Science Policy Forum: Should we trust healthcare explanations from AI predictive systems?
Some in industry voice their concerns
Curator: Stephen J. Williams, PhD
Post on AI healthcare and explainable AI
In a Policy Forum article in Science “Beware explanations from AI in health care”, Boris Babic, Sara Gerke, Theodoros Evgeniou, and Glenn Cohen discuss the caveats on relying on explainable versus interpretable artificial intelligence (AI) and Machine Learning (ML) algorithms to make complex health decisions. The FDA has already approved some AI/ML algorithms for analysis of medical images for diagnostic purposes. These have been discussed in prior posts on this site, as well as issues arising from multi-center trials. The authors of this perspective article argue that choice of type of algorithm (explainable versus interpretable) algorithms may have far reaching consequences in health care.
Summary
Artificial intelligence and machine learning (AI/ML) algorithms are increasingly developed in health care for diagnosis and treatment of a variety of medical conditions (1). However, despite the technical prowess of such systems, their adoption has been challenging, and whether and how much they will actually improve health care remains to be seen. A central reason for this is that the effectiveness of AI/ML-based medical devices depends largely on the behavioral characteristics of its users, who, for example, are often vulnerable to well-documented biases or algorithmic aversion (2). Many stakeholders increasingly identify the so-called black-box nature of predictive algorithms as the core source of users’ skepticism, lack of trust, and slow uptake (3, 4). As a result, lawmakers have been moving in the direction of requiring the availability of explanations for black-box algorithmic decisions (5). Indeed, a near-consensus is emerging in favor of explainable AI/ML among academics, governments, and civil society groups. Many are drawn to this approach to harness the accuracy benefits of noninterpretable AI/ML such as deep learning or neural nets while also supporting transparency, trust, and adoption. We argue that this consensus, at least as applied to health care, both overstates the benefits and undercounts the drawbacks of requiring black-box algorithms to be explainable.
Types of AI/ML Algorithms: Explainable and Interpretable algorithms
- Interpretable AI: A typical AI/ML task requires constructing algorithms from vector inputs and generating an output related to an outcome (like diagnosing a cardiac event from an image). Generally the algorithm has to be trained on past data with known parameters. When an algorithm is called interpretable, this means that the algorithm uses a transparent or “white box” function which is easily understandable. Such example might be a linear function to determine relationships where parameters are simple and not complex. Although they may not be as accurate as the more complex explainable AI/ML algorithms, they are open, transparent, and easily understood by the operators.
- Explainable AI/ML: This type of algorithm depends upon multiple complex parameters and takes a first round of predictions from a “black box” model then uses a second algorithm from an interpretable function to better approximate outputs of the first model. The first algorithm is trained not with original data but based on predictions resembling multiple iterations of computing. Therefore this method is more accurate or deemed more reliable in prediction however is very complex and is not easily understandable. Many medical devices that use an AI/ML algorithm use this type. An example is deep learning and neural networks.
The purpose of both these methodologies is to deal with problems of opacity, or that AI predictions based from a black box undermines trust in the AI.
For a deeper understanding of these two types of algorithms see here:
https://www.kdnuggets.com/2018/12/machine-learning-explainability-interpretability-ai.html
or https://www.bmc.com/blogs/machine-learning-interpretability-vs-explainability/
(a longer read but great explanation)
From the above blog post of Jonathan Johnson
- How interpretability is different from explainability
- Why a model might need to be interpretable and/or explainable
- Who is working to solve the black box problem—and how
What is interpretability?
Does Chipotle make your stomach hurt? Does loud noise accelerate hearing loss? Are women less aggressive than men? If a machine learning model can create a definition around these relationships, it is interpretable.
All models must start with a hypothesis. Human curiosity propels a being to intuit that one thing relates to another. “Hmm…multiple black people shot by policemen…seemingly out of proportion to other races…something might be systemic?” Explore.
People create internal models to interpret their surroundings. In the field of machine learning, these models can be tested and verified as either accurate or inaccurate representations of the world.
Interpretability means that the cause and effect can be determined.
What is explainability?
ML models are often called black-box models because they allow a pre-set number of empty parameters, or nodes, to be assigned values by the machine learning algorithm. Specifically, the back-propagation step is responsible for updating the weights based on its error function.
To predict when a person might die—the fun gamble one might play when calculating a life insurance premium, and the strange bet a person makes against their own life when purchasing a life insurance package—a model will take in its inputs, and output a percent chance the given person has at living to age 80.
Below is an image of a neural network. The inputs are the yellow; the outputs are the orange. Like a rubric to an overall grade, explainability shows how significant each of the parameters, all the blue nodes, contribute to the final decision.
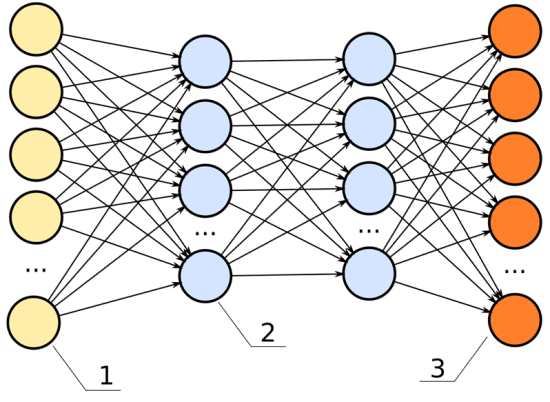
In this neural network, the hidden layers (the two columns of blue dots) would be the black box.
For example, we have these data inputs:
- Age
- BMI score
- Number of years spent smoking
- Career category
If this model had high explainability, we’d be able to say, for instance:
- The career category is about 40% important
- The number of years spent smoking weighs in at 35% important
- The age is 15% important
- The BMI score is 10% important
Explainability: important, not always necessary
Explainability becomes significant in the field of machine learning because, often, it is not apparent. Explainability is often unnecessary. A machine learning engineer can build a model without ever having considered the model’s explainability. It is an extra step in the building process—like wearing a seat belt while driving a car. It is unnecessary for the car to perform, but offers insurance when things crash.
The benefit a deep neural net offers to engineers is it creates a black box of parameters, like fake additional data points, that allow a model to base its decisions against. These fake data points go unknown to the engineer. The black box, or hidden layers, allow a model to make associations among the given data points to predict better results. For example, if we are deciding how long someone might have to live, and we use career data as an input, it is possible the model sorts the careers into high- and low-risk career options all on its own.
Perhaps we inspect a node and see it relates oil rig workers, underwater welders, and boat cooks to each other. It is possible the neural net makes connections between the lifespan of these individuals and puts a placeholder in the deep net to associate these. If we were to examine the individual nodes in the black box, we could note this clustering interprets water careers to be a high-risk job.
In the previous chart, each one of the lines connecting from the yellow dot to the blue dot can represent a signal, weighing the importance of that node in determining the overall score of the output.
- If that signal is high, that node is significant to the model’s overall performance.
- If that signal is low, the node is insignificant.
With this understanding, we can define explainability as:
Knowledge of what one node represents and how important it is to the model’s performance.
So how does choice of these two different algorithms make a difference with respect to health care and medical decision making?
The authors argue:
“Regulators like the FDA should focus on those aspects of the AI/ML system that directly bear on its safety and effectiveness – in particular, how does it perform in the hands of its intended users?”
A suggestion for
- Enhanced more involved clinical trials
- Provide individuals added flexibility when interacting with a model, for example inputting their own test data
- More interaction between user and model generators
- Determining in which situations call for interpretable AI versus explainable (for instance predicting which patients will require dialysis after kidney damage)