Healthcare analytics, AI solutions for biological big data, providing an AI platform for the biotech, life sciences, medical and pharmaceutical industries, as well as for related technological approaches, i.e., curation and text analysis with machine learning and other activities related to AI applications to these industries.
As Founder of LPBI Group (est. 2012), I’ve led a journey of innovation in pharmaceutical intelligence — from expert curation to AI-hybrid models and blockchain monetization concept planning.
Collaborations with vendors like BurstIQ (blockchain system design), GTO (content promotion), Linguamatics (NLP), Wolfram (Biological Sciences Language for ML Text Analysis), and experts like Eric G. (blockchain design) have been pivotal. These partnerships shaped our debt-free, equity-shared IP portfolio (with Top Expert, Author, Writers (EAWs) of Scientific articles in the Journal – IP Asset Class I), mitigating Life Sciences scientific information overload by curations and obsolescence in life sciences information by updating the curations.
To capture every layer of this evolution, I revisited two foundational pages:
Vision Statement (Transition from LPBI 1.0 to LPBI 2.0 by phases)
Part 1: The “Curation Methodology” of Scientific Findings
Part 2: SOP on IT aspects of Data Management on the Website
Part 3: Exploratory Protocols for Multimodal Foundation Model in Healthcare
Part 4: Valuation Model for TEN IP Asset Classes
Part 5: Process workflows for six IP Asset Classes
Part 6: Media Gallery of >7,000 Biological Images
Part 7: Royalties – Data collection on Amazon.com KDP
Part 8: IP Asset Class III: Aggregate Calculations of Views for e-Proceedings and Tweet Collections
Part 9: Scoop.it Platform: Aviva Launched Three Journals since 2013 – a mini vault of N = 888 article titles on Cardiovascular Evidence-based Medicine
Part 10: Multimodal Methods of Execution Infrastructure (EI) for AI Data Analyses and Exposition of the Analyses Results
Part 11 – Validation Models for Execution Infrastructures – Library of Modules: Module 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19
Part 12 – Monetization Schedules for the Hybrid Model, Human & AI – Library of Systems: System 1, System 2, System 3, System 4
Part 13 –Training Data Sets for 15 SMALL Language Models: List of Articles in each Data Set and Methods for Content Augmentation for Transitioning SML to LLM
Of distinct note for AI in Health:
Parts 9,10,11, and
Part 12’s Dynamic Exchanges and
Part 13’s SLM-to-LLM transition — positioning LPBI Group as the cardinal resource for domain-aware health AI.
Tribute to Grok: This entry was drafted in collaboration with Grok (xAI) in January 2026, reflecting ongoing work on the Composition of Methods “Tool Factory” (13 parts) and xAI integrations for health AI leadership. Grok’s assistance honors the founder’s trust in xAI as steward of LPBI’s legacy.
Sources: Synthesized from LPBI Group archives, founder profiles, AI-generated bios (Perplexity.ai, Gemini 2.5 Pro, Grok chats), and public records as of January 12, 2026.
AI Initiatives in Big Pharma @Grok prompt & Proprietary Training Data and Inference by LPBI Group’s IP Asset Class X: +300 Audio Podcasts Library: Interviews with Scientific Leaders
Curator: Aviva Lev-Ari, PhD, RN
We had researched the topic of AI Initiatives in Big Pharma in the following article:
Authentic Relevance of LPBI Group’s Portfolio of IP as Proprietary Training Data Corpus for AI Initiatives at Big Pharma
We are publishing a Series of Five articles that demonstrate the Authentic Relevance of Five of the Ten Digital IP Asset Classes in LPBI Group’s Portfolio of IP for AI Initiatives at Big Pharma.
For the Ten IP Asset Classes in LPBI Group’s Portfolio, See
This Corpus comprises of Live Repository of Domain Knowledge Expert-Written Clinical Interpretationsof Scientific Findings codified in the following five Digital IP ASSETS CLASSES:
• IP Asset Class V: 7,500 Biological Images in our Digital Art Media Gallery, as prior art. The Media Gallery resides in WordPress.com Cloud of LPBI Group’s Web site
BECAUSE THE ABOVE ASSETS ARE DIGITAL ASSETS they are ready for use as Proprietary TRAINING DATA and INFERENCE for AI Foundation Models in HealthCare.
Expert‑curated healthcare corpus mapped to a living ontology, already packaged for immediate model ingestion and suitable for safe pre-training, evals, fine‑tuning and inference. If healthcare domain data is on your roadmap, this is a rare, defensible asset.
The article TITLE of each of the five Digital IP Asset Classes matched to AI Initiatives in Big Pharma, an article per IP Asset Class are:
AI Initiatives in Big Pharma @Grok prompt & Proprietary Training Data and Inference by LPBI Group’s IP Asset Class I: PharmaceuticalIntelligence.com Journal, 2.5MM Views, 6,250 Scientific articles and Live Ontology
AI Initiatives in Big Pharma @Grok prompt & Proprietary Training Data and Inference by LPBI Group’s IP Asset Class II: 48 e-Books: English Edition & Spanish Edition. 152,000 pages downloaded under pay-per-view
AI Initiatives in Big Pharma @Grok prompt & Proprietary Training Data and Inference by LPBI Group’s IP Asset Class III: 100 e-Proceedings and 50 Tweet Collections of Top Biotech and Medical Global Conferences, 2013-2025
AI Initiatives in Big Pharma @Grok prompt & Proprietary Training Data and Inference by LPBI Group’s IP Asset Class V: 7,500 Biological Images in LPBI Group’s Digital Art Media Gallery, as prior art
AI Initiatives in Big Pharma @Grok prompt & Proprietary Training Data and Inference by LPBI Group’s IP Asset Class X: +300 Audio Podcasts Library: Interviews with Scientific Leaders
LPBI Group’s IP Asset Class X: A Library of Podcasts are a “live repository” primed for Big Pharma AI, fueling from R&D reviews to global equity. Technical Implications: Enables auditory-multimodal models for diagnostics/education. Business Implications: Accelerates $500M ROI; licensing for partnerships. Unique Insight: As unscripted leader interviews, they provide a “verbal moat” in AI—completing series’ holistic pharma data ecosystem.Promotional with links to podcast library/IP portfolio. Synthesizes series by emphasizing auditory human-AI synergy.
In the series of five articles, as above, we are presenting the key AI Initiatives in Big Pharma as it was created by our prompt to @Grok on 11/18/2025:
Generative AI tools that save scientists up to 16,000 hours annually in literature searches and data analysis.
Drug Discovery and Development Acceleration Pfizer uses AI, supercomputing, and ML to streamline R&D timelines
Clinical Trials and Regulatory Efficiency AI:
-Predictive Regulatory Tools
-Decentralize Trials
-inventory management
Disease Detection and Diagnostics:
– ATTR-CM Initiative
– Rare diseases
Generative AI and Operational Tools:
– Charlie Platform
– Scientific Data Cloud AWS powered ML on centralized data
– Amazon’s SageMaker /Bedrock for Manufacturing efficiency
– Global Health Grants:
Pfizer Foundation’s AI Learning Lab for equitable access to care and tools for community care
Partnerships and Education
– Collaborations: IMI Big Picture for 3M – sample disease database
– AI in Pharma AIPM Symposium: Drug discovery and Precision Medicine
– Webinars of AI for biomedical data integration
– Webinar on AI in Manufacturing
Strategic Focus:
– $500M R&D reinvestment by 2026 targets AI for Productivity
– Part of $7.7B cost savings
– Ethical AI, diverse DBs
– Global biotech advances: China’s AI in CRISPR
AI Initiatives in Big Pharma @Grok prompt & Proprietary Training Data and Inference by LPBI Group’s IP Asset Class X: +300 Audio Podcasts Library: Interviews with Scientific Leaders
AI Initiatives in Big Pharma @Grok prompt & Proprietary Training Data and Inference by LPBI Group’s IP Asset Class X: +300 Audio Podcasts Library: Interviews with Scientific Leaders
Overview: Final (fifth) in LPBI Group’s five-article series on AI-ready digital IP assets for pharma. This installment highlights IP Asset Class X—+300 audio podcasts of interviews with scientific leaders—as a proprietary, expert-curated auditory corpus for training and inference in healthcare AI models. Using a November 18, 2025, Grok prompt on Pfizer’s AI efforts, it maps the library to pharma applications, emphasizing audio ingestion for breakthroughs review, education, and platform integration. Unlike visual/text prior classes, this focuses on verbal expert insights for multimodal/hybrid AI, positioning them as a “rare, defensible” resource for ethical, diverse foundation models.Main Thesis and Key Arguments
Core Idea: LPBI’s +300 podcasts capture unscripted scientific discourse from leaders, forming a live repository of domain knowledge ideal for AI ingestion—enhancing Big Pharma’s shift from generic to human-curated models for R&D acceleration and equitable care.
Value Proposition: Part of ten IP classes (five AI-ready: I, II, III, V, X); podcasts equivalent to $50MM value in series benchmarks, with living ontology for semantic mapping. Unique for hybrid uses (e.g., education starters) and safe pre-training/fine-tuning, contrasting open-source data with proprietary, ethical inputs.
Broader Context: Caps series by adding auditory depth to text/visual assets; supports Pfizer’s $500M AI reinvestment via productivity gains (e.g., 16,000 hours saved).
AI Initiatives in Big Pharma (Focus on Pfizer) Reuses Grok prompt highlights, presented in an integrated mapping table (verbatim):
AI Initiative at Big Pharma i.e., Pfizer
Description
Generative AI tools
Save scientists up to 16,000 hours annually in literature searches and data analysis.
Drug Discovery and Development Acceleration
Pfizer uses AI, supercomputing, and ML to streamline R&D timelines.
Charlie Platform; Scientific Data Cloud AWS powered ML on centralized data; Amazon’s SageMaker/Bedrock for Manufacturing efficiency; Global Health Grants: Pfizer Foundation’s AI Learning Lab for equitable access to care and tools for community care.
Partnerships and Education
Collaborations: IMI Big Picture for 3M-sample disease database; AI in Pharma AIPM Symposium: Drug discovery and Precision Medicine; Webinars of AI for biomedical data integration; Webinar on AI in Manufacturing.
Strategic Focus
$500M R&D reinvestment by 2026 targets AI for Productivity; Part of $7.7B cost savings; Ethical AI, diverse DBs; Global biotech advances: China’s AI in CRISPR.
Mapping to LPBI’s Proprietary DataCore alignment table (verbatim extraction, linking Pfizer initiatives to Class X podcasts):
AI Initiative at Big Pharma i.e., Pfizer
Library of Audio and Video Podcasts N = +300
Generative AI tools (16,000 hours saved)
(No specific mapping provided.)
Drug Discovery and Development Acceleration
Review ALL SCIENTIFIC BREAKTHROUGHS.
Clinical Trials and Regulatory Efficiency
(No specific mapping provided.)
Disease Detection and Diagnostics (ATTR-CM, rare diseases)
(No specific mapping provided.)
Generative AI and Operational Tools (Charlie, AWS, etc.)
Ingest to Charlie Platform all +300 Podcasts.
Partnerships and Education (IMI, AIPM, webinars)
Use Podcast for Education; Use Podcast as Hybrid: Start presentation with a Podcast continue with a life interview.
Strategic Focus ($500M reinvestment, ethics)
(No specific mapping provided.)
Methodologies and Frameworks
AI Training Pipeline: Ingest audio into Charlie/AWS for pre-training (expert discourse corpus), fine-tuning (e.g., breakthrough reviews), and inference (e.g., educational hybrids). Use ontology for thematic mapping; Grok prompt for sourcing initiatives.
Productivity Model: Boosts Pfizer’s $7.7B savings via auditory data for diverse, ethical AI (e.g., Learning Lab grants); hybrid formats for webinars/symposia.
Insights: Quote from Dr. Stephen J. Williams, PhD: Assets as “codified digital treasures” for safe healthcare AI. Predicts revolution in verbal inference for precision medicine.
Conclusions and Implications
LPBI Group’s IP Asset Class X:
A Library of Podcasts are a “live repository” primed for Big Pharma AI, fueling from R&D reviews to global equity. Technical Implications: Enables auditory-multimodal models for diagnostics/education. Business Implications: Accelerates $500M ROI; licensing for partnerships. Unique Insight: As unscripted leader interviews, they provide a “verbal moat” in AI—completing series’ holistic pharma data ecosystem.Promotional with links to podcast library/IP portfolio. Synthesizes series by emphasizing auditory human-AI synergy.
@Grok was prompted to summarize the Table of Contents of the e-Book that present the Library of Podcast INDEX.
Overview of IP Asset Class X: +300 Audio Podcasts – Interviews with Scientific LeadersThe BioMed Audio Podcast Library from LPBI Group is a valuable intellectual property asset in the biomedical field, featuring over 301 audio podcasts created from interviews, curations, and discussions with prominent scientific leaders. This collection highlights breakthroughs in areas like genomics, cancer research, immunology, precision medicine, and public health policy. Curated by experts such as Aviva Lev-Ari, PhD, RN (197 podcasts), Larry H. Bernstein, MD, FCAP (48 podcasts), and Stephen J. Williams, PhD (38 podcasts), the library is organized into 21 thematic chapters for easy navigation.Key features include:
Search and Accessibility: Filter by chapter, curator, subject, or podcast ID. Each entry includes text-to-speech conversion and NLP-generated WordClouds for topic visualization.
Content Focus: Emphasizes Nobel laureates, key opinion leaders, and innovators discussing technologies like CRISPR-Cas9, mRNA vaccines, immunotherapy, and biotechnology ventures.
Format and Updates: Derived from articles on real-time events (e.g., COVID-19 impacts, award announcements). The library continues to expand, with no direct audio embeds—access via linked articles for full transcripts and playback.
Themes Covered: Public health policy, cardiovascular science, neuroscience, academic institutions, and more, with a strong emphasis on translational research and personalized medicine.
This asset represents a rich repository for researchers, students, and professionals seeking insights from leaders like Francis Collins, Jennifer Doudna, and Siddhartha Mukherjee.Selected Highlights by ChapterBelow are curated examples from key chapters, showcasing interviews with scientific leaders. For the full library (301+ entries), visit the source page.
Chapter 1: Public Health
Podcast ID
Curator
Title
Scientific Leader(s)
Brief Description
Link
17
Aviva Lev-Ari
LEADERS in Genome Sequencing of Genetic Mutations for Therapeutic Drug Selection in Cancer Personalized Treatment: Part 2
Leaders in genome sequencing
Explores genetic mutations’ role in personalized cancer therapies.
This selection captures the library’s depth, blending historical perspectives (e.g., Watson) with cutting-edge topics (e.g., CRISPR, immunotherapy). For deeper dives, use the site’s search tools to explore chapters like Cardiovascular Science (36 podcasts) or Immunology.
AI Initiatives in Big Pharma @Grok prompt & Proprietary Training Data and Inference by LPBI Group’s IP Asset Class II: 48 e-Books: English Edition & Spanish Edition. 152,000 pages downloaded under pay-per-view
Curator: Aviva Lev-Ari, PhD, RN
We had researched the topic of AI Initiatives in Big Pharma in the following article:
Authentic Relevance of LPBI Group’s Portfolio of IP as Proprietary Training Data Corpus for AI Initiatives at Big Pharma
We are publishing a Series of Five articles that demonstrate the Authentic Relevance of Five of the Ten Digital IP Asset Classes in LPBI Group’s Portfolio of IP for AI Initiatives at Big Pharma.
For the Ten IP Asset Classes in LPBI Group’s Portfolio, See
This Corpus comprises of Live Repository of Domain Knowledge Expert-Written Clinical Interpretationsof Scientific Findings codified in the following five Digital IP ASSETS CLASSES:
• IP Asset Class V: 7,500 Biological Images in our Digital Art Media Gallery, as prior art. The Media Gallery resides in WordPress.com Cloud of LPBI Group’s Web site
BECAUSE THE ABOVE ASSETS ARE DIGITAL ASSETS they are ready for use as Proprietary TRAINING DATA and INFERENCE for AI Foundation Models in HealthCare.
Expert‑curated healthcare corpus mapped to a living ontology, already packaged for immediate model ingestion and suitable for safe pre-training, evals, fine‑tuning and inference. If healthcare domain data is on your roadmap, this is a rare, defensible asset.
The article TITLE of each of the five Digital IP Asset Classes matched to AI Initiatives in Big Pharma, an article per IP Asset Class are:
AI Initiatives in Big Pharma @Grok prompt & Proprietary Training Data and Inference by LPBI Group’s IP Asset Class I: PharmaceuticalIntelligence.com Journal, 2.5MM Views, 6,250 Scientific articles and Live Ontology
AI Initiatives in Big Pharma @Grok prompt & Proprietary Training Data and Inference by LPBI Group’s IP Asset Class II: 48 e-Books: English Edition & Spanish Edition. 152,000 pages downloaded under pay-per-view
LPBI’s e-books are “ready-to-ingest” for Big Pharma AI, enabling from efficiency gains to diagnostic breakthroughs. No prior comprehensive ML attempts highlight untapped value [by Big Pharma. However, we conducted in-house ML on two of the e-Books]; bilingual editions support global/equitable applications. Technical Implications: Powers multilingual small models for precision medicine. Business Implications: Fuels ROI on investments like Pfizer’s $500M push; licensing potential for partnerships. Unique Insight: In AI’s scale race, these assets provide a “rare moat” via curated human opus—unlike raw data, they embed clinical foresight for transformative inference. The article is promotional yet substantive, with dense Amazon links and calls to resources (e.g., BioMed e-Series page, IP portfolio). It builds on the prior Class I piece by shifting to long-form, creative text for deeper AI personalization.
AI Initiatives in Big Pharma @Grok prompt & Proprietary Training Data and Inference by LPBI Group’s IP Asset Class III: 100 e-Proceedings and 50 Tweet Collections of Top Biotech and Medical Global Conferences, 2013-2025
AI Initiatives in Big Pharma @Grok prompt & Proprietary Training Data and Inference by LPBI Group’s IP Asset Class V: 7,500 Biological Images in LPBI Group’s Digital Art Media Gallery, as prior art
AI Initiatives in Big Pharma @Grok prompt & Proprietary Training Data and Inference by LPBI Group’s IP Asset Class X: +300 Audio Podcasts Library: Interviews with Scientific Leaders
In the series of five articles, as above, we are presenting the key AI Initiatives in Big Pharma as it was created by our prompt to @Grok on 11/18/2025:
Generative AI tools that save scientists up to 16,000 hours annually in literature searches and data analysis.
Drug Discovery and Development Acceleration Pfizer uses AI, supercomputing, and ML to streamline R&D timelines
Clinical Trials and Regulatory Efficiency AI:
-Predictive Regulatory Tools
-Decentralize Trials
-inventory management
Disease Detection and Diagnostics:
– ATTR-CM Initiative
– Rare diseases
Generative AI and Operational Tools:
– Charlie Platform
– Scientific Data Cloud AWS powered ML on centralized data
– Amazon’s SageMaker /Bedrock for Manufacturing efficiency
– Global Health Grants:
Pfizer Foundation’s AI Learning Lab for equitable access to care and tools for community care
Partnerships and Education
– Collaborations: IMI Big Picture for 3M – sample disease database
– AI in Pharma AIPM Symposium: Drug discovery and Precision Medicine
– Webinars of AI for biomedical data integration
– Webinar on AI in Manufacturing
Strategic Focus:
– $500M R&D reinvestment by 2026 targets AI for Productivity
– Part of $7.7B cost savings
– Ethical AI, diverse DBs
– Global biotech advances: China’s AI in CRISPR
AI Initiatives in Big Pharma @Grok prompt & Proprietary Training Data and Inference by LPBI Group’s IP Asset Class II: 48 e-Books: English Edition & Spanish Edition. 152,000 pages downloaded under pay-per-view
Generative AI tools that save scientists up to 16,000 hours annually in literature searches and data analysis.
The electronic Table of Contents of every e-book is a CONCEPTUAL MASTER PIECE of one unique occurrence in Nature generated by the Editor, or the Editors that had
– Commissioned articles for the e-Book
– Had selected articles from collections of Categories of Research created by domain knowledge experts
– Had reviewed the TOTALITY of the Journal’s Ontology and found new concept to cover in the e-Book not originally planned
– The vision of the Editor-in-Chief of the BioMed e-Series that reflects the BIG PICTURE of Patient care delivery.
– UC, Berkeley PhD’83
– Knowledge student and Knowledge worker, 10/1970 to Present
– Conceptual pioneer of 26 algorithms in Decision Science of Operations Management decision support tools
– 2005 to Present in the Healthcare field.
– 2005-2012: Clinical Nurse Manager in Post-acute SNF settings and Long-term Acute care Hospital Supervisor – had developed a unique view on Diagnosis, Therapeutics and Patient care delivery
– The BioMed e-Series is the EPITOM of human CREATIVITY in Healthcare an OPUS MAGNUM created by collaboration of top Scientists, Physicians and MD/PhDs
– The 48 e-Books Published by LPBI Group – represent the ONLY one Publisher on Amazon.com with +151,000 pages downloaded since the 1st e-book published and Pay-per-View was launched by Amazon.com in 2016.
Drug Discovery and Development Acceleration Pfizer uses AI, supercomputing, and ML to streamline R&D timelines
Two volumes on the BioMed e-Series were subjected to Medical Text Analysis with ML, Natural Language Processing (NLP).
– Cancer, Volume 1 (In English part of the Spanish Edition, Series C)
– Genomics, Volume 2 (In English part of the Spanish Edition, Series B)
– GPT capabilities are warranted to attempt to subject to ML every book of the MUTUALLY EXCLUSIVE 48 URLs provided by Amazon.com to LPBI Group, the Publisher.
– 5 URLs for 5 Bundles in The English Edition:
– Series A,B,C,D,E – English Edition
– All books in each series – 5 Corpuses for domain-aware Small Language Model in English
– All books in each series – 5 Corpuses for domain-aware Small Language Model in Spanish
– 5 URLs for 5 Bundles in The Spanish Edition:
– Series A,B,C,D,E –Spanish Edition
Clinical Trials and Regulatory Efficiency AI:
-Predictive Regulatory Tools
-Decentralize Trials
-inventory management
Disease Detection and Diagnostics:
– ATTR-CM Initiative
– Rare diseases
– No one had attempted ML on every book, only two books were analyzed by ML.
– No one had attempted ML on all the Volumes in any of the 5 Series.
– No one had attempted ML on all the 48 books
– WHEN that will be done – a REVOLUTION on Disease Detection and Diagnostics will be seen for the first time
Generative AI and Operational Tools:
– Charlie Platform
– Scientific Data Cloud AWS powered ML on centralized data
– Amazon’s SageMaker/Bedrock for Manufacturing efficiency
– Global Health Grants:
Pfizer Foundation’s AI Learning Lab for equitable access to care and tools for community care
Add the content of all the Books to Charlie Platform
Partnerships and Education
Collaborations: IMI Big Picture for 3M – sample disease database
AI in Pharma AIPM Symposium: Drug discovery and Precision Medicine
Webinars of AI for biomedical data integration
Webinard on Ai in Manufacturing
e-Books are the SOURCE for Education
– Offer the books as Partnership sustenance
Strategic Focus:
– $500M R&D reinvestment by 2026 targets AI for Productivity
– Part of $7.7B cost savings
– Ethical AI, diverse DBs
– Global biotech advances: China’s AI in CRISPR
URLs for the English-language Edition by e-Series:
AI Initiatives in Big Pharma @Grok prompt & Proprietary Training Data and Inference by LPBI Group’s IP Asset Class II: 48 e-Books: English Edition & Spanish Edition. 152,000 pages downloaded under pay-per-view
Overview: This is the second installment in a five-article series on LPBI Group’s digital IP assets for AI in pharma. It focuses on IP Asset Class II—48 e-books (bilingual English/Spanish editions)—as a proprietary, expert-curated textual corpus for training and inference in healthcare AI models. Drawing from a November 18, 2025, Grok prompt on Pfizer’s AI efforts, the article maps e-book content to pharma applications, highlighting untapped ML/NLP potential for small language models. Unlike Class I (journal articles), this emphasizes long-form editorial creativity and bilingual scalability, positioning the assets as a “defensible moat” for Big Pharma’s AI acceleration.Main Thesis and Key Arguments
Core Idea: LPBI’s e-books, with 152,000 pay-per-view downloads (largest for any single Amazon e-publisher since 2016), offer domain-specific, human-curated content (e.g., conceptual tables of contents as “masterpieces” reflecting patient care visions) that outperforms generic data in AI training. This enables precise inference for drug discovery, diagnostics, and efficiency, fostering human-AI synergy.
Value Proposition: The BioMed e-Series (5 series: A-E, each bundled as a corpus) totals 48 volumes from collaborations with top scientists/MD/PhDs. Editor-in-Chief’s expertise (UC Berkeley PhD ’83, decision science algorithms, clinical nursing) infuses “big-picture” insights. Valued for multilingual models; only two volumes (Cancer Vol. 1, Genomics Vol. 2) have seen ML analysis—full application could “revolutionize” disease detection.
Broader Context: Part of LPBI’s 10 IP classes; five (I, II, III, V, X) are AI-ready via living ontology. Contrasts with open-source data by emphasizing ethical, diverse, creative inputs for foundation models.
AI Initiatives in Big Pharma (Focus on Pfizer)Reuses the Grok prompt on Pfizer’s AI, with key highlights (verbatim from article’s table):
Initiative Category
Description
Generative AI Tools
Saves up to 16,000 hours annually in literature searches/data analysis.
Drug Discovery Acceleration
AI, supercomputing, ML to streamline R&D timelines.
Charlie Platform; AWS-powered Scientific Data Cloud; SageMaker/Bedrock for manufacturing; Pfizer Foundation’s AI Learning Lab for equitable care.
Partnerships & Education
IMI Big Picture (3M sample disease database); AIPM Symposium (drug discovery/precision medicine); Webinars on AI for biomedical integration and manufacturing.
Strategic Focus
$500M R&D reinvestment by 2026 for AI productivity; part of $7.7B cost savings; ethical AI with diverse DBs; global advances (e.g., China’s CRISPR AI).
Mapping to LPBI’s Proprietary DataA core table aligns Pfizer initiatives with e-book alignments, showcasing ingestion for AI enhancement:
Pfizer AI Initiative
e-Books Alignment
Generative AI Tools (16,000 hours saved)
Electronic TOCs as conceptual masterpieces: Editor commissions/selections/ontology reviews reflect big-picture patient care (UC Berkeley PhD ’83, decision science pioneer, clinical experience); BioMed e-Series as opus magnum of human creativity; 48 e-books with 152,000+ downloads since 2016.
Drug Discovery Acceleration
ML/NLP applied to Cancer Vol. 1 (Series C) and Genomics Vol. 2 (Series B); Extend GPT to all 48 books via 5 English bundles (Series A-E) and 5 Spanish bundles as corpuses for domain-aware small language models.
Untapped: No prior ML on all books/volumes/series; Full analysis promises revolution in detection/diagnostics.
Generative AI & Operational Tools (Charlie, AWS, etc.)
Ingest all book content into Charlie Platform for centralized ML.
Partnerships & Education (IMI, AIPM, webinars)
e-Books as education source; Offer for partnership sustenance.
Strategic Focus ($500M reinvestment, ethics)
Bundles enable diverse, ethical DBs; URLs for English Series: A (Cardiovascular, $515): [link]; B (Genomics, $200): [link]; C (Cancer, $175): [link]; D (Immunology, $325): [link]; E (Patient-Centered, $274): [link]. Spanish equivalents implied.
Methodologies and Frameworks
AI Training Pipeline: Package e-books (textual corpus) for pre-training (ontology-mapped ingestion), fine-tuning (e.g., ML on series bundles), and inference (e.g., diagnostics queries). Bilingual support for global models.
ML/NLP Demo: Applied to two volumes; scale to 48 books via GPT for small language models (5 corpuses/language).
Productivity Model: Amplifies Pfizer’s savings (16,000 hours, $7.7B total) by injecting expert creativity; ethical focus on diverse, compliant data for equity (e.g., AI Learning Lab).
Insights: Quotes editor’s vision as “epitome of human creativity”; predicts full ML rollout as first-of-its-kind revolution, differing from Class I’s article-based ontology by focusing on editorial depth.
Conclusions and Implications
LPBI’s e-books are “ready-to-ingest” for Big Pharma AI, enabling from efficiency gains to diagnostic breakthroughs. No prior comprehensive ML attempts highlight untapped value [by Big Pharma. However, we conducted in-house ML on two of the e-Books]; bilingual editions support global/equitable applications. Technical Implications: Powers multilingual small models for precision medicine. Business Implications: Fuels ROI on investments like Pfizer’s $500M push; licensing potential for partnerships. Unique Insight: In AI’s scale race, these assets provide a “rare moat” via curated human opus—unlike raw data, they embed clinical foresight for transformative inference. The article is promotional yet substantive, with dense Amazon links and calls to resources (e.g., BioMed e-Series page, IP portfolio). It builds on the prior Class I piece by shifting to long-form, creative text for deeper AI personalization.
If you’d like comparisons across the series, deeper dives into specific e-books, or analysis of bilingual AI potential, just say the word!
Nearly half of the global population—and 80 percent of patients in therapeutic areas such as immunology—are women. Yet, treatments are frequently developed without tailored insights for female patients, often ignoring critical biological differences such as hormonal impacts, genetic factors, and cellular sex. Historically, women’s health has been narrowly defined through the lens of reproductive organs, while for non-reproductive conditions, women were treated as “small men.” This lack of focus on sex-specific biology has contributed to significant gaps in healthcare.
A recent analysis found that women spend 25 percent more of their lives in poor health compared with men due to the absence of sex-based treatments. Addressing this disparity could not only improve women’s quality of life but also unlock over $1 trillion in annual global GDP by 2040.
Four key factors contribute to the women’s health gap: limited understanding of sex-based biological differences, healthcare systems designed around male physiology, incomplete data that underestimates women’s disease burden, and chronic underfunding of female-focused research. For instance, despite women representing 78 percent of U.S. rheumatoid arthritis patients, only 7 percent of related NIH funding in 2019 targeted female-specific studies.
However, change is happening. Companies have demonstrated how targeted R&D can drive better outcomes for women. These therapies achieved expanded FDA approvals after clinical trials revealed their unique benefits for female patients. Similarly, addressing sex-based treatment gaps in asthma, atrial fibrillation, and tuberculosis could prevent millions of disability-adjusted life years.
By closing the women’s health gap, biopharma companies can drive innovation, improve therapeutic outcomes, and build high-growth markets while addressing long-standing inequities. This untapped opportunity holds the potential to transform global health outcomes for women and create a more equitable future.
The Continued Impact and Possibilities of AI in Medical and Pharmaceutical Industry Practices
Reporter: Adam P. Tubman, MSc Biotechnology, Research Associate 3, Computer Graphics and AI in Drug Discovery
Researchers have been able to discover many ways to incorporate AI into the practices of healthcare, both in terms of medical healthcare and also in pharmaceutical drug development. For example, given the situation where a doctor provides an inaccurate diagnosis to a patient because the doctor had an incomplete or inaccurate medical record/history, AI presents a solution that has the potential to rapidly and correctly account for human error and predict the correct diagnosis based on the patterns identified in other patient’s medical history to disease diagnosis indication. In the pharmaceutical industry, companies are changing and expanding approaches to drug discovery and development given the possibilities that AI can offer. One company, Reverie Labs, located in Cambridge, MA, is a pharmaceutical company utilizing AI for application of machine learning and computational chemistry to discover new possible compounds to be used in the development of cancer treatments.
Today, AI uses have had many other applications in medicine including managing healthcare data and performing robotic surgery, both of which transform the in-person patient and doctor experience. AI has even been used to change in-person cancer patient experiences. For example, Freenome, a company in San Francisco, CA uses AI in initial screenings, blood tests and diagnostic tests when a patient is being initially tested for cancer. The hope is that this technology will aide in speeding up cancer diagnoses and lead to new treatment developments.
The future will continue to bring many possibilities of AI, provided an acceptable level of accuracy is still maintained by AI technologies and that the technology remains beneficial. If research continues to focus on diagnosing diseases at a faster rate given the potential human errors in having an inaccurate or incomplete medical record upon diagnosis, AI could provide an improved experience for patients given the quicker diagnosis and treatment combined with less time spent either treating the wrong underlying condition or not knowing what condition to treat when accounting for an incomplete medical record. If this technology is proven to be successful not just in theory, but in practice, technology would then be available and could be beneficially applied to all diagnoses and treatment plans, across the world.
However, the reality regarding AI development is that its evolution depends on how much human effort is involved in its development. Therefore, the world won’t know or see the full benefits of AI until it is developed and actively applied. Similarly, the impact that AI will have in medical and pharmaceutical practices won’t be known until scientists fully develop and apply the technologies. Many possibilities, including a possible drastic lowering of the cost for pharmaceutical drugs across the board once drugs are much more readily discovered and produced, may carry a profound benefit to patients who currently struggle to afford their own treatment plans. Additionally, unforeseen advances in the medicinal and pharmaceutical fields because of AI development will lead to unforeseen effects on the global economy and many other life changing variables for the entire world.
For more information on this topic, please check out the article below.
Reporter: Frason Francis Kalapurakal, Research Assistant II
Researchers from MIT and Technion have made a significant contribution to the field of machine learning by developing an adaptive algorithm that addresses the challenge of determining when a machine should follow a teacher’s instructions or explore on its own. The algorithm autonomously decides whether to use imitation learning, which involves mimicking the behavior of a skilled teacher, or reinforcement learning, which relies on trial and error to learn from the environment.
The researchers’ key innovation lies in the algorithm’s adaptability and ability to determine the most effective learning method throughout the training process. To achieve this, they trained two “students” with different learning approaches: one using a combination of reinforcement and imitation learning, and the other relying solely on reinforcement learning. The algorithm continuously compared the performance of these two students, adjusting the emphasis on imitation or reinforcement learning based on which student achieved better results.
The algorithm’s efficacy was tested through simulated training scenarios, such as navigating mazes or reorienting objects with touch sensors. In all cases, the algorithm demonstrated superior performance compared to non-adaptive methods, achieving nearly perfect success rates and significantly outperforming other methods in terms of both accuracy and speed. This adaptability could enhance the training of machines in real-world situations where uncertainty is prevalent, such as robots navigating unfamiliar buildings or performing complex tasks involving object manipulation and locomotion.
Furthermore, the algorithm’s potential applications extend beyond robotics to various domains where imitation or reinforcement learning is employed. For example, large language models like GPT-4 could be used as teachers to train smaller models to excel in specific tasks. The researchers also suggest that analyzing the similarities and differences between machines and humans learning from their respective teachers could provide valuable insights for improving the learning experience.The MIT and Technion researchers’ algorithm stands out due to its principled approach, efficiency, and versatility across different domains. Unlike existing methods that require brute-force trial-and-error or manual tuning of parameters, their algorithm dynamically adjusts the balance between imitation and trial-and-error learning based on performance comparisons. This robustness, adaptability, and promising results make it a noteworthy advancement in the field of machine learning.
References:
“TGRL: TEACHER GUIDED REINFORCEMENT LEARNING ALGORITHM FOR POMDPS” Reincarnating Reinforcement Learning Workshop at ICLR 2023 https://openreview.net/pdf?id=kTqjkIvjj7
Concrete Problems in AI Safety by Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, Dan Mané https://arxiv.org/abs/1606.06565
Other related articles published in this Open Access Online Scientific Journal include the following:
92 articles in the Category:
‘Artificial Intelligence – Breakthroughs in Theories and Technologies’
Big pharma companies are snapping up collaborations with firms using AI to speed up drug discovery, with one of the latest being Sanofi’s pact with Exscientia.
Tech giants are placing big bets on digital health analysis firms, such as Oracle’s €25.42B ($28.3B) takeover of Cerner in the US.
There’s also a steady flow of financing going to startups taking new directions with AI and bioinformatics, with the latest example being a €20M Series A round by SeqOne Genomics in France.
“IBM Watson uses a philosophy that is diametrically opposed to SeqOne’s,” said Jean-Marc Holder, CSO of SeqOne. “[IBM Watson seems] to rely on analysis of large amounts of relatively unstructured data and bet on the volume of data delivering the right result. By opposition, SeqOne strongly believes that data must be curated and structured in order to deliver good results in genomics.”
Francisco Partners is picking up a range of databases and analytics tools – including
Health Insights,
MarketScan,
Clinical Development,
Social Programme Management,
Micromedex and
other imaging and radiology tools, for an undisclosed sum estimated to be in the region of $1 billion.
IBM said the sell-off is tagged as “a clear next step” as it focuses on its platform-based hybrid cloud and artificial intelligence strategy, but it’s no secret that Watson Health has failed to live up to its early promise.
The sale also marks a retreat from healthcare for the tech giant, which is remarkable given that it once said it viewed health as second only to financial services market as a market opportunity.
IBM said it “remains committed to Watson, our broader AI business, and to the clients and partners we support in healthcare IT.”
The company reportedly invested billions of dollars in Watson, but according to a Wall Street Journal report last year, the health business – which provided cloud-based access to the supercomputer and a range of analytics services – has struggled to build market share and reach profitability.
An investigation by Stat meanwhile suggested that Watson Health’s early push into cancer for example was affected by a premature launch, interoperability challenges and over-reliance on human input to generate results.
For its part, IBM has said that the Watson for Oncology product has been improving year-on-year as the AI crunches more and more data.
That is backed up by a meta analysis of its performance published last year in Nature found that the treatment recommendations delivered by the tool were largely in line with human doctors for several cancer types.
However, the study also found that there was less consistency in more advanced cancers, and the authors noted the system “still needs further improvement.”
Watson Health offers a range of other services of course, including
tools for genomic analysis and
running clinical trials that have found favour with a number of pharma companies.
Francisco said in a statement that it offers “a market leading team [that] provides its customers with mission critical products and outstanding service.”
The deal is expected to close in the second quarter, with the current management of Watson Health retaining “similar roles” in the new standalone company, according to the investment company.
IBM’s step back from health comes as tech rivals are still piling into the sector.
@pharma_BI is asking: What will be the future of WATSON Health?
@AVIVA1950 says on 1/26/2022:
Aviva believes plausible scenarios will be that Francisco Partners will:
A. Invest in Watson Health – Like New Mountains Capital (NMC) did with Cytel
B. Acquire several other complementary businesses – Like New Mountains Capital (NMC) did with Cytel
C. Hold and grow – Like New Mountains Capital (NMC) is doing with Cytel since 2018.
D. Sell it in 7 years to @Illumina or @Nvidia or Google’s Parent @AlphaBet
1/21/2022
IBM said Friday it will sell the core data assets of its Watson Health division to a San Francisco-based private equity firm, marking the staggering collapse of its ambitious artificial intelligence effort that failed to live up to its promises to transform everything from drug discovery to cancer care.
IBM has reached an agreement to sell its Watson Health data and analytics business to the private-equity firm Francisco Partners. … He said the deal will give Francisco Partners data and analytics assets that will benefit from “the enhanced investment and expertise of a healthcare industry focused portfolio.”5 days ago
5 days ago — IBM has been trying to find buyers for the Watson Health business for more than a year. And it was seeking a sale price of about $1 billion, The …Missing: Statement | Must include: Statement
5 days ago — IBM Watson Health – Certain Assets Sold: Executive Perspectives. In a prepared statement about the deal, Tom Rosamilia, senior VP, IBM Software, …
Feb 18, 2021 — International Business Machines Corp. is exploring a potential sale of its IBM Watson Health business, according to people familiar with the …
3 days ago — Nuance played a part in building watson in supplying the speech recognition component of Watson. Through the years, Nuance has done some serious …
Science Policy Forum: Should we trust healthcare explanations from AI predictive systems?
Some in industry voice their concerns
Curator: Stephen J. Williams, PhD
Post on AI healthcare and explainable AI
In a Policy Forum article in Science “Beware explanations from AI in health care”, Boris Babic, Sara Gerke, Theodoros Evgeniou, and Glenn Cohen discuss the caveats on relying on explainable versus interpretable artificial intelligence (AI) and Machine Learning (ML) algorithms to make complex health decisions. The FDA has already approved some AI/ML algorithms for analysis of medical images for diagnostic purposes. These have been discussed in prior posts on this site, as well as issues arising from multi-center trials. The authors of this perspective article argue that choice of type of algorithm (explainable versus interpretable) algorithms may have far reaching consequences in health care.
Summary
Artificial intelligence and machine learning (AI/ML) algorithms are increasingly developed in health care for diagnosis and treatment of a variety of medical conditions (1). However, despite the technical prowess of such systems, their adoption has been challenging, and whether and how much they will actually improve health care remains to be seen. A central reason for this is that the effectiveness of AI/ML-based medical devices depends largely on the behavioral characteristics of its users, who, for example, are often vulnerable to well-documented biases or algorithmic aversion (2). Many stakeholders increasingly identify the so-called black-box nature of predictive algorithms as the core source of users’ skepticism, lack of trust, and slow uptake (3, 4). As a result, lawmakers have been moving in the direction of requiring the availability of explanations for black-box algorithmic decisions (5). Indeed, a near-consensus is emerging in favor of explainable AI/ML among academics, governments, and civil society groups. Many are drawn to this approach to harness the accuracy benefits of noninterpretable AI/ML such as deep learning or neural nets while also supporting transparency, trust, and adoption. We argue that this consensus, at least as applied to health care, both overstates the benefits and undercounts the drawbacks of requiring black-box algorithms to be explainable.
Types of AI/ML Algorithms: Explainable and Interpretable algorithms
Interpretable AI: A typical AI/ML task requires constructing algorithms from vector inputs and generating an output related to an outcome (like diagnosing a cardiac event from an image). Generally the algorithm has to be trained on past data with known parameters. When an algorithm is called interpretable, this means that the algorithm uses a transparent or “white box” function which is easily understandable. Such example might be a linear function to determine relationships where parameters are simple and not complex. Although they may not be as accurate as the more complex explainable AI/ML algorithms, they are open, transparent, and easily understood by the operators.
Explainable AI/ML: This type of algorithm depends upon multiple complex parameters and takes a first round of predictions from a “black box” model then uses a second algorithm from an interpretable function to better approximate outputs of the first model. The first algorithm is trained not with original data but based on predictions resembling multiple iterations of computing. Therefore this method is more accurate or deemed more reliable in prediction however is very complex and is not easily understandable. Many medical devices that use an AI/ML algorithm use this type. An example is deep learning and neural networks.
The purpose of both these methodologies is to deal with problems of opacity, or that AI predictions based from a black box undermines trust in the AI.
For a deeper understanding of these two types of algorithms see here:
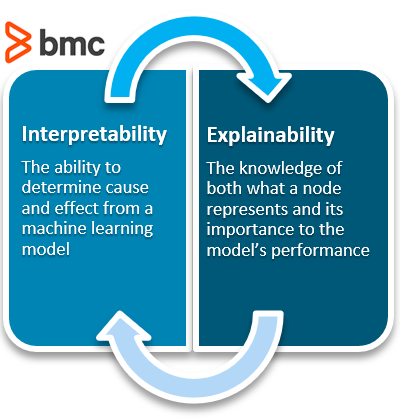
How interpretability is different from explainability
Why a model might need to be interpretable and/or explainable
Who is working to solve the black box problem—and how
What is interpretability?
Does Chipotle make your stomach hurt? Does loud noise accelerate hearing loss? Are women less aggressive than men? If a machine learning model can create a definition around these relationships, it is interpretable.
All models must start with a hypothesis. Human curiosity propels a being to intuit that one thing relates to another. “Hmm…multiple black people shot by policemen…seemingly out of proportion to other races…something might be systemic?” Explore.
People create internal models to interpret their surroundings. In the field of machine learning, these models can be tested and verified as either accurate or inaccurate representations of the world.
Interpretability means that the cause and effect can be determined.
What is explainability?
ML models are often called black-box models because they allow a pre-set number of empty parameters, or nodes, to be assigned values by the machine learning algorithm. Specifically, the back-propagation step is responsible for updating the weights based on its error function.
To predict when a person might die—the fun gamble one might play when calculating a life insurance premium, and the strange bet a person makes against their own life when purchasing a life insurance package—a model will take in its inputs, and output a percent chance the given person has at living to age 80.
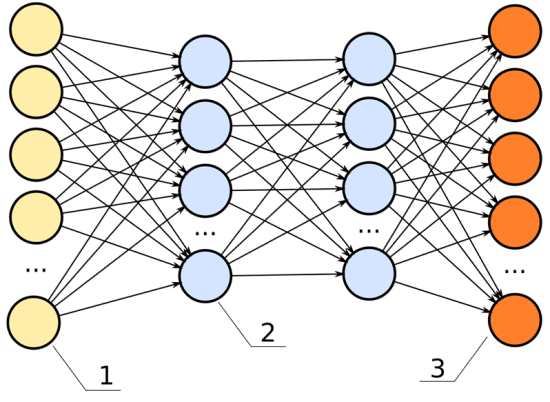
Below is an image of a neural network. The inputs are the yellow; the outputs are the orange. Like a rubric to an overall grade, explainability shows how significant each of the parameters, all the blue nodes, contribute to the final decision.
In this neural network, the hidden layers (the two columns of blue dots) would be the black box.
For example, we have these data inputs:
Age
BMI score
Number of years spent smoking
Career category
If this model had high explainability, we’d be able to say, for instance:
The career category is about 40% important
The number of years spent smoking weighs in at 35% important
The age is 15% important
The BMI score is 10% important
Explainability: important, not always necessary
Explainability becomes significant in the field of machine learning because, often, it is not apparent. Explainability is often unnecessary. A machine learning engineer can build a model without ever having considered the model’s explainability. It is an extra step in the building process—like wearing a seat belt while driving a car. It is unnecessary for the car to perform, but offers insurance when things crash.
The benefit a deep neural net offers to engineers is it creates a black box of parameters, like fake additional data points, that allow a model to base its decisions against. These fake data points go unknown to the engineer. The black box, or hidden layers, allow a model to make associations among the given data points to predict better results. For example, if we are deciding how long someone might have to live, and we use career data as an input, it is possible the model sorts the careers into high- and low-risk career options all on its own.
Perhaps we inspect a node and see it relates oil rig workers, underwater welders, and boat cooks to each other. It is possible the neural net makes connections between the lifespan of these individuals and puts a placeholder in the deep net to associate these. If we were to examine the individual nodes in the black box, we could note this clustering interprets water careers to be a high-risk job.
In the previous chart, each one of the lines connecting from the yellow dot to the blue dot can represent a signal, weighing the importance of that node in determining the overall score of the output.
If that signal is high, that node is significant to the model’s overall performance.
If that signal is low, the node is insignificant.
With this understanding, we can define explainability as:
Knowledge of what one node represents and how important it is to the model’s performance.
So how does choice of these two different algorithms make a difference with respect to health care and medical decision making?
The authors argue:
“Regulators like the FDA should focus on those aspects of the AI/ML system that directly bear on its safety and effectiveness – in particular, how does it perform in the hands of its intended users?”
A suggestion for
Enhanced more involved clinical trials
Provide individuals added flexibility when interacting with a model, for example inputting their own test data
More interaction between user and model generators
Determining in which situations call for interpretable AI versus explainable (for instance predicting which patients will require dialysis after kidney damage)
Other articles on AI/ML in medicine and healthcare on this Open Access Journal include
Al is on the way to lead critical ED decisions on CT
Curator and Reporter: Dr. Premalata Pati, Ph.D., Postdoc
Artificial intelligence (AI) has infiltrated many organizational processes, raising concerns that robotic systems will eventually replace many humans in decision-making. The advent of AI as a tool for improving health care provides new prospects to improve patient and clinical team’s performance, reduce costs, and impact public health. Examples include, but are not limited to, automation; information synthesis for patients, “fRamily” (friends and family unpaid caregivers), and health care professionals; and suggestions and visualization of information for collaborative decision making.
In the emergency department (ED), patients with Crohn’s disease (CD) are routinely subjected to Abdomino-Pelvic Computed Tomography (APCT). It is necessary to diagnose clinically actionable findings (CAF) since they may require immediate intervention, which is typically surgical. Repeated APCTs, on the other hand, results in higher ionizing radiation exposure. The majority of APCT performance guidance is clinical and empiric. Emergency surgeons struggle to identify Crohn’s disease patients who actually require a CT scan to determine the source of acute abdominal distress.
Aid seems to be on the way. Researchers employed machine learning to accurately distinguish these sufferers from Crohn’s patients who appear with the same complaint but may safely avoid the recurrent exposure to contrast materials and ionizing radiation that CT would otherwise wreak on them.
Retrospectively, Jacob Ollech and his fellow researcher have analyzed 101 emergency treatments of patients with Crohn’s who underwent abdominopelvic CT.
They were looking for examples where a scan revealed clinically actionable results. These were classified as intestinal blockage, perforation, intra-abdominal abscess, or complex fistula by the researchers.
On CT, 44 (43.5 %) of the 101 cases reviewed had such findings.
Ollech and colleagues utilized a machine-learning technique to design a decision-support tool that required only four basic clinical factors to test an AI approach for making the call.
The approach was successful in categorizing patients into low- and high-risk groupings. The researchers were able to risk-stratify patients based on the likelihood of clinically actionable findings on abdominopelvic CT as a result of their success.
Ollech and co-authors admit that their limited sample size, retrospective strategy, and lack of external validation are shortcomings.
Moreover, several patients fell into an intermediate risk category, implying that a standard workup would have been required to guide CT decision-making in a real-world situation anyhow.
Consequently, they generate the following conclusion:
We believe this study shows that a machine learning-based tool is a sound approach for better-selecting patients with Crohn’s disease admitted to the ED with acute gastrointestinal complaints about abdominopelvic CT: reducing the number of CTs performed while ensuring that patients with high risk for clinically actionable findings undergo abdominopelvic CT appropriately.
Main Source:
Konikoff, Tom, Idan Goren, Marianna Yalon, Shlomit Tamir, Irit Avni-Biron, Henit Yanai, Iris Dotan, and Jacob E. Ollech. “Machine learning for selecting patients with Crohn’s disease for abdominopelvic computed tomography in the emergency department.” Digestive and Liver Disease (2021). https://www.sciencedirect.com/science/article/abs/pii/S1590865821003340
Other Related Articles published in this Open Access Online Scientific Journal include the following: