Landscape of Cardiac Biomarkers for Improved Clinical Utilization
Curator and Author: Larry H Bernstein, MD, FCAP
Curation
This reviewer has been engaged in the development, the application, and the validation of cardiac biomarkers for over 30 years. There has been a nonlinear introduction of new biomarkers in that period, with an explosion of methods discovery and large studies to validate them in concert with clinical trials. The improvement of interventional methods, imaging methods, and the unraveling of patient characteristics associated with emerging cardiovascular disease is both cause for alarm (technology costs) and for raised expectations for both prevention, risk reduction, and treatment. What is strikingly missing is the kind of data analyses on the population database that could alleviate the burden of physician overload. It is an urgent requirement for the EHR, and it needs to be put in place to facilitate patient care.
Introduction
This is a journey through the current status of biochemical markers in cardiac evaluation.
In the traditional use of cardiac biomarkers, the is a timed blood sampling from the decubital fossa. This was the case with alanine aminotransferase (AST, then SGOT), creatine kinase (CK) or its isoenzyme MB, and lactic dehydrogenase (or the isoenzyme-1). The time of sampling was based on time to appearance from time of damage, and the release of the biomarker is a stochastic process. The earliest studies of CK-MB appearance, peak height, and disappearance was by Burton Sobel and associates related to measuring the extent of damage, and determined that reperfusion had an effect. A significant reason for using a combination of CK-MB and LD-1 was that a patient who is a late arrival might have a CK-MB on the decline (peak at 18 h) while the LD-1 is rising (peak at 48 h).
The introduction of the troponins was accompanied by a serial 4 h measurement, usually for 4 draws (0, 4, 8, 12 h). The computational power of laboratory information systems was limited until recently, so it is somewhat surprising, given what we have seen – in addition to published work in the 1980’s – that this capability is not in use today, when regression and nonparametric classification algorithms are now so advanced that would enable much improved and effective communication to the physician needing the information.
J Adan, LH Bernstein, J Babb. Can peak CK-MB segregate patients with acute myocardial infarction into different outcome classes? Clin Chem 1985; 31(2):996-997. ICID: 844986.
RA Rudolph, LH Bernstein, J Babb. Information induction for predicting acute myocardial infarction. Clin Chem 1988; 34(10):2031-2038. ICID: 825568.
LH Bernstein, IJ Good, GI Holtzman, ML Deaton, J Babb. Diagnosis of acute myocardial infarction from two measurements of creatine kinase isoenzyme MB with use of nonparametric probability estimation. Clin Chem 1989; 35(3):444-447. ICID: 825570.
L H Bernstein, A Qamar, C McPherson, S Zarich, R Rudolph. Diagnosis of myocardial infarction: integration of serum markers and clinical descriptors using information theory. Clin Chem 1999; 72(1):5-13. ICID: 825618
Vermunt, J.K. & Magidson, J. (2000a). “Latent Class Cluster Analysis”, chapter 3 in J.A. Hagenaars and A.L. McCutcheon (eds.), Advances in Latent Class Analysis. Cambridge University Press.
Vermunt, J.K. & Magidson, J. (2000b). Latent GOLD 2.0 User’s Guide. Belmont, MA: Statistical Innovations Inc.
LH Bernstein, A Qamar, C McPherson, S Zarich. Evaluating a new graphical ordinal logit method (GOLDminer) in the diagnosis of myocardial infarction utilizing clinical features and laboratory data. Yale J Biol Med. 1999; 72(4):259-268. ICID: 825617.
L Bernstein, K Bradley, S Zarich. GOLDmineR: improving models for classifying patients with chest pain.
Yale J Biol Med. 2002; 75(4):183-198. ICID: 825624
SA Haq, M Tavakol, LH Bernstein, J Kneifati-Hayek, M Schlefer, et al. The ACC/ESC Recommendation for 99th Percentile of the Reference NormalTroponin I Overestimates the Risk of an Acute Myocardial Infarction: a novel enhancement in the diagnostic performance of troponins. “6th Scientific Forum on Quality of Care and Outcomes Research in Cardiovascular Disease and Stroke.” Circulation 2005; 111(20):e313-313. ICID: 939931.
LH Bernstein, MY Zions, SA Haq, S Zarich, J Rucinski, B Seamonds, …., John F Heitner. Effect of renal function loss on NT-proBNP level variations. Clin Biochem 2009; 42(10-11):1091-1098. ICID: 937529
SA Haq, M Tavakol, S Silber, L Bernstein, J Kneifati-Hayek, et al. Enhancing the diagnostic performance of troponins in the acute care setting. J Emerg Med 2008; ICID: 937619
Gil David, LarryH Bernstein, Ronald Coifman. Generating Evidence Based Interpretation of Hematology Screens via Anomaly Characterization. OCCJ 2011; 4(1):10-16. ICID: 939928
The use and limitations of high-sensitivity cardiac troponin and natriuretic peptide concentrations in at risk populations
Background: High-sensitivity cardiac troponin (hs-cTn) assays are now available that can detect measurable troponin in significantly more individuals in the general population than conventional assays. The clinical use of these hs-cTn assays depends on the development of proper reference values. However, even with a univariate biomarker for risk and/or severity of ischemic heart disease, a single reference value for the cardiac biomarker does not discriminate the probabilities between 2 or 3 different cardiac disorders, or identify any combination of these, such as, heart failure or renal disease > stage 2 and acute coronary syndrome. True, the physician has a knowledge of the history and presentation as a guide. Do we know how adequate the information is in a patient who has an atypical presentation? Again, the same problem arises with the use of the natriuretic peptides, but the value of these tests is improved over the previous generation tests. Let us parse through the components of this diagnostic problem, which is critical for reaching the best decisions under the circumstances.
Issue 1. The use of the clinical information, such as, patient age, gender, past medical history, known medical illness, CHEST PAIN, ECG, medications, are the basis of longstanding clinical practice. These may be sufficient in a patient who presents with acute coronary syndrome and a Q-wave not previously seen, or with ST-elevation, ST-depression, T-wave inversion, or rhythm abnormality. Many patients don’t present that way.
Issue 2. The use of a single ‘decision-value’ for critical situations decribed, leaves us with a yes-no answer. If you use a receiver-operator characteristic curve, all of the patients used to construct the sensitivity/specificity analysis have to be decisively known for identification. Otherwise, one might just take the median of a very large population, and the median represents the best value for a data set that is not normal distribution. However, the ROC method may inform about an acute event, if that is the purpose, but with a single value for a single variable, it can’t identify a likelihood of an event in the next six months.
Issue 3. There are several quantitative biomarkers that are considerably better than were available 15 years prior to this discussion. These can be used alone, but preferably in combination for diagnostic evaluation, for predictiong prognosis, and for therapeutic decision-making. What is now available was unimagined 20 years ago, both in test selection and in treatment selection.
Cardiac troponin assays were recently reviewed in Clin Chem by Fred Apple and Amy Seenger. (The State of Cardiac Troponin Assays: Looking Bright and Moving in the Right Direction).
Cardiac troponin assays have evolved substantially over 20 years, owing to the efforts of manufacturers to make them more precise and sensitive. These enhancements have led to high-sensitivity cardiac troponin assays, which ideally would give measureable values above the limit of detection (LoD) for 100% of healthy individuals and demonstrate an imprecision (CV) of ≤10% at the 99th percentile.
As laboratorians, we wish to comment on the recently published “ACCF 2012 Expert Consensus Document on Practical Clinical Considerations in the Implementation of Troponin Elevations”. Our purpose is to address 8 analytical issues that we believe have the potential to cause confusion and that therefore deserve clarification.
Since the initial publications by the National Academy of Clinical Biochemistry (NACB) in 1999 and by the European Society of Cardiology/American College of Cardiology in 2000, when both organizations endorsed cardiac troponin I (cTnI) or cTnT as the preferred biomarker for the detection of myocardial infaction, numerous other organizations have followed suit and promoted the sole use of cardiac troponin in this clinical application. The American College of Cardiology Foundation (ACCF) 2012 Expert Consensus Document summarizes the recently published 2012 Third Universal Definition of Myocardial Infarction by the Global Task Force, thus providing some practical recommendations on the use and interpretation of cardiac troponin in clinical practice.
This commentator has already expressed the view that there is no ‘silver bullet’, and the potential for confusion is not yet going to be resolved. The potential for greater accuracy in diagnosis is bolstered by currently available imaging.
Current strength of cardiac biomarker opportunities:
A recent study measured hs-tnI in 1716 (93%) of the community-based study cohort and 499 (88%) of the healthy reference cohort. Parameters that significantly contributed to higher hs-cTnI concentrations in the healthy reference cohort included age, male sex, systolic blood pressure, and left ventricular mass. Glomerular filtration rate and body mass index were not independently associated with hs-cTnI in the healthy reference cohort. Individuals with diastolic and systolic dysfunction, hypertension, and coronary artery disease (but not impaired renal function) had significantly higher hs-cTnI values than the healthy reference cohort.
The authors concluded that hs-cTnI assay with the aid of echocardiographic imaging in a large, well-characterized community-based cohort demonstrated hs-cTnI to be remarkably sensitive in the general population, and there are important sex and age differences among healthy reference individuals. Even though the results have important implications for defining hs-cTnI reference values and identifying disease, the reference value is not presented, and the question remains about how many subjects in the 88% (499) healthy reference consort had elevated systolic blood pressure or left ventricular hypertrophy (LVH) measured by imaging. Furthermore, while impaired renal function dropped out as an independent predictor of associated hs-cTnI, one would expect it to have a strong association with LVH.
Defining High-Sensitivity Cardiac Troponin Concentrations in the Community.
PM McKie, DM Heublein, CG. Scott, ML Gantzer, …and AS Jaffe.
Depart Med & Lab Med and Pathology, Mayo Clinic and Foundation, Rochester, MN; Siemens Diagnostics, Newark, DE. Clin Chem 2013.
hsTnI with NSTEMI
Another study looks at the prognostic performance of hs-TnI assay with non-STEMI. High-sensitivity assays for cardiac troponin enable more precise measurement of very low concentrations and improved diagnostic accuracy. However, the prognostic value of these measurements, particularly at low concentrations, is less well defined. (This is the sensitivity vs specificity dilemma raised with regard to the impoved hs-cTn assays.) But the value of low measured values is a matter for prognostic evaluation, based on the hypothesis that any cTnI that is measured in serum is leaked from cardiomyocytes. This assay evaluation used the Abbott ARCHITECT. The data were 4695 patients with non–ST-segment elevation acute coronary syndromes (NSTE-ACS) from the EARLY-ACS (Early Glycoprotein IIb/IIIa Inhibition in NSTE-ACS) and SEPIA-ACS1-TIMI 42 (Otamixaban for the Treatment of Patients with NSTE-ACS–Thrombolysis in Myocardial Infarction 42) trials. The primary endpoint was cardiovascular death or new myocardial infarction (MI) at 30 days. Baseline cardiac troponin was categorized at the 99th percentile reference limit (26 ng/L for hs-cTnI; 10 ng/L for cTnT) and at sex-specific 99th percentiles for hs-cTnI.
All patients at baseline had detectable hs-cTnI compared with 94.5% with detectable cTnT. With adjustment for all other elements of the TIMI risk score, patients with hs-cTnI ≥99th percentile had a 3.7-fold higher adjusted risk of cardiovascular death or MI at 30 days relative to patients with hs-cTnI <99th percentile (9.7% vs 3.0%; odds ratio, 3.7; 95% CI, 2.3–5.7; P < 0.001). Similarly, when stratified by categories of hs-cTnI, very low concentrations demonstrated a graded association with cardiovascular death or MI (P-trend < 0.001). Thus, Application of this hs-cTnI assay identified a clinically relevant higher risk of recurrent events among patients with NSTE-ACS, even at very low troponin concentrations.
Prognostic Performance of a High-Sensitivity Cardiac Troponin I Assay in Patients with Non–ST-Elevation Acute Coronary Syndrome. EA Bohula May, MP Bonaca, P Jarolim, EM Antman, …and DA Morrow. Clin Chem 2013.
Combination test with cTnI and a troponin
The next study looks at the value of a combination of cTnT and N-Terminal pro-B-type-natriuretic-peptide (NT proBNP) to predict heart failure risk. Recall that NT proBNP has been a stabd-alone biomarker for CHF. The study was done with the consideration that heart failure (HF) is projected to have the largest increases in incidence over the coming decades. Therefore, would cardiac troponin T (cTnT) measured with a high-sensitivity assay and N-terminal pro-B–type natriuretic peptide (NT-proBNP), biomarkers strongly associated with incident HF, improve HF risk prediction in the Atherosclerosis Risk in Communities (ARIC) study?
Using sex-specific models, we added cTnT and NT-proBNP to age and race (“laboratory report” model) and to the ARIC HF model (includes age, race, systolic blood pressure, antihypertensive medication use, current/former smoking, diabetes, body mass index, prevalent coronary heart disease, and heart rate) in 9868 participants without prevalent HF; area under the receiver operating characteristic curve (AUC), integrated discrimination improvement, net reclassification improvement (NRI), and model fit were described.
Over a mean follow-up of 10.4 years, 970 participants developed incident HF. Adding cTnT and NT-proBNP to the ARIC HF model significantly improved all statistical parameters (AUCs increased by 0.040 and 0.057; the continuous NRIs were 50.7% and 54.7% in women and men, respectively). Interestingly, the simpler laboratory report model was statistically no different than the ARIC HF model.
Troponin T and N-Terminal Pro-B–Type Natriuretic Peptide: A Biomarker Approach to Predict Heart Failure Risk: The Atherosclerosis Risk in Communities Study. V Nambi, X Liu, LE Chambless, JA de Lemos, SS Virani, et al.
Clin Chem 2013.
BCM Researchers Discover Simpler, Improved Biomarkers to Predict Heart Failure As Accurate As Complex Models Posted by: Anna Ishibashi Sep 17, 2013
Biomarkers for heart failure Researchers at the Baylor College of Medicine and the Michael E. DeBakey Veterans Affairs hospital discovered two improved biomarkers in the bloodstream that predict who is at higher risk of having heart failure in 10 years. The study was published in the journal Clinical Chemistry.
In the Atherosclerosis Risk in Communities (ARIC) clinical study, researchers measured the blood concentration of troponin T and N-terminal-pro-B-type natriuretic peptide (NT-proBNP) in the models, while also collecting age and race data. The important point taken from the study was that researchers did not find any difference in the accuracy of heart failure risk prediction statistically between this simpler test and the traditional, more complex one, which includes information of age, race, systolic blood pressure, antihypertensive medication use, smoking status, diabetes, body-mass index, prevalent coronary heart disease and heart rate.
Troponin T is an indicator of damaged heart muscle and can be detected in low levels even in individuals with no symptoms through this simpler, improved testing method. Similarly, NT-proBNP is a by-product of brain natriuretic peptide (BNP), which is a small neuropeptide hormone that has been shown to be effective in diagnosing congestive heart failure.
The critical issues that we must now address is what lifestyle and drug therapies can prevent the development of heart failures for individuals who are at high risk – according to Dr. Christie Ballantyne, professor of medicine and section chief of cardiology and cardiovascular research at BCM and the Houston Methodist Center for Cardiovascular Disease Prevention.
Although chest pain is widely considered a key symptom in the diagnosis of myocardial infarction (MI), not all patients with MI present with chest pain. This study was done the frequency with which patients with MI present without chest pain and to examine their subsequent management and outcome. A total of 434,877 patients with confirmed MI enrolled June 1994 to March 1998 in the National Registry of Myocardial Infarction, which includes 1674 hospitals in the United States. Outcome measures were prevalence of presentation without chest pain; clinical characteristics, treatment, and mortality among MI patients without chest pain vs those with chest pain.
Of all patients diagnosed as having MI, 142,445 (33%) did not have chest pain on presentation to the hospital. This group of MI patients was, on average, 7 years older than those with chest pain (74.2 vs 66.9 years), with a higher proportion of women (49.0% vs 38.0%) and patients with diabetes mellitus (32.6% vs 25.4%) or prior heart failure (26.4% vs 12.3%). Also, MI patients without chest pain had a longer delay before hospital presentation (mean, 7.9 vs 5.3 hours), were less likely to be diagnosed as having confirmed MI at the time of admission (22.2% vs 50.3%), and were less likely to receive thrombolysis or primary angioplasty (25.3% vs 74.0%), aspirin (60.4% vs 84.5%), β-blockers (28.0% vs 48.0%), or heparin (53.4% vs 83.2%). Myocardial infarction patients without chest pain had a 23.3% in-hospital mortality rate compared with 9.3% among patients with chest pain (adjusted odds ratio for mortality, 2.21 [95% confidence interval, 2.17-2.26]).
We tested the hypotheses that MI patients without chest pain compared with those with chest pain would present later for medical attention, would be less likely to be diagnosed as having acute MI on initial evaluation, and would receive fewer appropriate medical treatments within the first 24 hours. We also evaluated the association between the presence of atypical presenting symptoms and hospital mortality related to MI.
Our results suggest that patients without chest pain on presentation represent a large segment of the MI population and are at increased risk for delays in seeking medical attention, less aggressive treatments, and in-hospital mortality.
Prevalence, Clinical Characteristics, and Mortality Among Patients With Myocardial Infarction Presenting Without Chest Pain. JG Canto, MG Shlipak, WJ Rogers, JA Malmgren, PD Frederick, et al. JAMA 2013; 283(24):3223-3229. http://dx.doi.org/10.1001/jama.283.24.3223
cTnT degraded forms in circulation
This recent study questions whether degraded cTnT forms circulate in the patient’s blood. Separation of cTnT forms by gel filtration chromatography (GFC) was performed in sera from 13 AMI patients to examine cTnT degradation. The GFC eluates were subjected to Western blot analysis with the original antibodies from the Roche immunoassay used to mimic the clinical cTnT assay. GFC analysis of AMI patients’ sera revealed 2 cTnT peaks with retention volumes of 5 and 21 mL. Western blot analysis identified these peaks as cTnT fragments of 29 and 14–18 kDa, respectively. Furthermore, the performance of direct Western blots on standardized serum samples demonstrated a time-dependent degradation pattern of cTnT, with fragments ranging between 14 and 40 kDa. Intact cTnT (40 kDa) was present in only 3 patients within the first 8 h after hospital admission.
Time-Dependent Degradation Pattern of Cardiac Troponin T Following Myocardial Infarction. EPM Cardinaels, AMA Mingels T van Rooij, PO Collinson, FW Prinzen and MP van Dieijen-Visser. Clin Chem 2013.
Older patients with higher cTNI
One of the problems of interpretation of cTnI is the age relationship to the 99th percentile of the elderly. cTnI was measured using a high-sensitivity assay (Abbott Diagnostics) in 814 community-dwelling individuals at both 70 and 75 years of age. The cTnI 99th percentiles were determined separately using nonparametric methods in the total sample, in men and women, and in individuals with and without CVD.
The cTnI 99th percentile at baseline was 55.2 ng/L for the total cohort. Higher 99th percentiles were noted in men (69.3 ng/L) and individuals with CVD (74.5 ng/L). The cTnI 99th percentile in individuals free from CVD at baseline (n = 498) increased by 51% from 38.4 to 58.0 ng/L during the 5-year observation period. Relative increases ranging from 44% to 83% were noted across all subgroups. Male sex [odds ratio, 5.3 (95% CI, 1.5–18.3)], log-transformed N-terminal pro-B-type natriuretic peptide [odds ratio, 1.9 (95% CI, 1.2–3.0)], and left-ventricular mass index [odds ratio, 1.3 (95% CI, 1.1–1.5)] predicted increases in cTnI concentrations from below the 99th percentile (i.e., 38.4 ng/L) at baseline to concentrations above the 99th percentile at the age of 75 years.
cTnI concentration and its 99th percentile threshold depend strongly on the characteristics of the population being assessed. Among elderly community dwellers, higher concentrations were seen in men and individuals with prevalent CVD. Aging contributes to increasing concentrations, given the pronounced changes seen with increasing age across all subgroups. These findings should be taken into consideration when applying cTnI decision thresholds in clinical settings.
KM Eggers, Lars Lind, Per Venge and Bertil Lindahl. Factors Influencing the 99th Percentile of Cardiac Troponin I Evaluated in Community-Dwelling Individuals at 70 and 75 Years of Age/. Clin Chem 2013.
Background: Atrial natriuretic peptide (ANP) has antihypertrophic and antifibrotic properties that are relevant to AF substrates. The −G664C and rs5065 ANP single nucleotide polymorphisms (SNP) have been described in association with clinical phenotypes, including hypertension and left ventricular hypertrophy. A recent study assessed the association of early AF and rs5065 SNPs in low-risk subjects. In a Caucasian population with moderate-to-high cardiovascular risk profile and structural AF, we conducted a case-control study to assess whether the ANP −G664C and rs5065 SNP associate with nonfamilial structural AF.
Methods: 168 patients with nonfamilial structural AF and 168 age- and sex-matched controls were recruited. The rs5065 and −G664C ANP SNPs were genotyped.
Results: The study population had a moderate-to-high cardiovascular risk profile with 86% having hypertension, 23% diabetes, 26% previous myocardial infarction, and 23% left ventricular systolic dysfunction. Patients with AF had greater left atrial diameter (44 ± 7 vs. 39 ± 5 mm; P , 0.001) and higher plasma NTproANP levels (6240 ± 5317 vs. 3649 ± 2946 pmol/mL; P , 0.01). Odds ratios (ORs) for rs5065 and −G664C gene variants were 1.1 (95% confidence interval [CI], 0.7–1.8; P = 0.71) and 1.2 (95% CI, 0.3–3.2; P = 0.79), respectively, indicating no association with AF. There were no differences in baseline clinical characteristics among carriers and noncarriers of the −664C and rs5065 minor allele variants.
Conclusions: We report lack of association between the rs5065 and −G664C ANP gene SNPs and AF in a Caucasian population of patients with structural AF. Further studies will clarify whether these or other ANP gene variants affect the risk of different subphenotypes of AF driven by distinct pathophysiological mechanisms.
P Francia, A Ricotta, A Frattari, R Stanzione, A Modestino, et al.
Atrial Natriuretic Peptide Single Nucleotide Polymorphisms in Patients with Nonfamilial Structural Atrial Fibrillation.
Clinical Medicine Insights: Cardiology 2013:7 153–159 http://dx.doi.org/10.4137/CMC.S12239 http://www.la-press.com/atrial-natriuretic-peptide-single-nucleotide-polymorphisms-in-patients-article-a3882
Cystatin C and eGFR predict AMI or CVD mortality
BACKGROUND: The estimated glomerular filtration rate (eGFR) independently predicts cardiovascular death or myocardial infarction (MI) and can be estimated by creatinine and cystatin C concentrations. We evaluated 2 different cystatin C assays, alone or combined with creatinine, in patients with acute coronary syndrome.
METHODS: We analyzed plasma cystatin C, measured with assays from Gentian and Roche, and serum creatinine in 16 279 patients from the PLATelet Inhibition and Patient Outcomes (PLATO) trial. We evaluated Pearson correlation and agreement (Bland–Altman) between methods, as well as prognostic value in relation to cardiovascular death or MI during 1 year of follow up by multivariable logistic regression analysis including clinical variables, biomarkers, c-statistics, and relative integrated discrimination improvement (IDI).
RESULTS: Median cystatin C concentrations (interquartile intervals) were 0.83 (0.68–1.01) mg/L (Gentian) and 0.94 (0.80–1.14) mg/L (Roche). Overall correlation was 0.86 (95% CI 0.85–0.86). The level of agreement was within 0.39 mg/L (2 SD) (n = 16 279).
The areas under the curve (AUCs) in the multivariable risk prediction model with cystatin C (Gentian, Roche) or Chronic Kidney Disease Epidemiology Collaboration eGFR (CKD-EPI) added were 0.6914, 0.6913, and 0.6932. Corresponding relative IDI values were 2.96%, 3.86%, and 4.68% (n = 13 050). Addition of eGFR by the combined creatinine–cystatin C equation yielded AUCs of 0.6923 (Gentian) and 0.6924 (Roche) with relative IDI values of 3.54% and 3.24%.
CONCLUSIONS: Despite differences in cystatin C concentrations, overall correlation between the Gentian and Roche assays was good, while agreement was moderate. The combined creatinine–cystatin C equation did not outperform risk prediction by CKD-EPI.
A Åkerblom, L Wallentin, A Larsson, A Siegbahn, et al.
Cystatin C– and Creatinine-Based Estimates of Renal Function and Their Value for Risk Prediction in Patients with Acute Coronary Syndrome: Results from the PLATelet Inhibition and Patient Outcomes (PLATO) Study.
T2Dm has many subphenotypes in the prediabetic phase
For decades, glucose, hemoglobin A1c, insulin, and C peptide have been the laboratory tests of choice to detect and monitor diabetes. However, these tests do not identify individuals at risk for developing type 2 diabetes (T2Dm) (so-called prediabetic individuals and the subphenotypes therein), which would be a prerequisite for individualized prevention. Nor are these parameters suitable to identify T2Dm subphenotypes, a prerequisite for individualized therapeutic interventions. The oral glucose tolerance test (oGTT) is still the only means for the early and reliable identification of people in the prediabetic phase with impaired glucose tolerance (IGT). This procedure, however, is very time-consuming and expensive and is unsuitable as a screening method in a doctor′s office. Hence, there is an urgent need for innovative laboratory tests to simplify the early detection of alterations in glucose metabolism.
The search for diabetic risk genes was the first and most intensively pursued approach for individualized diabetes prevention and treatment. Over the last 20 years cohorts of tens of thousands of people have been analyzed, and more than 70 susceptibility loci associated with T2Dm and related metabolic traits have been identified. But despite extensive replication, no susceptibility loci or combinations of loci have proven suitable for diagnostic purposes.
Why did the genomic studies fail? One reason might be that T2Dm is a polygenetic disease, but there is another more important reason. The large diabetes cohorts investigated in these studies were very heterogeneous, consisting of poorly characterized individuals who were usually selected because they had an increase in blood glucose. Subsequently it has become clear that many different subphenotypes already exist in the prediabetic phase.
Metabolomics represents a new potential approach to move the diagnosis of diabetes beyond the application of the classical diabetic laboratory tests.
Rainer Lehmann. Diabetes Subphenotypes and Metabolomics: The Key to Discovering Laboratory Markers for Personalized Medicine?
Ca2+/calmodulin-dependent protein kinase II (CaMKII) has recently emerged as a ROS activated proarrhythmic signal
Background—Atrial fibrillation is a growing public health problem without adequate therapies. Angiotensin II (Ang II) and reactive oxygen species (ROS) are validated risk factors for atrial fibrillation (AF) in patients, but the molecular pathway(s) connecting ROS and AF is unknown. The Ca2+/calmodulin-dependent protein kinase II (CaMKII) has recently emerged as a ROS activated proarrhythmic signal, so we hypothesized that oxidized CaMKII(ox-CaMKII) could contribute to AF.
Methods and Results—We found ox-CaMKII was increased in atria from AF patients compared to patients in sinus rhythm and from mice infused with Ang II compared with saline. Ang II treated mice had increased susceptibility to AF compared to saline treated WT mice, establishing Ang II as a risk factor for AF in mice. Knock in mice lacking critical oxidation sites in CaMKII (MM-VV) and mice with myocardial-restricted transgenic over-expression of methionine sulfoxide reductase A (MsrA TG), an enzyme that reduces ox-CaMKII, were resistant to AF induction after Ang II infusion.
Conclusions—Our studies suggest that CaMKII is a molecular signal that couples increased ROS with AF and that therapeutic strategies to decrease ox-CaMKII may prevent or reduce AF.
Key words: atrial fibrillation, calcium/calmodulin-dependent protein kinase II, angiotensin II, reactive oxygen species, arrhythmia (mechanisms)
A Purohit, AG Rokita, X Guan, B Chen, et al. Oxidized CaMKII Triggers Atrial Fibrillation. Circulation. Sep 12, 2013;
Microparticles (MP)s give clues about vascular endothelial injury
BACKGROUND: Endothelial dysfunction is an early event in the development and progression of a wide range of cardiovascular diseases. Various human studies have identified that measures of endothelial dysfunction may offer prognostic information with respect to vascular events. Microparticles (MPs) are a heterogeneous population of small membrane fragments shed from various cell types. The endothelium is one of the primary targets of circulating MPs, and MPs isolated from blood have been considered biomarkers of vascular injury and inflammation.
CONTENT: This review summarizes current knowledge of the potential functional role of circulating MPs in promoting endothelial dysfunction. Cells exposed to different stimuli such as shear stress, physiological agonists, proapoptotic stimulation, or damage release MPs, which contribute to endothelial dysfunction and the development of cardiovascular diseases. Numerous studies indicate that MPs may trigger endothelial dysfunction by disrupting production of nitric oxide release from vascular endothelial cells and subsequently modifying vascular tone. Circulating MPs affect both proinflammatory and proatherosclerotic processes in endothelial cells. In addition, MPs can promote coagulation and inflammation or alter angiogenesis and apoptosis in endothelial cells.
SUMMARY: MPs play an important role in promoting endothelial dysfunction and may prove to be true biomarkers of disease state and progression.
Fina Lovren and Subodh Verma. Evolving Role of Microparticles in the Pathophysiology of Endothelial Dysfunction.
Outcomes of STEMI and NSTEMI different predicted by NPs after MI
Patients with increased blood concentrations of natriuretic peptides (NPs) have poor cardiovascular outcomes after myocardial infarction (MI). Data from 41 683 patients with non–ST-segment elevation MI (NSTEMI) and 27 860 patients with ST-segment elevation MI (STEMI) at 309 US hospitals were collected as part of the ACTION Registry®–GWTG™ (Acute Coronary Treatment and Intervention Outcomes Network Registry–Get with the Guidelines) (AR-G) between July 2008 and September 2009.
B-type natriuretic peptide (BNP) or N-terminal pro-BNP (NT-proBNP) was measured in 19 528 (47%) of NSTEMI and 9220 (33%) of STEMI patients. Patients in whom NPs were measured were older and had more comorbidities, including prior heart failure or MI. There was a stepwise increase in the risk of in-hospital mortality with increasing BNP quartiles for both NSTEMI (1.3% vs 3.2% vs 5.8% vs 11.1%) and STEMI (1.9% vs 3.9% vs 8.2% vs 17.9%). The addition of BNP to the AR-G clinical model improved the C statistic from 0.796 to 0.807 (P < 0.001) for NSTEMI and from 0.848 to 0.855 (P = 0.003) for STEMI. The relationship between NPs and mortality was similar in patients without a history of heart failure or cardiogenic shock on presentation and in patients with preserved left ventricular function.
NPs are measured in almost 50% of patients in the US admitted with MI and appear to be used in patients with more comorbidities. Higher NP concentrations were strongly and independently associated with in-hospital mortality in the almost 30 000 patients in whom NPs were assessed, including patients without heart failure.
BM Scirica, MB Kadakia, JA de Lemos, MT Roe, DA Morrow, et al. Association between Natriuretic Peptides and Mortality among Patients Admitted with Myocardial Infarction: A Report from the ACTION Registry®–GWTG™.
Predictive value of processed forms of BNP in circulation
B-type natriuretic peptide (BNP) is secreted in response to pathologic stress from the heart. Its use as a biomarker of heart failure is well known; however, its diagnostic potential in ischemic heart disease is less explored. Recently, it has been reported that processed forms of BNP exist in the circulation. We characterized processed forms of BNP by a newly developed mass spectrometry–based detection method combined with immunocapture using commercial anti-BNP antibodies.
Measurements of processed forms of BNP by this assay were found to be strongly associated with presence of restenosis. Reduced concentrations of the amino-terminal processed peptide BNP(5–32) relative to BNP(3–32) [as the index parameter BNP(5–32)/BNP(3–32) ratio] were seen in patients with restenosis [median (interquartile range) 1.19 (1.11–1.34), n = 22] vs without restenosis [1.43 (1.22–1.61), n = 83; P < 0.001] in a cross-sectional study of 105 patients undergoing follow-up coronary angiography. A sensitivity of 100% to rule out the presence of restenosis was attained at a ratio of 1.52. Processed forms of BNP may serve as viable potential biomarkers to rule out restenosis.
H Fujimoto, T Suzuki, K Aizawa, D Sawaki, J Ishida, et al. Processed B-Type Natriuretic Peptide Is a Biomarker of Postinterventional Restenosis in Ischemic Heart Disease. Clin Chem 2013.
Circulating proteins from patients requiring revascularization
More than a million diagnostic cardiac catheterizations are performed annually in the US for evaluation of coronary artery anatomy and the presence of atherosclerosis. Nearly half of these patients have no significant coronary lesions or do not require mechanical or surgical revascularization. Consequently, the ability to rule out clinically significant coronary artery disease (CAD) using low cost, low risk tests of serum biomarkers in even a small percentage of patients with normal coronary arteries could be highly beneficial. METHODS: Serum from 359 symptomatic subjects referred for catheterization was interrogated for proteins involved in atherogenesis, atherosclerosis, and plaque vulnerability. Coronary angiography classified 150 patients without flow-limiting CAD who did not require percutaneous intervention (PCI) while 209 required coronary revascularization (stents, angioplasty, or coronary artery bypass graft surgery). Continuous variables were compared across the two patient groups for each analyte including calculation of false discovery rate (FDR [less than or equal to]1%) and Q value (P value for statistical significance adjusted to [less than or equal to]0.01).
Significant differences were detected in circulating proteins from patients requiring revascularization including increased apolipoprotein B100 (APO-B100), C-reactive protein (CRP), fibrinogen, vascular cell adhesion molecule 1 (VCAM-1), myeloperoxidase (MPO), resistin, osteopontin, interleukin (IL)-1beta, IL-6, IL-10 and N-terminal fragment protein precursor brain natriuretic peptide (NT-pBNP) and decreased apolipoprotein A1 (APO-A1). Biomarker classification signatures comprising up to 5 analytes were identified using a tunable scoring function trained against 239 samples and validated with 120 additional samples. A total of 14 overlapping signatures classified patients without significant coronary disease (38% to 59% specificity) while maintaining 95% sensitivity for patients requiring revascularization. Osteopontin (14 times) and resistin (10 times) were most frequently represented among these diagnostic signatures. The most efficacious protein signature in validation studies comprised osteopontin (OPN), resistin, matrix metalloproteinase 7 (MMP7) and interferon gamma (IFNgamma) as a four-marker panel while the addition of either CRP or adiponectin (ACRP-30) yielded comparable results in five protein signatures.
Proteins in the serum of CAD patients predominantly reflected
-
a positive acute phase, inflammatory response and
-
alterations in lipid metabolism, transport, peroxidation and accumulation.
There were surprisingly few indicators of growth factor activation or extracellular matrix remodeling in the serum of CAD patients except for elevated OPN. These data suggest that many symptomatic patients without significant CAD could be identified by a targeted multiplex serum protein test without cardiac catheterization thereby eliminating exposure to ionizing radiation and decreasing the economic burden of angiographic testing for these patients.
WA Laframboise, R Dhir, LA Kelly, P Petrosko, JM Krill-Burger, et al. Serum protein profiles predict coronary artery disease in symptomatic patients referred for coronary angiography.
BMC Medicine (impact factor: 6.03). 12/2012; 10(1):157. http://dx.doi.org/10.1186/1741-7015-10-157
miRNAs in CAD
MicroRNAs are small RNAs that control gene expression. Besides their cell intrinsic function, recent studies reported that microRNAs are released by cultured cells and can be detected in the blood. To address the regulation of circulating microRNAs in patients with stable coronary artery disease. To determine the regulation of microRNAs, we performed a microRNA profile using RNA isolated from n=8 healthy volunteers and n=8 patients with stable coronary artery disease that received state-of-the-art pharmacological treatment. Interestingly, most of the highly expressed microRNAs that were lower in the blood of patients with coronary artery disease are known to be expressed in endothelial cells (eg, miR-126 and members of the miR-17 approximately 92 cluster). To prospectively confirm these data, we detected selected microRNAs in plasma of 36 patients with coronary artery disease and 17 healthy volunteers by quantitative PCR. Consistent with the data obtained by the profile, circulating levels of miR-126, miR-17, miR-92a, and the inflammation-associated miR-155 were significantly reduced in patients with coronary artery disease compared with healthy controls. Likewise, the smooth muscle-enriched miR-145 was significantly reduced. In contrast, cardiac muscle-enriched microRNAs (miR-133a, miR-208a) tend to be higher in patients with coronary artery disease. These results were validated in a second cohort of 31 patients with documented coronary artery disease and 14 controls. Circulating levels of vascular and inflammation-associated microRNAs are significantly downregulated in patients with coronary artery disease.
S Fichtlscherer, S De Rosa, H Fox, T Schwietz, A Fischer, et al. Circulating microRNAs in patients with coronary artery disease. Circulation Research 09/2010; 107(5):677-84.
Imaging modalities compared
This review compares the noninvasive anatomical imaging modalities of coronary artery calcium scoring and coronary CT angiography to the functional assessment modality of MPI in the diagnosis and prognostication of significant CAD in symptomatic patients. A large number of studies investigating this subject are analyzed with a critical look on the evidence, underlying the strengths and limitations. Although the overall findings of the presented studies are favoring the use of CT-based anatomical imaging modalities over MPI in the diagnosis and prognosticating of CAD, the lack of a high number of large- scale, multicenter randomized controlled studies limits the generalizability of this early evidence. Further studies comparing the short- and long-term clinical outcomes and cost-effectiveness of these tests are required to determine their optimal role in the management of symptomatic patients with suspected CAD.
Y Hacioglu, M Gupta, Matthew J Budoff. Noninvasive anatomical coronary artery imaging versus myocardial perfusion imaging: which confers superior diagnostic and prognostic information?
Journal of computer assisted tomography 34(5):637-44.
Three Dimensional In-Room Imaging (3DCA) in PCI
Introduction: Coronary angiography is a two-dimensional (2D) imaging modality and thus is limited in its ability to represent complex three-dimensional (3D) vascular anatomy. Lesion length, bifurcation angles/lesions, and tortuosity are often inadequately assessed using 2D angiography due to vessel overlap and foreshortening. 3D Rotational Angiography (3DRA) with subsequent reconstruction generates models of the coronary vasculature from which lesion length measurements and Optimal View Maps (OVM) defining the amount of vessel foreshortening for each gantry angle can be derived. This study sought to determine if 3DRA-assisted percutaneous coronary interventions resulted in improved procedural results by minimizing foreshortening and optimizing stent selection.
Rotational angiographic acquisitions were performed and a 3D model was generated from two images greater than 30° apart. An optimal view map identifying the least amount of vessel foreshortening and overlap was derived from the 3D model.
The clinical validation of in-room image-processing tools such as 3DCA and optimal view maps is important since FDA approval of these tools does not require the presentation of any data on clinical experience and impact on clinical outcomes. While the technology of 3DRA and optimal view calculations has been well validated by the work of Chen and colleagues, this study is important in demonstrating how clinical care may be impacted [4,5,7]. This study was biased toward minimizing the impact of these tools on clinical decision-making since the study site, cardiologists, and staff have extensive experience in rotational angiography, 3-D modeling and reconstruction, and the impact of foreshortening on the assessment of lesion length and choice of stent size.
3DRA assistance significantly reduced target vessel foreshortening when compared to operator’s choice of working view for PCI (2.99% ± 2.96 vs. 9.48% ± 7.56, p=0.0001). The operators concluded that 3DRA recommended better optimal view selection for PCI in 14 of 26 (54%) total cases. In 9 (35%) of 26 cases 3DRA assistance facilitated stent positioning. 3DRA based imaging prompted stent length changes in 4/26 patients (15%).
MH. Eng, PA Hudson, AJ Klein, SYJ Chen, … , JA Garcia. Impact of Three Dimensional In-Room Imaging (3DCA) in the Facilitation of Percutaneous Coronary Interventions. J Cardio Vasc Med 2013; 1: 1-5.
Related References from PharmaceuticalIntelligence.com:
Genomics & Genetics of Cardiovascular Disease Diagnoses: A Literature Survey of AHA’s Circulation Cardiovascular Genetics, 3/2010 – 3/2013
Curators: Aviva Lev-Ari, PhD, RN and Larry H. Bernstein, MD, FCAP
http://pharmaceuticalintelligence.com/2013/03/07/genomics-genet…cs-32010-32013/
http://wp.me/p2kEDv-2Jp
Prognostic Marker Importance of Troponin I in Acute Decompensated Heart Failure (ADHF)
Larry H Bernstein and Aviva Lev-Ari
http://pharmaceuticalintelligence.com/2013/06/30/troponin-i-in-…-heart-failure
http://wp.me/p2kEDv-41S
A Changing expectation from cardiac biomarkers.
Larry H Bernstein
http://pharmaceuticalintelligence.com/2012/12/25/assessing-card…ith-biomarkers/
http://wp.me/p2kEDv-1DN
Dealing with the Use of the High Sensitivity Troponin (hs cTn) Assays
Larry H Bernstein and Aviva Lev-Ari
http://pharmaceuticalintelligence.com/2013/05/18/dealing-with-t…-hs-ctn-assays/
http://pharmaceuticalintelligence.com/wp-admin/post.php?post=13255
http://wp.me/p2kEDv-3rN
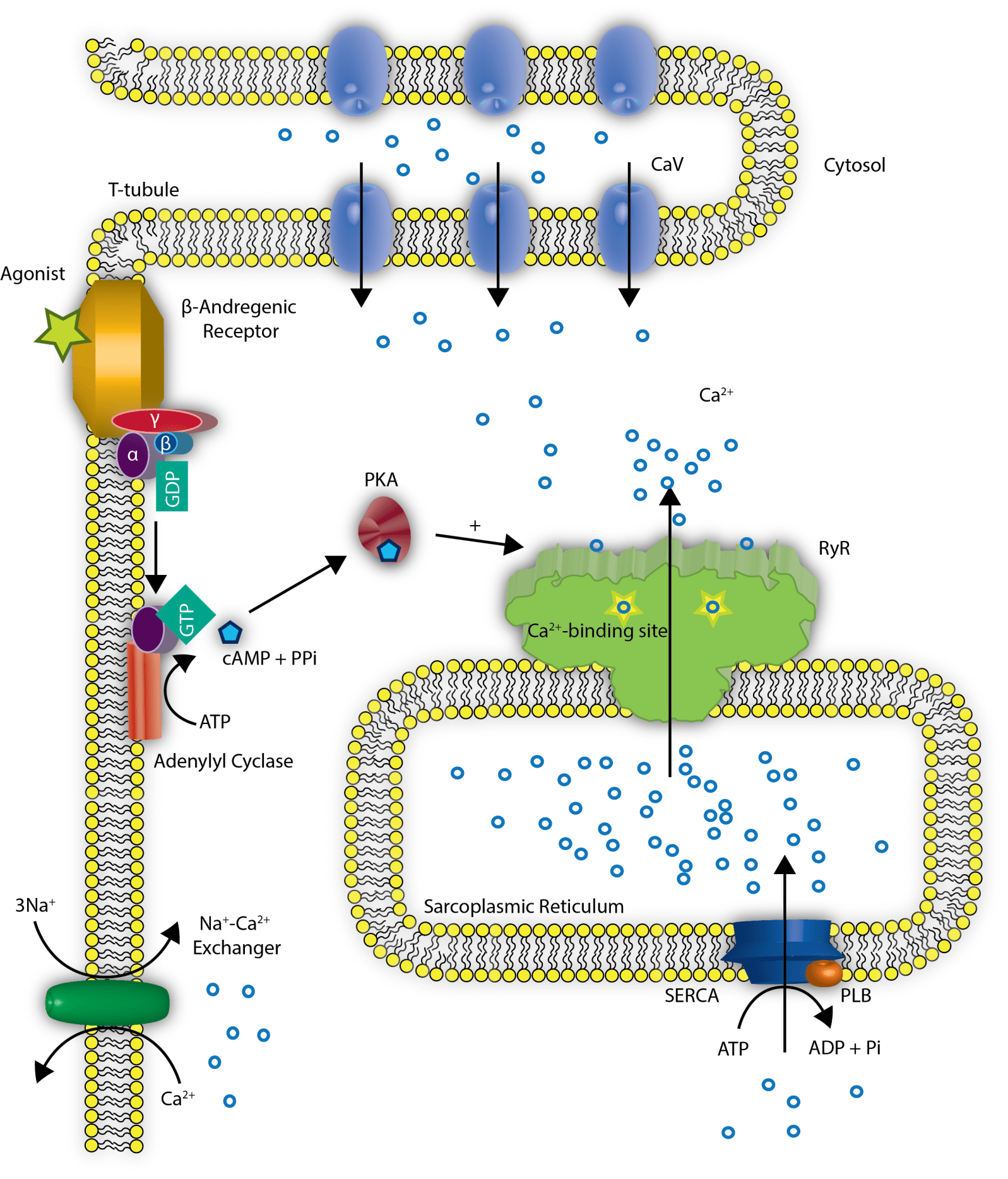
For Disruption of Calcium Homeostasis in Cardiomyocyte Cells, see
Part VI: Calcium Cycling (ATPase Pump) in Cardiac Gene Therapy: Inhalable Gene Therapy for Pulmonary Arterial Hypertension and Percutaneous Intra-coronary Artery Infusion for Heart Failure: Contributions by Roger J. Hajjar, MD
Aviva Lev-Ari, PhD, RN
http://pharmaceuticalintelligence.com/2013/08/01/calcium-molecule-in-cardiac-gene-therapy-inhalable-gene-therapy-for-pulmonary-arterial-hypertension-and-percutaneous-intra-coronary-artery-infusion-for-heart-failure-contributions-by-roger-j-hajjar/
Part VII: Cardiac Contractility & Myocardium Performance: Ventricular Arrhythmias and Non-ischemic Heart Failure – Therapeutic Implications for Cardiomyocyte Ryanopathy (Calcium Release-related Contractile Dysfunction) and Catecholamine Responses
Justin Pearlman, MD, PhD, FACC, Larry H Bernstein, MD, FCAP and Aviva Lev-Ari, PhD, RN
http://pharmaceuticalintelligence.com/2013/08/28/cardiac-contractility-myocardium-performance-ventricular-arrhythmias-and-non-ischemic-heart-failure-therapeutic-implications-for-cardiomyocyte-ryanopathy-calcium-release-related-contractile/
Part VIII: Disruption of Calcium Homeostasis: Cardiomyocytes and Vascular Smooth Muscle Cells: The Cardiac and Cardiovascular Calcium Signaling Mechanism
Justin Pearlman, MD, PhD, FACC, Larry H Bernstein, MD, FCAP and Aviva Lev-Ari, PhD, RN
http://pharmaceuticalintelligence.com/2013/09/12/disruption-of-calcium-homeostasis-cardiomyocytes-and-vascular-smooth-muscle-cells-the-cardiac-and-cardiovascular-calcium-signaling-mechanism/
Read Full Post »