian cells. Nature 2001;411:494-8.
Kanasty R, Dorkin JR, Vegas A, Anderson D. Delivery materials for siRNA therapeutics. Nature Mater 2013;12:967-77.
U.S. National Institutes of Health. Phase 2 Study to Evaluate ALN-TTRSC in Patients With Transthyretin (TTR) Cardiac Amyloidosis (ClinicalTrials.gov website). 2014. Available at: https://www.clinicaltrials.gov/ct2/show/NCT01981837. Accessed 8/19/2015.
U.S. National Institutes of Health. Efficacy and Safety of ISIS-TTRRx in Familial Amyloid Polyneuropathy (Clinical Trials.gov Website. 2013. Available at: http://www.clinicaltrials.gov/ct2/show/NCT01737398. Accessed 8/19/2015.
Sekijima Y, Dendle MA, Kelly JW. Orally administered diflunisal stabilizes transthyretin against dissociation required for amyloidogenesis. Amyloid 2006;13:236-49.
Tojo K, Sekijima Y, Kelly JW, Ikeda S. Diflunisal stabilizes familial amyloid polyneuropathy-associated transthyretin variant tetramers in serum against dissociation required for amyloidogenesis. Neurosci Res 2006;56:441-9.
Epstein M. Non-steroidal anti-inflammatory drugs and the continuum of renal dysfunction. J Hypertens Suppl 2002;20:S17-23.
Wallace JL. Pathogenesis of NSAID-induced gastroduodenal mucosal injury. Best Pract Res Clin Gastroenterol 2001;15:691-703.
Mukherjee D, Nissen SE, Topol EJ. Risk of cardiovascular events associated with selective COX-2 inhibitors. JAMA 2001;286:954-9.
Page J, Henry D. Consumption of NSAIDs and the development of congestive heart failure in elderly patients: an underrecognized public health problem. Arch Intern Med 2000;160:777-84.
Castano A, Helmke S, Alvarez J, Delisle S, Maurer MS. Diflunisal for ATTR cardiac amyloidosis. Congest Heart Fail 2012;18:315-9.
Berk JL, Suhr OB, Obici L, et al. Repurposing diflunisal for familial amyloid polyneuropathy: a randomized clinical trial. JAMA 2013;310:2658-67.
Quarta CCF, Solomon RH Suhr SD, et al. The prevalence of cardiac amyloidosis in familial amyloidotic polyneuropathy with predominant neuropathy: The Diflunisal Trial. International Symposium on Amyloidosis 2014:88-9.
Hammarstrom P, Jiang X, Hurshman AR, Powers ET, Kelly JW. Sequence-dependent denaturation energetics: A major determinant in amyloid disease diversity. Proc Natl Acad Sci U S A 2002;99 Suppl 4:16427-32.
Coelho T, Maia LF, Martins da Silva A, et al. Tafamidis for transthyretin familial amyloid polyneuropathy: a randomized, controlled trial. Neurology 2012;79:785-92.
Merlini G, Plante-Bordeneuve V, Judge DP, et al. Effects of tafamidis on transthyretin stabilization and clinical outcomes in patients with non-Val30Met transthyretin amyloidosis. J Cardiovasc Transl Res 2013;6:1011-20.
Maurer MS, Grogan DR, Judge DP, et al. Tafamidis in transthyretin amyloid cardiomyopathy: effects on transthyretin stabilization and clinical outcomes. Circ Heart Fail 2015;8:519-26.
U.S. National Institutes of Health. Safety and Efficacy of Tafamidis in Patients With Transthyretin Cardiomyopathy (ATTR-ACT) (ClinicalTrials.gov website). 2014. Available at: http://www.clinicaltrials.gov/show/NCT01994889. Accessed 8/19/2015.
Obici L, Cortese A, Lozza A, et al. Doxycycline plus tauroursodeoxycholic acid for transthyretin amyloidosis: a phase II study. Amyloid 2012;19 Suppl 1:34-6.
U.S. National Institutes of Health. Safety, Efficacy and Pharmacokinetics of Doxycycline Plus Tauroursodeoxycholic Acid in Transthyretin Amyloidosis (ClinicalTrials.gov website). 2011. Available at: http://www.clinicaltrials.gov/ct2/show/NCT01171859. Accessed 8/19/2015.
U.S. National Institutes of Health. Tolerability and Efficacy of a Combination of Doxycycline and TUDCA in Patients With Transthyretin Amyloid Cardiomyopathy (ClinicalTrials.gov website). 2013. Available at: http://www.clinicaltrials.gov/ct2/show/NCT01855360. Accessed 8/19/2015.
U.S. National Institutes of Health. Safety and Effect of Doxycycline in Patients With Amyloidosis (ClinicalTrials.gov website).2015. Available at: https://clinicaltrials.gov/ct2/show/NCT01677286. Accessed 8/19/2015.
Pepys MB, Dash AC. Isolation of amyloid P component (protein AP) from normal serum as a calcium-dependent binding protein. Lancet 1977;1:1029-31.
Bodin K, Ellmerich S, Kahan MC, et al. Antibodies to human serum amyloid P component eliminate visceral amyloid deposits. Nature 2010;468:93-7.
Richards DB, Cookson LM, Berges AC, et al. Therapeutic Clearance of Amyloid by Antibodies to Serum Amyloid P Component. N Engl J Med 2015;373:1106-14.
…
The Acid-Mediated Denaturation Pathway of Transthyretin Yields a Conformational Intermediate That Can Self-Assemble into Amyloid†
Transthyretin (TTR) amyloid fibril formation is observed during partial acid denaturation and while refolding acid-denatured TTR, implying that amyloid fibril formation results from the self-assembly of a conformational intermediate. The acid denaturation pathway of TTR has been studied in detail herein employing a variety of biophysical methods to characterize the intermediate(s) capable of amyloid fibril formation. At physiological concentrations, tetrameric TTR remains associated from pH 7 to pH 5 and is incapable of amyloid fibril formation. Tetrameric TTR dissociates to a monomer in a process that is dependent on both pH and protein concentration below pH 5. The extent of amyloid fibril formation correlates with the concentration of the TTR monomer having an altered, but defined, tertiary structure over the pH range of 5.0−3.9. The inherent Trp fluorescence-monitored denaturation curve of TTR exhibits a plateau over the pH range where amyloid fibril formation is observed (albeit at a higher concentration), implying that a steady-state concentration of the amyloidogenic intermediate with an altered tertiary structure is being detected. Interestingly, 1-anilino-8-naphthalenesulfonate fluorescence is at a minimum at the pH associated with maximal amyloid fibril formation (pH 4.4), implying that the amyloidogenic intermediate does not have a high extent of hydrophobic surface area exposed, consistent with a defined tertiary structure. Transthyretin has two Trp residues in its primary structure, Trp-41 and Trp-79, which are conveniently located far apart in the tertiary structure of TTR. Replacement of each Trp with Phe affords two single Trp containing variants which were used to probe local pH-dependent tertiary structural changes proximal to these chromophores. The pH-dependent fluorescence behavior of the Trp-79-Phe mutant strongly suggests that Trp-41 is located near the site of the tertiary structural rearrangement that occurs in the formation of the monomeric amyloidogenic intermediate, likely involving the C-strand−loop−D-strand region. Upon further acidification of TTR (below pH 4.4), the structurally defined monomeric amyloidogenic intermediate begins to adopt alternative conformations that are not amyloidogenic, ultimately forming an A-state conformation below pH 3 which is also not amyloidogenic. In summary, analytical equilibrium ultracentrifugation, SDS−PAGE, far- and near-UV CD, fluorescence, and light scattering studies suggest that the amyloidogenic intermediate is a monomeric predominantly β-sheet structure having a well-defined tertiary structure.
Prevention of Transthyretin Amyloid Disease by Changing Protein Misfolding Energetics
Per Hammarström*, R. Luke Wiseman*, Evan T. Powers, Jeffery W. Kelly†+ Author Affiliations
Genetic evidence suggests that inhibition of amyloid fibril formation by small molecules should be effective against amyloid diseases. Known amyloid inhibitors appear to function by shifting the aggregation equilibrium away from the amyloid state. Here, we describe a series of transthyretin amyloidosis inhibitors that functioned by increasing the kinetic barrier associated with misfolding, preventing amyloidogenesis by stabilizing the native state. The trans-suppressor mutation, threonine 119 → methionine 119, which is known to ameliorate familial amyloid disease, also functioned through kinetic stabilization, implying that this small-molecule strategy should be effective in treating amyloid diseases.
Rational design of potent human transthyretin amyloid disease inhibitors
Thomas Klabunde1,2, H. Michael Petrassi3, Vibha B. Oza3, Prakash Raman3, Jeffery W. Kelly3 & James C. Sacchettini1
The human amyloid disorders, familial amyloid polyneuropathy, familial amyloid cardiomyopathy and senile systemic amyloidosis, are caused by insoluble transthyretin (TTR) fibrils, which deposit in the peripheral nerves and heart tissue. Several nonsteroidal anti-inflammatory drugs and structurally similar compounds have been found to strongly inhibit the formation of TTR amyloid fibrils in vitro. These include flufenamic acid, diclofenac, flurbiprofen, and resveratrol. Crystal structures of the protein–drug complexes have been determined to allow detailed analyses of the protein–drug interactions that stabilize the native tetrameric conformation of TTR and inhibit the formation of amyloidogenic TTR. Using a structure-based drug design approach ortho-trifluormethylphenyl anthranilic acid and N-(meta-trifluoromethylphenyl) phenoxazine 4,6-dicarboxylic acid have been discovered to be very potent and specific TTR fibril formation inhibitors. This research provides a rationale for a chemotherapeutic approach for the treatment of TTR-associated amyloid diseases.
First European consensus for diagnosis, management, and treatment of transthyretin familial amyloid polyneuropathy
Adams, Davida; Suhr, Ole B.b; Hund, Ernstc; Obici, Laurad; Tournev, Ivailoe,f; Campistol, Josep M.g; Slama, Michel S.h; Hazenberg, Bouke P.i; Coelho, Teresaj; from the European Network for TTR-FAP (ATTReuNET)
Purpose of review: Early and accurate diagnosis of transthyretin familial amyloid polyneuropathy (TTR-FAP) represents one of the major challenges faced by physicians when caring for patients with idiopathic progressive neuropathy. There is little consensus in diagnostic and management approaches across Europe.
Recent findings: The low prevalence of TTR-FAP across Europe and the high variation in both genotype and phenotypic expression of the disease means that recognizing symptoms can be difficult outside of a specialized diagnostic environment. The resulting delay in diagnosis and the possibility of misdiagnosis can misguide clinical decision-making and negatively impact subsequent treatment approaches and outcomes.
Summary: This review summarizes the findings from two meetings of the European Network for TTR-FAP (ATTReuNET). This is an emerging group comprising representatives from 10 European countries with expertise in the diagnosis and management of TTR-FAP, including nine National Reference Centres. The current review presents management strategies and a consensus on the gold standard for diagnosis of TTR-FAP as well as a structured approach to ongoing multidisciplinary care for the patient. Greater communication, not just between members of an individual patient’s treatment team, but also between regional and national centres of expertise, is the key to the effective management of TTR-FAP.
Transthyretin familial amyloid polyneuropathy (TTR-FAP) is a highly debilitating and irreversible neurological disorder presenting symptoms of progressive sensorimotor and autonomic neuropathy [1▪,2▪,3]. TTR-FAP is caused by misfolding of the transthyretin (TTR) protein leading to protein aggregation and the formation of amyloid fibrils and, ultimately, to amyloidosis (commonly in the peripheral and autonomic nervous system and the heart) [4,5]. TTR-FAP usually proves fatal within 7–12 years from the onset of symptoms, most often due to cardiac dysfunction, infection, or cachexia [6,7▪▪].
The prevalence and disease presentation of TTR-FAP vary widely within Europe. In endemic regions (northern Portugal, Sweden, Cyprus, and Majorca), patients tend to present with a distinct genotype in large concentrations, predominantly a Val30Met substitution in the TTR gene [8–10]. In other areas of Europe, the genetic footprint of TTR-FAP is more varied, with less typical phenotypic expression [6,11]. For these sporadic or scattered cases, a lack of awareness among physicians of variable clinical features and limited access to diagnostic tools (i.e., pathological studies and genetic screening) can contribute to high rates of misdiagnosis and poorer patient outcomes [1▪,11]. In general, early and late-onset variants of TTR-FAP, found within endemic and nonendemic regions, present several additional diagnostic challenges [11,12,13▪,14].
Delay in the time to diagnosis is a major obstacle to the optimal management of TTR-FAP. With the exception of those with a clearly diagnosed familial history of FAP, patients still invariably wait several years between the emergence of first clinical signs and accurate diagnosis [6,11,14]. The timely initiation of appropriate treatment is particularly pertinent, given the rapidity and irreversibility with which TTR-FAP can progress if left unchecked, as well as the limited effectiveness of available treatments during the later stages of the disease [14]. This review aims to consolidate the existing literature and present an update of the best practices in the management of TTR-FAP in Europe. A summary of the methods used to achieve a TTR-FAP diagnosis is presented, as well as a review of available treatments and recommendations for treatment according to disease status.
Patients with TTR-FAP can present with a range of symptoms [11], and care should be taken to acquire a thorough clinical history of the patient as well as a family history of genetic disease. Delay in diagnosis is most pronounced in areas where TTR-FAP is not endemic or when there is no positive family history [1▪]. TTR-FAP and TTR-familial amyloid cardiomyopathy (TTR-FAC) are the two prototypic clinical disease manifestations of a broader disease spectrum caused by an underlying hereditary ATTR amyloidosis [19]. In TTR-FAP, the disease manifestation of neuropathy is most prominent and definitive for diagnosis, whereas cardiomyopathy often suggests TTR-FAC. However, this distinction is often superficial because cardiomyopathy, autonomic neuropathy, vitreous opacities, kidney disease, and meningeal involvement all may be present with varying severity for each patient with TTR-FAP.
Among early onset TTR-FAP with usually positive family history, symptoms of polyneuropathy present early in the disease process and usually predominate throughout the progression of the disease, making neurological testing an important diagnostic aid [14]. Careful clinical examination (e.g., electromyography with nerve conduction studies and sympathetic skin response, quantitative sensation test, quantitative autonomic test) can be used to detect, characterize, and scale the severity of neuropathic abnormalities involving small and large nerve fibres [10]. Although a patient cannot be diagnosed definitively with TTR-FAP on the basis of clinical presentation alone, symptoms suggesting the early signs of peripheral neuropathy, autonomic dysfunction, and cardiac conduction disorders or infiltrative cardiomyopathy are all indicators that further TTR-FAP diagnostic investigation is warranted. Late-onset TTR-FAP often presents as sporadic cases with distinct clinical features (e.g., milder autonomic dysfunction) and can be more difficult to diagnose than early-onset TTR-FAP (Table 2) [1▪,11,12,13▪,14,20].
Genetic testing is carried out to allow detection of specific amyloidogenic TTR mutations (Table 1), using varied techniques depending on the expertise and facilities available in each country (Table S2, http://links.lww.com/CONR/A39). A targeted approach to detect a specific mutation can be used for cases belonging to families with previous diagnosis. In index cases of either endemic and nonendemic regions that do not have a family history of disease, are difficult to confirm, and have atypical symptoms, TTR gene sequencing is required for the detection of both predicted and new amyloidogenic mutations [26,27].
Following diagnosis, the neuropathy stage and systemic extension of the disease should be determined in order to guide the next course of treatment (Table 4) [3,30,31]. The three stages of TTR-FAP severity are graded according to a patient’s walking disability and degree of assistance required [30]. Systemic assessment, especially of the heart, eyes, and kidney, is also essential to ensure all aspects of potential impact of the disease can be detected [10].
The goals of cardiac investigations are to detect serious conduction disorders with the risk of sudden death and infiltrative cardiomyopathy. Electrocardiograms (ECG), Holter-ECG, and intracardiac electrophysiology study are helpful to detect conduction disorders. Echocardiograms, cardiac magnetic resonance imaging, scintigraphy with bone tracers, and biomarkers (e.g., brain natriuretic peptide, troponin) can all help to diagnose infiltrative cardiomyopathy[10]. An early detection of cardiac abnormalities has obvious benefits to the patient, given that the prophylactic implantation of pacemakers was found to prevent 25% of major cardiac events in TTR-FAP patients followed up over an average of 4 years [32▪▪]. Assessment of cardiac denervation with 123-iodine meta-iodobenzylguanidine is a powerful prognostic marker in patients diagnosed with FAP [33].
…..
Tafamidis
Tafamidis is a first-in-class therapy that slows the progression of TTR amyloidogenesis by stabilizing the mutant TTR tetramer, thereby preventing its dissociation into monomers and amyloidogenic and toxic intermediates [55,56]. Tafamidis is currently indicated in Europe for the treatment of TTR amyloidosis in adult patients with stage I symptomatic polyneuropathy to delay peripheral neurological impairment [57].
In an 18-month, double-blind, placebo-controlled study of patients with early-onset Val30Met TTR-FAP, tafamidis was associated with a 52% lower reduction in neurological deterioration (P = 0.027), a preservation of nerve function, and TTR stabilization versus placebo [58▪▪]. However, only numerical differences were found for the coprimary endpoints of neuropathy impairment [neuropathy impairment score in the lower limb (NIS-LL) responder rates of 45.3% tafamidis vs 29.5% placebo; P = 0.068] and quality of life scores [58▪▪]. A 12-month, open-label extension study showed that the reduced rates of neurological deterioration associated with tafamidis were sustained over 30 months, with earlier initiation of tafamidis linking to better patient outcomes (P = 0.0435) [59▪]. The disease-slowing effects of tafamidis may be dependent on the early initiation of treatment. In an open-label study with Val30Met TTR-FAP patients with late-onset and advanced disease (NIS-LL score >10, mean age 56.4 years), NIS-LL and disability scores showed disease progression despite 12 months of treatment with tafamidis, marked by a worsening of neuropathy stage in 20% and the onset of orthostatic hypotension in 22% of patients at follow-up [60▪].
Tafamidis is not only effective in patients exhibiting the Val30Met mutation; it also has proven efficacy, in terms of TTR stabilization, in non-Val30Met patients over 12 months [61]. Although tafamidis has demonstrated safe use in patients with TTR-FAP, care should be exercised when prescribing to those with existing digestive problems (e.g., diarrhoea, faecal incontinence) [60▪].
Diflunisal is a nonsteroidal anti-inflammatory drug (NSAID) that, similar to tafamidis, slows the rate of amyloidogenesis by preventing the dissociation, misfolding, and misassembly of the mutated TTR tetramer [62,63]. Off-label use has been reported for patients with stage I and II disease, although diflunisal is not currently licensed for the treatment of TTR-FAP.
Evidence for the clinical effectiveness of diflunisal in TTR-FAP derives from a placebo-controlled, double-blind, 24-month study in 130 patients with clinically detectable peripheral or autonomic neuropathy[64▪]. The deterioration in NIS scores was significantly more pronounced in patients receiving placebo compared with those taking diflunisal (P = 0.001), and physical quality of life measures showed significant improvement among diflunisal-treated patients (P = 0.001). Notable during this study was the high rate of attrition in the placebo group, with 50% more placebo-treated patients dropping out of this 2-year study as a result of disease progression, advanced stage of the disease, and varied mutations.
One retrospective analysis of off-label use of diflunisal in patients with TTR-FAP reported treatment discontinuation in 57% of patients because of adverse events that were largely gastrointestinal [65]. Conclusions on the safety of diflunisal in TTR-FAP will depend on further investigations on the impact of known cardiovascular and renal side-effects associated with the NSAID drug class [66,67].
The retina is responsible for capturing images from the visual field. Retinitis pigmentosa, which refers to a group of inherited diseases that cause retinal degeneration, causes a gradual decline in vision because retinal photoreceptor cells (rods and cones) die. Images on the left are courtesy of the National Eye Institute, NIH; image on the right is courtesy of Robert Fariss, Ph.D., and Ann Milam, Ph.D., National Eye Institute, NIH.
Metabolomics, the comprehensive evaluation of the products of cellular processes, can provide new findings and insight in a vast array of diseases and dysfunctions. Though promising, metabolomics lacks the standing of genomics or proteomics. It is, in a manner of speaking, the new kid on the “omics” block.
Even though metabolomics is still an emerging discipline, at least some quarters are giving it a warm welcome. For example, metabolomics is being advanced by the Common Fund, an initiate of the National Institutes of Health (NIH). The Common Fund has established six national metabolomics cores. In addition, individual agencies within NIH, such as the National Institute of Environmental Health Sciences (NIEHS), are releasing solicitations focused on growing more detailed metabolomics programs.
Whether metabolomic studies are undertaken with or without public support, they share certain characteristics and challenges. Untargeted or broad-spectrum studies are used for hypotheses generation, whereas targeted studies probe specific compounds or pathways. Reproducibility is a major challenge in the field; many studies cannot be reproduced in larger cohorts. Carefully defined guidance and standard operating procedures for sample collection and processing are needed.
While these challenges are being addressed, researchers are patiently amassing metabolomic insights in several areas, such as retinal diseases, neurodegenerative diseases, and autoimmune diseases. In addition, metabolomic sleuths are availing themselves of a growing selection of investigative tools.
A Metabolomic Eye on Retinal Degeneration
The retina has one of the highest metabolic activities of any tissue in the body and is composed of multiple cell types. This fact suggests that metabolomics might be helpful in understanding retinal degeneration. At least, that’s what occurred to Ellen Weiss, Ph.D., a professor of cell biology and physiology at the University of North Carolina School of Medicine at Chapel Hill. To explore this possibility, Dr. Weiss began collaborating with Susan Sumner, Ph.D., director of systems and translational sciences at RTI International.
Retinal degeneration is often studied through the use of genetic-mouse models that mimic the disease in humans. In the model used by Dr. Weiss, cells with a disease-causing mutation are the major light-sensing cells that degenerate during the disease. Individuals with the same or a similar genetic mutation will initially lose dim-light vision then, ultimately, bright-light vision and color vision.
Wild-type and mutant phenotypes, as well as dark- and light-raised animals, were compared, since retinal degeneration is exacerbated by light in this genetic model. Retinas were collected as early as day 18, prior to symptomatic disease, and analyzed. Although data analysis is ongoing, distinct differences have emerged between the phenotypes as well as between dark- and light-raised animals.
“There is a clear increase in oxidative stress in both light-raised groups but to a larger extent in the mutant phenotype,” reports Dr. Weiss. “There are global changes in metabolites that suggest mitochondrial dysfunction, and dramatic changes in lipid profiles. Now we need to understand how these metabolites are involved in this eye disease and the relevance of these perturbations.”
For example, the glial cells in the retina that upregulate a number of proteins in response to stress to attempt to save the retina are as likely as the light-receptive neurons to undergo metabolic changes.
“One of the challenges in metabolomics studies is assigning the signals that represent the metabolites or compounds in the samples,” notes Dr. Sumner. “Signals may be ‘unknown unknowns,’ compounds that have never been identified before, or ‘known unknowns,’ compounds that are known but that have not yet been assigned in the biological matrix.”
Internal and external libraries, such as the Human Metabolome Dictionary, are used to match signals. Whether or not a match exists, fragmentation patterns are used to characterize the metabolite, and when possible a standard is obtained to confirm identity. To assist with this process, the NIH Common Fund supports Metabolite Standard Synthesis Cores (MSSCs). RTI International holds an MSSC contract in addition to being a NIH-designated metabolomics core.
Mitochondrial Dysfunction in Alzheimer’s Disease
Alzheimer’s disease (AD) is difficult to diagnose early due to its asymptomatic phase; accurate diagnosis occurs only in postmortem brain tissue. To evaluate familial AD, a rare inherited form of the disease, the laboratory of Eugenia Trushina, Ph.D., associate professor of neurology and associate professor of pharmacology at the Mayo Clinic, uses mouse models to study the disease’s early molecular mechanisms.
Synaptic loss underlies cognitive dysfunction. The length of neurons dictates that mitochondria move within the cell to provide energy at the site of the synapses. An initial finding was that very early on mitochondrial trafficking was affected reducing energy supply to synapses and distant parts of the cell.
During energy production, the major mitochondrial metabolite is ATP, but the organelle also produces many other metabolites, molecules that are implicated in many pathways. One can assume that changes in energy utilization, production, and delivery are associated with some disturbance.
“Our goal,” explains Dr. Trushina, “was to get a proof of concept that we could detect in the blood of AD patients early changes of mitochondria dysfunction or other changes that could be informative of the disease over time.”
A Mayo Clinic aging study involves a cohort of patients, from healthy to those with mild cognitive impairment (MCI) through AD. Patients undergo an annual battery of tests including cognitive function along with blood and cerebrospinal fluid sampling. Metabolic signatures in plasma and cerebrospinal fluid of normal versus various disease stages were compared, and affected mitochondrial and lipid pathways identified in MCI patients that progressed to AD.
“Last year we published on a new compound that goes through the blood/brain barrier, gets into mitochondria, and very specifically, partially inhibits mitochondrial complex I activity, making the cell resistant to oxidative damage,” details Dr. Trushina. “The compound was able to either prevent or slow the disease in the animal familial models.
“Treatment not only reduced levels of amyloid plaques and phosphorylated tau, it also restored mitochondrial transport in neurons. Now we have additional compounds undergoing investigation for safety in humans, and target selectivity and engagement.”
“Mitochondria play a huge role in every aspect of our lives,” Dr. Trushina continues. “The discovery seems counterintuitive, but if mitochondria function is at the heart of AD, it may provide insight into the major sporadic form of the disease.”
Distinguishing Types of Asthma
In children, asthma generally manifests as allergy-induced asthma, or allergic asthma. And allergic asthma has commonalities with allergic dermatitis/eczema, food allergies, and allergic rhinitis. In adults, asthma is more heterogeneous, and distinct and varied subpopulations emerge. Some have nonallergic asthma; some have adult-onset asthma; and some have obesity-, occupational-, or exercise-induced asthma.
Adult asthmatics may have markers of TH2 high verus TH2 low asthma (T helper 2 cell cytokines) and they may respond to various triggers—environmental antigens, occupational antigens, irritants such as perfumes and chlorine, and seasonal allergens. Exercise, too, can trigger asthma.
One measure that can phenotype asthmatics is nitric oxide, an exhaled breath biomarker. Nitric oxide is a smooth muscle relaxant, vasodilator, and bronchodilator that can have anti-inflammatory properties. There is a wide range of values in asthmatics, and a number of values are needed to understand the trend in a particular patient. L-arginine is the amino acid that produces nitric oxide when converted to L-citrulline, a nonessential amino acid.
According to Nicholas Kenyon, M.D., a pulmonary and critical care specialist who is co-director of the University of California, Davis Asthma Network (UCAN), some metabolomic studies suggest that there is a state of L-arginine depletion during asthma attacks or in severe asthma suggesting a lack of substrate to produce nitric oxide. Dr. Kenyon is conducting clinical work on L-arginine supplementation in a double-blind cross-over intervention trial of L-arginine versus placebo. The 50-subject study in severe asthmatics should be concluded in early 2017.
Many new biologic therapies are coming to market to treat asthma; it will be challenging to determine which advanced therapy to provide to which patient. Therapeutics mostly target severe asthma populations and are for patients with evidence of higher numbers of eosinophils in the blood and lung, which include anti-IL-5 and (soon) anti-IL-13, among others.
Tools Development
Waters is developing metabolomics applications that use multivariate statistical methods to highlight compounds of interest. Typically these applications combine separation procedures, accomplished by means of liquid chromatography or gas chromatography (LC or GC), with detection methods that rely on mass spectrometry (MS). To support the identification, quantification, and analysis of LC-MS data, the company provides bioinformatics software. For example, Progenesis QI software can interrogate publicly available databases and process information about isotopic patterns, retention times, and collision cross-sections.
Mass spectrometry (MS) is the gold standard in metabolomics and lipidomics. But there is a limit to what accurate mass and resolution can achieve. For example, neither isobaric nor isomeric species are resolvable solely by MS. New orthogonal analytical tools will allow more confident identifications.
To improve metabolomics separations before MS detection, a post-ionization separation tool, like ion mobility, which is currently used to support traditional UPLC-MS and MS imaging metabolomics protocols, becomes useful. The collision-cross section (CCS), which measures the shape of molecules, can be derived, and it can be used as an additional identification coordinate.
Other new chromatographic tools are under development, such as microflow devices and UltraPerformance Convergence Chromatography (UPC2), which uses liquid CO2 as its mobile phase, to enable new ways of separating chiral metabolites. Both UPC2 and microflow technologies have decreased solvent consumption and waste disposal while maintaining UPLC-quality performance in terms of chromatographic resolution, robustness, and reproducibility.
Informatics tools are also improving. In the latest versions of Waters’ Progenesis software, typical metabolomics identification problems are resolved by allowing interrogation of publicly available databases and scoring according to accurate mass, isotopic pattern, retention time, CCS, and either theoretical or experimental fragments.
MS imaging techniques, such as MALDI and DESI, provide spatial information about the metabolite composition in tissues. These approaches can be used to support and confirm traditional analyses without sample extraction, and they allow image generation without the use of antibodies, similar to immunohistochemistry.
“Ion-mobility tools will soon be implemented for routine use, and the use of extended CCS databases will help with metabolite identification,” comments Giuseppe Astarita Ph.D., principal scientist, Waters. “More applications of ambient ionization MS will emerge, and they will allow direct-sampling analyses at atmospheric pressure with little or no sample preparation, generating real-time molecular fingerprints that can be used to discriminate among phenotypes.”
Microflow Technology
Microflow technology offers sensitivity and robustness. For example, at the Proteomics and Metabolomics Facility, Colorado State University, peptide analysis was typically performed using nanoflow chromatography; however, nanoflow chromatography is slow and technically challenging. Moving to microflow offered significant improvements in robustness and ease-of-use and resulted in improved chromatography without sacrificing sensitivity.
Conversely, small molecule applications were typically performed with analytical-scale chromatography. While this flow regime is extremely robust and fast, it can sometimes be limited in sensitivity. Moving to microflow offered significant improvements in sensitivity, 5- to 10-fold depending on the compound, without sacrificing robustness.
But broad-scale microflow adoption is hampered by a lack of available column chemistries and legacy HPLC or UPLC infrastructure that is not conducive to low-flow operation.
“We utilize microflow technology on all of our tandem quadrupole instruments for targeted quantitative assays,” says Jessica Prenni, Ph.D., director, Proteomics and Metabolomics Facility, Colorado State University. “All of our peptide quantitation is exclusively performed with microflow technology, and many of our small molecule assays. Application examples include endocannabinoids, bile acids and plant phytohormone panels.”
Compound annotation and comparability and transparency in data processing and reporting is a challenge in metabolomics research. Multiple groups are actively working on developing new tools and strategies; common best practices need to be adopted.
The continued growth of open-source spectral databases and new tools for spectral prediction from compound databases will dramatically impact the ability for metabolomics to result in novel discoveries. The move to a systems-level understanding through the combination of various omics data also will have a huge influence and be enabled by the continued development of open-source and user-friendly pathway-analysis tools.
Where Trackless Terrain Once Challenged Biomarker Development, Clearer Paths Are Emerging
Fusion detection can be carried out with traditional opposing primer-based library preparation methods, which require target- and fusion-specific primers that define the region to be sequenced. With these methods, primers are needed that flank the target region and the fusion partner, so only known fusions can be detected. An alternative method, ArcherDX’ Anchored Multiplex PCR (AMP), can be used to detect the target of interest, plus any known and unknown fusion partners. This is because AMP uses target-specific unidirectional primers, along with reverse primers, that hybridize to the sequencing adapter that is ligated to each fragment prior to amplification.
In time, the narrow, tortuous paths followed by pioneers become wider and straighter, whether the pioneers are looking to settle new land or bring new biomarkers to the clinic.
In the case of biomarkers, we’re still at the stage where pioneers need to consult guides and outfitters or, in modern parlance, consultants and technology providers. These hardy souls tend to congregate at events like the Biomarker Conference, which was held recently in San Diego.
At this event, biomarker experts discussed ways to avoid unfortunate detours on the trail from discovery and development to clinical application and regulatory approval. Of particular interest were topics such as the identification of accurate biomarkers, the explication of disease mechanisms, the stratification of patient groups, and the development of standard protocols and assay platforms. In each of these areas, presenters reported progress.
Another crucial subject is the integration of techniques such as next-generation sequencing (NGS). This particular technique has been instrumental in advancing clinical cancer genomics and continues to be the most feasible way of simultaneously interrogating multiple genes for driver mutations.
Enriching nucleic acid libraries for target genes of interest prior to NGS greatly enhances the sensitivity of detecting mutations, as the enriched regions are sequenced multiple times. This is particularly useful when analyzing clinical samples, which generate low amounts of poor-quality nucleic acids.
Most target-enrichment strategies require prior knowledge of both ends of the target region to be sequenced. Therefore, only gene fusions with known partners can be amplified for downstream NGS assays.
Archer’s Anchored Multiplex PCR (AMP™) technology overcomes this limitation, as it can enrich for novel fusions, while only requiring knowledge of one end of the fusion pair. At the heart of the AMP chemistry are unique Molecular Barcode (MBC) adapters, ligated to the 5′ ends of DNA fragments prior to amplification. The MBCs contain universal primer binding sites for PCR and a molecular barcode for identifying unique molecules. When combined with 3′ gene-specific primers, MBCs enable amplification of target regions with unknown 5′ ends.
“Tagging each molecule of input nucleic acid with a unique molecular barcode allows for de-duplication, error correction, and quantitative analysis, resulting in high sequencing consensus. With its low error rate and low limits of detection, AMP is revolutionizing the field of cancer genomics.”
In a proof-of-concept study, a single-tube 23-plex panel was designed to amplify the kinase domains of ALK, RET, ROS1, and MUSK genes by AMP. This enrichment strategy enabled identification of gene fusions with multiple partners and alternative splicing events in lung cancer, thyroid cancer, and glioblastoma specimens by NGS.
Over the last decade, the Biomarker/Translational Research Laboratory has focused on developing clinical genotyping and fluorescent in situ hybridization (FISH) assays for rapid personalized genomic testing.
“Initially, we analyzed the most prevalent hotspot mutations, about 160 in 25 cancer genes,” continued Dr. Borger. “However, this approach revealed mutations in only half of our patients. With the advent of NGS, we are able to sequence 190 exons in 39 cancer genes and obtain significantly richer genetic fingerprints, finding genetic aberrations in 92% of our cancer patients.”
Using multiplexed approaches, Dr. Borger’s team within the larger Center for Integrated Diagnostics (CID) program at MGH has established high-throughput genotyping service as an important component of routine care. While only a few susceptible molecular alterations may currently have a corresponding drug, the NGS-driven analysis may supply new information for inclusion of patients into ongoing clinical trials, or bank the result for future research and development.
“A significant impediment to discovery of clinically relevant genomic signatures is our current inability to interconnect the data,” explained Dr. Borger. “On the local level, we are striving to compile the data from clinical observations, including responses to therapy and genotyping. Globally, it is imperative that comprehensive public databases become available to the research community.”
This image, from the Massachusetts General Hospital Cancer Center, shows multicolor fluorescence in situ hybridization (FISH) analysis of cells from a patient with esophagogastric cancer. Remarkably, the FISH analysis revealed that co-amplification of the MET gene (red signal) and the EGFR gene (green signal) existed simultaneously in the same tumor cells. A chromosome 7 control probe is shown in blue.
Tumor profiling at MGH have already yielded significant discoveries. Dr. Borger’s lab, in collaboration with oncologists at the MGH Cancer Center, found significant correlations between mutations in the genes encoding the metabolic enzymes isocitrate dehydrogenase (IDH1 and IDH2) and certain types of cancers, such as cholangiocarcinoma and acute myelogenous leukemia (AML).
Historically, cancer signatures largely focus on signaling proteins. Discovery of a correlative metabolic enzyme offered a promise of diagnostics based on metabolic byproducts that may be easily identified in blood. Indeed, the metabolite 2-hydroxyglutarate accumulates to high levels in the tissues of patients carrying IDH1 and IDH2 mutations. They have reported that circulating 2-hydroxyglutarate as measured in the blood correlates with tumor burden, and could serve as an important surrogate marker of treatment response. …..
Researchers Uncover How ‘Silent’ Genetic Changes Drive Cancer
“Traditionally, it has been hard to use standard methods to quantify the amount of tRNA in the cell,” says Tavazoie. The lead authors of the article, Hani Goodarzi, formerly a postdoc in the lab and now a new assistant professor at UCSF, and research assistant Hoang Nguyen, devised and applied a new method that utilizes state-of-the-art genomic sequencing technology to measure the amount of tRNAs in different cell types.
The team chose to compare breast tissue from healthy individuals with tumor samples taken from breast cancer patients–including both primary tumors that had not spread from the breast to other body sites, and highly aggressive, metastatic tumors.
They found that the levels of two specific tRNAs were significantly higher in metastatic cells and metastatic tumors than in primary tumors that did not metastasize or healthy samples. “There are four different ways to encode for the protein building block arginine,” explains Tavazoie. “Yet only one of those–the tRNA that recognizes the codon CGG–was associated with increased metastasis.”
The tRNA that recognizes the codon GAA and encodes for a building block known as glutamic acid was also elevated in metastatic samples.
The team hypothesized that the elevated levels of these tRNAs may in fact drive metastasis. Working in mouse models of primary, non-metastatic tumors, the researchers increased the production of the tRNAs, and found that these cells became much more invasive and metastatic.
They also did the inverse experiment, with the anticipated results: reducing the levels of these tRNAs in metastatic cells decreased the incidence of metastases in the animals.
How do two tRNAs drive metastasis? The researchers teamed up with members of the Rockefeller University proteomics facility to see how protein expression changes in cells with elevated levels of these two tRNAs.
“We found global increases in many dozens of genes,” says Tavazoie, “so we analyzed their sequences and found that the majority of them had significantly increased numbers of these two specific codons.”
According to the researchers, two genes stood out among the list. Known as EXOSC2 and GRIPAP1, these genes were strongly and directly induced by elevated levels of the specific glutamic acid tRNA.
“When we mutated the GAA codons to GAG– a “silent” mutation because they both spell out the protein building block glutamic acid–we found that increasing the amount of tRNA no longer increased protein levels,” explains Tavazoie. These proteins were found to drive breast cancer metastasis.
The work challenges previous assumptions about how tRNAs function and suggests that tRNAs can modulate gene expression, according to the researchers. Tavazoie points out that “it is remarkable that within a single cell type, synonymous changes in genetic sequence can dramatically affect the levels of specific proteins, their transcripts, and the way a cell behaves.”
Testing Blood Metabolites Could Help Tailor Cancer Treatment
Scientists have found that measuring how cancer treatment affects the levels of metabolites – the building blocks of fats and proteins – can be used to assess whether the drug is hitting its intended target.
This new way of monitoring cancer therapy could speed up the development of new targeted drugs – which exploit specific genetic weaknesses in cancer cells – and help in tailoring treatment for patients.
Scientists at The Institute of Cancer Research, London, measured the levels of 180 blood markers in 41 patients with advanced cancers in a phase I clinical trial conducted with The Royal Marsden NHS Foundation Trust.
They found that investigating the mix of metabolic markers could accurately assess how cancers were responding to the targeted drug pictilisib.
Their study was funded by the Wellcome Trust, Cancer Research UK and the pharmaceutical company Roche, and is published in the journal Molecular Cancer Therapeutics.
Pictilisib is designed to specifically target a molecular pathway in cancer cells, called PI3 kinase, which has key a role in cell metabolism and is defective in a range of cancer types.
As cancers with PI3K defects grow, they can cause a decrease in the levels of metabolites in the bloodstream.
The new study is the first to show that blood metabolites are testable indicators of whether or not a new cancer treatment is hitting the correct target, both in preclinical mouse models and also in a trial of patients.
Using a sensitive technique called mass spectrometry, scientists at The Institute of Cancer Research (ICR) initially analysed the metabolite levels in the blood of mice with cancers that had defects in the PI3K pathway.
They found that the blood levels of 26 different metabolites, which were low prior to therapy, had risen considerably following treatment with pictilisib. Their findings indicated that the drug was hitting its target, and reversing the effects of the cancer on mouse metabolites.
Similarly, in humans the ICR researchers found that almost all of the metabolites – 22 out of the initial 26 – once again rose in response to pictilisib treatment, as seen in the mice.
Blood levels of the metabolites began to increase after a single dose of pictilisib, and were seen to drop again when treatment was stopped, suggesting that the effect was directly related to the drug treatment.
Metabolites vary naturally depending on the time of day or how much food a patient has eaten. But the researchers were able to provide the first strong evidence that despite this variation metabolites can be used to test if a drug is working, and could help guide decisions about treatment.
New Metabolic Pathway Reveals Aspirin-Like Compound’s Anti-Cancer Properties
Researchers at the Gladstone Institutes say they have found a new pathway by which salicylic acid, a key compound in the nonsteroidal anti-inflammatory drugs aspirin and diflunisal, stops inflammation and cancer.
In a study (“Salicylate, Diflunisal and Their Metabolites Inhibit CBP/p300 and Exhibit Anticancer Activity”) published in eLife, the investigators discovered that both salicylic acid and diflunisal suppress two key proteins that help control gene expression throughout the body. These sister proteins, p300 and CREB-binding protein (CBP), are epigenetic regulators that control the levels of proteins that cause inflammation or are involved in cell growth.
By inhibiting p300 and CBP, salicylic acid and diflunisal block the activation of these proteins and prevent cellular damage caused by inflammation. This study provides the first concrete demonstration that both p300 and CBP can be targeted by drugs and may have important clinical implications, according to Eric Verdin, M.D., associate director of the Gladstone Institute of Virology and Immunology .
“Salicylic acid is one of the oldest drugs on the planet, dating back to the Egyptians and the Greeks, but we’re still discovering new things about it,” he said. “Uncovering this pathway of inflammation that salicylic acid acts upon opens up a host of new clinical possibilities for these drugs.”
Earlier research conducted in the laboratory of co-author Stephen D. Nimer, M.D., director of Sylvester Comprehensive Cancer Center at the University of Miami Miller School of Medicine, and a collaborator of Verdin’s, established a link between p300 and the leukemia-promoting protein AML1-ETO. In the current study, scientists at Gladstone and Sylvester worked together to test whether suppressing p300 with diflunisal would suppress leukemia growth in mice. As predicted, diflunisal stopped cancer progression and shrunk the tumors in the mouse model of leukemia. ……
Novel Protein Agent Targets Cancer and Host of Other Diseases
Researchers at Georgia State University have designed a new protein compound that can effectively target the cell surface receptor integrin v3, mutations in which have been linked to a number of diseases. Initial results using this new molecule show its potential as a therapeutic treatment for an array of illnesses, including cancer.
The novel protein molecule targets integrin v3 at a novel site that has not been targeted by other scientists. The researchers found that the molecule induces apoptosis, or programmed cell death, of cells that express integrin v3. This integrin has been a focus for drug development because abnormal expression of v3 is linked to the development and progression of various diseases.
“This integrin pair, v3, is not expressed in high levels in normal tissue,” explained senior study author Zhi-Ren Liu, Ph.D., professor in the department of biology at Georgia State. “In most cases, it’s associated with a number of different pathological conditions. Therefore, it constitutes a very good target for multiple disease treatment.”
“Here we use a rational design approach to develop a therapeutic protein, which we call ProAgio, which binds to integrin αvβ3 outside the classical ligand-binding site,” the authors wrote. “We show ProAgio induces apoptosis of integrin αvβ3-expressing cells by recruiting and activating caspase 8 to the cytoplasmic domain of integrin αvβ3.”
The findings from this study were published recently in Nature Communications in an article entitled “Rational Design of a Protein That Binds Integrin αvβ3 Outside the Ligand Binding Site.” …..
“We took a unique angle,” Dr. Lui noted. “We designed a protein that binds to a different site. Once the protein binds to the site, it directly triggers cell death. When we’re able to kill pathological cells, then we’re able to kill the disease.”
The investigators performed extensive cell and molecular testing that confirmed ProAgio interacts and binds well with integrin v3. Interestingly, they found that ProAgio induces apoptosis by recruiting caspase 8—an enzyme that plays an essential role in programmed cell death—to the cytoplasmic area of integrin v3. ProAgio was much more effective in inducing cell death than other agents tested.
Noncoding RNAs Not So Noncoding
Bits of the transcriptome once believed to function as RNA molecules are in fact translated into small proteins.
In 2002, a group of plant researchers studying legumes at the Max Planck Institute for Plant Breeding Research in Cologne, Germany, discovered that a 679-nucleotide RNA believed to function in a noncoding capacity was in fact a protein-coding messenger RNA (mRNA).1 It had been classified as a long (or large) noncoding RNA (lncRNA) by virtue of being more than 200 nucleotides in length. The RNA, transcribed from a gene called early nodulin 40 (ENOD40), contained short open reading frames (ORFs)—putative protein-coding sequences bookended by start and stop codons—but the ORFs were so short that they had previously been overlooked. When the Cologne collaborators examined the RNA more closely, however, they found that two of the ORFs did indeed encode tiny peptides: one of 12 and one of 24 amino acids. Sampling the legumes confirmed that these micropeptides were made in the plant, where they interacted with a sucrose-synthesizing enzyme.
Five years later, another ORF-containing mRNA that had been posing as a lncRNA was discovered inDrosophila.2,3 After performing a screen of fly embryos to find lncRNAs, Yuji Kageyama, then of the National Institute for Basic Biology in Okazaki, Japan, suppressed each transcript’s expression. “Only one showed a clear phenotype,” says Kageyama, now at Kobe University. Because embryos missing this particular RNA lacked certain cuticle features, giving them the appearance of smooth rice grains, the researchers named the RNA “polished rice” (pri).
Turning his attention to how the RNA functioned, Kageyama thought he should first rule out the possibility that it encoded proteins. But he couldn’t. “We actually found it was a protein-coding gene,” he says. “It was an accident—we are RNA people!” The pri gene turned out to encode four tiny peptides—three of 11 amino acids and one of 32—that Kageyama and colleagues showed are important for activating a key developmental transcription factor.4
Since then, a handful of other lncRNAs have switched to the mRNA ranks after being found to harbor micropeptide-encoding short ORFs (sORFs)—those less than 300 nucleotides in length. And given the vast number of documented lncRNAs—most of which have no known function—the chance of finding others that contain micropeptide codes seems high.
Overlooked ORFs
From the late 1990s into the 21st century, as species after species had their genomes sequenced and deposited in databases, the search for novel genes and their associated mRNAs duly followed. With millions or even billions of nucleotides to sift through, researchers devised computational shortcuts to hunt for canonical gene and mRNA features, such as promoter regions, exon/intron splice sites, and, of course, ORFs.
ORFs can exist in practically any stretch of RNA sequence by chance, but many do not encode actual proteins. Because the chance that an ORF encodes a protein increases with its length, most ORF-finding algorithms had a size cut-off of 300 nucleotides—translating to 100 amino acids. This allowed researchers to “filter out garbage—that is, meaningless ORFs that exist randomly in RNAs,” says Eric Olsonof the University of Texas Southwestern Medical Center in Dallas.
Of course, by excluding all ORFs less than 300 nucleotides in length, such algorithms inevitably missed those encoding genuine small peptides. “I’m sure that the people who came up with [the cut-off] understood that this rule would have to miss anything that was shorter than 100 amino acids,” saysNicholas Ingolia of the University of California, Berkeley. “As people applied this rule more and more, they sort of lost track of that caveat.” Essentially, sORFs were thrown out with the computational trash and forgotten.
Aside from statistical practicality and human oversight, there were also technical reasons that contributed to sORFs and their encoded micropeptides being missed. Because of their small size, sORFs in model organisms such as mice, flies, and fish are less likely to be hit in random mutagenesis screens than larger ORFs, meaning their functions are less likely to be revealed. Also, many important proteins are identified based on their conservation across species, says Andrea Pauli of the Research Institute of Molecular Pathology in Vienna, but “the shorter [the ORF], the harder it gets to find and align this region to other genomes and to know that this is actually conserved.”
As for the proteins themselves, the standard practice of using electrophoresis to separate peptides by size often meant micropeptides would be lost, notes Doug Anderson, a postdoc in Olson’s lab. “A lot of times we run the smaller things off the bottom of our gels,” he says. Standard protein mass spectrometry was also problematic for identifying small peptides, says Gerben Menschaert of Ghent University in Belgium, because “there is a washout step in the protocol so that only larger proteins are retained.”
But as researchers take a deeper dive into the function of the thousands of lncRNAs believed to exist in genomes, they continue to uncover surprise micropeptides. In February 2014, for example, Pauli, then a postdoc in Alex Schier’s lab at Harvard University, discovered a hidden code in a zebrafish lncRNA. She had been hunting for lncRNAs involved in zebrafish development because “we hadn’t really anticipated that there would be any coding regions out there that had not been discovered—at least not something that is essential,” she says. But one lncRNA she identified actually encoded a 58-amino-acid micropeptide, which she called Toddler, that functioned as a signaling protein necessary for cell movements that shape the early embryo.5
Then, last year, Anderson and his colleagues reported another. Since joining Olson’s lab in 2010, Anderson had been searching for lncRNAs expressed in the heart and skeletal muscles of mouse embryos. He discovered a number of candidates, but one stood out for its high level of sequence conservation—suggesting to Anderson that it might have an important function. He was right, the RNA was important, but for a reason that neither Anderson nor Olson had considered: it was in fact an mRNA encoding a 46-amino-acid-long micropeptide.6
“When we zeroed in on the conserved region [of the gene], Doug found that it began with an ATG [start] codon and it terminated with a stop codon,” Olson says. “That’s when he looked at whether it might encode a peptide and found that indeed it did.” The researchers dubbed the peptide myoregulin, and found that it functioned as a critical calcium pump regulator for muscle relaxation.
With more and more overlooked peptides now being revealed, the big question is how many are left to be discovered. “Were there going to be dozens of [micropeptides]? Were there going to be hundreds, like there are hundreds of microRNAs?” says Ingolia. “We just didn’t know.”
Little things mean a lot. To any biologist, this time-worn maxim is old news. But it’s worth revisiting. As several articles in this issue of The Scientist illustrate, how researchers define and examine the “little things” does mean a lot.
Consider this month’s cover story, “Noncoding RNAs Not So Noncoding,” by TS correspondent Ruth Williams. Combing the human genome for open reading frames (ORFs), sequences bracketed by start and stop codons, yielded a protein-coding count somewhere in the neighborhood of 24,000. That left a lot of the genome relegated to the category of junk—or, later, to the tens of thousands of mostly mysterious long noncoding RNAs (lncRNAs). But because they had only been looking for ORFs that were 300 nucleotides or longer (i.e., coding for proteins at least 100 amino acids long), genome probers missed so-called short ORFs (sORFs), which encode small peptides. “Their diminutive size may have caused these peptides to be overlooked, their sORFs to be buried in statistical noise, and their RNAs to be miscategorized, but it does not prevent them from serving important, often essential functions, as the micropeptides characterized to date demonstrate,” writes Williams.
How little things work definitely informs another field of life science research: synthetic biology. As the functions of genes and gene networks are sussed out, bioengineers are using the information to design small, synthetic gene circuits that enable them to better understand natural networks. In “Synthetic Biology Comes into Its Own,” Richard Muscat summarizes the strides made by synthetic biologists over the last 15 years and offers an optimistic view of how such networks may be put to use in the future. And to prove him right, just as we go to press, a collaborative group led by one of syn bio’s founding fathers, MIT’s James Collins, has devised a paper-based test for Zika virus exposure that relies on a freeze-dried synthetic gene circuit that changes color upon detection of RNAs in the viral genome. The results are ready in a matter of hours, not the days or weeks current testing takes, and the test can distinguish Zika from dengue virus. “What’s really exciting here is you can leverage all this expertise that synthetic biologists are gaining in constructing genetic networks and use it in a real-world application that is important and can potentially transform how we do diagnostics,” commented one researcher about the test.
Moving around little things is the name of the game when it comes to delivering a package of drugs to a specific target or to operating on minuscule individual cells. Mini-scale delivery of biocompatible drug payloads often needs some kind of boost to overcome fluid forces or size restrictions that interfere with fine-scale manipulation. To that end, ingenious solutions that motorize delivery by harnessing osmotic changes, magnets, ultrasound, and even bacterial flagella are reviewed in “Making Micromotors Biocompatible.”
Cilengitide, a cyclic RGD pentapeptide, is currently in clinical phase III for treatment of glioblastomas and in phase II for several other tumors. This drug is the first anti-angiogenic small molecule targeting the integrins αvβ3, αvβ5 and α5β1. It was developed by us in the early 90s by a novel procedure, the spatial screening. This strategy resulted in c(RGDfV), the first superactive αvβ3 inhibitor (100 to 1000 times increased activity over the linear reference peptides), which in addition exhibited high selectivity against the platelet receptor αIIbβ3. This cyclic peptide was later modified by N-methylation of one peptide bond to yield an even greater antagonistic activity in c(RGDf(NMe)V). This peptide was then dubbed Cilengitide and is currently developed as drug by the company Merck-Serono (Germany).
This article describes the chemical development of Cilengitide, the biochemical background of its activity and a short review about the present clinical trials. The positive anti-angiogenic effects in cancer treatment can be further increased by combination with “classical” anti-cancer therapies. Several clinical trials in this direction are under investigation.
Integrins are heterodimeric receptors that are important for cell-cell and cell-extracellular matrix (ECM) interactions and are composed of one α and one β-subunit [1, 2]. These cell adhesion molecules act as transmembrane linkers between their extracellular ligands and the cytoskeleton, and modulate various signaling pathways essential in the biological functions of most cells. Integrins play a crucial role in processes such as cell migration, differentiation, and survival during embryogenesis, angiogenesis, wound healing, immune and non-immune defense mechanisms, hemostasis and oncogenic transformation [1]. The fact that many integrins are also linked with pathological conditions has converted them into very promising therapeutic targets [3]. In particular, integrins αvβ3, αvβ5 and α5β1 are involved in angiogenesis and metastasis of solid tumors, being excellent candidates for cancer therapy [4–7].
There are a number of different integrin subtypes which recognize and bind to the tripeptide sequence RGD (arginine, glycine, aspartic acid), which represents the most prominent recognition motif involved in cell adhesion. For example, the pro-angiogenic αvβ3 integrin binds various RGD-containing proteins, including fibronectin (Fn), fibrinogen (Fg), vitronectin (Vn) and osteopontin [8]. It is therefore not surprising that this integrin has been targeted for cancer therapy and that RGD-containing peptides and peptidomimetics have been designed and synthesized aiming to selectively inhibit this receptor [9, 10].
One classical strategy used in drug design is based on the knowledge about the structure of the receptor-binding pocket, preferably in complex with the natural ligand. However, this strategy, the so-called “rational structure-based design”, could not be applied in the field of integrin ligands since the first structures of integrin’s extracellular head groups were not described until 2001 for αvβ3 [11] (one year later, in 2002 the structure of this integrin in complex with Cilengitide was also reported [12]) and 2004 for αIIbβ3 [13]. Therefore, initial efforts in this field focused on a “ligand-oriented design”, which concentrated on optimizing RGD peptides by means of different chemical approaches in order to establish structure-activity relationships and identify suitable ligands.
We focused our interest in finding ligands for αvβ3 and based our approach on three chemical strategies pioneered in our group: 1) Reduction of the conformational space by cyclization; 2) Spatial screening of cyclic peptides; and 3)N-Methyl scan.
The combination of these strategies lead to the discovery of the cyclic peptidec(RGDf(NMe)V) in 1995. This peptide showed subnanomolar antagonistic activity for the αvβ3 receptor, nanomolar affinities for the closely related integrins αvβ5 and α5β1, and high selectivity towards the platelet receptor αIIbβ3. The peptide was patented together with Merck in 1997 (patent application submitted in 15.9.1995, opened in 20.3.1997) [14] and first presented with Merck’s agreement at the European Peptide Symposium in Edinburgh (September 1996) [15]. The synthesis and activity of this molecule was finally published in 1999 [16]. This peptide is now developed by Merck-Serono, (Darmstadt, Germany) under the name “Cilengitide” and has recently entered Phase III clinical trials for treating glioblastoma [17]. …..
The discovery 30 years ago of the RGD motif in Fn was a major breakthrough in science. This tripeptide sequence was also identified in other ECM proteins and was soon described as the most prominent recognition motif involved in cell adhesion. Extensive research in this direction allowed the description of a number of bidirectional proteins, the integrins, which were able to recognize and bind to the RGD sequence. Integrins are key players in the biological function of most cells and therefore the inhibition of RGD-mediated integrin-ECM interactions became an attractive target for the scientific community.
However, the lack of selectivity of linear RGD peptides represented a major pitfall which precluded any clinical application of RGD-based inhibitors. The control of the molecule’s conformation by cyclization and further spatial screening overcame these limitations, showing that it is possible to obtain privileged bioactive structures, which enhance the biological activity of linear peptides and significantly improve their receptor selectivity. Steric control imposed in RGD peptides together with their biological evaluation and extensive structural studies yielded the cyclic peptide c(RGDfV), the first small selective anti-angiogenic molecule described. N-Methylation of this cyclic peptide yielded the much potentc(RGDf(NMe)V), nowadays known as Cilengitide.
The fact that brain tumors, which are highly angiogenic, are more susceptible to the treatment with integrin antagonists, and the positive synergy observed for Cilengitide in combination with radio-chemotherapy in preclinical studies, encouraged subsequent clinical trials. Cilengitide is currently in phase III for GBM patients and in phase II for other types of cancers, with to date a promising therapeutic outcome. In addition, the absence of significant toxicity and excellent tolerance of this drug allows its combination with classical therapies such as RT or cytotoxic agents. The controlled phase III study CENTRIC was launched in 2008, with primary outcome measures due on September 2012. The results of this and other clinical studies are expected with great hope and interest.
Integrins are heterodimeric, transmembrane receptors that function as mechanosensors, adhesion molecules and signal transduction platforms in a multitude of biological processes. As such, integrins are central to the etiology and pathology of many disease states. Therefore, pharmacological inhibition of integrins is of great interest for the treatment and prevention of disease. In the last two decades several integrin-targeted drugs have made their way into clinical use, many others are in clinical trials and still more are showing promise as they advance through preclinical development. Herein, this review examines and evaluates the various drugs and compounds targeting integrins and the disease states in which they are implicated.
Integrins are heterodimeric cell surface receptors found in nearly all metazoan cell types, composed of non-covalently linked α and β subunits. In mammals, eighteen α-subunits and eight β-subunits have been identified to date 1. From this pool, 24 distinct heterodimer combinations have been observed in vivo that confer cell-to-cell and cell-to-ligand specificity relevant to the host cell and the environment in which it functions 2. Integrin-mediated interactions with the extracellular matrix (ECM) are required for the attachment, cytoskeletal organization, mechanosensing, migration, proliferation, differentiation and survival of cells in the context of a multitude of biological processes including fertilization, implantation and embryonic development, immune response, bone resorption and platelet aggregation. Integrins also function in pathological processes such as inflammation, wound healing, angiogenesis, and tumor metastasis. In addition, integrin binding has been identified as a means of viral entry into cells 3. ….
Combination of cilengitide and radiation therapy and temozolomide. The addition of cilengitide to radiotherapy and temozolomide based treatment regimens has shown promising preliminary results in ongoing Phase II trials in both newly diagnosed and progressive glioblastoma multiforme 139–140. In addition to the Phase II objectives sought, these trials are significant in that they represent progress that has made in determining tumor drug uptake and in identifying a subset of patients that may benefit from treatment. In a Phase II trial enrolling 52 patients with newly diagnosed glioblastoma multiforme receiving 500 mg cilengitide twice weekly during radiotherapy and in combination with temozolomide for 6 monthly cycles following radiotherapy, 69% achieved 6 months progression free survival compared to 54 % of patients receiving radiotherapy followed by temozolomide alone. The one-year overall survival was 67 and 62 % of patients for the cilengitide combination group and the radiotherapy and temozolomide group, respectively. Non-hematological grade 3-4 toxcities were limited, and included symptoms of fatigue, asthenia, anorexia, elevated liver function tests, deep vein thrombosis and pulmonary embolism in across a total of 5.7% of the patients. Grade 3-4 hematological malignancies were more common and included lymphopenia (53.8%), thrombocytopenia (13.4%) and neutropenia (9.6%). This trial is significant in the fact that is has provided the first evidence correlating a molecular biomarker with response to treatment. Decreased methylguanine methyltransferase (MGMT) expression was associated with favorable outcome. Patients harboring increased MGMT promoter methylation appeared to benefit more from combined treatment with cilengitide than did patients lacking promoter methylation. The significance of the MGMT promoter methylation in predicting response is likely due to inclusion of temozolomide in the treatment combination.
A similar Phase II study evaluating safety and differences in overall survival among newly diagnosed glioblastoma multiforme patients receiving radiation therapy combined with temozolomide and varying doses of cilengitide is nearing completion. Preliminary reports specify that initial safety run-in studies in 18 patients receiving doses 500, 1000 and 2000 mg cilengitide found no dose limiting toxicities. Subsequently 94 patients were randomized to receive standard therapy plus 500 or 2000 mg cilengitide. Median survival time in both cohorts was 18.9 months. At 12 months the overall survival was 79.5 % (89/112 patients).
In the last two decades great progress has been made in the discovery and development of integrin targeted therapeutics. Years of intense research into integrin function has provided an understanding of the potential applications for the treatment of disease. Advances in structural characterization of integrin-ligand interactions has proved beneficial in the design and development of potent, selective inhibitors for a number of integrins involved in platelet aggregation, inflammatory responses, angiongenesis, neovascularization and tumor growth.
The αIIbβ3 integrin antagonists were the first inhibitors to make their way into clinical use and have proven to be effective and safe drugs, contributing to the reduction of mortality and morbidity associated with acute coronary syndromes. Interestingly, the prolonged administration of small molecules targeting this integrin for long-term prevention of thrombosis related complications have not been successful, for reasons that are not yet fully understood. This suggests that modulating the intensity, duration and temporal aspects of integrin function may be more effective than simply shutting off integrin signaling in some instances. Further research into the dynamics of platelet activation and thrombosis formation may elucidate the mechanisms by which integrin activation is modulated.
The introduction of α4 targeted therapies held great promise for the treatment of inflammatory diseases. The development of Natalizumab greatly improved the quality of life for multiple sclerosis patients and those suffering with Crohn’s Disease compared to previous treatments, but the role in asthma related inflammation could not be validated. Unfortunately for MS and Crohn’s patients, immune surveillance in the central nervous system was also compromised as a direct effect α4β7 antagonism, with potentially lethal effects. Thus Natalizumab and related α4β7 targeting drugs are now limited to patients refractory to standard therapies. The design and development of α4β1 antagonists for the treatment of Crohn’s Disease may offer benefit with decreased risks. The involvement of these integrins in fetal development also raises concerns for widespread clinical use.
Integrin antagonists that target angiogenesis are progressing through clinical trials. Cilengitide has shown promising results for the treatment of glioblastomas and recurrent gliomas, cancers with notoriously low survival and cure rates. The greatest challenge facing the development of anti-angiogenic integrin targeted therapies is the overall lack of biomarkers by which to measure treatment efficacy.
Mapping the ligand-binding pocket of integrin α5β1 using a gain-of-function approach
Integrin α5β1 is a key receptor for the extracellular matrix protein fibronectin. Antagonists of human α5β1 have therapeutic potential as anti-angiogenic agents in cancer and diseases of the eye. However, the structure of the integrin is unsolved and the atomic basis of fibronectin and antagonist binding by α5β1 is poorly understood. Here we demonstrate that zebrafish α5β1 integrins do not interact with human fibronectin or the human α5β1 antagonists JSM6427 and cyclic peptide CRRETAWAC. Zebrafish α5β1 integrins do bind zebrafish fibronectin-1, and mutagenesis of residues on the upper surface and side of the zebrafish α5 subunit β-propeller domain shows that these residues are important for the recognition of RGD and synergy sites in fibronectin. Using a gain-of-function analysis involving swapping regions of the zebrafish α5 subunit with the corresponding regions of human α5 we show that blades 1-4 of the β-propeller are required for human fibronectin recognition, suggesting that fibronectin binding involves a broad interface on the side and upper face of the β-propeller domain. We find that the loop connecting blades 2 and 3 of the β-propeller (D3-A3 loop) contains residues critical for antagonist recognition, with a minor role played by residues in neighbouring loops. A new homology model of human α5β1 supports an important function for D3-A3 loop residues Trp-157 and Ala-158 in the binding of antagonists. These results will aid the development of reagents that block α5β1 functions in vivo.
Structural Basis of Integrin Regulation and Signaling
Integrins are cell adhesion molecules that mediate cell-cell, cell-extracellular matrix, and cellpathogen interactions. They play critical roles for the immune system in leukocyte trafficking and migration, immunological synapse formation, costimulation, and phagocytosis. Integrin adhesiveness can be dynamically regulated through a process termed inside-out signaling. In addition, ligand binding transduces signals from the extracellular domain to the cytoplasm in the classical outside-in direction. Recent structural, biochemical, and biophysical studies have greatly advanced our understanding of the mechanisms of integrin bidirectional signaling across the plasma membrane. Large-scale reorientations of the ectodomain of up to 200 Å couple to conformational change in ligand-binding sites and are linked to changes in α and β subunit transmembrane domain association. In this review, we focus on integrin structure as it relates to affinity modulation, ligand binding, outside-in signaling, and cell surface distribution dynamics.
The immune system relies heavily on integrins for (a) adhesion during leukocyte trafficking from the bloodstream, migration within tissues, immune synapse formation, and phagocytosis; and (b) signaling during costimulation and cell polarization. Integrins are so named because they integrate the extracellular and intracellular environments by binding to ligands outside the cell and cytoskeletal components and signaling molecules inside the cell. Integrins are noncovalently associated heterodimeric cell surface adhesion molecules. In vertebrates, 18 α subunits and 8 β subunits form 24 known αβ pairs (Figure 1). This diversity in subunit composition contributes to diversity in ligand recognition, binding to cytoskeletal components and coupling to downstream signaling pathways. Immune cells express at least 10 members of the integrin family belonging to the β2, β7, and β1 subfamilies (Table 1). The β2 and β7 integrins are exclusively expressed on leukocytes, whereas the β1 integrins are expressed on a wide variety of cells throughout the body. Distribution and ligand-binding properties of the integrins on leukocytes are summarized in Table 1. For reviews, see References 1 and 2. Mutations that block expression of the β2 integrin subfamily lead to leukocyte adhesion deficiency, a disease associated with severe immunodeficiency (3).
As adhesion molecules, integrins are unique in that their adhesiveness can be dynamically regulated through a process termed inside-out signaling or priming. Thus, stimuli received by cell surface receptors for chemokines, cytokines, and foreign antigens initiate intracellular signals that impinge on integrin cytoplasmic domains and alter adhesiveness for extracellular ligands. In addition, ligand binding transduces signals from the extracellular domain to the cytoplasm in the classical outside-in direction (outside-in signaling). These dynamic properties of integrins are central to their proper function in the immune system. Indeed, mutations or small molecules that stabilize either the inactive state or the active adhesive state—and thereby block the adhesive dynamics of leukocyte integrins—inhibit leukocyte migration and normal immune responses.
Novel Discoveries in Molecular Biology and Biomedical Science, Volume 2 (Volume Two: Latest in Genomics Methodologies for Therapeutics: Gene Editing, NGS and BioInformatics, Simulations and the Genome Ontology), Part 1: Next Generation Sequencing (NGS)
Novel Discoveries in Molecular Biology and Biomedical Science
Curator: Larry H. Bernstein, MD, FCAP
UPDATED on 6/1/2016
The following is a collection of current articles on noncoding DNA, synthetic genome engineering, protein regulation of apoptosis, drug design, and geometrics.
No longer ‘junk DNA’ — shedding light on the ‘dark matter’ of the genome
A new tool called “LIGR-Seq” enables scientists to explore in depth what non-coding RNAs actually do in human cells May 23, 2016
he LIGR-seq method for global-scale mapping of RNA-RNA interactions in vivo to reveal unexpected functions for uncharacterized RNAs that act via base-pairing interactions (credit: University of Toronto)
What used to be dismissed by many as “junk DNA” has now become vitally important, as accelerating genomic data points to the importance of non-coding RNAs (ncRNAs) — a genome’s messages that do not specifically code for proteins — in development and disease.
But our progress in understanding these molecules has been slow because of the lack of technologies that allow for systematic mapping of their functions.
Now, professor Benjamin Blencowe’s team at the University of Toronto’s Donnelly Centre has developed a method called “LIGR-seq” that enables scientists to explore in depth what ncRNAs do in human cells.
The study, described in Molecular Cell, was published on May 19, along with two other papers, in Molecular Cell and Cell, respectively, from Yue Wan’s group at the Genome Institute of Singapore and Howard Chang’s group at Stanford University in California, who developed similar methods to study RNAs in different organisms.
Of the 3 billion letters in the human genome, only two per cent make up the protein-coding genes. The genes are copied, or transcribed, into messenger RNA (mRNA) molecules, which provide templates for building proteins that do most of the work in the cell. Much of the remaining 98 per cent of the genome was initially considered by some as lacking in functional importance. However, large swaths of the non-coding genome — between half and three quarters of it — are also copied into RNA.
So then what might the resulting ncRNAs do? That depends on whom you ask. Some researchers believe that most ncRNAs have no function, that they are just a by-product of the genome’s powerful transcription machinery that makes mRNA. However, it is emerging that many ncRNAs do have important roles in gene regulation — some ncRNAs act as carriages for shuttling the mRNAs around the cell, or provide a scaffold for other proteins and RNAs to attach to and do their jobs.
But the majority of available data has trickled in piecemeal or through serendipitous discovery. And with emerging evidence that ncRNAs could drive disease progression, such as cancer metastasis, there was a great need for a technology that would allow a systematic functional analysis of ncRNAs.
“Up until now, with existing methods, you had to know what you are looking for because they all require you to have some information about the RNA of interest. The power of our method is that you don’t need to preselect your candidates; you can see what’s occurring globally in cells, and use that information to look at interesting things we have not seen before and how they are affecting biology,” says Eesha Sharma, a PhD candidate in Blencowe’s group who, along with postdoctoral fellow Tim Sterne-Weiler, co-developed the method.
The human RNA-RNA interactome, showing interactions detected by LIGR-seq (credit: University of Toronto)
The new ‘‘LIGation of interacting RNA and high-throughput sequencing’’ (LIGR-seq) tool captures interactions between different RNA molecules. When two RNA molecules have matching sequences — strings of letters copied from the DNA blueprint — they will stick together like Velcro. With LIGR-seq, the paired RNA structures are removed from cells and analyzed by state-of-the-art sequencing methods to precisely identify the RNAs that are stuck together.
“Most researchers in the life sciences agree that there’s an urgent need to understand what ncRNAs do. This technology will open the door to developing a new understanding of ncRNA function,” says Blencowe, who is also a professor in the Department of Molecular Genetics.
Not having to rely on pre-existing knowledge will boost the discovery of RNA pairs that have never been seen before. Scientists can also, for the first time, look at RNA interactions as they occur in living cells, in all their complexity, unlike in the juices of mashed up cells that they had to rely on before. This is a bit like moving on to explore marine biology from collecting shells on the beach to scuba-diving among the coral reefs, where the scope for discovery is so much bigger.
Actually, ncRNAs come in multiple flavors: there’s rRNA, tRNA, snRNA, snoRNA, piRNA, miRNA, and lncRNA, to name a few, where prefixes reflect the RNA’s place in the cell or some aspect of its function. But the truth is that no one really knows the extent to which these ncRNAs control what goes on in the cell, or how they do this.
Discoveries
Nonetheless, the new technology developed by Blencowe’s group has been able to pick up new interactions involving all classes of RNAs and has already revealed some unexpected findings.
The team discovered new roles for small nucleolar RNAs (snoRNAs), which normally guide chemical modifications of other ncRNAs. It turns out that some snoRNAs can also regulate stability of a set of protein-coding mRNAs. In this way, snoRNAs can also directly influence which proteins are made, as well as their abundance, adding a new level of control in cell biology.
And this is only the tip of the iceberg; the researchers plan to further develop and apply their technology to investigate the ncRNAs in different settings.
“We would like to understand how ncRNAs function during development. We are particularly interested in their role in the formation of neurons. But we will also use our method to discover and map changes in RNA-RNA interactions in the context of human diseases,” says Blencowe.
Abstract of Global Mapping of Human RNA-RNA Interactions
The majority of the human genome is transcribed into non-coding (nc)RNAs that lack known biological functions or else are only partially characterized. Numerous characterized ncRNAs function via base pairing with target RNA sequences to direct their biological activities, which include critical roles in RNA processing, modification, turnover, and translation. To define roles for ncRNAs, we have developed a method enabling the global-scale mapping of RNA-RNA duplexes crosslinked in vivo, “LIGation of interacting RNA followed by high-throughput sequencing” (LIGR-seq). Applying this method in human cells reveals a remarkable landscape of RNA-RNA interactions involving all major classes of ncRNA and mRNA. LIGR-seq data reveal unexpected interactions between small nucleolar (sno)RNAs and mRNAs, including those involving the orphan C/D box snoRNA, SNORD83B, that control steady-state levels of its target mRNAs. LIGR-seq thus represents a powerful approach for illuminating the functions of the myriad of uncharacterized RNAs that act via base-pairing interactions.
Understanding the unknown functions of these genes may lead to the creation of new diagnostic tests for clinical laboratories and anatomic pathology groups
Once again, J. Craig Venter, PhD, is charting new ground in gene sequencing andgenomic science. This time his research team has built upon the first synthetic cell they created in 2010 to build a more sophisticated synthetic cell. Their findings from this work may give pathologists and medical laboratory scientists new tools to diagnose disease.
Recently the research team at the J. Craig Venter Institute (JCVI) and Synthetic Genomics, Inc. (SGI) published their latest findings. Among the things they learned is that science still does not understand the functions of about a third of the genes required for their synthetic cells to function.
JCVI-syn3.0 Could Radically Alter Understanding of Human Genome
Based in La Jolla, Calif., and Rockville, Md., JCVI is a not-for-profit research institute aiming to advance genomics. Building upon its first synthetic cell—Mycoplasma mycoides (M. mycoides) JCVI-syn1.0, which JCVI constructed in 2010—the same team of scientists created the first minimal synthetic bacterial cell, which they calledJCVI-syn3.0. This new artificial cell contains 531,560 base pairs and just 473 genes, which means it is the smallest genome of any organism that can be grown in laboratory media, according to a JCVI-SGI statement.
For pathologists and medical laboratory leaders, the creation of a synthetic life form is a milestone toward better understanding genome sequencing and how this new knowledge may help advance both diagnostics and therapeutics.
“What we’ve done is important because it is a step toward completely understanding how a living cell works,” Clyde Hutchison III, PhD, told New Scientist. “If we can really understand how the cell works, then we will be able to design cells efficiently for the production of pharmaceutical and other useful products.” Hutchison is Professor Emeritus of Microbiology and Immunology at the University of North Carolina at Chapel Hill, Distinguished Professor at the J. Craig Venter Institute, a member of the National Academy of Sciences, and a fellow of the American Academy of Arts and Sciences.
Clyde Hutchison, III, PhD (above), Professor Emeritus of Microbiology and Immunology at the University of North Carolina at Chapel Hill and Distinguished Professor at the J. Craig Venter Institute, stated that his team’s “goal is to have a cell for which the precise biological function of every gene is known.” (Photo credit: JCVI.)
Understanding a Gene’s True Purpose
According to the JCVI researchers, 149 genes have no known purpose. They are, however, necessary for life and health.
“We know about two-thirds of the essential biology, and we’re missing a third,” stated J. Craig Venter, PhD, Founder and CEO of JCVI, in a story published by MedPage Today.
This knowledge is based upon decades of research. JCVI seeks to create a minimal cell operating system to understand biology, while also providing what the JCVI statement called a “chassis for use in industrial applications.”
What Do these Genes Do Anyway?
The JCVI team found that among most genes’ biological functions:
“JCVI-syn3.0 is a working approximation of a minimal cellular genome—a compromise between a small genome size and a workable growth rate for an experimental organism. It retains almost all the genes that are involved in the synthesis and processing of macromolecules. Unexpectedly, it also contains 149 genes with unknown biological functions, suggesting the presence of undiscovered functions that are essential for life,” the researchers told the journal Science.
More research is needed, the scientists say, into the 149 genes that appear to lack specific biologic functions.
Unlocking Mystery of the 149 Genes Could Lead to Advances in Genomic Science
“Finding so many genes without a known function is unsettling, but it’s exciting because it’s left us with much still to learn. It’s like the ‘dark matter’ of biology,” said Alistair Elfick, PhD, Chair of Synthetic Biological Engineering, University of Edinburgh, UK, in the New Scientist article.
Studies such as JCVI’s research is key to broadening understanding and framing appropriate questions about scientific, ethical, and economic implications of synthetic biology.
The creation of a synthetic cell will have a profound and positive impact on understanding of biology and how life works, JCVI said.
Such research may inspire new whole genome synthesis tools and semi-automated processes that could dramatically affect clinical laboratory procedures. It also could lead to new techniques and tools for advanced vaccine and pharmaceuticals, JCVI pointed out.
No single technique has set the molecular biology field ablaze with excitement and potential like the CRISPR-Cas9 genome editing system has following its introduction only a few short years ago. The following articles represent the flexibility of this technique to potentially treat a host of genetic disorders and possibly even prevent the onset of disease.
Scientists recently convened at the CRISPR Precision Gene Editing Congress, held in Boston, to discuss the new technology. As with any new technique, scientists have discovered that CRISPR comes with its own set of challenges, and the Congress focused its discussion around improving specificity, efficiency, and delivery.
With a staggering number of papers published in the past several years involving the characterization and use of the CRISPR/Cas9 gene editing system, it is surprising that researchers are still finding new features of the versatile molecular scissor enzyme.
If a Cas9 nuclease variant could be engineered that was less grabby, it might loosen its grip on DNA sequences throughout the genome—except those sequences representing on-target sites. That’s the assumption that guided a new investigation by researchers at Massachusetts General Hospital.
The gene-editing technology known as CRISPR-Cas9 is starting to raise expectations in the therapeutic realm. In fact, CRISPR-Cas9 and other CRISPR systems are moving so close to therapeutic uses that the technology’s ethical implications are starting to attract notice.
Published: Tuesday, May 24, 2016 A comparison of synthetic gene-activating Cas9 proteins can help guide research and development of therapeutic approaches.
The CRISPR-Cas9 system has come to be known as the quintessential tool that allows researchers to edit the DNA sequences of many organisms and cell types. However, scientists are also increasingly recognizing that it can be used to activate the expression of genes. To that end, they have built a number of synthetic gene activating Cas9 proteins to study gene functions or to compensate for insufficient gene expression in potential therapeutic approaches.
“The possibility to selectively activate genes using various engineered variants of the CRISPR-Cas9 system left many researchers questioning which of the available synthetic activating Cas9 proteins to use for their purposes. The main challenge was that all had been uniquely designed and tested in different settings; there was no side-by-side comparison of their relative potentials,” said George Church, Ph.D., who is Core Faculty Member at the Wyss Institute for Biologically Inspired Engineering at Harvard University, leader of its Synthetic Biology Platform, and Professor of Genetics at Harvard Medical School. “We wanted to provide that side-by-side comparison to the biomedical research community.”
In a study published on 23 May in Nature Methods, the Wyss Institute team reports how it rigorously compared and ranked the most commonly used artificial Cas9 activators in different cell types from organisms including humans, mice and flies. The findings provide a valuable guide to researchers, allowing them to streamline their endeavors.
The team also included Wyss Core Faculty Member James Collins, Ph.D., who also is the Termeer Professor of Medical Engineering & Science and Professor of Biological Engineering at the Massachusetts Institute of Technology (MIT)’s Department of Biological Engineering and Norbert Perrimon, Ph.D., a Professor of Genetics at Harvard Medical School.
Gene activating Cas9 proteins are fused to variable domains borrowed from proteins with well-known gene activation potentials and engineered so that the DNA editing ability is destroyed. In some cases, the second component of the CRISPR-Cas9 system, the guide RNA that targets the complex to specific DNA sequences, also has been engineered to bind gene-activating factors.
“We first surveyed seven advanced Cas9 activators, comparing them to each other and the original Cas9 activator that served to provide proof-of-concept for the gene activation potential of CRISPR-Cas9. Three of them, provided much higher gene activation than the other candidates while maintaining high specificities toward their target genes,” said Marcelle Tuttle, Research Fellow at the Wyss and a co-lead author of the study.
The team went on to show that the three top candidates were comparable in driving the highest level of gene expression in cells from humans, mice and fruit flies, irrespective of their tissue and developmental origins. The researchers also pinpointed ways to further maximize gene activation employing the three leading candidates.
“In some cases, maximum possible activation of a target gene is necessary to achieve a cellular or therapeutic effect. We managed to cooperatively enhance expression of specific genes when we targeted them with three copies of a top performing activator using three different guide RNAs,” said Alejandro Chavez, Ph.D., a Postdoctoral Fellow and the study’s co-first author.
“The ease of use of CRISPR-Cas9 offers enormous potential for development of genome therapeutics. This study provides valuable new design criteria that will help enable synthetic biologists and bioengineers to develop more effective targeted genome engineering technologies in the future,” said Wyss Institute Founding Director Donald Ingber, M.D., Ph.D., who is the Judah Folkman Professor of Vascular Biology at Harvard Medical School and the Vascular Biology Program at Boston Children’s Hospital, and also Professor of Bioengineering at the Harvard John A. Paulson School of Engineering and Applied Sciences.
Engineering T Cells to Functionally Cure HIV-1 Infection
Despite the ability of antiretroviral therapy to minimize human immunodeficiency virus type 1 (HIV-1) replication and increase the duration and quality of patients’ lives, the health consequences and financial burden associated with the lifelong treatment regimen render a permanent cure highly attractive. Although T cells play an important role in controlling virus replication, they are themselves targets of HIV-mediated destruction. Direct genetic manipulation of T cells for adoptive cellular therapies could facilitate a functional cure by generating HIV-1–resistant cells, redirecting HIV-1–specific immune responses, or a combination of the two strategies. In contrast to a vaccine approach, which relies on the production and priming of HIV-1–specific lymphocytes within a patient’s own body, adoptive T-cell therapy provides an opportunity to customize the therapeutic T cells prior to administration. However, at present, it is unclear how to best engineer T cells so that sustained control over HIV-1 replication can be achieved in the absence of antiretrovirals. This review focuses on T-cell gene-engineering and gene-editing strategies that have been performed in efforts to inhibit HIV-1 replication and highlights the requirements for a successful gene therapy–mediated functional cure.
Automated top-down design technique simplifies creation of DNA origami nanostructures
Nanoparticles for drug delivery and cell targeting, nanoscale robots, custom-tailored optical devices, and DNA as a storage medium are among the possible applications
May 27, 2016
The boldfaced line, known as a spanning tree, follows the desired geometric shape of the target DNA origami design method, touching each vertex just once. A spanning tree algorithm is used to map out the proper routing path for the DNA strand. (credit: Public Domain)
MIT, Baylor College of Medicine, and Arizona State University Biodesign Institute researchers have developed a radical new top-down DNA origami* design method based on a computer algorithm that allows for creating designs for DNA nanostructures by simply inputting a target shape.
DNA origami (using DNA to design and build geometric structures) has already proven wildly successful in creating myriad forms in 2- and 3- dimensions, which conveniently self-assemble when the designed DNA sequences are mixed together. The tricky part is preparing the proper DNA sequence and routing design for scaffolding and staple strands to achieve the desired target structure. Typically, this is painstaking work that must be carried out manually.
The new algorithm, which is reported together with a novel synthesis approach in the journal Science, promises to eliminate all that and expands the range of possible applications of DNA origami in biomolecular science and nanotechnology. Think nanoparticles for drug delivery and cell targeting, nanoscale robots in medicine and industry, custom-tailored optical devices, and most interesting: DNA as a storage medium, offering retention times in the millions of years.**
Shape-shifting, top-down software
Unlike traditional DNA origami, in which the structure is built up manually by hand, the team’s radical top-down autonomous design method begins with an outline of the desired form and works backward in stages to define the required DNA sequence that will properly fold to form the finished product.
“The Science paper turns the problem around from one in which an expert designs the DNA needed to synthesize the object, to one in which the object itself is the starting point, with the DNA sequences that are needed automatically defined by the algorithm,” said Mark Bathe, an associate professor of biological engineering at MIT, who led the research. “Our hope is that this automation significantly broadens participation of others in the use of this powerful molecular design paradigm.”
The algorithm, which is known as DAEDALUS (DNA Origami Sequence Design Algorithm for User-defined Structures) after the Greek craftsman and artist who designed labyrinths that resemble origami’s complex scaffold structures, can build any type of 3-D shape, provided it has a closed surface. This can include shapes with one or more holes, such as a torus.
A simplified version of the top-down procedure used to design scaffolded DNA origami nanostructures. It starts with a polygon corresponding to the target shape. Software translates a wireframe version of this structure into a plan for routing DNA scaffold and staple strands. That enables a 3D DNA-based atomic-level structural model that is then validated using 3D cryo-EM reconstruction. (credit: adapted from Biodesign Institute images)
With the new technique, the target geometric structure is first described in terms of a wire mesh made up of polyhedra, with a network of nodes and edges. A DNA scaffold using strands of custom length and sequence is generated, using a “spanning tree” algorithm — basically a map that will automatically guide the routing of the DNA scaffold strand through the entire origami structure, touching each vertex in the geometric form once. Complementary staple strands are then assigned and the final DNA structural model or nanoparticle self-assembles, and is then validated using 3D cryo-EM reconstruction.
The software allows for fabricating a variety of geometric DNA objects, including 35 polyhedral forms (Platonic, Archimedean, Johnson and Catalan solids), six asymmetric structures, and four polyhedra with nonspherical topology, using inverse design principles — no manual base-pair designs needed.
To test the method, simpler forms known as Platonic solids were first fabricated, followed by increasingly complex structures. These included objects with nonspherical topologies and unusual internal details, which had never been experimentally realized before. Further experiments confirmed that the DNA structures produced were potentially suitable for biological applications since they displayed long-term stability in serum and low-salt conditions.
Biological research uses
The research also paves the way for designing nanoscale systems mimicking the properties of viruses, photosynthetic organisms, and other sophisticated products of natural evolution. One such application is a scaffold for viral peptides and proteins for use as vaccines. The surface of the nanoparticles could be designed with any combination of peptides and proteins, located at any desired location on the structure, in order to mimic the way in which a virus appears to the body’s immune system.
The researchers demonstrated that the DNA nanoparticles are stable for more than six hours in serum, and are now attempting to increase their stability further.
The nanoparticles could also be used to encapsulate the CRISPR-Cas9 gene editing tool. The CRISPR-Cas9 tool has enormous potential in therapeutics, thanks to its ability to edit targeted genes. However, there is a significant need to develop techniques to package the tool and deliver it to specific cells within the body, Bathe says.
This is currently done using viruses, but these are limited in the size of package they can carry, restricting their use. The DNA nanoparticles, in contrast, are capable of carrying much larger gene packages and can easily be equipped with molecules that help target the right cells or tissue.
The most exciting aspect of the work, however, is that it should significantly broaden participation in the application of this technology, Bathe says, much like 3-D printing has done for complex 3-D geometric models at the macroscopic scale.
* DNA origami brings the ancient Japanese method of paper folding down to the molecular scale. The basics are simple: Take a length of single-stranded DNA and guide it into a desired shape, fastening the structure together using shorter “staple strands,” which bind in strategic places along the longer length of DNA. The method relies on the fact that DNA’s four nucleotide letters—A, T, C, & G stick together in a consistent manner — As always pairing with Ts and Cs with Gs.
The DNA molecule in its characteristic double stranded form is fairly stiff, compared with single-stranded DNA, which is flexible. For this reason, single stranded DNA makes for an ideal lace-like scaffold material. Further, its pairing properties are predictable and consistent (unlike RNA).
** A single gram of DNA can store about 700 terabytes of information — an amount equivalent to 14,000 50-gigabyte Blu-ray disks — and could potentially be operated with a fraction of the energy required for other information storage options.
Essential role of miRNAs in orchestrating the biology of the tumor microenvironment
MicroRNAs (miRNAs) are emerging as central players in shaping the biology of the Tumor Microenvironment (TME). They do so both by modulating their expression levels within the different cells of the TME and by being shuttled among different cell populations within exosomes and other extracellular vesicles. This review focuses on the state-of-the-art knowledge of the role of miRNAs in the complexity of the TME and highlights limitations and challenges in the field. A better understanding of the mechanisms of action of these fascinating micro molecules will lead to the development of new therapeutic weapons and most importantly, to an improvement in the clinical outcome of cancer patients. Keywords: Exosomes, microRNAs, Tumor microenvironment, Cancer
While cancer treatment and survival have improved worldwide, the need for further understanding of the underlying tumor biology remains. In recent years, there has been a significant shift in scientific focus towards the role of the tumor microenvironment (TME) on the development, growth, and metastatic spread of malignancies. The TME is defined as the surrounding cellular environment enmeshed around the tumor cells including endothelial cells, lymphocytes, macrophages, NK cells, other cells of the immune system, fibroblasts, mesenchymal stem cells (MSCs), and the extracellular matrix (ECM). Each of these components interacts with and influences the tumor cells, continually shifting the balance between pro- and anti-tumor phenotype. One of the predominant methods of communication between these cells is through extracellular vesicles and their microRNA (miRNA) cargo. Extracellular vesicles (EVs) are between 30 nm to a few microns in diameter, are surrounded by a phospholipid bilayer membrane, and are released from a variety of cell types into the local environment. There are three well characterized groups of EVs: 1) exosomes, typically 30–100 nm, 2) microvesicles (or ectosomes), typically 100–1000 nm, and 3) large oncosomes, typically 1–10 μm. Each of these categories has a distinctly unique biogenesis and purpose in cellcell communication despite the fact that current laboratory methods do not always allow precise differentiation. EVs are found to be enriched with membrane-bound proteins, lipid raft-associated and cytosolic proteins, lipids, DNA, mRNAs, and miRNAs, all of which can be transferred to the recipient cell upon fusion to allow cell-cell communications [1]. Of these, miRNAs have been of particular interest in cancer research, both as modifiers of transcription and translation as well as direct inhibitors or enhancers of key regulatory proteins. These miRNAs are a large family of small non-coding RNAs (19–24 nucleotides) and are known to be aberrantly expressed, both in terms of content as well as number, in both the tumor cells and the cells of the TME. Synthesis of these mature miRNA is a complex process, starting with the transcription of long, capped, and polyadenylated pri-miRNA by RNA polymerase II. These are cropped into a 60–100 nucleotide hairpinstructure pre-miRNA by the microprocessor, a heterodimer of Drosha (a ribonuclease III enzyme) and DGCR8 (DiGeorge syndrome critical region gene 8). The premiRNA is then exported to the cytoplasm by exportin 5, cleaved by Dicer, and separated into single strands by helicases. The now mature miRNA are incorporated into the RNA-induced silencing complex (RISC), a cytoplasmic effector machine of the miRNA pathway. The primary mechanism of action of the mature miRNA-RISC complex is through their binding to the 3’ untranslated region, or less commonly the 5’ untranslated region, of target mRNA, leading to protein downregulation either via translational repression or mRNA degradation. More recently, it has been shown that miRNAs can also upregulate the expression of target genes [2]. MiRNA genes are mostly intergenic and are transcribed by independent promoters [3] but can also be encoded by introns, sharing the same promoter of their host gene [4]. MiRNAs undergo the same regulatory mechanisms of any other protein coding gene (promoter methylation, histone modifications, etc.…) [5, 6]. Interestingly, each miRNA may have contradictory effects both within varying tumor cell lines and within different cells of the TME. In this review, we provide a state-of-the-art description of the key role that miRNAs have in the communication between tumor cells and the TME and their subsequent effects on the malignant phenotype. Finally, this review has made every effort to clarify, whenever possible, whether the reference is to the −3p or the -5p miRNA. Whenever such clarification has not been provided, this indicates that it was not possible to infer such information from the cited bibliography.
Angiogenesis and miRNAs Cellular plasticity, critical in the development of malignancy, includes the many diverse mechanisms elicited by cancer cells to increase their malignant potential and develop increasing treatment resistance. One such mechanism, angiogenesis, is critical to the development of metastatic disease, affecting both the growth of malignant cells locally and their survival at distant sites. In the last ten years, miRNAs, often packaged in tumor cell-derived exosomes, have emerged as important contributors to the complicated regulation and balance of pro- and anti-angiogenic factors.
Most commonly, miRNAs derived from cancer cells have oncogenic activity, promoting angiogenesis and tumor growth and survival. The most-well characterized of the pro-angiogenic miRNAs, the miR-17-92 cluster encoding six miRNAs (miR-17, −18a, −19a, −19b, −20a, and −92a), is found on chromosome 13, and is highly conserved among vertebrates [7]. The complex and multifaceted functions of the miR-17-92 cluster are summarized in Fig. 1. Amplification, both at the genetic and RNA level, of miR-17-92 was initially found in several lymphoma cell lines and has subsequently been observed in multiple mouse tumor models [7].
Central role of the miR-17-92 cluster in the biology of the TME. The miR-17-92 cluster encoding miR-17, −18a, −19b, −20a, and -92a is upregulated in multiple tumor types and interacts with various components of the TME to finely “tune” the TME through a complex combination of pro- and anti-tumoral effects
Most commonly, miRNAs derived from cancer cells have oncogenic activity, promoting angiogenesis and tumor growth and survival. The most-well characterized of the pro-angiogenic miRNAs, the miR-17-92 cluster encoding six miRNAs (miR-17, −18a, −19a, −19b, −20a, and −92a), is found on chromosome 13, and is highly conserved among vertebrates [7]. The complex and multifaceted functions of the miR-17-92 cluster are summarized in Fig. 1. Amplification, both at the genetic and RNA level, of miR-17-92 was initially found in several lymphoma cell lines and has subsequently been observed in multiple mouse tumor models [7]. Up-regulation of this particular locus has further been confirmed in miRnome analysis across multiple different tumor types, including lung, breast, stomach, prostate, colon, and pancreatic cancer [8]. The miR-17-92 cluster is directly activated by Myc and modulates a variety of downstream transcription factors important in cell cycle regulation and apoptosis including activation of E2F family and Cyclin-dependent kinase inhibitor (CDKN1A) and downregulation of BCL2L11/BIM and p21 [7]. In addition to promoting cell cycle progression and inhibiting apoptosis, the miR-17-92 cluster also downregulates thrombospondin-1 (Tsp1) and connective tissue growth factor (CTGF), important antiangiogenic proteins [7]. Similarly, microvesicles from colorectal cancer cells contain miR-1246 and TGF-β which are transferred to endothelial cells to silence promyelocytic leukemia protein (PML) and activate Smad 1/5/8 signaling promoting proliferation and migration [9]. Likewise, lung cancer cell line derived microvesicles contain miR-494, in response to hypoxia, which targets PTEN in the endothelial cells promoting angiogenesis through the Akt/eNOS pathway [10]. Lastly, exosomal miR-135b from multiple myeloma cells suppresses the HIF-1/FIH-1 pathway in endothelial cells, increasing angiogenesis [11]. A summary of the studies showing the functions of exosomal miRNAs in shaping the biology of the TME is provided in Table 1.
Table 1
Actions of exosomal miRNAs exchanged between cells of the TME
The most common target of anti-angiogenic therapy is VEGF, and not unsurprisingly, multiple miRNAs (including miR-9, miR-20b, miR-130, miR-150, and miR-497) promote angiogenesis through the induction of the VEGF pathway. The most studied of these is the up-regulation of miR-9 which has been linked to a poor prognosis in multiple tumor types, including breast cancer, non-small cell lung cancer, and melanoma [12]. The two oncogenes MYC and MYCN activate miR-9 and cause E-cadherin downregulation resulting in the upregulated transcription of VEGF [13]. In addition, miR-9 has been shown to upregulate the JAK-STAT pathway, supporting endothelial cell migration and tumor angiogenesis [13]. Both amplification of miR-20b and miR-130 as well as miR-497 suppression regulate VEGF through hypoxia inducible factor 1α (HIF-1α) supporting increased angiogenesis [14, 15, 16, 17]. …..
The pivotal discovery in 2012 by Mitra et al. laid the ground-work for our current knowledge on the interactions between tumor-derived miRNAs and fibroblasts. In combination, the down-regulation of miR-214 and miR-31 and the up-regulation of miR-155 trigger the reprogramming of quiescent fibroblasts to CAFs [32]. As expected, the reverse regulation of these miRNAs reduced the migration and invasion of co-cultured ovarian cancer cells [32]. While the pathway of miR-155’s involvement in CAF biology is still being elucidated, the pathways of miR-214 and miR-31 have been established. In endometrial cancer, miR-31 was found to target the homeobox gene SATB2, leading to enhanced tumor cell migration and invasion [33]. MiR-214 similarly has an inverse correlation with its chemokine target, C-C motif Ligand 5 (CCL5) [32]. CCL5 secretion has been associated with enhanced motility, invasion, and metastatic potential through NF-κB-mediated MMP9 activation and through generation and differentiation of myeloid-derived suppressor cells (MDSCs) [34, 35, 36]. Furthermore, miR-210 and miR-133b overexpression and miR-149 suppression have been subsequently found to independently trigger the conversion to CAFs, possibly through paracrine stimulation, and to additionally promote EMT in prostate and gastric cancer, respectively [37, 38,39]. MiR-210 additionally enlists monocytes and encourages angiogenesis [37]. …
Another function of CAFs is the destruction of the ECM and its remodeling with a tumor-supportive composition and structure which includes modulation of specific integrins and metalloproteinases as some of the most studied miRNA targets. The 23 matrix metalloproteinases (MMPs) are critical in the ECM degradation, disruption of the growth signal balance, resistance to apoptosis, establishment of a favorable metastatic niche, and promotion of angiogenesis [54]. As expected, miRNAs have been found to regulate the actions of MMPs, together working to promote cancer cell growth, invasiveness, and metastasis. In HCC, MMP2 and 9 expression is up-regulated by miR-21 via PTEN pathway downregulation. Similarly, in cholangiocarcinoma it was observed that reduced levels of miR-138 induced up-regulation of RhoC, leading to increased levels of the same two MMPs [55, 56]. ….
As has been shown throughout this review, miRNAs have an important and varied effect on human carcinogenesis by shaping the biology of the TME towards a more permissive pro-tumoral phenotype. The complex events leading to such an outcome are currently quite universally defined as the “educational” process of cancer cells on the surrounding TME. While the initial focus was on the direction from the cancer cell to the surrounding TME, increasingly interest is centered on the implications of a more dynamic bidirectional exchange of genetic information. MiRNAs represent only part of the cargo of the extracellular vesicles, but an increasing scientific literature points towards their pivotal role in creating the micro-environmental conditions for cancer cell growth and dissemination. The nearby future will have to address several questions still unanswered. First, it is absolutely necessary to clarify which miRNAs and to what extent they are involved in this process. The contradictory results of some studies can be explained by the differences in tumor-types and by different concentrations of miRNAs used for functional studies. Understanding whether different concentrations of the same miRNA elicit different target effects and therefore changes the biology of the TME, will represent a significant consideration in the development of this field. It is certainly very attractive (especially in an attempt to develop new and desperately needed better cancer biomarkers) to think that concentrations of miRNAs within the TME are reflected systemically in the circulating levels of that same miRNA, however this has not yet been irrefutably demonstrated. Moreover, the study of the paracrine interactions among different cell populations of the TME and their reciprocal effects has been limited to two, maximum three cell populations. This is still way too far from describing the complexity of the TME and only the development of new tridimensional models of the TME will be able to cast a more conclusive light on such complexity. Finally, the pharmacokinetics of miRNA-containing vesicles is in its infancy at best, and needs to be further developed if the goal is development of new therapies based on the use of exosomic miRNAs. Therefore, the future of miRNA research, particularly in its role in the TME, holds still a lot of questions that need answering. However, for these exact same reasons, this is an incredibly exciting time for research in this field. We can envision a not too far future in which these concerns will be satisfactorily addressed and our understanding of the role of miRNAs within the TME will allow us to use them as new therapeutic weapons to successfully improve the clinical outcome of cancer patients.
Researchers at the Walter and Eliza Hall Institute in Australia have discovered a new way to trigger cell death that could lead to drugs to treat cancer and autoimmune disease.
Programmed cell death (a.k.a. apoptosis) is a natural process that removes unwanted cells from the body. Failure of apoptosis can allow cancer cells to grow unchecked or immune cells to inappropriately attack the body.
The protein known as Bak is central to apoptosis. In healthy cells, Bak sits in an inert state but when a cell receives a signal to die, Bak transforms into a killer protein that destroys the cell.
Triggering the cancer-apoptosis trigger
Institute researchers Sweta Iyer, PhD, Ruth Kluck, PhD, and colleagues unexpectedly discovered that an antibody they had produced to study Bak actually bound to the Bak protein and triggered its activation. They hope to use this discovery to develop drugs that promote cell death.
The researchers used information about Bak’s three-dimensional structure to find out precisely how the antibody activated Bak. “It is well known that Bak can be activated by a class of proteins called ‘BH3-only proteins’ that bind to a groove on Bak. We were surprised to find that despite our antibody binding to a completely different site on Bak, it could still trigger activation,” Kluck said. “The advantage of our antibody is that it can’t be ‘mopped up’ and neutralized by pro-survival proteins in the cell, potentially reducing the chance of drug resistance occurring.”
Drugs that target this new activation site could be useful in combination with other therapies that promote cell death by mimicking the BH3-only proteins. The researchers are now working with collaborators to develop their antibody into a drug that can access Bak inside cells.
Their findings have just been published in the open-access journal Nature Communications. The research was supported by the National Health and Medical Research Council, the Australian Research Council, the Victorian State Government Operational Infrastructure Support Scheme, and the Victorian Life Science Computation Initiative.
Abstract of Identification of an activation site in Bak and mitochondrial Bax triggered by antibodies
During apoptosis, Bak and Bax are activated by BH3-only proteins binding to the α2–α5 hydrophobic groove; Bax is also activated via a rear pocket. Here we report that antibodies can directly activate Bak and mitochondrial Bax by binding to the α1–α2 loop. A monoclonal antibody (clone 7D10) binds close to α1 in non-activated Bak to induce conformational change, oligomerization, and cytochrome c release. Anti-FLAG antibodies also activate Bak containing a FLAG epitope close to α1. An antibody (clone 3C10) to the Bax α1–α2 loop activates mitochondrial Bax, but blocks translocation of cytosolic Bax. Tethers within Bak show that 7D10 binding directly extricates α1; a structural model of the 7D10 Fab bound to Bak reveals the formation of a cavity under α1. Our identification of the α1–α2 loop as an activation site in Bak paves the way to develop intrabodies or small molecules that directly and selectively regulate these proteins.
“Cure” is a word that’s dominated the rhetoric in the war on cancer for decades. But it’s a word that medical professionals tend to avoid. While the American Cancer Society reports that cancer treatment has improved markedly over the decades and the five-year survival rate is impressively high for many cancers, oncologists still refrain from declaring their cancer-free patients cured. Why?
Patients are declared cancer-free (also called complete remission) when there are no more signs of detectable disease.
However, minuscule clusters of cancer cells below the detection level can remain in a patient’s body after treatment. Moreover, such small clusters of straggler cells may undergo metastasis, where they escape from the initial tumor into the bloodstream and ultimately settle in a distant site, often a vital organ such as the lungs, liver or brain.
When a colony of these metastatic cells reaches a detectable size, the patient is diagnosed with recurrent metastatic cancer. About one in three breast cancer patients diagnosed with early-stage cancer later develop metastatic disease, usually within five years of initial remission.
By the time metastatic cancer becomes evident, it is much more difficult to treat than when it was originally diagnosed.
What if these metastatic cells could be detected earlier, before they established a “foothold” in a vital organ? Better yet, could these metastatic cancer cells be intercepted, preventing them them from lodging in a vital organ in the first place?
The implant is a tiny porous polymer disc (basically a miniature sponge, no larger than a pencil eraser) that can be inserted just under a patient’s skin. Implantation triggers the immune system’s “foreign body response,” and the implant starts to soak up immune cells that travel to it. If the implant can catch mobile immune cells, then why not mobile metastatic cancer cells?
We gave implants to mice specially bred to model metastatic breast cancer. When the mice had palpable tumors but no evidence of metastatic disease, the implant was removed and analyzed.
Cancer cells were indeed present in the implant, while the other organs (potential destinations for metastatic cells) still appeared clean. This means that the implant can be used to spot previously undetectable metastatic cancer before it takes hold in an organ.
For patients with cancer in remission, an implant that can detect tumor cells as they move through the body would be a diagnostic breakthrough. But having to remove it to see if it has captured any cancer cells is not the most convenient or pleasant detection method for human patients.
Detecting cancer cells with noninvasive imaging
There could be a way around this, though: a special imaging method under development at Northwestern University called Inverse Spectroscopic Optical Coherence Tomography (ISOCT). ISOCT detects molecular-level differences in the way cells in the body scatter light. And when we scan our implant with ISOCT, the light scatter pattern looks different when it’s full of normal cells than when cancer cells are present. In fact, the difference is apparent when even as few as 15 out of the hundreds of thousands of cells in the implant are cancer cells.
There’s a catch – ISOCT cannot penetrate deep into tissue. That means it is not a suitable imaging technology for finding metastatic cells buried deep in internal organs. However, when the cancer cell detection implant is located just under the skin, it may be possible to detect cancer cells trapped in it using ISOCT. This could offer an early warning sign that metastatic cells are on the move.
This early warning could prompt doctors to monitor their patients more closely or perform additional tests. Conversely, if no cells are detected in the implant, a patient still in remission could be spared from unneeded tests.
The ISOCT results show that noninvasive imaging of the implant is feasible. But it’s a method still under development, and thus it’s not widely available. To make scanning easier and more accessible, we’re working to adapt more ubiquitous imaging technologies like ultrasound to detect tiny quantities of tumor cells in the implant.
Besides providing a way to detect tiny numbers of cancer cells before they can form new tumors in other parts of the body, our implant offers an even more intriguing possibility: diverting metastatic cells away from vital organs, and sequestering them where they cannot cause any damage.
In our mouse studies, we found that metastatic cells got caught in the implant before they were apparent in vital organs. When metastatic cells eventually made their way into the organs, the mice with implants still had significantly fewer tumor cells in their organs than implant-free controls. Thus, the implant appears to provide a therapeutic benefit, most likely by taking the metastatic cells it catches out of the circulation, preventing them from lodging anywhere vital.
Interestingly, we have not seen cancer cells leave the implant once trapped, or form a secondary tumor in the implant. Ongoing work aims to learn why this is. Whether the cells can stay safely immobilized in the implant or if it would need to be removed periodically will be important questions to answer before the implant could be used in human patients.
What the future may hold
For now, our work aims to make the implant more effective at drawing and detecting cancer cells. Since we tested the implant with metastatic breast cancer cells, we also want to see if it will work on other types of cancer. Additionally, we’re studying the cells the implant traps, and learning how the implant interacts with the body as a whole. This basic research should give us insight into the process of metastasis and how to treat it.
In the future (and it might still be far off), we envision a world where recovering cancer patients can receive a detector implant to stand guard for disease recurrence and prevent it from happening. Perhaps the patient could even scan their implant at home with a smartphone and get treatment early, when the disease burden is low and the available therapies may be more effective. Better yet, perhaps the implant could continually divert all the cancer cells away from vital organs on its own, like Iron Man’s electromagnet that deflects shrapnel from his heart.
This solution is still not a “cure.” But it would transform a formidable disease that one out of three cancer survivors would otherwise ultimately die from into a condition with which they could easily live.
New PSA Test Examines Protein Structures to Detect Prostate Cancers
5/16/2016 by Cleveland Clinic
A promising new test is detecting prostate cancer more precisely than current tests, by identifying molecular changes in the prostate specific antigen (PSA) protein, according to Cleveland Clinic research presented today at the American Urological Association annual meeting.
The study – part of an ongoing multicenter prospective clinical trial – found that the IsoPSATM test can also differentiate between high-risk and low-risk disease, as well as benign conditions.
Although widely used, the current PSA test relies on detection strategies that have poor specificity for cancer – just 25 percent of men who have a prostate biopsy due to an elevated PSA level actually have prostate cancer, according to the National Cancer Institute – and an inability to determine the aggressiveness of the disease.
The IsoPSA test, however, identifies prostate cancer in a new way. Developed by Cleveland Clinic, in collaboration with Cleveland Diagnostics, Inc., IsoPSA identifies the molecular structural changes in protein biomarkers. It is able to detect cancer by identifying these structural changes, as opposed to current tests that simply measure the protein’s concentration in a patient’s blood.
“While the PSA test has undoubtedly been one of the most successful biomarkers in history, its limitations are well known. Even currently available prostate cancer diagnostic tests rely on biomarkers that can be affected by physiological factors unrelated to cancer,” said Eric Klein, M.D., chair of Cleveland Clinic’s Glickman Urological & Kidney Institute. “These study results show that using structural changes in PSA protein to detect cancer is more effective and can help prevent unneeded biopsies in low-risk patients.”
The clinical trial involves six healthcare institutions and 132 patients, to date. It examined the ability of IsoPSA to distinguish patients with and without biopsy-confirmed evidence of cancer. It also evaluated the test’s precision in differentiating patients with high-grade (Gleason = 7) cancer from those with low-grade (Gleason = 6) disease and benign findings after standard ultrasound-guided biopsy of the prostate.
Substituting the IsoPSA structure-based composite index for the standard PSA resulted in improvement in diagnostic accuracy. Compared with serum PSA testing, IsoPSA performed better in both sensitivity and specificity.
“We took an ‘out of the box’ approach that has shown success in detecting prostate cancer but also has the potential to address other clinically important questions such as clinical surveillance of patients after treatment,” said Mark Stovsky, M.D., staff member, Cleveland Clinic Glickman Urological & Kidney Institute’s Department of Urology. Stovsky has a leadership position (Chief Medical Officer) and investment interest in Cleveland Diagnostics, Inc. “In general, the clinical utility of prostate cancer early detection and screening tests is often limited by the fact that biomarker concentrations may be affected by physiological processes unrelated to cancer, such as inflammation, as well as the relative lack of specificity of these biomarkers to the cancer phenotype. In contrast, clinical research data suggests that the IsoPSA assay can interrogate the entire PSA isoform distribution as a single stand-alone diagnostic tool which can reliably identify structural changes in the PSA protein that correlate with the presence or absence and aggressiveness of prostate cancer.”
Point of Care, Highly Accurate Cervical Cancer Screening
Fifty-five million times a year, American women go to their gynecologist for a Pap Smear. After waiting a few weeks for the results, more than 3.5 million of them are called back to the physician for a follow up visualization of the cervix. Beyond the stress related to possibly having cancer, the women are then subjected to a colposcopic exam, and all too often, a painful biopsy. Then more stressful waiting for a final diagnosis from the pathologist.
Cervical cancer develops slowly, allowing for successful treatment, when identified on time. Regions with high screening compliancy have low mortality rates from this cancer. In the US, for instance, where screening rates are close to 90%, only 4,200 women die from cervical cancer, annually, or 2.6 women per 100,000. However, the screening process in the developed world is long, complicated and not optimized.
In developing regions however, cervical cancer is a leading cause of women death. Over 85% of the total deaths from this cancer are in developing countries. Regions suffering from low screening rates include not only Africa, India and China, but many Eastern European countries as well. According to an OECD report from 2014, the cervical cancer screening rates in Romania and Hungary are as low as 14.6% and 36.7% respectively. The mortality rates in these countries are high, 16 in 100,000 women in Romania and 7.7 in 100,000 in Hungary.
The current screening process for cervical cancer detection is long, beginning with a Pap or HPV test. Cytology results take weeks to receive. A positive result requires follow-up testing by colposcopy and often biopsy. In countries where there is little access to medical care, or where screening compliancy is low, the chances of successful detection via this multi-step process are small. Developing regions and non-compliant countries require a point of care diagnostic method, which eliminates the need for return visits.
Additional limitations to cervical cancer screening are the low sensitivity and specificity rates of Pap tests and the high false positive rates of HPV test, leading to unnecessary colposcopies. Both cytology and colposcopy testing are highly dependent on operator proficiency for accurate diagnosis.
Biop has developed a new technology for the optimization of this process, into one, three minute, painless optical scan. The vaginal probe uses advanced optical, imaging and non-imaging technologies to identify and classify epithelium based cancers and pre-cancerous lesions. The probe is inserted into the vaginal canal, and scans the entire cervix. The resulting images and optical signatures created from the light, and captured by the sensors, are analyzed by the proprietary algorithm. The result is two pictures, on the physician’s screen; a high resolution photograph of the patient’s cervix, immediately next to a hot/cold map indicating a precise classification and location of any diseased lesions.
Deep learning applied to drug discovery and repurposing
Deep neural networks for drug discovery (credit: Insilico Medicine, Inc.)
Scientists from Insilico Medicine, Inc. have trained deep neural networks (DNNs) to predict the potential therapeutic uses of 678 drugs, using gene-expression data obtained from high-throughput experiments on human cell lines from Broad Institute’s LINCS databases and NIH MeSH databases.
The supervised deep-learning drug-discovery engine used the properties of small molecules, transcriptional data, and literature to predict efficacy, toxicity, tissue-specificity, and heterogeneity of response.
“We used LINCS data from Broad Institute to determine the effects on cell lines before and after incubation with compounds, co-author and research scientist Polina Mamoshina explained to KurzweilIAI.
“We used gene expression data of total mRNA from cell lines extracted and measured before incubation with compound X and after incubation with compound X to identify the response on a molecular level. The goal is to understand how gene expression (the transcriptome) will change after drug uptake. It is a differential value, so we need a reference (molecular state before incubation) to compare.”
The research is described in a paper in the upcoming issue of the journal Molecular Pharmaceutics.
Helping pharmas accelerate R&D
Alex Zhavoronkov, PhD, Insilico Medicine CEO, who coordinated the study, said the initial goal of their research was to help pharmaceutical companies significantly accelerate their R&D and increase the number of approved drugs. “In the process we came up with more than 800 strong hypotheses in oncology, cardiovascular, metabolic, and CNS spaces and started basic validation,” he said.
The team measured the “differential signaling pathway activation score for a large number of pathways to reduce the dimensionality of the data while retaining biological relevance.” They then used those scores to train the deep neural networks.*
“This study is a proof of concept that DNNs can be used to annotate drugs using transcriptional response signatures, but we took this concept to the next level,” said Alex Aliper, president of research, Insilico Medicine, Inc., lead author of the study.
Via Pharma.AI, a newly formed subsidiary of Insilico Medicine, “we developed a pipeline for in silico drug discovery — which has the potential to substantially accelerate the preclinical stage for almost any therapeutic — and came up with a broad list of predictions, with multiple in silico validation steps that, if validated in vitro and in vivo, can almost double the number of drugs in clinical practice.”
Despite the commercial orientation of the companies, the authors agreed not to file for intellectual property on these methods and to publish the proof of concept.
Deep-learning age biomarkers
According to Mamoshina, earlier this month, Insilico Medicine scientists published the first deep-learned biomarker of human age — aiming to predict the health status of the patient — in a paper titled “Deep biomarkers of human aging: Application of deep neural networks to biomarker development” by Putin et al, in Aging; and an overview of recent advances in deep learning in a paper titled “Applications of Deep Learning in Biomedicine” by Mamoshina et al., also in Molecular Pharmaceutics.
Insilico Medicine is located in the Emerging Technology Centers at Johns Hopkins University in Baltimore, Maryland, in collaboration with Datalytic Solutions and Mind Research Network.
* In this study, scientists used the perturbation samples of 678 drugs across A549, MCF-7 and PC-3 cell lines from the Library of Integrated Network-Based Cellular Signatures (LINCS) project developed by the National Institutes of Health (NIH) and linked those to 12 therapeutic use categories derived from MeSH (Medical Subject Headings) developed and maintained by the National Library of Medicine (NLM) of the NIH.
To train the DNN, scientists utilized both gene level transcriptomic data and transcriptomic data processed using a pathway activation scoring algorithm, for a pooled dataset of samples perturbed with different concentrations of the drug for 6 and 24 hours. Cross-validation experiments showed that DNNs achieve 54.6% accuracy in correctly predicting one out of 12 therapeutic classes for each drug.
One peculiar finding of this experiment was that a large number of drugs misclassified by the DNNs had dual use, suggesting possible application of DNN confusion matrices in drug repurposing. FutureTechnologies Media Group | Video presentation Insilico medicine
Abstract of Deep learning applications for predicting pharmacological properties of drugs and drug repurposing using transcriptomic data
Deep learning is rapidly advancing many areas of science and technology with multiple success stories in image, text, voice and video recognition, robotics and autonomous driving. In this paper we demonstrate how deep neural networks (DNN) trained on large transcriptional response data sets can classify various drugs to therapeutic categories solely based on their transcriptional profiles. We used the perturbation samples of 678 drugs across A549, MCF-7 and PC-3 cell lines from the LINCS project and linked those to 12 therapeutic use categories derived from MeSH. To train the DNN, we utilized both gene level transcriptomic data and transcriptomic data processed using a pathway activation scoring algorithm, for a pooled dataset of samples perturbed with different concentrations of the drug for 6 and 24 hours. When applied to normalized gene expression data for “landmark genes,” DNN showed cross-validation mean F1 scores of 0.397, 0.285 and 0.234 on 3-, 5- and 12-category classification problems, respectively. At the pathway level DNN performed best with cross-validation mean F1 scores of 0.701, 0.596 and 0.546 on the same tasks. In both gene and pathway level classification, DNN convincingly outperformed support vector machine (SVM) model on every multiclass classification problem. For the first time we demonstrate a deep learning neural net trained on transcriptomic data to recognize pharmacological properties of multiple drugs across different biological systems and conditions. We also propose using deep neural net confusion matrices for drug repositioning. This work is a proof of principle for applying deep learning to drug discovery and development.
A novel nanoscale organic transistor-based biosensor that can detect molecules associated with neurodegenerative diseases and some types of cancer has been developed by researchers at the National Nanotechnology Laboratory (LNNano) in Brazil.
The transistor, mounted on a glass slide, contains the reduced form of the peptide glutathione (GSH), which reacts in a specific way when it comes into contact with the enzyme glutathione S-transferase (GST), linked to Parkinson’s, Alzheimer’s and breast cancer, among other diseases.
Sensitive water-gated copper phthalocyanine (CuPc) thin-film transistor (credit: Rafael Furlan de Oliveira et al./Organic Electronics)
“The device can detect such molecules even when they’re present at very low levels in the examined material, thanks to its nanometric sensitivity,” explained Carlos Cesar Bof Bufon, Head of LNNano’s Functional Devices & Systems Lab (DSF).
Bufon said the system can be adapted to detect other substances by replacing the analytes (detection compounds). The team is working on paper-based biosensors to further lower the cost, improve portability, and facilitate fabrication and disposal.
The research is published in the journal Organic Electronics.
Abstract of Water-gated phthalocyanine transistors: Operation and transduction of the peptide–enzyme interaction
The use of aqueous solutions as the gate medium is an attractive strategy to obtain high charge carrier density (1012 cm−2) and low operational voltages (<1 V) in organic transistors. Additionally, it provides a simple and favorable architecture to couple both ionic and electronic domains in a single device, which is crucial for the development of novel technologies in bioelectronics. Here, we demonstrate the operation of transistors containing copper phthalocyanine (CuPc) thin-films gated with water and discuss the charge dynamics at the CuPc/water interface. Without the need for complex multilayer patterning, or the use of surface treatments, water-gated CuPc transistors exhibited low threshold (100 ± 20 mV) and working voltages (<1 V) compared to conventional CuPc transistors, along with similar charge carrier mobilities (1.2 ± 0.2) x 10−3 cm2 V−1 s−1. Several device characteristics such as moderate switching speeds and hysteresis, associated with high capacitances at low frequencies upon bias application (3.4–12 μF cm−2), indicate the occurrence of interfacial ion doping. Finally, water-gated CuPc OTFTs were employed in the transduction of the biospecific interaction between tripeptide reduced glutathione (GSH) and glutathione S-transferase (GST) enzyme, taking advantage of the device sensitivity and multiparametricity.
The study offers understanding of potential therapeutic targets.
Building on data from The Cancer Genome Atlas (TCGA) project, a multi-institutional team of scientists have completed the first large-scale “proteogenomic” study of breast cancer, linking DNA mutations to protein signaling and helping pinpoint the genes that drive cancer. Conducted by members of the National Cancer Institute’s Clinical Proteomic Tumor Analysis Consortium (CPTAC), including Baylor College of Medicine, Broad Institute of MIT and Harvard, Fred Hutchinson Cancer Research Center, New York University Langone Medical Center, and Washington University School of Medicine, the study takes aim at proteins, the workhorses of the cell, and their modifications to better understand cancer.
Appearing in the Advance Online Publication of Nature, the study illustrates the power of integrating genomic and proteomic data to yield a more complete picture of cancer biology than either analysis could do alone. The effort produced a broad overview of the landscape of the proteome (all the proteins found in a cell) and the phosphoproteome (the sites at which proteins are tagged by phosphorylation, a chemical modification that drives communication in the cell) across a set of 77 breast cancer tumors that had been genomically characterized in the TCGA project. Although the TCGA produced an extensive catalog of somatic mutations found in cancer, the effects of many of those mutations on cellular functions or patients’ outcomes are unknown.
In addition, not all mutated genes are true “drivers” of cancer — some are merely “passenger” mutations that have little functional consequence. And some mutations are found within very large DNA regions that are deleted or present in extra copies, so winnowing the list of candidate genes by studying the activity of their protein products can help identify therapeutic targets. “We don’t fully understand how complex cancer genomes translate into the driving biology that causes relapse and mortality,” said Matthew Ellis, director of the Lester and Sue Smith Breast Center at Baylor College of Medicine and a senior author of the paper.
“These findings show that proteogenomic integration could one day prove to be a powerful clinical tool, allowing us to traverse the large knowledge gap between cancer genomics and clinical action.” In this study, the researchers at the Broad Institute analyzed breast tumors using accurate mass, high-resolution mass spectrometry, a technology that extends the coverage of the proteome far beyond the coverage that can be achieved by traditional antibody-based methods. This allowed them to scale their efforts and quantify more than 12,000 proteins and 33,000 phosphosites, an extremely deep level of coverage.
Scripps scientists have designed a drug candidate that decreases growth of breast cancer cells.
In a development that could lead to a new generation of drugs to precisely treat a range of diseases, scientists from the Florida campus of The Scripps Research Institute (TSRI) have for the first time designed a drug candidate that decreases the growth of tumor cells in animal models in one of the hardest to treat cancers—triple negative breast cancer.
“This is the first example of taking a genetic sequence and designing a drug candidate that works effectively in an animal model against triple negative breast cancer,” said TSRI Professor Matthew Disney. “The study represents a clear breakthrough in precision medicine, as this molecule only kills the cancer cells that express the cancer-causing gene—not healthy cells. These studies may transform the way the lead drugs are identified—by using the genetic makeup of a disease.”
The study, published by the journal Proceedings of the National Academy of Sciences, demonstrates that the Disney lab’s compound, known as Targaprimir-96, triggers breast cancer cells to kill themselves via programmed cell death by precisely targeting a specific RNA that ignites the cancer.
Short-Cut to Drug Candidates
While the goal of precision medicine is to identify drugs that selectively affect disease-causing biomolecules, the process has typically involved time-consuming and expensive high-throughput screens to test millions of potential drug candidates to identify those few that affect the target of interest. Disney’s approach eliminates these screens.
The new study uses the lab’s computational approach called Inforna, which focuses on developing designer compounds that bind to RNA folds, particularly microRNAs.
MicroRNAs are short molecules that work within all animal and plant cells, typically functioning as a “dimmer switch” for one or more genes, binding to the transcripts of those genes and preventing protein production. Some microRNAs have been associated with diseases. For example, microRNA-96, which was the target of the new study, promotes cancer by discouraging programmed cell death, which can rid the body of cells that grow out of control.
In the new study, the drug candidate was tested in animal models over a 21-day course of treatment. Results showed decreased production of microRNA-96 and increased programmed cell death, significantly reducing tumor growth. Since targaprimir-96 was highly selective in its targeting, healthy cells were unaffected.
In contrast, Disney noted, a typical cancer therapeutic targets and kills cells indiscriminately, often leading to side effects that can make these drugs difficult for patients to tolerate.
Benjamin Zealley and Aubrey D.N.J. de Grey Commentary on Some Recent Theses Relevant to Combating Aging: June 2015
Cancer Autoantibody Biomarker Discovery and Validation Using Nucleic Acid Programmable Protein Array Jie Wang, PhD, Arizona State University
Currently in the United States, many patients with cancer do not benefit from population-based screening due to challenges associated with the existing cancer screening scheme. Blood-based diagnostic assays have the potential to detect diseases in a non-invasive way. Proteins released from small early tumors may only be present intermittently and are diluted to tiny concentrations in the blood, making them difficult to use as biomarkers. However, they can induce autoantibody (AAb) responses, which can amplify the signal and persist in the blood even if the antigen is gone. Circulating autoantibodies are a promising class of molecules that have the potential to serve as early detection biomarkers for cancers. This PhD thesis aims to screen for autoantibody biomarkers for the early detection of two deadly cancers, basal-like breast cancer and lung adenocarcinoma. First, a method was developed to display proteins in both native and denatured conformations on a protein array. This method adopted a novel protein tag technology, called a HaloTag, to immobilize proteins covalently on the surface of a glass slide. The covalent attachment allowed these proteins to endure harsh treatment without becoming dissociated from the slide surface, which enabled the profiling of antibody responses against both conformational and linear epitopes. Next, a plasma screening protocol was optimized to increase significantly the signal-to-noise ratio of protein array–based AAb detection. Following this, the AAb responses in basal-like breast cancer were explored using nucleic acid programmable protein arrays (NAPPA) containing 10,000 full-length human proteins in 45 cases and 45 controls. After verification in a large sample set (145 basal-like breast cancer cases, 145 controls, 70 non-basal breast cancer) by enzyme-linked immunosorbent assay (ELISA), a 13-AAb classifier was developed to differentiate patients from controls with a sensitivity of 33% at 98% specificity. A similar approach was also applied to the lung cancer study to identify AAbs that distinguished lung cancer patients from computed tomography–positive benign pulmonary nodules (137 lung cancer cases, 127 smoker controls, 170 benign controls). In this study, two panels of AAbs were discovered that showed promising sensitivity and specificity. Six out of eight AAb targets were also found to have elevated mRNA levels in lung adenocarcinoma patients using TCGA data. These projects as a whole provide novel insights into the association between AAbs and cancer, as well as general B cell antigenicity against self-proteins.
Comment: There are two widely supported models for cancer development and progression—the clonal evolution (CE) model and the cancer stem cell (CSC) model. Briefly, the former claims that most or all cells in a tumor contribute to its maintenance; as newer and more aggressive clones develop by random mutation, they become responsible for driving growth. The range of different mutational profiles generated is assumed to be large enough to account for disease recurrence after therapy (due to rare resistant clones) and metastasis (clones arising with the ability to travel to distant sites). The CSC model instead asserts that a small number of mutated stem cells are the origin of the primary cell mass, drive metastasis through the intermittent release of undifferentiated, highly mobile progeny, and account for recurrence due to a generally quiescent metabolic profile conferring potent resistance to chemotherapy. In either case, the immunological visibility of an early tumor may be highly sporadic. Clones arising early in CE differ little in proteomic terms from healthy host cells; those that do trigger a response are unlikely to have acquired robust resistance to immune attack, so are destroyed quickly in favor of their stealthier brethren. Likewise, CSCs share some of the immune privilege of normal stem cells and, due to their inherent ability to produce differentiated progeny with distinct proteomic signatures, are partially protected from attacks on their descendants. Consequently, such well-hidden cells may remain in the body for years to decades. The autoantibody panel developed in this study for basal-like breast cancer exhibits exceptional specificity despite a comparatively small training set. Given its ease of application, this suggests great promise for a more exhaustively trained classifier as a populationlevel screening tool.
Condition-Specific Differential Sub-Network Analysis for Biological Systems Deepali Jhamb, PhD, Indiana University
Biological systems behave differently under different conditions. Advances in sequencing technology over the last decade have led to the generation of enormous amounts of condition-specific data. However, these measurements often fail to identify low-abundance genes and proteins that can be biologically crucial. In this work, a novel textmining system was first developed to extract condition-specific proteins from the biomedical literature. The literaturederived data was then combined with proteomics data to construct condition-specific protein interaction networks. Furthermore, an innovative condition-specific differential analysis approach was designed to identify key differences, in the form of sub-networks, between any two given biological systems. The framework developed here was implemented to understand the differences between limb regenerationcompetent Ambystoma mexicanum and regeneration-deficient Xenopus laevis. This study provides an exhaustive systems-level analysis to compare regeneration competent and deficient sub-networks to show how different molecular entities inter-connect with each other and are rewired during the formation of an accumulation blastema in regenerating axolotl limbs. This study also demonstrates the importance of literature-derived knowledge, specific to limb regeneration, to augment the systems biology analysis. Our findings show that although the proteins might be common between the two given biological conditions, they can have a high dissimilarity based on their biological and topological properties in the sub-network. The knowledge gained from the distinguishing features of limb regeneration in amphibians can be used in future to induce regeneration chemically in mammalian systems. The approach developed in this dissertation is scalable and adaptable to understanding differential sub-networks between any two biological systems. This methodology will not only facilitate the understanding of biological processes and molecular functions that govern a given system, but will also provide novel intuitions about the pathophysiology of diseases/conditions.
Comment: We have long advocated a principle of directly comparing young and old bodies as a means to identify the classes of physical damage that accumulate in the body during aging. This approach circumvents our ignorance of the full etiology of each particular disease manifestation, a phenomenally difficult question given the ethical issues of experimenting on human subjects, the lengthy ‘‘incubation time’’ of aging-related diseases, and the complex interconnections between their risk factors—innate and environmental. Repairing such damage has the potential to prevent pathology before symptoms appear, an approach now becoming increasingly mainstream.11 However, a naı¨ve comparison faces a number of difficulties, even given a sufficiently large sample set to compensate for inter-individual variation. Most importantly, the causal significance of a given species cannot be reliably determined from its simple prevalence.12 The catalytic nature of cell biology means that those entities whose abundance changes the most profoundly in absolute terms are quite unlikely to be the drivers of that change and may even spontaneously revert to baseline levels in the absence of on-going stimulation. Meanwhile, functionality is often heavily influenced independently of abundance by post-translational modifications that may escape direct detection. Sub-network analysis uses computational means to identify groups of genes and/or proteins that vary in a synchronized way with some parameter, indicating functional connectivity. The application of methods such as those developed here to the comparison of a wide range of younger and older conditions will facilitate the identification of processes—not merely individual factors—that are impaired with age, and thus will help greatly in identifying the optimal points for intervention.
Development of a Light Actuated Drug Delivery-on-Demand System Chase Linsley, PhD, University of California, Los Angeles
The need for temporal–spatial control over the release of biologically active molecules has motivated efforts to engineer novel drug delivery-on-demand strategies actuated via light irradiation. Many systems, however, have been limited to in vitro proof-of-concept due to biocompatibility issues with the photo-responsive moieties or the light wavelength, intensity, and duration. To overcome these limitations, the objective of this dissertation was to design a light-actuated drug delivery-on-demand strategy that uses biocompatible chromophores and safe wavelengths of light, thereby advancing the clinical prospects of light-actuated drug delivery-on-demand systems. This was achieved by: (1) Characterizing the photothermal response of biocompatible visible light and near-infrared-responsive chromophores and demonstrating the feasibility and functionality of the light actuated on-demand drug delivery system in vitro; and (2) designing a modular drug delivery-on-demand system that could control the release of biologically active molecules over an extended period of time. Three biocompatible chromophores—Cardiogreen, Methylene Blue, and riboflavin—were identified and demonstrated significant photothermal response upon exposure to near-infrared and visible light, and the amount of temperature change was dependent upon light intensity, wavelength, as well as chromophore concentration. As a proof-of-concept, pulsatile release of a model protein from a thermally responsive delivery vehicle fabricated from poly(N-isopropylacrylamide) was achieved over 4 days by loading the delivery vehicle with Cardiogreen and irradiating with near-infrared light. To extend the useful lifetime of the light-actuated drug delivery-on-demand system, a modular, reservoir-valve system was designed. Using poly(ethylene glycol) as a reservoir for model small molecule drugs combined with a poly(N-isopropylacrylamide) valve spiked with chromophore-loaded liposomes, pulsatile release was achieved over 7 days upon light irradiation. Ultimately, this drug delivery strategy has potential for clinical applications that require explicit control over the presentation of biologically active molecules. Further research into the design and fabrication of novel biocompatible thermally responsive delivery vehicles will aid in the advancement of the light-actuated drug delivery-on-demand strategy described here. Comment: Our combined comments on this thesis and the next one appear after the next abstract.
Light-Inducible Gene Regulation in Mammalian Cells Lauren Toth, PhD, Duke University
The growing complexity of scientific research demands further development of advanced gene regulation systems. For instance, the ultimate goal of tissue engineering is to develop constructs that functionally and morphologically resemble the native tissue they are expected to replace. This requires patterning of gene expression and control of cellular phenotype within the tissue-engineered construct. In the field of synthetic biology, gene circuits are engineered to elucidate mechanisms of gene regulation and predict the behavior of more complex systems. Such systems require robust gene switches that can quickly turn gene expression on or off. Similarly, basic science requires precise genetic control to perturb genetic pathways or understand gene function. Additionally, gene therapy strives to replace or repair genes that are responsible for disease. The safety and efficacy of such therapies require control of when and where the delivered gene is expressed in vivo.
Unfortunately, these fields are limited by the lack of gene regulation systems that enable both robust and flexible cellular control. Most current gene regulation systems do not allow for the manipulation of gene expression that is spatially defined, temporally controlled, reversible, and repeatable. Rather, they provide incomplete control that forces the user to choose to control gene expression in either space or time, and whether the system will be reversible or irreversible. The recent emergence of the field of optogenetics—the ability to control gene expression using light—has made it possible to regulate gene expression with spatial, temporal, and dynamic control. Light-inducible systems provide the tools necessary to overcome the limitations of other gene regulation systems, which can be slow, imprecise, or cumbersome to work with. However, emerging light-inducible systems require further optimization to increase their efficiency, reliability, and ease of use.
Initially, we engineered a light-inducible gene regulation system that combines zinc finger protein technology and the light-inducible interaction between Arabidopsis thaliana plant proteins GIGANTEA (GI) and the light oxygen voltage (LOV) domain of FKF1. Zinc finger proteins (ZFPs) can be engineered to target almost any DNA sequence through tandem assembly of individual zinc finger domains that recognize a specific 3-bp DNA sequence. Fusion of three different ZFPs to GI (GI-ZFP) successfully targeted the fusion protein to the specific DNA target sequence of the ZFP. Due to the interaction between GI and LOV, co-expression of GI-ZFP with a fusion protein consisting of LOV fused to three copies of the VP16 transactivation domain (LOV-VP16) enabled blue-light dependent recruitment of LOV-VP16 to the ZFP target sequence. We showed that placement of three to nine copies of a ZFP target sequence upstream of a luciferase or enhanced green fluorescent protein (eGFP) transgene enabled expression of the transgene in response to blue light. Gene activation was both reversible and tunable on the basis of duration of light exposure, illumination intensity, and the number of ZFP binding sites upstream of the transgene. Gene expression could also be patterned spatially by illuminating the cell culture through photomasks containing various patterns.
Although this system was useful for controlling the expression of a transgene, for many applications it is useful to control the expression of a gene in its natural chromosomal position. Therefore, we capitalized on recent advances in programmed gene activation to engineer an optogenetic tool that could easily be targeted to new, endogenous DNA sequences without re-engineering the light inducible proteins. This approach took advantage of CRISPR/Cas9 technology, which uses a gene-specific guide RNA (gRNA) to facilitate Cas9 targeting and binding to a desired sequence, and the light-inducible heterodimerizers CRY2 and CIB1 from Arabidopsis thaliana to engineer a lightactivated CRISPR/Cas9 effector (LACE) system. We fused the full-length (FL) CRY2 to the transcriptional activator VP64 (CRY2FL-VP64) and the amino-terminal fragment of CIB1 to the amino, carboxyl, or amino and carboxyl terminus of a catalytically inactive Cas9. When CRY2-VP64 and one of the CIBN/dCas9 fusion proteins are expressed with a gRNA, the CIBN/dCas9 fusion protein localizes to the gRNA target. In the presence of blue light, CRY2FL binds to CIBN, which translocates CRY2FL-VP64 to the gene target and activates transcription. Unlike other optogenetic systems, the LACE system can be targeted to new endogenous loci by solely manipulating the specificity of the gRNA without having to re-engineer the light-inducible proteins. We achieved light-dependent activation of the IL1RN, HBG1/2, or ASCL1 genes by delivery of the LACE system and four gene-specific gRNAs per promoter region. For some gene targets, we achieved equivalent activation levels to cells that were transfected with the same gRNAs and the synthetic transcription factor dCas9-VP64. Gene activation was also shown to be reversible and repeatable through modulation of the duration of blue light exposure, and spatial patterning of gene expression was achieved using an eGFP reporter and a photomask.
Finally, we engineered a light-activated genetic ‘‘on’’ switch (LAGOS) that provides permanent gene expression in response to an initial dose of blue light illumination. LAGOS is a lentiviral vector that expresses a transgene only upon Cre recombinase–mediated DNA recombination. We showed that this vector, when used in conjunction with a light-inducible Cre recombinase system, could be used to express MyoD or the synthetic transcription factor VP64- MyoD in response to light in multiple mammalian cell lines, including primary mouse embryonic fibroblasts. We achieved light-mediated up-regulation of downstream myogenic markers myogenin, desmin, troponin T, and myosin heavy chains I and II as well as fusion of C3H10T1/2 cells into myotubes that resembled a skeletal muscle cell phenotype. We also demonstrated LAGOS functionality in vivo by engineering the vector to express human VEGF165 and human ANG1 in response to light. HEK 293T cells stably expressing the LAGOS vector and transiently expressing the light-inducible Cre recombinase proteins were implanted into mouse dorsal window chambers. Mice that were illuminated with blue light had increased micro-vessel density compared to mice that were not illuminated. Analysis of human vascular endothelial growth factor (VEGF) and human ANG1 levels by enzyme-linked immunosorbent assay (ELISA) revealed statistically higher levels of VEGF and ANG1 in illuminated mice compared to non-illuminated mice.
In summary, the objective of this work was to engineer robust light-inducible gene regulation systems that can control genes and cellular fate in a spatial and temporal manner. These studies combine the rapid advances in gene targeting and activation technology with natural light-inducible plant protein interactions. Collectively, this thesis presents several optogenetic systems that are expected to facilitate the development of multicellular cell and tissue constructs for use in tissue engineering, synthetic biology, gene therapy, and basic science both in vitro and in vivo.
Comment: Although it is easy to characterize technological progress as following in the wake of scientific discoveries, the reverse is almost equally true; advances in technique open the door to types of experiment previously intractable or impossible. Such is currently the case for the field of optically controlled biotechnology, which has exploded into prominence, particularly over the last half-decade. Light of an appropriate wavelength can penetrate mammalian tissues to a depth of up to a couple of centimeters, rendering much of the living body accessible to optical study and control—still more if the detector/source is integrated into an endoscopic or fiber optic probe. Techniques borrowed from the semiconductor industry allow patterns of illumination to be controlled down to the nanometer scale, ideal for addressing individual cells. The highly controlled time course of such experiments, as compared to traditional means of gene activation, such as the addition of a chemical agent to the medium, eliminates confounding variables, and simplifies data analysis. Furthermore, this level of immediate control opens the door to closed-loop systems where the activity of entities under optical control can be continuously tuned in relation to some parameter(s). In the first of these two illuminating theses, a vehicle is developed that permits light-driven release of a small molecule. Such a system could be employed to target a systemically administered antibiotic or anti-neoplastic agent to a site of infection or cancer while sparing other bodily tissues from toxicity. Because most modern drugs cannot be produced in the body, even given arbitrarily good control of cellular biochemistry, this technique will have lasting value in numerous clinical contexts. In the second thesis, the level of precision achieved is even more profound; the CRISPR/Cas9 system has received much recent attention13 in its own right for its capacity to target arbitrary genetic sequences without an arduous protein-engineering step. The LACE system described stands to permit genetic manipulation with almost arbitrarily good spatial, temporal, and genomic site-specific control, using only means available to a typical university laboratory.
Targeting T Cells for the Immune-Modulation of Human Diseases Regina Lin, PhD, Duke University
Dysregulated inflammation underlies the pathogenesis of a myriad of human diseases ranging from cancer to autoimmunity. As coordinators, executers, and sentinels of host immunity, T cells represent a compelling target population for immune-modulation. In fact, the antigen-specificity, cytotoxicity, and promise of long-lived of immune-protection make T cells ideal vehicles for cancer immunotherapy. Interventions for autoimmune disorders, on the other hand, aim to dampen T cell–mediated inflammation and promote their regulatory functions. Although significant strides have been made in targeting T cells for immune modulation, current approaches remain less than ideal and leave room for improvement. In this dissertation, I seek to improve on current T cell-targeted immunotherapies, by identifying and pre-clinically characterizing their mechanisms of action and in vivo therapeutic efficacy.
CD8+ cytotoxic T cells have potent anti-tumor activity and therefore are leading candidates for use in cancer immunotherapy. The application of CD8+ T cells for clinical use has been limited by the susceptibility of ex vivo– expanded CD8+ T cells to become dysfunctional in response to immunosuppressive microenvironments. To enhance the efficacy of adoptive cell transfer therapy (ACT), we established a novel microRNA (miRNA)-targeting approach that augments CTL cytotoxicity and preserves immunocompetence. Specifically, we screened for miRNAs that modulate cytotoxicity and identified miR-23a as a strong functional repressor of the transcription factor Blimp-1, which promotes CTL cytotoxicity and effector cell differentiation. In a cohort of advanced lung cancer patients, miR- 23a was up-regulated in tumor-infiltrating CD8+ T cells, and its expression correlated with impaired anti-tumor potential of patient CD8+ T cells. We determined that tumor-derived transforming growth factor-b (TGF-b) directly suppresses CD8+ T cell immune function by elevating miR-23a and down-regulating Blimp-1. Functional blockade of miR-23a in human CD8+ T cells enhanced granzyme B expression; and in mice with established tumors, immunotherapy with just a small number of tumor-specific CD8+ T cells in which miR-23a was inhibited robustly hindered tumor progression. Together, our findings provide a miRNA-based strategy that subverts the immunosuppression of CD8+ T cells that is often observed during adoptive cell transfer tumor immunotherapy and identify a TGF-bmediated tumor immune-evasion pathway
Having established that miR-23a-inhibition can enhance the quality and functional resilience of anti-tumor CD8+ T cells, especially within the immune-suppressive tumor microenvironment, we went on to interrogate the translational applicability of this strategy in the context of chimeric antigen receptor (CAR)-modified CD8+ T cells. Although CAR T cells hold immense promise for ACT, CAR T cells are not completely curative due to their in vivo functional suppression by immune barriers—such as TGF-b—within the tumor microenvironment. Because TGF-b poses a substantial immune barrier in the tumor microenvironment, we sought to investigate whether inhibiting miR-23a in CAR T cells can confer immune competence to afford enhanced tumor clearance. To this end, we retrovirally transduced wild-type and miR-23a–deficient CD8+ T cells with the EGFRvIII-CAR, which targets the PepvIII tumorspecific epitope expressed by glioblastomas (GBM). Our in vitro studies demonstrated that while wild-type EGFRvIIICAR T cells were vulnerable to functional suppression by TGF-b, miR-23a abrogation rendered EGFRvIII-CAR T cells immune-resistant to TGF-b. Rigorous preclinical studies are currently underway to evaluate the efficacy of miR-23adeficient EGFRvIII-CAR T cells for GBM immunotherapy.
Last, we explored novel immune-suppressive therapies by the biological characterization of pharmacological agents that could target T cells. Although immune-suppressive drugs are classical therapies for a wide range of autoimmune diseases, they are accompanied by severe adverse effects. This motivated our search for novel immunesuppressive agents that are efficacious and lack undesirable side effects. To this end, we explored the potential utility of subglutinol A, a natural product isolated from the endophytic fungus Fusarium subglutinans. We showed that subglutinol A exerts multimodal immune-suppressive effects on activated T cells in vitro. Subglutinol A effectively blocked T cell proliferation and survival, while profoundly inhibiting pro-inflammatory interferon-c (IFN-c) and interleukin-17 (IL-17) production by fully differentiated effector Th1 and Th17 cells. Our data further revealed that subglutinol A might exert its anti-inflammatory effects by exacerbating mitochondrial damage in T cells, but not in innate immune cells or fibroblasts. Additionally, we demonstrated that subglutinol A significantly reduced lymphocytic infiltration into the footpad and ameliorated footpad swelling in the mouse model of Th1-driven delayed-type hypersensitivity. These results suggest the potential of subglutinol A as a novel therapeutic for inflammatory diseases.
Comment: Immunotherapy is among the most promising approaches to cancer treatment, having the specificity and scope to selectively target transformed cells wherever they may reside within the body and the potential to install a permanent defense against disease recurrence. By the time a typical cancer is clinically diagnosed, however, it has already found means to survive a prolonged period of potential immune attack. The mechanisms by which tumors evade immune surveillance are beginning to be elucidated,15,16 and include both direct suppression of effector cells and progressive editing of the host’s immune repertoire to disfavor future attack. It is inherently difficult to interfere with these defenses directly, due to the selection pressures in genetically heterogeneous neoplastic tissue. Much effort is thus being focused on methods for rendering therapeutically delivered immune cells resistant to their effects. The cytokine TGF-b is paradoxically known to function as both a tumor suppressor in healthy tissue and as a tumorderived species associated with multiple cancer-promoting activities, including enhanced immune evasion. This work identifies the pathway by which TGF-b compromises cytotoxic T cell function in the tumor microenvironment, and demonstrates an effective method for blocking this signal. In many clinical cases, however, editing of the patient’s immune repertoire has already removed or rendered anergic those immune cells able to recognize their cancer. Thus, the finding that blocking TGF-b signaling also appears to enhance the effectiveness of CAR-modified T cells— engineered with an antibody fragment targeting them with high affinity to a particular tumor-associated epitope—is a welcome addition to these already promising results.
Novel Fibonacci and non-Fibonacci structure in the sunflower: results of a citizen science experiment
Jonathan Swinton, Erinma Ochu, The MSI Turing’s Sunflower Consortium
This citizen science study evaluates the occurrence of Fibonacci structure in the spirals of sunflower (Helianthus annuus) seedheads. This phenomenon has competing biomathematical explanations, and our core premise is that observation of both Fibonacci and non-Fibonacci structure is informative for challenging such models. We collected data on 657 sunflowers. In our most reliable data subset, we evaluated 768 clockwise or anticlockwise parastichy numbers of which 565 were Fibonacci numbers, and a further 67 had Fibonacci structure of a predefined type. We also found more complex Fibonacci structures not previously reported in sunflowers. This is the third, and largest, study in the literature, although the first with explicit and independently checkable inclusion and analysis criteria and fully accessible data. This study systematically reports for the first time, to the best of our knowledge, seedheads without Fibonacci structure. Some of these are approximately Fibonacci, and we found in particular that parastichy numbers equal to one less than a Fibonacci number were present significantly more often than those one more than a Fibonacci number. An unexpected further result of this study was the existence of quasi-regular heads, in which no parastichy number could be definitively assigned.
Introduction
Fibonacci structure can be found in hundreds of different species of plants [1]. This has led to a variety of competing conceptual and mathematical models that have been developed to explain this phenomenon. It is not the purpose of this paper to survey these: reviews can be found in [1–4], with more recent work including [5–10]. Instead, we focus on providing empirical data useful for differentiating them.
These models are in some ways now very mathematically satisfying in that they can explain high Fibonacci numbers based on a small number of plausible assumptions, though they are not so satisfying to experimental scientists [11]. Despite an increasingly detailed molecular and biophysical understanding of plant organ positioning [12–14], the very parsimony and generality of the mathematical explanations make the generation and testing of experimental hypotheses difficult. There remains debate about the appropriate choice of mathematical models, and whether they need to be central to our understanding of the molecular developmental biology of the plant. While sunflowers provide easily the largest Fibonacci numbers in phyllotaxis, and thus, one might expect, some of the stronger constraints on any theory, there is a surprising lack of systematic data to support the debate. There have been only two large empirical studies of spirals in the capitulum, or head, of the sunflower: Weisse [15] and Schoute [16], which together counted 459 heads; Schoute found numbers from the main Fibonacci sequence 82% of the time and Weise 95%. The original motivation of this study was to add a third replication to these two historical studies of a widely discussed phenomenon. Much more recently, a study of a smaller sample of 21 seedheads was carried out by Couder [17], who specifically searched for non-Fibonacci examples, whereas Ryan et al. [18] studied the arrangement of seeds more closely in a small sample of Helianthus annuus and a sample of 33 of the related perennial H. tuberosus.
Neither the occurrence of Fibonacci structure nor the developmental biology leading to it are at all unique to sunflowers. As common in other species, the previous sunflower studies found not only Fibonacci numbers, but also the occasional occurrence of the double Fibonacci numbers, Lucas numbers and F4 numbers defined below [1]. It is worth pointing out the warning of Cooke [19] that numbers from these sequences make up all but three of the first 17 integers. This means that it is particularly valuable to look at specimens with large parastichy numbers, such as the sunflowers, where the prevalence of Fibonacci structure is at its most striking.
Neither Schoute nor Weisse reported their precise technique for assigning parastichy numbers to their samples, and it is noteworthy that neither author reported any observation of non-Fibonacci structure. One of the objectives of this study was to rigorously define Fibonacci structure in advance and to ensure that the assignment method, though inevitably subjective, was carefully documented.
This paper concentrates on the patterning of seeds towards the outer rim of sunflower seedheads. The number of ray florets (the ‘petals’, typically bright yellow) or the green bracts behind them tends to have a looser distribution around a Fibonacci number. In the only mass survey of these, Majumder & Chakravarti [20] counted ray florets on 1002 sunflower heads and found a distribution centred on 21.
This citizen science study evaluates the occurrence of Fibonacci structure in the spirals of sunflower (Helianthus annuus) seedheads. This phenomenon has competing biomathematical explanations, and our core premise is that observation of both Fibonacci and non-Fibonacci structure is informative for challenging such models. We collected data on 657 sunflowers. In our most reliable data subset, we evaluated 768 clockwise or anticlockwise parastichy numbers of which 565 were Fibonacci numbers, and a further 67 had Fibonacci structure of a predefined type. We also found more complex Fibonacci structures not previously reported in sunflowers. This is the third, and largest, study in the literature, although the first with explicit and independently checkable inclusion and analysis criteria and fully accessible data. This study systematically reports for the first time, to the best of our knowledge, seedheads without Fibonacci structure. Some of these are approximately Fibonacci, and we found in particular that parastichy numbers equal to one less than a Fibonacci number were present significantly more often than those one more than a Fibonacci number. An unexpected further result of this study was the existence of quasi-regular heads, in which no parastichy number could be definitively assigned.
Incorporation of irregularity into the mathematical models of phyllotaxis is relatively recent: [17] gave an example of a disordered pattern arising directly from the deterministic model while more recently the authors have begun to consider the effects of stochasticity [10,21]. Differentiating between these models will require data that go beyond capturing the relative prevalence of different types of Fibonacci structure, so this study was also designed to yield the first large-scale sample of disorder in the head of the sunflower.
The Fibonacci sequence is the sequence of integers 1,2,3,5,8,13,21,34,55,89,144… in which each member after the second is the sum of the two preceding. The Lucas sequence is the sequence of integers 1,3,4,7,11,18,29,47,76,123… obeying the same rule but with a different starting condition; the F4 sequence is similarly 1,4,5,9,14,23,37,60,97,…. The double Fibonacci sequence 2,4,6,10,16,26,42,68,110,… is double the Fibonacci sequence. We say that a parastichy number which is any of these numbers has Fibonacci structure. The sequencesF5=1,5,6,11,17,28,45,73,… and F8=1,8,9,17,26,43,69,112… also arise from the same rule, but as they had not been previously observed in sunflowers we did not include these in the pre-planned definition of Fibonacci structure for parsimony. One example of adjacent pairs from each of these sequences was, in fact, observed but both examples are classified as non-Fibonacci below. A parastichy number which is any of 12,20,33,54,88,143 is also not classed as having Fibonacci structure but is distinguished as a Fibonacci number minus one in some of the analyses, and similarly 14,22,35,56,90,145 as Fibonacci plus one.
When looking at a seedhead such as in figure 1 the eye naturally picks out at least one family of parastichies or spirals: in this case, there is a clockwise family highlighted in blue in the image on the right-hand side.
Figure 5 plots the individual pairs observed. On the reference line, the ratio of the numbers is equal to the golden ratio so departures from the line mark departures from Fibonacci structure, which are less evident in the more reliable photoreviewed dataset. It can be seen from table 3 that Fibonacci pairings dominate the dataset.
Observed pairings of Fibonacci types of clockwise and anticlockwise parastichy numbers. Other means any parastichy number which neither has Fibonacci structure nor is Fibonacci ±1. Of all the Fibonacci ±1/Fibonacci pairs, only sample 191, a (21,20) pair, was not close to an adjacent Fibonacci pair.
One typical example of a Fibonacci pair is shown in figure 6, with a double Fibonacci case infigure 1 and a Lucas one in figure 7. There was no photoreviewed example of an F4 pairing. The sole photoreviewed assignment of a parastichy number to the F4 sequence was the anticlockwise parastichy number 37 in sample 570, which was relatively disordered. The clockwise parastichy number was 55, lending support to the idea this may have been a perturbation of a (34,55) pattern. We also found adjacent members of higher-order Fibonacci series. Figures 8 and 9 each show well-ordered examples with parastichy counts found adjacent in the F5 and F8 series, respectively: neither of these have been previously reported in the sunflower.
Sunflower 095. An (89,55) example with 89 clockwise parastichies and 55 anticlockwise ones, extending right to the rim of the head. Because these are clear and unambiguous, the other parastichy families which are visible towards the centre are not counted here.
Sunflower 667. Anticlockwise parastichies only, showing competing parastichy families which are distinct but in some places overlapping.
Our core results are twofold. First, and unsurprisingly, Fibonacci numbers, and Fibonacci structure more generally, are commonly found in the patterns in the seedheads of sunflowers. Given the extent to which Fibonacci patterns have attracted pseudo-scientific attention [33], this substantial replication of limited previous studies needs no apology. We have also published, for the first time, examples of seedheads related to the F5 and F8 sequences but by themselves they do not add much to the evidence base. Our second core result, though, is a systematic survey of cases where Fibonacci structure, defined strictly or loosely, did not appear. Although not common, such cases do exist and should shed light on the underlying developmental mechanisms. This paper does not attempt to shed that light, but we highlight the observations that any convincing model should explain. First, the prevalence of Lucas numbers is higher than those of double Fibonacci numbers in all three large datasets in the literature, including ours, and there are sporadic appearances of F4, F5 and F8 sequences. Second, counts near to but not exactly equal to Fibonacci structure are also observable: we saw a parastichy count of 54 more often than the most common Lucas count of 47. Sometimes, ambiguity arises in the counting process as to whether an exact Fibonacci-structured number might be obtained instead, but there are sufficiently many unambiguous cases to be confident this is a genuine phenomenon. Third, among these approximately Fibonacci counts, those which are a Fibonacci number minus one are significantly more likely to be seen than a Fibonacci number plus one. Fourth, it is not uncommon for the parastichy families in a seedhead to have strong departures from rotational symmetry: this can have the effect of yielding parastichy numbers which have large departures from Fibonacci structure or which are completely uncountable. This is related to the appearance of competing parastichy families. Fifth, it is common for the parastichy count in one direction to be more orderly and less ambiguous than that in the other. Sixth, seedheads sometimes possess completely disordered regions which make the assignment of parastichy numbers impossible. Some of these observations are unsurprising, some can be challenged by different counting protocols, and some are likely to be easily explained by the mathematical properties of deformed lattices, but taken together they pose a challenge for further research.
It is in the nature of this crowd-sourced experiment with multiple data sources that it is much easier to show variability than it is to find correlates of that variability. We tried a number of cofactor analyses that found no significant effect of geography, growing conditions or seed type but if they do influence Fibonacci structure, they are likely to be much easier to detect in a single-experimenter setting.
We have been forced by our results to extend classifications of seedhead patterns beyond structured Fibonacci to approximate Fibonacci ones. Clearly, the more loose the definition of approximate Fibonacci, the easier it is to explain away departures from model predictions. Couder [17] found one case of a (54,87) pair that he interpreted as a triple Lucas pair 3×(18,29). While mathematically true, in the light of our data, it might be more compellingly be thought of as close to a (55,89) ideal than an exact triple Lucas one. Taken together, this need to accommodate non-exact patterns, the dominance of one less over one more than Fibonacci numbers, and the observation of overlapping parastichy families suggest that models that explicitly represent noisy developmental processes may be both necessary and testable for a full understanding of this fascinating phenomenon. In conclusion, this paper provides a testbed against which a new generation of mathematical models can and should be built.
UC Berkeley researchers have found a long-elusive Achilles’ heel within “triple-negative” breast tumors, a common type of breast cancer that is difficult to treat. The scientists then used a drug-like molecule to successfully target this vulnerability, killing cancer cells in the lab and shrinking tumors in mice.
“We were looking for targets that drive cancer metabolism in triple-negative breast cancer, and we found one that was very specific to this type of cancer,” said Daniel K. Nomura, an associate professor of chemistry and of nutritional sciences and toxicology at UC Berkeley and senior author for the study, which is published online ahead of print in Cell Chemical Biology.
Triple-negative breast cancers account for about one in five breast cancers, and they are deadlier than other forms of breast cancer, in part because no drugs have been developed to specifically target these tumors.
Triple-negative breast cancers do not rely on the hormones estrogen and progesterone for growth, nor on human epidermal growth factor receptor 2 (HER2). Because they do not depend on these three targets, they are not vulnerable to modern hormonal therapies or to the HER2-targeted drug Herceptin (trastuzumab).
Instead, oncologists treat triple-negative breast cancer with older chemotherapies that target all dividing cells. If triple-negative breast cancer spreads beyond the breast to distant sites within the body, an event called metastasis, there are few treatment options.
Tumor cells develop abnormal metabolism, which they rely on to get the energy boost they need to fuel their rapid growth. In their new study, the research team used an innovative approach to search for active enzymes that triple-negative breast cancers use differently for metabolism in comparison to other cells and even other tumors.
Inhibiting cancer metabolism
They discovered that cells from triple-negative breast cancer cells rely on vigorous activity by an enzyme called glutathione-S-transferase Pi1 (GSTP1). They showed that in cancer cells, GSTP1 regulates a type of metabolism called glycolysis, and that inhibition of GSTP1 impairs glycolytic metabolism in triple-negative cancer cells, starving them of energy, nutrients and signaling capability. Normal cells do not rely as much on this particular metabolic pathway to obtain usable chemical energy, but cells within many tumors heavily favor glycolysis.
Co-author Eranthie Weerapana, an associate professor of chemistry at Boston College, developed a molecule named LAS17 that tightly and irreversibly attaches to the target site on the GSTP1 molecule. By binding tightly to GSTP1, LAS17 inhibits activity of the enzyme. The researchers found that LAS17 was highly specific for GSTP1, and did not attach to other proteins in cells.
According to Nomura, LAS17 did not appear to have toxic side effects in mice, where it shrank tumors grown to an invasive stage from surgically transplanted, human, triple-negative breast cancer cells that had long been maintained in lab cultures.
The research team intends to continue studying LAS17, Nomura said, with the next step being to study tumor tissue resected from human triple-negative breast cancers and transplanted directly into mice.
“Inhibiting GSTP1 impairs glycolytic metabolism,” Nomura said. “More broadly, this inhibition starves triple-negative breast cancer cells, preventing them from making the macromolecules they need, including the lipids they need to make membranes and the nucleic acids they need to make DNA. It also prevents these cells from making enough ATP, the molecule that is the basic energy fuel for cells.”
Beyond the metabolic role they first sought to track down, GSTP1 also appears to aid signaling within triple-negative breast cancer cells, helping to spur tumor growth, the researchers found.
Technique identifies Achilles’ heels
Nomura said it was surprising that a single, unique target emerged from the research team’s search.
The method used by the researchers, called “reactivity-based chemoproteomics,” can quickly lead to specific targetable sites — the Achilles’ heels — on proteins of interest, and eventually to drug development strategies, Nomura said.
The approach is to search for protein targets that are actively functioning within cells, instead of first using the well-trod path of surveying all genes to identify the specific genes that have taken the first step toward protein production. With that more conventional strategy, the switching on, or “expression,” of genes is evidenced by the easily quantified molecule called messenger RNA, made by the cell from a gene’s DNA template.
Nomura’s team instead first used chemical probes that can react with certain configurations of two of the amino acid building blocks of protein — cysteine and lysine — known to be involved in several kinds of important structural and functional transitions that active proteins can undergo.
“A lot can happen after the first step in protein production, and we believe our method for identifying fully formed, active proteins is more useful for tracking down relevant differences in cellular physiology,” Nomura said.
The researchers analyzed and compared cells from five distinct triple-negative breast cancers that had been grown in cell cultures for generations, along with cells from four distinct breast cancers that were not triple negative.
The scientists used a chemical identification technique known as mass spectrometry to narrow down the set of proteins that had active lysines and cysteines to just those that were metabolic enzymes. Only then did they use the more conventional approach of measuring gene expression in the different cancer cell types.
GSTP1 was the only metabolically active enzyme that was specifically expressed only in triple-negative breast cancer cells compared to other breast cancer cell types, the researchers found. Separate analysis of databases of human breast cancer by UC San Francisco co-authors confirmed that GSTP1 is overexpressed in patients with triple-negative breast cancers in comparison to patients with other breast cancers.
In addition to Nomura and Weerapana, study authors included Sharon Louie, Elizabeth Grossman, Lucky Ding, Tucker Huffman and David Miyamoto, from UC Berkeley; Roman Camarda and Andrei Goga, from UC San Francisco, and Lisa Crawford, from Boston College. Study funders included the National Institutes of Health, the American Cancer Society, the U.S. Department of Defense, and the Searle Scholar Foundation.
Breast cancer metastasized to the liver (Courtesy of National Cancer Institute)
UC Berkeley researchers have found a long-elusive Achilles’ heel within “triple-negative” breast tumors, a common type of breast cancer that is difficult to treat. The scientists then used a drug-like molecule to successfully target this vulnerability, killing cancer cells in the lab and shrinking tumors in mice.
“We were looking for targets that drive cancer metabolism in triple-negative breast cancer, and we found one that was very specific to this type of cancer,” said Daniel K. Nomura, an associate professor of chemistry and of nutritional sciences and toxicology at UC Berkeley and senior author for the study, which is published online ahead of print on May 12 in Cell Chemical Biology.
Triple-negative breast cancers account for about one in five breast cancers, and they are deadlier than other forms of breast cancer, in part because no drugs have been developed to specifically target these tumors.
Triple-negative breast cancers do not rely on the hormones estrogen and progesterone for growth, nor on human epidermal growth factor receptor 2 (HER2). Because they do not depend on these three targets, they are not vulnerable to modern hormonal therapies or to the HER2-targeted drug Herceptin (trastuzumab).
Instead, oncologists treat triple-negative breast cancer with older chemotherapies that target all dividing cells. If triple-negative breast cancer spreads beyond the breast to distant sites within the body, an event called metastasis, there are few treatment options.
Tumor cells develop abnormal metabolism, which they rely on to get the energy boost they need to fuel their rapid growth. In their new study, the research team used an innovative approach to search for active enzymes that triple-negative breast cancers use differently for metabolism in comparison to other cells and even other tumors.
Inhibiting cancer metabolism
They discovered that cells from triple-negative breast cancer cells rely on vigorous activity by an enzyme called glutathione-S-transferase Pi1 (GSTP1). They showed that in cancer cells, GSTP1 regulates a type of metabolism called glycolysis, and that inhibition of GSTP1 impairs glycolytic metabolism in triple-negative cancer cells, starving them of energy, nutrients and signaling capability. Normal cells do not rely as much on this particular metabolic pathway to obtain usable chemical energy, but cells within many tumors heavily favor glycolysis.
•We used chemoproteomics to profile metabolic drivers of breast cancer
•GSTP1 is a novel triple-negative breast cancer-specific target
•GSTP1 inhibition impairs triple-negative breast cancer pathogenicity
•GSTP1 inhibition impairs GAPDH activity to affect metabolism and signaling
Breast cancers possess fundamentally altered metabolism that fuels their pathogenicity. While many metabolic drivers of breast cancers have been identified, the metabolic pathways that mediate breast cancer malignancy and poor prognosis are less well understood. Here, we used a reactivity-based chemoproteomic platform to profile metabolic enzymes that are enriched in breast cancer cell types linked to poor prognosis, including triple-negative breast cancer (TNBC) cells and breast cancer cells that have undergone an epithelial-mesenchymal transition-like state of heightened malignancy. We identified glutathione S-transferase Pi 1 (GSTP1) as a novel TNBC target that controls cancer pathogenicity by regulating glycolytic and lipid metabolism, energetics, and oncogenic signaling pathways through a protein interaction that activates glyceraldehyde-3-phosphate dehydrogenase activity. We show that genetic or pharmacological inactivation of GSTP1 impairs cell survival and tumorigenesis in TNBC cells. We put forth GSTP1 inhibitors as a novel therapeutic strategy for combatting TNBCs through impairing key cancer metabolism and signaling pathways.
Cyclic Dinucleotides and Histone deacetylase inhibitors
Curators: Larry H. Bernsten, MD, FCAP and Aviva Lev-Ari, PhD, RN
LPBI
New Class of Immune System Stimulants: Cyclic Di-Nucleotides (CDN): Shrink Tumors and bolster Vaccines, re-arm the Immune System’s Natural Killer Cells, which attack Cancer Cells and Virus-infected Cells
Reporter: Aviva Lev-Ari, PhD, RN
The Immunotherapeutics and Vaccine Research Initiative (IVRI), a UC Berkeley effort funded by Aduro Biotech, Inc.
A new class of immune system stimulants called cyclic di-nucleotides have shown promise in shrinking tumors and bolstering vaccines against tuberculosis, and research that could help re-arm the immune system’s natural killer cells, which normally attack cancer cells and virus-infected cells, to better fight tumors.
Much of the excitement around combining these two areas — the immunology of cancer and the immunology of infectious disease — comes from the amazing success of immunotherapy against cancer, which started with the work of James Allison when he was a professor of immunology at UC Berkeley and director of the Cancer Research Laboratory from 1985 to 2004. Allison, now at the University of Texas MD Anderson Cancer Center, discovered a way to release a brake on the body’s immune response to cancer that has proved highly successful at unleashing the immune system to attack melanoma and is being tried against other types of cancer. Allison’s technique uses an antibody that blocks an immune suppressor called CTLA4, antibodies that block another immune suppressor, PD1. This has been successful in treating melanoma, renal cancer and a type of lung cancer. Both CTLA4 and PD1 antibodies are now FDA-approved as cancer therapies.
Another promising avenue involves a protein in cells that responds to foreign DNA to launch an innate immune response — the first response of the body’s immune system. The protein, dubbed STING, is triggered by small molecules called cyclic di-nucleotides (CDN), and makes immune cells release interferon and other cytokines that activate disease-fighting T cells and stimulate the production of antibodies that together kill invading pathogens and destroy cancer cells. Listeria bacteria, for example, secrete a CDN directly into infected cells that activates STING.
Russell Vance, a UC Berkeley professor of molecular and cell biology and current head of the Cancer Research Laboratory, discovered several years ago that the chemical structure of these di-nucleotides is critical to their ability to work in humans. Aduro has since developed a CDN designed to work in humans and found that injecting it directly into a tumor in mice caused the tumor to shrink.
Sarah Stanley, an assistant professor of public health, has found evidence that CDNs can help improve the imperfect vaccines we have today against tuberculosis.
Researchers at UC Berkeley will have access to Aduro’s novel technology platforms for research use, including its STING pathway activators, proprietary monoclonal antibodies and the engineered listeria bacteria, referred to as LADD (listeria attenuated double-deleted). David Raulet, professor of molecular and cell biology and director of IVRI has contributed to making these cells a new focus of cancer research. As tumors advance, NK cells inside the tumors appear to become desensitized, he said. Recent research shows that some cytokines and other immune mediators Raulet discovered are able to “wake them up” and get them to resume their elimination of cancer cells.
Histone deacetylase inhibitors: molecular mechanisms of action
This review focuses on the mechanisms of action of histone deacetylase (HDAC) inhibitors (HDACi), a group of recently discovered ‘targeted’ anticancer agents. There are 18 HDACs, which are generally divided into four classes, based on sequence homology to yeast counterparts. Classical HDACi such as the hydroxamic acid-based vorinostat (also known as SAHA and Zolinza) inhibits classes I, II and IV, but not the NAD+-dependent class III enzymes. In clinical trials, vorinostat has activity against hematologic and solid cancers at doses well tolerated by patients. In addition to histones, HDACs have many other protein substrates involved in regulation of gene expression, cell proliferation and cell death. Inhibition of HDACs causes accumulation of acetylated forms of these proteins, altering their function. Thus, HDACs are more properly called ‘lysine deacetylases.’ HDACi induces different phenotypes in various transformed cells, including growth arrest, activation of the extrinsic and/or intrinsic apoptotic pathways, autophagic cell death, reactive oxygen species (ROS)-induced cell death, mitotic cell death and senescence. In comparison, normal cells are relatively more resistant to HDACi-induced cell death. The plurality of mechanisms of HDACi-induced cell death reflects both the multiple substrates of HDACs and the heterogeneous patterns of molecular alterations present in different cancer cells.
Acetylation and deacetylation of histones play an important role in transcription regulation of eukaryotic cells (Lehrmann et al., 2002;Mai et al., 2005). The acetylation status of histones and non-histone proteins is determined by histone deacetylases (HDACs) and histone acetyl-transferases (HATs). HATs add acetyl groups to lysine residues, while HDACs remove the acetyl groups. In general, acetylation of histone promotes a more relaxed chromatin structure, allowing transcriptional activation. HDACs can act as transcription repressors, due to histone deacetylation, and consequently promote chromatin condensation. HDAC inhibitors (HDACi) selectively alter gene transcription, in part, by chromatin remodeling and by changes in the structure of proteins in transcription factor complexes (Gui et al., 2004). Further, the HDACs have many non-histone proteins substrates such as hormone receptors, chaperone proteins and cytoskeleton proteins, which regulate cell proliferation and cell death (Table 1). Thus, HDACi-induced transformed cell death involves transcription-dependent and transcription-independent mechanisms (Marks and Dokmanovic, 2005; Rosato and Grant, 2005; Bolden et al., 2006;Minucci and Pelicci, 2006).
In humans, 18 HDAC enzymes have been identified and classified, based on homology to yeast HDACs (Blander and Guarente, 2004;Bhalla, 2005; Marks and Dokmanovic, 2005). Class I HDACs include HDAC1, 2, 3 and 8, which are related to yeast RPD3 deacetylase and have high homology in their catalytic sites. Recent phylogenetic analyses suggest that this class can be divided into classes Ia (HDAC1 and -2), Ib (HDAC3) and Ic (HDAC8) (Gregoretti et al., 2004). Class II HDACs are related to yeast Hda1 (histone deacetylase 1) and include HDAC4, -5, -6, -7, -9 and -10 (Bhalla, 2005; Marks and Dokmanovic, 2005). This class is divided into class IIa, consisting of HDAC4, -5, -7 and -9, and class IIb, consisting of HDAC6 and -10, which contain two catalytic sites. All class I and II HDACs are zinc-dependent enzymes. Members of a third class, sirtuins, require NAD+ for their enzymatic activity (Blander and Guarente, 2004) (see review by E Verdin, in this issue). Among them, SIRT1 is orthologous to yeast silent information regulator 2. The enzymatic activity of class III HDACs is not inhibited by compounds such as vorinostat or trichostatin A (TSA), that inhibit class I and II HDACs. Class IV HDAC is represented by HDAC11, which, like yeast Hda 1 similar 3, has conserved residues in the catalytic core region shared by both class I and II enzymes (Gao et al., 2002).
HDACs are not redundant in function (Marks and Dokmanovic, 2005; Rosato and Grant, 2005; Bolden et al., 2006). Class I HDACs are primarily nuclear in localization and ubiquitously expressed, while class II HDACs can be primarily cytoplasmic and/or migrate between the cytoplasm and nucleus and are tissue-restricted in expression.
The structural details of the HDAC–HDACi interaction has been elucidated in studies of a histone deacetylase-like protein from an anerobic bacterium with TSA and vorinostat (Finnin et al., 1999). More recently, the crystal structure of HDAC8–hydroxamate interaction has been solved (Somoza et al., 2004; Vannini et al., 2004). These studies provide an insight into the mechanism of deacetylation of acetylated substrates. The hydroxamic acid moiety of the inhibitor directly interacts with the zinc ion at the base of the catalytic pocket.
This review focuses on the molecular mechanisms triggered by inhibitors of zinc-dependent HDACs in tumor cells that explain in part: (I) the effects of these compounds in inducing transformed cell death and (II) the relative resistance of normal and certain cancer cells to HDACi induced cell death. HDACi, for example, the hydroxamic acid-based vorinostat (SAHA, Zolinza), are promising drugs for cancer treatment (Richon et al., 1998; Marks and Breslow, 2007). Several HDACi are in phase I and II clinical trials, being tested in different tumor types, such as cutaneous T-cell lymphoma, acute myeloid leukemia, cervical cancer, etc (Bug et al., 2005; Chavez-Blanco et al., 2005; Kelly and Marks, 2005;Duvic and Zhang, 2006) (Table 2). Although considerable progress has been made in elucidating the role of HDACs and the effects of HDACi, these areas are still in early stages of discovery.
Recent phylogenetic analyses of bacterial HDACs suggest that all four HDAC classes preceded the evolution of histone proteins (Gregoretti et al., 2004). This suggests that the primary activity of HDACs may be directed against non-histone substrates. At least 50 non-histone proteins of known biological function have been identified, which may be acetylated and substrates of HDACs (Table 1) (Glozak et al., 2005; Marks and Dokmanovic, 2005;Rosato and Grant, 2005; Bolden et al., 2006; Minucci and Pelicci, 2006; Zhao et al., 2006). In addition, two recent proteomic studies identified many lysine-acetylated substrates (Iwabata et al., 2005; Kim et al., 2006). In view of all these findings, HDACs may be better called ‘N-epsilon-lysine deacetylase’. This designation would also distinguish them from the enzymes that catalyse other types of deacetylation in biological reactions, such as acylases that catalyse the deacetylation of a range of N-acetyl amino acids (Anders and Dekant, 1994).
Non-histone protein targets of HDACs include transcription factors, transcription regulators, signal transduction mediators, DNA repair enzymes, nuclear import regulators, chaperone proteins, structural proteins, inflammation mediators and viral proteins (Table 1). Acetylation can either increase or decrease the function or stability of the proteins, or protein–protein interaction (Glozak et al., 2005). These HDAC substrates are directly or indirectly involved in many biological processes, such as gene expression and regulation of pathways of proliferation, differentiation and cell death. These data suggest that HDACi could have multiple mechanisms of inducing cell growth arrest and cell death (Figure 1).
HDACi have been discovered with different structural characteristics, including hydroximates, cyclic peptides, aliphatic acids and benzamides (Table 2) (Miller et al., 2003; Yoshida et al., 2003; Marks and Breslow, 2007). Certain HDACi may selectively inhibit different HDACs. For example, MS-275 preferentially inhibits HDAC1 with IC50, at 0.3 m, compared to HDAC3 with an IC50 of about 8 m, and has little or no inhibitory effect against HDAC6 and HDAC8 (Hu et al., 2003). Two novel synthetic compounds, SK7041 and SK7068, preferentially target HDAC1 and 2 and exhibit growth inhibitory effects in human cancer cell lines and tumor xenograft models (Kim et al., 2003a). A small molecule, tubacin, selectively inhibits HDAC6 activity and causes an accumulation of acetylated -tubulin, but does not affect acetylation of histones, and does not inhibit cell cycle progression (Haggarty et al., 2003). No other HDACi for a specific HDAC has been reported.
HDACi selectively alters gene expression
HDACi-induced antitumor pathways
HDACi induces cell cycle arrest
HDACi activates the extrinsic apoptotic pathways
HDACi activates the intrinsic apoptotic pathways
HDACi induces mitotic cell death
HDACi induces autophagic cell death and senescence
ROS, thioredoxin and Trx binding protein 2 in HDACi-induced cell death
Antitumor effects of HDAC6 inhibition
Activation of protein phosphatase 1
Disruption of the function of chaperonin HSP90
Disruption of the aggresome pathway
HDACi inhibits angiogenesis
HDACi can block tumor angiogenesis by inhibition of hypoxia inducible factors (HIF) (Liang et al., 2006). HIF-1 and HIF-2 are transcription factors for angiogenic genes (Brown and Wilson, 2004). The oxygen level can control HIF activity through two mechanisms. First, under normoxic conditions, HIF-1 binds to von Hippel–Lindau protein (pVHL) and is degraded by the ubiquitination–proteasome system. Second, HIF activity depends on its transactivation potential (TAP), which is affected by the interaction with the coactivator p300/CBP among others. This complex can be disrupted by Factor Inhibiting HIF (FIH). Hypoxic conditions activate HIF through repression of the hydroxylases responsible for HIF degradation and loss of function.
Combination of HDACi with other antitumor agents
The HDACi have shown synergistic or additive antitumor effects with a wide range of antitumor reagents, including chemotherapeutic drugs, new targeted therapeutic reagents and radiation, by various mechanisms, some unique for particular combinations (Rosato and Grant, 2004; Bhalla, 2005; Marks and Dokmanovic, 2005; Bolden et al., 2006).
Clinical development of HDACi
At least 14 different HDACi are in some phase of clinical trials as monotherapy or in combination with retinoids, taxols, gemcitabine, radiation, etc, in patients with hematologic and solid tumors, including cancer of lung, breast, pancreas, renal and bladder, melanoma, glioblastoma, leukemias, lymphomas, multiple myeloma (see National Cancer Institute website for CTEP clinical trials, ctep.cancer.gov or clinicaltrials.gov, and website of companies developing HDACi; Table 2).
The resistance to HDACi
Conclusions and perspectives
HDACs have multiple substrates involved in many biological processes, including proliferation, differentiation, apoptosis and other forms of cell death. Indeed, the fact that HDACs have histone and multiple nonhistone protein substrates suggests these enzymes should be referred to as ‘lysine deacetylases’. HDACi can cause transformed cells to undergo growth arrest, differentiation and/or cell death. Normal cells are relatively resistant to HDACi. HDACi are selective in altering gene expression, which may reflect, in part, the proteins composing the transcription factor complex to which HDACs are recruited. Both altered gene expression and changes in non-histone proteins caused by HDACi-induced acetylation play a role in the antitumor activity of HDACi. This is reflected in the different inducer-activated antitumor pathways in transformed cells (Figure 1). The functions of HDACs are not redundant. Thus, a pan-HDAC inhibitor such as vorinostat may activate more antitumor pathways and have therapeutic advantages compared to HDAC isotype-specific inhibitors.
Almost all cancers have multiple defects in the expression and/or structure of proteins that regulate cell proliferation and death. Compared to other antitumor reagents, the plurality of action of HDACi potentially confers efficacy in a wide spectrum of cancers, which have heterogeneity and multiple defects, both among different types of cancer and within different individual tumors of the same type. The multiple defects in a cancer cell may be the reason for transformed cells being more sensitive than normal cells to HDACi. Thus, given the relatively rapid reversibility of vorinostat inhibition of HDACs, normal cells may be able to compensate for HDACi-induced changes more effectively than cancer cells.
HDACi have synergistic or additive antitumor effects with many other antitumor reagents – suggesting that combination of HDACi and other anticancer agents may be very attractive therapeutic strategies for using these agents. Complete understanding of the mechanisms underlying the resistance and sensitivity to HDACi has obvious therapeutic importance. Targeting resistant factors will enhance the antitumor efficacy of HDACi. Identifying markers that can predict response to HDACi is a high priority for expanding the efficacy of these novel anticancer agents.
The complexity of cancer has been known for almost a century, in large part from the seminal work of Otto Warburg in the 1920s using manometry, and following the work of Louis Pasteur 60 years earlier with fungi.
The volume of work and our unlocking of mitotic activity, apoptosis, mitochondria, and the cytoskeleton has taken us further into the cell interior, cell function, metabolic regulation, and pathophysiology. Despite the enormous contributions to our knowledge of genomics, there is a large body of work in pathways of cell function that resides in no small part in activity of protein catalysts and enzymes.
The work that has been described covers only cyclic dinucleotides and HDACi’s. Some of the activities described have relevance to microorganisms as well as cancer. As we have seen, blocking HDACs boosts the activity of regulatory T-cells. There are many specific functional alterations elucidated above.
The first presentation is of an antibody that blocks an immune suppressor called CTLA4, antibodies that block another immune suppressor, PD1. This also involves a protein in cells that responds to foreign DNA to launch an innate immune response — the first response of the body’s immune system. The protein, dubbed STING, is triggered by small molecules called cyclic di-nucleotides (CDN), and makes immune cells release interferon and other cytokines that activate disease-fighting T cells and stimulate the production of antibodies that together kill invading pathogens and destroy cancer cells. Listeria bacteria, for example, secrete a CDN directly into infected cells that activates STING.
The second is resident in acetylation status of histones and non-histone proteins is determined by histone deacetylases (HDACs) and histone acetyl-transferases (HATs). HATs add acetyl groups to lysine residues, while HDACs remove the acetyl groups. In general, acetylation of histone promotes a more relaxed chromatin structure, allowing transcriptional activation. HDACs can act as transcription repressors, due to histone deacetylation, and consequently promote chromatin condensation. HDAC inhibitors (HDACi) selectively alter gene transcription, in part, by chromatin remodeling and by changes in the structure of proteins in transcription factor complexes (Gui et al., 2004). The description focuses on the molecular mechanisms triggered by inhibitors of zinc-dependent HDACs in tumor cells that explain in part: (I) the effects of these compounds in inducing transformed cell death and (II) the relative resistance of normal and certain cancer cells to HDACi induced cell death.
HDACs have multiple substrates involved in many biological processes, including proliferation, differentiation, apoptosis and other forms of cell death. Indeed, the fact that HDACs have histone and multiple nonhistone protein substrates suggests these enzymes should be referred to as ‘lysine deacetylases’. HDACi can cause transformed cells to undergo growth arrest, differentiation and/or cell death. Normal cells are relatively resistant to HDACi. HDACi are selective in altering gene expression, which may reflect, in part, the proteins composing the transcription factor complex to which HDACs are recruited. Both altered gene expression and changes in non-histone proteins caused by HDACi-induced acetylation play a role in the antitumor activity of HDACi.
A little adversity builds character, or so the saying goes. True or not, the saying does seem an apt description of a developmental phenomenon that shapes gene expression. While it knows nothing of character, the gene expression apparatus appears to respond well to short-term mitochondrial stress that occurs early in development. In fact, transient stress seems to result in lasting benefits. These benefits, which include improved metabolic function and increased longevity, have been observed in both worms and mice, and may even occur—or be made to occur—in humans.
Gene expression is known to be subject to reprogramming by epigenetic modifiers, but such modifiers generally affect metabolism or lifespan, not both. A new set of epigenetic modifiers, however, has been found to trigger changes that do just that—both improve metabolism and extend lifespan.
Scientists based at the University of California, Berkeley, and the École Polytechnique Fédérale de Lausanne (EPFL) have discovered enzymes that are ramped up after mild stress during early development and continue to affect the expression of genes throughout the animal’s life. When the scientists looked at strains of inbred mice that have radically different lifespans, those with the longest lifespans had significantly higher expression of these enzymes than did the short-lived mice.
“Two of the enzymes we discovered are highly, highly correlated with lifespan; it is the biggest genetic correlation that has ever been found for lifespan in mice, and they’re both naturally occurring variants,” said Andrew Dillin, a UC Berkeley professor of molecular and cell biology. “Based on what we see in worms, boosting these enzymes could reprogram your metabolism to create better health, with a possible side effect of altering lifespan.”
Details of the work, which appeared online April 29 in the journal Cell, are presented in a pair of papers. One paper (“Two Conserved Histone Demethylases Regulate Mitochondrial Stress-Induced Longevity”) resulted from an effort led by Dillin and the EPFL’s Johan Auwerx. The other paper (“Mitochondrial Stress Induces Chromatin Reorganization to Promote Longevity and UPRmt”) resulted from an effort led by Dillin and his UC Berkeley colleague Barbara Meyer.
According to these papers, mitochondrial stress activates enzymes in the brain that affect DNA folding, exposing a segment of DNA that contains the 1500 genes involved in the work of the mitochondria. A second set of enzymes then tags these genes, affecting their activation for much or all of the lifetime of the animal and causing permanent changes in how the mitochondria generates energy.
The first set of enzymes—methylases, in particular LIN-65—add methyl groups to the DNA, which can silence promoters and thus suppress gene expression. By also opening up the mitochondrial genes, these methylases set the stage for the second set of enzymes—demethylases, in this case jmjd-1.2 and jmjd-3.1—to ramp up transcription of the mitochondrial genes. When the researchers artificially increased production of the demethylases in worms, all the worms lived longer, a result identical to what is observed after mitochondrial stress.
“By changing the epigenetic state, these enzymes are able to switch genes on and off,” Dillin noted. This happens only in the brain of the worm, however, in areas that sense hunger or satiety. “These genes are expressed in neurons that are sensing the nutritional status of the animal, and these signals emanate out to the periphery to change peripheral metabolism,” he continued.
When the scientists profiled enzymes in short- and long-lived mice, they found upregulation of these genes in the brains of long-lived mice, but not in other tissues or in the brains of short-lived mice. “These genes are expressed in the hypothalamus, exactly where, when you eat, the signals are generated that tell you that you are full. And when you are hungry, signals in that region tell you to go and eat,” Dillin explained said. “These genes are all involved in peripheral feedback.”
Among the mitochondrial genes activated by these enzymes are those involved in the body’s response to proteins that unfold, which is a sign of stress. Increased activity of the proteins that refold other proteins is another hallmark of longer life.
These observations suggest that the reversal of aging by epigenetic enzymes could also take place in humans.
“It seems that, while extreme metabolic stress can lead to problems later in life, mild stress early in development says to the body, ‘Whoa, things are a little bit off-kilter here, let’s try to repair this and make it better.’ These epigenetic switches keep this up for the rest of the animal’s life,” Dillin stated.
Two Conserved Histone Demethylases Regulate Mitochondrial Stress-Induced Longevity
Carsten Merkwirth6, Virginija Jovaisaite6, Jenni Durieux,…., Reuben J. Shaw, Johan Auwerx, Andrew Dillin
•H3K27 demethylases jmjd-1.2 and jmjd-3.1 are required for ETC-mediated longevity
•jmjd-1.2 and jmjd-3.1 extend lifespan and are sufficient for UPRmt activation
•UPRmt is required for increased lifespan due to jmjd-1.2 or jmjd-3.1 overexpression
•JMJD expression is correlated with UPRmt and murine lifespan in inbred BXD lines
Across eukaryotic species, mild mitochondrial stress can have beneficial effects on the lifespan of organisms. Mitochondrial dysfunction activates an unfolded protein response (UPRmt), a stress signaling mechanism designed to ensure mitochondrial homeostasis. Perturbation of mitochondria during larval development in C. elegans not only delays aging but also maintains UPRmt signaling, suggesting an epigenetic mechanism that modulates both longevity and mitochondrial proteostasis throughout life. We identify the conserved histone lysine demethylases jmjd-1.2/PHF8 and jmjd-3.1/JMJD3 as positive regulators of lifespan in response to mitochondrial dysfunction across species. Reduction of function of the demethylases potently suppresses longevity and UPRmt induction, while gain of function is sufficient to extend lifespan in a UPRmt-dependent manner. A systems genetics approach in the BXD mouse reference population further indicates conserved roles of the mammalian orthologs in longevity and UPRmt signaling. These findings illustrate an evolutionary conserved epigenetic mechanism that determines the rate of aging downstream of mitochondrial perturbations.
Mitochondrial Stress Induces Chromatin Reorganization to Promote Longevity and UPRmt
Ye Tian, Gilberto Garcia, Qian Bian, Kristan K. Steffen, Larry Joe, Suzanne Wolff, Barbara J. Meyer, Andrew Dillin
•LIN-65 accumulates in the nucleus in response to mitochondrial stress
•Mitochondrial stress-induced chromatin changes depend on MET-2 and LIN-65
•LIN-65 and DVE-1 exhibit interdependence in nuclear accumulation
•met-2 and atfs-1 act in parallel to affect mitochondrial stress-induced longevity
Organisms respond to mitochondrial stress through the upregulation of an array of protective genes, often perpetuating an early response to metabolic dysfunction across a lifetime. We find that mitochondrial stress causes widespread changes in chromatin structure through histone H3K9 di-methylation marks traditionally associated with gene silencing. Mitochondrial stress response activation requires the di-methylation of histone H3K9 through the activity of the histone methyltransferase met-2 and the nuclear co-factor lin-65. While globally the chromatin becomes silenced by these marks, remaining portions of the chromatin open up, at which point the binding of canonical stress responsive factors such as DVE-1 occurs. Thus, a metabolic stress response is established and propagated into adulthood of animals through specific epigenetic modifications that allow for selective gene expression and lifespan extension
Siddharta Mukherjee’s Writing Career Just Got Dealt a Sucker Punch
Siddharha Mukherjee won the 2011 Pulitzer Prize in non-fiction for his book, The Emperor of All Maladies. The book has received widespread acclaim among lay audience, physicians, and scientists alike. Last year the book was turned into a special PBS series. But, according to a slew of scientists, we should all be skeptical of his next book scheduled to hit book shelves this month, The Gene, An Intimate History.
Publishing an article on epigenetics in the New Yorker this week–perhaps a selection from his new book–Mukherjee has waltzed into one of the most active scientific debates in all of biology: that of gene regulation, or epigenetics.
Jerry Coyne, the evolutionary biologist known for keeping journalists honest, has published a two part critique of Mukherjee’s New Yorker piece. The first part–wildly tweeted yesterday–is a list of quotes from Coyne’s colleagues and those who have written in to the New Yorker, including two Nobel prize winners, Wally Gilbert and Sidney Altman, offering some very unfriendly sentences.
Wally Gilbert: “The New Yorker article is so wildly wrong that it defies rational analysis.”
Sidney Altman: “I am not aware that there is such a thing as an epigenetic code. It is unfortunate to inflict this article, without proper scientific review, on the audience of the New Yorker.”
The second part is a thorough scientific rebuttal of the Mukherjee piece. It all serves as a great drama about one of the most contested ideas in biology and also as a cautionary tale to journalists, even experienced writers such as Mukherjee, about the dangers of wading into scientific arguments. Readers may remember that a few years ago, science writer, David Dobbs, similarly skated into the same topic with his piece, Die, Selfish Gene, Die, and which raised a similar shitstorm, much of it from Coyne.
Mukherjee’s mistake is in giving credence to only one side of a very fierce debate–that the environment causes changes in the genome which can be passed on; another kind of evolution–as though it were settled science. Either Mukherjee, a physicisan coming off from a successful book and PBS miniseries on cancer, is setting himself up as a scientist, or he has been a truly naive science reporter. If he got this chapter so wrong, what does it mean about an entire book on the gene?
Coyne quotes one of his colleagues who raised some questions about the New Yorker’s science reporting, one particular question we’ve been asking here at Mendelspod. How do we know what we know? Does science now have an edge on any other discipline for being able to create knowledge?
Coyne’s colleague is troubled by science coverage in the New Yorker, and goes so far as to write that the New Yorker has been waging a “war on behalf of cultural critics and literary intellectuals against scientists and technologists.”
From my experience, it’s not quite that tidy. First of all, the New Yorker is the best writing I read each week. Period. Second, I haven’t found their science writing to have the slant claimed in the quote above. For example, most other mainstream outlets–including the New York Times with the Amy Harmon pieces–have given the anti-GMO crowd an equal say in the mistaken search for a “balance” on whether GMOs are harmful. (Remember John Stewart’s criticism of Fox News? That they give a false equivalent between two sides even when there is no equivalent on the other side?)
But the New Yorker has not fallen into this trap on GMOs and most of their pieces on the topic–mainly by Michael Specter–have been decidedly pro science and therefore decided pro GMO.
So what led Mukherjee to play scientist as well as journalist? There’s no question about whether I enjoy his prose. His writing beautifully whisks me away so that I don’t feel that I’m really working to understand. There is a poetic complexity that constantly brings different threads effortlessly together, weaving them into the same light. At one point he uses the metaphor of a web for the genome, with the epigenome being the stuff that sticks to the web. He borrows the metaphor from the Hindu notion of “being”, or jaal.
“Genes form the threads of the web; the detritus that adheres to it transforms every web into a singular being.”
There have been a few writers on Twitter defending Mukherjee’s piece. Tech Review’s Antonio Regalado called Coyne and his colleagues “tedious literalists” who have an “issue with epigenetic poetry.”
At his best, Mukherjee can take us down the sweet alleys of his metaphors and family stories with a new curiosity for the scientific truth. He can hold a mirror up to scientists, or put the spotlight on their work. At their worst, Coyne and his scientific colleagues can reek of a fear of language and therefore metaphor. The always outspoken scientist and author, Richard Dawkins, who made his name by personifying the gene, was quick to personify epigentics in a tweet: “It’s high time the 15 minutes of underserved fame for “epigenetics” came to an overdue end.” Dawkins is that rare scientist who has consistently been as comfortable with rhetoric and language as he is with data.
Hats off to Coyne who reminds us that a metaphor–however lovely–does not some science make. If Mukherjee wants to play scientist, let him create and gather data. If it’s the role of science journalist he wants, let him collect all the science he can before he begins to pour it into his poetry.
Same but Different
How epigenetics can blur the line between nature and nurture.
The author’s mother (right) and her twin are a study in difference and identity. CREDIT: PHOTOGRAPH BY DAYANITA SINGH FOR THE NEW YORKER
October 6, 1942, my mother was born twice in Delhi. Bulu, her identical twin, came first, placid and beautiful. My mother, Tulu, emerged several minutes later, squirming and squalling. The midwife must have known enough about infants to recognize that the beautiful are often the damned: the quiet twin, on the edge of listlessness, was severely undernourished and had to be swaddled in blankets and revived.
The first few days of my aunt’s life were the most tenuous. She could not suckle at the breast, the story runs, and there were no infant bottles to be found in Delhi in the forties, so she was fed through a cotton wick dipped in milk, and then from a cowrie shell shaped like a spoon. When the breast milk began to run dry, at seven months, my mother was quickly weaned so that her sister could have the last remnants.
Tulu and Bulu grew up looking strikingly similar: they had the same freckled skin, almond-shaped face, and high cheekbones, unusual among Bengalis, and a slight downward tilt of the outer edge of the eye, something that Italian painters used to make Madonnas exude a mysterious empathy. They shared an inner language, as so often happens with twins; they had jokes that only the other twin understood. They even smelled the same: when I was four or five and Bulu came to visit us, my mother, in a bait-and-switch trick that amused her endlessly, would send her sister to put me to bed; eventually, searching in the half-light for identity and difference—for the precise map of freckles on her face—I would realize that I had been fooled.
But the differences were striking, too. My mother was boisterous. She had a mercurial temper that rose fast and died suddenly, like a gust of wind in a tunnel. Bulu was physically timid yet intellectually more adventurous. Her mind was more agile, her tongue sharper, her wit more lancing. Tulu was gregarious. She made friends easily. She was impervious to insults. Bulu was reserved, quieter, and more brittle. Tulu liked theatre and dancing. Bulu was a poet, a writer, a dreamer.
….. more
Why are identical twins alike? In the late nineteen-seventies, a team of scientists in Minnesota set out to determine how much these similarities arose from genes, rather than environments—from “nature,” rather than “nurture.” Scouring thousands of adoption records and news clips, the researchers gleaned a rare cohort of fifty-six identical twins who had been separated at birth. Reared in different families and different cities, often in vastly dissimilar circumstances, these twins shared only their genomes. Yet on tests designed to measure personality, attitudes, temperaments, and anxieties, they converged astonishingly. Social and political attitudes were powerfully correlated: liberals clustered with liberals, and orthodoxy was twinned with orthodoxy. The same went for religiosity (or its absence), even for the ability to be transported by an aesthetic experience. Two brothers, separated by geographic and economic continents, might be brought to tears by the same Chopin nocturne, as if responding to some subtle, common chord struck by their genomes.
One pair of twins both suffered crippling migraines, owned dogs that they had named Toy, married women named Linda, and had sons named James Allan (although one spelled the middle name with a single “l”). Another pair—one brought up Jewish, in Trinidad, and the other Catholic, in Nazi Germany, where he joined the Hitler Youth—wore blue shirts with epaulets and four pockets, and shared peculiar obsessive behaviors, such as flushing the toilet before using it. Both had invented fake sneezes to diffuse tense moments. Two sisters—separated long before the development of language—had invented the same word to describe the way they scrunched up their noses: “squidging.” Another pair confessed that they had been haunted by nightmares of being suffocated by various metallic objects—doorknobs, fishhooks, and the like.
The Minnesota twin study raised questions about the depth and pervasiveness of qualities specified by genes: Where in the genome, exactly, might one find the locus of recurrent nightmares or of fake sneezes? Yet it provoked an equally puzzling converse question: Why are identical twins different? Because, you might answer, fate impinges differently on their bodies. One twin falls down the crumbling stairs of her Calcutta house and breaks her ankle; the other scalds her thigh on a tipped cup of coffee in a European station. Each acquires the wounds, calluses, and memories of chance and fate. But how are these changes recorded, so that they persist over the years? We know that the genome can manufacture identity; the trickier question is how it gives rise to difference.
….. more
But what turns those genes on and off, and keeps them turned on or off? Why doesn’t a liver cell wake up one morning and find itself transformed into a neuron? Allis unpacked the problem further: suppose he could find an organism with two distinct sets of genes—an active set and an inactive set—between which it regularly toggled. If he could identify the molecular switches that maintain one state, or toggle between the two states, he might be able to identify the mechanism responsible for cellular memory. “What I really needed, then, was a cell with these properties,” he recalled when we spoke at his office a few weeks ago. “Two sets of genes, turned ‘on’ or ‘off’ by some signal.”
more…
“Histones had been known as part of the inner scaffold for DNA for decades,” Allis went on. “But most biologists thought of these proteins merely as packaging, or stuffing, for genes.” When Allis gave scientific seminars in the early nineties, he recalled, skeptics asked him why he was so obsessed with the packing material, the stuff in between the DNA. …. A skein of silk tangled into a ball has very different properties from that same skein extended; might the coiling or uncoiling of DNA change the activity of genes?
In 1996, Allis and his research group deepened this theory with a seminal discovery. “We became interested in the process of histone modification,” he said. “What is the signal that changes the structure of the histone so that DNA can be packed into such radically different states? We finally found a protein that makes a specific chemical change in the histone, possibly forcing the DNA coil to open. And when we studied the properties of this protein it became quite clear that it was also changing the activity of genes.” The coils of DNA seemed to open and close in response to histone modifications—inhaling, exhaling, inhaling, like life.
Allis walked me to his lab, a fluorescent-lit space overlooking the East River, divided by wide, polished-stone benches. A mechanical stirrer, whirring in a corner, clinked on the edge of a glass beaker. “Two features of histone modifications are notable,” Allis said. “First, changing histones can change the activity of a gene without affecting the sequence of the DNA.” It is, in short, formally epi-genetic, just as Waddington had imagined. “And, second, the histone modifications are passed from a parent cell to its daughter cells when cells divide. A cell can thus record ‘memory,’ and not just for itself but for all its daughter cells.”
…..
The New Yorker screws up big time with science: researchers criticize the Mukherjee piece on epigenetics
Abstract: This is a two part-post about a science piece on gene regulation that just appeared in the New Yorker. Today I give quotes from scientists criticizing that piece; tomorrow I’ll present a semi-formal critique of the piece by two experts in the field.
esterday I gave readers an assignment: read the new New Yorkerpiece by Siddhartha Mukherjee about epigenetics. The piece, called “Same but different” (subtitle: “How epigenetics can blur the line between nature and nurture”) was brought to my attention by two readers, both of whom praised it. Mukherjee, a physician, is well known for writing the Pulitzer-Prize-winning book (2011) The Emperor of All Maladies: A Biography of Cancer. (I haven’t read it yet, but it’s on my list.) Mukherjee has a new book that will be published in May: The Gene: An Intimate History. As I haven’t seen it, the New Yorker piece may be an excerpt from this book.
Everyone I know who has read The Emperor of All Maladies gives it high praise. I wish I could say the same for Mukherjee’s New Yorker piece. When I read it at the behest of the two readers, I found his analysis of gene regulation incomplete and superficial. Although I’m not an expert in that area, I knew that there was a lot of evidence that regulatory proteins called “transcription factors”, and not “epigenetic markers” (see discussion of this term tomorrow) or modified histones—the factors emphasized by Mukherjee—played hugely important roles in gene regulation. The speculations at the end of the piece about “Lamarckian evolution” via environmentally induced epigenetic changes in the genome were also unfounded, for we have no evidence for that kind of adaptive evolution. Mukherjee does, however, mention that lack of evidence, though I wish he’d done so more strongly given that environmental modification of DNA bases is constantly touted as an important and neglected factor in evolution.
Unbeknownst to me, there was a bit of a kerfuffle going on in the community of scientists who study gene regulation, with many of them finding serious mistakes and omissions in Mukherjee’s piece. There appears to have been some back-and-forth emailing among them, and several wrote letters to the New Yorker, urging them to correct the misconceptions, omissions, and scientific errors in “Same but different.” As I understand it, both Mukherjee and the New Yorker simply batted these criticisms away, and, as far as I know, will not publish any corrections. So today and tomorrow I’ll present the criticisms here, just so they’ll be on the record.
Because Mukherjee writes very well, and because even educated laypeople won’t know the story of gene regulation revealed over the last few decades, they may not see the big lacunae in his piece. It is, then, important to set matters straight, for at least we should know what science has told us about how genes are turned on and off. The criticism of Mukherjee’s piece, coming from scientists who really are experts in gene regulation, shows a lack of care on the part of Mukherjee and theNew Yorker: both a superficial and misleading treatment of the state of the science, and a failure of the magazine to properly vet this piece (I have no idea whether they had it “refereed” not just by editors but by scientists not mentioned in the piece).
Let me add one thing about science and the New Yorker. I believe I’ve said this before, but the way the New Yorker treats science is symptomatic of the “two cultures” problem. This is summarized in an email sent me a while back by a colleague, which I quote with permission:
The New Yorker is fine with science that either serves a literary purpose (doctors’ portraits of interesting patients) or a political purpose (environmental writing with its implicit critique of modern technology and capitalism). But the subtext of most of its coverage (there are exceptions) is that scientists are just a self-interested tribe with their own narrative and no claim to finding the truth, and that science must concede the supremacy of literary culture when it comes to anything human, and never try to submit human affairs to quantification or consilience with biology. Because the magazine is undoubtedly sophisticated in its writing and editing they don’t flaunt their postmodernism or their literary-intellectual proprietariness, but once you notice it you can make sense of a lot of their material.
. . . Obviously there are exceptions – Atul Gawande is consistently superb – but as soon as you notice it, their guild war on behalf of cultural critics and literary intellectuals against scientists, technologists, and analytic scholars becomes apparent.
…. more
Researchers criticize the Mukherjee piece on epigenetics: Part 2
Trigger warning: Long science post!
Yesterday I provided a bunch of scientists’ reactions—and these were big names in the field of gene regulation—to Siddhartha Mukherjee’s ill-informed piece in The New Yorker, “Same but different” (subtitle: “How epigenetics can blur the line between nature and nurture”). Today, in part 2, I provide a sentence-by-sentence analysis and reaction by two renowned researchers in that area. We’ll start with a set of definitions (provided by the authors) that we need to understand the debate, and then proceed to the critique.
Let me add one thing to avoid confusion: everything below the line, including the definition (except for my one comment at the end) was written by Ptashne and Greally.
by Mark Ptashne and John Greally
Introduction
Ptashne is The Ludwig Professor of Molecular Biology at the Memorial Sloan Kettering Cancer Center in New York. He wrote A Genetic Switch, now in its third edition, which describes the principles of gene regulation and the workings of a ‘switch’; and, with Alex Gann, Genes and Signals, which extends these principles and ideas to higher organisms and to other cellular processes as well. John Greally is the Director of the Center for Epigenomics at the Albert Einstein College of Medicine in New York.
The New Yorker (May 2, 2016) published an article entitled “Same But Different” written by Siddhartha Mukherjee. As readers will have gathered from the letters posted yesterday, there is a concern that the article is misleading, especially for a non-scientific audience. The issue concerns our current understanding of “gene regulation” and how that understanding has been arrived at.
First some definitions/concepts:
Gene regulation refers to the “turning on and off of genes”. The primary event in turning a gene “on” is to transcribe (copy) it into messenger RNA (mRNA). That mRNA is then decoded, usually, into a specific protein. Genes are transcribed by the enzyme called RNA polymerase.
Development: the process in which a fertilized egg (e.g., a human egg) divides many times and eventually forms an organism. During this process, many of the roughly 23,000 genes of a human are turned “on” or “off” in different combinations, at different times and places in the developing organism. The process produces many different cell types in different organs (e.g. liver and brain), but all retain the original set of genes.
Transcription factors: proteins that bind to specific DNA sequences near specific genes and turn transcription of those genes on and off. A transcriptional ‘activator’, for example, bears two surfaces: one binds a specific sequence in DNA, and the other binds to, and thereby recruits to the gene, protein complexes that include RNA polymerase. It is widely acknowledged that the identity of a cell in the body depends on the array of transcription factors present in the cell, and the cell’s history. RNA molecules can also recognize specific genomic sequences, and they too sometimes work as regulators. Neither transcription factors nor these kinds of RNA molecules – the fundamental regulators of gene expression and development – are mentioned in the New Yorker article.
Signals: these come in many forms (small molecules like estrogen, larger molecules (often proteins such as cytokines) that determine the ability of transcription factors to work. For example, estrogen binds directly to a transcription factor (the estrogen receptor) and, by changing its shape, permits it to bind DNA and activate transcription.
“Memory”: a dividing cell can (often does) produce daughters that are identical, and that express identical genes as does the mother cell. This occurs because the transcription factors present in the mother cell are passively transmitted to the daughters as the cell divides, and they go to work in their new contexts as before. To make two different daughters, the cell must distribute its transcription factors asymmetrically.
PositiveFeedback: An activator can maintain its own expression by positive feedback. This requires, simply, that a copy of the DNA sequence to which the activator binds is present near its own gene. Expression of the activator then becomes self-perpetuating. The activator (of which there now are many copies in the cell) activates other target genes as it maintains its own expression. This kind of ‘memory circuit’, first described in bacteria, is found in higher organisms as well. Positive feedback can explain how a fully differentiated cell (that is, a cell that has reached its developmental endpoint) maintains its identity.
Nucleosomes: DNA in higher organisms (eukaryotes) is wrapped, like beads on a string, around certain proteins (called histones), to form nucleosomes. The histones are subject to enzymatic modifications: e.g., acetyl, methyl, phosphate, etc. groups can be added to these structures. In bacteria there are no nucleosomes, and the DNA is more or less ‘naked’.
“Epigenetic modifications”: please don’t worry about the word ”epigenetic”; it is misused in any case. What Mukherjee refers to by this term are the histone modifications mentioned above, and a modification to DNA itself: the addition of methyl groups. Keep in mind that the organisms that have taught us the most about development – flies (Drosophila) and worms (C. elegans)—do not have the enzymes required for DNA methylation. That does not mean that DNA methylation cannot do interesting things in humans, for example, but it is obviously not at the heart of gene regulation.
Specificity Development requires the highly specific sequential turning on and off of sets of genes. Transcription factors and RNA supply this specificity, but enzymes that impart modifications to histones cannot: every nucleosome (and hence every gene) appears the same to the enzyme. Thus such enzymes cannot pick out particular nucleosomes associated with particular genes to modify. Histone modifications might be imagined to convey ‘memory’ as cells divide – but there are no convincing indications that this happens, nor are there molecular models that might explain why they would have the imputed effects.
Analysis and critique of Mukherjee’s article
The picture we have just sketched has taken the combined efforts of many scientists over 50 years to develop. So what, then, is the problem with the New Yorker article?
There are two: first, the picture we have just sketched, emphasizing the primary role of transcription factors and RNA, is absent. Second, that picture is replaced by highly dubious speculations, some of which don’t make sense, and none of which has been shown to work as imagined in the article.
(Quotes from the Mukherjee article are indented and in plain text; they are followed by comments, flush left and in bold, by Ptashne and Greally.)
In 1978, having obtained a Ph.D. in biology at Indiana University, Allis began to tackle a problem that had long troubled geneticists and cell biologists: if all the cells in the body have the same genome, how does one become a nerve cell, say, and another a blood cell, which looks and functions very differently?
The problems referred to were recognized long before 1978. In fact, these were exactly the problems that the great French scientists François Jacob and Jacques Monod took on in the 1950s-60s. In a series of brilliant experiments, Jacob and Monod showed that in bacteria, certain genes encode products that regulate (turn on and off) specific other genes. Those regulatory molecules turned out to be proteins, some of which respond to signals from the environment. Much of the story of modern biology has been figuring out how these proteins – in bacteria and in higher organisms – bind to and regulate specific genes. Of note is that in higher organisms, the regulatory proteins look and act like those in bacteria, despite the fact that eukaryotic DNA is wrapped in nucleosomes whereas bacterial DNA is not. We have also learned that certain RNA molecules can play a regulatory role, a phenomenon made possible by the fact that RNA molecules, like regulatory proteins, can recognize specific genomic sequences.
In the nineteen-forties, Conrad Waddington, an English embryologist, had proposed an ingenious answer: cells acquired their identities just as humans do—by letting nurture (environmental signals) modify nature (genes). For that to happen, Waddington concluded, an additional layer of information must exist within a cell—a layer that hovered, ghostlike, above the genome. This layer would carry the “memory” of the cell, recording its past and establishing its future, marking its identity and its destiny but permitting that identity to be changed, if needed. He termed the phenomenon “epigenetics”—“above genetics.”
This description greatly misrepresents the original concept. Waddington argued that development proceeds not by the loss (or gain) of genes, which would be a “genetic” process, but rather that some genes would be selectively expressed in specific and complex cellular patterns as development proceeds. He referred to this intersection of embryology (then called “epigenesis”) and genetics as “epigenetic”.We now understand that regulatory proteins work in combinations to turn on and off genes, including their own genes, and that sometimes the regulatory proteins respond to signals sent by other cells. It should be emphasized that Waddington never proposed any “ghost-like” layer of additional information hovering above the gene. This is a later misinterpretation of a literal translation of the term epigenetics, with “epi-“ meaning “above/upon” the genetic information encoded in DNA sequence. Unfortunately, this new and pervasive definition encompasses all of transcriptional regulation and is of no practical value.
…..more
By 2000, Allis and his colleagues around the world had identified a gamut of proteins that could modify histones, and so modulate the activity of genes. Other systems, too, that could scratch different kinds of code on the genome were identified (some of these discoveries predating the identification of histone modifications). One involved the addition of a chemical side chain, called a methyl group, to DNA. The methyl groups hang off the DNA string like Christmas ornaments, and specific proteins add and remove the ornaments, in effect “decorating” the genome. The most heavily methylated parts of the genome tend to be dampened in their activity.
It is true that enzymes that modify histones have been found—lots of them. A striking problem is that, after all this time, it is not at all clear what the vast majority of these modifications do. When these enzymatic activities are eliminated by mutation of their active sites (a task substantially easier to accomplish in yeast than in higher organisms) they mostly have little or no effect on transcription. It is not even clear that histones are the biologically relevant substrates of most of these enzymes.
In the ensuing decade, Allis wrote enormous, magisterial papers in which a rich cast of histone-modifying proteins appear and reappear through various roles, mapping out a hatchwork of complexity. . . These protein systems, overlaying information on the genome, interacted with one another, reinforcing or attenuating their signals. Together, they generated the bewildering intricacy necessary for a cell to build a constellation of other cells out of the same genes, and for the cells to add “memories” to their genomes and transmit these memories to their progeny. “There’s an epigenetic code, just like there’s a genetic code,” Allis said. “There are codes to make parts of the genome more active, and codes to make them inactive.”
By ‘epigenetic code’ the author seems to mean specific arrays of nucleosome modifications, imparted over time and cell divisions, marking genes for expression. This idea has been tested in many experiments and has been found not to hold.
….. and more
Larry H. Bernstein, MD, FCAP
I hope that this piece brings greater clarity to the discussion. I have heard the use of the term “epigenetics” for over a decade. The term was never so clear. I think that the New Yorker article was a reasonable article for the intended audience. It was not intended to clarify debates about a mechanism for epigenetic based changes in evolutionary science. I think it actually punctures the “classic model” of the cell depending only on double stranded DNA and transcription, which deflates our concept of the living cell. The concept of epigenetics was never really formulated as far as I have seen, and I have done serious work in enzymology and proteins at a time that we did not have the technology that exists today. I have considered with the critics that protein folding, protein misfolding, protein interactions with proximity of polar and nonpolar groups, and the regulatory role of microRNAs that are not involved in translation, and the evolving concept of what is “dark (noncoding) DNA” lend credence to the complexity of this discussion. Even more interesting is the fact that enzymes (and isoforms of enzymes) have a huge role in cellular metabolic differences and in the function of metabolic pathways. What is less understood is the extremely fast reactions involved in these cellular reactions. These reactions are in my view critical drivers. This is brought out by Erwin Schroedinger in the book What is Life? which infers that there can be no mathematical expression of life processes.
hysical chemists have devised a rolling DNA-based motor that’s 1,000 times faster than any other synthetic DNA motor, giving it potential for real-world applications, such as disease diagnostics. Nature Nanotechnology is publishing the finding.
“Unlike other synthetic DNA-based motors, which use legs to ‘walk’ like tiny robots, ours is the first rolling DNA motor, making it far faster and more robust,” says Khalid Salaita, the Emory University chemist who led the research. “It’s like the biological equivalent of the invention of the wheel for the field of DNA machines.”
The speed of the new DNA-based motor, which is powered by ribonuclease H, means a simple smart phone microscope can capture its motion through video. The researchers have filed an invention disclosure patent for the concept of using the particle motion of their rolling molecular motor as a sensor for everything from a single DNA mutation in a biological sample to heavy metals in water.
“Our method offers a way of doing low-cost, low-tech diagnostics in settings with limited resources,” Salaita says.
The field of synthetic DNA-based motors, also known as nano-walkers, is about 15 years old. Researchers are striving to duplicate the action of nature’s nano-walkers. Myosin, for example, are tiny biological mechanisms that “walk” on filaments to carry nutrients throughout the human body.
“It’s the ultimate in science fiction,” Salaita says of the quest to create tiny robots, or nano-bots, that could be programmed to do your bidding. “People have dreamed of sending in nano-bots to deliver drugs or to repair problems in the human body.”
So far, however, mankind’s efforts have fallen far short of nature’s myosin, which speeds effortlessly about its biological errands. “The ability of myosin to convert chemical energy into mechanical energy is astounding,” Salaita says. “They are the most efficient motors we know of today.”
Some synthetic nano-walkers move on two legs. They are essentially enzymes made of DNA, powered by the catalyst RNA. These nano-walkers tend to be extremely unstable, due to the high levels of Brownian motion at the nano-scale. Other versions with four, and even six, legs have proved more stable, but much slower. In fact, their pace is glacial: A four-legged DNA-based motor would need about 20 years to move one centimeter.
Kevin Yehl, a post-doctoral fellow in the Salaita lab, had the idea of constructing a DNA-based motor using a micron-sized glass sphere. Hundreds of DNA strands, or “legs,” are allowed to bind to the sphere. These DNA legs are placed on a glass slide coated with the reactant: RNA.
The DNA legs are drawn to the RNA, but as soon as they set foot on it they destroy it through the activity of an enzyme called RNase H. As the legs bind and then release from the substrate, they guide the sphere along, allowing more of the DNA legs to keep binding and pulling.
“It’s called a burnt-bridge mechanism,” Salaita explains. “Wherever the DNA legs step, they trample and destroy the reactant. They have to keep moving and step where they haven’t stepped in order to find more reactant.”
The combination of the rolling motion, and the speed of the RNase H enzyme on a substrate, gives the new DNA motor its stability and speed.
“Our DNA-based motor can travel one centimeter in seven days, instead of 20 years, making it 1,000 times faster than the older versions,” Salaita says. “In fact, nature’s myosin motors are only 10 times faster than ours, and it took them billions of years to evolve.”
Emory post-doctoral fellow Kevin Yehl sets up a smart-phone microscope to get a readout for the particle motion of the rolling DNA-based motor.
The researchers demonstrated that their rolling motors can be used to detect a single DNA mutation by measuring particle displacement. They simply glued lenses from two inexpensive laser pointers to the camera of a smart phone to turn the phone into a microscope and capture videos of the particle motion.
“Using a smart phone, we can get a readout for anything that’s interfering with the enzyme-substrate reaction, because that will change the speed of the particle,” Salaita says. “For instance, we can detect a single mutation in a DNA strand.”
This simple, low-tech method could come in handy for doing diagnostic sensing of biological samples in the field, or anywhere with limited resources.
The proof that the motors roll came by accident, Salaita adds. During their experiments, two of the glass spheres occasionally became stuck together, or dimerized. Instead of making a wandering trail, they left a pair of straight, parallel tracks across the substrate, like a lawn mower cutting grass. “It’s the first example of a synthetic molecular motor that goes in a straight line without a track or a magnetic field to guide it,” Salaita says.
In addition to Salaita and Yehl, the co-authors on the Nature Nanotechnology paper include Emory researchers Skanda Vivek, Yang Liu, Yun Zhang, Megzhen Fan, Eric Weeks and Andrew Mugler (who is now at Purdue University).
DNA-based machines that walk by converting chemical energy into controlled motion could be of use in applications such as next-generation sensors, drug-delivery platforms and biological computing. Despite their exquisite programmability, DNA-based walkers are challenging to work with because of their low fidelity and slow rates (∼1 nm min–1). Here we report DNA-based machines that roll rather than walk, and consequently have a maximum speed and processivity that is three orders of magnitude greater than the maximum for conventional DNA motors. The motors are made from DNA-coated spherical particles that hybridize to a surface modified with complementary RNA; the motion is achieved through the addition of RNase H, which selectively hydrolyses the hybridized RNA. The spherical motors can move in a self-avoiding manner, and anisotropic particles, such as dimerized or rod-shaped particles, can travel linearly without a track or external force. We also show that the motors can be used to detect single nucleotide polymorphism by measuring particle displacement using a smartphone camera.
A 3-D rendering of a fluorescence image mapping the piconewton forces applied by T cells. The height and color indicates the magnitude of the applied force. (Microscopy image by Yang Liu.)
By Carol Clark
T cells, the security guards of the immune system, use a kind of mechanical “handshake” to test whether a cell they encounter is a friend or foe, a new study finds.
“We’ve provided the first direct evidence that a T cell gives precise mechanical tugs to other cells,” Salaita says. “And we’ve shown that these tugs are central to a T cell’s process of deciding whether to mount an immune response. A tug that releases easily, similar to a casual handshake, signals a friend. A stronger grip indicates a foe.”
T cells continuously patrol through the body in search of foreign invaders. They have molecules known as T-cell receptors (TCR) that can recognize specific antigenic peptides on the surface of a pathogenic or cancerous cell. When a T cell detects an antigen-presenting cell (APC), its TCR connects to a ligand, or binding molecule, of the APC. If the T cell determines the ligand is foreign, it becomes activated and starts pumping calcium. The calcium is part of a signaling chain that recruits other cells to come and help mount an immune response.
Scientists have known about this process for decades, but they have not fully understood how the T cell distinguishes small modifications to the antigenic ligand and how it decides to respond to it. “If you view this T cell response purely as a chemical process, it does not fully explain the remarkable specifity of the binding,” Salaita says. “When you take the two components – the TCR and the ligand on the surface of cells – and just let them chemically bind in a solution, for example, you can’t predict what will trigger a strong or a weak immune response.”
The researchers hypothesized that mechanical strain might also play a role in a T cell response, since the T cell continues to move even as it locks into a bind with an antigenic ligand.
To test this idea, the Salaita lab developed DNA-based gold nanoparticle tension sensors that light up, or fluoresce, in response to a miniscule mechanical force of a piconewton – about one million-millionth the weight of an apple.
The researchers designed experiments using T cells from a mouse and allowed them to test ligands containing eight amino acid peptides that had slight mutations.
“We swapped out the fourth amino acid position to create really subtle chemical changes in the ligand that would be very difficult to distinguish without a mechanical component,” Salaita says.
Some of the mutated ligands were given a firmer anchor to give them a tighter “grip” to the moving TCR.
Through the experiments, captured on microscopy video, the researchers were able to see, record and measure the responses of the T cells as they moved across the ligands.
“As a T cell moves across a cell’s surface and encounters a ligand, it pulls on it,” Salaita explains. “It doesn’t pull very hard, it’s a very precise and tiny tug that is not sustained. The T cell pulls and stops, pulls and stops, all across the surface. It’s like the T cell is doing a mechanical test of the ligand.”
During the experiments, the T cells did not activate fully when they encountered ligands with weak anchors. In contrast, when a T cell encountered a ligand with a firm anchor, the T cell became activated, showing that it experienced a piconewton level of resistance.
The amount of force that was applied by the T cell was mapped by using tension probes of different stiffness. Probes that responded to 19 piconewtons did not fluoresce, while softer, 12-piconewton probes produced high signal.
Following the fluorescence of the probe, the T cells switched on their calcium pumps and increased the calcium concentration within the cell, indicating that the T cell is mounting an immune response.
“We were able to map out the order of the cascade of chemical and mechanical reactions,” Salaita says. “First, the T cell uses a very specific and finely tuned mechanical tug to distinguish friend from foe. And when it senses a precise, piconewton level of force in response to that tug, the T cell realizes that it has encountered a foreign body and gives the signal for attack.”
The discovery could help in the search for treatments of auto-immune diseases and the development of immune therapies for cancer.
“Cancer cells have an extra molecule that can make T cell security guards ‘drunk’ or ‘sleepy’ so that they are not able to function properly,” Salaita says. “Learning more about the mechanical forces involved in an effective immune response may help us develop ways to evade this defense system of cancer cells.”
Co-authors on the study include Yang Liu, Victor Pui-Yan Ma, Kornelia Galior and Zheng Liu (from the Salaita lab); and Lori Blanchfield and Rakieb Andargachew (from the Evavold lab).
T cells protect the body against pathogens and cancer by recognizing specific foreign peptides on the cell surface. Because antigen recognition occurs at the junction between a migrating T cell and an antigen-presenting cell (APC), it is likely that cellular forces are generated and transmitted through T-cell receptor (TCR)-ligand bonds. Here we develop a DNA-based nanoparticle tension sensor producing the first molecular maps of TCR-ligand forces during T cell activation. We find that TCR forces are orchestrated in space and time, requiring the participation of CD8 coreceptor and adhesion molecules. Loss or damping of TCR forces results in weakened antigen discrimination, showing that T cells harness mechanics to optimize the specificity of response to ligand.
T cells are triggered when the T-cell receptor (TCR) encounters its antigenic ligand, the peptide-major histocompatibility complex (pMHC), on the surface of antigen presenting cells (APCs). Because T cells are highly migratory and antigen recognition occurs at an intermembrane junction where the T cell physically contacts the APC, there are long-standing questions of whether T cells transmit defined forces to their TCR complex and whether chemomechanical coupling influences immune function. Here we develop DNA-based gold nanoparticle tension sensors to provide, to our knowledge, the first pN tension maps of individual TCR-pMHC complexes during T-cell activation. We show that naïve T cells harness cytoskeletal coupling to transmit 12–19 pN of force to their TCRs within seconds of ligand binding and preceding initial calcium signaling. CD8 coreceptor binding and lymphocyte-specific kinase signaling are required for antigen-mediated cell spreading and force generation. Lymphocyte function-associated antigen 1 (LFA-1) mediated adhesion modulates TCR-pMHC tension by intensifying its magnitude to values >19 pN and spatially reorganizes the location of TCR forces to the kinapse, the zone located at the trailing edge of migrating T cells, thus demonstrating chemomechanical crosstalk between TCR and LFA-1 receptor signaling. Finally, T cells display a dampened and poorly specific response to antigen agonists when TCR forces are chemically abolished or physically “filtered” to a level below ∼12 pN using mechanically labile DNA tethers. Therefore, we conclude that T cells tune TCR mechanics with pN resolution to create a checkpoint of agonist quality necessary for specific immune response.
Andrej Kosmrlj et al., Proc Natl Acad Sci U S A, 2008
Larry H. Bernstein, MD, FCAP, Curator
LPBI
The two articles above are connected in an interesting way by the fact that cellular forces are generated and transmitted through T-cell receptor (TCR)-ligand bonds. The T-cell receptor (TCR) encounters its antigenic ligand, the peptide-major histocompatibility complex (pMHC), on the surface of antigen presenting cells (APCs). The movement detected by the fluorescent sensor may be based on only a single amino acid at the cell surface ligand. The result is chemomechanical crosstalk between TCR and LFA-1 receptor signaling
This illustration depicts an experiment at SLAC that revealed how a protein from photosynthetic bacteria changes shape in response to light in less than a trillionth of a second. (Credit: SLAC National Accelerator Laboratory)
For the variety of Earth’s fauna and flora, sunlight provides nutrients essential for life.
“Converting light from the sun into energy is what keeps us alive,” Sébastien Boutet, a senior staff scientist at SLAC National Accelerator Laboratory’s Linac Coherent Light Source (LCLS), toldR&D Magazine.
While scientists know biomolecules harness light to carry out important biological processes, it’s difficult to capture these reactions on the atomic and molecular levels because they occur so quickly.
Boutet, along with a team of international researchers, used the LCLS’ powerful x-ray laser to capture such a reaction at speeds hitherto unattainable.
“We’re trying to see ultrafast reactions” and “the x-ray source that we have here is very unique,” said Boutet, who took a job at LCLS about nine years ago to develop the beam line used in the experiment.
In their study, which was published recently in Science, the team zeroed in on a light-sensitive part of a protein called photoactive yellow protein (PYP). According to SLAC, it functions as a proverbial eye in purple bacteria, allowing the organism to detect blue light and stay away from potentially harmful light.
According to Marius Schmidt, the study’s principal investigator from the University of Wisconsin, Milwaukee, the team is the first to capture real-time snapshots of an ultrafast structure transition, during which a “molecule excited by light relaxed by rearranging its structure in what is known as trans-to-cisisomerization.”
Previously, researchers had studied this PYP at atomic motions as fast as 10 billionths of a second. But with a few tweaks, they were able to glimpse the reaction 1,000 times faster than before.
It was known what was happening at the nanosecond timescale, said Boutet. But now, there’s a window into in the picosecond and sub-picosecond timescale.
During the experiment, the researchers sent a stream of PYP crystals inside a sample chamber, according to SLAC. Then, Boutet explained, they shot the crystals with laser light to start a reaction, then used an x-ray beam to see the reaction.
“Since LCLS’s x-ray pulses are extremely short, lasting only a few quadrillionths of a second, they can in principle probe processes on that very timescale … if the optical laser also matches the tremendous speed,” according to SLAC.
“These types of tools are the way to understand at the atomic and molecular level these reactions that are really essential to life,” said Boutet. “Photosynthesis is the poster child for this. If we could understand this better, we could potentially build better artificial energy conversion using the sun.”
Additionally, this technology could reveal how the human eye’s visual pigments respond to light, helping researchers understand just how excessive absorption damages the human eye.
“The techniques that we use to understand energy conversion is one of the things that LCLS is very useful for,” Boutet concluded.
Femtosecond structural dynamics drives the trans/cis isomerization in photoactive yellow protein
Kanupriya Pande1,2, Christopher D. M. Hutchison3, Gerrit Groenhof4, Andy Aquila5, Josef S. Robinson5, Jason Tenboer1, Shibom Basu6, Sébastien Boutet5, et al.
Science 06 May 2016; 352(6286):725-729 http://dx.doi.org:/10.1126/science.aad5081
Visualizing a response to light
Many biological processes depend on detecting and responding to light. The response is often mediated by a structural change in a protein that begins when absorption of a photon causes isomerization of a chromophore bound to the protein. Pande et al. used x-ray pulses emitted by a free electron laser source to conduct time-resolved serial femtosecond crystallography in the time range of 100 fs to 3 ms. This allowed for the real-time tracking of the trans-cis isomerization of the chromophore in photoactive yellow protein and the associated structural changes in the protein.
A variety of organisms have evolved mechanisms to detect and respond to light, in which the response is mediated by protein structural changes after photon absorption. The initial step is often the photoisomerization of a conjugated chromophore. Isomerization occurs on ultrafast time scales and is substantially influenced by the chromophore environment. Here we identify structural changes associated with the earliest steps in the trans-to-cis isomerization of the chromophore in photoactive yellow protein. Femtosecond hard x-ray pulses emitted by the Linac Coherent Light Source were used to conduct time-resolved serial femtosecond crystallography on photoactive yellow protein microcrystals over a time range from 100 femtoseconds to 3 picoseconds to determine the structural dynamics of the photoisomerization reaction.
Pinchas Cohen led a team that identified tiny proteins that appear to play a role in controlling how the body ages. (Photo/Beth Newcomb)
A group of six newly discovered proteins may help to divulge secrets of how we age, potentially unlocking insights into diabetes, Alzheimer’s, cancer and other aging-related diseases.
The tiny proteins appear to play several big roles in our bodies’ cells, from decreasing the amount of damaging free radicals and controlling the rate at which cells die to boosting metabolism and helping tissues throughout the body respond better to insulin. The naturally occurring amounts of each protein decrease with age, leading researchers to believe that they play an important role in the aging process and the onset of diseases linked to older age.
The research team led by Pinchas Cohen, dean of the USC Davis School of Gerontology, identified the tiny proteins for the first time and observed their surprising origin from organelles in the cell called mitochondria and their game-changing roles in metabolism and cell survival. This latest finding builds upon prior research by Cohen and his team that uncovered two significant proteins, humanin and MOTS-c, hormones that appear to have significant roles in metabolism and diseases of aging.
Unlike most other proteins, humanin and MOTS-c are encoded in mitochondria, the structure within cells that produces energy from food, instead of in the cell’s nucleus where most genes are contained.
Key functions
Mitochondria have their own small collection of genes, which were once thought to play only minor roles within cells but now appear to have important functions throughout the body. Cohen’s team used computer analysis to see if the part of the mitochondrial genome that provides the code for humanin was coding for other proteins as well. The analysis uncovered the genes for six new proteins, which were dubbed small humanin-like peptides, or SHLPs, 1 through 6 (the name of this hardworking group of proteins is appropriately pronounced “schlep”).
After identifying the six SHLPs and successfully developing antibodies to test for several of them, the team examined both mouse tissues and human cells to determine their abundance in different organs as well as their functions. The proteins were distributed quite differently among organs, which suggests that the proteins have varying functions based on where they are in the body.
Of particular interest is SHLP 2, Cohen said. The protein appears to have profound insulin-sensitizing, anti-diabetic effects as well as potent neuro-protective activity that may emerge as a strategy to combat Alzheimer’s disease. He added that SHLP 6 is also intriguing, with a unique ability to promote cancer cell death and thus potentially target malignant diseases.
“Together with the previously identified mitochondrial peptides, the newly recognized SHLP family expands the understanding of the mitochondria as an intracellular signaling organelle that communicates with the rest of the body to regulate metabolism and cell fate,” Cohen said. “The findings are an important advance that will be ripe for rapid translation into drug development for diseases of aging.”
The study first appeared online in the journal Aging on April 10. Cohen’s research team included collaborators from the Albert Einstein College of Medicine; the findings have been licensed to the biotechnology company CohBar for possible drug development.
The research was supported by a Glenn Foundation Award and National Institutes of Health grants to Cohen (1P01AG034906, 1R01AG 034430, 1R01GM 090311, 1R01ES 020812) and an Ellison/AFAR postdoctoral fellowship to Kelvin Yen. Study authors Laura Cobb, Changhan Lee, Nir Barzilai and Pinchas Cohen are consultants and stockholders of CohBar Inc.
On a blazingly hot morning this past June, a half-dozen scientists convened in a hotel conference room in suburban Maryland for the dress rehearsal of what they saw as a landmark event in the history of aging research. In a few hours, the group would meet with officials at the U.S. Food and Drug Administration (FDA), a few kilometers away, to pitch an unprecedented clinical trial—nothing less than the first test of a drug to specifically target the process of human aging.
“We think this is a groundbreaking, perhaps paradigm-shifting trial,” said Steven Austad, chairman of biology at the University of Alabama, Birmingham, and scientific director of the American Federation for Aging Research (AFAR). After Austad’s brief introductory remarks, a scientist named Nir Barzilai tuned up his PowerPoint and launched into a practice run of the main presentation.
Barzilai is a former Israeli army medical officer and head of a well-known study of centenarians based at the Albert Einstein College of Medicine in the Bronx, New York. To anyone who has seen the ebullient scientist in his natural laboratory habitat, often in a short-sleeved shirt and always cracking jokes, he looked uncharacteristically kempt in a blue blazer and dress khakis. But his practice run kept hitting a historical speed bump. He had barely begun to explain the rationale for the trial when he mentioned, in passing, “lots of unproven, untested treatments under the category of anti-aging.” His colleagues pounced.
“Nir,” interrupted S. Jay Olshansky, a biodemographer of aging from the University of Illinois, Chicago. The phrase “anti-aging … has an association that is negative.”
“I wouldn’t dignify them by calling them ‘treatments,’” added Michael Pollak, director of cancer prevention at McGill University in Montreal, Canada. “They’re products.”
Barzilai, a 59-year-old with a boyish mop of gray hair, wore a contrite grin. “We know the FDA is concerned about this,” he conceded, and deleted the offensive phrase.
Then he proceeded to lay out the details of an ambitious clinical trial. The group—academics all—wanted to conduct a double-blind study of roughly 3000 elderly people; half would get a placebo and half would get an old (indeed, ancient) drug for type 2 diabetes called metformin, which has been shown to modify aging in some animal studies. Because there is still no accepted biomarker for aging, the drug’s success would be judged by an unusual standard—whether it could delay the development of several diseases whose incidence increases dramatically with age: cardiovascular disease, cancer, and cognitive decline, along with mortality. When it comes to these diseases, Barzilai is fond of saying, “aging is a bigger risk factor than all of the other factors combined.”
But the phrase “anti-aging” kept creeping into the rehearsal, and critics kept jumping in. “Okay,” Barzilai said with a laugh when it came up again. “Third time, the death penalty.”
The group’s paranoia about the term “anti-aging” captured both the audacity of the proposed trial and the cultural challenge of venturing into medical territory historically associated with charlatans and quacks. The metformin initiative, which Barzilai is generally credited with spearheading, is unusual by almost any standard of drug development. The people pushing for the trial are all academics, none from industry (although Barzilai is co-founder of a biotech company, CohBar Inc., that is working to develop drugs targeting age-related diseases). The trial would be sponsored by the nonprofit AFAR, not a pharmaceutical company. No one stood to make money if the drug worked, the scientists all claimed; indeed, metformin is not only generic, costing just a few cents a dose, but belongs to a class of drugs that has been part of the human apothecary for 500 years. Patient safety was unlikely to be an issue; millions of diabetics have taken metformin since the 1960s, and its generally mild side effects are well-known.
Finally, the metformin group insisted they didn’t need a cent of federal money to proceed (although they do intend to ask for some). Nor did they need formal approval from FDA to proceed. But they very much wanted the agency’s blessing. By recognizing the merit of such a trial, Barzilai believes, FDA would make aging itself a legitimate target for drug development.
By the time the scientists were done, the rehearsal—which was being filmed for a television documentary—had the feel of a pep rally. They spoke with unguarded optimism. “What we’re talking about here,” Olshansky said, “is a fundamental sea change in how we look at aging and disease.” To Austad, it is “the key, potentially, to saving the health care system.”
As the group piled into a van for the drive to FDA headquarters, there was more talk about setting precedents and opening doors. So it was a little disconcerting when Austad led the delegation up to the main entrance of FDA—and couldn’t get the door open. ……
Mitochondrial Peptides Found in a Preclinical Study Seen to Control Cell Metabolism
CohBar, a developer of mitochondria-based therapeutics, announced that preclinical research by its academic collaborators has found small humanin-like peptides (SHLPs) that can control metabolism and cell survival. The findings have implications for age-related diseases such as Alzheimer’s and cancer.
Researchers discovered the SHLPs by examining the genome of mitochondria with the help of a bioinformatics approach, which identified six peptides. The team then verified the presence of the factors and explored their function in laboratory animals.
CohBar, who have the exclusive license to develop SHLPs into therapeutics, works closely with its academic partners to explore the peptides in preclinical models.
While it was previously believed that mitochondria only have 37 genes, research has revealed that the mitochondrial genome is far more versatile, potentially harboring a multitude of new genes, which can encode peptides acting as cellular signaling factors. The peptides, it has turned out, have shown neuroprotective and anti-inflammatory effects, and act to protect cells in disease-modifying ways in preclinical models of aging.
CohBar’s goal is to bring these peptides to the market as therapies for age-related diseases, such as obesity, type 2 diabetes, cancer, atherosclerosis and neurodegenerative disorders.
“Together with the previously described mitochondrial-derived peptides humanin and MOTS-c, the SHLP family expands our understanding of the role that these peptides play in intracellular signaling throughout the body to regulate both metabolism and cell survival,” Pinchas Cohen, dean of the USC Leonard Davis School of Gerontology, founder and director of CohBar, and the study’s senior author, said in a press release. “These findings further illustrate the enormous potential that mitochondria-based therapeutics could have on treating age-associated diseases like Alzheimer’s and cancer.”
“The pre-clinical evidence continues to confirm that these peptides represent a new class of naturally occurring metabolic regulators,” added Simon Allen, CohBar’s CEO. “They form the foundation of our pipeline of first-in-class treatments for age-related diseases, and we are committed to rapidly advancing them through pre-clinical and clinical activities as we move forward.”
Naturally occurring mitochondrial-derived peptides are age-dependent regulators of apoptosis, insulin sensitivity, and inflammatory markers
Laura J. Cobb1,5, Changhan Lee2, Jialin Xiao2, Kelvin Yen2, Richard G. Wong2, Hiromi K. Nakamura1, ….., Derek M. Huffman4, Junxiang Wan2, Radhika Muzumdar3, Nir Barzilai4 , and Pinchas Cohen2 http://www.impactaging.com/papers/v8/n4/full/100943.html
Mitochondria are key players in aging and in the pathogenesis of age-related diseases. Recent mitochondrial transcriptome analyses revealed the existence of multiple small mRNAs transcribed from mitochondrial DNA (mtDNA). Humanin (HN), a peptide encoded in the mtDNA 16S ribosomal RNA region, is a neuroprotective factor. An in silico search revealed six additional peptides in the same region of mtDNA as humanin; we named these peptides small humanin-like peptides (SHLPs). We identified the functional roles for these peptides and the potential mechanisms of action. The SHLPs differed in their ability to regulate cell viability in vitro. We focused on SHLP2 and SHLP3 because they shared similar protective effects with HN. Specifically, they significantly reduced apoptosis and the generation of reactive oxygen species, and improved mitochondrial metabolism in vitro. SHLP2 and SHLP3 also enhanced 3T3-L1 pre-adipocyte differentiation. Systemic hyperinsulinemic-euglycemic clamp studies showed that intracerebrally infused SHLP2 increased glucose uptake and suppressed hepatic glucose production, suggesting that it functions as an insulin sensitizer both peripherally and centrally. Similar to HN, the levels of circulating SHLP2 were found to decrease with age. These results suggest that mitochondria play critical roles in metabolism and survival through the synthesis of mitochondrial peptides, and provide new insights into mitochondrial biology with relevance to aging and human biology.
Human mitochondrial DNA (mtDNA) is a double-stranded, circular molecule of 16,569 bp and contains 37 genes encoding 13 proteins, 22 tRNAs, and 2 rRNAs. Recent mitochondrial transcriptome analyses revealed the existence of small RNAs derived from mtDNA [1]. In 2001, Nishimoto and colleagues identified humanin (HN), a 24-amino-acid peptide encoded from the 16S ribosomal RNA (rRNA) region of mtDNA. HN is a potent neuroprotective factor capable of antagonizing Alzheimer’s disease (AD)-related cellular insults [2]. HN is a component of a novel retrograde signaling pathway from the mitochondria to the nucleus, which is distinct from mitochondrial signaling pathways, such as the SIRT4-AMPK pathway [3]. HN-dependent cellular protection is mediated in part by interacting with and antagonizing pro-apoptotic Bax-related peptides [4] and IGFBP-3 (IGF binding protein 3) [5].
Because of their involvement in energy production and free radical generation, mitochondria likely play a major role in aging and age-related diseases [6–8]. In fact, improvement of mitochondrial function has been shown to ameliorate age-related memory loss in aged mice [9]. Recent studies have shown that HN levels decrease with age, suggesting that HN could play a role in aging and age-related diseases, such as Alzheimer’s disease (AD), atherosclerosis, and diabetes. Along with lower HN levels in the hypothalamus, skeletal muscle, and cortex of older rodents, the circulating levels of HN were found to decline with age in both humans and mice [10]. Notably, circulating HN levels were found to be (i) significantly higher in long-lived Ames dwarf mice but lower in short-lived growth hormone (GH) transgenic mice, (ii) significantly higher in a GH-deficient cohort of patients with Laron syndrome, and (iii) reduced in mice and humans treated with GH or IGF-1 (insulin-like growth factor 1) [11]. Age-dependent declines in the circulating HN levels may be due to higher levels of reactive oxygen species (ROS) that contribute to atherosclerosis development. Using mouse models of atherosclerosis, it was found that HN-treated mice had a reduced disease burden and significant health improvements [12,13]. In addition, HN improved insulin sensitivity, suggesting clinical potential for mitochondrial peptides in diseases of aging [10]. The discovery of HN represents a unique addition to the spectrum of roles that mitochondria play in the cell [14,15]. A second mitochondrial-derived peptide (MDP), MOTS-c (mitochondrial open reading frame of the 12S rRNA-c), has also been shown to have metabolic effects on muscle and may also play a role in aging [16].
We further investigated mtDNA for the presence of other MDPs. Recent technological advances have led to the identification of small open reading frames (sORFs) in the nuclear genomes ofDrosophila[17,18] and mammals [19,20]. Therefore, we attempted to identify novel sORFs using the following approaches: 1) in silico identification of potential sORFs; 2) determination of mRNA expression levels; 3) development of specific antibodies against these novel peptides to allow for peptide detection in cells, organs, and plasma; 4) elucidating the actions of these peptides by performing cell-based assays for mitochondrial function, signaling, viability, and differentiation; and 5) delivering these peptides in vivo to determine their systemic metabolic effects. Focusing on the 16S rRNA region of the mtDNA where the humanin gene is located, we identified six sORFs and named them small humanin-like peptides (SHLPs) 1-6. While surveying the biological effects of SHLPs, we found that SHLP2 and SHLP3 were cytoprotective; therefore, we investigated their effects on apoptosis and metabolism in greater detail. Further, we showed that circulating SHLP2 levels declined with age, similar to HN, suggesting that SHLP2 is involved in aging and age-related disease progression.
SHLP2 and SHLP3 regulate the expression of metabolic and inflammatory markers
Epidemiological studies have demonstrated that increased levels of mediators of inflammation and acute-phase reactants, such as fibrinogen, C-reactive protein (CRP), and IL-6, correlate with the incidence of type 2 diabetes mellitus (T2DM) [34–36]. In humans, anti-inflammatory drugs, such as aspirin and sodium salicylate, reduce fasting plasma glucose levels and ameliorate the symptoms of T2DM. In addition, anti-diabetic drugs, such as fibrates [37] and thiazolidinediones [38], have been found to lower some markers of inflammation. SHLP2 increased the levels of leptin, which is known to improve insulin sensitivity, but had no effect on the levels of the pro-inflammatory cytokines IL-6 and MCP-1. SHLP3 significantly increased the leptin levels, but also elevated IL-6 and MCP-1 levels, which could explain the lack of an in vivo insulin-sensitizing effect of SHLP3. The mechanism by which SHLPs regulate the expression of metabolic and inflammatory markers remains unclear and needs to be further investigated. Furthermore, SHLPs have different effects on inflammatory marker expression, suggesting differential regulation and function of individual SHLPs.
SHLP2 in aging
Mitochondria have been implicated in increased lifespan in several life-extending treatments [39,40]; however, it is not known whether the relationship is correlative or causative [40]. Additionally, it is well known that hormone levels change with aging. For example, levels of aldosterone, calcitonin, growth hormone, and IGF-I decrease with age. Circulating HN levels decline with age in humans and rodents, specifically in the hypothalamus and skeletal muscle of older rats. These changes parallel increases in the incidence of age-associated diseases such as AD and T2DM. The decline in circulating SHLP2 levels with age (Fig. 6), the anti-oxidative stress function of SHLP2 (Fig. 3C), and its neuroprotective effect (Fig. 6B) indicate that SHLP2 has a role in the regulation of aging and age-related diseases.
Conclusion
By analyzing the mitochondrial transcriptome, we found that sORFs from mitochondrial DNA encode functional peptides. We identified many mRNA transcripts within 13 protein-coding mitochondrial genes [1]. Such previously underappreciated sORFs have also been described in the nuclear genome [41]. The MDPs we describe here may represent retrograde communication signals from the mitochondria to the nucleus and may explain important aspects of mitochondrial biology that are implicated in health and longevity.
Larry, John Walker is working on mt proteins dynamics. His rotor – stator mechanism in ATPase synthase, a ‘complex’ that biologist accepted as energy generator is likely wrong. I was suppose to have met him in Germany few years ago. Energy in biological systems has nothing to do with heat. Heat is an outcome of a reaction, meaning that IR spectra accordingly to wave theory is a source of information memorized in water interference with carbon open systems within protein and glyo-proteins complexes as well as genome space-time outcomes. Physically speaking from a pure perspective of science ATP is highly unstable form of phosphate ‘chains’. It cannot hold energy, it is actually in contrary, it is like a resonator, trapping negativity, thus functioning as space propeller by expanding carbon skeleton of protein ‘machines’ Now, we don’t know what is ‘aging’ in a pure physical sense, except that we observe structural changes in what we call complexes. We we know is that proteins are not stationary structures, but highly dynamic forms of matter, seemingly occupying discrete and relative spaces. A piece of mt ATP ase could be discovered in the nucleus as transcription factor. Our notion of operational space in terms of electro dynamics from a motor – stator perspective is now translated toward defining semi conducting and supracoductive strings. The reality of which is so much more fascinating and beautiful as time progresses overally. There are spaces where time does not change, and there are spaces where time walks, and there are spaces, where time flies, and there are spaces where time runs. Amazing, indeed! The story of aging gets a lot deeper that science could even imagine, probably to roots of immortal energy- spaces. We know that matter is transient, that is nearly all living matter, replenishes of about 3 to 7 weeks.
Take a glass full of some kind of liquid, you know the mass of the glass and the mass of the liquid (say wine, beer, water, or milk) You also know to an approximate reality the composition of both. Now lift the glass full of liquid and let it break on a surface of your choice. Depending on the surface pieces of the glass would travel differential from a center projected by the vertical axis of your hand. What technology does today is recollecting those pieces and modelling them to fit in a form again that would resemble a holding device, a glass. The liquid we don’t know exactly how it spilled due the nature of its absorbancy of both surface physics and physical ‘state’ properties. Thus we can say how much approximate energy we have held thinking of m/z as time flight objectives. Each technology can read 1D and approximate the 2D, absolutely lacking computational methodology for 3D dynamic reality. Many scientists confuse space and volume. Volume is a one dimensional characteristic! So is crystalography! BY taking quantum chemical method computing principles following imaginative rules we could approach 2D, however , that is not enough to define 3D. Time we use as a reference frame of clocks we have invented in order to keep track of a sense to observable ‘change’ . But remember, time is absolute and parallel in continuity while energy is discrete , coming in quantum packages, realization of accumulated information. Information is highly redundant we see, so annotating information is an objective to modern days simulations that could predict outcomes of possible parallel realities we call worlds. One could ‘jump’ from one reality to another through guidance of light and water, but what remains unsolved is why people make mistakes, constantly by accusing in name of greed and power , or disobedience of commandments of the Lord!
On Thu, Apr 21, 2016 at 3:41 AM, Leaders in Pharmaceutical Business Intelligence (LPBI) Group wrote:
> larryhbern posted: “New Insights into mtDNA, mitochondrial proteins, > aging, and metabolic control Larry H. Bernstein, MD, FCAP, Curator LPBI > Newly discovered proteins may protect against age-related illnesses The > proteins could play a key role in the ” >
Metabolic features of the cell danger response
– Mitochondria in Health and Disease
The Cell Danger Response (CDR) is defined in terms of an ancient metabolic response to threat.
The CDR encompasses inflammation, innate immunity, oxidative stress, and the ER stress response.
The CDR is maintained by extracellular nucleotide (purinergic) signaling.
Abnormal persistence of the CDR lies at the heart of many chronic diseases.
Antipurinergic therapy (APT) has proven effective in many chronic disorders in animal models
The cell danger response (CDR) is the evolutionarily conserved metabolic response that protects cells and hosts from harm. It is triggered by encounters with chemical, physical, or biological threats that exceed the cellular capacity for homeostasis. The resulting metabolic mismatch between available resources and functional capacity produces a cascade of changes in cellular electron flow, oxygen consumption, redox, membrane fluidity, lipid dynamics, bioenergetics, carbon and sulfur resource allocation, protein folding and aggregation, vitamin availability, metal homeostasis, indole, pterin, 1-carbon and polyamine metabolism, and polymer formation. The first wave of danger signals consists of the release of metabolic intermediates like ATP and ADP, Krebs cycle intermediates, oxygen, and reactive oxygen species (ROS), and is sustained by purinergic signaling. After the danger has been eliminated or neutralized, a choreographed sequence of anti-inflammatory and regenerative pathways is activated to reverse the CDR and to heal. When the CDR persists abnormally, whole body metabolism and the gut microbiome are disturbed, the collective performance of multiple organ systems is impaired, behavior is changed, and chronic disease results. Metabolic memory of past stress encounters is stored in the form of altered mitochondrial and cellular macromolecule content, resulting in an increase in functional reserve capacity through a process known as mitocellular hormesis. The systemic form of the CDR, and its magnified form, the purinergic life-threat response (PLTR), are under direct control by ancient pathways in the brain that are ultimately coordinated by centers in the brainstem. Chemosensory integration of whole body metabolism occurs in the brainstem and is a prerequisite for normal brain, motor, vestibular, sensory, social, and speech development. An understanding of the CDR permits us to reframe old concepts of pathogenesis for a broad array of chronic, developmental, autoimmune, and degenerative disorders. These disorders include autism spectrum disorders (ASD), attention deficit hyperactivity disorder (ADHD), asthma, atopy, gluten and many other food and chemical sensitivity syndromes, emphysema, Tourette’s syndrome, bipolar disorder, schizophrenia, post-traumatic stress disorder (PTSD), chronic traumatic encephalopathy (CTE), traumatic brain injury (TBI), epilepsy, suicidal ideation, organ transplant biology, diabetes, kidney, liver, and heart disease, cancer, Alzheimer and Parkinson disease, and autoimmune disorders like lupus, rheumatoid arthritis, multiple sclerosis, and primary sclerosing cholangitis.
This is a confocal microscopy image of human fibroblasts derived from embryonic stem cells. The nuclei appear in blue, while smaller and more numerous mitochondria appear in red. [Shoukhrat Mitalipov]
Mutations in our mitochondrial DNA tend to be inconspicuous, but they can become more prevalent as we age. They can even vary in frequency from cell to cell. Naturally, some cells will be relatively compromised because they happen to have a higher percentage of mutated mitochondrial DNA. Such cells make a poor basis for stem cell lines. They should be excluded. But how?
To answer this question, a team of scientists scrutinized skin fibroblasts, blood cells, and induced pluripotent stem cells (iPSCs) for mitochondrial genome integrity. When the scientists tested the samples for mitochondrial DNA mutations, the levels of mutations appeared low. But when the scientists sequenced the iPS cell lines, they found higher numbers of mitochondrial DNA mutations, particularly in cells from patients over 60.
The scientists were led by Shoukhrat Mitalipov, Ph.D., director of the Center for Embryonic Cell and Gene Therapy at Oregon Health & Science University, and Taosheng Huang, M.D., a medical geneticist and director of the Mitochondrial Medicine Program at Cincinnati Children’s Hospital. The Mitalipov/Huang-led team also found higher percentages of mitochondria containing mutations within a cell. The higher the load of mutated mitochondrial DNA in a cell, the more compromised the cell’s function.
Since each iPSC line is created from a different cell, each line may contain different types of mitochondrial DNA mutations and mutation loads. To choose the least damaged line, the authors recommend screening multiple lines per patient. “It’s a good idea to check the iPS clones for mitochondrial DNA mutations and make sure you pick a good cell line,” said Dr. Huang.
This recommendation appeared April 14 in the journal Cell Stem Cell, in an article entitled, “Age-Related Accumulation of Somatic Mitochondrial DNA Mutations in Adult-Derived Human iPSCs.” This article holds that mitochondrial genome integrity is a vital readout in assessing the proficiency of patient-derived regenerative products destined for clinical applications.
“We found that pooled skin and blood mtDNA contained low heteroplasmic point mutations, but a panel of ten individual iPSC lines from each tissue or clonally expanded fibroblasts carried an elevated load of heteroplasmic or homoplasmic mutations, suggesting that somatic mutations randomly arise within individual cells but are not detectable in whole tissues,” wrote the article’s authors. “The frequency of mtDNA defects in iPSCs increased with age, and many mutations were nonsynonymous or resided in RNA coding genes and thus can lead to respiratory defects.”
Potential therapies using stem cells hold tremendous promise for treating human disease. However, defects in the mitochondria could undermine the iPS cells’ ability to repair damaged tissue or organs.
“If you want to use iPS cells in a human, you must check for mutations in the mitochondrial genome,” declared Dr. Huang. “Every single cell can be different. Two cells next to each other could have different mutations or different percentages of mutations.”
Prior to the creation of a therapeutic iPS cell line, a collection of cells is taken from the patient. These cells will be tested for mutations. If the tester uses Sanger sequencing, older technology that is not as sensitive as newer next-generation sequencing, any mutation that occurs in less than 20% of the sample will go undetected. But mitochondrial DNA mutations might occur in less than 20% of mitochondria in the pooled cells. As a result, mutation rates have not been well understood. “These mitochondrial mutations are actually hidden,” explained Dr. Mitalipov.
The mitochondrial genome is relatively small, containing just 37 genes, so screening should be feasible using next generation sequencing, Dr. Mitalipov added. “It should be relatively cheap and do-able.”
Dr. Mitalipov also commented on a more general point, the implications of the current study on illuminating the mechanisms of age-related disease: “Pathogenic mutations in our mitochondrial DNA have long been thought to be a driving force in aging and age-onset diseases, though clear evidence was missing. This foundational knowledge of how cells are damaged in the natural process of aging may help to illuminate the role of mutated mitochondria in degenerative disease.”
A new paperfrom Shoukhrat Mitalipov’s lab on stem cell mitochondria points to a pattern whereby induced pluripotent stem (IPS) cells tend to have more problems if they are from older patients.
What does this paper mean for the stem cell field and could it impact more specifically the clinical applications of IPS cells?
The new paper Kang, et al is entitled “Age-Related Accumulation of Somatic Mitochondrial DNA Mutations in Adult-Derived Human iPSCs”.
This paper reminds us of the very important realities that mitochondria are key players in stem cell function and that mitochondria have their own genomes that impact that function. A lot of us don’t think about mitochondria and their genome as often as we should.
The paper came to three major scientific conclusions (this from the Highlights section of the paper and also see the graphical abstract for a visual sense of the results overall):
Human iPSC clones derived from elderly adults show accumulation of mtDNA mutations
Fewer mtDNA mutations are present in ESCs and iPSCs derived from younger adults
Accumulated mtDNA mutations can impact metabolic function in iPSCs
Importantly the team looked at IPS cells derived from both blood and skin cells and found that the former were less likely to have mitochondrial mutations.
This study suggests that those teams producing or working with human IPS cells (hIPSCs) should be screening the different lines for mitochondrial mutations. This excellent piece from Sara Reardon on the Mitalipov paper quotes IPS cell expert Jeanne Loring on this very point:
“It’s one of those things most of us don’t think about,” says Jeanne Loring, a stem-cell biologist at the Scripps Research Institute in La Jolla, California. Her lab is working towards using iPS cells to treat Parkinson’s disease, and Loring now plans to go back and examine the mitochondria in her cell lines. She suspects that it will be fairly easy for researchers to screen cells for use in therapies.”
Mitalipov goes further and suggests that his team’s new findings could support the use of human embryonic stem cells (hESC) derived by somatic cell nuclear transfer (SCNT) which would be expected to have mitochondria with fewer mutations. However, as Loring points out in the Reardon article, SCNT is really difficult to successfully perform and only a few labs in the world can do it at present. In that context, working with hIPSC and adding on the additional layer of mitochondrial DNA mutation screening could be more practical.
New York stem cell researcher Dieter Egli, however, is quoted that hIPSC have other differences with hESC as well such as epigenetic differences and he’s quoted in the Reardon piece, “It’s going to be very hard to find a cell line that’s perfect.”
One might reasonably ask both Egli and oneself, “What is a perfect cell line”?
In the end the best approach for use of human pluripotent stem cells of any kind is going to involve a balance between practicality of production and the potentially positive or negative traits of those cells as determined by rigorous validation screening.
With this new paper we’ve just learned more about another layer of screening that is needed. An interesting question is whether adult stem cells such as mesenchymal stromal/stem cells (MSC) also should be screened for mitochondrial mutations. They are often produced from patients who are getting up there in years. I hope that someone will publish on that too.
As to pluripotent cells, I expect that sometimes the best lines, meaning those most perfect for a given clinical application, will be hIPSC (autologous or allogeneic in some instances) and in other cases they may be hESC made from leftover IVF embryos. If SCNT-derived hESC can be more widely produced in an affordable manner and they pass validation as well then those (sometimes called NT-hESC) may also come into play clinically. So far that hasn’t happened for the SCNT cells, but it may over time. …..
Age-Related Accumulation of Somatic Mitochondrial DNA Mutations in Adult-Derived Human iPSCs
In Brief Mitalipov, Huang, and colleagues show that human iPSCs derived from older adults carry more mitochondrial DNA mutations than those derived from younger individuals. Defects in metabolic function caused by mtDNA mutations suggest careful screening of hiPSC clones for mutational load before clinical application.
Highlights
Human iPSC clones derived from elderly adults show accumulation of mtDNA mutations
Fewer mtDNA mutations are present in ESCs and iPSCs derived from younger adults
Accumulated mtDNA mutations can impact metabolic function in iPSCs
The genetic integrity of iPSCs is an important consideration for therapeutic application. In this study, we examine the accumulation of somatic mitochondrial genome (mtDNA) mutations in skin fibroblasts, blood, and iPSCs derived from young and elderly subjects (24–72 years). We found that pooled skin and blood mtDNA contained low heteroplasmic point mutations, but a panel of ten individual iPSC lines from each tissue or clonally expanded fibroblasts carried an elevated load of heteroplasmic or homoplasmic mutations, suggesting that somatic mutations randomly arise within individual cells but are not detectable in whole tissues. The frequency of mtDNA defects in iPSCs increased with age, and many mutations were non-synonymous or resided in RNA coding genes and thus can lead to respiratory defects. Our results highlight a need to monitor mtDNA mutations in iPSCs, especially those generated from older patients, and to examine the metabolic status of iPSCs destined for clinical applications.
Induced pluripotent stem cells (iPSCs) offer an unlimited source for autologous cell replacement therapies to treat age-associated degenerative diseases. Aging is generally characterized by increased DNA damage and genomic instability (Garinis et al., 2008; Lombard et al., 2005); thus, iPSCs derived from elderly subjects may harbor point mutations and larger genomic rearrangements. Indeed, iPSCs display increased chromosome aberrations (Mayshar et al., 2010), subchromosomal copy number variations (CNVs) (Abyzov et al., 2012; Laurent et al., 2011), and exome mutations (Johannesson et al., 2014), compared to natural embryonic stem cell (ESC) counterparts (Ma et al., 2014). The rate of mtDNA mutations is believed to be at least 10- to 20-fold higher than that observed in the nuclear genome (Wallace, 1994), and often both mutated and wild-type mtDNA (heteroplasmy) can coexist in the same cell (Rossignol et al., 2003). Large deletions are most frequently observed mtDNA abnormalities in aged post-mitotic tissues such as brain, heart, and muscle (Bender et al., 2006; Bua et al., 2006; Corral-Debrinski et al., 1992; Cortopassi et al., 1992; Mohamed et al., 2006) and have been implicated in aging and diseases such as Alzheimer’s disease (AD), Parkinson’s disease (PD), amyotrophic lateral sclerosis (ALS), and diabetes (Larsson, 2010; Lin and Beal, 2006; Petersen et al., 2003; Wallace, 2005). In addition, mtDNA point mutations were reported in some tumors and replicating tissues (Chatterjee et al., 2006; Ju et al., 2014; Michikawa et al., 1999; Taylor et al., 2003). However, the extent of mtDNA defects in proliferating peripheral tissues commonly used for iPSC induction, such as skin and blood, is thought to be low and limited to common non-coding variants (Schon et al., 2012; Yao et al., 2015). Accumulation of mtDNA variants in these tissues with age was insignificant (Greaves et al., 2010; Hashizume et al., 2015). Several point mutations were identified in iPSCs generated from the newborn foreskin fibroblasts, although most of these variants were non-coding, common for the general population, and did not affect their metabolic activity (Prigione et al., 2011). Somatic mtDNA mutations may be under-reported secondary to the level of sample interrogation. …..
Figure 2. mtDNA Mutations in Skin Fibroblasts, Blood, and the iPSCs of a 72-YearOld B Subject (A) Sixteen mutations at low heteroplasmy levels were detected in the DNA of PF, while a panel of ten FiPSC lines carried nine mutations, including four that were homoplasmic. Gray rectangles define the mutations shared between PF and FiPSCs. (B) Venn diagram showing only one mutation in FiPSCs shared with PF. (C) All ten FiPSC lines carried between one and five high-heteroplasmy (>15%) mutations. (D) Mutation distribution in whole blood and BiPSCs was similar to that in PF and FiPSCs. Six mutations at low-heteroplasmy levels were observed in blood, while BiPSC lines displayed 21 mutations, including four over the 80% heteroplasmy level. (E) Venn diagram showing four mutations in BiPSCs shared with whole blood and the 17 novel variants. (F) Distribution of mutations in individual BiPSC lines. See also Figures S2 and S3; Table S1; Table S3, sheet 2; and Table S4, sheet 1 ….
Figure 4. Transmission and Distribution of Somatic mtDNA Mutations to iPSCs (A) A total of 112 mtDNA mutations were discovered in parental cells (PF, CF, and blood) from 11 subjects. Of these, 39 variants (35%) were found in corresponding 130 iPSC lines. Among non-transmitted, transmitted, and novel mutations in iPSCs, comparable percentages of variants (68%, 69%, and 79%, respectively) were coding mutations in protein, rRNA, or tRNA genes. This suggests that most pathogenic mutations do not affect iPSC induction. However, certain coding mutations including in ND3, ND4L, and 14 tRNA genes were not detected in iPSCs, suggesting possible pathogenicity. n, the number of mtDNA mutations. Blue font genes were detected in parental cells. (B–D) A total of 80 high heteroplasmic (>15%) variants were detected in the present study in 130 FiPSC or BiPSC lines from 11 subjects. (B) The majority of these variants (76%) were non-synonymous or frame-shift mutations in protein-coding genes or affected rRNA and tRNA genes. (C) More than half of the mutations (56%) were never reported in a database containing whole mtDNA sequences from 26,850 healthy subjects representing the general human population (http://www.mitomap.org/MITOMAP). (D) Most mutations (90%) were never reported in a database containing sequences from healthy subjects with corresponding mtDNA haplotypes. freq., frequent. See also Figure S5 and Tables S3 and S4. ….
sjwilliamspa
Mutations will accumulate over age in mitochondrial DNA, however the current study has the difficulty that the authors could not use patient-age-matched controls, in essence they could only compare induced pluripotent stem cells derived from different patients. This could confound the results but the result with higher frequency of mutation in mtDNA in cells reprogrammed from younger patients is interesting but might limit the ability of autologous regenerative therapy in older patients. However reprogramming, although the method not mentioned here although I am assuming by transfection with lentivirus is a rough procedure, involving multiple dedifferentiation steps. Therefore it is very understandable that cells obtained from elderly patients would respond less favorably to such a rough reprogramming regimen, especially if it produced a higher degree of ROS, which has been shown to alter mtDNA. This is why I feel it is more advantageous to obtain a stem cell population from fat cells and forgo the Oct4, htert, reprogramming with lentiviral vectors.
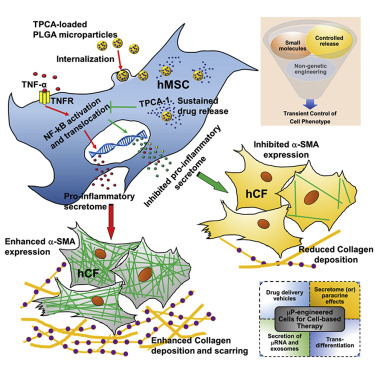









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}