Healthcare analytics, AI solutions for biological big data, providing an AI platform for the biotech, life sciences, medical and pharmaceutical industries, as well as for related technological approaches, i.e., curation and text analysis with machine learning and other activities related to AI applications to these industries.
SNU-BioTalk 2025: Symphony of Cellular Signals in Metabolism and Immune Response – International Conference at Sister Nivedita University, Kolkata, India on 16 & 17 January 2025
Joint Convenor: Dr. Sudipta Saha (Member of LPBI since 2012)
About the Conference:
The International Conference on ‘Symphony of Cellular Signals in Metabolism and Immune Response’ focuses on the complex signalling pathways governing cellular functions in health and disease. It will explore the cellular mechanisms that regulate metabolism, immune responses, and survival, highlighting advances in medical science and biotechnology. Bringing together leading experts and emerging researchers, the conference will feature keynote lectures, panel discussions, research presentations, and interactive sessions, all designed to foster collaboration and innovation. By promoting an exchange of ideas, the event aims to drive transformative insights and solutions that impact human health and sustainable healthcare practices.
The conference will also be livestreamed on YouTube and Facebook
This programme will also host I-STEM: Indian Science, Technology and Engineering facilities Map (I-STEM) is a dynamic and interactive national portal for research cooperation.
Thrust areas:
Intracellular signalling processes of cellular metabolism
Signalling pathways in physiological and pathological processes
Reporter: Arav Gandhi, Research Assistant 2, Domain Content: Cardiovascular Diseases, Series A
AI, also known as artificial intelligence, has not only taken over the objectives of major technology giants such as Google and Microsoft, but also introduced itself to many fields, one of which being the medical field. Several advancements have been made to improve the way medical professionals view patients and their ability to see beyond their own perspective. One such field within medicine that has been primarily transformed is cardiology.
Cardiology is a branch of medicine dealing with all diseases and possible abnormalities found within the heart. For a medical professional, it can be viewed as a stressful occupation dependent on making the right diagnosis at the right time while a patient may view it as one of “the most unsettling moments” of their life hoping to receive the right treatment. But what if the pressure and uncertainty of cardiologists could be reduced? This is where artificial intelligence comes into play. Common medical devices such as ECGs to CT scans can be used to an extent beyond the capability of the human mind. With artificial intelligence, it can capture invaluable data with concepts such as machine learning geared to develop more accurate diagnostics as it receives more data. This not only improves the ability to which clinicians can understand the results of a test, but improve overall patient care: the most critical aspect of medicine. There are several examples by which artificial intelligence aids cardiologists.
If a patient is found with heart palpitations, chest pain or any other cardiac symptoms, an accurate diagnosis with respect to time is of the essence. Although technologies such as portable ultrasounds output results and observations, it is the smart use of data generated that allows for a significant decrease in uncertainty than before. Artificial intelligence is able to automate such measurements and interpretations complexifying the data to reveal much more beyond the human mind. For instance, a 3D CT angiography can show coronary stenosis and a cardiac MRI can show the downstream effect. By implementing artificial intelligence, it can interpret both results in relation to each other to develop a diagnosis and allow cardiologists to understand the patient beyond their own intuition. Not only does artificial intelligence play an important role in interpretation of results, but also in treatment.
After the diagnosis of the patient, there must be a treatment plan optimized to efficiency of time and risk tailored to the patient itself. Artificial intelligence showcases its true power of precision when subject to the cases of patients affected by disease. For instance, through guided imaging solutions such as X-ray, AI is able to explore all possible procedures from minimally invasive to complex methods. Moreover, it even allows clinicians to understand the full perspective of the procedure and determine the best possible tools to use. Yet, AI proves to be helpful beyond the operation room.
With AI, it can reduce clinician and patient exposure to radiation while still obtaining an optimal image quality. Not only has it contributed to safety, but AI has allowed for a better understanding of patient flow and issue real-time notifications so clinicians can prioritize which patients need their attention. With the cardiology department constantly going through issues throughout a day, AI can help reduce this and ease the stress at which the clinicians go through.
Although many fear that artificial intelligence may replace clinicians entirely, this is merely a misconception by which clinicians rather can use artificial intelligence to improve their own view of a patient. Not only does this improve access to quality care, but it also gives those in the field of medicine a piece of mind knowing that they are able to consider all possibilities before developing treatment on a patient.
To learn more about the topic, check out the article below.
The female reproductive lifespan is regulated by the menstrual cycle. Defined as the interval between the menarche and menopause, it is approximately 35 years in length on average. Based on current average human life expectancy figures, and excluding fertility issues, this means that the female body can bear children for almost half of its lifetime. Thus, within this time span many individuals may consider contraception at some point in their reproductive life. A wide variety of contraceptive methods are now available, which are broadly classified into hormonal and non-hormonal approaches. A normal menstrual cycle is controlled by a delicate interplay of hormones, including estrogen, progesterone, follicle-stimulating hormone (FSH) and luteinizing hormone (LH), among others. These molecules are produced by the various glands in the body that make up the endocrine system.
Hormonal contraceptives – including the contraceptive pill, some intrauterine devices (IUDs) and hormonal implants – utilize exogenous (or synthetic) hormones to block or suppress ovulation, the phase of the menstrual cycle where an egg is released into the uterus. Beyond their use as methods to prevent pregnancy, hormonal contraceptives are also being increasingly used to suppress ovulation as a method for treating premenstrual syndromes. Hormonal contraceptives composed of exogenous estrogen and/or progesterone are commonly administered artificial means of birth control. Despite many benefits, adverse side effects associated with high doses such as thrombosis and myocardial infarction, cause hesitation to usage.
Scientists at the University of the Philippines and Roskilde University are exploring methods to optimize the dosage of exogenous hormones in such contraceptives. Their overall aim is the creation of patient-specific minimizing dosing schemes, to prevent adverse side effects that can be associated with hormonal contraceptive use and empower individuals in their contraceptive journey. Their research data showed evidence that the doses of exogenous hormones in certain contraceptive methods could be reduced, while still ensuring ovulation is suppressed. Reducing the total exogenous hormone dose by 92% in estrogen-only contraceptives, or the total dose by 43% in progesterone-only contraceptives, prevented ovulation according to the model. In contraceptives combining estrogen and progesterone, the doses could be reduced further.
Mission #1: Medical Text Analysis using NLP, ML-AI
Wolfram Vendor selection
Workflow Ten-steps Template for NLP in Books
NLP – Book Assignment
– Genomics Volume 1: Satwik – Started on 1/4/2022
– Genomics Volume 2: Madison – DONE
– Cancer Volume 1: Satwick – NLP – DONE
– Danielle – Book prep PART B
– Cancer Volume 2: Juliet Wu
– Nitric Oxide: Yash C.
– 3D BioPrinting: Ms. Joshi
Organizational
July 19: Launch of LPBI India
Marketing Communication
March 2: Podcast with many updates – LPBI is a Very Unique Organization
DESIGN of CONTENT PROMOTION campaigns: Montero & GTO
Mission #2: Blockchain for Content Monetization and Auction of
(1) Curations as NFT and
(2) Therapeutics Molecules
9/14: Selection of Fluree Foundation for our Blockchain
IT & Data Science Internship – LPBI gained the code to run Article Views by any date, 2012 – 2021 – Contributions by Srini and by Abhisar
Text to Sound: 150 of the 270 Interviews with Scientific Leaders were converted to Podcasts – Contribution by Ethan
Sign up agreement with SpeechKit – Text to Sound conversion for (a) $204 for 360 podcasts per year (b) Archive bulk conversion 20 cents per Podcast (c) Use API for Spanish Text to Spanish Sound
ALL 18 BOOKS have a COVER PAGE and an eTOCs in Spanish – Montero competed its Contract and was paid by a Loan Aviva made to LPBI. On 9/1/2021 wired the funds to cover the Invoice.
DESIGN and ENABLEMENT of Content Monetization – Blockchain
IT & Data Science – Audit capabilities to Journal Articles
Mission #4:Drug Design with Synthetic Biology Software
LPBI strategy is for BLOCKCHAIN technology to be MARRIED to NLP FOR CONTENT MONETIZATION
BLOCKCHAIN for Auction of New molecules:
Give Dr. Nir Right of Use
Hosting the molecules in Blockchain Knowledge Graph Data Base
Open up the molecules for licensing in a cyber secured confidential Auction
Host molecules inventories from Technology Transfer Offices in several Academic centers around the Globe. We have relations to three Academic institutions in Israel, and three in the US
8/10: Spanish Translation going on
11/14: Erich of Blockchain Schema
12/14: Xavier and Eric on NFT as Presented by LPBI Group’s Portfolio of IP Assets Classes I – XIV
Rehearsal of Linguamatics Proposal for a Health Care Insurer
8/10: Synthetic Biology Software – New Molecules DESIGN
10/12: Dr. Williams presented
Wolfram Platform: What can LPBI do to get access for MULTIPLE computers beyond 2 seats, currently held by Madison and by Yash – WHAT can we do with Wolfram to enable access to all INTERNS?
What is the state of development for the decision on the Software to be selected for Synthetic Biology for our Interns?
HOW the work by David MacMillan on BioCatalysis can be harnessed for our Synthetic Biology for Drug Discovery effort
11/9: PROTAC – PRossetaC with Prof. Nir London, Weizmann Institute
Tweets and Re-Tweets of Tweets by @pharma_BI@AVIVA1950at EmTech MIT 2021, #EmTechMIT, Technology Review’s flagship event, September 28-30, 2021
REAL TIME EVENT COVERAGE as PRESS by invitation from EmTech MIT 2021 at #EmTechMIT:
Aviva Lev-Ari, PhD, RN
Tweet Collection Curator:
Aviva Lev-Ari, PhD, RN
TWEET HIGHLIGHTS
Top Tweet earned 24K impressions
@pharma_BI@AVIVA1950#EmTechMIT Charles Hoskinson CEO and Founder, Input Output Global; Founder, Cardano, 2015 Nation scale [Ethiopia] and Global scale – records ledger and smart contracts, credentials identity, reversible auditable that operates at scale; Cofounder, Ethereum
@pharma_BI@AVIVA1950#EmTechMIT Charles Hoskinson CEO and Founder, Input Output Global; Founder, Cardano, 2015 Nation scale [Ethiopia] and Global scale – records ledger and smart contracts, credentials identity, reversible auditable that operates at scale; Cofounder, Ethereum
Technology Review’s flagship event, September 28-30, 2021 – #EmTechMIT 2021 EmTech MIT 2021 – Agenda Overview & Speakers: Leading with innovation, Virtual MIT Techno…https://lnkd.in/eFCbbwsa
@pharma_BI @AVIVA1950 #EmTechMIT Sumant Sinha Founder, Chairman, Renew Power India exceeded Paris Guidelines, Government involved in Renewable energies. Faster adoption. cost of renewal energy is plummeting. Demand increased by 5%-10% in coming 3 years, In 10 years 10%-15%
@pharma_BI @AVIVA1950 #EmTechMIT Urho Konttori Cofounder and CTO, VarjoVR and XR headsets: True Telepresence, device will be size of goggles. In 2025 standardization of the Industry.Human communication iwll be come Teleportation
@pharma_BI @AVIVA1950 #EmTechMIT Judith Olson Head of Atomic Clock Division, ColdQuanta Next generation of #GPS local network of clock landslide alert system to use GPS, precision timing, atomic is a better clock over time satellites and vehicles rugged and portable hydrogen
@pharma_BI @AVIVA1950 #EmTechMIT Polls of Blockchain: many (34%) said it change the World. Few said will invest in it or will use it. Call to have more regulations Congress try to regulate the Internet may e coming Technology & Ingenuity gap robots can empower humans unfamiliar
@pharma_BI @AVIVA1950 #EmTechMIT Aamer Baig Senior Partner, McKinsey Technology Cloud migration Scale and where the value comes from CIO, CFO, CEO Cloud has cost components Business opportunity that business process and business transformation
@pharma_BI @AVIVA1950 #EmTechMIT @EmTechMIT Daniel Theobald Founder CIO Vecna Robotics Where the Optimization will come from? Supply Chain problem solving. Edge computing like Cloud computing allows to collect data Robots collect data – automated guided vehicles
@pharma_BI @AVIVA1950 #EmTechMIT @EmTechMIT Wendy Nather Head of Advisory CISOs @Cisco mid 90s Two-way authentications Who are the attackers, changes, abuse of the platform by users Technology to buy Proactive Refresh Tech done by vendor is best security practice
@pharma_BI @AVIVA1950 #EmTechMIT Charles Hoskinson CEO and Founder, Input Output Global; Founder, Cardano, 2015 Nation scale [Ethiopia] and Global scale – records ledger and smart contracts, credentials identity, reversible auditable that operates at scale; Cofounder, Ethereum
@pharma_BI @AVIVA1950 #EmTechMIT Michael Casey Chief Content Officer, CoinDesk adoption of bitcoin increased during COVID, NFT – what do you own? you own the NFT it is very valuable, decentralized status mechanism NFT’s value is their scarcity
@pharma_BI @AVIVA1950 #EmTechMIT Charles Hoskinson CEO and Founder, Input Output Global; Founder, Cardano, 2015 Nation scale [Ethiopia] and Global scale – records ledger and smart contracts, credentials identity, reversible auditable that operates at scale; Cofounder, Ethereum
@pharma_BI @AVIVA1950 #EmTechMIT Kevin Scott CTO @Microsoft Compute is the only constraint Open source version of OpenAI API no need to build OS. Responsible AI within Microsoft – Standard for the whole company to be rolled up soon. Regulation to consider where we are going to be
@pharma_BI @AVIVA1950 #EmTechMIT Nick Selby Chief Security Officer, Paxos Trust Company at Timehop GDPR a bridge of security disclosure to US Citizens 5% of EU opt out 7/418 ADM password changed User database was compromised protect customers data Recovery architecture monitor
@pharma_BI @AVIVA1950 #EmTechMIT @EmTechMIT Wendy Nather Head of Advisory CISOs @Cisco mid 90s Two-way authentications Who are the attackers, changes, abuse of the platform by users Technology to buy Proactive Refresh Tech done by vendor is best security practice
@pharma_BI @AVIVA1950 #EmTechMIT Kevin Scott CTO @Microsoft Compute is the only constraint Open source version of OpenAI API no need to build OS. Responsible AI within Microsoft – Standard for the whole company to be rolled up soon. Regulation to consider where we are going to be
#EmTechMIT James Temple, MIT TR Green Hydrogen was a surprise the need and the interest cost is deceasing it is in our capacity to overcome Amy Nordrum innovators under 35 small satellite hand size CRISPR as Diagnostics
#EmTechMIT Dava Newman Director, MIT Media Lab New directions Bionics and prostetics for kids 3D Printing Assists Health and Wellness. Surgery and MGH collaboration Robotics Limbs. Videos using systemic view. Co-create the vision AI and data from Satellite
#EmTechMIT Dava Newman Director, MIT Media Lab Co-create the vision AI and data from Satellite Bridge ML and Data physics Predict crime in cities, inequality sensors in Urban environment to change behavior in Cities near Coast line floods. Buildings
#EmTechMIT Diversity inclussivity celebrated makers, designers, iterate and mind play creatively envisioning 10 years in the future invention of the future, users, communities and communities, co-create
#EmTechMIT Dava Newman Director, MIT Media Lab Transition from a financial crisis and the Pandemic interruption – emergence into great opportunities with societal impact. New directions Bionics and prostetics for kids 3D Printing Assists Health and Wellness
#EmTechMIT Jesse Levinson Co-Founder CTO, Zoox Autonomous Vehicle for Urban Challenge History of Zoox, 2014 Better way to create a new type of car optimize on Drivers experience vs autonomous vehicle Symmetrical and Bi-directional, shorter car interior big
#EmTechMIT Jesse Levinson Co-Founder CTO, Zoox Passenger different experience add premium features, car is rented for few hours only.RObotTaxi like LIFT without a driver, each ride is in the same car. Expirience is UNIQUE to Zoox
#EmTechMIT Varun Sivaram American companies to assist in South East Asia in Clean energy, Book Energize America. Steel synthetic fuel from petrochemical, like solar drive cost down
#EmTechMIT Varun Sivaram Senior Director, Clean Energy & Innovation, U.S. Department of State Clean energy transition US will leverage technologies around the Global Drive down cost for Cleaner technologies National Labs lessons to be shared technical talent
#EmTechMIT Leah Ellis CEO and Cofounder, Sublime SystemsPatent-pending electrochemical system based on MIT research totally decarbonized cement commercially viable technology to scale cement made today
#EmTechMIT Mircea Dinca Professor, MIT; Cofounder, Transaera How AC can consume 50% less energy an adds on device on top of AC unit to deal with the water cool air not cool water Technology and Policy must work together reduce energy consumption
#EmTechMIT Meagan Mauter Associate Professor, Stanford University Automation, Precision preparation of resilient systems manage separation processing margilarity in water consumption electrify smart
#EmTechMIT Anthony Brower Director Gensler Building geometry, low tech shift from Rectangular to Square foot print. move stairs outside the building. Roof design Green rook sun is absorbed, eliminate lighting by sensor lighting reduce energy construction
#EmTechMIT Kate Marvel NASA’s Evaporation leads to droughts, Cold snaps like TX, cold air and Jet stream, Air quality particle level Ozon, high Probabilities based of 1988 projections of Temp getting it right for 2010 Warming is expected How bad gets
#EmTechMIT Kate Marvel NASA’s Goddard Institute for Space Studies; Professor, Columbia University Problem Space, Physical Climate Scientist Human are causing ALL the climate change, vulcanos not responsible for warming TEMP dopping the weather Heat waves
#EmTechMIT Christoph Noeres Head of Green Hydrogen (GH) Electrolysis process of production of GH de-carbonizing by CO2 free for green housing low cost renewable industry at scale to push forward transport supply chain Green Hydrogen industry transformation
#EmTechMIT Leah Stokes UC Santa Barbara Clean Energy to power homes and cars, pollution is draining the Power potential. Fossil fuel infrastructure IMPEDE decrease of Temperature by 5 degrees Celcius. Let’s make Clean energy cheaper by policy incentives
#EmTechMIT Bill McKibben Cofounder http://350.org Washington Clean Energy Incentives, Utilities are engaged, Demand from the Public, investment $50Trillion divestment by Universities from Oil related investment.
#EmTechMIT Bill McKibben Cofounder http://350.org Climate change challenging fossil fuel energy industry. Changing is hard against Utilities and Oil interests
#EmTechMIT Jesse Jenkins Princeton University Cleaners energies 2030 50% lower emission Presidential mandate. Cost of batteries of electric cars, cost of Wind decreased by energy policy, push from oil energy to zero emission cars, accelerate clean energy
#EmTechMIT Sumant Sinha Founder, Chairman, Renew Power India exceeded Paris Guidelines, Government involved in Renewable energies. Faster adoption. cost of renewal energy is plummeting. Demand increased by 5%-10% in coming 3 years, In 10 years 10%-15%
#EmTechMIT Sumant Sinha Founder, Chairman, Renew Power compromise of economic growth not favorable to all stakeholders. Intermittency regarding transmission and distribution of clean energy sources. Renewable only 15%, 2030 35%. Government GRID Management
#EmTechMIT Day 3: Powering Our World Start Now ongoint till 5PM From next-generation power grids to nuclear power and renewable energy, understanding the impact, scalability, and tradeoffs of different energy technologies is critical to powering our future
#EmTechMIT Urho Konttori Cofounder and CTO, Varjo VR and XR headsets focus on Professional Medical, Design and engineering, customers: Volvo, Boeing, Toyata Human Eye Resolution is the best vs consumer grade Pilot simulation used this device training pilots.
#EmTechMIT st Vice President, XR Tools, Unity How much compute is enabled by the Cloud computing, glasses can be used as a controlling remove device interoperability among devices, manufacturing devices to be considered for advancement
#EmTechMIT Marc Miskin UPenn application of microelectronic for design of robots microorganism size not visible to eye laser spot is a control function parallel design of one robot allows deployment of an army of robots like microorganisms Repair of nerves
#EmTechMIT Janice ChenCofounder CTO, Mammoth BiosciencesOn Demand Diagnostic Tool based on CRISPR: read, detect, Protein Discovery – Meta-genomics – proteins Cas14, delivery advantages. Target proteins for diagnostics: detect DNA and RNA the exact sequence
#EmTechMIT Jonathan Weissman Professor, MIT; Investigator, HHMI CRISPR 2.0 under DARPA Chemical and BioChem. CRISPR gene editing correct the underlining genetics, where to cut the DNA for changing the sequence Cas9 – complicated technology.
#EmTechMIT Jonathan Weissman Professor, MIT; Investigator, HHMI Turn up and down -Silence a gene, an existing gene programmable Epigenetic memory engineering (15 month) n CRISP off Variant 1 vs CRISPR off Variant 2 only the targeted gene precision editing
#EmTechMIT Christina Rudzinski Lincoln Laboratory, MIT Priority is both detection in advance and the vaccine capability virus detected as pathogen Actice biological weapons Nation states as adversary Lab escape virus is a possibility Lab Survelience systems
#EmTechMIT Christina Rudzinski Lincoln Laboratory, MIT Infection progression: Pre-exposure Human transmission incubation symptoms onset illness early environmental detection population survelience Bio-signal data for detection of host’s response to infection
#EmTechMIT Christina Rudzinski Lincoln Laboratory, MIT Reducing Biological threats. COVID19 is a Global Pandemic by a pathogen, diagnostics deployed Future pathogen infections. genetically engineered pathogens pathones evolve have been used maliciously
#EmTechMIT Roy Azevedo Education and Training 37,000 employees 5,000 were hired during the Pandemic. Three innovation new engine work, radio frequencies Radars, cyber technology
#EmTechMIT Roy Azevedo Simulation importance in the process of AI development, the only way to know that fidelity in the system is what bring trust to the system in Pandemic just-in-time ML applied to COVID Tests modeling Virus DNA
#EmTechMIT Roy Azevedo Knowhow Satellite system for Weather prediction system data run through scenarios ethics applied before using AI-ML algorithm latency is not affordable, operator make decision at the edge Test & Verify Modeling & Simulation perform
#EmTechMIT Roy Azevedo President, Raytheon Intelligence & Space High-stake environments: NSA Logistics, Cyber Satellite, Weather Storms, Deploy AI to explain the recommendation for trust into the decision making. AI is distrusted as it nears autonomy
#EmTechMIT Ron Weiss MIT Liver vascularization dysfunction, Pancreas function by design mature Organoids Cyp3A4 – for druggability. Cancer immunotherapy will be first to benefit numeric synthetic Biology for therapeutic intervention to improve precision
#EmTechMIT Ron Weiss MIT Professor Synthetic Biology – complexity biology: Pathways and Disease state (1) Sensing (2) Logic Processing (3) Therapeutics development. Controlling Stem cell differentiation. Programming a cell development for drug development
#EmTechMIT Ani Kembhavi Single Purpose Model vs Multi Purpose Model AI agents, CEREBRA – Cognitive Rudiments for building AI Models – multi skills models simulators, robots, based on physical principles Multi modal AI Visual, Audio, Text
#EmTechMIT Ani Kembhavi Allen Institute for AI Research Manager Learning Skills, Learning Concepts, Search Engine Data to teach after learning skills and concepts using richer vocabularies using Visual and Text data. Learn to interact, navigate.
#EmTechMIT Ani Kembhavi Allen Institute for AI Research Manager Single Purpose Model vs Multi Purpose Model (1) General Models (2) Understand (3) Question and get answers.
#EmTechMIT Virginia Smith CMU Federate Learning (FL) (1) Cross Silo [high availability] vs (2) Cross device FT [communication bottleneck] – Distributive model [Privacy] interoperability [heterogeneity}. Personalized FT: among the devices Accuracy Bias Data
#EmTechMIT Virginia Smith CMU Assistant Professor Federated Learning beneficial – Distributed AI Learning Model. Where does the Data comes from Two canonical approaches in Federated Design: Centralized Learning vs Federated Learning – training at the Edge
#EmTechMIT Timnit Gebru Independent Scholar experiences isolation. Labor rights and anti-discrimination rights, censoring research sounds like propaganda, outside the Tech company to impact the industry, to keep Tech companies accountable own institute on AI
#EmTechMIT >>> Jeff Hawkins Numenta The concept of competition, Structure of the Brain is known Goal is not Human’s Intelligent machine will act in the World Computing models can be smart nto human but helping humans in Pattern recognition Consciousness AI
#EmTechMIT >>> Jeff Hawkins Numenta Model of the World, learning through movement, Two elements of new modeling: (1) fastest NN (2) Sparcity learn new information Integration of these theoretical concept into companies building products
#EmTechMIT Jeff Hawkins Cofounder and Chief Scientist, Numenta Deep Learning, stattistical techniques, no intelligence in it we know how to do that, must move to learn reference brain the structure of the world we have in the brain stored info in Brain vs AI
#EmTechMIT Polls of Blockchain: many (34%) said it change the World. Few said will invest in it or will use it. Call to have more regulations Congress try to regulate the Internet may e coming Technology & Ingenuity gap robots can empower humans unfamiliar
#EmTechMIT Judith Olson Head of Atomic Clock Division, ColdQuanta helium permeation Why atom make a better clock allows consistence use a lot of atoms non interacting in vacuum the future of the definition of second, utilize clock in new ways
#EmTechMIT Judith Olson Head of Atomic Clock Division, ColdQuanta disputes on automated transactions regarding transaction announcement detection of pre-earthquake coming opticla atomic clock for sell in 3 years funding and testing are limitations, microwave
#EmTechMIT Judith Olson Head of Atomic Clock Division, ColdQuanta Judith Olson Head of Atomic Clock Division, ColdQuanta precision timing, atomic is a better clock over time satellites vehicles rugged portable hydrogen ColdQuanta’s Fieldable Optical Clocks
#EmTechMIT Judith Olson Head of Atomic Clock Division, ColdQuanta Next generation of #GPS local network of clock landslide alert system to use GPS, precision timing, atomic is a better clock over time satellites and vehicles rugged and portable hydrogen
#EmTechMIT David Wentzloff Cofounder & Co-CTO, Everactive Monitoring solutions analytics for the customers Sensors on a chip energy harvesting interface to a capacitor and a storage device. FFT on the data results shipped to customer Superior wireless tech
#EmTechMIT David Wentzloff Cofounder & Co-CTO, Everactive Analytics requires data and data needs to be collected renewable energy sources at the micro scale: Power supply and Demand for wireless devices Batteryless technology slack systems solution a service
#EmTechMIT Aamer Baig Senior Partner, McKinsey Technology The #CLOUD Enabler and catalist (a) Strategy & Management (b) Business domain adoption (c) Processes and risk postures 1. Innovate 2. Rejuvenate 3. Pioneer adoption New technologies: Blockchain
#EmTechMIT Sara Spangelo CEO & Cofounder, Swarm Technologies IoT 4Billion new devices Global affordable 150 Satellite connectivity $5 per month subscription access to water combating drought early detection of fires from satellites ofter the devices transmit
#EmTechMIT Adnan Mehonic Assistant Professor, University College LondonTraining an AI Model using Memistore silicon oxidefor digital memory it can be used for In memory computing, Neuromorphic Computing: Digital CMOS, Neuromorphic Computing
#EmTechMIT Silvio Micali Founder, Algorand Governance rules for decentralized vs centralized system: Who chooses the next block? Algorand – proof of stake for financial inclusion in El Salvador atomic consumption, allowing all access Blockchain functionality
#EmTechMIT Charles Hoskinson Space is more inclusive, diverse industry. Mongolia has bitcoin and Nigeria and Vietnam had adopted bitcoin and microfinance in Kenia and Philippines
#EmTechMIT Charles Hoskinson decentralization of energy consumption, hardware with limited supply, 3rd generation systems become decentralized. Speed of Networks, base ledge proof of reserve, auction computation – hybrid model decentralized and centralized
#EmTechMIT Charles Hoskinson What is in El Salvador for crypto currency? Cardano ? Contract system, EDA is transaction system, consensus protocol, energy consumption comes from hash for every step, representation not actual, 2015 – decentralization of energy
#EmTechMIT Charles Hoskinson CEO and Founder, Input Output Global; Founder, Cardano, 2015 Nation scale [Ethiopia] and Global scale – records ledger and smart contracts, credentials identity, reversible auditable that operates at scale; Cofounder, Ethereum
#EmTechMIT Michael Casey Chief Content Officer, CoinDesk adoption of bitcoin increased during COVID, NFT – what do you own? you own the NFT it is very valuable, decentralized status mechanism NFT’s value is their scarcity
Security Culture, reporting security incidence fishing testing is wrong but incentivising security awareness democratizing security because technology is being security vendors need to provide options
mid 90s Two-way authentications Who are the attackers, changes, abuse of the platform by users Technology to buy Proactive Refresh Tech done by vendor is best security practice
#EmTechMIT Nick Selby Chief Security Officer, Paxos Trust Company at Timehop GDPR a bridge of security disclosure to US Citizens 5% of EU opt out 7/418 ADM password changed User database was compromised protect customers data Recovery architecture monitor
Compute is the only constraint Open source version of OpenAI API no need to build OS. Responsible AI within Microsoft – Standard for the whole company to be rolled up soon. Regulation to consider where we are going to be
ScottCTO & EVP, Technology and Research, Microsoft Seen innovations training bigger models gets better in use of #microlanguage#AI solving milestone sentiment analysis of Tweets supervised models transformer models little fine tuning
Proposal for New e-Book Architecture: Bi-Lingual eTOCs, English & Spanish with NLP and Deep Learning results of Medical Text Analysis – Phase 1: six volumes
Author: Aviva Lev-Ari, PhD, RN
UPDATED on 8/5/2021
Smart use of customizable software in conjunction with 1.0 LPBI IP assets and competencies:
Mission #1: Natural Language Processing (NLP) – Team in USA & India – Medical Text Analysis with NLP – on LPBI 3.3 Giga Bytes of Content. Two NLP types: (a) Statistical NLP and (b) Deep Learning by Machine Learning using Wolfram Language for Biological Sciences
In Mission #1: Using Machine Learning (ML) algorithms for Text Analysis of our 3.3 Giga Bytes of English Text
Statistical Natural Language Processing (NLP). This yields
WordClouds, Bar Diagrams for each article and Tree Diagrams for collection of articles
Deep Learning (DL) for Semantic Analysis of the Text. This yields
Hyper-graphs for collections of articles using knowledge graphs in knowledge graph databases.
Mission #2: Blockchain IT and NLP Processing API generating NLP visualization Products used by Knowledge Graphs stored in Graph Databases – Content monetization infrastructure B2B and B2C.
In Mission #2: The Transactions-enabled blockchain platform for Content Monetization of IP assets embodies the development of a Blockchain information technology infrastructure that is transactions-enabled allowing payments for content digital products. On the blockchain we will store all the following Digital products:
1.0 LPBI four IP Asset Classes:
IP Asset Class I: Journal articles +6,070
IP Asset Class II: electronic Books in Medicine
IIa. 18 e-books in English
IIb. 18 Bi-Lingual electronic Table of Contents (eTOCs): Spanish & English
IIc.. 18 e-Books – NLP visualization products
IId. 18 e-Books Expert written NLP results Interpretations: Spanish & English
IIe. For 18 books all audio Podcasts in Spanish & English – selective content
IIf. For each e-Series, A,B,C,D,E we plan to publish a volume containing the Bi-Lingual Spanish-English electronic Table of Contents in each e-Series for all the e-Books in the e-Series – an additional 5 Bi-Lingual e-Books.https://c0.pubmine.com/sf/0.0.3/html/safeframe.htmlREPORT THIS AD
IP Asset Class III. e-Proceedings: 100 volumes
IP Asset Class V: Gallery of Biological Images 6,200 to grow if NLP yields 10 graphs 📊 per article
2.0 LPBI all products of NLP, see Yields for Mission #1, above PLUS IP Asset Classes XI, XII, XIII, mentioned, below serve as a compelling justification for the selection of Blockchain Transactions Network architecture as our IS/IT platform.= among other alternatives.
IP Asset Class XI: New Digital Products as a result of Discovery 💡 of new digital products derived from and created for the new queries by users to be generated on the fly
IP Asset Class XII: All digital products of Mission #3, below and
P Asset Class XIII: All digital products of Mission #4, below
Mission #3: New GENRE of Multimedia Scientific Books: These 18 LPBI e-Books will be the first on the Medical Books Market to contain Text Analysis with NLP of the original e-Books. BioMed e-Books – Book Republishing in new GENRE – Bi-Lingual and Multimedia Audio Podcast for Books in the 18-e-Books in five e-Series: A,B,C,D,E . The New book architecture for each Book:
Part A: Spanish and English electronic Table of Contents in Text and in Audio Podcast.
Part B: NLP & Expert Interpretation of the visualizations in Text and Podcast: English and Spanish,NLP results for the content of the e-Book
Hyper-graphs for each Chapter
Domain Knowledge Expert Interpretation of all NLP results:
TO BE CREATED – English Text and Spanish TextTO BE CREATED – English Audio Podcast and Spanish Audio Podcast
Part C: Editorial of original book (Preface, Volume Introduction, Volume Summary and Epilogue) -English Audio Podcast
Part 1: the original book’s electronic Table of Contents
Media Format:
1.1 Bi-Lingual: English and Spanish
1.2 Text to Sound – Audio Podcast in Spanish
Part 2: Text Analysis with AI by Yash Choudhary, IIT, Kanpur
2.1 Statistical NLP for each Chapter, all chapters in the Book
2.2 Semantic NLP for each Chapter, all chapters in the Book
Media Format:
2.1 Statistical Graphs – Bar Diagrams and Tree Diagrams
2.2 Semantic Graphs – Hyper-graphs, one per chapter
2.3 Domain Knowledge Expert: Interpretation of 2.1 and 2.2
Media Format:
2.3.1 English Text
2.3.1.1 Text to Sound – Podcast
2.3.2 Spanish Text – New translation to Spanish of the Expert’s Interpretation will need to be commissioned
2.3.2.1 Text to Sound – English Podcast
2.3.2.2 Text to Sound – Spanish Podcast
Part 3: The original Book Editorial: Preface, Volume Introduction, Volume Summary and Epilogue
Media Format:
English Text to Sound – English Audio Podcast
Blockchain relations:
Each of the above outputs: I.e.,
1. eTOCs in English2. eTOCs in Spanish For each of the 18 books: Phase 1: six books of the 18.
3. Every graph of Statistical NLP
4. Every graph of Semantic Deep Learning by Machine Learning, Wolfram Language for Biological Sciences
5. Expert Interpretation of 3 & 4, above In English Text, Spanish Text, English Podcast, Spanish Podcast
6. Editorial for the volume: English Text and English Podcast
All of the above are discrete DIGITAL PRODUCTS WITH A LIST PRICE to become available for download on LPBI’s Blockchain platform for Content Monetization (is now under design) in LPBI Digital Store on a Digital Healthcare Marketplace. Discovery is performed by data science and & analytics among the data entities and their representation by nodes and edges in the knowledge graph.
We launched a NEW Genre for Scientific Books: Bi-Lingual: English – Spanish with the NLP Results of the Text Analysis by NLP and Domain Knowledge Expert Interpretations in Text and in Sound. The eTOCs in Spanish Audio, NLP results Interpretation in English Audio and in Spanish Audio and Editorial in English Audio.
Dr. Lev-Ari statement on 7/25/2021
Bi-Lingual electronic Table Of Contents (eTOCs), English & Spanish with Montero Language Services, Madrid as the Translator of eighteen Books’ Cover Pages and the 18 books electronic Table of Contents.
The Content promotion in the Spanish speaking Countries with GTO, Madrid as AD Agency.
NLPs results of Medical Text Analysis with domain knowledge expert Interpretations in Foreign Languages and in Audio: in Spanish and in other languages, forthcoming
Original English Book – Only Editorials (Preface, Introductions, Summaries and Epilogue) because the Bi-Lingual part has the eTOCs of the e-Book
This is a new genre and a new architecture of 18 MULTIMEDIA SCIENTIFIC e-Books with (a) NLP results of the Medical Text analysis with machine learning, (b) Expert Interpretation of the Visualization Results. Bi-Lingual Podcasts: (c) eTOCs and (d) Bi-Lingual Expert Interpretation in English and Spanish Text and audio Podcasts, and (e) Books’ Editorials in English Audio Podcast
UPDATED on 7/31/2021
BioMed e-Books – Book Republishing in new GENRE – Bi-Lingual and Multimedia Audio Podcast for Books in the 18-e-Books in five e-Series: A,B,C,D,E
New Genre e-Book Architecture has the following Book architecture:
Bi-Lingual English to Spanish eTOCs
NLP Results with Audio interpretation of results by Domain knowledge Expert in several languages
English Editorial in Audio Podcast
STATE OF AFFAIRS for LPBI’s BioMed e-Series – 18 Books
• Currently we have a massive effort of Converting ALL the electronic Table of Contents of the 18 books from English Text to Spanish Text. Same for the 18 Cover Pages
We may decide to
• Convert the SPANISH TEXT to SPANISH AUDIO PODCAST
• Domain Knowledge Expert INTERPRETATION of NLP RESULTS on six volumes:
Series B: Genomics – 2 volumes
Series C: Cancer – 2 volumes
Series A: Volume 1 – Nitric Oxide
Series E: Volume 4 – 3D BioPrinting
All above NLP interpretation of visualization products will be written by Domain knowledge experts as English Text:
Cancer & Genomics: Dr. Williams, LPBI USA
Cardiovascular: Dr. Vivek Lal, LPBI India
The Interpretations English Text will be subjected to:
• Conversion of English Text to Sound: English Audio Podcast
• Conversion of English Text to Spanish Text to Spanish Audio Podcast
• Other Languages Audio Podcast: Japanese, Russian
For the following FOUR VOLUMES: GENOMICS 1&2 and CANCER 1&2 We will have NLP – 10-Step Workflow protocol implemented on. Few additional e-Books will be added for that workflow.
WORKFLOW for a Ten-Steps Medical Text Analysis Operation using NLP on LPBI Medical and Life Sciences Content
Genomics Vol 2 • NLP by Madison: ——-> Part 1,2,3,4 very big COMPLETED and ——-> Part 5,6,7,8 very small – Madison
Cancer Vol 1• NLP by Danielle: Chapters 1 – 6: COMPLETED and • NLP by Dr. Pati: Chapters 7 – 12: COMPLETED
Cancer Vol 2• NLP – Ms. Ingle, Chapters 1 – 10
Cancer Vol 2• NLP – TBA Chapters 11 – 20
We HAVE already for THESE FOUR VOLUMES the SPANISH TRANSLATION of:
A. Book’s Cover Page: One page English, One Page Spanish
B. Book’s electronic Table of Contents is Bi-Lingual: English and Spanish
– article Title in Spanish
– article Title in English
– URL – original
– Author Name, PhD or MD – original
NEW IDEA UNDER CONSIDERATION IS AS FOLLOWS:
1. Originally we planned to publish the Spanish translation A and B, above followed by the English Book as on the Journal 2. The Book on Amazon.com contains
2.1 abbreviated eTOCs – LIVE LINKS TO ARTICLES
2.2 each article inside the book as an MS Word file, thus
• Cancer Vol 1 is 2,400 pages
• Cancer Vol 2 is 3,747 pages
3. NOW Cancer Vol 1 – NLP is completed (Danielle and Dr. Pati) and the Spanish Translation A and B, above is completed
The NEW IDEA is To Publish these FOUR volumes in the following NEW BOOK Architecture FORMAT:
Cancer Volume 1: EXAMPLE for the new e-Book Architecture
• Cover Page English
• Cover Page Spanish • eTOCs Bi-Lingual: The Spanish Translation by Montero • Medical Text Analysis using Wolfram NLP by Danielle Smolyar and Dr. Premalata Pati
1. WordClouds are already in the articles
2. From the TABLE I SENT TO CHECK OFF FOR QA
2.1 Article title and Bar Diagram in PPT
2.2 for Each Chapter a Hyper-graph and a Tree Diagram – 2 GRAPHS
2.3 Dr. Williams Interpretation on 2.2 in English Text
2.4 To have a Podcast for 2.3 in English and in Spanish
2.5 PlugIn was Installed on 7/30/2021 and we have now access to 50 languages – Text to Sound Conversion
Followed by
• Book eTOCs in English with all the editorials: Preface
Volume Introduction
Volume Summary
Epilogue
The RESULTS WOULD BE:
For Genomics Vol 1&2 and Cancer Vol 1&2
These volumes will be re-published as
Medical Text Analysis – NLP 10-Steps Workflow Operation of the ORIGINAL BOOK content
• Intern(s) name(s) as Performers of NLP on the original Text appears on the book and all their NLP work is included in the book
2. English and Spanish Cover Page by Montero
3. Bi-Lingual English and Spanish eTOCs by Montero
4. English Book as in the Journal (NOT AS ON AMAZON.com)
This is an EXAMPLE of an LPBI Book in the new Book Architecture format
Genomics Volume 2 will be RE-Published in a new Format having the following three parts:
Part A: Bi-Lingual electronic Table of Contents (eTOCs)
Spanish Translation by Montero Language Services, Madrid, Spain
*As of the writing of these steps, the Anchor feature that converts articles to podcasts is relatively new. As of my most recent communication with representatives of Anchor, they are planning on adding features that would simplify this process.
Converting an Article to a Podcast
The first thing you will need to do is create an account on Anchor who has recently partnered with WordPress to allow users to link their accounts and convert articles into podcasts. The link to do so is below.
It is important to note that Anchor will not let you link to a WordPress account if you create a generic account it must be an account linked with WordPress. This link should allow you to do so.
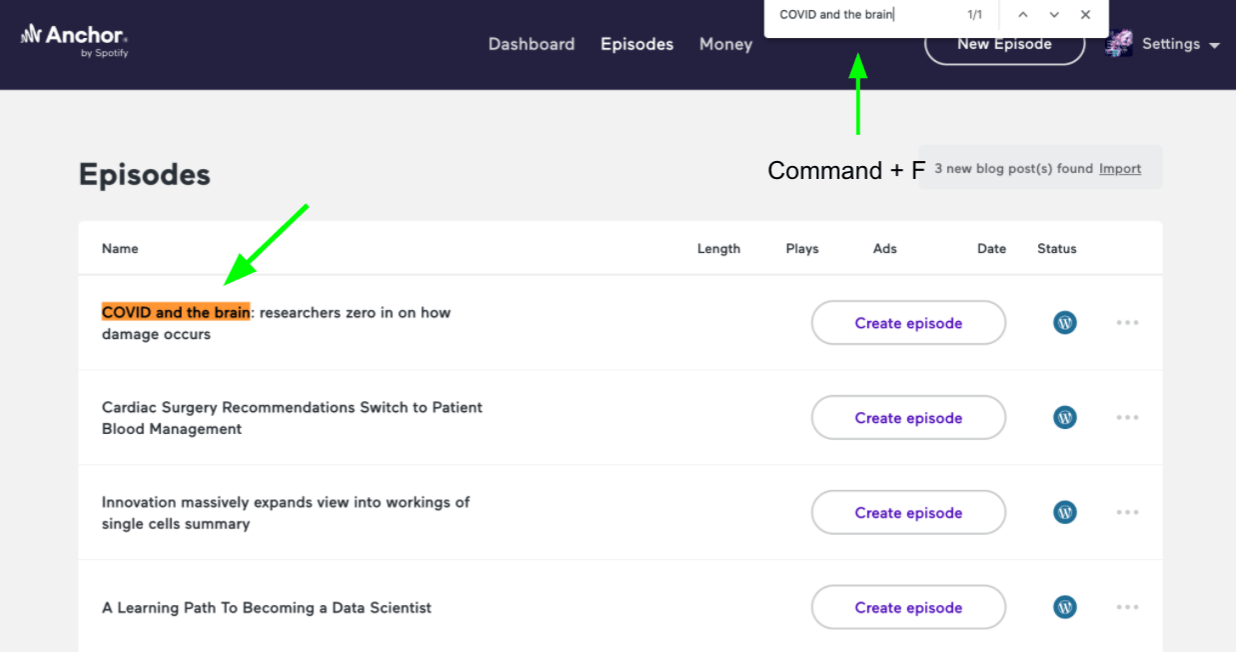
Once you have linked your account, you will want to go to the tab for “Episodes”.
On the episodes tab, there should be a button that allows you to import articles from your WordPress account.
Unfortunately, as of this update, Anchor does not have a feature to allow users to search for a specific article. I have spoken with workers from Anchor who have told me they will work on implementing this feature right away so check and see if they have finished implementing a search bar or some other way to filter. As of this update, the articles are loaded in chronologically with the most recent articles appearing on the first page.
If you are looking to convert an article that was recently published on WordPress, it should appear on this page or one of the first few.
One option you have to try to find specific articles is to use the (command F) feature of a mac or the (control F) feature of windows. This allows you to search for a specific keyword within a page.
With the publishing date of the article you are looking for in mind, you should be able to find the article within a few minutes. Articles that were published earlier will take longer to find than articles published in the last couple weeks. Many of the articles have dates in their titles so as you go through the pages, you will be able to tell if you have passed your articles if the dates in the titles are from before when the one you are looking for was published. Similarly, you will know you have not arrived yet if the titles are from dates after the one you are looking for.
Each time you go to a new page, you will need to press the (command F) function, and then the (return) with the title (or a keyword or phrase from the title you are looking for) in the search bar. This will quickly search the page and tell you if the title you are looking for is there. If no results are found, you know you can go to the next one.
I have found this speeds up the process as I get in a rhythm of pressing the button for the next page and then quickly searching the page I am on.
If you do not press (command F) function, and then the (return), the search tool will not update and tell you if the word you are looking for is in the page.
You may want to play around with these features with an article on the first page or two to make sure you understand before searching for an article published several years ago.
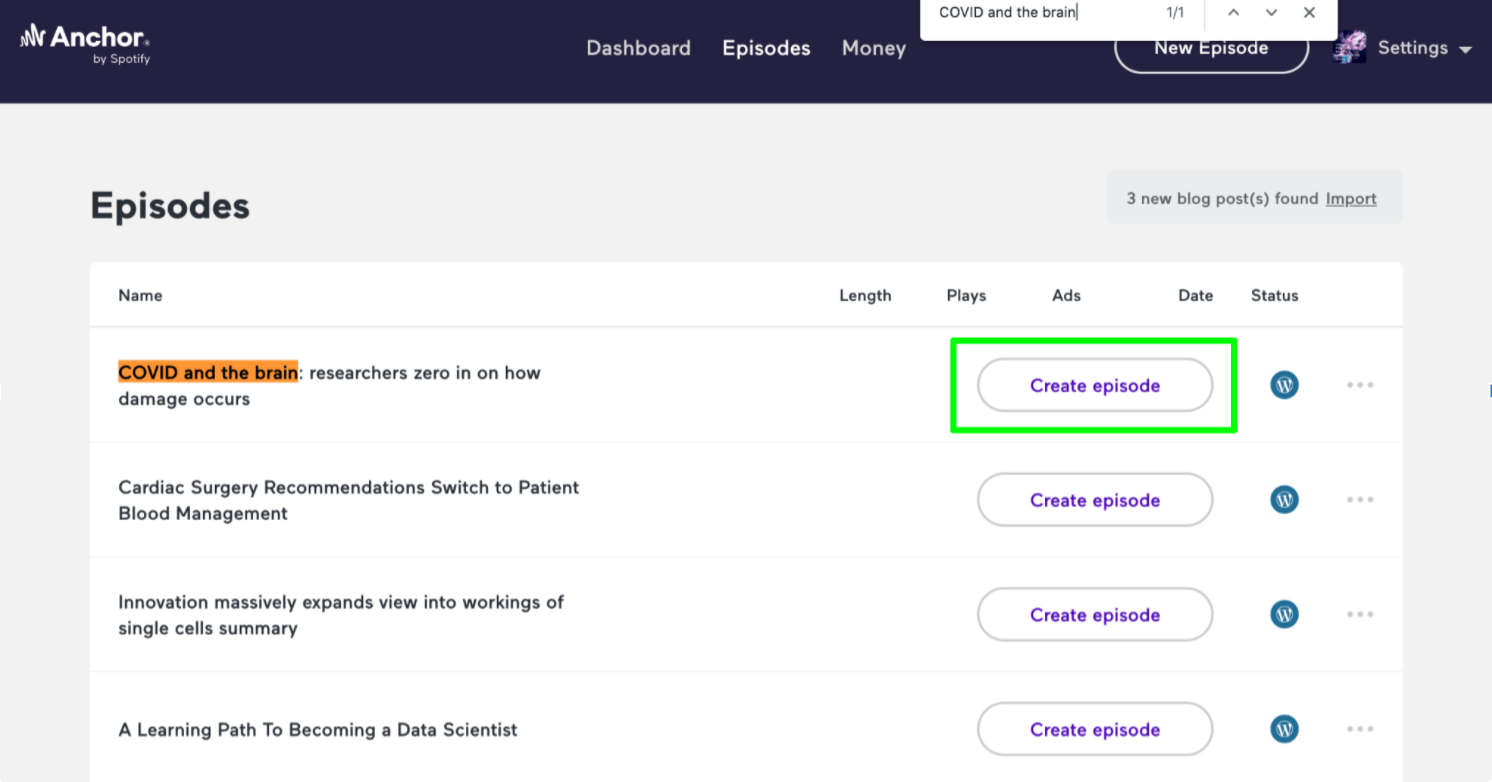
Once you have found the article you are looking for, you will then press the large create episode button.
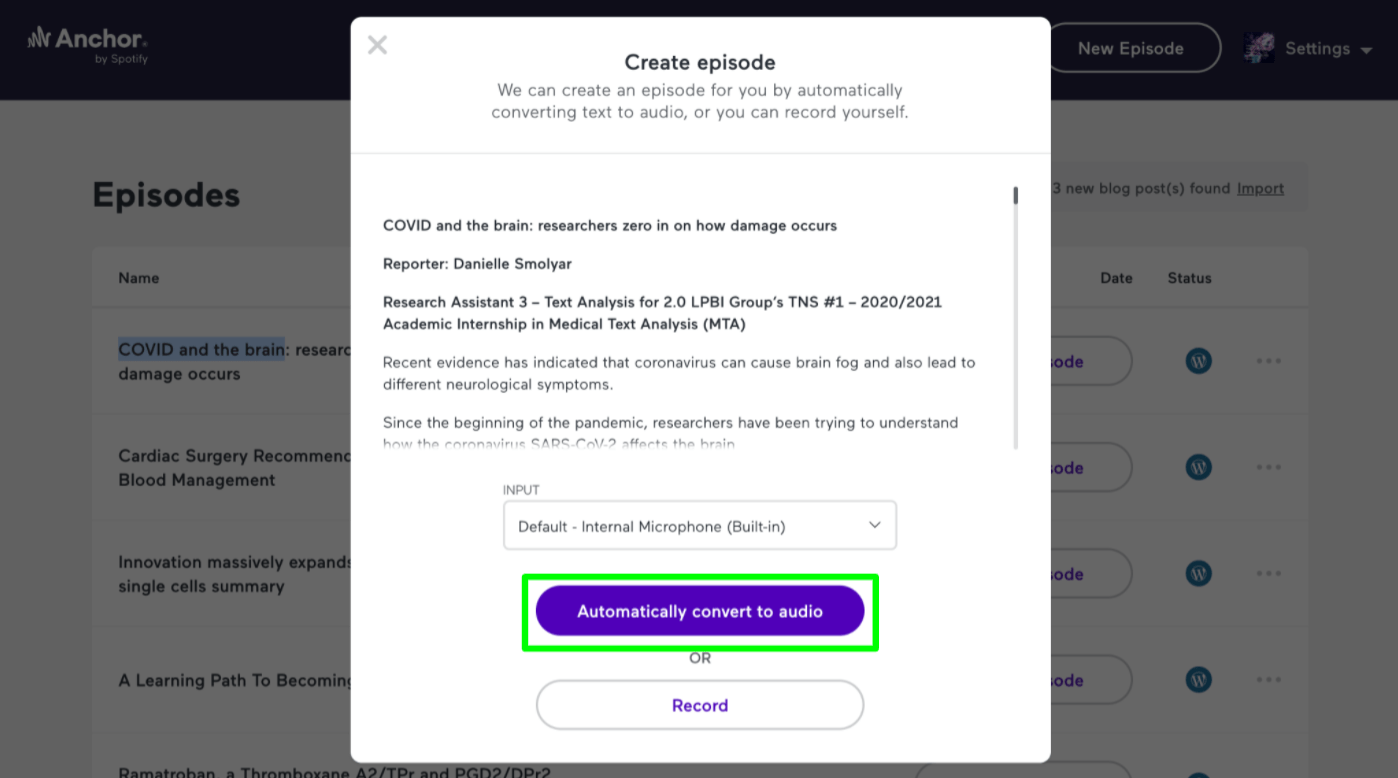
You will then be presented with the option to “Automatically convert to audio” or “Record” yourself.
If you would like to quickly automatically convert the article, select that option.
There are several voices you will then be able to select from. You choose the one you like most.
Anchor then converts the entire article.
As of now there is no way to select only a portion of the text to convert so the entire article (including headers and captions) will be converted.
Once the article is converted, you will then press the “Save and continue” button.
Several optional features will then pop up. If you would like to add a song or messages to your podcast, this is the place where you would do it. Once the podcast is how you would like it, you then press the “Save changes” button.
If you would like to update the episodes “Cover art”. Select the pencil to the right of the podcast.
Scroll to the bottom and upload whatever image you would like.
Embedding a Podcast into an article
Once you have published an article on Anchor, you are now able to embed it within your article for viewers to listen and read at the same time.
When on Anchor, make sure you are on the Dashboard. There, you should see a button that says “View public site”. Click this button.
You will then be directed to a page that gives several options. You will then press the button that says “Listen on Spotify”
This will then take you to a page on Spotify instead of Anchor. Here, you will see all articles published using your anchor account. It may take a couple minutes for recently converted articles to show up on this page.
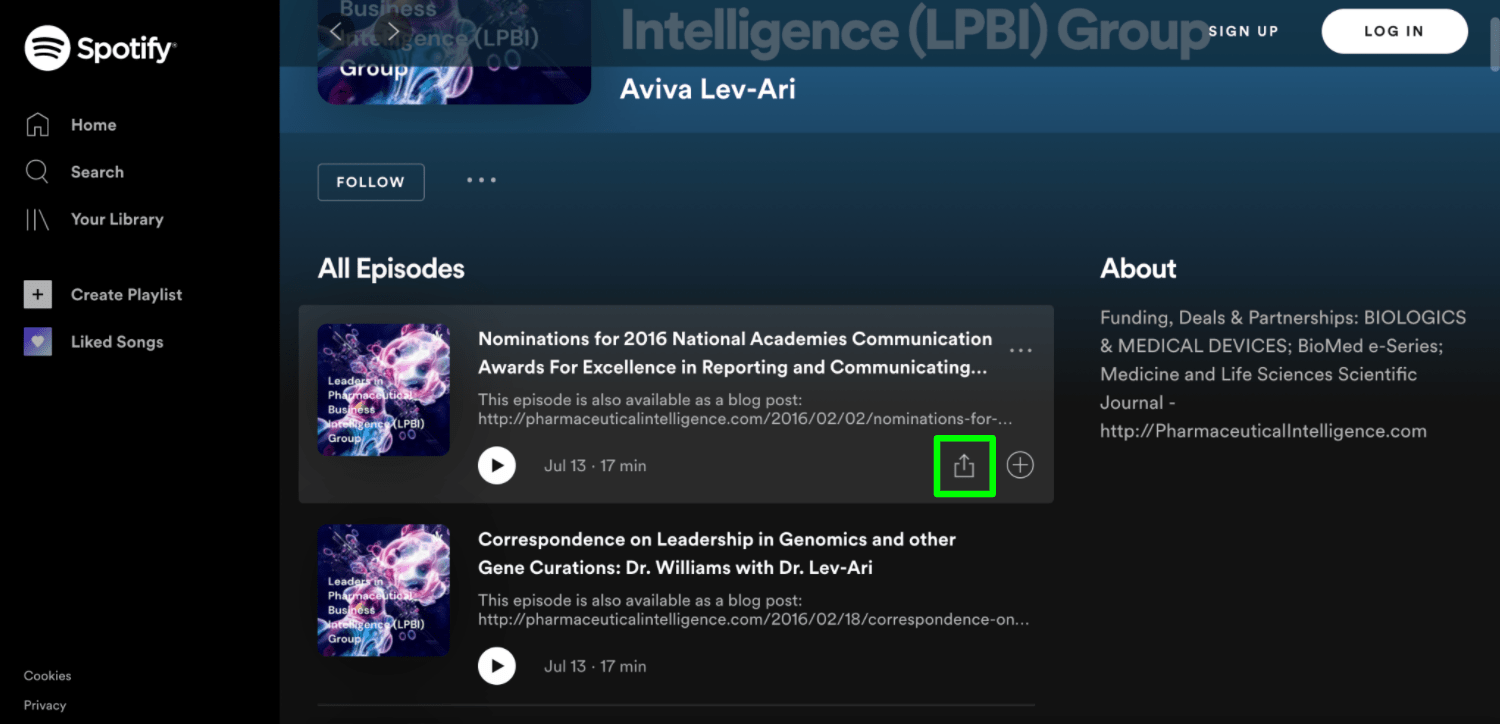
Once you see your podcast title, when you hover your mouse over the podcast, a box with an arrow pointing upwards will appear in the bottom right of your highlighted podcast. When you click this button, it will copy a link to your podcast on Spotify. You will use this link to embed your podcast.
Returning back to your WordPress article, insert a block where you would like your podcast to be embedded. When you press the plus button to insert a block, choose the browse all option. Scroll all the way down to embeds and select the one with the Spotify icon.
You will then be able to past the link you previously copied from Spotify, and your podcast will now be embedded.
Editing a previously published podcast
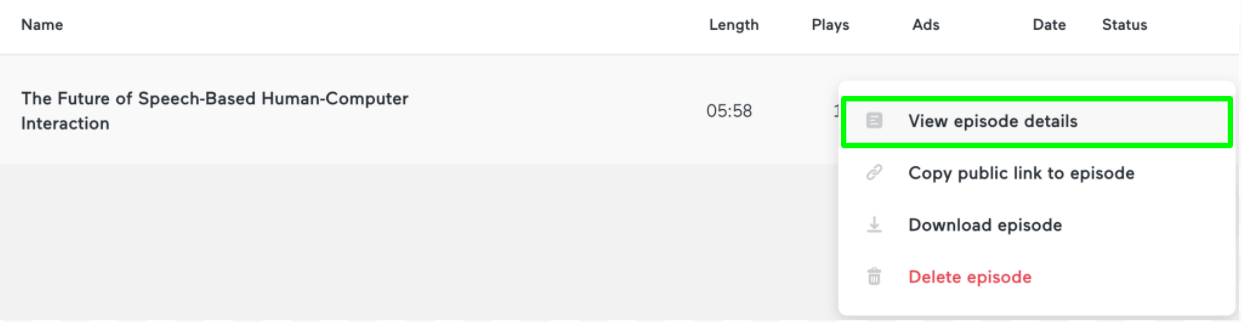
Anchor stores all previously published podcasts in the Episodes tab.
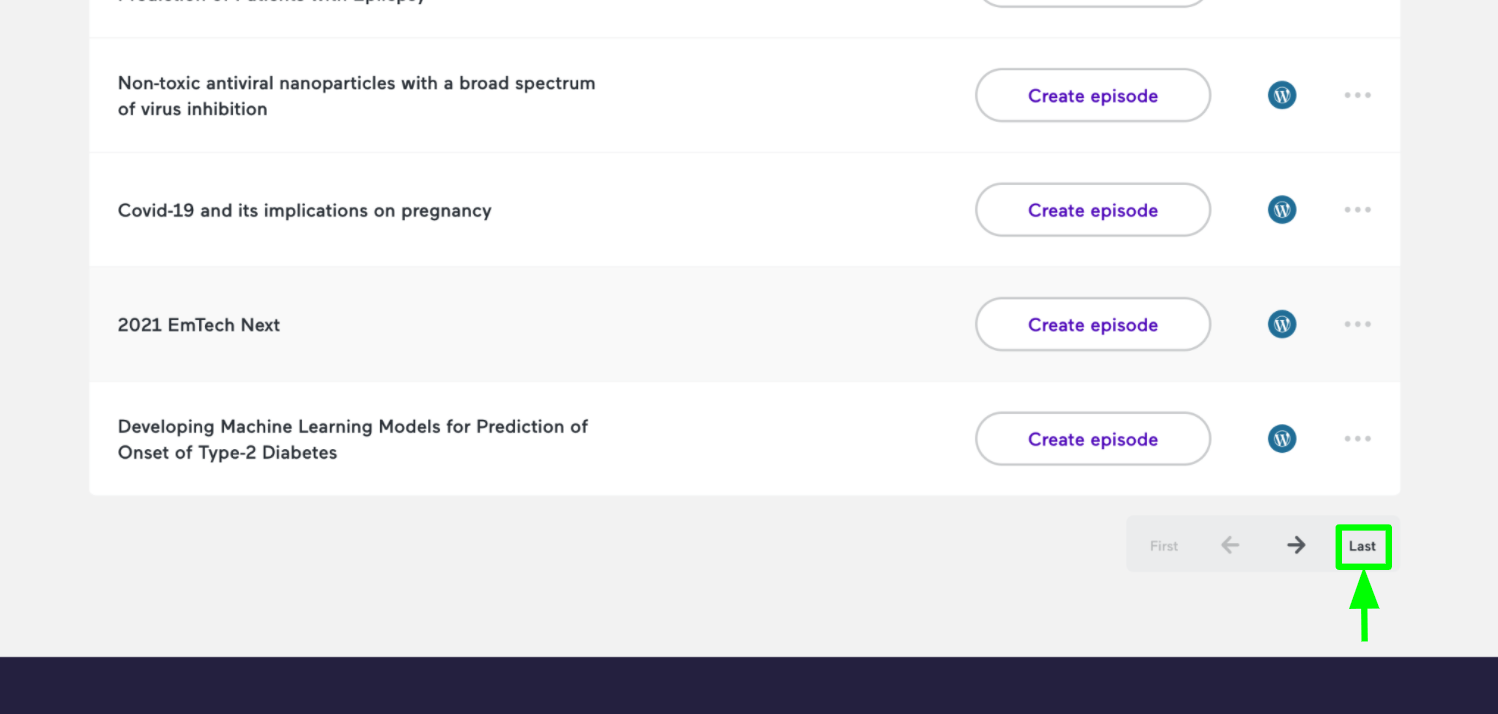
Once you are in Episodes, select the button in the bottom right that says “Last”. This will take you to where all published podcasts are.
If you would like to edit a podcast, click the three dots to the right of the podcast and select “View episode details”
BurstIQ and The National Center for Advancing Translational Sciences (NCATS) At The National Institutes of Health (NIH) Collaborate to Apply Blockchain to Intellectual Property Management
Reporter: Aviva Lev-Ari, PhD, RN
The collaboration between National Center for Advancing Translational Sciences (NCATS) at NIH and BurstIQ
will transform how IP-sensitive data is managed and shared across the NCATS’ network
DENVER, May 25, 2021 /PRNewswire/ —BurstIQ, the leading provider of blockchain-based data exchange solutions, announced today that the company has entered into a research collaboration agreement with The National Center for Advancing Translational Sciences (NCATS) at the National Institutes of Health (NIH) to address the protection of intellectual property associated with NCATS’ work on translational science.
BurstIQ
The collaboration focuses on development of artificial intelligence/machine learning models for modulating investigators’ data access within collaborative research environments. The segmentation, encryption, and secure storage of chemical information happens seamlessly and data access is enforced with minimal manual intervention and management. The technology enables evidence-based synthesis route design with the help of electronic laboratory notebooks (eLNs) while protecting IP-sensitive chemical information of active research projects.
The collaboration leverages BurstIQ’s groundbreaking blockchain-based secure data exchange platform, which allows governments and organizations to manage the ownership and sharing of sensitive data using dynamic consent and multi-level governance. The platform combines blockchain, best-in-class data security, and orchestration, allowing organizations to build and manage secure data networks in which highly sensitive data can be seamlessly contributed, verified and shared with ownership, governance, and automation built in.
The initial project will integrate BurstIQ’s blockchain platform with NCATS/NIH’s computational infrastructure that is designed to streamline the translational research process so that new treatments and cures for disease can be delivered to patients faster.
“For research communities, the ability to maintain intellectual property ownership is critical,” says Frank Ricotta, CEO of BurstIQ. “In the past, this has been a barrier to collaborative research. This collaboration with NCATS is designed break down this barrier and make it possible for researchers to share ideas and information with each other confidently, which will truly accelerate the pace of discovery.”
To learn more about BurstIQ’s collaboration with NCATS and how the companies are working together to drive collaborative research, please contact us at info@burstiq.com.
About BurstIQ™ BurstIQ is the leading provider of blockchain-enabled data solutions for the identity, healthcare, and life sciences industries. The company’s secure data exchange network allows organizations to build secure networks to manage the ownership and sharing of sensitive data, with ownership, consent, governance, and workflow orchestration built in. The platform combines blockchain, Big Data, and best-in-class security to build multi-dimensional profiles of people, places, and things and empower the interactions between them. The result is a global, secure data network that allows health systems, payers, digital health companies, pharma & life science companies, and governments to collaborate, share, discover, and build the impossible. For more information visit: Website | Facebook | Twitter | LinkedIn
2021 Virtual World Medical Innovation Forum, Mass General Brigham, Gene and Cell Therapy, VIRTUAL May 19–21, 2021
Reporter: Aviva Lev-Ari, PhD, RN
The 2021 Virtual World Medical Innovation Forum will focus on the growing impact of gene and cell therapy.Senior healthcare leaders from all over look to shape and debate the area of gene and cell therapy. Our shared belief: no matter the magnitude of change, responsible healthcare is centered on a shared commitment to collaborative innovation–industry, academia, and practitioners working together to improve patients’ lives.
About the World Medical Innovation Forum
Mass General Brigham is pleased to present the World Medical Innovation Forum (WMIF) virtual event Wednesday, May 19 – Friday, May 21. This interactive web event features expert discussions of gene and cell therapy (GCT) and its potential to change the future of medicine through its disease-treating and potentially curative properties. The agenda features 150+ executive speakers from the healthcare industry, venture, startups, life sciences manufacturing, consumer health and the front lines of care, including many Harvard Medical School-affiliated researchers and clinicians. The annual in-person Forum will resume live in Boston in 2022. The World Medical Innovation Forum is presented by Mass General Brigham Innovation, the global business development unit supporting the research requirements of 7,200 Harvard Medical School faculty and research hospitals including Massachusetts General, Brigham and Women’s, Massachusetts Eye and Ear, Spaulding Rehab and McLean Hospital. Follow us on Twitter: twitter.com/@MGBInnovation
Accelerating the Future of Medicine with Gene and Cell Therapy What Comes Next
Cryo-EM disclosed how the D614G mutation changes SARS-CoV-2 spike protein structure.
Reporter: Dr. Premalata Pati, Ph.D., Postdoc
SARS-CoV-2, the virus that causes COVID-19, has had a major impact on human health globally; infecting a massive quantity of people around 136,046,262 (John Hopkins University); causing severe disease and associated long-term health sequelae; resulting in death and excess mortality, especially among older and prone populations; altering routine healthcare services; disruptions to travel, trade, education, and many other societal functions; and more broadly having a negative impact on peoples physical and mental health.
It’s need of the hour to answer the questions like what allows the variants of SARS-CoV-2 first detected in the UK, South Africa, and Brazil to spread so quickly? How can current COVID-19 vaccines better protect against them?
Bing Chen, HMS professor of pediatrics at Boston Children’s, and colleagues analyzed the changes in the structure of the spike proteins with the genetic change by D614G mutation by all three variants. Hence they assessed the structure of the coronavirus spike protein down to the atomic level and revealed the reason for the quick spreading of these variants.
This model shows the structure of the spike protein in its closed configuration, in its original D614 form (left) and its mutant form (G614). In the mutant spike protein, the 630 loop (in red) stabilizes the spike, preventing it from flipping open prematurely and rendering SARS-CoV-2 more infectious.
Fig. 1. Cryo-EM structures of the full-length SARS-CoV-2 S protein carrying G614.
(A) Three structures of the G614 S trimer, representing a closed, three RBD-down conformation, an RBD-intermediate conformation and a one RBD-up conformation, were modeled based on corresponding cryo-EM density maps at 3.1-3.5Å resolution. Three protomers (a, b, c) are colored in red, blue and green, respectively. RBD locations are indicated. (B) Top views of superposition of three structures of the G614 S in (A) in ribbon representation with the structure of the prefusion trimer of the D614 S (PDB ID: 6XR8), shown in yellow. NTD and RBD of each protomer are indicated. Side views of the superposition are shown in fig. S8.
The mutant spikes were imaged by Cryo-Electron microscopy (cryo-EM), which has resolution down to the atomic level. They found that the D614G mutation (substitution of in a single amino acid “letter” in the genetic code for the spike protein) makes the spike more stable as compared with the original SARS-CoV-2 virus. As a result, more functional spikes are available to bind to our cells’ ACE2 receptors, making the virus more contagious.
Fig. 2. Cryo-EM revealed how the D614G mutation changes SARS-CoV-2 spike protein structure.
Say the original virus has 100 spikes,” Chen explained. “Because of the shape instability, you may have just 50 percent of them functional. In the G614 variants, you may have 90 percent that is functional. So even though they don’t bind as well, the chances are greater and you will have an infection
Forthcoming directions by Bing Chen and Team
The findings suggest the current approved COVID-19 vaccines and any vaccines in the works should include the genetic code for this mutation. Chen has quoted:
Since most of the vaccines so far—including the Moderna, Pfizer–BioNTech, Johnson & Johnson, and AstraZeneca vaccines are based on the original spike protein, adding the D614G mutation could make the vaccines better able to elicit protective neutralizing antibodies against the viral variants
Chen proposes that redesigned vaccines incorporate the code for this mutant spike protein. He believes the more stable spike shape should make any vaccine based on the spike more likely to elicit protective antibodies. Chen also has his sights set on therapeutics. He and his colleagues are further applying structural biology to better understand how SARS-CoV-2 binds to the ACE2 receptor. That could point the way to drugs that would block the virus from gaining entry to our cells.
In January, the team showed that a structurally engineered “decoy” ACE2 protein binds to SARS-CoV-2 200 times more strongly than the body’s own ACE2. The decoy potently inhibited the virus in cell culture, suggesting it could be an anti-COVID-19 treatment. Chen is now working to advance this research into animal models.
Main Source:
Abstract
Substitution for aspartic acid by glycine at position 614 in the spike (S) protein of severe acute respiratory syndrome coronavirus 2 appears to facilitate rapid viral spread. The G614 strain and its recent variants are now the dominant circulating forms. We report here cryo-EM structures of a full-length G614 S trimer, which adopts three distinct prefusion conformations differing primarily by the position of one receptor-binding domain. A loop disordered in the D614 S trimer wedges between domains within a protomer in the G614 spike. This added interaction appears to prevent premature dissociation of the G614 trimer, effectively increasing the number of functional spikes and enhancing infectivity, and to modulate structural rearrangements for membrane fusion. These findings extend our understanding of viral entry and suggest an improved immunogen for vaccine development.
Comparing COVID-19 Vaccine Schedule Combinations, or “Com-COV” – First-of-its-Kind Study will explore the Impact of using eight different Combinations of Doses and Dosing Intervals for Different COVID-19 Vaccines