Healthcare analytics, AI solutions for biological big data, providing an AI platform for the biotech, life sciences, medical and pharmaceutical industries, as well as for related technological approaches, i.e., curation and text analysis with machine learning and other activities related to AI applications to these industries.
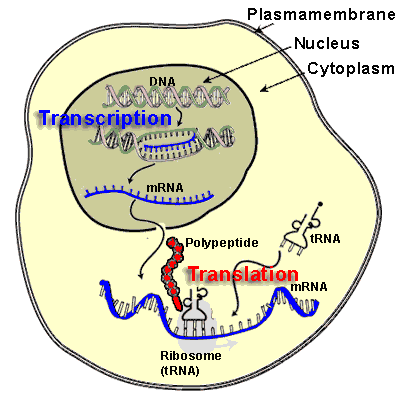
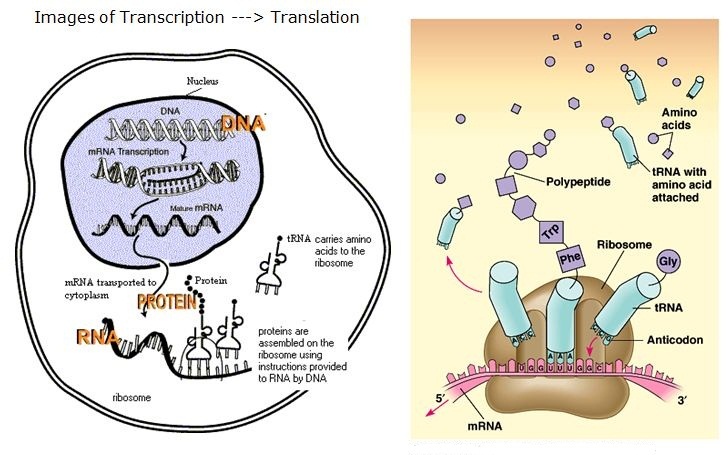
The following chapter of the metabolism/transcriptomics/proteomics/metabolomics series deals with the subcellular structure of the cell. This would have to include the cytoskeleton, which has a key role in substrate and ion efflux and influx, and in cell movement mediated by tubulins. It has been extensively covered already. Much of the contributions here are concerned with the mitochondrion, which is also covered in metabolic pathways. The ribosome is the organelle that we have discussed with respect to the transcription and translation of the genetic code through mRNA and tRNA, and the therapeutic implications of SiRNA as well as the chromatin regulation of lncRNA.
We have also encountered the mitochondrion and the lysosome in the discussion of apoptosis and autophagy, maintaining the balance between cell regeneration and cell death.
Found within the cytoplasm of both plant and animal cells, the Golgi is composed of stacks of membrane-bound structures known as cisternae (singular: cisterna). An individual stack is sometimes called a dictyosome (from Greek dictyon: net + soma: body), especially in plant cells. A mammalian cell typically contains 40 to 100 stacks. Between four and eight cisternae are usually present in a stack; however, in some protists as many as sixty have been observed. Each cisterna comprises a flat, membrane-enclosed disc that includes special Golgi enzymes which modify or help to modify cargo proteins that travel through it.
The cisternae stack has four functional regions: the cis-Golgi network, medial-Golgi, endo-Golgi, and trans-Golgi network. Vesicles from the endoplasmic reticulum (via the vesicular-tubular clusters) fuse with the network and subsequently progress through the stack to the trans-Golgi network, where they are packaged and sent to their destination.
The Golgi apparatus is integral in modifying, sorting, and packaging these macromolecules for cell secretion (exocytosis) or use within the cell. It primarily modifies proteins delivered from the rough endoplasmic reticulum, but is also involved in the transport of lipids around the cell, and the creation of lysosomes. Enzymes within the cisternae are able to modify the proteins by addition of carbohydrates (glycosylation) and phosphates (phosphorylation). In order to do so, the Golgi imports substances such as nucleotide sugars from the cytosol. These modifications may also form a signal sequence which determines the final destination of the protein. For example, the Golgi apparatus adds a mannose-6-phosphate label to proteins destined for lysosomes.
The Golgi plays an important role in the synthesis of proteoglycans, which are molecules present in the extracellular matrix of animals. It is also a major site of carbohydrate synthesis. This includes the production of glycosaminoglycans (GAGs), long unbranched polysaccharides which the Golgi then attaches to a protein synthesised in the endoplasmic reticulum to form proteoglycans. Enzymes in the Golgi polymerize several of these GAGs via a xylose link onto the core protein. Another task of the Golgi involves the sulfation of certain molecules passing through its lumen via sulfotranferases that gain their sulfur molecule from a donor called PAPS. This process occurs on the GAGs of proteoglycans as well as on the core protein. Sulfation is generally performed in the trans-Golgi network. The level of sulfation is very important to the proteoglycans’ signalling abilities, as well as giving the proteoglycan its overall negative charge.
The phosphorylation of molecules requires that ATP is imported into the lumen of the Golgi and utilised by resident kinases such as casein kinase 1 and casein kinase 2. One molecule that is phosphorylated in the Golgi is apolipoprotein, which forms a molecule known as VLDL that is found in plasma. It is thought that the phosphorylation of these molecules labels them for secretion into the blood.
The Golgi has a putative role in apoptosis, with several Bcl-2 family members localised there, as well as to the mitochondria. A newly characterized protein, GAAP (Golgi anti-apoptotic protein), almost exclusively resides in the Golgi and protects cells from apoptosis by an as-yet undefined mechanism.
The vesicles that leave the rough endoplasmic reticulum are transported to the cis face of the Golgi apparatus, where they fuse with the Golgi membrane and empty their contents into the lumen. Once inside the lumen, the molecules are modified, then sorted for transport to their next destinations. The Golgi apparatus tends to be larger and more numerous in cells that synthesize and secrete large amounts of substances; for example, the plasma B cells and the antibody-secreting cells of the immune system have prominent Golgi complexes.
Those proteins destined for areas of the cell other than either the endoplasmic reticulum or Golgi apparatus are moved towards the trans face, to a complex network of membranes and associated vesicles known as the trans-Golgi network (TGN). This area of the Golgi is the point at which proteins are sorted and shipped to their intended destinations by their placement into one of at least three different types of vesicles, depending upon the molecular marker they carry.
Nucleus_ER_golgi
Diagram of secretory process from endoplasmic reticulum (orange) to Golgi apparatus (pink). 1. Nuclear membrane; 2. Nuclear pore; 3. Rough endoplasmic reticulum (RER); 4. Smooth endoplasmic reticulum (SER); 5. Ribosome attached to RER; 6. Macromolecules; 7. Transport vesicles; 8. Golgi apparatus; 9. Cis face of Golgi apparatus; 10. Trans face of Golgi apparatus; 11. Cisternae of the Golgi Apparatus
Exocytotic vesicles
After packaging, the vesicles bud off and immediately move towards the plasma membrane, where they fuse and release the contents into the extracellular space in a process known as constitutive secretion. (Antibody release by activated plasma B cells)
Secretory vesicles
After packaging, the vesicles bud off and are stored in the cell until a signal is given for their release. When the appropriate signal is received they move towards the membrane and fuse to release their contents. This process is known as regulated secretion. (Neurotransmitter release from neurons)
Lysosomal vesicles
Vesicle contains proteins and ribosomes destined for the lysosome, an organelle of degradation containing many acid hydrolases, or to lysosome-like storage organelles. These proteins include both digestive enzymes and membrane proteins. The vesicle first fuses with the late endosome, and the contents are then transferred to the lysosome via unknown mechanisms.
Enzymes of the lysosomes are synthesised in the rough endoplasmic reticulum. The enzymes are released from Golgi apparatus in small vesicles which ultimately fuse with acidic vesicles called endosomes, thus becoming full lysosomes. In the process the enzymes are specifically tagged with mannose 6-phosphate to differentiate them from other enzymes. Lysosomes are interlinked with three intracellular processes namely phagocytosis, endocytosis and autophagy. Extracellular materials such as microorganisms taken up by phagocytosis, macromolecules by endocytosis, and unwanted cell organelles are fused with lysosomes in which they are broken down to their basic molecules. Thus lysosomes are the recycling units of a cell.
The endoplasmic reticulum (ER) is a type of organelle in the cells of eukaryotic organisms that forms an interconnected network of flattened, membrane-enclosed sacs or tubes known as cisternae. The membranes of the ER are continuous with the outer membrane of the nuclear envelope. Endoplasmic reticulum occurs in most types of eukaryotic cells, including the most primitive Giardia, but is absent from red blood cells and spermatozoa. There are two types of endoplasmic reticulum, rough endoplasmic reticulum (RER) and smooth endoplasmic reticulum (SER). The outer (cytosolic) face of the rough endoplasmic reticulum is studded with ribosomes that are the sites of protein synthesis. The rough endoplasmic reticulum is especially prominent in cells such as hepatocytes where active smooth endoplasmic reticulum lacks ribosomes and functions in lipid metabolism, carbohydrate metabolism, and detoxificationand is especially abundant in mammalian liver and gonad cells. The lacey membranes of the endoplasmic reticulum were first seen in 1945 by Keith R. Porter, Albert Claude, Brody Meskers and Ernest F. Fullam, using electron microscopy.
The Effects of Actomyosin Tension on Nuclear Pore Transport
Rachel Sammons
Undergraduate Honors Thesis
Spring 2011
The cytoskeleton maintains cellular structure and tension through a force balance with the nucleus, where actomyosin is anchored to the nuclear envelope by nesprin integral proteins. It is hypothesized that the presence or absence of this tension alters the transport of molecules through the nuclear pore complex. We tested the effects of cytoskeletal tension on nuclear transport in human umbilical vein endothelial cells (HUVECs) by performing fluorescence recovery after photo-bleaching (FRAP) experiments on the nuclei to monitor the passive transport of the molecules through nuclear pores.
Using myosin inhibitors, as well as siRNA transfections to reduce the expression of nesprin-1, we altered the nucleo-cytoskeletal force balance and monitored the effect of each on the nuclear pore. FRAP data was fit to a diffusion model by assuming pseudo-steady state inside the nuclear pore, perfect mixing within both the cytoplasm and the nucleus, and no intracellular binding of the fluorescent probes. From these results and a model from the current literature relating diffusion rate constants to nuclear pore radii, we were able to determine that changing cytoskeletal tension alters nuclear pore size and passive transport.
nuclear pores in nuclear envelope
image of nuclear pores on the external surface of the nuclear envelope
nuclear envelope and FG filaments
nuclear envelope and FG filaments
Figure 1: The structure and location of the nuclear pore, shown by (a) AFM image of nuclear pores on the external surface of the nuclear envelope[5] and (b) computer model cross-section. The nuclear envelope is shown in cyan, and FG filaments in blue can be seen throughout the channel. The nuclear basket extends into the nucleoplasm.
Fusion-pore expansion during syncytium formation is restricted by an actin network
A Chen, E Leikina, K Melikov, B Podbilewicz, MM. Kozlov and LV. Chernomordik,*
J Cell Sci 1 Nov 2008;121: 3619-3628. http://dx.doi.org:/10.1242/jcs.032169
Effects of actin-modifying agents indicate that the actin cortex slows down pore expansion. We propose that the growth of the strongly bent fusion-pore rim is restricted by a dynamic resistance of the actin network and driven by membrane-bending proteins that are involved in the generation of highly curved intracellular membrane compartments.
This chapter I made to follow signaling, rather than to precede it. I had already written much of the content before reorganizing the contents. The previous chapters on carbohydrate and on lipid metabolism have already provided much material on proteins and protein function, which was persuasive of the need to introduce signaling, which entails a substantial introduction to conformational changes in proteins that direct the trafficking of metabolic pathways, but more subtly uncovers an important role for microRNAs, not divorced from transcription, but involved in a non-transcriptional role. This is where the classic model of molecular biology lacked any integration with emerging metabolic concepts concerning regulation. Consequently, the science was bereft of understanding the ties between the multiple convergence of transcripts, the selective inhibition of transcriptions, and the relative balance of aerobic and anaerobic metabolism, the weight of the pentose phosphate shunt, and the utilization of available energy source for synthetic and catabolic adaptive responses.
The first subchapter serves to introduce the importance of transcription in translational science. The several subtitles that follow are intended to lay out the scope of the transcriptional activity, and also to direct attention toward the huge role of proteomics in the cell construct. As we have already seen, proteins engage with carbohydrates and with lipids in important structural and signaling processes. They are integrasl to the composition of the cytoskeleton, and also to the extracellular matrix. Many proteins are actually enzymes, carrying out the transformation of some substrate, a derivative of the food we ingest. They have a catalytic site, and they function with a cofactor – either a multivalent metal or a nucleotide.
The amino acids that go into protein synthesis include “indispensable” nutrients that are not made for use, but must be derived from animal protein, although the need is partially satisfied by plant sources. The essential amino acids are classified into well established groups. There are 20 amino acids commonly found in proteins. They are classified into the following groups based on the chemical and/or structural properties of their side chains :
Aliphatic Amino Acids
Cyclic Amino Acid
AAs with Hydroxyl or Sulfur-containing side chains
Inosine triphosphate pyrophosphatase – Pyrophosphatase that hydrolyzes the non-canonical purine nucleotides inosine triphosphate (ITP), deoxyinosine triphosphate (dITP) as well as 2′-deoxy-N-6-hydroxylaminopurine triposphate (dHAPTP) and xanthosine 5′-triphosphate (XTP) to their respective monophosphate derivatives. The enzyme does not distinguish between the deoxy- and ribose forms. Probably excludes non-canonical purines from RNA and DNA precursor pools, thus preventing their incorporation into RNA and DNA and avoiding chromosomal lesions.
Genetic variation of inosine triphosphatase (ITPA) causing an accumulation of inosine triphosphate (ITP) has been shown to protect patients against ribavirin (RBV)-induced anemia during treatment for chronic hepatitis C infection by genome-wide association study (GWAS). However, the biologic mechanism by which this occurs is unknown.
Although ITP is not used directly by human erythrocyte ATPase, it can be used for ATP biosynthesis via ADSS in place of guanosine triphosphate (GTP). With RBV challenge, erythrocyte ATP reduction was more severe in the wild-type ITPA genotype than in the hemolysis protective ITPA genotype. This difference also remains after inhibiting adenosine uptake using nitrobenzylmercaptopurine riboside (NBMPR).
ITP confers protection against RBV-induced ATP reduction by substituting for erythrocyte GTP, which is depleted by RBV, in the biosynthesis of ATP. Because patients with excess ITP appear largely protected against anemia, these results confirm that RBV-induced anemia is due primarily to the effect of the drug on GTP and consequently ATP levels in erythrocytes.
Determination of inosine triphosphate pyrophosphatase phenotype in human red blood cells using HPLC.
Citterio-Quentin A1, Salvi JP, Boulieu R.
Thiopurine drugs, widely used in cancer chemotherapy, inflammatory bowel disease, and autoimmune hepatitis, are responsible for common adverse events. Only some of these may be explained by genetic polymorphism of thiopurine S-methyltransferase. Recent articles have reported that inosine triphosphate pyrophosphatase (ITPase) deficiency was associated with adverse drug reactions toward thiopurine drug therapy. Here, we report a weak anion exchange high-performance liquid chromatography method to determine ITPase activity in red blood cells and to investigate the relationship with the occurrence of adverse events during azathioprine therapy.
The chromatographic method reported allows the analysis of IMP, inosine diphosphate, and ITP in a single run in <12.5 minutes. The method was linear in the range 5-1500 μmole/L of IMP. Intraassay and interassay precisions were <5% for red blood cell lysates supplemented with 50, 500, and 1000 μmole/L IMP. Km and Vmax evaluated by Lineweaver-Burk plot were 677.4 μmole/L and 19.6 μmole·L·min, respectively. The frequency distribution of ITPase from 73 patients was investigated.
The method described is useful to determine the ITPase phenotype from patients on thiopurine therapy and to investigate the potential relation between ITPase deficiency and the occurrence of adverse events.
System wide analyses have underestimated protein abundances and the importance of transcription in mammals
Jingyi Jessica Li1, 2, Peter J Bickel1 and Mark D Biggin3
Using individual measurements for 61 housekeeping proteins to rescale whole proteome data from Schwanhausser et al. (2011), we find that the median protein detected is expressed at 170,000 molecules per cell and that our corrected protein abundance estimates show a higher correlation with mRNA abundances than do the uncorrected protein data. In addition, we estimated the impact of further errors in mRNA and protein abundances using direct experimental measurements of these errors. The resulting analysis suggests that mRNA levels explain at least 56% of the differences in protein abundance for the 4,212 genes detected by Schwanhausser et al. (2011), though because one major source of error could not be estimated the true percent contribution should be higher.We also employed a second, independent strategy to determine the contribution of mRNA levels to protein expression.We show that the variance in translation rates directly measured by ribosome profiling is only 12% of that inferred by Schwanhausser et al. (2011), and that the measured and inferred translation rates correlate poorly (R2 D 0.13). Based on this, our second strategy suggests that mRNA levels explain 81% of the variance in protein levels. We also determined the percent contributions of transcription, RNA degradation, translation and protein degradation to the variance in protein abundances using both of our strategies. While the magnitudes of the two estimates vary, they both suggest that transcription plays a more important role than the earlier studies implied and translation a much smaller role. Finally, the above estimates only apply to those genes whose mRNA and protein expression was detected. Based on a detailed analysis by Hebenstreit et al. (2012), we estimat that approximately 40% of genes in a given cell within a population express no mRNA. Since there can be no translation in the ab-sence of mRNA, we argue that differences in translation rates can play no role in determining the expression levels for the 40% of genes that are non-expressed.
Related studies that reveal issues that are not part of this chapter:
Ubiquitylation in relationship to tissue remodeling
Post-translational modification of proteins
Glycosylation
Phosphorylation
Methylation
Nitrosylation
Sulfation – sulfotransferases
cell-matrix communication
Acetylation and histone deacetylation (HDAC)
Connecting Protein Phosphatase to 1α (PP1α)
Acetylation complexes (such as CBP/p300 and PCAF)
Sirtuins
Rel/NF-kB Signal Transduction
Homologous Recombination Pathway of Double-Strand DNA Repair
Glycination
cyclin dependent kinases (CDKs)
lyase
transferase
This year, the Lasker award for basic medical research went to Kazutoshi Mori (Kyoto University) and Peter Walter (University of California, San Francisco) for their “discoveries concerning the unfolded protein response (UPR) — an intracellular quality control system that
detects harmful misfolded proteins in the endoplasmic reticulum and signals the nucleus to carry out corrective measures.”
About UPR: Approximately a third of cellular proteins pass through the Endoplasmic Reticulum (ER) which performs stringent quality control of these proteins. All proteins need to assume the proper 3-dimensional shape in order to function properly in the harsh cellular environment. Related to this is the fact that cells are under constant stress and have to make rapid, real time decisions about survival or death.
A major indicator of stress is the accumulation of unfolded proteins within the Endoplasmic Reticulum (ER), which triggers a transcriptional cascade in order to increase the folding capacity of the ER. If the metabolic burden is too great and homeostasis cannot be achieved, the response shifts from
damage control to the induction of pro-apoptotic pathways that would ultimately cause cell death.
This response to unfolded proteins or the UPR is conserved among all eukaryotes, and dysfunction in this pathway underlies many human diseases, including Alzheimer’s, Parkinson’s, Diabetes and Cancer.
The discovery of a new class of human proteins with previously unidentified activities
In a landmark study conducted by scientists at the Scripps Research Institute, The Hong Kong University of Science and Technology, aTyr Pharma and their collaborators, a new class of human proteins has been discovered. These proteins [nearly 250], called Physiocrines belong to the aminoacyl tRNA synthetase gene family and carry out novel, diverse and distinct biological functions.
The aminoacyl tRNA synthetase gene family codes for a group of 20 ubiquitous enzymes almost all of which are part of the protein synthesis machinery. Using recombinant protein purification, deep sequencing technique, mass spectroscopy and cell based assays, the team made this discovery. The finding is significant, also because it highlights the alternate use of a gene family whose protein product normally performs catalytic activities for non-catalytic regulation of basic and complex physiological processes spanning metabolism, vascularization, stem cell biology and immunology
Muscle maintenance and regeneration – key player identified
Muscle tissue suffers from atrophy with age and its regenerative capacity also declines over time. Most molecules discovered thus far to boost tissue regeneration are also implicated in cancers. During a quest to find safer alternatives that can regenerate tissue, scientists reported that the hormone Oxytocin is required for proper muscle tissue regeneration and homeostasis and that its levels decline with age.
Oxytocin could be an alternative to hormone replacement therapy as a way to combat aging and other organ related degeneration.
Oxytocin is an age-specific circulating hormone that is necessary for muscle maintenance and regeneration (June 2014)
Role of forkhead box protein A3 in age-associated metabolic decline.
Ma X1, Xu L1, Gavrilova O2, Mueller E3.
Aging is associated with increased adiposity and diminished thermogenesis, but the critical transcription factors influencing these metabolic changes late in life are poorly understood. We recently demonstrated that the winged helix factor forkhead box protein A3 (Foxa3) regulates the expansion of visceral adipose tissue in high-fat diet regimens; however, whether Foxa3 also contributes to the increase in adiposity and the decrease in brown fat activity observed during the normal aging process is currently unknown. Here we report that during aging, levels of Foxa3 are significantly and selectively up-regulated in brown and inguinal white fat depots, and that midage Foxa3-null mice have increased white fat browning and thermogenic capacity, decreased adipose tissue expansion, improved insulin sensitivity, and increased longevity. Foxa3 gain-of-function and loss-of-function studies in inguinal adipose depots demonstrated a cell-autonomous function for Foxa3 in white fat tissue browning. Furthermore, our analysis revealed that the mechanisms of Foxa3 modulation of brown fat gene programs involve the suppression of peroxisome proliferator activated receptor γ coactivtor 1 α (PGC1α) levels through interference with cAMP responsive element binding protein 1-mediated transcriptional regulation of the PGC1α promoter.
Asymmetric mRNA localization contributes to fidelity and sensitivity of spatially localized systems
Although many proteins are localized after translation, asymmetric protein distribution is also achieved by translation after mRNA localization. Why are certain mRNA transported to a distal location and translated on-site? Here we undertake a systematic, genome-scale study of asymmetrically distributed protein and mRNA in mammalian cells. Our findings suggest that asymmetric protein distribution by mRNA localization enhances interaction fidelity and signaling sensitivity. Proteins synthesized at distal locations frequently contain intrinsically disordered segments. These regions are generally rich in assembly-promoting modules and are often regulated by post-translational modifications. Such proteins are tightly regulated but display distinct temporal dynamics upon stimulation with growth factors. Thus, proteins synthesized on-site may rapidly alter proteome composition and act as dynamically regulated scaffolds to promote the formation of reversible cellular assemblies. Our observations are consistent across multiple mammalian species, cell types and developmental stages, suggesting that localized translation is a recurring feature of cell signaling and regulation.
An overview of the potential advantages conferred by distal-site protein synthesis, inferred from our analysis.
An overview of the potential advantages conferred by distal-site protein synthesis
Turquoise and red filled circle represents off-target and correct interaction partners, respectively. Wavy lines represent a disordered region within a distal site synthesis protein. Grey and red line in graphs represents profiles of t…
Tweaking transcriptional programming for high quality recombinant protein production
Since overexpression of recombinant proteins in E. coli often leads to the formation of inclusion bodies, producing properly folded, soluble proteins is undoubtedly the most important end goal in a protein expression campaign. Various approaches have been devised to bypass the insolubility issues during E. coli expression and in a recent report a group of researchers discuss reprogramming the E. coli proteostasis [protein homeostasis] network to achieve high yields of soluble, functional protein. The premise of their studies is that the basal E. coli proteostasis network is insufficient, and often unable, to fold overexpressed proteins, thus clogging the folding machinery.
By overexpressing a mutant, negative-feedback deficient heat shock transcription factor [σ32 I54N] before and during overexpression of the protein of interest, reprogramming can be achieved, resulting in high yields of soluble and functional recombinant target protein. The authors explain that this method is better than simply co-expressing/over-expressing chaperones, co-chaperones, foldases or other components of the proteostasis network because reprogramming readies the folding machinery and up regulates the essential folding components beforehand thus maintaining system capability of the folding machinery.
The Heat-Shock Response Transcriptional Program Enables High-Yield and High-Quality Recombinant Protein Production in Escherichia coli (July 2014)
Unfolded proteins collapse when exposed to heat and crowded environments
Proteins are important molecules in our body and they fulfil a broad range of functions. For instance as enzymes they help to release energy from food and as muscle proteins they assist with motion. As antibodies they are involved in immune defence and as hormone receptors in signal transduction in cells. Until only recently it was assumed that all proteins take on a clearly defined three-dimensional structure – i.e. they fold in order to be able to assume these functions. Surprisingly, it has been shown that many important proteins occur as unfolded coils. Researchers seek to establish how these disordered proteins are capable at all of assuming highly complex functions.
Ben Schuler’s research group from the Institute of Biochemistry of the University of Zurich has now established that an increase in temperature leads to folded proteins collapsing and becoming smaller. Other environmental factors can trigger the same effect.
Measurements using the “molecular ruler”
“The fact that unfolded proteins shrink at higher temperatures is an indication that cell water does indeed play an important role as to the spatial organisation eventually adopted by the molecules”, comments Schuler with regard to the impact of temperature on protein structure. For their studies the biophysicists use what is known as single-molecule spectroscopy. Small colour probes in the protein enable the observation of changes with an accuracy of more than one millionth of a millimetre. With this “molecular yardstick” it is possible to measure how molecular forces impact protein structure.
With computer simulations the researchers have mimicked the behaviour of disordered proteins.
(Courtesy of Jose EDS Roselino, PhD.
MLKL compromises plasma membrane integrity
Necroptosis is implicated in many diseases and understanding this process is essential in the search for new therapies. While mixed lineage kinase domain-like (MLKL) protein has been known to be a critical component of necroptosis induction, how MLKL transduces the death signal was not clear. In a recent finding, scientists demonstrated that the full four-helical bundle domain (4HBD) in the N-terminal region of MLKL is required and sufficient to induce its oligomerization and trigger cell death.
They also found a patch of positively charged amino acids on the surface of the 4HBD that bound to phosphatidylinositol phosphates (PIPs) and allowed the recruitment of MLKL to the plasma membrane that resulted in the formation of pores consisting of MLKL proteins, due to which cells absorbed excess water causing them to explode. Detailed knowledge about how MLKL proteins create pores offers possibilities for the development of new therapeutic interventions for tolerating or preventing cell death.
MLKL compromises plasma membrane integrity by binding to phosphatidylinositol phosphates (May 2014)
Mitochondrial and ER proteins implicated in dementia
Mitochondria and the endoplasmic reticulum (ER) form tight structural associations that facilitate a number of cellular functions. However, the molecular mechanisms of these interactions aren’t properly understood.
A group of researchers showed that the ER protein VAPB interacted with mitochondrial protein PTPIP51 to regulate ER-mitochondria associations and that TDP-43, a protein implicated in dementia, disturbs this interaction to regulate cellular Ca2+ homeostasis. These studies point to a new pathogenic mechanism for TDP-43 and may also provide a potential new target for the development of new treatments for devastating neurological conditions like dementia.
ER-mitochondria associations are regulated by the VAPB-PTPIP51 interaction and are disrupted by ALS/FTD-associated TDP-43. Nature (June 2014)
A novel strategy to improve membrane protein expression in Yeast
Membrane proteins play indispensable roles in the physiology of an organism. However, recombinant production of membrane proteins is one of the biggest hurdles facing protein biochemists today. A group of scientists in Belgium showed that,
by increasing the intracellular membrane production by interfering with a key enzymatic step of lipid synthesis,
enhanced expression of recombinant membrane proteins in yeast is achieved.
Specifically, they engineered the oleotrophic yeast, Yarrowia lipolytica, by
deleting the phosphatidic acid phosphatase, PAH1 gene,
which led to massive proliferation of endoplasmic reticulum (ER) membranes.
For all 8 tested representatives of different integral membrane protein families, they obtained enhanced protein accumulation.
An unconventional method to boost recombinant protein levels
MazF is an mRNA interferase enzyme in E.coli that functions as and degrades cellular mRNA in a targeted fashion, at the “ACA” sequence. This degradation of cellular mRNA causes a precipitous drop in cellular protein synthesis. A group of scientists at the Robert Wood Johnson Medical School in New Jersey, exploited the degeneracy of the genetic code to modify all “ACA” triplets within their gene of interest in a way that the corresponding amino acid (Threonine) remained unchanged. Consequently, induction of MazF toxin caused degradation of E.coli cellular mRNA but the recombinant gene transcription and protein synthesis continued, causing significant accumulation of high quality target protein. This expression system enables unparalleled signal to noise ratios that could dramatically simplify structural and functional studies of difficult-to-purify, biologically important proteins.
Tandem fusions and bacterial strain evolution for enhanced functional membrane protein production
Membrane protein production remains a significant challenge in its characterization and structure determination. Despite the fact that there are a variety of host cell types, E.coli remains the popular choice for producing recombinant membrane proteins. A group of scientists in Netherlands devised a robust strategy to increase the probability of functional membrane protein overexpression in E.coli.
By fusing Green Fluorescent Protein (GFP) and the Erythromycin Resistance protein (ErmC) to the C-terminus of a target membrane protein they wer e able to track the folding state of their target protein while using Erythromycin to select for increased expression. By increasing erythromycin concentration in the growth media and testing different membrane targets, they were able to identify four evolved E.coli strains, all of which carried a mutation in the hns gene, whose product is implicated in genome organization and transcriptional silencing. Through their experiments the group showed that partial removal of the transcriptional silencing mechanism was related to production of proteins that were essential for functional overexpression of membrane proteins.
The role of an anti-apoptotic factor in recombinant protein production
In a recent study, scientists at the Johns Hopkins University and Frederick National Laboratory for Cancer Research examined an alternative method of utilizing the benefits of anti-apoptotic gene expression to enhance the transient expression of biotherapeutics, specifically, through the co-transfection of Bcl-xL along with the product-coding target gene.
Chinese Hamster Ovary(CHO) cells were co-transfected with the product-coding gene and a vector containing Bcl-xL, using Polyethylenimine (PEI) reagent. They found that the cells co-transfected with Bcl-xL demonstrated reduced apoptosis, increased specific productivity, and an overall increase in product yield.
B-cell lymphoma-extra-large (Bcl-xL) is a mitochondrial transmembrane protein and a member of the Bcl-2 family of proteins which are known to act as either pro- or anti-apoptotic proteins. Bcl-xL itself acts as an anti-apoptotic molecule by preventing the release of mitochondrial contents such as cytochrome c, which would lead to caspase activation. Higher levels of Bcl-xL push a cell toward survival mode by making the membranes pores less permeable and leaky.
Introduction to Protein Synthesis and DegradationUpdated 8/31/2019
N-Terminal Degradation of Proteins: The N-End Rule and N-degrons
In both prokaryotes and eukaryotes mitochondria and chloroplasts, the ribosomal synthesis of proteins is initiated with the addition of the N-formyl methionine residue. However in eukaryotic cytosolic ribosomes, the N terminal was assumed to be devoid of the N-formyl group. The unformylated N-terminal methionine residues of eukaryotes is then often N-acetylated (Ac) and creates specific degradation signals, the Ac N-end rule. These N-end rule pathways are proteolytic systems which recognize these N-degrons resulting in proteosomal degradation or autophagy. In prokaryotes this system is stimulated by certain amino acid deficiencies and in eukaryotes is dependent on the Psh1 E3 ligase.
Two papers in the journal Science describe this N-degron in more detail.
In both bacteria and eukaryotic mitochondria and chloroplasts, the ribosomal synthesis of proteins is initiated with the N-terminal (Nt) formyl-methionine (fMet) residue. Nt-fMet is produced pretranslationally by formyltransferases, which use 10-formyltetrahydrofolate as a cosubstrate. By contrast, proteins synthesized by cytosolic ribosomes of eukaryotes were always presumed to bear unformylated N-terminal Met (Nt-Met). The unformylated Nt-Met residue of eukaryotic proteins is often cotranslationally Nt-acetylated, a modification that creates specific degradation signals, Ac/N-degrons, which are targeted by the Ac/N-end rule pathway. The N-end rule pathways are a set of proteolytic systems whose unifying feature is their ability to recognize proteins containing N-degrons, thereby causing the degradation of these proteins by the proteasome or autophagy in eukaryotes and by the proteasome-like ClpAP protease in bacteria. The main determinant of an N‑degron is a destabilizing Nt-residue of a protein. Studies over the past three decades have shown that all 20 amino acids of the genetic code can act, in cognate sequence contexts, as destabilizing Nt‑residues. The previously known eukaryotic N-end rule pathways are the Arg/N-end rule pathway, the Ac/N-end rule pathway, and the Pro/N-end rule pathway. Regulated degradation of proteins and their natural fragments by the N-end rule pathways has been shown to mediate a broad range of biological processes.
RATIONALE
The chemical similarity of the formyl and acetyl groups and their identical locations in, respectively, Nt‑formylated and Nt-acetylated proteins led us to suggest, and later to show, that the Nt-fMet residues of nascent bacterial proteins can act as bacterial N-degrons, termed fMet/N-degrons. Here we wished to determine whether Nt-formylated proteins might also form in the cytosol of a eukaryote such as the yeast Saccharomyces cerevisiae and to determine the metabolic fates of Nt-formylated proteins if they could be produced outside mitochondria. Our approaches included molecular genetic techniques, mass spectrometric analyses of proteins’ N termini, and affinity-purified antibodies that selectively recognized Nt-formylated reporter proteins.
RESULTS
We discovered that the yeast formyltransferase Fmt1, which is imported from the cytosol into the mitochondria inner matrix, can generate Nt-formylated proteins in the cytosol, because the translocation of Fmt1 into mitochondria is not as efficacious, even under unstressful conditions, as had previously been assumed. We also found that Nt‑formylated proteins are greatly up-regulated in stationary phase or upon starvation for specific amino acids. The massive increase of Nt-formylated proteins strictly requires the Gcn2 kinase, which phosphorylates Fmt1 and mediates its retention in the cytosol. Notably, the ability of Gcn2 to retain a large fraction of Fmt1 in the cytosol of nutritionally stressed cells is confined to Fmt1, inasmuch as the Gcn2 kinase does not have such an effect, under the same conditions, on other examined nuclear DNA–encoded mitochondrial matrix proteins. The Gcn2-Fmt1 protein localization circuit is a previously unknown signal transduction pathway. A down-regulation of cytosolic Nt‑formylation was found to increase the sensitivity of cells to undernutrition stresses, to a prolonged cold stress, and to a toxic compound. We also discovered that the Nt-fMet residues of Nt‑formylated cytosolic proteins act as eukaryotic fMet/N-degrons and identified the Psh1 E3 ubiquitin ligase as the recognition component (fMet/N-recognin) of the previously unknown eukaryotic fMet/N-end rule pathway, which destroys Nt‑formylated proteins.
CONCLUSION
The Nt-formylation of proteins, a long-known pretranslational protein modification, is mediated by formyltransferases. Nt-formylation was thought to be confined to bacteria and bacteria-descended eukaryotic organelles but was found here to also occur at the start of translation by the cytosolic ribosomes of a eukaryote. The levels of Nt‑formylated eukaryotic proteins are greatly increased upon specific stresses, including undernutrition, and appear to be important for adaptation to these stresses. We also discovered that Nt-formylated cytosolic proteins are selectively destroyed by the eukaryotic fMet/N-end rule pathway, mediated by the Psh1 E3 ubiquitin ligase. This previously unknown proteolytic system is likely to be universal among eukaryotes, given strongly conserved mechanisms that mediate Nt‑formylation and degron recognition.
(Top) Under undernutrition conditions, the Gcn2 kinase augments the cytosolic localization of the Fmt1 formyltransferase, and possibly also its enzymatic activity. Consequently, Fmt1 up-regulates the cytosolic fMet–tRNAi (initiator transfer RNA), and thereby increases the levels of cytosolic Nt-formylated proteins, which are required for the adaptation of cells to specific stressors. (Bottom) The Psh1 E3 ubiquitin ligase targets the N-terminal fMet-residues of eukaryotic cytosolic proteins, such as Cse4, Pgd1, and Rps22a, for the polyubiquitylation-mediated, proteasome-dependent degradation.
(Top) Under undernutrition conditions, the Gcn2 kinase augments the cytosolic localization of the Fmt1 formyltransferase, and possibly also its enzymatic activity. Consequently, Fmt1 up-regulates the cytosolic fMet–tRNAi (initiator transfer RNA), and thereby increases the levels of cytosolic Nt-formylated proteins, which are required for the adaptation of cells to specific stressors. (Bottom) The Psh1 E3 ubiquitin ligase targets the N-terminal fMet-residues of eukaryotic cytosolic proteins, such as Cse4, Pgd1, and Rps22a, for the polyubiquitylation-mediated, proteasome-dependent degradation.
The second paper describes a glycine specific N-degron pathway in humans. Specifically the authors set up a screen to identify specific N-terminal degron motifs in the human. Findings included an expanded repertoire for the UBR E3 ligases to include substrates with arginine and lysine following an intact initiator methionine and a glycine at the extreme N-terminus, which is a potent degron.
Glycine N-degron regulation revealed
For more than 30 years, N-terminal sequences have been known to influence protein stability, but additional features of these N-end rule, or N-degron, pathways continue to be uncovered. Timms et al. used a global protein stability (GPS) technology to take a broader look at these pathways in human cells. Unexpectedly, glycine exposed at the N terminus could act as a potent degron; proteins bearing N-terminal glycine were targeted for proteasomal degradation by two Cullin-RING E3 ubiquitin ligases through the substrate adaptors ZYG11B and ZER1. This pathway may be important, for example, to degrade proteins that fail to localize properly to cellular membranes and to destroy protein fragments generated during cell death.
The ubiquitin-proteasome system is the major route through which the cell achieves selective protein degradation. The E3 ubiquitin ligases are the major determinants of specificity in this system, which is thought to be achieved through their selective recognition of specific degron motifs in substrate proteins. However, our ability to identify these degrons and match them to their cognate E3 ligase remains a major challenge.
RATIONALE
It has long been known that the stability of proteins is influenced by their N-terminal residue, and a large body of work over the past three decades has characterized a collection of N-end rule pathways that target proteins for degradation through N-terminal degron motifs. Recently, we developed Global Protein Stability (GPS)–peptidome technology and used it to delineate a suite of degrons that lie at the extreme C terminus of proteins. We adapted this approach to examine the stability of the human N terminome, allowing us to reevaluate our understanding of N-degron pathways in an unbiased manner.
RESULTS
Stability profiling of the human N terminome identified two major findings: an expanded repertoire for UBR family E3 ligases to include substrates that begin with arginine and lysine following an intact initiator methionine and, more notably, that glycine positioned at the extreme N terminus can act as a potent degron. We established human embryonic kidney 293T reporter cell lines in which unstable peptides that bear N-terminal glycine degrons were fused to green fluorescent protein, and we performed CRISPR screens to identify the degradative machinery involved. These screens identified two Cul2 Cullin-RING E3 ligase complexes, defined by the related substrate adaptors ZYG11B and ZER1, that act redundantly to target substrates bearing N-terminal glycine degrons for proteasomal degradation. Moreover, through the saturation mutagenesis of example substrates, we defined the composition of preferred N-terminal glycine degrons specifically recognized by ZYG11B and ZER1.
We found that preferred glycine degrons are depleted from the native N termini of metazoan proteomes, suggesting that proteins have evolved to avoid degradation through this pathway, but are strongly enriched at annotated caspase cleavage sites. Stability profiling of N-terminal peptides lying downstream of all known caspase cleavages sites confirmed that Cul2ZYG11Band Cul2ZER1 could make a substantial contribution to the removal of proteolytic cleavage products during apoptosis. Last, we identified a role for ZYG11B and ZER1 in the quality control of N-myristoylated proteins. N-myristoylation is an important posttranslational modification that occurs exclusively on N-terminal glycine. By profiling the stability of the human N-terminome in the absence of the N-myristoyltransferases NMT1 and NMT2, we found that a failure to undergo N-myristoylation exposes N-terminal glycine degrons that are otherwise obscured. Thus, conditional exposure of glycine degrons to ZYG11B and ZER1 permits the selective proteasomal degradation of aberrant proteins that have escaped N-terminal myristoylation.
CONCLUSION
These data demonstrate that an additional N-degron pathway centered on N-terminal glycine regulates the stability of metazoan proteomes. Cul2ZYG11B– and Cul2ZER1-mediated protein degradation through N-terminal glycine degrons may be particularly important in the clearance of proteolytic fragments generated by caspase cleavage during apoptosis and in the quality control of protein N-myristoylation.
Stability profiling of the human N-terminome revealed that N-terminal glycine acts as a potent degron. CRISPR screening revealed two Cul2 complexes, defined by the related substrate adaptors ZYG11B and ZER1, that recognize N-terminal glycine degrons. This pathway may be particularly important for the degradation of caspase cleavage products during apoptosis and the removal of proteins that fail to undergo N-myristoylation.
Stability profiling of the human N-terminome revealed that N-terminal glycine acts as a potent degron. CRISPR screening revealed two Cul2 complexes, defined by the related substrate adaptors ZYG11B and ZER1, that recognize N-terminal glycine degrons. This pathway may be particularly important for the degradation of caspase cleavage products during apoptosis and the removal of proteins that fail to undergo N-myristoylation.
A new method for looking at how proteins fold inside mammal cells could one day lead to better flu vaccines, among other practical applications, say Cornell researchers.
The method, described online in the Proceedings of the National Academy of Sciences July 16, allows researchers to take snapshots of the cell’s protein-making machinery — called ribosomes — in various stages of protein production. The scientists then pieced together the snapshots to reconstruct how proteins fold during their synthesis.
Proteins are made up of long chains of amino acids called polypeptides, and folding gives each protein its characteristic structure, which determines its function. Though researchers have used synthetic and purified proteins to study protein folding, this study looks at proteins from their inception, providing a truer picture for how partially synthesized polypeptides can fold in cells.
Proteins fold so quickly — in microseconds — that it has been a longtime mystery just how polypeptide chains fold to create the protein’s structure.
“The speed is very fast, so it’s very hard to capture certain steps, but our approach can look at protein folding at the same time as it is being synthesized by the ribosomes,” said Shu-Bing Qian, assistant professor of nutritional sciences and the corresponding author on the paper. Yan Han, a postdoctoral associate in Qian’s lab, is the paper’s first author.
In a nutshell, messenger RNA (mRNA) carries the coding information for proteins from the DNA to ribosomes, which translate those codes into chains of amino acids that make up proteins. Previously, other researchers had developed a technique to localize the exact position of the ribosomes on the mRNA. Qian and colleagues further advanced this technique to selectively enrich only a certain portion of the protein-making machinery, basically taking snapshots of different stages of the protein synthesis process.
“Like a magnifier, we enrich a small pool from the bigger ocean and then paint a picture from early to late stages of the process,” Qian said.
In the paper, the researchers also describe applying this technique to better understanding a protein called hemagglutinin (HA), located on the surface of the influenza A virus; HA’s structure (folding) allows it to infect the cell.
Flu vaccines are based on antibodies that recognize such proteins as HA. But viruses have high mutation rates to escape antibody detection. Often, flu vaccines lose their effectiveness because surface proteins on the virus mutate. HA, for example, has the highest mutation rate of the flu virus’ surface proteins.
The researchers proved that their technique can identify how the folding process changes when HA mutates.
“If people know the folding picture of how a mutation changes, it will be helpful for designing a better vaccine,” Qian said.
“Folding is a very fundamental issue in biology,” Qian added. “It’s been a long-term mystery how the cell achieves this folding successfully, with such speed and with such a great success rate.”
The research was funded by the National Institute of Allergy and Infectious Diseases Division of Intramural Research, National Institutes of Health Grant, Ellison Medical Foundation Grant and U.S. Department of Defense Exploration-Hypothesis Development Award.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}