Deciphering the Epigenome
Curator: Larry H. Bernstein, MD, FCAP
UPDATED on 1/29/2016

2.2.10 Deciphering the Epigenome, Volume 2 (Volume Two: Latest in Genomics Methodologies for Therapeutics: Gene Editing, NGS and BioInformatics, Simulations and the Genome Ontology), Part 2: CRISPR for Gene Editing and DNA Repair
RNA Epigenetics
DNA isn’t the only decorated nucleic acid in the cell. Modifications to RNA molecules are much more common and are critical for regulating diverse biological processes.
By Dan Dominissini, Chuan He and Gidi Rechavi | January 1, 2016
RNA SOUP: Newly transcribed messenger RNA exiting the nucleus via nuclear pores
© BENJAMIN CAMPILLO/SCIENCE SOURCE
http://www.the-scientist.com/January2016/feature2.jpg
For years, researchers described DNA and RNA as linear chains of four building blocks—the nucleotides A, G, C, and T for DNA; and A, G, C, and U for RNA. But these information molecules are much more than their core sequences. A variety of chemical modifications decorate the nucleic acids, increasing the alphabet of DNA to about a dozen known nucleotide variants. The alphabet of RNA is even more impressive, consisting of at least 140 alternative nucleotide forms. The different building blocks can affect the complementarity of the RNA molecules, alter their structure, and enable the binding of specific proteins that mediate various biochemical and cellular outcomes.
The large size of RNA’s vocabulary relative to that of DNA’s is not surprising. DNA is involved mainly with genetic information storage, while RNA molecules—mRNA, rRNA, tRNA, miRNA, and others—are engaged in diverse structural, catalytic, and regulatory activities, in addition to translating genes into proteins. RNA’s multitasking prowess, at the heart of the RNA World hypothesis implicating RNA as the first molecule of life, likely spurred the evolution of numerous modified nucleotides. This enabled the diversified complementarity and secondary structures that allow RNA species to specifically interact with other components of the cellular machinery such as DNA and proteins.
Methylating RNA
The nucleotide building blocks of RNA contain pyrimidine or purine rings, and each position of these rings can be chemically altered by the addition of various chemical groups. Most frequently, a methyl (–CH3) group is tacked on to the outside of the ring. Other chemical additions such as acetyl, isopentenyl, and threonylcarbamoyl are also found added to RNA bases.
Among the 140 modified RNA nucleotide variants identified, methylation of adenosine at the N6 position (m6A) is the most prevalent epigenetic mark in eukaryotic mRNA. Identified in bacterial rRNAs and tRNAs as early as the 1950s, this type of methylation was subsequently found in other RNA molecules, including mRNA, in animal and plant cells as well. In 1984, researchers identified a site that was specifically methylated—the 3′ untranslated region (UTR) of bovine prolactin mRNA.1 As more sites of m6A modification were identified, a consistent pattern emerged: the methylated A is preceded by A or G and followed by C (A/G—methylated A—C).
The alphabet of RNA consists of at least 140 alternative nucleotide forms.
Although the identification of m6A in RNA is 40 years old, until recently researchers lacked efficient molecular mapping and quantification methods to fully understand the functional implications of the modification. In 2012, we (D.D. and G.R.) combined the power of next-generation sequencing (NGS) with traditional antibody-mediated capture techniques to perform high-resolution transcriptome-wide mapping of m6A, an approach we termed m6A-seq.2 Briefly, the transcriptome is randomly fragmented and an anti-m6A antibody is used to fish out the methylated RNA fragments; the m6A-containing fragments are then sequenced and aligned to the genome, thus allowing us to locate the positions of methylation marks.
Analyzing the human transcriptome in this way, we identified more than 12,000 methylated sites in mRNA molecules derived from approximately 7,000 protein-coding genes. The transcripts of most expressed genes, in a variety of cell types, were shown to be methylated, indicating that m6A modifications are widespread. In addition, about 250 noncoding RNA sequences—including well-characterized long noncoding RNAs (lncRNAs), such as the XIST transcripts that have a key role in X-chromosome inactivation—are decorated by m6A. In almost all cases, the epigenetic mark was found on adenosines embedded in the predicted A/G—methylated A—C sequence. We found that this pattern was consistently preceded by an additional purine (A or G) and followed by a uracil (U), extending the known consensus sequence to A/G—A/G—methylated A—C—U.2
At the macro level, we found that m6A methylation sites were enriched at two distinct landmarks. The highest relative representation of m6A was found in the stop codon–3′ UTR segment of the RNA, with nearly a third of such methylation found in this sequence just beyond a gene’s coding region. Within the coding regions of the RNA molecules, m6A enrichment mapped to unusually long internal exons; 87 percent of the exonic methylation peaks were found in exons longer than 400 nucleotides. (The average human exon is only 145 nucleotides in length). This pattern of decoration of transcribed RNA suggests that m6A is involved in the mediation of splicing of long-exon transcripts. RNAs transcribed from single-isoform genes were found to be relatively undermethylated, while transcripts that are known to have multiple isoforms, determined by alternative splicing patterns, were hypermethylated.2 Moreover, specific alternative splicing types, such as intron retention, exon skipping, and alternative first or last exon usage, were highly correlated with m6A decoration. And silencing the m6A methylating protein METTL3 affected global gene expression and alternative splicing patterns in both human and mouse cells.2
These findings clearly indicate the importance of m6A decoration in regulating the expression of diverse transcripts. Moreover, our parallel study of the human and mouse methylome by m6A-seq has uncovered a remarkable degree of conservation in both consensus sequence and areas of enrichment, further supporting the importance of m6A function.2 But research into understanding how m6A marks themselves are regulated, and how this affects various cellular processes, is only just beginning.
Writers, erasers, and readers
The accumulating findings regarding the cellular consequences of m6A transcriptome decoration led to the search for the mediators that enable m6A to exert its influence. Epigenetic marks are introduced by enzymes and cofactors known as “writers,” and m6A is no exception. This mark is added to RNA by a large protein complex that includes three well-characterized components: METTL3, METTL14, and WTAP.3,4 (See illustration on opposite page.)
The transcripts of most expressed genes, in a variety of cell types, were shown to be methylated.
The reverse process of RNA demethylation is performed by “erasers.” In 2011, one of us (C.H.) and an international group of colleagues identified the first m6A eraser: the fat mass and obesity–associated protein (FTO).5 Four years earlier, three independent studies had discovered that a single-nucleotide polymorphism in the first intron of Fto was strongly associated with body mass index and obesity risk, and studies of mouse models where Fto was deleted or overexpressed further demonstrated its link with altered body weight. The research from the C.H. group showed that silencing the Fto gene or protein increased total m6A levels, while overexpression decreased levels of the epigenetic mark.5 C.H.’s group later discovered that another protein from the same protein family as FTO, ALKBH5, behaves as an active m6A demethylase.6 In contrast to the ubiquitous expression of Fto in all tissues, the highest expression level of Alkbh5 was demonstrated in mouse testes. Indeed, Alkbh5-null male mice exhibit aberrant spermatogenesis, probably a result of m6A-mediated altered expression of spermatogenesis-related genes.6
RNA METHYLATION DYNAMICS: At least 140 alternative RNA nucleotide forms exist. On mRNA, the most common is the methylation of adenosine on the N6 position (m6A). This epigenetic mark is laid down by a “writer” protein complex that includes three well-characterized components: METTL3, METTL14, and WTAP. The reverse process of RNA demethylation is performed by “erasers,” such as the enzymes FTO and ALKBH5.
http://www.the-scientist.com/January2016/methylation2.jpg
See full infographic: WEB | PDF THE SCIENTIST STAFF
These writers and erasers facilitate the dynamic nature of m6A methylation, which was shown when we (D.D. and G.R.) demonstrated changes in response to environmental stimuli, such as UV irradiation, heat shock, and exposure to interferon gamma or hepatocyte growth factor.2 Once RNA epigenetic modifications are laid down, they are recognized by specific “reader” proteins that bind to the modified nucleotide and mediate enhancement or inhibition of gene expression. In 2012, the G.R. group used methylated and nonmethylated versions of synthetic RNA baits that include the m6A consensus sequence to identify such readers of m6A.2 By preferential binding to the methylated bait, we isolated several specific m6A-binding proteins, including members of the RNA-binding YTH domain family, whose function was previously unknown.2
The finding of the first m6A-binding reader proteins has accelerated the deciphering of the various molecular and cellular processes mediated by m6A marking. In 2014, for example, we (C.H. and colleagues) showed that the human YTH domain family 2 (YTHDF2) reader protein selectively recognizes m6A and mediates mRNA degradation.7 We identified more than 3,000 cellular RNA targets of YTHDF2, most of which are mRNAs. Binding of YTHDF2 to m6A in mRNA results in the translocation of bound mRNA from the translatable pool to mRNA decay sites, such as processing bodies in the cytoplasm where mRNA turnover is regulated.
Recently, C.H. and colleagues identified another m6A reader protein, YTHDF1, with a very different function—stimulating protein synthesis by ramping up the efficiency of translation machinery.8 The dueling functions of YTHDF2 and YTHDF1 provide a mechanism by which cells can adjust gene expression promptly and precisely to environmental stimuli. Finally, G.R. and his group have identified an additional reader protein, the RNA-binding protein heterogeneous nuclear ribonucleoprotein A2B1 (HNRNPA2B1),2 which directly binds a set of m6A decorated transcripts and mediates alternative splicing.9
Clearly, m6A plays diverse roles in regulating cellular function, starting with basic processes such as gene expression, translation, and alternative splicing. As work on this epigenetic mark continues, we will undoubtedly link m6A to numerous phenotypes, and its dysregulation may undergird various diseases and syndromes.
RNA epigenetics in action
Understanding the molecular mechanisms by which m6A regulation controls RNA stability, translation efficiency, and alternative splicing is helping researchers decipher the importance of this new epigenetic mark in physiological and pathological processes. For example, researchers recently showed that translation increases in stressed mice thanks to m6A decoration. In 2015, two studies from Cornell University and Weill Cornell Medical College found increased m6A methylation of specific 5′ UTR adenosines in newly transcribed mRNAs as a result of stress-induced nuclear localization of the m6A YTHDF2 reader. The researchers suggested that the nuclear YTHDF2 preserves the unique 5′ UTR m6A methylation of stress-induced transcripts by limiting the demethylation activity of the FTO eraser. Increased 5′ UTR m6A methylation in turn promotes translation of specific transcripts, such as those for the heat shock protein Hsp70. While conventional mRNA translation starts by binding of the ribosome components to a region of the 5′ UTR marked by the unusual nucleotide 7meG (the “cap”), under stress conditions initiation of translation can start farther downstream.10
DECIDING CELL FATE: Among its many roles in the cell, m6A methylation helps regulate the expression of RNA transcripts that mediate the transition from pluripotency to differentiation. The presence of m6A appears to decrease the stability of transcripts important for maintaining pluripotency, priming the cells for future differentiation. The loss of METTL3, an m6A methlyase component, in mouse embryonic stem cells leads to the cells’ inability to exit the pluripotent state, a lethal outcome in the early embryos.
http://www.the-scientist.com/January2016/feature2_21.jpg
See full infographic: WEB THE SCIENTIST STAFF
In a second study, Weill Cornell Medical College’s Samie Jaffrey, who collaborated on the previous study, led a team that showed m6A-methylated mRNAs can be translated in a cap-independent manner. The researchers showed that a specific 5′ UTR m6A binds the eukaryotic initiation factor 3 (eIF3), which recruits the ribosomal 43S complex and initiates cap-independent translation. This study also demonstrated increased m6A levels in the Hsp70 mRNA that enhanced its cap-independent translation following heat-shock stress.11
Other work has hinted at m6A’s role in the regulation of circadian rhythms. Researchers identified m6A sites on many transcripts of genes involved in the regulation of daily cycles. Inhibition of m6A methylation by silencing of the METTL3 writer led to circadian period elongation, with altered distribution and processing of the transcripts of the clock genes Per2 and Arntl.12
It’s quickly becoming clear that m6A decoration has diverse cellular and physiological functions. But perhaps the best illustration of its critical ability to precisely control processes at the cellular level is its involvement in early embryogenesis. Cell-fate decisions are coordinated by alterations in global gene expression, which are orchestrated by epigenetic regulation. Well-established epigenetic marks, such as DNA methylation and histone modifications, are known to mediate embryonic stem cell (ESC) cell-fate decisions, and it turns out that m6A modification is no different.
Dynamic m6A RNA markings, the new kid on the epigenetic block, herald the era of tripartite epigenetics where modifications of DNA, RNA, and proteins join hands to fine-tune gene expression and to execute prompt and precise responses to environmental stimuli and stresses.
We (G.R. and collaborators) and other groups recently demonstrated that the m6A writer METTL3 is also an essential regulator for termination of mouse embryonic stem cell pluripotency. Knocking out Mettl3 in preimplantation murine epiblasts and in undifferentiated ESCs led to depletion of m6A in mRNAs. Cell viability was not affected, suggesting that m6A decoration is not essential for the maintenance of the ESC naive state, but m6A marks were critical for early differentiation. The loss of this modification led to aberrant and restricted lineage priming at the post-implantation stage, resulting in early embryonic lethality.13 The presence of m6A also decreased mRNA stability, including in those transcripts important for maintaining pluripotency. These findings demonstrated, for the first time, an essential function for an mRNA modification in vivo.14
Beyond mRNA
While m6A methylation is most prevalent on mRNAs, this mark also decorates other RNA species. It is well established, for example, that m6A is abundant on rRNAs, tRNAs, and small nuclear RNAs (snRNAs), which mediate splicing and other RNA processing and protein synthesis reactions.
More recently, researchers found that the reader protein HNRNPA2B1 binds to m6A marks in a subset of primary microRNA (miRNA) transcripts, recruiting the miRNA-microprocessor complex and promoting primary miRNA processing that is essential for mature miRNA biogenesis.9 Not only is the biogenesis of miRNA regulated by m6A marking and recruitment of HNRNPA2B1, miRNAs themselves appear to play a role in the placement of the m6A epigenetic marks. MiRNAs regulate m6A modification in specific transcript sites using a sequence-pairing mechanism where the “seed” sequence of a specific miRNA binds a complementary target sequence in the 3′ UTR of mRNA and directs methylation.15 The interaction is bidirectional: manipulation of miRNA sequence or expression affects m6A modification also by reducing binding of the METTL3 writer to the target mRNA sites.
Similarly, m6A appears to be involved in structural alterations of mRNAs and lncRNAs to facilitate binding of heterogeneous nuclear ribonucleoprotein C (HNRNPC), an abundant RNA-binding protein responsible for mRNA processing. This novel mechanism, termed m6A-switch, was shown to affect alternative splicing and abundance of multiple target mRNAs.16 Taken together, these results demonstrate that m6A is an important mark on diverse RNA species.
Dynamic m6A RNA markings, the new kid on the epigenetic block, herald the era of tripartite epigenetics where modifications of DNA, RNA, and proteins join hands to fine-tune gene expression and to execute prompt and precise responses to environmental stimuli and stresses. Indeed, m6A is just one of 140 modified RNA nucleotides that likely affect the function of the nucleic acid messenger and key cellular actor in diverse ways. Molecular approaches are paving the way for the study of additional RNA modifications.
As the list of RNA epigenetic marks continues to expand, researchers will gain a clearer picture of how diverse cellular processes are regulated. The extremely large repertoire of such modifications is expected to reveal various RNA marks analogous to the known DNA and histone epigenetic marks, and the various modifications of DNA, RNA, and proteins can enrich the language that allows the development, adaptation, and diversity of complex organisms.
Dan Dominissini is a postdoctoral fellow in Chuan He’s group at the University of Chicago. Gidi Rechavi is a pediatric hematologist-oncologist and a researcher in genetics and genomics at the Chaim Sheba Medical Center in Tel Hashomer, Israel, and a Professor of Hematology at the Sackler School of Medicine at Tel Aviv University. Sharon Moshitch-Moshkovitz, a senior researcher in RNA biology at the Chaim Sheba Medical Center, also contributed to this article.
References
- S. Horowitz et al., “Mapping of N6-methyladenosine residues in bovine prolactin mRNA,” PNAS, 81:5667-71, 1984.
- D. Dominissini et al., “Topology of the human and mouse m6A RNA methylomes revealed by m6A-seq,” Nature, 485:201-06, 2012.
- Y. Fu et al., “Gene expression regulation mediated through reversible m6A RNA methylation,” Nat Rev Genet, 15:293-306, 2014.
- K.D. Meyer, S.R. Jaffrey, “The dynamic epitranscriptome: N6-methyladenosine and gene expression control,” Nat Rev Mol Cell Biol, 15:313-26, 2014.
- G. Jia et al., “N6-methyladenosine in nuclear RNA is a major substrate of the obesity-associated FTO,” Nat Chem Biol, 7:885-87, 2011.
- G. Zheng et al., “ALKBH5 is a mammalian RNA demethylase that impacts RNA metabolism and mouse fertility,” Mol Cell, 49:18-29, 2013.
- X. Wang et al., “N6-methyladenosine-dependent regulation of messenger RNA stability,” Nature, 505:117-20, 2014.
- X. Wang et al., “N6-methyladenosine modulates messenger RNA translation efficiency,” Cell, 161:1388-99, 2015.
- C.R. Alarcón et al., “HNRNPA2B1 is a mediator of m6A-dependent nuclear RNA processing events,”Cell, 162:1299-308, 2015.
- J. Zhou et al., “Dynamic m6A mRNA methylation directs translational control of heat shock response,” Nature, 526:591-94, 2015.
- K.D. Meyer et al. “5′ UTR m6A promotes cap-independent translation,” Cell, 163:999-1010, 2015.
- J.-M. Fustin et al., “RNA-methylation-dependent RNA processing controls the speed of the circadian clock,” Cell, 155:793-806, 2013.
- S. Geula et al., “m6A mRNA methylation facilitates resolution of naive pluripotency toward differentiation,” Science, 347:1002-06, 2015.
- P.J. Batista et al., “m6A RNA modification controls cell fate transition in mammalian embryonic stem cells,” Cell Stem Cell, 15:707-19, 2014.
- T. Chen et al., “m6A RNA methylation is regulated by microRNAs and promotes reprogramming to pluripotency,” Cell Stem Cell, 16:289-301, 2015.
- N. Liu et al., “N6-methyladenosine-dependent RNA structural switches regulate RNA-protein interactions,” Nature, 518:560-64, 2015.
Tags
RNA methylation, RNA epigenetics, rna, methylation, epigenetics and epigenetic regulation
Telomerase Overdrive
Two mutations in a gene involved in telomere extension reverse the gene’s epigenetic silencing.
By Ashley P. Taylor | January 1, 2016
http://www.the-scientist.com//?articles.view/articleNo/44768/title/Telomerase-Overdrive/
EPIGENETIC ACTIVATION: A single base-pair mutation (lower allele) leads to epigenetic changes that promote expression of a telomerase gene.COURTESY OF JOSH STERN
http://www.the-scientist.com/January2016/shortlit2.jpg
EDITOR’S CHOICE IN GENETICS & GENOMICS
The paper
J.L. Stern et al., “Mutation of the TERT promoter, switch to active chromatin, and monoallelic TERTexpression in multiple cancers,” Genes Dev, doi:10.1101/gad.269498, 2015.
The foundation
Chromosome ends are slightly shortened with each DNA replication. Terminal repetitive sequences called telomeres buffer coding DNA from this fate. In stem cells, telomerase extends the telomeres so that cell division can continue, perhaps indefinitely. In somatic cells, telomerase is inactive in part because the gene encoding telomerase’s catalytic subunit, telomerase reverse transcriptase (TERT), is epigenetically silenced. In most cancers, however, telomerase is again turned on and aids proliferation.
The mutations
In 2013, researchers found two mutations in the TERT promoter that occur frequently in cancer cell lines and are tied with TERT expression.
Regulation
To probe the mechanism of TERT activation, Josh Stern, a postdoctoral fellow in the lab of Thomas Cech at the University of Colorado Boulder, studied cancer cell lines that were heterozygous for one of these TERTmutations. Stern and his colleagues determined that the mutant TERT allele had histone methylation marks associated with gene activation and was transcribed, whereas the wild-type allele bore other histone methylation marks characteristic of gene silencing and was not transcribed.
“It’s very nice biochemical work to show that a single-base-pair mutation in the cancer genome activates the expression of the telomerase gene,” says Dana-Farber Cancer Institute’s Franklin Huang.
Application
“Telomerase is a fantastic therapeutic target for cancers because so many cancers are absolutely reliant on telomerase,” says Stern. “These TERT promoter mutations only occur in cancer, so if we can understand the mechanism, then we can potentially develop a highly specific cancer therapeutic.”
Tags
transcription, telomeres, telomerase, mutation, literature, genetics & genomics, epigenetics and cancer
CRISPR Fixes Stem Cells Harboring Blindness-Causing Defect
http://www.genengnews.com/gen-news-highlights/crispr-fixes-stem-cells-harboring-blindness-causing-defect/81252293/
Marking yet another CRISPR-related first, scientists have replaced a defective gene associated with a sensory disease in stem cells that were derived from a patient’s tissue. The disease, retinitis pigmentosa (RP), is an inherited condition that degrades the retina and leads to blindness. A patient with the disease supplied a skin sample that was used to generate the stem cells, which were manipulated by means of the CRISPR/Cas9 gene-editing system.
CRISPR/Cas9, which zeroed in on a single disease-causing mutation in the RGPR gene, was able to make the necessary correction in 13% of the stem cells. This correction rate, according to the Columbia University and University of Iowa scientists who announced the results, is indicative of a practical approach—albeit one that still needs work. The Columbia/Iowa team added that they are working to show that their technique does not introduce any unintended genetic modifications in human cells, and that the corrected cells are safe for transplantation.
While the scientists freely acknowledge that their technique needs additional development before any cures are possible, they basked in the success of having accomplished a difficult genetic fix. The RGPR mutation that needed to be repaired sits in a highly repetitive sequence of the gene where it can be tricky to discriminate one region from another. In fact, it was not clear that CRISPR/Cas9 would be able to home in on and correct the point mutation.
The scientists described their work January 27 in the journal Scientific Reports in an article entitled “Precision Medicine: Genetic Repair of Retinitis Pigmentosa in Patient-Derived Stem Cells.”
“Fibroblasts cultured from a skin-punch biopsy of an XLRP patient were transduced to produce [induced pluripotent stem cells (iPSCs)] carrying the patient’s c.3070G > T mutation,” the authors wrote. “The iPSCs were transduced with CRISPR guide RNAs, Cas9 endonuclease, and a donor homology template. Despite the gene’s repetitive and GC-rich sequences, 13% of RPGR gene copies showed mutation correction and conversion to the wild-type allele.”
The authors asserted that theirs was the first report of CRISPR/Cas9 being used to correct a pathogenic mutation in iPSCs derived from a patient with photoreceptor degeneration. This proof-of-concept finding, they added, supports the development of personalized iPSC-based transplantation therapies for retinal disease.
The authors also emphasized that because the corrections are made in cells derived from the patient’s own tissue, doctors can retransplant the cells with fewer fears of rejection by the immune system. Previous clinical trials have shown that generating retinal cells from embryonic stem cells and using them for transplantation is a safe and potentially effective procedure.
Recently, another group has used CRISPR to ablate a disease-causing mutation in rats with retinitis pigmentosa. Going forward, the first clinical use of CRISPR could be for treating an eye disease because compared to other body parts, the eye is easy to access for surgery, readily accepts new tissue, and can be noninvasively monitored.
Edited stem cells offer hope of precision therapy for blindness
http://www.rdmag.com/news/2016/01/edited-stem-cells-offer-hope-precision-therapy-blindness
http://www.rdmag.com/sites/rdmag.com/files/newsletter-ads/RD_stemcells.jpg
Skin cells from a patient with X-linked Retinitis Pigmentosa were transformed into induced pluripotent stem cells and the blindness-causing point mutation in the RPGR gene was corrected using CRISPR/Cas9. Credit: Vinit Mahajan, Univ.of Iowa Health Care
Using a new technology for repairing disease genes–the much-talked-about CRISPR/Cas9 gene editing–Univ. of Iowa researchers working together with Columbia Univ. Medical Center ophthalmologists have corrected a blindness-causing gene mutation in stem cells derived from a patient. The result offers hope that eye diseases might one day be treated by personalized, precision medicine in which patients’ own cells are used to grow replacement tissue.
With the aim of repairing the deteriorating retina in patients with an inherited blinding disease, X-linked Retinitis Pigmentosa (XLRP), Alexander Bassuk, MD, PhD, and Vinit Mahajan, MD, PhD, led a team of researchers who generated stem cells from patient skin cells and then repaired the damaged gene. The editing technique is so precise it corrected a single DNA change that had damaged the RPGR gene. More importantly, the corrected tissue had been derived from the patient’s own stem cells, and so could potentially be transplanted without the need for harmful drugs to prevent tissue rejection. The research was published Jan. 27 in the journal Scientific Reports.
“With CRISPR gene editing of human stem cells, we can theoretically transplant healthy new cells that come from the patient after having fixed their specific gene mutation, ” says Mahajan, clinical assistant professor of ophthalmology and visual sciences in the UI Carver College of Medicine. “And retinal diseases are a perfect model for stem cell therapy, because we have the advanced surgical techniques to implant cells exactly where they are needed.”
The study was a “proof-of-concept” experiment showing it is possible not only to repair a rare gene mutation, but that it can be done in patient stem cells. Use of stem cells is key because they can be re-programmed into retinal cells.
The CRISPR technology was able to correct the RPGR mutation in 13 percent of the stem cells, which is a practically workable correction rate.
Bassuk notes this result is particularly encouraging because the gene mutation sits in a highly repetitive sequence of the RPGR gene where it can be tricky to discriminate one region from another. In fact, initially determining the DNA sequence in this part of the gene was challenging. It was not clear that CRISPR/Cas9 would be able to home in on and correct the “point mutation.”
“We didn’t know before we started if we were going to be able to fix the mutation,” says Bassuk, associate professor in the Stead Family Department of Pediatrics at University of Iowa Children’s Hospital.
Epigenetics Research Reveals a Range of Clinical Possibilities
Advantageously Epigenetic Analyses Can Capture both Genetic Factors and Environmental Exposures
Richard A. Stein, M.D., Ph.D.
http://www.genengnews.com/gen-articles/epigenetics-research-reveals-a-range-of-clinical-possibilities/5650/
- Over half a century ago, Conrad Hal Waddington introduced his model of the epigenetic landscape. He depicted a differentiating cell as a ball rolling down a landscape of bifurcating valleys and ridges, with each valley representing an alternative developmental path. Just as a ball may roll from valley to valley until it reaches the bottom of the landscape, a cell may progress from one developmental alternative to another until it reaches its fully differentiated state.
The model’s original purpose was to integrate concepts from genetics and developmental biology and to describe mechanisms that connect the genotype to the phenotype. Today, the model remains a compelling metaphor for epigenetics, which has developed into one of the most vibrant biomedical fields. Epigenetics has become indispensable for exploring development, differentiation, homeostasis, and diseases that span virtually every clinical discipline.
- Analyzing Methylation Patterns
“Modern efforts toward explaining human disease purely based upon sequencing cannot possibly succeed in isolation,” says Andrew P. Feinberg, M.D., professor of medicine and director of the Center for Epigenetics at Johns Hopkins University School of Medicine. “At least half of human disease is caused by exposure to the environment.”
While the contribution of genetic factors to disease is more predictable and easier to study in the case of highly penetrant Mendelian disorders, most medical conditions involve multiple genes that may interact with one another and with environmental factors. Particularly for these conditions, capturing epigenetic changes becomes a crucial aspect of understanding pathogenesis and designing prophylactic and therapeutic interventions.
“In these cases,” notes Dr. Feinberg, “an approach not including epigenetics will be severely limited in what it can accomplish.”
In a recent study, Dr. Feinberg and colleagues reported that large blocks of the human genome are hypomethylated in the epidermis as a result of sun exposure, which together with aging represents a known risk factor for skin cancer. These hypomethylated regions overlap with regions that have methylation changes in patients with squamous cell carcinoma.
This overlap could explain the causal link between sun exposure and the increased risk of malignancy found in many epidemiological studies. Most of the methylation changes were observed in the epidermis, not in the dermis, pointing toward the combination between the genotype and exposure, acting on specific cell types, as a key factor in shaping disease.
“One of the advantages of epigenetic analyses is that they capture both genetic factors and environmental exposures,” explains Dr. Feinberg. In the study of complex diseases, the existence of many distinct genetic variants identified in different individuals makes it challenging to understand their roles in pathogenesis. “But if genetic variants converge on gene regulatory loci, then measuring methylation can still be informative about these variants,” continues Dr. Feinberg, “even if genetic changes are inconsistent across the patients.”
In combining data from genome-wide association analysis and epigenome-wide analysis, Dr. Feinberg and colleagues revealed that two single-nucleotide polymorphisms on human chromosome 11, located 100 kb apart and involved in different aspects of lipid metabolism, controlled DNA methylation at two CpG sites in a bidirectional promoter situated between two genes encoding the fatty acid desaturases FADS1 and FADS2. Genome-wide association studies alone would not capture the convergence of these two single-nucleotide polymorphisms as they regulate DNA methylation in the shared promoter region.
“Measuring DNA methylation,” concludes Dr. Feinberg, “can pick up the fact that these single nucleotide polymorphisms act through DNA methylation to regulate the genes.”
The image shows a cleavage-stage human embryo. This is around the same stage that DNA methylation is ‘set’ at metastable epialleles. [Instituto Bernabeu]
http://www.genengnews.com/Media/images/Article/Jan15_2016_RobertWaterland_CleavageStageHumanEmbryo3202193100.jpg
Identifying Metastable Epialleles
Over the years, genome-wide association studies provided opportunities to establish links between genetic variation and phenotypic changes. For these analyses, genetic material from any of an individual’s cells, such as a peripheral white blood cell, is informative about the individual’s genotype. However, for epigenetic changes, which vary across tissues and within the same tissue among different cells, it is much more challenging to examine associations with disease.
Robert A. Waterland, Ph.D., associate professor of pediatrics and molecular and human genetics at Baylor College of Medicine, thinks that identifying human metastable epialleles will help circumvent some of these challenges. “Getting investigators and the field interested in metastable epialleles is going to be an important first step in helping us understand how epigenetic dysregulation contributes to human disease,” says Dr. Waterland.
The term metastable epialleles refers to genomic loci with differential epigenetic regulation that are variably expressed in genetically identical individuals, and where the epigenetic state is established stochastically in the very early embryo, before gastrulation, and subsequently maintained. This leads to systemic (non-tissue-specific) interindividual epigenetic differences that are not genetically mediated.
The fact that DNA methylation at metastable epialleles is particularly sensitive to environmental influences makes these loci valuable in mechanistically exploring the developmental origins hypothesis, the concept that environmental exposures during critical periods of prenatal and early postnatal development can have long-term implications in the risk of disease. Previous studies have implicated epigenetic modifications as a mechanism by which environmental changes during pregnancy may lead to epigenetic changes that influence health later in life.
In the most recent genome-wide screen meant to identify metastable epialleles in humans, Dr. Waterland teamed up with Dr. Andrew Prentice and colleagues at the London School of Hygiene and Tropical Medicine and used two independent and complementary experimental approaches to identify DNA methylation changes that occur in the cleavage-stage embryo (shortly after the time of conception). The first approach involved a genome-wide screen for DNA methylation in multiple tissues from two healthy Caucasian adults. In parallel, genome-wide DNA methylation profiling was performed in a rural population from The Gambia to examine the link between the season of conception (a proxy for maternal nutritional status) and DNA methylation in the offspring and sought to capture the effect of maternal nutritional status on the epigenetic profile of the offspring.
“We identified the same genomic locus as the top hit in both screens, suggesting that this is likely to be a key indicator of early environmental influences on the epigenome,” explains Dr. Waterland. Both approaches identified VTRNA2-1 as the lead candidate for an environmentally-responsive epiallele.
VTRNA2-1, a genomically imprinted small noncoding RNA and a putative tumor suppressor gene, is preferentially methylated on the maternally inherited allele, and loss of imprinting at this locus promises to link the early embryonic environment to epigenetic changes that shape disease risk later in life. Besides VTRNA2-1, over 100 metastable epialleles were identified in the study.
“At metastable epialleles such as VTRNA2-1, DNA methylation in peripheral blood or in any easily accessible tissue can give an indication about the epigenetic regulation throughout the body,” concludes Dr. Waterland. “That is what is really different.”
http://www.genengnews.com/Media/images/Article/thumb_Jan15_2016_DavidBazettJones_ElectronSpectroscopic1381311078.jpg
Electron spectroscopic image of a region of the nucleus of a mouse embryonic fibroblast. Phosphorus and nitrogen maps allow chromatin (yellow) to be distinguished from protein-based structures (cyan). The arrow indicates the nuclear envelope. The large structure in the middle of the field, a chromocentre, is an accumulation of pericentric heterochromatin. It is surrounded by dispersed chromatin fibers. The heterochromatin mark, trimethlated H3K9, is immunolabelled and visualized with gold tags (white foci). [David Bazett-Jones]
Mapping Heterochromatin Domains
Electron spectroscopic image of a region of the nucleus of a mouse embryonic fibroblast. Phosphorus and nitrogen maps allow chromatin (yellow) to be distinguished from protein-based structures (cyan). The arrow indicates the nuclear envelope. The large structure in the middle of the field, a chromocentre, is an accumulation of pericentric heterochromatin. It is surrounded by dispersed chromatin fibers. The heterochromatin mark, trimethlated H3K9, is immunolabelled and visualized with gold tags (white foci). [David Bazett-Jones]
“For the first time, we found that a histone chaperone is implicated in organizing chromatin at a large scale,” says David Bazett-Jones, Ph.D., professor of biochemistry at the University of Toronto and senior scientist at the Hospital for Sick Children. The discovery and characterization of histone variants has been a vital facet of understanding chromatin organization and dynamics.
One of the most extensively studied histone variants is H3.3. Although H3.3 is 96% identical at the amino acid level to histone H3.1, histones H3.3 and H3.1 are functionally distinct. Histone H3.3 is expressed throughout the cell cycle, and it is enriched in transcriptionally active chromatin and in certain types of post-translational modifications. The death domain-associated protein DAXX, one of the proteins associated with histone H3.3 deposition, was recently identified as its chaperone.
Dr. Bazett-Jones and colleagues, including his graduate student Lindsy Rapkin, revealed that the loss of DAXX led to a global structural change in the chromatin landscape, characterized by genomic regions enriched in the trimethylated H3K9 epigenetic mark that were juxtaposed to large chromatin domains devoid of this modification.
“These major changes probably occur because the boundaries between heterochromatin domains and other regions were not being respected, leading to the inappropriate insertions of histone H3.3, and this exerted quite profound effects,” explains Dr. Bazett-Jones. The loss of DAXX led to the uncoupling of the epigenetic marks from the global chromatin architecture. “This shows that a major global reorganization of the chromatin was taking place,” Dr. Bazett-Jones continues.
To visualize chromatin changes that result from the loss of DAXX, Dr. Bazett-Jones and colleagues used electron spectroscopic imaging, an experimental approach that is based on the principle of electron energy loss spectroscopy. When a biological specimen is targeted with electrons and its atoms become ionized, the ionization energy is equal to the energy that is lost by the incident electrons that generated the event.
The electron microscope technique generates nitrogen and phosphorus maps, which are used to discriminate between nucleic-acid-rich and protein-rich cellular structures. These maps offer high-contrast images of chromatin and its three-dimensional organization in intact cells.
Another component of the DAXX deletion phenotype included the loss of nucleolar structural integrity, resulting in an increased number of cells containing mini-nucleoli, and the dispersal of ribosomal DNA genes outside the nucleolus. Collectively, these findings pointed toward a novel role that DAXX plays in the subnuclear organization of chromatin and in maintaining nucleolar structural integrity.
“Historically, we thought that the well-known epigenetic modifications dictate the compact character of heterochromatin,” notes Dr. Bazett-Jones. “But our findings, and those from other groups, reveal that a heterochromatin domain epigenetically marked with H3K9 trimethylation, for example, can be found in a structurally ‘open’ state, similar to euchromatin.”
This indicates that the boundaries between heterochromatin and euchromatin are much more fluid than previously envisioned, a concept that is crucial for understanding factors that dynamically shape the three-dimensional interaction between epigenetic changes. A key implication of these findings is that the epigenetic marks at a specific genomic locus depend on both the local environment and the three-dimensional context.
“We need to look at what loci come together in specific regions of the nucleus in three dimensions and how they affect each other,” concludes Dr. Bazett-Jones. “This is on top of capturing epigenetic marks, which are on top of the genomic sequences that we need to explore.”
Identifying Druggable Epigenetic Processes
“There is a big gap in understanding the biology of epigenetics,” says Chris J. Burns, Ph.D., laboratory head, Division of Chemical Biology, Walter and Eliza Hall Institute of Medical Research, Melbourne. “And this goes hand in hand with the need to learn how to generate small molecule probes or drugs.”
When interrogating epigenetic processes, researchers find it useful to integrate biological and chemical perspectives. For example, researchers have generated a large body of literature demonstrating that many epigenetic processes involve highly complicated protein complexes.
Historically, genetics studies have typically relied on knocking down or knocking out a gene and its protein product to examine the resulting phenotype. “In contrast, knocking down a protein that is part of a protein complex fundamentally alters that complex, and the phenotype could be quite different from the one that can be seen with a small molecule inhibition of a catalytic component of the protein complex,” notes Dr. Burns. This opens an acute need to identify small molecules that can selectively impact just one particular aspect of these protein complexes.
A major effort in Dr. Burns’ lab is focusing on identifying therapeutic agents that could target epigenetic processes. “Epigenetics in terms of drug discovery and development is still in an early stage,” explains Dr. Burns. While several drugs that target epigenetic processes have become available in recent years—drugs such as HDAC inhibitors and DNA methyl transferase inhibitors—many other drugs are still at early stages of development.
“Some epigenetic processes have not yet been drugged,” Dr. Burns points out. “For some of them, there may not be any therapeutic agents that are particularly good.”
Dr. Burns’ lab has collaborated with investigators led by Carl Walkley, Ph.D., joint head, Stem Cell Regulation Unit, St. Vincent’s Institute of Medical Research, Melbourne. Together, the research teams revealed that several bromodomain inhibitors exert powerful antitumor activity in human osteosarcoma cell lines and in osteosarcoma primary cells from mouse models of the disease.
The researchers’ findings were surprising. JQ1, one the bromodomain inhibitors tested, exerted its antiproliferative activity by inducing apoptosis, and not by mediating cell cycle arrest, as expected. Moreover, even though previous studies identified MYC as an oncogenic driver in osteosarcoma, the activity of JQ1 was exerted independently of MYC downregulation.
At the same time, this work revealed that downregulation of FOSL1, a gene previously implicated in osteoblast differentiation, is an important contributor to the effects of JQ1, marking the first time when this gene was implicated in osteosarcoma.
“Because we used primary cell from animals, these findings reflect the disease process better than cell lines, which may take on a number of other mutations,” concludes Dr. Burns. “This explains why our findings are contrary to previous reports in the literature.”
“We have shown that epigenetic drugs may work not only on protein-coding genes but also on the noncoding part of the genome,” says Claes Wahlestedt, M.D., Ph.D., professor and associate dean for therapeutic innovation at the University of Miami Miller School of Medicine.
A therapeutically promising class of epigenetic compounds consists of bromodomain inhibitors. These compounds have received increasing attention in recent years, and several leads have entered clinical trials for malignancies, atherosclerosis, and type 2 diabetes.
”One of our interests is to see if bromodomain inhibitors could be used for diseases of the nervous system,” notes Dr. Wahlestedt.
Using in vitro and in vivo approaches, investigators in Dr. Wahlestedt’s group, in collaboration with investigators led by Nagi Ayad, Ph.D., found that BET bromodomain inhibitors can inhibit glioblastoma cell proliferation by inducing a cyclin-dependent kinase inhibitor. These findings set the stage for subsequent experiments that used single molecule sequencing to profile long noncoding RNAs (lncRNAs) differentially expressed in glioblastoma multiforme. This helped identify a set of transcripts that are specific for this malignancy and could be regulated by bromodomain inhibitors.
In glioblastoma multiforme cells, the I-BET151 bromodomain inhibitor localized to the promoter of HOTAIR, a tumor-promoting lncRNA that acts as an epigenetic silencer and has been implicated in several cancers, decreased its expression, and restored the expression of several lncRNA species that are downregulated in this malignancy.
In another collaborative endeavor, Dr. Wahlestedt and colleagues conducted a semi-high-throughput gene-expression-based screen to identify small molecules that could increase the expression of C9ORF72. A GGGGCC hexanucleotide repeat expansion in the noncoding region of the C9ORF72 gene is the most common genetic cause for amyotrophic lateral sclerosis. Individuals without this condition harbor 2 to 25 of these repeats, but their number can reach up to several hundreds in ALS patients, reducing C9ORF72 expression, which has been implicated in the pathogenesis of this condition.
The gene-expression-based screen identified, in fibroblasts from affected and unaffected individuals, small interfering RNAs against the BRD3 bromodomain protein and several small molecule bromodomain inhibitors that were able to increase C9ORF72 expression. This effect occurred without changes in promoter CpG hypermethylation and trimethylated H3K9 marks, which are heterochromatin markers of the expanded C9ORF72 alleles.
“The mechanism of action of these compounds is probably broader than we thought before,” concludes Dr. Wahlestedt.
CRISPR Works Well but Needs Upgrades
More Effective and Reliable CRISPR Tools Will Have To Be Developed
MaryAnn Labant
http://www.genengnews.com/gen-articles/crispr-works-well-but-needs-upgrades/5652/
http://www.genengnews.com/Media/images/Article/thumb_UnivIllinois_Cas9DSB1921455173.jpg
In this image, which comes from the University of Illinois at Urbana-Champaign, Cas9 (green) is shown cutting DNA (white and brown) at the target sequence specified by the single guide RNA (red). The image was created from the Protein Data Bank file 4un3.pdb using Pymol, and it was enhanced using Photoshop.
The gene-editing technology known as CRISPR-Cas9 went through a disruptive phase when it first took the research world by storm.
Now, thousands of research articles later, it is starting to raise expectations in the therapeutic realm. In fact, CRISPR-Cas9 and other CRISPR systems are moving so close to therapeutic uses that the technology’s ethical implications are starting to attract notice. For example, people worry that CRISPR could be used to alter human germline cells, introducing genomic changes that could impact future generations.
Before any of that can happen, however, CRISPR will have to overcome a number of practical obstacles. If CRISPR is to be harnessed effectively and leveraged to its full potential, it will have to be better understood. Also, more effective and reliable CRISPR tools will have to be developed.
For example, little progress has been made in the area of targeted integration. “We effectively have the tools to cut, yet we lack efficient tools to paste. How the cells repair the double-strand break created by the RNA-guided nucleases, or RGNs, depends almost exclusively on the cells themselves in that there is no control over the repair mechanism. In addition to the RGNs, we deliver a vector that can function as a repair template, and hope the cells will use it,” explained Pablo Perez-Pinera, M.D., Ph.D., assistant professor, department of bioengineering, University of Illinois at Urbana-Champaign.
Fun with Lego (molecules)
http://www.rdmag.com/news/2016/01/fun-lego-molecules
http://www.rdmag.com/sites/rdmag.com/files/newsletter-ads/RD_legos.jpg
Depending on the relative amounts of different building-block molecules, it is possible to create different sandwich and wheel topologies (shown above in micrographs and below as models). Credit: American Chemical Society. Copyright 2016
A great childhood pleasure is playing with Legos and marveling at the variety of structures you can create from a small number of basic elements. Such control and variety of superstructures is a goal of polymer chemists, but it is hard to regulate their specific size and how the pieces fit together. This week in ACS Central Science, researchers report a simple system to make different nano-architectures with precision.
Using a variety of highly efficient chemical transformations and other techniques to ensure high yields and purity, Stephen Z. D. Cheng, Yiwen Li, Wen-Bin Zhang and coworkers designed systems to create giant molecules with ‘orthogonal’ ends, meaning that they only fit together with a specific partner just like Legos. Depending on the relative amounts of different building-block molecules, these molecules come together in different superstructures — ranging from cubes to wheels and sandwiches. Eventually, they could be employed in device-creation, where it is crucial to have precise control over the positions of the components.
Protein Expression Systems Proliferate
Bioprocessing Assembly Lines Are Being Retooled, Often At the Genomic Scale
Angelo DePalma, Ph.D.
http://www.genengnews.com/Media/images/Article/thumb_iStock_32784234_eColi1930160883.jpg
Despite some bells and whistles, most E. coli production systems have been the same. Now, new systems are being introduced that purport to express proteins more efficiently. [iStock/Scharvik]
Biomanufacturers enjoy a host of tools to optimize the production of therapeutic proteins, including expression systems, media, feeds, and gene-editing tools. Suffice it to say that protein expression is a growth industry.
Industry research firm Future Market Insights (FMI) breaks down the protein expression market into four product areas: competent cells, expression vectors, instruments, and reagents serving demand for research-grade and therapeutic proteins.
FMI has identified noteworthy growth drivers: the rising significance of biologics; innovations in proteomics; and patent expirations among small-molecule drugs. “These demands will boost the overall protein expression market in the coming future,” FMI literature states. “However, [attempts to contain rising costs] in various R&D activities in the fields of biotechnology and pharmaceutical industry as well as market consolidation of a high degree are some restraining factors for this market.”
The largest market for protein expression is expected to emerge in North America, given this region’s “well-established healthcare infrastructure.” North America is followed by Europe, and the Asia-Pacific region shows the highest growth. This information was derived from an FMI report (“Protein Expression Market: Global Industry Analysis and Opportunity Assessment 2015–2025”) that was issued last December.
Landmark Year
Through the efforts of scientists at Thermo Fisher Scientific, 2015 was a landmark year for transient protein production in CHO cells. The company’s ExpiCHO™ transient expression system achieved multiple g/L levels of protein expression previously thought possible only in stable cell lines, according to Jonathan Zmuda, Ph.D., associate director of cell biology at Thermo Fisher Scientific’s Gibco business unit.
“ExpiCHO allows drug developers to obtain meaningful quantities of protein from CHO cells at the very earliest stages of biologics development,” Dr. Zmuda asserts. “It allows CHO-derived protein to be used from discovery day one through the transition to stable cell lines, bioproduction, clinical trials, and product licensing.”
This has had the effect of streamlining drug development by eliminating the risk of starting a program with HEK 293-derived drug candidates, while also providing an alternative high-expressing system for proteins that are difficult to express in HEK 293.
New E. Coli Expression System
http://www.genengnews.com/Media/images/Article/NewEnglandBiolabsFigure28614117612.jpg
New England BioLabs says that its SHuffle T7 E. coli expression system is able to express non-di-sulfide bonded proteins more efficiently than wild-type E. coli. The actual SHuffle strain expressing GFP is shown here.
Since E. coli was recruited for service around 1950, hundreds of thousands of publications have sung the praises of this bedrock expression system. But Mehmet Berkmen, Ph.D., staff scientist at New England BioLabs, notes that no more than a dozen distinct protein production strains exist. When production strains are examined closely, all are found to belong to just two basic strains, E. coli K-12 and E. coli B.
“Some strains have ‘bells and whistles,’ but the basic platform is the same,” Dr. Berkmen points out. “People are still looking for engineered lines that express protein more efficiently.”
Most expression systems are based on E. coli B, but that strain is not engineered specifically for protein production. The B strain is somewhat less domesticated than K-12, which has gone through numerous generations of selection for DNA manipulation. “E. coli B is more wild and tends to make protein better,” Dr. Berkmen notes. “But if you ask people why that is the case, they can’t provide an answer.”
New England BioLabs claims that its SHuffle® T7 E. coli expression system represents a breakthrough for microbial fermentation. The bacteria, which are chemically competent E. coli K-12 cells engineered to form proteins containing disulfide bonds in the cytoplasm, are suitable for T7-promoter-driven protein expression. The company has recently produced full-length antibodies, complete with disulfide bonds, in SHuffle organisms, which Dr. Berkmen calls “a significant step toward engineering and developing novel antibody formats and tools.”
New England BioLabs manufactures more than 500 proteins, 98% of them in E. coli. Perhaps even more interesting is the SHuffle system’s ability to express non-disulfide-bonded proteins more efficiently than wild-type E. coli. “SHuffle,” insists Dr. Berkmen, “represents a new chassis for protein production.”
The E. coli bacterium does not form disulfide bonds in its cytoplasm because two reducing pathways maintain the cytoplasmic proteome in its reduced state. Dr. Berkmen’s group knocked out those pathways and inserted a gene for a disulfide bond isomerase that increases fidelity of disulfide bond formation.
In addition to benefits already mentioned, SHuffle has a greatly diminished reducing capacity, permitting the formation of disulfide bonds for proteins that require it for folding and activity. Additionally, the cells, which are under oxidative stress, produce chaperones that also improve folding. For example, the activity of green fluorescent protein (GFP) expressed in SHuffle is much higher than protein produced in wild-type E. coli B.
It should be noted that a lack of glycosylation machinery persists in SHuffle cells. This problem, however, can be circumvented, as demonstrated in a seminal study carried out by Dr. Berkmen and colleagues. This study, which appeared last year in Nature Communications, described how IgG could be produced in SHuffle cells. Specifically, the investigators introduced mutations into the Fc portion of IgG. This resulted in efficient binding of aglycosylated IgG to its cognate receptor FcγRI.
Even in the absence of such ingenuity, E. coli remains a valuable expression system. It can be used to produce diagnostic and reagent proteins, or proteins for which glycosylation is noncritical.
“A Matter of Trying”
The principal advantages of using E. coli. are time and cost. “It takes basically one day, more or less, to obtain enough protein to suit many applications,” says David Chereau, Ph.D., CSO at Biozilla, a biotechnology contract research organization. As previously noted, the main disadvantages are lack of glycosylation apparatus and inability to support disulfide bond formation.
Workaround strategies can achieve stable disulfide bonds for some proteins. One strategy involves the following steps: Express the protein as an inclusion body, in insoluble form. Isolate the insoluble fraction. Solubilize this fraction with urea or some other suitable agent. Refold the protein.
“The process is relatively straightforward,” observes Dr. Chereau. “It’s much more difficult to find refolding conditions, which are normally determined empirically.” Refolding requires just the right buffer, salt concentrations, and additives. Also, refolding must be done in an oxidizing environment if disulfide bonds are to be achieved or maintained.
Dr. Chereau is philosophical about CHO cells’ inability to glycosylate: “Lack of glycosylation can be seen as an advantage or an inconvenience, depending.” E. coli is definitely out where glycosylation is a sine qua non. “But for the many applications where glycosylation isn’t needed, E. coli can be advantageous,” comments Dr. Chereau. Diagnostics and reagents are two such products. Additionally, obtaining a crystal structure during protein characterization is easier with glycans absent.
As part of its proof-of-concept services, Biozilla performs rapid screens to determine if E. coli is the right expression system for a particular product. Screening resembles design-of-experiment for mammalian cells, varying plasmids and vectors, as well as expression conditions.
Due to the success of CHO cells, bioprocessors tend to dismiss microbial fermentation, particularly for large proteins. “A lot of people think that expressing large proteins in E coli is difficult,” Dr. Chereau states, “but it’s often just a matter of trying. We have recently expressed a protein of 215 kDa in E. coli, which most people will tell you cannot be done. And we achieved it in very high yield.”
Rapid Prototyping
In June 2015, Invenra, a preclinical stage biotech company specializing in next-generation antibodies and antibody derivatives, entered an agreement with Oxford BioTherapeutics (OBT) to identify and characterize fully human therapeutic monoclonal antibodies (mAbs) against a novel cancer target that OBT has identified.
Invenra’s protein expression platform, through which it is capable of producing hundreds of thousands of full-length antibodies, uses cell-free expression to multiplex up to 10,000 protein variants simultaneously.
“We think of our technology as a rapid prototyping tool for proteins,” says Bryan Glaser, Ph.D., Invenra’s R&D director. “Once we have DNA, we can get protein in less than a day.” Invenra’s expression platform is suitable mainly for discovery and rapid protein prototyping. Yields are quite good: up to 500 μg/mL.
Other firms, such as Sutro Biopharma, are working on cell-free expression at much larger scales. Sutro claims that its Express CF™ technology can produce g/L yields in eight hours.
Cell-free expression involves E. coli extracts, typically S30 (used by most cell-free expression systems) and S12. The numbers reflect centrifugation speed. “Our system is based on S12, which is spun at lower speed than S30,” informs Dr. Glaser. “Our extract also does not undergo dialysis. We think of it as a ‘whole grain’ version.”
In addition to E. coli extracts, additives contain varying quantities of supplemental energy sources, nucleotides, and other small molecules that facilitate in vitro transcription and translation. Every vendor has its own unique blend.
Invenra’s standard mix, which is similar to off-the-shelf products from most commercial sources, is optimized for less complex molecules that don’t require disulfide bonds. Another mix has been optimized to include chaperones formulated to help expression and folding of IgGs and IgG-like molecules.
The upshot: fully functional, correctly folded IgGs and some bispecific antibodies, scFvs, and Fabs. More complex molecules are also possible, but each must be investigated independently. It is possible those could be made, but they would need to be optimized structure by structure. Dr. Glaser says expression capability depends to a large extent on amino acid sequence.
“We can fine-tune expression and folding conditions better than is possible in E. coli,” Dr. Glaser asserts. “We have better control over redox environment to facilitate disulfide bond formation, and we can add chaperones that are not present in E. coli organisms.” Still, the more disulfides the more complex the structure, and the lower the yield.
Dr. Glaser adds that antibody frameworks that express well in E. coli express well in cell-free systems, and ones that don’t express well in bacteria or mammalian cells tend not to express well cell-free. “It could be a framework sequence dependency,” he speculates. “It could be how well that framework folds. Perhaps the best-expressing molecules are those that do not require as much assistance from various chaperones and isomerases.”
Invenra’s expression system lends itself well to large-scale parallelism. The company has developed a credit-card-sized nanowell platform that expresses up to 10,000 unique antibodies per nanowell array. Cell-free expression of IgG using the Invenra nanowell platform system enables the incorporation of functional screening very early into the discovery process.
The ability to screen in excess of 100,000 IgG molecules can reduce the antibody display selection steps and preserve a larger diversity of epitope coverage. In addition, large combinations of binding partners can be empirically tested in various bispecific formats with relevant functional assays to identify the best pair and format for activity.
Getting the Bugs Out
Interest is growing for insect cell expression systems transiently transfected through the baculovirus expression vector system (BEVS). More and more clinical candidates are being generated in insect cells, including development-stage products for respiratory syncytial virus, Ebola virus, and norovirus.
A good deal of BEVS’ success is the ability of insect cells to produce multivalent, multisubunit vaccines through virus-like particles. These proteins can be made at large scale with BEVS for structural studies or to elucidate protein function.
Additionally, insect cells are ideal for making proteins that are toxic to mammalian or E. coli expression systems. BEVS shows its flexibility by providing rapid development cycles for treatments like seasonal influenza or pandemic infection vaccines. Because it is a transient system, BEVS allows for rapid turnaround times compared with mammalian cells, from identification of vaccine candidates to production.
Progress toward Therapeutic Epigenetics
Epigenetic Targets Are Plentiful but Well Camouflaged
Angelo DePalma, Ph.D.
GEN Jan 15, 2016 (Vol. 36, No. 2) http://www.genengnews.com/gen-articles/progress-toward-therapeutic-epigenetics/5664/
-
Epigenetics is poised to become a cornerstone of drug development in oncology, diabetes, inflammation, developmental and metabolic disorders, cardiovascular and autoimmune diseases, pain, and neurological disorders.
According to citations from PubMed Epigenetics, 40% year-on-year increases in epigenetics-related scientific publications occurred during the last decade, accompanied by a substantial increase in research funding. Data from ClinicalTrials.gov indicate that more than 40 different epigenetics-related drugs are undergoing clinical trials. Epigenetics will also likely affect developments in animal, plant, and environmental health.
Jim Corbett, president of the human health business at PerkinElmer, notes that epigenetics research is currently limited by the number and availability of fully validated targets and preclinical disease models. “Another limitation stems from the relative dearth of fully selective antibodies for some of the writer and eraser targets to elucidate these complex signaling and modification events,” he points out. “Epigenetics research also suffers from a lack of a translational continuum for specific applications and for solutions from bench to bedside.”
Nevertheless, the field is characterized by a high level of optimism. Research by Mordor Intelligence (“North America and Europe Epigenetics Market Growth, Trends and Forecasts, 2014–2020”) estimates that epigenetics will grow in market reach from approximately $2.9 billion in 2012 to about $12 billion in 2018.
“I anticipate the development of second-generation epigenetic inhibitors with increased selectivity and targeting potential, standardization of epigenetic assays, and the validation of preclinical disease models leading to an improved understanding of epigenetic targets and mechanisms,” Corbett ventures. “The emergence of selective genome-editing technologies such as CRISPR will also apply in epigenetics and epigenome editing. I envision the future the emergence of personalized epigenetic profiles in patients.”
-
Computer Analogy
Randy L. Jirtle, Ph.D., professor of epigenetics at North Carolina State University, describes epigenetics as a type of biological software. He explains an embryo’s combination of paternal and maternal genetic information, and eventual differentiation into 200–300 cell types, on the basis of cells running different programs.
“The cell can be thought of as a programmable computer where the hardware is DNA and the software is the epigenome,” says Dr. Jirtle. “Very shortly after fertilization, this computer tells the cell how to work. And as with actual computers, things can go wrong because of viruses or—in the case of cells—mutations.”
Dr. Jirtle demonstrated in 2003 that epigenetic modifications in utero may determine adult disease susceptibility, a notion that was not welcomed enthusiastically. “If you think of life as hardware, no known mechanism would explain this [connection],” asserts Dr. Jirtle. “But when you consider the ‘software,’ it becomes understandable.”
Epigenetics can bring about positive effects as well. Through a process known as hormesis, low doses of a toxic agent or low doses of radiation can be administered strategically to improve an organism’s subsequent health. For example, mice exposed to low levels of ionizing radiation experienced a positive adaptive effect, which flies in the face of prevailing “no safe dosage” logic.
In one strain of an experimental mouse bred to develop human-like diseases, 1 cGy of exposure—about the dose received from five X-rays—resulted in a decidedly positive hypermethylation of the epigenome. Exposed mice developed obesity, diabetes, and cancer at significantly lower rates than nonexposed mice. Negative effects occur at significantly higher doses as expected.
Similarly positive epigenetic effects have been observed in plants exposed to very low doses of herbicides.
Dr. Jirtle believes that the characterization of the repertoire of genes imprinted in humans, and their regulatory elements, the imprintome, will guide epigenome-based therapies. Imprinting is the process by which one parental copy of a gene is silenced. Thus, depending on the effectiveness of silencing, one could have two copies of a gene or none, either of which could potentially be deadly. In some cancers, for example, the inability to silence one parental gene for IGF2, which influences apoptosis, allows cancer cells to grow out of control.
“There are probably around 150–500 disease-influencing genes that are regulated this way,” Dr. Jirtle points out.
-
Implementation Hurdles
The connection between dysregulated DNA methylation and cancer is well established. Keith Booher, Ph.D., epigenetic service projects manager at Zymo Research, believes that modifying how methylation patterns change could allow a reset. Essentially, cells destined to become cancerous could be returned to a normal state.
But significant hurdles block straightforward implementation. For example, getting drugs into cells, particularly solid tumors, is not easy. “It’s no coincidence that DNA methylation inhibitors have proved most successful for blood-based cancers, which are easier to target,” Dr. Booher tells GEN.
Another hurdle is drug resistance, an issue with nearly all oncology agents. Moreover, drugs that alter the activity of the ubiquitous DNA methyl transferase will have broad activity on normal as well as abnormal cell processes.
“Normal cells show low and high methylation levels,” Dr. Booher explains. “DNA methylation tends to limit gene expression, so you want to shut down those genes. And where DNA methylation is absent, genes tend to be expressed.
“Methylation will change across the genome at different development stages, but in adult cells or developing blood cell you want methylation patterns to change in a regulated way. It’s difficult to limit the effect to diseased cells.”
Finally, the way methylation inhibitors interact with DNA is in itself harmful. The original epigenetics-based drugs tested as broad chemotherapeutics, but their toxicology was high. It was only later, after the understanding the relationship between DNA methylation and carcinogenesis was better established, that the potential to use these agents at much lower doses became possible.
Diagnostic Relevance

This Circos plot from Swift Biosciences represents the methylation status of 1 Mb bins across chromosomes 1–22 for Sample 8 (Metastatic colorectal adenocarcinoma with liver metastasis, 2 cm primary).
One of the most important advances in epigenetic research is the ability to obtain comprehensive, per-base methylation status of the methylome using next-generation sequencing (NGS). The significant drop in sequencing costs enables both whole-genome bisulfite sequencing and hybridization capture for targeted enrichment of the methylome.
Initially, notes Laurie Kurihara, Ph.D., director of R&D at Swift Biosciences, these techniques were developed for microgram inputs of genomic DNA that undergo standard NGS library preparation followed by bisulfite conversion, a chemical process that converts nonmethylated cytosines to uracil. Subsequently, the polymerase chain reaction (PCR) process can be used to convert uracil to thymidine. “But the methylated cytosines are protected, thus demarcating methylation status when the DNA sequence is determined,” Dr. Kurihara observes. “The drawback is that bisulfite-induced DNA fragmentation destroys the bulk of the prepared NGS library. Hence the requirement for microgram DNA inputs.”
To enable lower DNA inputs and improved methylome coverage and uniformity, Swift Biosciences has developed an NGS library preparation performed on bisulfite-converted DNA fragments. The underlying technology, Adaptase, is a proprietary NGS adapter attachment chemistry for single-stranded DNA.
“By significantly improving sample recovery from bisulfite-converted DNA,” explains Dr. Kurihara, “more complete analysis of clinical samples is possible, particularly cell-free DNA from plasma that is limited to low-nanogram quantities of DNA.”
Dr. Kurihara cites an example provided by Dennis Lo, M.D., Ph.D., professor of chemical pathology at the Chinese University of Hong Kong. Dr. Lo developed a noninvasive test for cancer by detection of genome-wide hypomethylation of cell-free DNA from patient plasma. Although this “liquid biopsy” does not uncover actionable cancer mutations, it may prove to be a sensitive blood test for early cancer detection as well as treatment monitoring.
More recently, Dr. Lo’s group mapped the tissue of origin for cell-free plasma DNA using genome-wide bisulfite sequencing after mapping tissue-specific methylation patterns. Such noninvasive testing from blood may identify tissue- or organ-specific pathologies, including cancer, stroke, myocardial infarction, autoimmune disorders, and transplant rejection.
“Given that advances in epigenetic technologies have enabled per-base methylation status from low DNA input clinical samples, proof of concept has been established that ‘liquid biopsy’ testing of patient blood may be a universal screen for a variety of diseases that may be pinpointed to individual organs or tissues,” Dr. Kurihara tells GEN. “Such universal testing could be particularly advantageous for early detection of cancer and other diseases where noninvasive screening has not previously been possible.”
-
NGS: An Enabling Technology
The widespread adoption of next-generation genomic sequencing means that for the first time scientists can sequence large numbers of cancer patient genomes. Thus far, these studies have demonstrated that a large proportion of mutated cancer genes may be classified as epigenetic modifying factors.
“Chromatin remodeling and modifying factors are involved in the regulation of gene expression,” says Ali Shilatifard, Ph.D., chairman of the department of biochemistry and molecular genetics at Northwestern University’s Feinberg School of Medicine. “The DNA methylation factors are highly mutated in most cancers characterized thus far.”
Dr. Shilatifard provides the example of a family of mixed-lineage leukemia genes within the complexes known as COMPASS (complex proteins associated with Set1), which are highly mutated in a large number of cancers. “We’ve shown that MLL3/4, two members of the COMPASS family, modify regulatory elements known as enhancers,” notes Dr. Shilatifard. “The job of this COMPASS family member is to regulate these cis-regulatory elements during development.”
It has been shown that MLL3/4 and another component of COMPASS, UTX, are some of the most mutated genes in cancer. “We propose that perhaps these mutations function through enhancer malfunction,” Dr. Shilatifard continues. “And enhancer malfunction through these family members could result in miscommunication of the regulatory elements and promoters and mis-regulation of the expression pattern, resulting in tissue-specific cancers. It’s now very clear that epigenetic regulation and enhancer malfunction are key events in cancer pathogenesis.”
Dr. Shilatifard believes that over the next several years, academic labs and pharmaceutical companies will increasingly rely on agents that intervene epigenetically. For example, a recent study indicated that approximately 75% of patients with diffuse intrinsic pontine glioma (DIPG), a rare brain cancer in children, carried a single point mutation on histone H3, transforming lysine 27 into methionine. Many copies of histone H3 exist in these patients, but mutation in just one copy is sufficient to cause DIPG.
After modeling this mutation in Drosophila, Dr. Shilatifard’s laboratory discovered that a single point mutation on one histone was associated with a global loss of histone methylation and an increase in histone acetylation.
“Epigenetic regulators could be central for treating this disease,” comments Dr. Shilatifard. “Numerous examples in the literature suggest that inhibition of epigenetic regulators and interactors could be very important for treating cancer, and this may work for the treatment of DIPG through the inhibition of factors that bind to hyper-acetylated histones.”
Like this:
Like Loading...
Read Full Post »










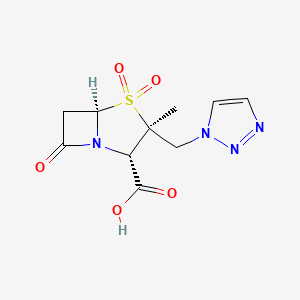

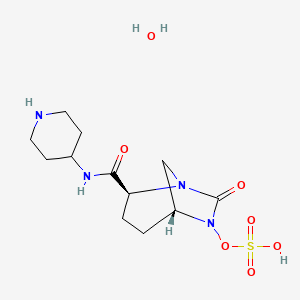
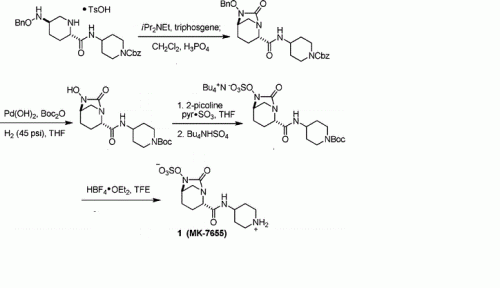



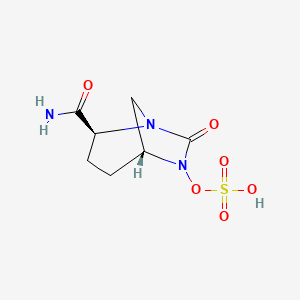








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}