Unlocking the Microbiome
Larry H. Bernstein, MD, FCAP, Curator
LPBI

3.3.11 Unlocking the Microbiome, Volume 2 (Volume Two: Latest in Genomics Methodologies for Therapeutics: Gene Editing, NGS and BioInformatics, Simulations and the Genome Ontology), Part 2: CRISPR for Gene Editing and DNA Repair
Machine-learning technique uncovers unknown features of multi-drug-resistant pathogen
January 29, 201 http://www.kurzweilai.net/machine-learning-technique-uncovers-unknown-features-of-pathogen

http://www.kurzweilai.net/images/Pseudomonas-aeruginosa.jpg
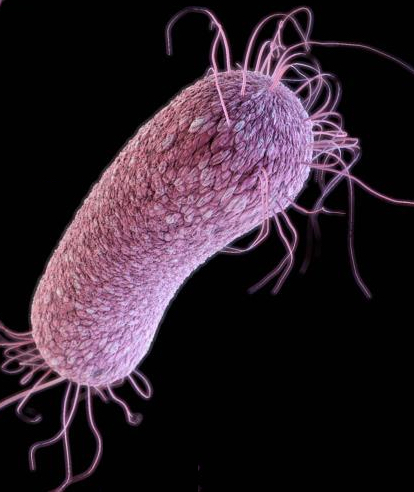
According to the CDC, Pseudomonas aeruginosa is a common cause of healthcare-associated infections, including pneumonia, bloodstream infections, urinary tract infections, and surgical site infections. Some strains of P. aeruginosa have been found to be resistant to nearly all or all antibiotics. (illustration credit: CDC)
A new machine-learning technique can uncover previously unknown features of organisms and their genes in large datasets, according to researchers from the Perelman School of Medicine at the University of Pennsylvania and the Geisel School of Medicine at Dartmouth University.
For example, the technique learned to identify the characteristic gene-expression patterns that appear when a bacterium is exposed in different conditions, such as low oxygen and the presence of antibiotics.
The technique, called “ADAGE” (Analysis using Denoising Autoencoders of Gene Expression), uses a “denoising autoencoder” algorithm, which learns to identify recurring features or patterns in large datasets — without being told what specific features to look for (that is, “unsupervised.”)*
Last year, Casey Greene, PhD, an assistant professor of Systems Pharmacology and Translational Therapeutics at Penn, and his team published, in an open-access paper in the American Society for Microbiology’s mSystems, the first demonstration of ADAGE in a biological context: an analysis of two gene-expression datasets of breast cancers.
Tracking down gene patterns of a multi-drug-resistant bacterium
The new study, published Jan. 19 in an open-access paper in mSystems, was more ambitious. It applied ADAGE to a dataset of 950 gene-expression arrays publicly available at the time for the multi-drug-resistant bacteriumPseudomonas aeruginosa. This bacterium is a notorious pathogen in the hospital and in individuals with cystic fibrosis and other chronic lung conditions; it’s often difficult to treat due to its high resistance to standard antibiotic therapies.
The data included only the identities of the roughly 5,000 P. aeruginosa genes and their measured expression levels in each published experiment. The goal was to see if this “unsupervised” learning system could uncover important patterns in P. aeruginosa gene expression and clarify how those patterns change when the bacterium’s environment changes — for example, when in the presence of an antibiotic.
Even though the model built with ADAGE was relatively simple — roughly equivalent to a brain with only a few dozen neurons — it had no trouble learning which sets of P. aeruginosa genes tend to work together or in opposition. To the researchers’ surprise, the ADAGE system also detected differences between the main laboratory strain of P. aeruginosa and strains isolated from infected patients. “That turned out to be one of the strongest features of the data,” Greene said.
“We expect that this approach will be particularly useful to microbiologists researching bacterial species that lack a decades-long history of study in the lab,” said Greene. “Microbiologists can use these models to identify where the data agree with their own knowledge and where the data seem to be pointing in a different direction … and to find completely new things in biology that we didn’t even know to look for.”
Support for the research came from the Gordon and Betty Moore Foundation, the William H. Neukom Institute for Computational Science, the National Institutes of Health, and the Cystic Fibrosis Foundation.
* In 2012, Google-sponsored researchers applied a similar method to randomly selected YouTube images; their system learned to recognize major recurring features of those images — including cats of course.
Abstract of ADAGE-Based Integration of Publicly Available Pseudomonas aeruginosa Gene Expression Data with Denoising Autoencoders Illuminates Microbe-Host Interactions
The increasing number of genome-wide assays of gene expression available from public databases presents opportunities for computational methods that facilitate hypothesis generation and biological interpretation of these data. We present an unsupervised machine learning approach, ADAGE (analysis using denoising autoencoders of gene expression), and apply it to the publicly available gene expression data compendium for Pseudomonas aeruginosa. In this approach, the machine-learned ADAGE model contained 50 nodes which we predicted would correspond to gene expression patterns across the gene expression compendium. While no biological knowledge was used during model construction, cooperonic genes had similar weights across nodes, and genes with similar weights across nodes were significantly more likely to share KEGG pathways. By analyzing newly generated and previously published microarray and transcriptome sequencing data, the ADAGE model identified differences between strains, modeled the cellular response to low oxygen, and predicted the involvement of biological processes based on low-level gene expression differences. ADAGE compared favorably with traditional principal component analysis and independent component analysis approaches in its ability to extract validated patterns, and based on our analyses, we propose that these approaches differ in the types of patterns they preferentially identify. We provide the ADAGE model with analysis of all publicly available P. aeruginosa GeneChip experiments and open source code for use with other species and settings. Extraction of consistent patterns across large-scale collections of genomic data using methods like ADAGE provides the opportunity to identify general principles and biologically important patterns in microbial biology. This approach will be particularly useful in less-well-studied microbial species.
Abstract of Unsupervised feature construction and knowledge extraction from genome-wide assays of breast cancer with denoising autoencoders
Big data bring new opportunities for methods that efficiently summarize and automatically extract knowledge from such compendia. While both supervised learning algorithms and unsupervised clustering algorithms have been successfully applied to biological data, they are either dependent on known biology or limited to discerning the most significant signals in the data. Here we present denoising autoencoders (DAs), which employ a data-defined learning objective independent of known biology, as a method to identify and extract complex patterns from genomic data. We evaluate the performance of DAs by applying them to a large collection of breast cancer gene expression data. Results show that DAs successfully construct features that contain both clinical and molecular information. There are features that represent tumor or normal samples, estrogen receptor (ER) status, and molecular subtypes. Features constructed by the autoencoder generalize to an independent dataset collected using a distinct experimental platform. By integrating data from ENCODE for feature interpretation, we discover a feature representing ER status through association with key transcription factors in breast cancer. We also identify a feature highly predictive of patient survival and it is enriched by FOXM1 signaling pathway. The features constructed by DAs are often bimodally distributed with one peak near zero and another near one, which facilitates discretization. In summary, we demonstrate that DAs effectively extract key biological principles from gene expression data and summarize them into constructed features with convenient properties.
references:
- Jie Tan, John H. Hammond, Deborah A. Hogan, Casey S. Greene. ADAGE-Based Integration of Publicly Available Pseudomonas aeruginosa Gene Expression Data with Denoising Autoencoders Illuminates Microbe-Host Interactions. mSystems, 19 January 2016; DOI: 10.1128/mSystems.00025-15 (open access)
- Tan J, Ung M, Cheng C, Greene CS. Unsupervised feature construction and knowledge extraction from genome-wide assays of breast cancer with denoising autoencoders. Pacific Symposium of Biocomputing 2015:132-43. (open access)

")
{kind=link}